










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
En la actualidad, con el desarrollo vertiginoso de las Tecnologías de la Información y Comunicación (TIC), se ha manifestado una tendencia hacia el crecimiento del desarrollo de aplicaciones, que en dependencia del tipo de negocio al que estén asociadas, se inclinan o no al procesamiento de grandes volúmenes de datos. Paralelo al desarrollo y penetración de las TIC crece la necesidad de la seguridad de la información que es generada, almacenada, intercambiada y procesada. Las tendencias mundiales revelan un crecimiento exponencial de acciones malignas encaminadas a poner en riesgo la seguridad de la información. Un ciberataque consiste en cualquier acción tomada para socavar las funciones de una red informática con fines políticos o de seguridad nacional (Salinas Macías, 2015).
El Informe de Amenaza de Seguridad de Internet, emitido por la corporación multinacional estadounidense Symantec (Symantec, 2019), arroja que, en los últimos años, las tácticas más sencillas y los delincuentes informáticos más innovadores consiguieron resultados sin precedentes en el panorama de las amenazas mundiales. Los ataques que se realizan utilizando las técnicas de ingeniería social (Hadnagy, 2011), estimulan un ambiente con cierta manipulación psicológica, con el fin de lograr mediante el engaño a usuarios o empleados, que estos entreguen sus credencias de acceso u otros datos confidenciales. Frecuentemente, se hace uso del correo electrónico u otro medio de comunicación que invoca la urgencia, el miedo o emociones similares en la víctima, lo que lleva a esta a revelar rápidamente información sensible, hacer clic en un enlace malicioso o abrir un archivo malicioso.
Los ataques de phishing son uno de los más comunes entre los de ingeniería social (Sumner and Yuan, 2019). Estos emplean subterfugios técnicos y de ingeniería social para robar los datos de identidad personal y las credenciales de las cuentas financieras de los consumidores (APWG, 2020). Este tipo de ataque suele lanzarse principalmente a través de mensajes de correo electrónico, que parecen ser enviados desde una fuente acreditada, con la intención de persuadir al usuario de que abra un archivo adjunto malicioso o siga una dirección URL fraudulenta. Una variante de phishing dirigido, denominada "spear phishing", se basa en la investigación previa de las víctimas para que la estafa parezca más auténtica (Allodi et al., 2019), lo que la convierte en uno de los tipos de ataque más exitosos contra los usuarios de las redes de datos. Debido a que el factor humano juega un papel determinante, el phishing, en los últimos años, se ha enfocado hacia las redes sociales (Yassein et al., 2019) y también hacia la mensajería de texto o SMS (smishing) (Balim and Gunal, 2019). Otras variantes de este ataque incluyen, el fraude de correo electrónico dirigido a ejecutivos (whaling) (Park and Rayz, 2018), el phishing a través de la redirección de los usuarios a un sitio falso (pharming) (Gajera et al., 2019), el phishing a través del servicio de voz (vishing) (Moul, 2019) y el phishing basado en el Localizador de Recursos Uniforme (URL maliciosas), contenidas en códigos de respuesta rápida o QR (QRishing) (Chorghe and Shekokar, 2016).
Durante el 2020, los Ataques de Comprometimiento de Correo Electrónico Empresarial (BEC), variante de spear phishing, fueron cada vez más costosos para las víctimas en todo el mundo. La solicitud media de transferencia bancaria en los ataques BEC aumentó de 48.000 dólares (USD) en el tercer trimestre a 75.000 dólares en el cuarto (APWG, 2020). El número de ataques de phishing observados por el Grupo de Trabajo Anti-Phishing (APWG) y sus miembros creció hasta 2020, duplicándose en el transcurso del año (APWG, 2020) (ver Figura 1).
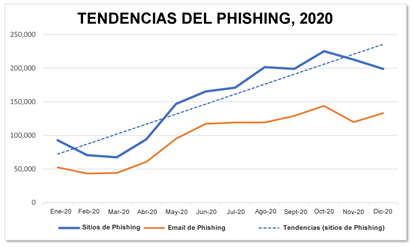
Fuente: APGW (APWG, 2020).
Otro aspecto a destacar es que los ataques de vishing se han detectado principalmente en el sector financiero, así como la suplantación de identidad en las redes sociales, ha aumentado considerablemente desde el 2016, debido a la utilidad que tienen los perfiles de usuario para los phishers (Sfakianakis et al., 2019). Dada la vigencia e impacto de estos ataques, se han realizado numerosas investigaciones sobre los enfoques de detección. Los trabajos de revisión precedentes (Adil et al., 2020; Althobaiti et al., 2019; Chorghe and Shekokar, 2016; Qabajeh et al., 2018; Shaikh et al., 2016; Yassein, Aljawarneh and Wahsheh, 2019; Zuraiq and Alkasassbeh, 2019) se han centrado en el estudio y clasificación de las técnicas de detección más significativas en cada servicio. Sin embargo, esta investigación proporcionará un análisis integral, amplio y actualizado de los métodos y herramientas informáticas existentes que han demostrado ser más efectivos en los últimos años.
Métodos o Metodología Computacional
A nivel internacional se han utilizado diversos métodos para la detección de los ataques de phishing. Según se aprecia en la Figura 2, el estudio de trabajos precedentes permite agrupar estas soluciones en dos grandes grupos: convencionales y automatizados (Hernández Dominguez and Baluja García, 2021).
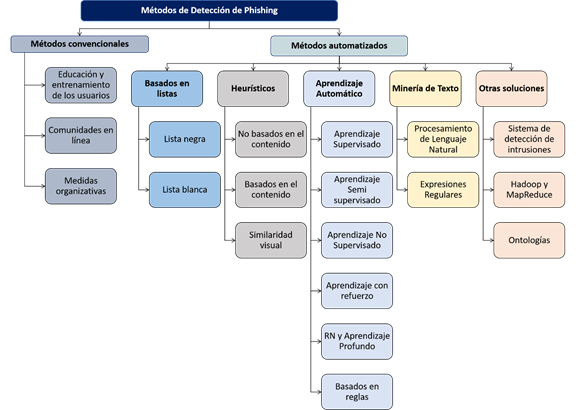
Fuente: (Hernández Dominguez and Baluja García, 2021).
Métodos convencionales
Según la literatura existen soluciones encaminadas a la formación de los usuarios, para detectar este tipo de ataques, utilizando para ello un entorno de entrenamiento integrado (Dixon et al., 2019) con situaciones reales. Otras soluciones son basadas en la experiencia del usuario, lo que ha permitido la creación de comunidades en línea como Anti-Phishing (APWG , PhishTank , Millersmiles , Symantec , entre otros), las cuales tienen como función general monitorizar y denunciar las actividades de phishing recientes a los diferentes grupos de interés (Baadel et al., 2018).
Soluciones para la educación y entrenamiento de los usuarios
A continuación, se describen brevemente las herramientas Anti Phishing (Aassal and Verma, 2019) para la formación de usuarios:
SecurityIQ-PhishSim: Plataforma basada en la web, desarrollada por el Instituto Infosec con el fin de formar en materia de Anti Phishing y concienciar a los usuarios en materia de seguridad. Entre las múltiples funcionalidades se encuentran la creación de correos electrónicos de phishing personalizados o el uso de plantillas ya disponibles, la simulación de ataques, las funciones de seguimiento y la posibilidad de enviar distintos tipos de correos electrónicos a diferentes usuarios como parte de un mismo ataque.
Gophish: Plataforma de código abierto desarrollada por Jordan Wright, en noviembre de 2013. Está diseñada para permitir a los probadores de penetración simular ataques de phishing de forma rápida y eficiente. Ofrece múltiples rasgos, como la importación del formato de correo electrónico y la clonación de sitios web, para utilizarlos como plantillas en una simulación determinada.
Software de phishing LUCY: Herramienta basada en la web que permite concienciar a los empleados sobre el phishing. A través de la plataforma en línea, los usuarios tienen acceso a un panel de control personal donde pueden hacer un seguimiento de todas las simulaciones realizadas, o crear otras nuevas, en vista de utilizarlas para futuros programas de entrenamiento. Además, se pueden configurar listas de destinatarios para utilizarlas en ataques de phishing. LUCY ofrece múltiples plantillas de correo electrónico, cada una de las cuales puede utilizarse en varios idiomas.
KingPhisher: Solución de código abierto desarrollada por SecureStare. King Phisher es una herramienta para probar y promover la sensibilización de los usuarios mediante la simulación de ataques de phishing. Cuenta con una arquitectura sencilla y flexible, que permite un control total sobre los correos electrónicos y el contenido del servidor. King Phisher puede ser utilizada para ejecutar las simulaciones que van desde la formación y concienciación simple hasta los escenarios más complicados en los que se sirven contenidos al usuario para recopilar credenciales.
SpeedPhish Framework: Herramienta en Python desarrollada por Adam Compton. Esta herramienta puede ser utilizada para entrenar a los usuarios acerca de los principales conceptos relacionados con phishing. Esta herramienta sólo está disponible en sistemas Linux. Uno de los rasgos útiles de esta herramienta es la función de reconocimiento que permite buscar en motores de búsqueda objetivos potenciales. También contiene desplegado un servidor web integrado basado en la biblioteca Twisted Python, mediante el cual se ofrecen funciones de clonación de sitios web.
Phishing Frenzy: Aplicación de código abierto para que un probador de penetración simule correos electrónicos de phishing. Desarrollada en 2013 por Brandon McCann, facilita la gestión de ataques de phishing de phishing. Entre sus funcionalidades destacan la disponibilidad de plantillas, la clonación de sitios web, la gestión de credenciales, emisión de estadísticas asociadas a un ataque y la exportación de los resultados en formatos XML o PDF.
Wombat Security - ThreatSim: Plataforma web para desarrollar ataques de phishing integrada con varios módulos de formación, adquirida por la empresa Wombat Security Technologies, hoy día Proofpoint Security Awareness Training, el 14 de octubre de 2015. Es una herramienta totalmente comercial que ofrece más de 130 plantillas actualizadas casi semanalmente, en más de 25 idiomas. Tiene soporte para distintos tipos de ataques de phishing. También ofrece múltiples funciones, incluyendo la clonación de sitios web y la edición de código HTML para el caso de las plantillas de correo electrónico y sitios web.
Métodos automatizados para la detección de phishing
Métodos basados en listas: Una práctica común es la utilización de bases de datos (lista negra y lista blanca), los cuales reflejan una efectividad de detección de ataques de phishing en el intervalo de un 47% a un 83%, como promedio (Dong et al., 2015). Algunos ejemplos son: MXToolBox Blacklist Check (Bikov et al., 2019), Barracuda Blacklist (Chin et al., 2018), Spamhaus Whitelist, las listas negras de PhishTank, Microsoft, Google (Dong, Kapadia, Blythe and Camp, 2015), entre otros. Estas soluciones pueden ser utilizadas en diversos servicios telemáticos.
Métodos heurísticos: Existen varias estrategias heurísticas contra el phishing que han sido debatidas en la literatura. Los enfoques se dividen comúnmente en tres tipos (Silva et al., 2020): el enfoque no basado en contenido (Jayan and Dija, 2015), el enfoque basado en contenido (Nathezhtha et al., 2019) y el enfoque basado en similitud visual (Huang et al., 2019), siendo este último el más utilizado. Para la extracción de los rasgos utilizados durante la clasificación, en el caso de la similitud visual, se utiliza generalmente la técnica de Reconocimiento Óptico de Caracteres (OCR) (Wang and Duncan, 2019).
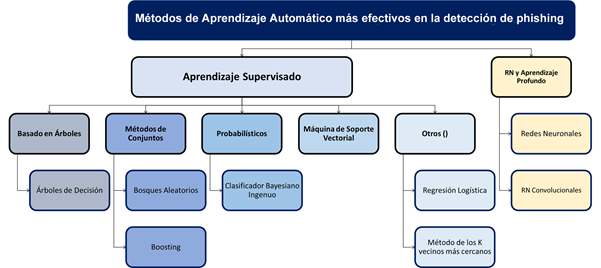
Métodos de Aprendizaje Automático (ML): Teniendo en cuenta que el phishing es un problema típico de clasificación (Qabajeh, Thabtah and Chiclana, 2018), las técnicas de ML y la Minería de Datos (DM) resultan apropiadas para obtener conocimiento. Algunos de los métodos de la Inteligencia Artificial (IA) más referenciados en la literatura (Mishra and Soni, 2019), para la detección de phishing, son: los Árboles de Decisión (DT), los Métodos de Conjunto (Bosques Aleatorios (RF)), los Modelos Probabilísticos (Clasificador Bayesiano Ingenuo (NB) y Redes Bayesianas), la Máquina de Soporte Vectorial (SVM), la Lógica Difusa, las Redes Neuronales (NN) y los algoritmos de Aprendizaje Profundo (DL). De cada uno de los métodos de Aprendizaje Automático se derivan diversos enfoques que son aplicados en los sistemas Anti-Phishing, por lo que uno de los factores analizados siempre es el nivel de efectividad que estos tienen.
Minería de Texto (TM) y Procesamiento del Lenguaje Natural (NLP): Utilizando estos métodos es posible identificar los intentos de phishing, a través del análisis de patrones sospechosos que incluyen, entre otros, el contenido de correos electrónicos, sitios web, URL, mensajes instantáneos, entre otros. Se han aplicado cuatro tipos de técnicas de TM y NLP en la detección de phishing: la Frecuencia de Término - Frecuencia Inversa de Documento (TF-IDF) (Dou et al., 2017), las Expresiones Regulares (RE) (Abahussain and Harrath, 2019), el Modelado de Temas usando Análisis Semántico Latente (LSA) (Jain and Gupta, 2016) y el Modelo de Memoria Distribuida de Vectores de Párrafo (PV-DM) (Douzi et al., 2017).
Otras Soluciones: Se identificaron varias técnicas emergentes contra el phishing, incluidas ontologías (Park and Rayz, 2018) y los Sistemas de Detección de Intrusos (Lam and Kettani, 2019). Además, en la literatura revisada (Vieira et al., 2019) se propone Hadoop y se utilizan las principales ventajas que proporciona la técnica de MapReduce para el procesamiento de los datos y la selección de rasgos que serán utilizados en la detección de phishing.
Rasgos más utilizados en la detección de phishing
A continuación, se resumen los rasgos más utilizados por los métodos automatizados de detección de phishing. En el caso de la web, se extraen mediante el análisis de las imágenes, los textos, y de los enlaces de los textos, de los documentos HTML y CSS del sitio web. Además, en este contexto también se tienen en cuenta los rasgos de JavaScript, los objetos ActiveX y los formularios, de ahí que se puedan agrupar de la siguiente manera:
Rasgos basados en la URL
Léxicos: Las URL presentan numerosos rasgos léxicos que se utilizan en la detección de phishing, que incluyen: dirección IP y número de puerto contenidos en la URL, longitud, cantidad de parámetros, frecuencia de palabras claves, existencia de caracteres especiales ('/', '=', ‘@’, ‘&’ y '_') frecuencia de palabras en la lista negra, relación entre dígitos y caracteres, uso del Protocolo Seguro de Transferencia de Hipertexto (HTTPS), cantidad de puntos (Korkmaz et al., 2020), complejidad de Kolmogorov (Cuzzocrea et al., 2018), Ngrams de caracteres (Vazhayil et al., 2018), entropía de URL (Aung and Yamana, 2019).
servicios de terceros: Rasgos obtenidos a partir de los servicios WHOIS (Fang et al., 2015) y Alexa Rank (Shirazi et al., 2018) (información de registro de nombre de dominio, edad del dominio, información geográfica y la similitud de nombre de dominio en función de la distancia de Levenshtein (Nathezhtha, Sangeetha and Vaidehi, 2019)), rasgos del dominio de nivel superior (TLD) (Tyagi et al., 2018), y el manejador de formularios del servidor (SFH) (Korkmaz, Sahingoz and Diri, 2020).
Rasgos basados en el contenido
HTML: cantidad de etiquetas, atributos de etiqueta HTML, Frecuencia de Término (TF-IDF), cantidad de elementos fuera de lugar, cantidad de elementos pequeños/ocultos, cantidad de elementos sospechosos, cantidad de enlaces internos/externos, enlaces nulos en el sitio y pie de página, existencia de más de una etiqueta de HEAD/BODY, marcos invisibles, cantidad de tipo de archivo específico, cantidad de iframes, árbol del Modelo de Objeto de Documento (DOM) (Sonowal and Kuppusamy, 2016), función ActiveX (Satam et al., 2016), clic derecho deshabilitado, administrador de formularios del servidor, e identidad de formulario de inicio de sesión (Korkmaz, Sahingoz and Diri, 2020).
JavaScript: cantidad de cadenas sospechosas, cantidad de cadenas de caracteres largos (>40, >51), rutinas de decodificación, detección de shellcode (Moustafa et al., 2018), cantidad de cadenas de iframe (Tahir et al., 2016), cantidad de objetos sospechosos, cantidad de scripts y cantidad de funciones (eval, setInterval, OnMouseOver) (Zhu et al., 2018).
Similitud visual del sitio web: Texto, imágenes y similitud general (captura de pantalla), color dominante y su coordenada centroide (Futai et al., 2016), logo (Park et al., 2017) y el ícono de página (favicon) (Hasan et al., 2019).
URL acortadas: Frecuencia de caracteres especiales ('/', '=', ‘@’, ‘&’ y '_'), ofuscación de la dirección IP, codificación de la URL, suplantación de la ruta, no coincidencia en el origen y destino de la URL, dirección IP del nombre de dominio, ofuscación de nombre de dominio, frecuencia de punto de entrada de la URL, cantidad de nombres de dominio y direcciones IP (Patil et al., 2017).
motor de búsqueda: Se obtienen a partir de consultas de las componentes de la URL (URL completa, nombre de dominio, y otros) en los motores de búsqueda. (Althobaiti, Rummani and Vaniea, 2019).
basados en redireccionamiento: cantidad de dominios diferentes, direcciones IP en la cadena de redirecciones, cantidad de redirecciones (Althobaiti, Rummani and Vaniea, 2019).
Rasgos basados en certificados
certificado TLS/SSL (seguridad en la capa de transporte/capa de sockets seguros): nivel de validación, la ubicación del emisor, si es de pago o gratuito, las fechas de inicio y finalización del certificado (Althobaiti, Rummani and Vaniea, 2019).
Por otro lado, los diferentes campos del mensaje del correo electrónico (Lam and Kettani, 2019) son utilizados como rasgos para detectar los ataques de phishing que habitualmente afectan este servicio. Existen variantes que incluyen el análisis de rasgos genéricos obtenidos a partir del encabezado y del propio contenido del mensaje. Resulta muy útil el resumen que se encuentra en (Han and Shen, 2016), en el que se agrupan los rasgos en cuatro categorías: de origen, de texto, de adjunto y de destinatario, pero solo es efectivo para el caso específico de los ataques de spear phishing.
Teniendo en cuenta esta clasificación y las presentadas en la literatura (Iyer et al., 2017) se identificaron los siguientes rasgos:
genéricos: tamaño, identificador del mensaje, fecha de envío del mensaje, cantidad de partes del cuerpo del mensaje (Han and Shen, 2016).
remitente: dominio, dirección IP, Número de Sistema Autónomo (ASN), país, organización (Iyer, Atrey, Varshney and Misra, 2017).
destinatario: dominio y organización (Verma and Aassal, 2017).
contenido
asunto: longitud, cantidad de palabras, cantidad de caracteres, palabras en lista negra (Rathod and Pattewar, 2015).
texto: longitud promedio de las palabras, longitud el texto del mensaje, cantidad de palabras funcionales, expresiones regulares, cantidad de palabras complejas y simples, cantidad de caracteres, métricas de estilo, índices de legibilidad (Egozi and Verma, 2018), análisis de redes semánticas (Bhakta and Harris, 2015), urgencia, recompensa, lenguaje de amenazas en el contenido, saludo, firma, despedida en el mensaje, presencia de "De:" y "Para:" en el contenido del correo electrónico, cantidad de dominios vinculados, palabras del mensaje en la lista negra, cantidad de eventos onClick() en el contenido del correo electrónico (Zhang et al., 2017), Indexación Semántica Latente (Chin, Xiong and Hu, 2018), y las métricas (índice de niebla, índice inverso de niebla, índice SMOG, Índice de Flesch-Kincaid (FKRI)), utilizadas por Han (Han and Shen, 2016).
Rasgos de archivos adjuntos: tamaño, tipo de archivo (Han and Shen, 2016).
En el caso de las redes sociales, según (Yassein, Aljawarneh and Wahsheh, 2019) los principales rasgos utilizados para detectar phishing se obtienen del contenido, la información de la red social y la reputación de los enlaces. Los rasgos identificados para el caso de los ataques basados en URL se pueden aplicar aquí, puesto que un texto compartido por un usuario puede contener direcciones electrónicas, según plantea (Al-Janabi et al., 2017). De igual manera, este autor plantea el uso de los siguientes rasgos específicos del perfil del usuario:
antigüedad de la cuenta
cantidad de seguidores
cantidad de perfiles seguidos
cantidad de elementos favoritos del usuario
imagen predeterminada del perfil
longitud del nombre de usuario
habilitación de la geolocalización de la cuenta
cantidad de contenido compartido.
Según (Amrutkar et al., 2017) los principales rasgos utilizados para detectar este tipo de phishing en la mensajería corta e instantánea son el contenido y la URL que pueda formar parte del contenido del mensaje enviado. En la Figura 3 se muestra un resumen de los principales rasgos según el servicio que se utilizan. Se puede observar como varios rasgos pueden ser utilizados en más de un servicio, lo que pudiera representar un elemento de relevancia a tener en cuenta en el desarrollo de soluciones integradas.
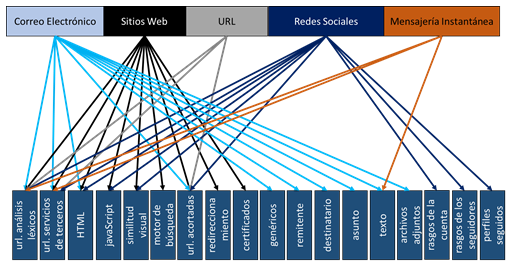
Herramientas que implementan la detección automatizada de phishing
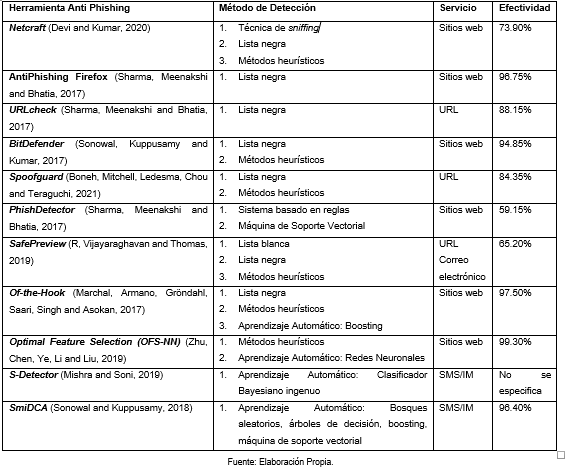
Según la literatura se han encontrado varias herramientas informáticas para la detección de phishing, las mismas se clasifican en: herramientas puras de detección de phishing y aquellas dedicadas a la formación y concienciación de los usuarios. Con respecto al primer caso, en la Tabla 1 se muestra la efectividad de cinco herramientas antivirus que presentan módulos para la detección de phishing.
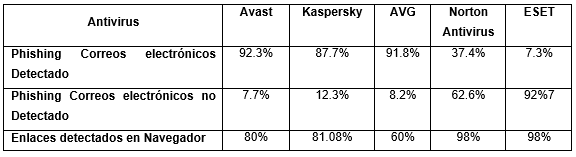
Fuente: (Aassal and Verma, 2019).
Cabe mencionar además las siguientes herramientas que pueden ser utilizadas para este fin:
Netcraft: Constituye una barra de herramientas que utiliza varios métodos para determinar la autenticidad de un sitio web. Detecta, fundamentalmente, los sitios con direcciones URL que contienen caracteres sin significado. Proporciona la ubicación donde se encuentra alojado el sitio web. Además, realiza advertencias emergentes a los usuarios sobre los sitios sospechosos de phishing (Devi and Kumar, 2020).
AntiPhishing: Complemento del navegador Mozilla Firefox cuyo objetivo es proteger a los usuarios inexpertos contra los ataques de phishing basados en sitios web. Esta barra de herramientas registra regularmente la información sensible del usuario y evita que esta información se transmita hacia un sitio web que no se considere "de confianza". Comprueba si el sitio web tiene una conexión segura con certificado SSL o no (Sharma et al., 2017).
Barra de información URLcheck: Esta herramienta comprueba direcciones URL, así como los dominios y las direcciones IP asociadas. Permite generar informes personalizados a partir de las URL que contienen caracteres alfanuméricos o especiales (Sharma, Meenakshi and Bhatia, 2017). La detección se realiza sobre la base de si la URL ya ha sido clasificada en otras plataformas AntiPhishing como PhishTank, APWG, entre otros.
BitDefender: Utiliza la combinación de métodos heurísticos y listas negras. La herramienta presenta tres modos de alerta: verde, rojo y amarillo, con los cuales el usuario puede identificar en tiempo real los intentos de phishing. Esta permite bloquear los sitios web de phishing detectados anteriormente. También detecta si un sitio web tiene rastreadores y su ubicación (Sonowal et al., 2017).
Spoofguard: Solución AntiPhishing desarrollada en la Universidad de Stanford. La barra de herramientas contiene varias reglas para identificar los sitios web de phishing. Inicialmente realiza un chequeo del nombre de dominio. Luego, se inspecciona la URL para detectar los números de puertos que no son estándares. SpoofGuard establece, a través de mecanismos heurísticos, advertencias a los usuarios de que el sitio es un sitio de phishing (Boneh et al., 2021).
PhishDetector: Es una extensión de Google Chrome para detectar sitios bancarios fraudulentos. Es un sistema basado en reglas que analiza el contenido de la página web para identificar los ataques de phishing. La barra de herramientas detecta las estafas bancarias en línea y con un valor bajo de falsos negativos. Para proteger al usuario del acceso a sitios web bancarios fraudulentos es muy recomendable instalar esta extensión en el navegador. Detecta un sitio de phishing en función de la revisión del contenido de la página web (Sharma, Meenakshi and Bhatia, 2017).
SafePreview: Extensión para el navegador Google Chrome que permite la comprobación de seguridad de sitios web, manteniendo el control de los enlaces sospechosos con servicios antivirus como Norton Safe Web, McAfee WOT, entre otros. Permite comprobar directamente un enlace recibido en un correo electrónico. La herramienta ofrece la posibilidad de añadir y eliminar sitios web de confianza para un sistema concreto (R et al., 2019).
Of-the-Hook: Complemento del navegador que permite detectar en tiempo real sitios web de phishing. La implementación se basa únicamente en la información extraída del navegador web, por lo tanto, se preserva la privacidad de los usuarios (Marchal et al., 2017). Mediante la combinación de una lista negra, un método de aprendizaje automático y 210 rasgos, este modelo puede detectar varios ataques de phishing (Zhu et al., 2019).
Optimal Feature Selection (OFS-NN): Modelo eficaz de detección de sitios web de phishing basado en el método de selección óptima de rasgos y en la teoría de las redes neuronales. Mediante los rasgos sensibles seleccionados y un gran número de análisis experimentales, se entrena la estructura óptima de la red neuronal y se construye el clasificador final. Este modelo es capaz de detectar con precisión muchos tipos de ataques de phishing. Gracias a las potentes capacidades de aprendizaje y ajuste de la red neuronal, OFS-NN muestra un mejor rendimiento que muchos sistemas existentes en la detección de sitios web de phishing (Marchal, Armano, Gröndahl, Saari, Singh and Asokan, 2017).
S-Detector: Modelo Anti Phishing que utiliza una combinación de técnicas basadas en el contenido y en la URL para detectar y bloquear los mensajes de smishing. Se divide en cuatro componentes: monitor de SMS, detector de SMS, analizador de SMS y base de datos. El contenido de los SMS se analiza comprobando la presencia de URL y palabras clave de smishing en el mensaje de texto. Las palabras clave de los SMS se analizan y clasifican mediante un clasificador bayesiano ingenuo (Mishra and Soni, 2019).
SmiDCA: Presenta un modelo de detección de smishing que utiliza una combinación de métodos heurísticos, extracción de rasgos basados en el contenido y algoritmos de aprendizaje automático para diferenciar los mensajes de phishing de los legítimos (Sonowal and Kuppusamy, 2018)
RESULTADOS Y DISCUSIÓN
En cuanto a las herramientas utilizadas para el entrenamiento de los usuarios, todas las analizadas tienen documentación disponible y dan al usuario cierta libertad en cuanto a la creación de plantillas para simular ataques de Phishing. PhishSim, por ejemplo, tiene una opción de edición limitada, ya que no es posible eliminar el pie de página del correo electrónico que se genera y que indica, que este forma parte de un entrenamiento y no constituye una amenaza real. Mientras que Gophish da libertad absoluta a la creación de correos electrónicos, pero no ofrece plantillas predeterminadas. Casi todas las herramientas permiten a los usuarios elegir un servidor SMTP específico para retransmitir los correos electrónicos. Esta funcionalidad puede ser peligrosa, ya que les permite a los usuarios elegir cualquier plantilla abierta y crear un mensaje de phishing, que luego puede ser utilizado por los phisher para enviar ataques reales, especialmente si el usuario tiene la mencionada libertad de edición de plantillas.
Métodos automatizados con mayor efectividad en la detección de phishing
La efectividad de estos métodos (algoritmos, modelos, marcos de trabajo, entre otros), se comparó en términos de EXACTITUD de la detección (relación entre las predicciones correctas y las predicciones totales (Tyagi, Shad, Sharma, Gaur and Kaur, 2018)). Tras la revisión de la literatura se ha determinado que los Árboles de Decisión y la Máquina de Soporte Vectorial son los métodos que ofrecen mayor efectividad y que se han utilizados para detectar phishing en todos los servicios analizados. Como se puede apreciar en la Tabla 2 y en la Figura 4, las Redes Neuronales Convolucionales, el Clasificador Bayesiano Ingenuo y los Bosques Aleatorios también destacan por su frecuencia de uso y efectividad.
Tabla 2 Comparación de la efectividad máxima en las propuestas de detección de phishing, según la literatura, por tipo de servicio
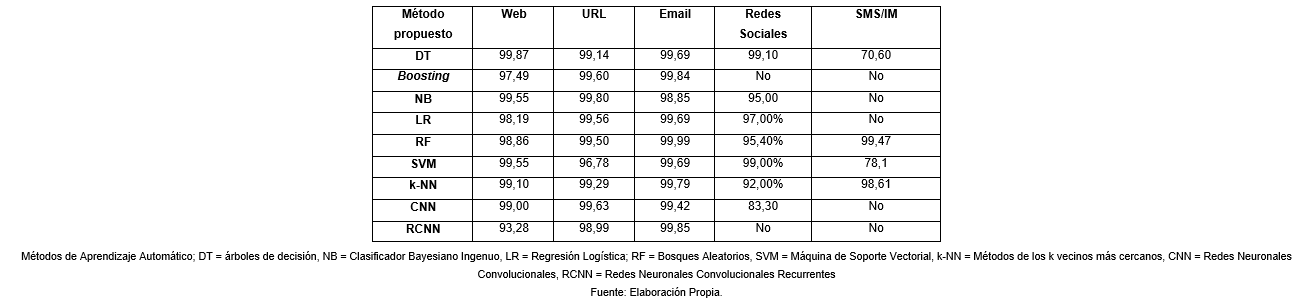
En la literatura se encontraron pocas soluciones integradas las que, como parte de su funcionamiento, permitan detectar Phishing en más de un servicio, con el objetivo de optimizar los niveles de efectividad. Al diseñar soluciones integradas, los métodos de Aprendizaje Automático deben constituir un mecanismo esencial, debido a los niveles de eficacia que se logran cuando se aplican a problemas más específicos. Las redes neuronales artificiales están entre las más precisas. Del mismo modo, cuando se combinan algunos métodos de Aprendizaje Automático, los valores de exactitud se incrementan aún más. Por tanto, como parte del diseño de nuevas propuestas híbridas se deben seleccionar aquellas combinaciones de métodos que ofrezcan mejores resultados. Por otra parte, los rasgos más comunes utilizados para detectar el phishing se basan en el contenido, especialmente en el cuerpo de los mensajes y las URL.
En cuanto a las herramientas para la detección, en la Tabla 3 se muestra una comparación de la efectividad de cada herramienta según la experimentación realizada en la literatura por (Sharma, Meenakshi and Bhatia, 2017), (Mishra and Soni, 2019) y (Vijayalakshmi et al., 2020). Las propuestas de Firefox, BitDefender, así como Of-the-Hook, SmiDCA y Optimal Feature Selection resultan las que más destacan con valores superiores al 90%. Por otra parte, se puede observar, como los métodos heurísticos y los basados en listas negras resultan ser ampliamente utilizados en la actualidad por las herramientas analizadas, aunque estos no sean precisamente los que mayor efectividad ofrezcan. Las siete primeras herramientas presentan un esquema comercial basado en el navegador o plataforma para la cual fueron desarrolladas. En el caso de los sitios web predomina la implementación de herramientas AntiPhishing de tipo complemento o extensión del navegador. Para el caso de la mensajería instantánea a partir del 2017 comienzan a surgir modelos híbridos que a futuro se incluirán en nuevas herramientas informáticas para la detección de phishing.
CONCLUSIONES
En este artículo se presenta una revisión de los principales métodos, modelos y herramientas informáticas para la detección y la educación de los usuarios en cuanto al phishing en redes de datos. Aunque la educación de los usuarios, ya sea utilizando o no herramientas informáticas, puede influir positivamente en los esfuerzos globales para detectar estos ataques, este enfoque exige altos costos. Dado que las técnicas de phishing continúan evolucionando, no todas las organizaciones tienen los recursos necesarios para invertir en este enfoque. Esto hace que los usuarios comunes sean vulnerables, incluso si poseen conocimientos básicos sobre phishing (Qabajeh, Thabtah and Chiclana, 2018). Además, esta solución requiere conocimientos básicos de seguridad informática entre los usuarios formados (Alkhalil et al., 2021).
Los métodos de Aprendizaje Automático (Bosques Aleatorios, Árboles de Decisión y la Máquina de Soporte Vectorial) resaltan por su efectividad y frecuencia de utilización en las propuestas científicas existentes. Las herramientas de detección analizadas utilizan en su mayoría la combinación de varios métodos, entre ellos las listas negras, los métodos heurísticos y en casos limitados las técnicas de aprendizaje automático, de ahí que estas en su mayoría no han implementado aún los métodos más exitosos de la literatura científica.
Las técnicas de Aprendizaje Profundo no se han explotado lo suficiente en las herramientas para la detección de phishing, por lo que constituyen un método novedoso a explorar en investigaciones y desarrollos futuros. Por otra parte, no existen soluciones que permitan detectar el phishing en diversos escenarios/servicios, ni en la literatura ni entre las herramientas, resaltando la necesidad de trabajar en el desarrollo de un método que permita obtener una solución integral para ser utilizada en escenarios con diversos servicios telemáticos, desde un enfoque sistémico y de gestión, que permita mejorar la detección de los ataques de phishing en las redes de datos.

