Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Ante la necesidad del constante perfeccionamiento de los métodos de análisis e interpretación de los resultados de las investigaciones clínicas para identificar factores pronósticos se creó una metodología que permitió el empleo eficiente del análisis estadístico implicativo (ASI) en estas investigaciones.
Este tipo de análisis conocido por la sigla ASI de Analyse Statistique Implicative del idioma francés donde se originó, es una herramienta de la minería de datos basada en las técnicas estadísticas multivariadas, la teoría de la cuasi-implicación, la inteligencia artificial y el álgebra booleana, para modelar la cuasi-implicación entre los sucesos y variables de un conjunto de datos. 1
Su creador, Régis Gras, 2,3,4,5 adoptó distintos enfoques teóricos para modelar la extracción y la representación del conocimiento en forma de reglas y metarreglas de inferencia que apuntan a la significación de un todo y no a la sumatoria de sus partes y su finalidad en principio fue resolver problemas de la didáctica de las matemáticas.
La aplicación empírica del ASI en las investigaciones clínicas de causalidad fue modelando las ideas de estas autoras para crear una metodología definitiva que permitiera la identificación de posibles factores causales en las investigaciones médicas, fue así que se evaluó su efectividad empleando la regresión logística binaria como estándar de oro en varios estudios para identificar factores pronósticos y de riesgo, los cuales constituyeron trabajos de terminación de la especialidad de los bioestadísticos graduados en la Universidad de Ciencias Médicas de Santiago de Cuba. (6,7,8,9,10,11,12
También se realizaron estudios colaterales para apoyar la validez de los resultados encontrados con la aplicación de la metodología propuesta.
El objetivo de este trabajo es exponer los métodos empleados en cada una de las fases de la investigación de obtención de la metodología propuesta desde su concepción hasta la formalización de su empleo por los investigadores, para lo cual se realizó una revisión documental de los métodos de validación apropiados, aprovechando las bases de datos bibliográficas de la Internet, lo cual se confrontó con la experiencia de las autoras para conformar el diseño y validación de la propuesta.
DESARROLLO
La presente investigación se desarrolló en las cinco etapas siguientes:
Fundamentación teórica-práctica de la utilidad del análisis estadístico implicativo en los estudios de causalidad en las ciencias médicas que conllevó al reconocimiento de la necesidad de crear una metodología para su aplicación eficiente.
Elaboración de una propuesta metodológica para la aplicación eficiente del análisis estadístico implicativo en los estudios de causalidad en las ciencias médicas.
Aplicación de la propuesta metodológica. Se presenta como ejemplo de aplicación en el estudio de identificación de factores pronósticos de mortalidad en el cáncer de mama.
Validación de la propuesta mediante tres formas diferentes:
Validación de criterio a través de estudios analíticos de tipo casos y controles clásicos o anidados en una cohorte, en los cuales se realizó la comparación de los resultados obtenidos tras la aplicación, sobre el mismo conjunto de datos, del análisis estadístico implicativo y la regresión logística binaria, seleccionada esta última, como estándar de oro, por ser la técnica habitualmente empleada en la identificación de factores pronósticos y de riesgo. Esta validación concluye con la evaluación del desempeño del análisis estadístico implicativo a través del cálculo de indicadores tales como: sensibilidad, especificidad, valores predictivos, cocientes de probabilidad, odds ratio diagnóstico, entre otros, con sus correspondientes intervalos del 95% de confianza.
Validación de contenido por tres vías:
Validez de apariencia, a través de la opinión de usuarios potenciales.
Validez racional, basada en la correspondencia de lo expresado en la literatura con lo encontrado tras la aplicación del análisis estadístico implicativo y verificado por una investigación documental.
Juicio de expertos para evaluar la calidad de las reglas derivadas del análisis estadístico implicativo.
Validación basada en la evidencia proporcionada por los 13 estudios realizados, en los cuales se ha empleado el análisis estadístico implicativo, según la metodología propuesta y se han comparado sus resultados con los de la regresión logística, según se describió en la primera opción de validación, a través de un metaanálisis.
Diseño definitivo de la metodología.
A continuación, se detalla cada una de estas etapas.
Primera etapa: Fundamentación
En esta etapa se realizó una investigación documental con una exhaustiva revisión bibliográfica, donde se aplicaron los métodos teóricos de la investigación para comprender los fundamentos que sustentan los procedimientos de cada una de las etapas de la metodología propuesta y elaborar las recomendaciones para su empleo adecuado. A partir de esta revisión se elaboró un amplio marco teórico donde se abordó el estado del arte de las técnicas estadísticas para el estudio de la causalidad como objeto de estudio. En el mismo, partiendo de un análisis histórico lógico, se enunciaron cinco etapas en la evolución histórica de estas técnicas, se sistematizaron las técnicas para el estudio de las relaciones bivariadas y multivariadas, los métodos gráficos para la exploración, el análisis y la presentación de las relaciones multicausales, así como las técnicas que aseguran la validez de estas investigaciones, incluyendo el diseño y control de sesgos.
Luego se evidenciaron los hechos que hacen posible el empleo del análisis estadístico implicativo en la identificación de factores pronósticos y de riesgo, se realizó una comparativa entre esta técnica y la regresión logística binaria, como la mejor propuesta para dicha identificación, en la cual se tuvieron en cuenta 14 aspectos de orden teóricos y prácticos. (13,14
También se revisaron las investigaciones de causalidad realizadas en las ciencias médicas en las cuales se empleó el análisis estadístico implicativo, lo que permitió determinar las regularidades y contradicciones que pautaron el diseño de la metodología y los cambios paulatinos en el análisis e interpretación de los resultados.
Segunda etapa: Elaboración
Basado en los resultados de la etapa anterior, se contextualizó el modo de analizar los datos, y se adaptó la interpretación de los resultados de este análisis, identificando las primeras seis etapas de la metodología, según su finalidad, algunas de ellas con subetapas, y dentro de cada etapa o subetapa, los procedimientos a desarrollar para lograr el objetivo. El diseño de la metodología estuvo condicionado por el reconocimiento de las principales adecuaciones del análisis estadístico implicativo para ser empleado en las investigaciones médicas de causalidad que, según las autoras de esta investigación, pueden dividirse en dos vertientes fundamentales:
Adecuaciones en el análisis de los datos, entre las que se destacan: la duplicación de la variable dependiente, que tradicionalmente es única con dos categorías y la obtención de dos grafos implicativos en modo cono, uno para las relaciones causales de los factores que influyeron en el desenlace peor, tomando como cono la variable dependiente de peor desenlace, y otro para los que influyeron en el mejor desenlace, tomado como cono la variable que representa el mejor desenlace. 15
Adecuaciones en la interpretación de los resultados, entre las que se destacan: la identificación de los posibles factores causales (a partir del modo cono del grafo implicativo), la identificación de posibles variables confusoras (mediante la presencia de dos nodos adyacentes unidos por un enlace bidireccional en el grafo implicativo, un cambio significativo (superior al 10 %) en la intensidad implicativa en el análisis al incluir o no la supuesta variable confusora y la obtención de reglas absurdas (sin sentido desde el punto de vista médico) en el árbol cohesitivo) y la creación de categorías que permiten clasificar los factores identificados en cuatro tipos de causas: cuasi-componentes, cuasi-suficiente, cuasi-necesaria y cuasi-equivalente (cuasi-suficiente y cuasi-necesaria a la vez).
Tercera etapa: Aplicación
Se escogió como ejemplo para la aplicación un estudio de casos y controles para identificar factores pronósticos, cuyo diseño se presenta a continuación.
1. Diseño y contexto del estudio
Se realizó un estudio observacional analítico prospectivo de tipo casos y controles anidado en una cohorte para la aplicación eficiente del análisis estadístico implicativo en la identificación de los factores pronósticos de mortalidad por una entidad en un territorio y momento determinados.
La entidad seleccionada fue el cáncer de mama, dada su elevada incidencia, prevalencia y letalidad en el mundo, el país y la provincia donde se realiza el estudio. Para verificar que este era un problema de salud y tener una primera aproximación que permitiera pasar a un estudio analítico se realizaron estudios descriptivos, de tendencia, supervivencia, estimación de los años de vida potencialmente perdidos, entre otros, los cuales constituyeron tesis de la especialidad de Bioestadística y otros publicados, como el de Rodríguez y colaboradores. (16
El periodo de reclutamiento se extendió de junio de 2014 a abril de 2019. Este periodo se estimó en base a la ocurrencia habitual de fallecidas a causa de esta entidad para garantizar un tamaño de muestra acorde con los requerimientos de la regresión logística que se empleó luego.
2. Universo y muestra
El universo de estudio quedó conformado por todas las mujeres mayores de 18 años de edad con el diagnóstico clínico e histológico de cáncer de mama, procedentes de la provincia de Santiago de Cuba, que fueron atendidas en el Hospital Oncológico “Conrado Benítez”, en el periodo antes mencionado, constituyendo los casos todas las fallecidas durante el periodo de estudio y los controles una muestra de las vivas en igual momento.
3. Elección de casos y controles
Al estar los casos y controles anidados en una cohorte cada caso fue seleccionándose a medida que ocurría un fallecimiento (caso incidente) y para aumentar la comparabilidad entre los grupos se escogió un control por cada caso, en el mismo momento, empleando un muestreo simple aleatorio a partir del listado de historias clínicas de pacientes con fecha de diagnóstico de no más o menos un mes de diferencia con respecto al caso actual, dada la existencia de este registro en el Departamento de Registros Médicos del hospital, lo cual facilitó la localización de las historias seleccionadas. Los controles que fallecieron en el periodo de estudio convirtiéndose en casos fueron sustituidos por otro control.
4. Criterios de exclusión
Se admitieron como criterios de exclusión el ser paciente fallecida por causa ajena a la enfermedad en estudio o paciente con enfermedad concomitante como Diabetes Mellitus, que pudiera interferir en la validez de los resultados del estudio.
5. Tamaño de muestra
Se tomó un control por cada caso para una razón 1:1, por lo que se empleó la fórmula de tamaño muestral para casos y controles balanceados, (17 cuyos parámetros se estimaron a partir de los resultados de dos estudios pilotos realizados; 8,12)
donde:
Para conformar el tamaño de muestra de este estudio se consideraron como eventos de interés las covariables significativamente asociadas con la variable dependiente, identificadas como factores pronósticos en los dos estudios pilotos. Se aplicó la fórmula anterior para cada una de dichas covariables y se tomó, a partir de los resultados obtenidos, el máximo valor de las
También se tuvo en cuenta que el número de casos excediera en 10 el número de variables a incluir en el modelo de regresión para evitar pérdida de precisión en la estimación de los coeficientes de regresión siguiendo el criterio de Freeman, citado en Sagaró y Zamora, 14) como el más apropiado. Teniendo en cuenta estos elementos se obtuvo que la muestra estuviera constituida por 140 casos y 140 controles.
6. Operacionalización de las variables
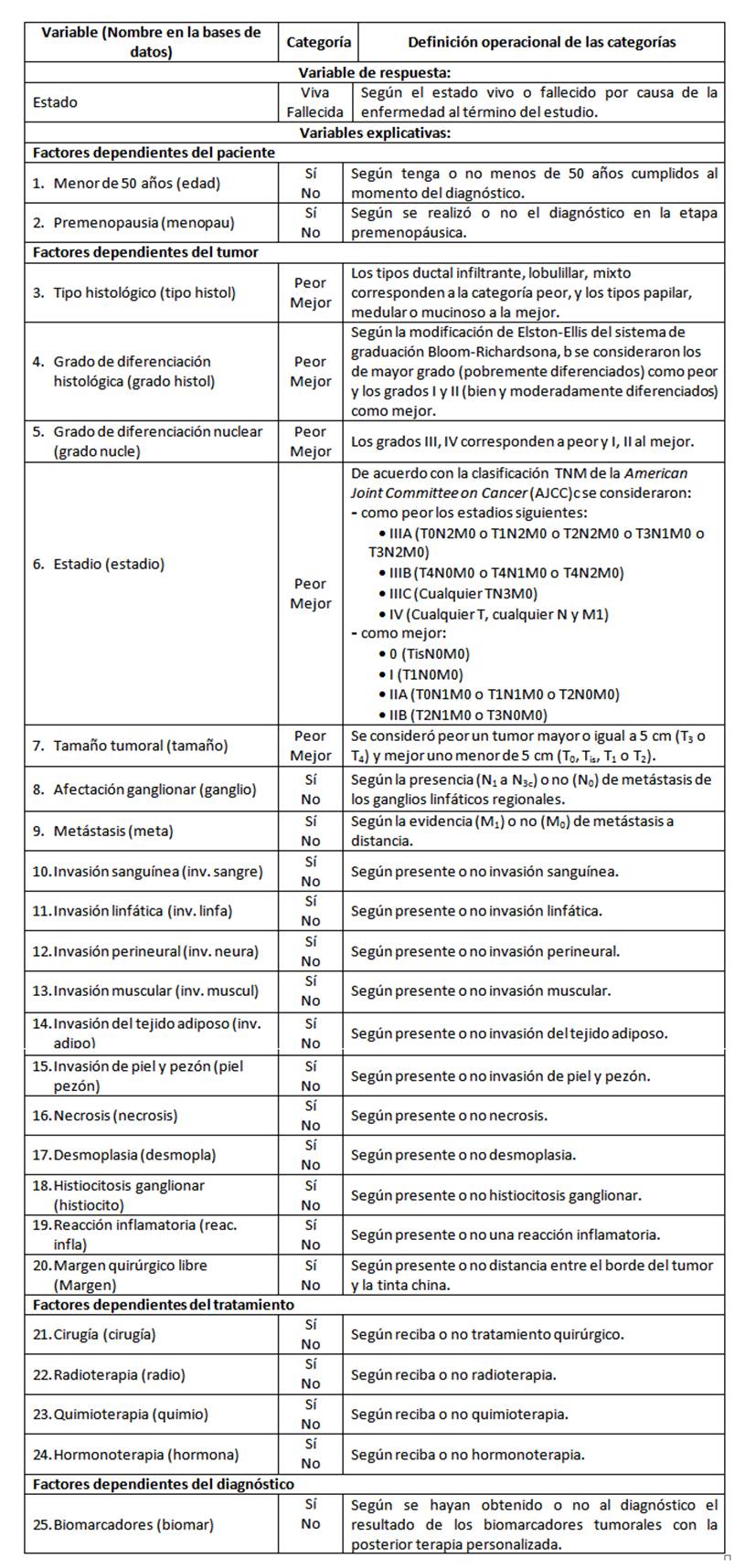
La selección de variables se realizó a partir de la revisión de la literatura, consulta a expertos y resultados de los dos estudios pilotos, (8,12 empleando 25 covariables, relacionadas con la paciente, el tumor, el tratamiento y el diagnóstico, cuya operacionalización y codificación en la base de datos se muestra en el Anexo 1.
7. Recolección de la información
Se realizó una extensa búsqueda bibliográfica en las bases de datos biomédicas alojadas en Internet para determinar el estado actual del problema en estudio. Para conocer los datos estadísticos de morbilidad y mortalidad se consultaron los anuarios estadísticos de salud de la Dirección Provincial de Estadística y de la Dirección Nacional de Registros Médicos y Estadísticas de Salud del Ministerio de Salud Pública.
La recolección del dato primario se realizó mediante la revisión de las historias clínicas de los casos y los controles que integraron la muestra del estudio, los informes de anatomía patológica y otros documentos con información de las variables en estudio. Para este fin, se confeccionó un formulario que recoge la información necesaria. (Anexo 2).
8. Procesamiento de la información
Se aplicó el análisis estadístico implicativo según lo previsto en las seis etapas propuestas: análisis exploratorio, transformación de los datos duplicando la variable dependiente, análisis principal con variable dependiente como principal y suplementaria, presentación de los resultados, interpretación y análisis a posteriori.
9. Síntesis y redacción
Para comunicar los resultados del estudio y conformar el artículo científico con los resultados de esta etapa se empleó la guía STROBE (STrengthening the Reporting of Observational studies in Epidemiology), que establece las directrices de comunicación para estudios observacionales. 18
Cuarta Etapa: Validación
La validación se realizó mediante tres estudios, considerando en cada uno de ellos una forma diferente de validación: validación de criterio, validación de contenido y metaanálisis.
Primer estudio: Validación de criterio
Para analizar las potencialidades de la técnica como un instrumento o medio para identificar posibles causas se decidió comparar la misma con un criterio externo. En este caso se consideró como la técnica estándar más empleada para estos fines según la literatura la regresión logística binaria; por lo que se aplicaron ambas técnicas al mismo conjunto de datos y se compararon sus resultados. La aplicación del análisis estadístico implicativo se realizó siguiendo las seis etapas antes mencionadas y la aplicación de la regresión logística se detalla a continuación.
1. Aplicación de la regresión logística
Para la aplicación de la regresión logística binaria se verificó el cumplimiento de los supuestos de la prueba, eliminando del modelo las variables correlacionadas biológica o estadísticamente y las consideradas intervinientes.
El diagnóstico de la multicolinealidad se realizó a través del factor de inflación de la varianza, creando nuevas combinaciones siempre que fue posible u omitiendo la variable menos importante según la literatura y los expertos. Se comprobó el ajuste del modelo por la prueba de Hosmer y Lemeshow. Se empleó el método por pasos hacia adelante Wald ya que fue el que mostró un mejor ajuste de los datos al modelo.
Como criterios para el método por pasos se tomó una probabilidad de entrada de 0.05 y una de eliminación de 0.10; con un punto de corte de 0.5 y un máximo de 20 iteraciones. Se incluyó la constante en el modelo. Se interpretó la significación de los factores a través de la prueba de Wald y del intervalo de confianza de las razones de ventajas representadas por las exponenciales de los coeficientes de regresión (Exp [βi], donde βi es el coeficiente asociado a la covariable i-ésima) con un 95 % de confianza.
2. Comparación del análisis estadístico implicativo con la regresión logística
Dada la respuesta dicotómica de estos procedimientos (identifica o no identifica) se construyó una tabla de contingencia de “2x2”, en la cual se consideraron como individuos u objetos de estudio a las covariables empleadas en el mismo y como resultado la identificación de la variable como factor causal o no según ambas técnicas. Se calcularon los indicadores de eficacia de una prueba diagnóstica para el análisis estadístico implicativo como la sensibilidad, la especificidad, los valores predictivos positivo y negativo y las razones de verosimilitud positiva y negativa, los índices de Youden, de Validez y de Kappa y el odds ratio de diagnóstico, así como sus intervalos de confianza del 95 %, según la expresión de Wilson. (19,20 El índice de Youden se estimó según su forma clásica definida en 1950 y según la versión de Chen de 2015. (21
Para el cálculo de los intervalos de confianza se programó una función en lenguaje R, teniendo en cuenta que se trabajó con un tamaño de muestra pequeño, representado por una cantidad de variables inferior a 30, y que los programas disponibles emplean fórmulas para su cálculo con aproximación a la distribución normal, no aplicable para muestras pequeñas.
Segundo estudio: Validación de contenido
Esta validación se realizó por tres vías. Para evaluar si la técnica está a tono con los requerimientos actuales de la investigación se empleó la validez de apariencia y para evaluar si los resultados obtenidos de su aplicación, específicamente las reglas, reflejan verazmente lo que ocurre en la práctica médica se empleó la validez racional y el juicio de expertos.
Validez de apariencia
Esta vía se fue a través de la opinión de los usuarios potenciales de la metodología propuesta acerca de las características que justifican el empleo de la misma en las investigaciones médicas de causalidad. La misma se llevó a cabo en cuatro fases: preparatoria, de consulta, de análisis y conclusiva, las cuales se exponen a continuación.
1. Preparatoria: se definieron los objetivos y diseño de a investigación, se seleccionaron los usuarios potenciales, se creó el instrumento a aplicar y se definió cómo aplicarlo.
Diseño de la investigación
Se realizó un estudio observacional con la aplicación de técnicas cualitativas de tipo criterio de expertos, funcionando como expertos los usuarios potenciales
Universo de estudio y muestra
El universo estuvo constituido por los profesionales de la Bioestadística y la Informática de la provincia de Santiago de Cuba con cinco años y más de experiencia. Luego de la localización y confección del listado de posibles usuarios que actuaran como expertos se realizó un proceso de selección a través de la clasificación por aspectos con su puntuación correspondiente, quedando seleccionados los 30 profesionales de mayor puntuación entre los clasificados como muy competentes y con disposición a cooperar en la investigación.
Procedimiento para la selección de los usuarios
Al tratarse de usuarios que iban a funcionar como expertos, para su selección, se realizó una clasificación de los mismos (biograma sintético) en base a los siguientes aspectos:
Especialidad: Bioestadística (10 puntos) e Informática (2 puntos)
Años de experiencia: de 5 a 10 - (5 puntos), de 11 a 20 - (10 puntos) y más de 20 - (20 puntos)
Dedicado al análisis estadístico de datos: Sí (10 puntos) o No (2 puntos)
Solo se seleccionaron aquellos que sumaron 25 puntos o más, para un total de 16 usuarios. Los aspectos para la clasificación y puntuación a otorgar se decidieron sobre la base de la experiencia de las autoras.
Características del instrumento
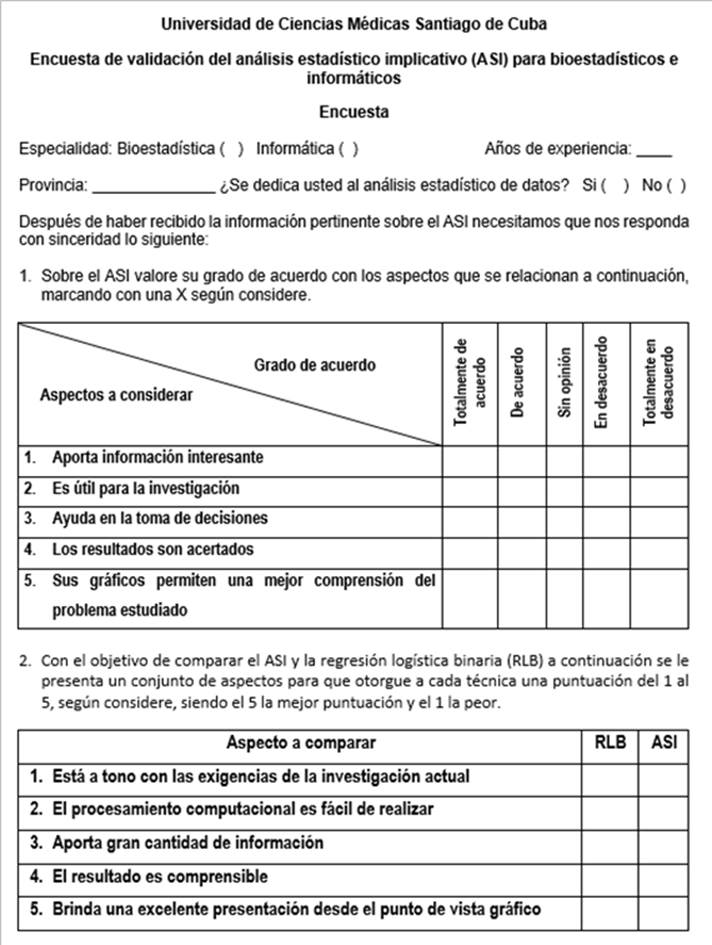
El instrumento a aplicar (Anexo 3) constó de dos preguntas, la primera sobre su grado de acuerdo con las consideraciones que se exponen acerca del análisis estadístico implicativo sobre si: aporta información interesante, es útil para la investigación, ayuda en la toma de decisiones, sus resultados son acertados y sus gráficos permiten una mejor comprensión del problema estudiado. Estas afirmaciones fueron presentadas a través de una escala Likert de 5 puntos de acuerdo desde el acuerdo total al desacuerdo total, pidiéndoles que marcaran con una “X” la más conveniente.
En la segunda pregunta, con el objetivo de comparar el análisis estadístico implicativo y la regresión logística binaria, se les presentó un conjunto de aspectos y se le pidió que otorgaran una puntuación del 1 al 5 referente a cada técnica en todos los aspectos, siendo el 5 la mejor puntuación. Los aspectos considerados para cada técnica fueron si: está más tono con las exigencias de la investigación actual, el procesamiento computacional es fácil de realizar, aporta gran cantidad de información, el resultado es comprensible, brinda una excelente presentación desde el punto de vista gráfico.
2. De consulta: en la cual se realizó un taller con la participación de los usuarios potenciales de la metodología seleccionados en la etapa previa que permitió obtener la información requerida.
Para la obtención de la información se desarrolló el taller antes mencionado, en el cual se explicó a los usuarios las características de la investigación y lo relacionado con el análisis estadístico implicativo, su aplicación en las ciencias médicas y otros aspectos necesarias para poder responder a las preguntas del instrumento. Al final se entregó el instrumento donde estos profesionales emitieron su juicio.
3. De análisis: en la cual se procesaron las respuestas al instrumento y se resumieron e interpretaron los resultados obtenidos.
La primera pregunta se procesó a través del cálculo del índice de validez de contenido V, coeficiente propuesto por Aiken (22) entre 1980 y 1985, cuya fórmula es:
donde:
V: valor del coeficiente V de Aiken
n: número de jueces
k: es el rango de los valores posibles de la escala Likert utilizada
A partir de estos intervalos se consideró un coeficiente estadísticamente significativo, en dependencia del estándar empleado, cuando el límite inferior estuvo por encima de 0.50 (Cicchetti) o de 0.70. (Charter).
Para la segunda pregunta se emplearon dos métodos considerados por las autoras, llamados A, basado en el promedio y B, basado en el coeficiente de concordancia de Kendall, los cuales se exponen a continuación.
Método A: se consideró como medida de resumen el promedio del puntaje dado en cada aspecto para cada técnica, con vistas a clasificar el aspecto a comparar, considerándolo excelente en caso de un promedio por encima de 4.5; bueno uno de 4.0 a 4.5; regular de 3.0 a 3.9 y malo, un puntaje promedio inferior a 3.0. Para identificar si existieron diferencias significativas entre ambas técnicas se empleó la prueba de rangos con signos de Wilcoxon con una significación del 5 %
Se obtuvo además la estimación por intervalos de confianza del 95 % de las puntuaciones por aspectos a comparar en ambas técnicas, la cual se presentó en gráfico de barras de error apiladas.
Método B: Teniendo en cuenta que el análisis estadístico implicativo debe ser tan eficiente como la regresión logística se buscó el grado de acuerdo entre las opiniones de los usuarios sobre ambas técnicas para lo cual se empleó el coeficiente de concordancia de Kendall (W) al tratarse de datos ordinales probando la hipótesis de que hay concordancia significativa entre los rangos o calificaciones otorgadas por los usuarios que actúan como jueces. La interpretación del coeficiente también permitió conocer la fuerza de la concordancia. (23
4. Conclusiva: se elaboró el informe ilustrado con tablas y gráficos.
Validez racional
Con el objetivo de verificar la correspondencia de lo expresado en la literatura con los resultados derivados de la aplicación del análisis estadístico implicativo se realizó una investigación documental, en la cual se desarrollaron las etapas propias de este tipo de investigación:
Diseño o plan de la investigación: en esta etapa se elaboró un plan con todos los procedimientos a ejecutar. Primeramente, se acopiaron todas las reglas obtenidas a partir de los 3 estudios desarrollados sobre factores pronósticos en cáncer de mama, se revisaron sus interpretaciones según el enfoque del supuesto factor causal al desenlace y viceversa y se seleccionaron 23 reglas a criterio de las autoras, teniendo en cuenta la no duplicidad y la variabilidad en los contenidos de las mismas. Algunas de las reglas escogidas verifican la misma relación, pero fueron interpretadas de manera diferente con el objetivo de determinar cuál de las formas de interpretación es mejor entendida.
Búsqueda de información documental: se realizó una amplia revisión bibliográfica aprovechando las bases de datos biomédicas alojadas en internet, con el empleo de los términos factores pronósticos y cáncer de mama en la estrategia de búsqueda en los idiomas español, inglés, francés y portugués.
Registro de información mediante técnica de fichero: se elaboraron 23 fichas resumen donde se plasmó todo lo encontrado referente a las variables que se relacionan en cada regla.
Correspondencia total: cuando la literatura plantea que la regla siempre se verifica en la práctica médica.
Correspondencia posible: cuando la regla puede verificarse o no en la práctica médica, pero nunca resulta absurda.
No correspondencia: cuando la regla nunca se verifica en la práctica médica porque es absurda.
Análisis de la información: se aplicaron métodos teóricos para analizar los artículos encontrados sobre el tema e identificar congruencias e incongruencias con las reglas analizadas y se redactó una síntesis con los aspectos referentes con cada una de estas reglas que permitió el debate en torno a los resultados encontrados con la aplicación del análisis estadístico implicativo.
Elaboración del informe final: se elaboró informe donde se presentaron los resultados mediante tablas y diagramas de barras simples y la discusión en relación con la veracidad de cada una de las reglas.
Presentación de resultados: se publicó un artículo científico y se elaboró un trabajo de tesis.
Juicio de expertos
Esta vía, al igual que la anterior, tuvo por objetivo evaluar la calidad de las reglas derivadas de la aplicación del análisis estadístico implicativo, para lo cual se emplearon las 23 reglas antes seleccionadas.
Diseño de la investigación
Se realizó un estudio observacional con la aplicación de técnicas cualitativas de tipo criterio de expertos, siguiendo las cuatro fases empleadas para determinar la validez de apariencia antes presentadas.
Universo de estudio y muestra
El universo de estudio estuvo constituido por un grupo de expertos integrado por profesionales a cargo de la atención del cáncer de mama en la provincia de Santiago de Cuba con 5 años y más de experiencia y que reunieran los requisitos de un buen experto como creatividad, colectivismo y espíritu crítico.
La muestra quedó integrada por los 33 expertos de mayor puntuación entre los clasificados como muy competentes y con disposición a cooperar en la investigación, según un proceso de selección.
Procedimiento para la selección de los expertos
La selección se llevó a cabo luego de la localización y confección del listado de posibles expertos y obtención del consentimiento para su participación. Fueron considerados diferentes aspectos a los que se les otorgó determinada puntuación, en base a criterios de la autora. No se empleó la autovaloración para calcular el coeficiente de competencia experta en base a los coeficientes de conocimiento y argumentación porque en la experiencia de las autoras el método provoca un aumento en la tasa de abandono de los expertos en la fase posterior de la investigación.
Para la clasificación de los expertos en la atención a pacientes con cáncer de mama se tuvo cuenta los siguientes aspectos con su puntuación:
Los años de experiencia como especialista de cualquier nivel:
El nivel de especialización:
Especialista básico: especialista de primer o segundo grado en Medicina General Integral (MGI), Medicina Interna o Ginecobstetricia. (2 puntos)
Especialista oncólogo: especialista de primer o segundo grado en Oncología. (5 puntos)
Superespecialista: especialista de primer o segundo grado en Oncología, Medicina Interna o Ginecobstetricia que está dedicado a la investigación y atención directa de pacientes con cáncer de mama por años y por lo cual son reconocidos entre sus colegas y pacientes. (10 puntos)
Se consideraron competentes para participar en el estudio solo aquellos expertos los que totalizaron 10 o más puntos. Esta indagación se hizo previa a la aplicación del instrumento y se corroboró por la respuesta del propio experto a los datos generales que pide el instrumento.
Obtención de la información
La obtención de la información se realizó de manera individual, se explicó a cada experto las características de la investigación y de la técnica evaluada para aplicar luego una encuesta con dos preguntas, donde los expertos emitieron su juicio. (Anexo 4).
Con la primera pregunta se evaluó la validez del grafo implicativo en modo cono para identificar posibles factores causales, en este caso en particular, factores pronósticos de mortalidad en cáncer de mama. En esta pregunta se le presentaron dos opciones, los factores encontrados por la regresión logística binaria y los encontrados por el análisis estadístico implicativo, respectivamente, a seleccionar la que consideraran más apropiada. A los expertos no se les dio a conocer que técnica fue la que aportó los resultados a seleccionar. Los factores presentados se tomaron del estudio de Pardo, 12 donde hubo mayores diferencias entre los hallazgos de cada técnica, que en el presente trabajo.
Con la segunda pregunta se evaluó la validez de las reglas que se forman con la aplicación del análisis estadístico implicativo. En ella se les presentó, mediante una escala Likert de cinco puntos u opciones de respuesta, las 23 reglas antes seleccionadas y se les pidió que consideraran con qué frecuencia se cumplen las mismas en la práctica médica. Los cinco puntos de la escala fueron: se cumple siempre, se cumple frecuentemente, se cumple pocas veces, casi nunca se cumple, nunca se cumple.
Procesamiento de los datos
En la primera pregunta se emplearon el número y el porcentaje para totalizar cuantas respuestas fueron a favor de los resultados del análisis estadístico implicativo y cuantas a favor de los resultados de la regresión logística binaria. Para decidir si hubo diferencias significativas en la selección de una u otra opción se aplicó la prueba de diferencia de proporciones con un nivel de significación del 5 %.
La segunda pregunta se procesó por el método Delphi. A partir de las respuestas de los expertos se conformó la tabla de frecuencias absolutas para las categorías de la escala asumida, para cada una de las reglas; se determinaron las frecuencias relativas y relativas acumuladas, y se buscó la imagen de las frecuencias relativas acumuladas a través de la inversa de la función de distribución normal, para lo cual se tuvo en cuenta que eran más de 30 expertos. (24
Se calcularon los promedios por filas (P), el promedio general (N) y la diferencia entre estos (N-P). Luego se establecieron los puntos de corte que se obtienen al dividir la suma de los valores correspondientes a cada columna entre el número de reglas en este caso (promedio relativo).
Por último, se determinó la categoría o el grado de adecuación de cada regla con la opinión de los expertos consultados, que se asignó según los siguientes valores:
Los valores de N-P menores o iguales que el valor del primer punto de corte quedaron clasificados como: “Se cumple siempre”.
Los valores mayores que el valor del primer punto de corte y menores o iguales que el segundo se clasificaron como: “Se cumple frecuentemente”.
Siguiendo este procedimiento para los restantes puntos de cortes se estableció entre los puntos de corte 2 y 3 como: “Se cumple a veces”.
Entre los puntos de corte 3 y 4 como: “Casi nunca se cumple”.
Los valores mayores que el punto de corte 4 quedaron como: “Nunca se cumple”
Una vez concluidas la validación racional y el juicio de experto se efectuó una triangulación metodológica al comparar ambos resultados buscando la posible concordancia entre la literatura y los expertos (dos métodos diferentes para evaluar la veracidad de las reglas obtenidas) para lo cual se estableció una correspondencia entre las categorías establecidas en ambos métodos formando las tres nuevas categorías siguientes:
I: si pertenece a la categoría “correspondencia total” de la validez racional o a las categorías “se cumple siempre” y “se cumple frecuentemente” del juicio de expertos.
II: si pertenece a la categoría “correspondencia posible” de la validez racional o a las categorías “se cumple a veces” y “casi nunca se cumple” del juicio de expertos.
si pertenece a “no correspondencia” de la validez racional o a “nunca se cumple” del juicio de expertos.
Se emplearon como medidas de resumen el número y el porcentaje de reglas en cada categoría y como medida del acuerdo el índice de Kappa ponderado y la prueba de 5 % de significación de la concordancia.
Esta triangulación permitió encontrar contradicciones literatura-experto que facilitaron la identificación de problemas en la redacción de las reglas, los cuales fueron reparados, pasando a la próxima ronda del criterio de expertos, en la cual se les presentó el resultado de la ronda anterior y las nuevas reglas, modificadas en su redacción. Nuevamente se procesó el juicio emitido por el método Delphi y se identificó la concordancia literatura-expertos. El criterio de parada para las rondas de expertos estuvo dado por la obtención de una concordancia excelente (superior a 0.75) entre los criterios de los expertos y lo planteado en la literatura.
Tercer estudio: Metaanálisis
Con el objetivo de evaluar la efectividad de la metodología propuesta, basada en la evidencia de la efectividad que reportan las 13 investigaciones que la han empleado, se realizó un metaanálisis, donde se utilizaron métodos estadísticos para combinar los resultados de estos estudios, lo cual permitió combinar los resultados procedentes de todos los estudios y obtener un solo indicador para cada uno de los efectos (sensibilidad, especificidad y otros), aumentando la potencia estadística y la precisión de estos indicadores.
Para llevar a cabo el mismo se siguieron los procedimientos propuestos por el Manual Cochrane de revisiones sistemáticas de intervenciones Versión 5.1.0 actualizado en 2011 adaptados a las condiciones de este trabajo. 25
Procedimientos llevados a cabo
Establecimiento de la pregunta que se desea responder: la pregunta a responder fue si el efecto de la metodología propuesta es suficientemente grande para asimilar su introducción en los estudios de identificación de factores pronósticos y de riesgos.
Cuantificación de los efectos: el efecto de la metodología se cuantificó mediante los índices de rendimiento de un procedimiento diagnóstico al considerar el análisis estadístico implicativo como tal en la identificación de factores pronóstico o de riesgo dentro del conjunto de las covariables investigadas, tomando como principal indicador el odds ratio de diagnóstico.
Localización de los estudios de investigación: se realizó una búsqueda exhaustiva de los trabajos originales sobre el tema en las bases de datos biomédicas alojadas en la internet y las redes sociales, siendo los únicos trabajos encontrados con aplicación del análisis estadístico implicativo para la identificación de factores pronósticos y de riesgo, los realizados en la Universidad de Ciencias Médicas de Santiago de Cuba bajo la dirección de la Dra. Zamora.
Criterios de inclusión y exclusión de los estudios: se incluyeron todos los trabajos publicados y no publicados con diseño caso control para identificar factores de riesgo o factores pronósticos donde se aplica el análisis estadístico implicativo comparativamente con la regresión logística binaria.
Búsqueda de información y datos relevantes de cada estudio: no fue necesario crear una estrategia de búsqueda pues se conoce la localización de todos los artículos al formar parte de la producción científica de las autoras y previamente se había identificado la no existencia de otros estudios similares.
Evaluación de la calidad de los estudios incluidos: se verificaron criterios para clasificar el riesgo de sesgo en bajo, moderado o alto, a partir de una propuesta de la Guía STARD (Standart for Reporting of Diagnostic Accuracy) de EQUATOR (normas consolidadas para la publicación de estudios de evaluación de medios diagnósticos). 26
Análisis de la heterogeneidad de los estudios: la homogeneidad de los estudios se garantiza por el tipo de diseño y otros factores que se han mantenido constantes en los mismos. No obstante, se midió con el test de homogeneidad de Cochran, los índices H2 e I2 y los gráficos de L’Abbé y de Galbraith previendo el tratamiento de la heterogeneidad con análisis en subgrupos y metarregresión. (27
Combinación de resultados: se calculó el promedio de forma ponderada y no ponderada, ponderando por la inversa de la varianza con modelo de efecto fijo o usando un modelo de efectos aleatorios, para producir los resultados intermedios. Los odds ratio de diagnóstico se combinaron en un estimador global mediante la técnica de Mantel-Haenszel. Las parejas de proporciones de verdaderos positivos y falsos positivos permitieron conformar una curva SROC (acrónimo de Summary Receiver Operating Characteristic), a partir de pares de valores
A partir de los pares antes mencionados se ajustó un modelo de regresión lineal simple, esto es,
Identificación del sesgo de publicación: se realizaron las técnicas habituales como gráfico en embudo o funnel plot donde se representó el tamaño muestral de cada trabajo frente al tamaño del efecto detectado y las técnicas estadísticas de Begg y de Egger. 29
Análisis de sensibilidad: se realizó el análisis separando los estudios de factores de riesgo y los de factores pronósticos y eliminando en cada paso un estudio diferente.
Actualización y mejora de la revisión: permanecerá vigente aún después de concluido este trabajo a raíz de los nuevos cambios.
Presentación de los resultados
Los resultados se presentaron mediante los gráficos de bosque para cada uno de los efectos medidos, en el cual se muestran las estimaciones del efecto individual de cada estudio, el valor global obtenido al combinar todos los resultados y su intervalo de confianza. La redacción del artículo científico se hizo acorde con la declaración PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses), establecida como guía de literatura crítica para este tipo de estudio. 30
Quinta Etapa: Diseño definitivo
En el diseño definitivo de la metodología, tras la aplicación del análisis estadístico implicativo, se identificaron dos nuevas etapas que se describen a continuación.
Selección de las variables a incluir en el modelo de regresión logística binaria: Elegir primero las variables que se enlazan con el cono de los dos grafos implicativos:
Discusión de los resultados: Contrastar con los resultados obtenidos por la regresión logística y comparar con los estudios anteriores
Sistemas informáticos y procesadores estadísticos empleados
Para el procesamiento y presentación de los resultados en las diferentes etapas de la investigación se emplearon los siguientes sistemas:
Microsoft Excel del paquete Office 2016, para confeccionar la base de datos en formato .xlsx para exportar al SPSS y en formato .csv como condición necesaria para la aplicación del CHIC y para el procesamiento de los instrumentos aplicados en la validación de contenido y programar el cálculo del coeficiente de Aiken y sus intervalos, el procesamiento por el método Delphi y otras fórmulas necesarias.
IBM SPSS Statistics 24.0, para obtener el modelo basado en la regresión logística.
CHIC 5.0, para obtener el modelo basado en el análisis estadístico implicativo, así como los gráficos ilustrativos de la técnica.
R 3.2.0 para efectuar el metaanálisis y la presentación de los resultados numéricos y gráficos del mismo, con el empleo de las librerías apropiadas (meta, metafor, compute.es, copas) y para la programación de las funciones que calculan los indicadores del desempeño del análisis estadístico implicativo comparado con la regresión logística binaria, teniendo en cuenta que todos los programas que calculan los intervalos de confianza de estos indicadores lo hacen con la aproximación a la normal, válido para muestras grandes y en este caso se necesitó la transformación de Wilson, y el RStudio 1.0.44 como entorno de desarrollo integrado sobre el cual se corrió el R.
Limitaciones del estudio
Los factores pronósticos clásicos se pueden obtener con un estudio histopatológico convencional. Sin embargo, desde hace algunos años, van apareciendo nuevos marcadores pronósticos relacionados con la estructura y el ciclo celular o mutaciones genéticas que requieren tecnologías de avanzada para su detección, como las técnicas inmunohistoquímicas.
Al no disponer de todos los resultados de los biomarcadores se decidió definir una variable explicativa que evaluara el tener o no la determinación, pues en caso contrario se hubiese tenido que descartar algunos casos y controles que no tenían el resultado de estos biomarcadores, con la consecuente reducción del tamaño de muestra y la imposibilidad de aplicar la regresión logística. Solo en la sexta etapa de análisis a posteriori se trabajó con los casos que tenían esta determinación para ver la influencia del subtipo molecular como factor pronóstico. Este inconveniente pudiera haber interferido en la precisión de los factores pronósticos identificados, pero no influyó en la demostración de la eficacia de la metodología propuesta que es el objetivo principal de este trabajo.
Bioética Médica
El presente estudio se articuló sobre los principios fundamentales que regulan la conducta ética médica, dispuestos en la Declaración de Helsinki de la Asociación Médica Mundial. 31 El diseño de la investigación e inclusión de variables fue consultado con el jefe provincial del programa de cáncer y los facultativos relacionados con la atención a las pacientes objeto de estudio. No se recogió el consentimiento informado por no tratarse de un experimento. Los datos obtenidos fueron estrictamente confidenciales y no serán utilizados con fines ajenos a esta investigación. Antes de iniciar la investigación se elaboró el proyecto, el cual fue aprobado por las autoridades competentes de los centros donde se desarrolló el estudio, los consejos científicos y los comités de ética de la investigación en salud de los niveles correspondientes.
Control de la calidad
Para tener certeza de la calidad de los datos empleados se determinó la calidad de todas las historias clínicas, informes de anatomía patológica y registros involucrados en el estudio como parte de un trabajo de terminación de especialidad en Bioestadística defendido en la Universidad de Ciencias Médicas de Santiago de Cuba, en noviembre de 2019. En los casos de historia defectuosa se sustituyó la unidad de análisis por otra cuya historia tuviera una calidad demostrada.
Se recomienda consultar los artículos de la bibliografía que explican en detalles y ejemplifican cómo aplicar este análisis de manera eficiente según las consideraciones de las autoras, lo cual hará posible que se sumen investigadores a su empleo.