










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Luego de la aparición de la pandemia de la COVID-19, el mundo experimentó una explosión de literatura científica sobre este tema. Las cifras de artículos desde 2019 hasta 2021 en la base de datos Dimension1 (términos COVID-19 o SARS-CoV-2 incluidos solo en el título o el resumen) fue de 393 134 documentos, lo que representó aproximadamente un promedio de 359 publicaciones diarias. El tema abarcó 2,12 % del total de la producción científica mundial anual en 2020, lo que resultó un hecho sin precedentes en la historia.2
Un análisis de redes de citas publicado por Martínez y colaboradores,3) que abarcó todos los artículos indizados en la Web of Science que incluían términos como “COVID-19” o “SARS-CoV-2” desde enero hasta junio de 2020 identificó que entre las áreas de mayor interés por parte de la comunidad científica se encontraban el curso clínico y el tratamiento de la enfermedad. Los estudios que abordaron el desarrollo y la validación de modelos de predicción clínica (MPC) estuvieron vinculados con estos dos temas y también resultaron de creciente interés.4
El número de publicaciones registradas en la base de datos Dimensions1 que contenían los términos “prediction model” o “prognostic model” en el título o el resumen aumentó en 2 466 documentos en 2019 (10 753 artículos) con respecto al año anterior al inicio de la pandemia en 2018 (8 287 artículos).5
El empleo de MPC hace más operativa y eficiente la estratificación por riesgo de severidad y la atención del paciente porque favorecen la uniformidad y precisión, también reducen las demoras del diagnóstico/pronóstico y optimizan la asignación o priorización de recursos sanitarios limitados. Sin embargo, es necesario que las estimaciones de riesgo obtenidas a través de los modelos sean válidas y extrapolables a la población diana.6
Según una revisión sistemática realizada por Wynants, (4) hasta junio de 2020, la mayoría de los MPC publicados para el diagnóstico o pronóstico de la COVID-19 no estaban bien informados en sus artículos correspondientes y no eran recomendables para su uso en la práctica clínica. Estudios como el de Gupta y colaboradores,7 cuestionan que modelos multivariados tengan mayor valor predictivo sobre la severidad de la COVID-19 que variables independientes como saturación de oxígeno en el aire y la edad del paciente.
Utilizar el conocimiento previo disponible en la literatura científica tiene una importancia cardinal antes de realizar una nueva investigación, ya que muchos de los desafíos futuros que se pueden presentar ya podrían haber sido abordados por otros investigadores. Por tanto, la literatura científica disponible podría ser útil en la identificación de variables de resultados, predictores candidatos, algoritmos óptimos, así como para prever posibles sesgos en el proceso.6
En este sentido, el problema científico del presente trabajo queda formulado a partir de las interrogantes siguientes: ¿Cuáles son las fuentes relevantes, autores y documentos claves que forman parte del frente de investigación sobre los MPC para la estratificación del riesgo de severidad en pacientes confirmados de la COVID-19? ¿Qué MPC han sido mejor aceptados por la comunidad científica?, ¿Qué variables de resultado, predictores y algoritmos han resultado más relevantes?, ¿En qué medida los modelos existentes podrían cumplir con los atributos de calidad (válidos y fiables)?, ¿Qué características deberían poseer estos modelos para ser aplicables en el contexto cubano?
El mundo reconoce que puede haber otra pandemia dado que persisten las condiciones para su aparición. Es por ello que es necesario preparar al país de forma oportuna con metodologías bien desarrolladas, discutidas y validadas. En este sentido, el presente trabajo tiene como objetivo describir las fuentes, autores, documentos claves que forman parte del frente de investigación. Identificar qué modelos, variables de resultado, predictores y algoritmos han resultado relevantes. Identificar en qué medida los modelos disponibles podrían cumplir con los atributos de calidad y qué características deberían poseer para ser aplicables en el contexto cubano.
MATERIAL Y MÉTODOS
Se realizó una revisión sistemática y análisis cienciométrico sobre el tema de MPC para estimar el riesgo de transición a la severidad en personas confirmadas con la COVID-19, así como una descripción de algunos modelos publicados en la literatura científica y sus características fundamentales.
Como fuente para obtener el registro de publicaciones se utilizó la base de datos Dimensions1 y la estrategia de búsqueda consistió en recuperar todos los artículos que incluyeron los términos “prediction model” o “prognostic model” y “COVID-19” o “SARS-CoV-2” en el título o el resumen, publicados entre 2019 y 2021. Como criterios de inclusión se asumió que los artículos fueran clasificados como investigación original y pertenecieran a los campos de investigación Ciencias Biomédicas y Clínicas o Ciencias de la Salud según la clasificación ANZSRC8 2020. Como criterio de exclusión se asumió que los artículos a los que no fuera posible acceder por diversas razones serían eliminados del estudio. (Figura 1).
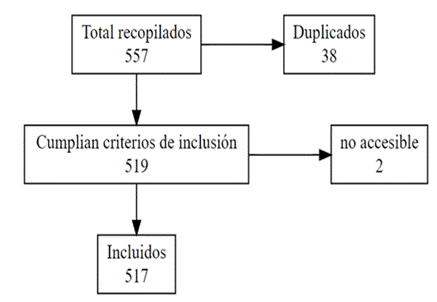
Para la descripción de los MPC disponibles en la literatura se utilizaron los datos de Covidprecise (https://www.covprecise.org), un consorcio internacional de expertos que evaluaba investigaciones sobre modelos de predicción para la COVID-19 y que periódicamente actualizan una revisión sistemática.4 Se utilizó la actualización de la base de datos hasta el 12 de agosto de 2022. Es posible acceder a esta fuente de información a partir de la dirección URL: https://www.covprecise.org/wp-content/uploads/2020/11/data_web-1.xlsx
Las variables analizadas para cada modelo fueron: predictores, variables de resultados y algoritmo empleado (variable para cada tipo específico con categorías sí o no), a partir de las cuales se calcularon distribuciones de frecuencia absolutas y relativas.
El análisis cienciométrico se estructuró para métricas de publicación de diferentes niveles como fuentes, autores y documentos, así como estructuras de conocimiento (estructura conceptual). Los indicadores de publicación consistieron en el número de publicaciones, el número de citas, la media de citas (MC), la proporción de citas de campo (FCR) y la proporción relativa de citas (RCR).9
Para el análisis de la estructura conceptual se realizó un mapa temático resultado de aplicar una técnica de escalamiento multidimensional (MDS) a los principales términos en los títulos de los trabajos como describen Cuccurullo y colaboradores.10,11 Se usó la asociación de dos palabras como parámetro de la técnica.
Para la identificación se empleó el software Bibliometrix.10 El análisis estadístico y descriptivo se realizó en el lenguaje de programación R (versión 4.2.2).12 Los resultados se presentaron en tablas y gráficos.
El estudio no transgredió ninguna norma ética, ya que se trató de un análisis de publicaciones que ha pasado las regulaciones establecidas en cada uno de los contextos. La investigación ha sido aprobada por el Comité de Ética de la institución responsable de la investigación.
RESULTADOS
Fuentes claves, autores y documentos relevantes
De los 519 artículos recuperados, 86,21 % recibió al menos una cita. Se muestra la lista de los -cinco más importantes- recursos de información, autores y documentos sobre el tema. (Tabla 1).
Tabla 1 Principales recursos de información, autores y artículos sobre el tema según Dimensions
| Publicaciones | Citas | MC | |
|---|---|---|---|
|
|
22 | 389 | 17,68 |
| 17 | 766 | 45,06 | |
| 16 | 103 | 6,44 | |
| BMJ Open | 14 | 119 | 8,50 |
| 11 | 289 | 26,27 | |
| Publicaciones | Citas | MC | |
| 6 | 2 231 | 371,83 | |
|
|
6 | 1 964 | 327,33 |
|
|
4 | 103 | 25,75 |
|
|
4 | 159 | 39,75 |
| 4 | 103 | 25,75 | |
| Citas | FCR | RCR | |
|
|
1 947 | 1084.01 | 177,66 |
|
|
187 | 67 | 13 |
|
|
48 | - | - |
|
|
123 | - | - |
|
|
95 | 28 | 9,58 |
Leyenda: MC= Citas medias, FCR= Proporción de citas de campo, RCR= Proporción relativa de citas.
La fuente de información que más aportó al tema fue Scientific Reports del portafolio de Nature y PLOS ONE. Ambas revistas son de acceso abierto y están entre las de más alto nivel de impacto en el campo de la salud. Con una diferencia marcada respecto al resto de publicaciones, el artículo de mayor interés correspondió a la revisión sistemática titulada Prediction Models for Diagnosis and Prognosis of Covid- 19: Systematic Review and Critical Appraisal, publicada en BMJ por Wynants y colaboradores. En esta revisión se realizó una evaluación crítica sobre la validez y utilidad de los informes publicados o preimpresos de modelos para el diagnóstico y el pronóstico de pacientes con la COVID-19. El autor más importante fue Martín Van Smeden del Centro Julius de Ciencias de la Salud y Atención Primaria en Utrecht, Países Bajos, coautor además de la revisión sistemática mencionada y líder del proyecto Covidprecise.
Análisis de temas y documentos relevantes
En el mapa temático se distinguen tres ejes: dos, bastantes homogéneos y uno, con mayor heterogeneidad. (Figura 2).
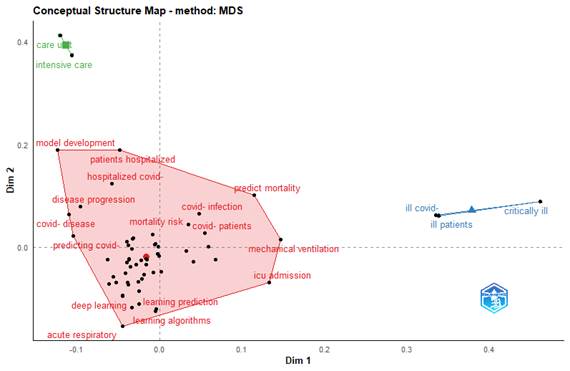
Figura 2 Principales conceptos de los trabajos seleccionados. Técnica de visualización Multidimensional Scaling (MDS) a partir de los títulos
A continuación, de arriba a abajo, se describe cada uno de los conglomerados:
Conglomerado verde (superior): Incluyó las palabras unidades de cuidados (care unit) y cuidados intensivos (intensive care). Los artículos del grupo pudieron estar enfocados en temas como el desarrollo de modelos en escenarios de muy alto riesgo de transición a la severidad o consultas de emergencia. El trabajo más relevante (162 citas) dentro del clúster fue Prediction model and risk scores of ICU admission and mortality in COVID-19 de Zirun Zhao y colaboradores, publicado en la revista PLOS ONE.13
Conglomerado rojo (medio): Resulta el grupo más amplio. El término principal lo constituye desarrollo de modelos (model development), acompañado de palabras como pacientes hospitalizados (patients hospitalized, hospitalized covid), que podrían indicar el contexto hospitalario como escenario principal para la aplicación de estos modelos. En el conglomerado también se encuentran palabras que pueden ser asociadas con la predicción de variables de respuesta como el riesgo de enfermar (predicting covid, covid infection, covid-disease), de transición a formas severas de la enfermedad (disease progression), en particular, admisión en unidades de cuidados intensivos (icu admission) o necesidad de ventilación mecánica (mechanical ventilation), así como el riesgo de muerte (predict mortality, mortality risk). Este conglomerado incluye la revisión sistemática de Wynants y colaboradores4 que constituyó el artículo más citado de esta colección como se describió en la Tabla 1.
Conglomerado azul (inferior): El grupo contiene palabras como pacientes críticos (critically ill patients) o pacientes críticos con la COVID-19 (critically ill covid patients) que denota un interés de la aplicación de modelos para explicar o predecir la enfermedad severa, así como el uso de técnicas de aprendizaje aproximado. El artículo de mayor relevancia (27 citas) fue publicado por Mohammad M. Banoei, en la revista Critical Care y se titula: Machine-learning-based COVID-19 mortality prediction model and identification of patients at low and high risk of dying.14
Principales modelos de predicción clínica analizados en la literatura científica y sus características
Hasta el 9 de agosto de 2022 se registró un total de 232 MPC, 7 para predecir la susceptibilidad a la COVID-19 en la población general (identificación de grupos de alto riesgo), 118 para realizar clasificaciones diagnósticas como la presencia de la COVID-19, COVID-19 severo y diagnóstico por imágenes, 107 se emplearon para estimar el riesgo de transición a la severidad en pacientes confirmados, incluido 28 para predecir el estado crítico y 39 para la muerte.4)
La base de datos del sitio www.covprecise.org hasta la fecha de este trabajo ha registrado 731 publicaciones entre estudios originales y actualizaciones de los modelos. Las variables de respuesta más utilizadas fueron mortalidad a los 30 días 265 (44,8 %), progresión a la severidad 84 (14,2 %), admisión en UCI 53 (9,0 %), neumonía 8 (1,4 %), estadía hospitalaria 10 (1,7 %), alta hospitalaria 6 (1,0 %) y otras variables dependientes compuestas 81 (13,7 %).
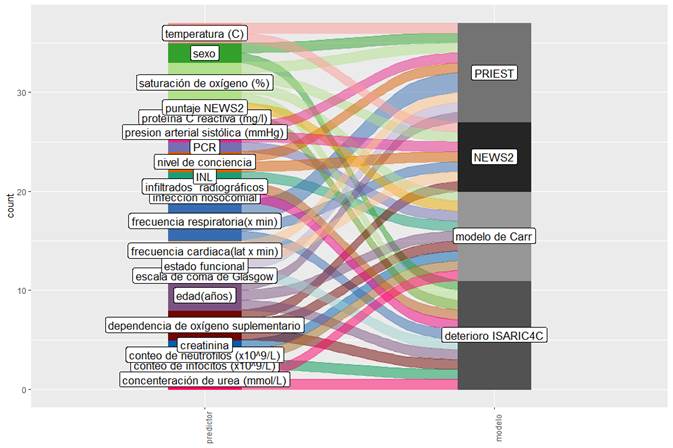
Las técnicas más utilizadas fueron la regresión logística con 215 artículos (38,2 %), otros algoritmos (126; 22,4 %), redes neuronales (85; 15,1 %), árboles de clasificación (55; 9,8 %), regresión de Cox (45; 8,0 %), máquina de soporte de vectores (17; 3,0 %), regresión lineal, multinomial u ordinal (19; 6,4 %) y otros modelos de supervivencia (1; 0,2 %). A continuación, en la Figura 3 se muestran los predictores correspondientes a los modelos seleccionados como los más prometedores. Entre ellos destacan edad, sexo, comorbilidades, signos vitales, algunos síntomas similares a los de la gripe, determinadas características de las imágenes, recuento de linfocitos y la proteína C reactiva.
DISCUSIÓN
Los tres componentes que mayor impactan sobre la reducción por la COVID-19 son el control de la trasmisión y la transición a la severidad, así como el tratamiento de la enfermedad grave.(2) Por su parte, la calidad de la clasificación es un elemento fundamental para el control de la transición a la severidad. Para realizar una clasificación de calidad se debe obtener metodología que permita dar respuesta a la siguiente interrogante: ¿Cómo identificar individuos donde la decisión de intensificar o atenuar el tratamiento pueda ser considerada como ética, eficaz y segura?
Dada las particularidades del ámbito donde se desarrolló la pandemia en Cuba, así como la característica de la COVID-19 como enfermedad, hace que la respuesta a la pregunta anterior sea difícil de obtener de la literatura científica, al menos completamente.
La enfermedad COVID-19 es nueva, diferente a otras enfermedades y sensible a fármacos cubanos. El grupo de peor pronóstico, sobre el que habría que intensificar el tratamiento suele ser pequeño, lo que a diferencia de otras enfermedades crónicas, las decisiones hay que tomarlas de forma inmediata dado que algunos casos evolucionan rápido a formas severas. Además, es importante subrayar que el curso clínico de la enfermedad depende de la conducta. En Cuba, a diferencia de otros países, se decidió el ingreso precoz a todos los confirmados. Esta confirmación se realizó por PCR. Se clasificó a los pacientes en función del índice neutrófilo linfocito (INL). Además, el tratamiento se realizó con fármacos de producción nacional.
El empleo de MPC como elemento de la metodología jugaría un papel fundamental. Estos modelos se obtienen a partir de un método científico riguroso. En su desarrollo se emplean la evidencia disponible. También se puede evaluar su desempeño a través de métricas de desempeño. Sin embargo, los MPC reportados en la literatura no deben ser aplicados de forma directa a la población diana, porque variaciones en el contexto puede provocar que las estimaciones del riesgo de severidad no sean extrapolables a la población cubana.
No se tiene referencia que existan MPC completamente fiables y reconocidos por la comunidad científica internacional por lo que el desarrollo y validación de MPC para la estratificación del riesgo de severidad en pacientes confirmados de la COVID-19 fue un campo no cubierto por la ciencia hasta 2021. Sin embargo, el tema constituyó un frente de investigación de gran interés que motivó una amplia producción científica.
Fuentes claves, autores, documentos relevantes
Los artículos sobre este tema fueron publicados en las revistas con más alto ranking de citas entre todas las disciplinas del conocimiento. Los autores más importantes fueron del continente Euroasiático donde destacan países como Reino Unido, China y en particular los líderes del proyecto Covidprecise.15
Precisamente, la tercera actualización de revisión sistemática que promueve el proyecto Covidprecise15 constituyó la obra más relevante dentro del frente de investigación según los indicadores bibliométricos analizados.4
Estos autores consideran que se trata de una fuente de información clave para la identificación y validación de modelos aplicables a los distintos escenarios de atención del Sistema Nacional de Salud. También puede ser de utilidad para la identificación de componentes estructurales de los modelos como variables de resultado, predictores y algoritmos que las relacionan.
El grupo Covidprecise15 examinó más de 126 000 estudios y en referencia a estos expresaron que la mayoría de los modelos publicados hasta el momento de la tercera revisión, no eran recomendables para su uso generalizado en la práctica clínica dado que no estuvieron bien informados y tenían un alto riesgo de sesgo, por lo que su rendimiento predictivo informado era probablemente optimista por sobreajuste.4
Por su parte, la OMS,16 Fuente: Covidprecisev15 en sus orientaciones para el manejo clínico de la COVID-19 en su actualización del 23 de noviembre de 2021 solo recomendó como métodos para la toma de decisiones el juicio clínico, las preferencias de pacientes y las políticas sanitarias regionales, en lugar de los MPC actuales a causa de una fiabilidad muy baja.4 No obstante, en relación con los modelos de mayor calidad identificados por el grupo Covidprecise,15 enunció que, para estar seguros del beneficio de estos modelos para los pacientes y el personal médico, era importante llevar a cabo estudios de validación para probarlos en nuevos pacientes y cuantificar la precisión de las predicciones.
Covidprecise15 agrupó los modelos en tres tipos principales según el contexto de aplicación de los mismos. El primer grupo se enfocó en predecir la vulnerabilidad a la COVID-19 en la población general, el segundo en predecir si los pacientes con la COVID-19 que acudían a consultas de urgencias evolucionaron a formas severas y el tercero en predecir en instituciones hospitalarias si los pacientes con la COVID-19 tuvieron un desenlace adverso, como muerte, cuidados críticos o soporte ventilatorio.4
Esta delimitación es congruente con los resultados del análisis temático realizado en este estudio. En Cuba, para el manejo de la pandemia es posible distinguir un escenario de bajo riesgo de transición a la severidad donde los pacientes son atendidos en la atención primaria de salud y uno de mayor riesgo contextualizado en las instituciones hospitalarias (unidades de vigilancia, unidades de vigilancia intensiva y UCI).
Principales modelos de predicción clínica analizados en la literatura científica y sus características
Es posible reconocer en los modelos disponibles en la literatura las potenciales aplicaciones según cada uno de los escenarios de atención del sistema nacional de salud cubano para el enfrentamiento a la COVID-19.
Por ejemplo, los modelos Qcovid17 podrían ser adaptados para el uso de intervenciones preventivas, como la vacunación y el blindaje; el modelo PRIEST18 podría ser útil para clasificar a los pacientes con la COVID-19 que acuden a consultas; y los modelos de deterioro ISARIC4C,19 el modelo de Carr,20 y el modelo de Xie4 podrían servir como complemento para tener las mejores decisiones posibles con pacientes individuales, según el riesgo de transición a la severidad en pacientes hospitalizados.
A partir del análisis de los modelos más fiables, es posible afirmar que existen evidencias en la literatura científica para considerar como potenciales componentes estructurales de los modelos cubanos variables de resultados como la admisión en UCI, o la mortalidad a los 30 días, así como predictores al momento de la consulta como la edad y el antecedente de determinadas comorbilidades (incluidas en índice de Charson más obesidad), la dependencia de oxígeno suplementario, el nivel de conciencia, la presión arterial, la frecuencia cardíaca y respiratoria. También resultados de exámenes complementarios como la saturación de oxígeno, el INL, la proteína C reactiva, la creatinina y la concentración de urea. Adicionalmente deberían ser valorados la inclusión de predictores que son el resultado de escalas como el NEW2 y la escala de coma de Glasgow (21 El empleo de algoritmos como la regresión logística, la regresión Lasso y los árboles de clasificación podrían ser técnicas adecuadas en el desarrollo de nuevos modelos.(4,6)
Aplicabilidad al contexto cubano
En opinión de estos autores, los modelos que se recomiendan en la literatura aún no satisfacen los atributos de calidad necesarios para ser integrados a una metodología para la estratificación del riesgo de transición a la severidad en pacientes confirmados de la COVID-19 en Cuba.
Es necesario entonces validar los modelos propuestos por Covidprecise15 en la población cubana o desarrollar nuevos modelos según el contexto de la organización de los sistemas y servicios de salud. La información resultante de esta revisión de la literatura podría ser útil para ello. Los datos recogidos de las historias clínicas y los sistemas de información de los pacientes confirmados podrían permitir tanto la validación de los modelos propuestos como el desarrollo de nuevos.
A partir de julio del 2021 (versión 1.5 del PANEC)22 los criterios obtenidos a partir de modelos de predicción clínica, en este caso, bajo un enfoque de árboles de clasificación fueron aplicados a los escenarios de ingreso en el hogar y seguimiento por la APS y unidades de vigilancia intensiva (UVI-A) con resultados satisfactorios. Estos análisis aportaron indicadores útiles para la toma de decisiones como el volumen del estrato, el riesgo se severidad y severidad explicada.23
Por su parte también se recogen antecedentes de que MPC desarrollados en instituciones hospitalarias como el Hospital Manuel Fajardo en la provincia de Villa Clara se han aplicado en el país. En este caso de la publicación de Herrera y colaboradores24) que hace referencia al desarrollo de un nomograma de predicción del riesgo en pacientes con COVID-19. El desarrollo de MPC puede contribuir a perfeccionar los procedimientos de derivación de los pacientes hacia los distintos escenarios y servir como referencia para países de recursos limitados.
Como limitación del estudio se declara que o fue posible contar con la totalidad de registros de investigaciones en todos los campos del conocimiento dado que la base de datos Dimensions solo permite descargar hasta 500 registros de forma gratuita.

