










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1.-INTRODUCCIÓN
La autenticación de un usuario para concederle acceso a un sistema o recurso es un aspecto esencial para la seguridad de la información [1]. Según la información que utilizan, los sistemas de autenticación suelen clasificarse en: sistemas basados en conocimiento (¿qué sabes?), en Tokens (¿qué tienes?) y en información Biométrica (¿quién eres?). Los basados en conocimiento emplean contraseñas, las que pueden ser alfanuméricas o gráficas [2].
Las contraseñas alfanuméricas son las más empleadas, a pesar de que poseen una contradicción entre su seguridad y su usabilidad, pues para ser seguras deben ser aleatorias, largas y no predecibles mientras que para ser usables deben ser memorizables, esta contradicción suele denotarse como the password problem [3]. Estas debilidades reducen el espacio de búsqueda y las hacen predecibles y vulnerables a diversos ataques basados en modelos probabilísticos [4].
Un interesante estudio sobre la aplicación de modelos probabilísticos para realizar ataques de diccionarios a las contraseñas alfanuméricas y también para evaluar su seguridad puede verse en [5]. Se profundiza en los dos modelos principales, los modelos de Márkov [6-7] y las gramáticas libres de contexto [8-10]. Existen otros modelos menos populares como la ley de zip [11-14], las redes neuronales [15] y técnicas de aprendizaje automático [16-17].
Para las contraseñas gráficas el empleo de modelos probabilísticos ha sido menos investigado y existen menos modelos. En su mayoría estos se basan en técnicas de tratamiento de imágenes digitales y en las características de la imagen [18-20]. Estos modelos permiten pronosticar, para cada imagen, la clave más probable a seleccionar por el usuario que se va a registrar. Se usan para escoger las imágenes más adecuadas a emplear en este tipo de autenticación y también para desarrollar ataques de diccionario.
En este trabajo se propone un nuevo modelo probabilístico de contraseñas gráfica, la novedad principal de este modelo consiste en que después que un usuario es autenticado, este modelo permite cuantificar la autenticidad de este usuario, asignándole una probabilidad de ser el usuario legítimo. Hasta donde saben los autores de este trabajo, no existen antecedentes de esto en los modelos de contraseñas gráficas. Se confirma experimentalmente que el modelo propuesto es efectivo y permite medir en la práctica el nivel de autenticidad de los usuarios autenticados.
Esta investigación se centra específicamente en los sistemas de autenticación gráfica del tipo Cued Recal [21-22].
2. PRELIMINARES
2.1. MODELOS PROBABILÍSTICOS: CONTRASEÑAS ALFANUMÉRICAS
Modelos Probabilísticos de contraseñas: Un modelo probabilístico de contraseñas [5], está determinado por cualquier función P, definida en el espacio de posibles contraseñas (S) en el intervalo [0,1], que asigna una probabilidad P(s) a cada contraseña de forma tal que:
Estos modelos constituyen una herramienta fundamental para investigar la seguridad de las contraseñas [5]. La definición e interpretación de P(s), depende del modelo.
La existencia de grandes bases de datos de contraseñas alfa- numéricas disponibles en internet [23], ha permitido capturar experimentalmente sus características, las que son utilizadas para la definición de P(s). Las cadenas de Márkov y las gramáticas libres de contexto han sido los dos modelos más empleados para cuantificar mediante P(s) la probabilidad de que esa contraseña s sea seleccionada, por el usuario, en la fase de registro. Estos valores P(s) son la base de los ataques de diccionario y de algunas métricas de evaluación de la seguridad de las contraseñas ([8], [24], [26],[39]).
Existen diversas herramientas (consideradas software libre) para atacar contraseñas [23], las cuales hacen uso de diferentes modelos y de la información obtenida de las bases de datos. Entre estas herramientas para investigar la seguridad de las contraseñas alfanuméricas se destaca PARS [27], una plataforma propuesta en 2015 que contiene 12 algoritmos para atacar contraseñas, 15 sitios sobre métricas de fortaleza de contraseñas, 8 métricas académicas de fortaleza de contraseñas y 15 métricas comerciales de fortaleza de contraseñas. En [27] se propone una herramienta estadística, para clasificar en 3 clases los intentos de autenticación mediante contraseñas alfanuméricas, detectando los intentos sospechosos. Se emplean diferentes parámetros como: dirección IP, geolocalización, configuración del browser, hora, etc.
En [5] se clasifican las investigaciones sobre contraseñas atendiendo a su objetivo, esta clasificación debe ser ampliada para incluir investigaciones como [27] y la propuesta en este trabajo. En [21] se presenta un resumen muy completo hasta 2011 de los sistemas de autenticación basados en contraseñas gráficas, [22] se enfoca en los sistemas del tipo Cued click points. Una descripción y evaluación critica actualizada de la seguridad y usabilidad de los diferentes sistemas de autenticación
2.2. SISTEMAS DE AUTENTICACIÓN GRÁFICA CUED RECALL
En [21] se presenta un resumen muy completo hasta 2011 de los sistemas de autenticación basados en contraseñas gráficas, [22] se enfoca en los sistemas del tipo Cued click points. Una descripción y evaluación crítica actualizada de la seguridad y usabilidad de los diferentes sistemas de autenticación gráfica puede verse en [4]. Una propuesta de 2018 para implementar autenticación para computación en la nube mediante contraseñas gráficas, se propone en [28]. En [29] se comparan distintos sistemas de autenticación gráfica de acuerdo a los parámetros usabilidad, confiabilidad, funcionalidad, mantenibilidad, eficiencia y portabilidad como se definen en la norma ISO − 9126 [30].
En los Sistemas de Autenticación Gráfica del tipo Cued Recall, la contraseña del usuario consiste en k puntos (pixeles) que este selecciona, en la fase de registro, de una (o varias) imágenes, dada por el sistema o escogida por el usuario. Se espera que el usuario legítimo recuerde aproximadamente el orden y la posición de los k pixeles seleccionados en la fase de registro, pero realmente es muy poco probable que logre recordar de forma exacta la posición de cada pixel. Por esta razón la imagen se discretiza, definiéndose una región de tolerancia alrededor de cada punto. En la fase de registro, el sistema por cuestiones de seguridad, no almacena los k puntos, ni sus regiones de tolerancia, sino el valor del hash de la concatenación ordenada de las k regiones de tolerancia determinadas por la contraseña.
En estos sistemas se han empleado varios métodos de discretización para definir la región de tolerancia, la discretización robusta [31], la centrada [32] y la óptima [33]. La discretización robusta requiere una región de tolerancia mayor que las centrada y óptima. Una descripción detallada de estas tres discretizaciones y una discusión de sus limitaciones puede verse en [34].
Para autenticarse, el usuario debe escoger en el orden correcto, los mismos k puntos aproximadamente. Será autenticado sí y solo sí los puntos que escoge determinan un hash igual al que fue guardado por el sistema, es decir si los k puntos que escogió están dentro de las regiones de tolerancia (definidas por el método de discretización) de su correspondiente punto de la contraseña. Entre los sistemas de este tipo, destaca por sus ventajas el sistema Pass Point [35].
El espacio de claves queda determinado por 3 parámetros, el tamaño de la imagen, el tamaño de la región de tolerancia, y el numero k de puntos de la contraseña. Para cada tamaño de imagen se pueden escoger el número de k puntos y el tamaño de la región de tolerancia de forma que la dimensión del espacio de contraseñas sea mayor que para una contraseña alfanumérica de k puntos.
2.3. LIMITACIONES DE LOS MÉTODOS DE DISCRETIZACIÓN
Durante la autenticación entre las principales limitaciones detectadas se encuentran:
Primera: La distancia entre el punto de la contraseña y el punto escogido para la autenticación se tiene en cuenta para autenticar o no al usuario, pero no se tiene en cuenta entre los usuarios autenticados. La autenticación no hace distinción entre los puntos dentro de la región de tolerancia y le da el mismo tratamiento a todos los puntos dentro de esta región. Este enfoque tiene una limitación pues contradice el comportamiento esperado para un usuario legítimo, del cual intuitivamente se espera que escoja con mayor frecuencia a los puntos más cercanos al punto legítimo de la contraseña. Sorpresivamente, no se han encontrado reportes donde se discuta esta limitación de la autenticación gráfica, la cual se investigará usando el modelo propuesto en este trabajo.
Segunda: Existen algunas parejas de puntos situados ambos a la misma distancia del punto de la contraseña, sin embargo, unos quedan dentro de la región de tolerancia y otros quedan fuera. Estos puntos serian igualmente aceptables para el usuario legítimo, sin embargo, la discretización les da un tratamiento diferente.
Tercera: Existen algunas parejas de puntos, tales que ambos están situados a diferentes distancias del punto de la contraseña, pero uno es interno a la región de tolerancia y el otro es externo. La limitación de la discretización consiste en que el punto que queda fuera de la región de tolerancia está más cerca del punto de la contraseña que el que queda adentro.
Las limitaciones segunda y tercera se deben a que la región de tolerancia es cuadrada mientras la distancia define un círculo, una solución podría ser definir una región de tolerancia circular [34], [36].
Cuarta: Cada una de estas discretizaciones conserva cierta información necesaria para repetir la discretización de la imagen en la fase de autenticación. Esa información es aprovechada para aumentar la efectividad de los ataques de diccionario [37], [38].
2.4. MODELOS PROBABILÍSTICOS DE CONTRASEÑAS GRÁFICAS
En contraseñas gráficas, no existen bases de datos de contraseñas disponibles en internet, pero aun así se han aplicado modelos probabilísticos [18-20]. Las características de la función P(s) han sido extraídas de tres fuentes principales, en primer lugar, de la propia imagen propuesta para la autenticación usando técnicas de segmentación de imágenes para detectar las regiones más probables. En segundo lugar, de la información aportada por el método de discretización y tercero de las características personales del usuario. Estos modelos son aplicados en ataques de diccionario, pero hasta donde sabemos, en ningún caso se aplica un modelo para cuantificar el grado de autenticidad del usuario.
En [18] se propone un modelo que para cada punto de la imagen calcula la probabilidad de que, en la fase de registro, ese punto sea seleccionado por el usuario legítimo como punto de la contraseña. Emplean segmentación de imágenes para detectar las regiones más probables. Es aplicable en ataques de diccionario y también para evaluar si una imagen es apropiada para ser usada en este tipo de autenticación.
En [19] a partir de la información en claro que el sistema guarda en el proceso de discretización, se construyen diccionarios de contraseñas más probables que permiten realizar ataques de diccionarios, altamente efectivos. En [20] se demuestra que existe correlación estadística entre las características personales del usuario (edad, sexo, etnia, educación, etc.) y los patrones existentes en la contraseña que el selecciona. Se propone una métrica para medir la fortaleza de las contraseñas, a partir de los patrones que ella contiene, sin conocimiento previo de la imagen, ni estudios estadísticos de contraseñas previas.
En conclusión, los sistemas de autenticación gráfica del tipo cued recall, clasifican a los usuarios que tratan de autenticarse en dos clases: usuario legítimo o usuario ilegítimo, pero no son capaces de diferenciar a los usuarios dentro de una de estas clases. El resultado de [25] para contraseñas alfanuméricas nos motivó a investigar la forma de definir para contraseñas gráficas una función P(S) que sea capaz de separar a los usuarios según su grado de legitimidad. Los resultados se muestran en el siguiente epígrafe y constituyen el aporte principal de este trabajo.
3. RESULTADOS Y DISCUSIÓN
3.1. NOTACIONES, HIPÓTESIS Y TRANSFORMACIÓN DEL ESTADÍGRA-FO DE VEROSIMILITUD
Se denotará por
A la contraseña
Por propiedades del logaritmo,
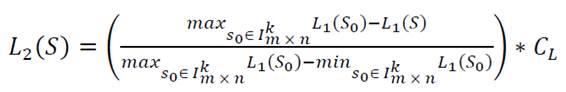 (3)
(3)
La transformación
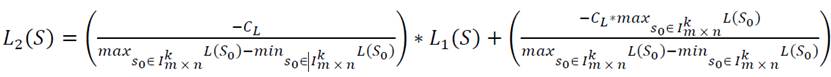 (4)
(4)
Para
El problema al calcular
La distancia
3.2. MODELACIÓN PROBABILÍSTICA DE LA AUTENTICACIÓN EN LOS SISTEMAS DE AUTENTICACIÓN GRÁFICA CUED RECALL
Denotando por
Este modelo refleja mediante la región
Si el usuario escoge un punto
El modelo asigna la misma probabilidad
Cada una de las
En resumen, una característica de la autenticación en estos sistemas y de este modelo asociado es que no tienen en cuenta las diferencias de los valores
3.3. MODELACIÓN DEL USUARIO LEGÍTIMO
Condiciones sobre P(s). Las condiciones 1 y 2 son las comunes a cualquier modelo probabilístico, para garantizar que
Condición 1:
Condición 2:
Se espera que el usuario legítimo escoja puntos s tales que
Condición 3:
En los sistemas actuales un usuario es autenticado si y solo si todos los puntos escogidos por ese usuario caen dentro de sus respectivas zonas de tolerancia, por eso
Para flexibilizar el proceso de autenticación y admitir esta posibilidad se introduce en el modelo un parámetro ε tal que
Condición 4:
La probabilidad de error de autenticación para el usuario legítimo será igual a:
3.4. MODELO PROBABILÍSTICO DE AUTENTICACIÓN GRÁFICA
Se propone una nueva función
Tal que
Interpretación geométrica de
Propuesta de
Para aplicar esta función se debe definir su argumento x como función de
Donde
Esta elección de P(s) cumple que:
Si
Para garantizar la condición
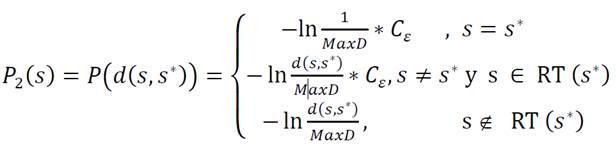 (10)
(10)
Para garantizar las condiciones 1 y 2 basta con dividir entre la suma de los valores de
Comparación de
Sobre el parámetro
Sustituyendo (10) en (12) se obtiene:
Por lo tanto, si analizamos el comportamiento del parámetro
Una forma de aumentar la influencia del parámetro
Al aumentar el valor del parámetro α aumentan
4. VALIDACIÓN EXPERIMENTAL DEL MODELO
Se comprobará que la expresión
Las probabilidades como función decreciente de las distancias. Para
Alta Probabilidad de la pequeña región de tolerancia. En una imagen de
A partir de las probabilidades
Diseño del experimento. Se empleó una imagen de dimensión
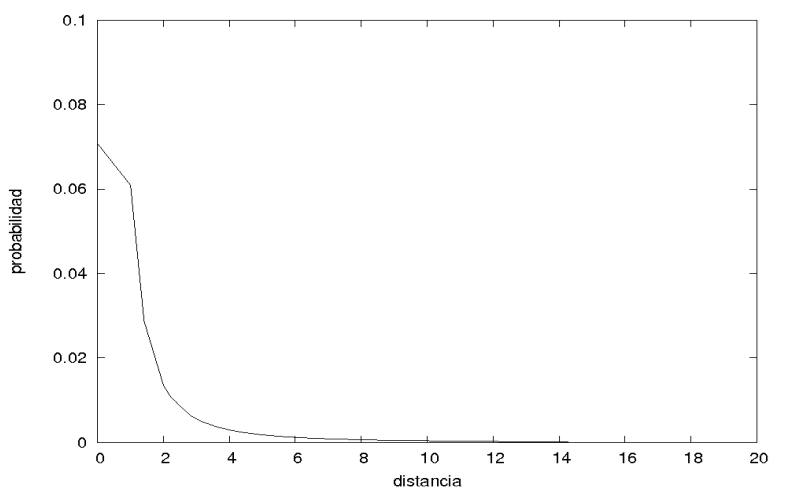
Figura 1 Probabilidades
Tabla 1 Porcentaje de puntos en la región de tolerancia y su probabilidad en una imagen de 441 × 331
|
|
|
|
|
|
0,05 | 0,302 |
|
|
0.95=1-0,05 | 0,99 = 1 − 0,01 |
El objetivo del experimento es comprobar si los valores de
Grupo G1: La contraseña
Grupo G2: Los 5 puntos
Grupo G3: Modelación de un usuario ilegítimo con más información, al menos uno de los puntos está dentro de la región de tolerancia, con una distancia tal que
Grupo G4: Los 5 puntos seleccionados por el usuario que intenta autenticarse están siempre fuera de la zona de tolerancia de
En cada grupo, los pixeles de la contraseña se escogieron aleatoriamente dentro del rango de distancias que caracterizan al grupo. Los métodos actuales de autenticación gráfica, autenticarán a los usuarios de los grupos 1 y 2, pero sin distinguir la diferencia entre ellos, mientras rechazan a usuarios de grupos 3 y 4.
Se espera que para las contraseñas
Para que el modelo sea efectivo, se espera que los valores de
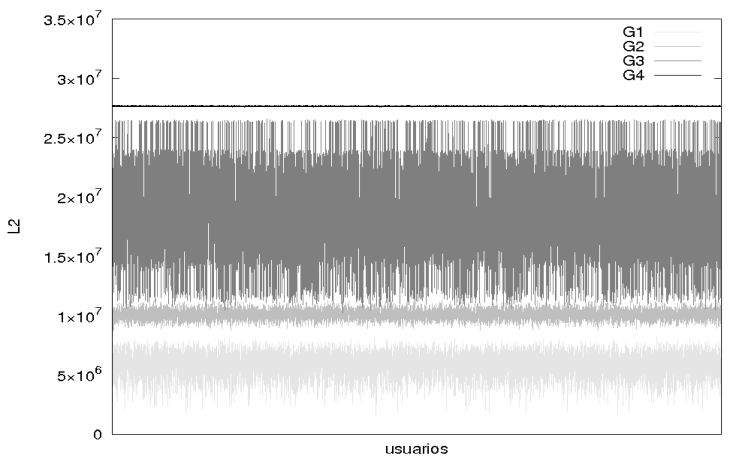
Discusión de los resultados. Se observa que el estadígrafo
El valor de
El grupo G3, a pesar de tener algunos puntos dentro de la región de tolerancia, es reconocido correctamente por el modelo la casi totalidad de las veces como un usuario ilegítimo, se observan algunos caso en que se confunde con un usuario del grupo 2. Lo más importante a destacar es que los valores de
Estos resultados experimentales validan la efectividad práctica del modelo para cuantificar el nivel de autenticidad de los usuarios, significa que el modelo propuesto permite diferenciar a los usuarios que son autenticados por el sistema, asignándoles diferentes grados de autenticidad y sugiere que tal vez el modelo pueda ser empleado para detectar los ataques de diccionario que realizan un pronóstico de la contraseña, lo cual es un aspecto que debe ser investigado. Los resultados ilustrados en la Figura 2 se resumen en la Figura 3 y en la Tabla 2.
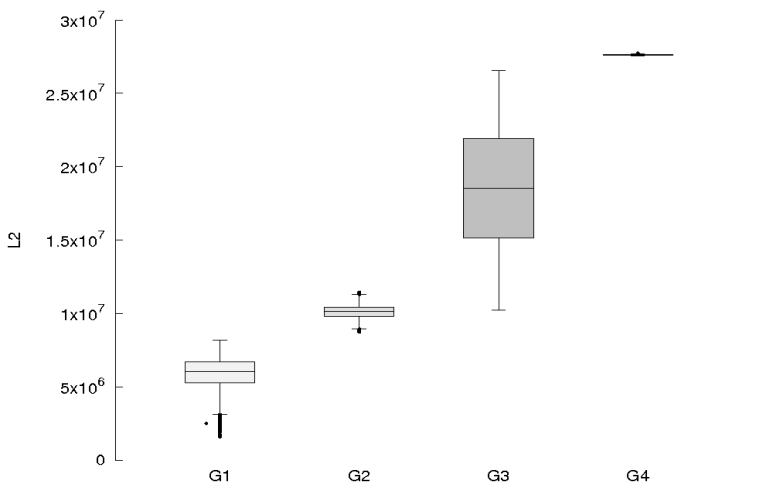
Tabla 2 Valores máximo y mínimo de
| Grupo | Máximo |
Frecuencia | Mínimo |
Frecuencia |
|---|---|---|---|---|
| 8201503 | 1 | 1602158 | 1 | |
| 11453131 | 1 | 8735939 | 1 | |
| 26546809 | 1 | 10252333 | 1 | |
| 27743039 | 1 | 27568825 | 1 | |
|
|
27743039 | 1 | 1602158 | 1 |
En la Figura 3 se observa que los valores esperados de
Estos resultados sugieren definir 3 umbrales y 4 regiones en las que se puede clasificar a los usuarios autenticados según su nivel de autenticidad, los cuales se presentan en la Tabla 3.
Tabla 3 Umbrales para los valores de
| Región |
|
Nivel de Autenticidad |
|---|---|---|
|
|
Alto | |
|
|
Medio | |
|
|
Bajo | |
|
|
Muy bajo |
Los usuarios de la región R4 corresponden a los no autenticados y las regiones R1, R2 y R3 a los autenticados, se propone investigar la forma de aprovechar este nuevo conocimiento sobre su nivel de autenticidad, por ejemplo, a los de la región R3 se les puede exigir alguna información adicional antes de autenticarlo. Se requieren nuevos experimentos con mayor número de muestras y diversidad de usuarios para evaluar con más exactitud el nivel de precisión alcanzado por el modelo y la conveniencia de redefinir los umbrales. Esta es una dirección de trabajo futuro.
5. INTRODUCCIÓN PRÁCTICA DEL MODELO EN LOS SISTEMAS DE AUTENTICACIÓN GRÁFICA
Para obtener
La dificultad anterior puede resolverse, en algunos casos, teniendo en cuenta las propiedades de los métodos de discretización. En discretización centrada y optima, una vez que un usuario es autenticado, se puede calcular, a cada uno de los puntos
El enfoque anterior no es aplicable en discretización robusta pues no se pueden recobrar los k puntos de la contraseña. Se propone para futuros trabajos, desarrollar una aplicación para incluir este criterio en sistemas de autenticación gráfica que emplean discretización óptima o centrada.
6. CONCLUSIONES Y TRABAJO FUTURO
Se obtuvo un nuevo modelo probabilístico que permite distinguir/clasificar a los usuarios asignándoles una probabilidad
A los usuarios autenticados con baja probabilidad de ser legítimos, se les puede solicitar una autenticación adicional lo cual aumentaría la seguridad del sistema de autenticación. Este modelo es aplicable on-line en los sistemas de autenticación que emplean discretización centrada y óptima. No puede ser empleado en los sistemas que emplean discretización robusta pues la información que requiere no está disponible y es necesario hallar la forma de hacerla accesible sin comprometer la seguridad del sistema.
Algunas direcciones de trabajos futuros son:
Desarrollar una aplicación que implemente el modelo y pueda incorporarse en sistemas de autenticación gráfica aumentando su seguridad.
Obtener valoraciones sobre la eficiencia de esta aplicación para evaluar la afectación a la usabilidad de los sistemas en que se utilice.
Evaluar el modelo en escenarios más complejos, por ejemplo, simulando a usuarios ilegítimos que tratan de pronosticar la contraseña por ataques de diccionarios, los cuales pueden llegar a tener varios puntos dentro de la región de tolerancia y hasta cerca del punto de la contraseña.
Caracterizar el comportamiento de
Usar el modelo para calcular k distribuciones de probabilidades, una por cada punto de la contraseña y cada una definidas sobre todos los puntos de la imagen, considerando la dependencia entre los k puntos.
Explorar el empleo de otros tipos de funciones
Cambiar el enfoque axiomático, para estimar la distribución a partir de muestras de las distancias

