










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Para finales del año 2050 se prevé un incremento de la población mundial a aproximadamente 9,1 billones de personas, lo que constituye un 34% más que la población actual; bajo esas condiciones, los requerimientos de alimentos se incrementarán un 70% [1]. En este sentido la agricultura juega un papel predominante, al ser la mayor fuente de alimentos. Sin embargo, para su desarrollo, es necesario el uso de varios recursos dentro de los que se destaca el agua, con un impacto significativo en la irrigación. Ante este complejo panorama es necesario optimizar el consumo de agua en la agricultura [2].
Los sistemas de irrigación por goteo ofrecen los mejores índices de conservación de agua entre todos los demás sistemas de irrigación. La principal razón de esta conservación se encuentra en que limita la zona humedecida a aproximadamente un 30% de lo permitido por los demás sistemas, reduciendo, por tanto, el drenaje profundo, el escurrimiento, y la evaporación de la superficie del suelo [3]. Pero el sistema por sí solo no basta, es necesario emplear alguna herramienta que permita perfeccionar los tiempos de irrigación para lograr su optimización [4, 5].
En función de dicho objetivo se debe tener una idea clara de las necesidades de los cultivos y se requiere elaborar algún modelo que relacione las principales variables que describen a la planta. Pero obtener el modelo matemático es complejo, demanda de numerosos análisis bajo el criterio de expertos que puedan definir el peso y tipo de la relación entre todos los parámetros, además, el modelo elaborado para un área o cultivo determinada puede no ser aplicable en otros casos que los analizados [5].
En la actualidad, el manejo de grandes cantidades de datos se vuelve una necesidad recurrente, entre otras causas, por el uso reiterado de la inteligencia artificial y su integración con numerosas áreas de la técnica, la investigación y la sociedad. Viendo el caso de la agricultura, resulta evidente como el empleo de dichas herramientas puede traer beneficios no solo al sector sino a la sociedad como un todo, ya que este se ha caracterizado comúnmente por tener un alto nivel de incertidumbre a causa de condiciones climáticas y ambientales y un balance volátil entre oferta y demanda [6, 7].
Resulta evidente entonces como el recopilar datos de variables que rigen los cultivos influiría de forma positiva en su manejo eficiente [8]. Sobre el tema Osinga [7] realiza una revisión sobre la adopción del Big Data en aplicaciones reales, mientras Tantalaki [9] lo hace sobre artículos publicados sobre el tema; ambos llegan a la conclusión de que esta tecnología desempeñará un papel fundamental en el futuro de la agricultura, si bien todavía su uso es discreto en la mayoría de los casos, con poca difusión. Cravero [10] investiga sobre las principales dificultades que enfrenta el Big Data en la agricultura y llega a la conclusión que el aumento exponencial en la cantidad de datos, que provoca que se deban modificar los modelos elaborados, resulta uno de los problemas principales y por lo tanto la dificultad a enfrentar.
Apache Spark es un motor informático rápido y versátil diseñado para el procesamiento de datos a gran escala. Realizando cálculos en memoria con conjuntos de datos distribuidos resilientes, Spark utiliza la memoria principal de manera más eficiente y minimiza las transferencias de datos de disco a disco. Internamente Spark emplea Hadoop, el cual es una infraestructura de sistemas distribuidos ideal para analizar y procesar cantidades masivas de datos. Por dicha razón tanto varios autores emplean la herramienta para el procesamiento de datos derivados de la agricultura [11, 12].
Metodología
Para la elaboración del conjunto de datos procesados es necesario inicialmente establecer un método de recogida y/o obtención de la data referente a las variables agrometeorológicas, posteriormente debe utilizarse alguna herramienta de software capaz de procesar los datos según se determine, así como elaborar gráficas, tablas e información relevante para la toma de decisiones.
Recopilación de datos y procesamiento con apache spark
Como resultado del empleo de una aplicación IoT encargada de la recopilación de datos, se obtuvo un histórico de valores de las variables iluminación, temperatura y humedad ambiental y humedad del suelo. Para esto se montaron tres nodos de recopilación de datos; dos de ellos destinados a medir humedad y temperatura del aire, los cuales se colocaron dos en un mismo cantero, y el nodo restante destinado a medir iluminación fue colocado en medio de la casa de cultivo. Los nodos se comunicaban a través de una red inalámbrica de largo alcance con un nodo enrutador que se encargaba de procesar la comunicación, al que se le enviaban las mediciones cada 15 minutos, y que se conectó a una Raspberry Pi 4 colocada en la sala de control del riego, que se encargaba de almacenar los datos y de comunicarse con el usuario [6].
Spark constituye una herramienta de software lo suficientemente versátil y ligera para ser empleada en la aplicación. Las funciones incluidas dentro del paquete Spark SQL permiten modificar grandes conjuntos de datos con una carga de procesamiento adecuada para el trabajo con sistemas computacionales discretos como el RaspberryPi [13], mientras que con MLlib se accede de manera rápida a algoritmos de reducción de dimensionalidad. Adicionalmente se explotan librerías como matplotlib y pandas con sus paquetes pensados para la elaboración y visualización de gráficos.
Determinación del coeficiente de evapotranspiración
El principal causante de pérdida de la humedad en el suelo lo constituye el agua evaporada desde la superficie libre del suelo y la transpirada por la planta [14]. A la combinación de ambos factores se la conoce como evapotranspiración (ETo) y se define como la cantidad de agua perdida en forma de vapor, desde una superficie cubierta de vegetación. Dicha variable resulta de gran utilidad a la hora de tomar decisiones en la agricultura, principalmente en lo referente al riego, por lo que constituye un buen añadido para la base de datos.
La forma más precisa y usual para estimar la Eto es mediante la ecuación de la FAO-56 Penman-Monteith [15], pero requiere valores de numerosos parámetros ambientales como la pendiente de la curva de la presión de vapor de saturación vs temperatura del aire, el flujo de calor en la superficie del suelo y la presión de vapor de saturación. Como alternativa se emplea la ecuación de Turc [16], la cual requiere una menor cantidad de variables ambientales para determinar el valor de la ETo y cuya expresión matemática es:
Para RH < 50%:
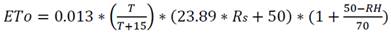 (1)
(1)
Para RH > 50%:
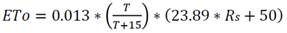 (2)
(2)
Donde Eto es la evapotranspiración de referencia, expresada en mm/día; Rs es la radiación solar incidente sobre la superficie del cultivo, expresada en MJ/m2/día; T es la temperatura del aire, expresada en °C y RH es la humedad relativa, expresada en % [16]. La evapotranspiración real del cultivo se determina multiplicando la evapotranspiración de referencia por el coeficiente de cultivo, un factor adimensional cuyo valor depende del cultivo, de su ciclo relativo, y de su fenología, así como de las condiciones específicas del cultivo en la explotación y de las condiciones climáticas locales. Otros investigadores se han basado en técnicas de Inteligencia Artificial para realizar esta estimación [17, 18, 19].
Preparación de los datos para el modelado
De la base de datos obtenida de los nodos debieron ser filtrados valores de variables propias de la comunicación como manejadores de alarmas, estados del sistema y ajustes de límites, las cuales resultaban innecesarias para el entrenamiento de los modelos. Las variables que se mantuvieron debieron ser indexadas, pues los indicadores asignados automáticamente durante la comunicación y almacenamiento eran poco sugerentes. Para ajustar la base de datos se agruparon los valores medidos con una diferencia de tiempo menor a 15 minutos, por ser el tiempo de muestreo de la red. En caso de los dos nodos que midieron temperatura, humedad y humedad del suelo se determinó emplear el valor promedio de sus mediciones en los instantes donde existía el dato de ambos. En los casos donde uno de los dos fallaba, se utilizaba la información del segundo [6].
La ETo obtenida de la ecuación de Turc constituye un promedio diario, pero el valor de radiación solar que se empleó provino de una medición instantánea. Por tanto, se determinó expresar el cálculo de ETo con una unidad de 0,1 mm3/ha/s. Para el entrenamiento de los modelos se crearon siete conjuntos de variables, los cuales agruparon diferente cantidad y distribución de los puntos de datos para formar series de tiempo, ya que estas constituyen una herramienta clave para modelar fenómenos dependientes del tiempo, así como para detectar patrones estacionales, ciclos y anomalías en los datos [20]. Dichas series contaron como variables de entrada o características los valores de: la hora a la que se planea predecir el valor; la diferencia de tiempo entre la hora a la que se desea predecir y el punto actual de la serie de tiempo; los valores de temperatura, humedad del ambiente y humedad del suelo en el punto de la serie de tiempo. Como variable a predecir o etiqueta de todos los conjuntos de datos se estableció un valor de evapotranspiración.
Resultados y discusión
Los datos obtenidos por la red de sensores IoT corresponden a un período de siembra de pepino ocurrido en las casas de cultivo protegido de la UEB “Valle del Yabú” en el municipio Santa Clara, provincia Villa Clara en Cuba en agosto del año 2022.
Evaluación, ajuste y depuración de los datos para el trabajo
La base de datos original contaba con mediciones de 58 variables, con un tamaño de data de 130446 elementos (Figura 1), de las cuales se mantuvieron la iluminación, la temperatura ambiental, la humedad ambiental y la humedad del suelo, reduciéndose la cantidad de datos a 16264.

Figura 1 Modificaciones y agrupamientos del conjunto de datos recopilados por los sensores (Fuente: elaboración propia).
Los datos fueron agrupados por instante de tiempo convertido a formato de fecha. Se determinó un valor único por variable y se filtraron los datos con valores de luminosidad incorrectos, lo que disminuyó el tamaño de la data a 2182 elementos. Posteriormente, empleando la fórmula de Turc (Ecuaciones 1 y 2), se determinó la evapotranspiración para cada punto de la base de datos (Figura 2). La evapotranspiración promedio determinada entre todos los puntos fue de 7263,03 mm3/ha/s, en el caso de los valores diurnos el promedio fue de 18332,66 mm3/ha/s, el cual representó el valor más cercano a la incidencia diaria, ya que esta se ve afectada en su mayoría por los valores diurnos. Del total, el valor más alto calculado fue de 56312,95 mm3/ha/s y el mínimo 1,24 mm3/ha/s.

Figura 2 Fragmento de los valores de evapotranspiración determinados con la fórmula de Turc (Fuente: elaboración propia).
Se determinó el factor de correlación entre los datos y se observó que las variables con mayor factor de correlación fueron la temperatura, la humedad del suelo y la luminosidad (Figura 3), por lo que se consideró el aplicar una reducción de dimensionalidad que englobara dichas variables.
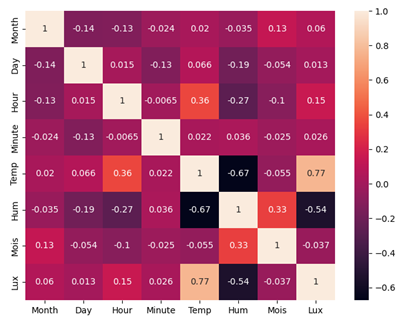
Creación de los conjuntos de datos
Para la creación de las series de tiempo se decidió optar por un máximo de cuatro puntos temporales, con el objetivo de reducir la carga de procesamiento del sistema encargado de modelar el algoritmo inteligente futuro. Se decidió seguir dos desarrollos temporales diferentes, uno basado en mediciones del mismo día de la predicción, separadas por un período de 2 horas, que aportaran datos de la variación de las condiciones climáticas en dicho día; la otra variante consistió en tomar los datos de la misma hora de la medición con diferencias de un día, los que aportan información de como se ha comportado el clima en un período más amplio. Ambos desarrollos fueron combinados dando como resultado los siguientes conjuntos de datos, listos para ser empleados por algún sistema inteligente:
1p_2h: Un punto, de dos horas previas a la predicción.
1p_1d: Un punto, a la misma hora del día anterior a la predicción.
2p_2h: Dos puntos, de dos y cuatro horas previas a la predicción.
2p_1d: Dos puntos, de los dos días anteriores a la predicción.
2p_2h_1d: Dos puntos, uno de dos horas previas y uno del día anterior.
3p_2h_1d: Tres puntos, dos de dos y cuatro horas previas y uno del día anterior.
4p_2h_1d: Cuatro puntos, dos de dos y cuatro horas previas y dos de los dos días anteriores.
Entrenamiento de los modelos
Para cada modelo se realizaron varias pruebas con diferentes parámetros de ajuste, con el objetivo de determinar la configuración que presentó los mejores resultados por cada modelo. Dicha configuración fue empleada en el paso comparativo entre modelos.
Con el modelo de Regresión Lineal (LR), se modificó el valor de las iteraciones máximas, probándose con 100, 10000 y 1000000 en los conjuntos de datos de 1p_2h, 1p_1d y 2p_2h_1d. Se observó que el valor de 10000 tenía mejores resultados para los datos con diferencia de dos horas con respecto al valor de 100, y resultados análogos con el valor de 1000000.
Los parámetros modificados en el caso de los Bosques Aleatorios Regresivos (RRF) fueron numTrees, maxDepth y maxBins, los cuales se variaron entre los valores de diez, 20 y 30 para los dos primeros, y 32, 80 y 120 para los compartimientos máximos. Los resultados de la combinación numTrees=20, maxDepth=20 y maxBins=80 fueron al menos tan buenos como los de las demás, por lo que fue seleccionada para entrenar el modelo. Para el caso de los Bosques Aleatorios de Gradiente Mejorado (GBTR) se inició el ajuste modificando el parámetro maxIter, dándole valores de 20 y 100. Se observó que el valor 20 obtuvo resultados ligeramente mejores que el de 100, por lo que este fue seleccionado.
Se realizó una comparación entre los diferentes algoritmos de ML utilizados, en un primer caso, los grupos de datos originalmente formados. En un segundo caso, se empleó un algoritmo de reducción de dimensionalidad que redujo la cantidad de variables de entrada en los grupos de datos originales y con ellos fueron entrenados los modelos con parámetros idénticos en ambos. Los modelos entrenados con los datos originales y los entrenados con datos de dimensionalidad reducida mostraron valores semejantes en los criterios de error para algoritmos de RRF.
Los mejores resultados en todos los parámetros se obtuvieron en los modelos de RRF, y los peores en los modelos de LR. En los modelos de RRF, el grupo de datos que mostró los mejores resultados fue el 2p_2h. En la figura 4 se muestra la predicción y el valor real para dicho grupo.
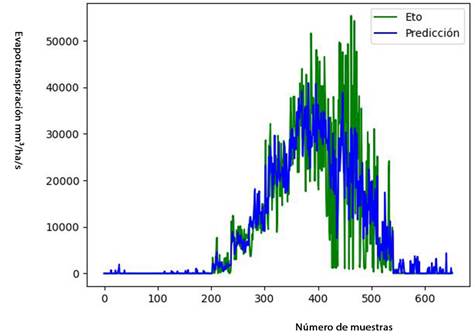
Figura 4 Comparación del valor real y la predicción de evapotranspiración en el grupo de datos 2p_2h (Fuente: elaboración propia).
Determinación del volumen de agua perdida por evapotranspiración
Empleando el modelo de RRF con dimensionalidad reducida que presentó el mejor resultado con el grupo de datos 2p_2h se realizó una predicción del valor de evapotranspiración en cada punto que se encontraba en el período de siete horas entre las ocho de la mañana y las tres de la tarde. Período donde se realizaban los riegos, obteniéndose un valor promedio de 23162,75 mm3/ha/s. Como diferencia de tiempo para la estimación se dividió el período en cinco riegos, determinándose un intervalo entre ellos de 84 minutos.
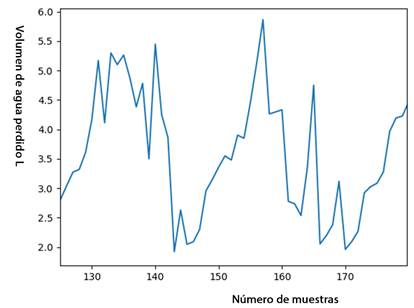
Con los valores de evapotranspiración presente y futura que predijo el modelo, multiplicados por el coeficiente del cultivo el cual fue de 0,75, pues el pepino se encontraba en la etapa final de siembra cuando se realizaron las mediciones. Además, teniendo en cuenta la diferencia de tiempo en segundos entre dos instantes de riego en un cantero de la casa de cultivo, se calculó el volumen de agua por área de cultivo que se pierde (en mm3/ha) como el área debajo de una curva de evapotranspiración en función del tiempo, ya que la evapotranspiración es una medida de velocidad de pérdida de agua. El volumen perdido promedio durante el tiempo analizado fue de 4,37 L, con un valor máximo de 8,67 L y un mínimo de 1,57 L figura 5.
Conclusiones
Como resultado final de esta investigación se obtuvo un sistema de apoyo al riego para condiciones de cultivo protegido basado en ML. La eficacia del modelo quedó demostrada tras un análisis de sus parámetros de ajuste y una comparación con fuentes bibliográficas actualizadas. El sistema obtenido mostró una toma de decisiones óptima en comparación a la planificación existente. En base a estos resultados pueden plantearse las siguientes conclusiones:
Se evidenció cómo a partir de los datos disponibles la función más apropiada para el cálculo de la Eto fue la de Turc, la que arrojó un valor promedio diurno equivalente a 1,5 mm/día.
A partir de la literatura consultada se determinó que las técnicas de ML más apropiadas para el sistema fueron la LR, los RRF y los GBTR. De ellas la que mejor resultados obtuvo fue los RRF, con un coeficiente r2 máximo de 0,79.
A partir de los datos recopilados el sistema fue capaz de proveer las estimaciones de la evapotranspiración y el volumen de agua perdido, los cuales constituyen indicadores del estado del cultivo que favorecen la correcta toma de decisiones de los especialistas.

