










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
La modelación matemática de poblaciones (1) permite describir la mayoría de los procesos biológicos (2). Sin embargo, la no implementación o no divulgación-extensión de softwares específicos, hace que en nuestro país sea aún incipiente su aplicación práctica.
La mayoría de los trabajos, que refieren la utilidad práctica de los modelos matemáticos en el campo de los estudios poblacionales, describen los diferentes modelos empleados y la posibilidad de proponer otros (2), pero existe una aparente desunión entre los múltiples modelos aplicados en la ecología cuantitativa de poblaciones para simular dinámica de insectos y los modelos para la simulación de enfermedades virales o bacterianas (3), que muestran un mayor avance en los estudios matemáticos de diseminación en correspondencia con los patrones de distribución (4).
Los trabajos tampoco hacen referencia explícita de las herramientas empleadas para la simulación y los algoritmos computacionales, lo que dificulta la reproducción de los modelos por parte de especialistas de otra rama, que son los más interesados en los resultados de la simulación de los modelos.
Por tal motivo, los objetivos de este artículo fueron analizar los principales modelos empleados en la modelación matemática de poblaciones, tanto de artrópodos como de enfermedades, y describir los pasos a seguir en la simulación y las herramientas usadas para este fin. Se referencian, además, diferentes trabajos que se han realizado en Cuba en esta línea de investigación.
MODELOS MATEMÁTICOS PARA LA SIMULACIÓN DE LA DINÁMICA DE POBLACIONES
Muchos han sido los modelos que a lo largo de la historia se han desarrollado y mejorado para simular la dinámica de las plagas en los cultivos. La simulación de estos modelos ha tenido diversos objetivos, como pueden ser interpretar el ciclo de desarrollo de una población, calcular los niveles de un control biológico que logran una estabilidad de su hospedante, entre otras aplicaciones (2).
Los más conocidos son los modelos presa-depredador (5), hospedante-parásito (6) y los de interacción tritrófica (7).
Entre los más usados a nivel mundial se encuentra el modelo presa-depredador (Fig. 1). Fue desarrollado por Lotka (1925)-Volterra (1931) y representa la interacción entre dos especies que conviven dentro de un mismo hábitat, en el cual el número de individuos de cada población depende no solo de la razón de crecimiento o decrecimiento natural, sino también de los encuentros exitosos entre ellos, es decir, que un depredador pueda cazar la presa (8).
No obstante, en la versión más simple de este modelo no existe un término de autoamortiguación poblacional (denso-dependencia) y las trayectorias de las abundancias de depredadores y presas se presentan como oscilaciones perpetuas no amortiguadas en el tiempo.
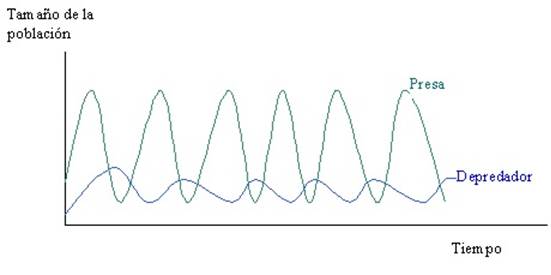
Solo para algunos valores de los parámetros el sistema logra una estabilidad, pero por regla general estos modelos describen sistemas inestables, donde los pequeños cambios en los parámetros producen grandes alteraciones en el espacio vectorial definido (9).
Sin embargo, Thomas Malthus sostenía que mientras el crecimiento de la población en el mundo se daba en forma geométrica, la producción de alimentos aumentaba en progresión aritmética. Ante esto proponía, como solución, aplicar un control de la natalidad y confiaba en que los factores de regulación natural retardarían la llegada de una crisis total de alimentación (2).
Aunque este modelo resulta sumamente útil para pronosticar el tamaño de la población sin asumir restricciones, solo es válido para pequeños espacios de tiempo. El modelo logístico parte del de Malthus, añade un término adicional, que representa la competencia entre los individuos de la misma especie por los recursos, esto induce un límite al crecimiento de una población (1).
Van den Bosch (10) se refirió al control biológico como la manipulación de los enemigos naturales por el hombre para controlar las plagas y lo diferenció del control natural que ocurre, según este autor, sin intervención humana.
Dentro del control biológico se distinguen: 1) la importación e introducción de un enemigo natural para controlar una plaga exótica (control biológico clásico) o nativa (control biológico neoclásico), 2) la cría artificial de un enemigo natural para su liberación en el cultivo en forma inoculativa o inundativa, y 3) la conservación de enemigos naturales por medio de manipulaciones ambientales para proteger y aumentar la abundancia, la diversidad y la efectividad de los mismos (10).
Otro modelo, a partir del propuesto por Lotka-Volterra, fue el desarrollado por Anderson y May en 1981 (Fig. 2), modelo mucho más complejo que muestra las interacciones del hospedante con su antagonista asociado; este describe las relaciones entre el hospedante y el parásito, basadas en la transición del hospedante sano al hospedante parasitado.
Este modelo presenta una característica particular y es que permite estimar la densidad de propagación del parásito facilitando determinar la cantidad de inóculo para controlar al hospedante (9).
FIGURA 2 Interacción Meloidogyne incognita-Trichoderma asperellum en garbanzo, simulada según modelo Anderson-May./ Simulated Meloidogyne incognita-Trichoderma asperellum interaction in chickpea according to the Anderson and May model.
Muchos otros modelos han surgido adaptando la idea inicial del modelo presa-depredador (5) para intentar reproducir la conducta de la población que describe, lo que indica que cada población debe ser analizada sugiriendo el modelo que mejor simula su dinámica.
Actualmente, los modelos de mayor uso para la simulación de la dinámica de plagas son los que incluyen interacciones tritróficas cultivo-plaga-control biológico. Un ejemplo de ello es el modelo que representa los diferentes estadios del nematodo agallero en la raíz en interacción con el hongo Trichoderma asperellum cuando actúa como control biológico (11). (Fig. 3)

FIGURA 3 Relación teórica estructural de M. incognita con T. asperellum. /Theoretical structural relationship between M. incognita and T. asperellum.
En la Figura 3 las variables indican:
H |
- Número de huevos de M. incognita |
J |
- Cantidad de juveniles de segundo estadio |
A |
- Adultos de M. incognita |
R |
- Raíz del cultivo |
O |
- Ootecas |
T |
- T. asperellum |
La idea de estos modelos es simular el comportamiento de las plagas, en uno o varios tipos de cultivos, en presencia de uno o varios controles biológicos (12).
En el caso de las enfermedades, también son muchos los modelos propuestos. La mayoría de la literatura de epidemiología refiere modelos que describen el proceso de comportamiento de las plantas, animales o humanos pasando por diferentes procesos. Ejemplo de ello son los modelos Susceptible-Infectados-Recuperados (SIR), Susceptible-Expuestos-Infectados-Recuperados (SEIR) y otros de naturaleza determinista o estocástica, según sea el efecto a modelar (3).
Algunos autores han incorporado ecuaciones de dispersión a estos modelos (4) y otros llegan a analizar la hostilidad del hospedante para modificar la epidemia incorporando parámetros del ciclo del cultivo al modelo (13) o analizando un hospedante sano y otro susceptible, en el que ambos pueden pasar a un periodo de latencia y solo los susceptibles pueden pasar automáticamente al proceso de infestación (14,15).
Lo anterior ratifica que el modelo depende del comportamiento de la enfermedad, de las características del vector que la trasmite, las cualidades del cultivo hospedante y de un sinnúmero de factores ambientales.
HERRAMIENTAS ESTADÍSTICAS Y COMPUTACIONALES PARA LA SIMULACIÓN DE MODELOS MATEMÁTICOS
Actualmente, para estos y muchos otros modelos existen diversas y potentes herramientas informáticas que permiten la simulación y ayudan en la toma de decisiones.
Entre los más usados en la última década se pueden mencionar SPSS, SAS, MatLab, Statistica, R, entre otros. La mayoría de estos paquetes estadísticos tiene varias desventajas: por los softwares propietarios debe pagarse cuantiosas sumas para las licencias, los de libre acceso y las versiones gratis de los anteriores no son tan potentes o no tienen todas las herramientas necesarias para las operaciones y, por último, algunos de los software de acceso libre requieren un alto grado de conocimiento de programación por parte del usuario, lo que también dificulta su uso.
SPSS: (Statistical Package for The Social Sciences o Paquete Estadístico para las Ciencias Sociales) se desarrolló en la Universidad de Chicago; se considera que es de los más potentes, pero sus licencias cuentan en el orden de los miles de euros. Es un paquete estadístico de uso general, que integra procedimientos estadísticos y gráficos interactivos de alta resolución, de tal manera que sirve de apoyo al análisis de datos.
Es útil, entre otros aspectos, para realizar análisis exploratorio desde el punto de vista gráfico; de igual manera, se utiliza para realizar análisis estadístico simple y/o avanzado. El programa sirve para profundizar en temas como: Métodos Cuantitativos, Métodos de Investigación, Segmentación de Mercados, Finanzas, Inferencia Estadística, Análisis Multivariado, Pronósticos con series de Tiempo, Métodos Multivariados y otros más (16), de manera que la simulación de procesos no incluye la modelación con ecuaciones diferenciales.
SAS: (Statistical Analysis System o Sistema para Análisis Estadístico), al igual que SPSS, es considerado uno de los más potentes por todas las características y herramientas que posee; las licencias de este paquete también rondan los miles de euros. Comprende amplias posibilidades de procedimientos estadísticos (métodos multivariados, regresión múltiple con posibilidades diagnósticas, análisis de supervivencia con riesgos proporcionales y regresión logística); permite cálculos exactos para tablas r x c y contiene potentes posibilidades gráficas. Todos los procedimientos pueden emplearse de una sola ejecución.
SAS ofrece la mayor flexibilidad para personalizar el manejo y análisis de datos; sin embargo, su principal inconveniente es que no resulta fácil aprender a usarlo (16). Para simular modelos dinámicos es necesario programar los algoritmos en lenguaje SAS, solo conocido entre los especialistas matemáticos con entrenamiento en el uso de este sistema.
STATISTICA: es un paquete estadístico usado en investigación, minería de datos y en el ámbito empresarial. Lo creó StatSoft, empresa que lo desarrolla y mantiene. El programa consta de varios módulos; el principal de ellos es el Base, que implementa las técnicas estadísticas más comunes. El paquete puede ser extendido a través de una interfaz con el lenguaje R. Además, se pueden modificar y añadir nuevas librerías usando el lenguaje .NET (16).
MATLAB: es un entorno de computación y desarrollo de aplicaciones totalmente integrado, orientado para llevar a cabo proyectos en los que se encuentren implicados elevados cálculos matemáticos y la visualización gráfica de los mismos. MATLAB integra análisis numérico, cálculo matricial, proceso de señal y visualización gráfica en un entorno completo, donde los problemas y sus soluciones se expresan del mismo modo en que se escribirían tradicionalmente, sin necesidad de hacer uso de la programación tradicional. Está dirigido a ingenieros y científicos; requiere que el operador adquiera conocimientos en su lenguaje de programación (16).
R: es un lenguaje y entorno de programación para análisis estadístico y gráfico. Se trata de un proyecto de software libre, resultado de la implementación GNU del premiado lenguaje S. R y S-Plus-versión comercial de S-. Ambos son, probablemente, los dos lenguajes más utilizados en investigación por la comunidad estadística y, además, muy populares en el campo de la investigación biomédica, la bioinformática y las matemáticas financieras.
A esto contribuye la posibilidad de cargar diferentes bibliotecas o paquetes con finalidades específicas de cálculo o gráfico (16). Al igual que MATLAB, es necesario conocer su lenguaje de programación para su uso.
SISTEMAS MULTIAGENTES
Hoy los Sistemas MultiAgentes (SMA) forman un área de investigación muy activa y se están empezando a utilizar en aplicaciones comerciales e industriales. Los SMA se centran en el comportamiento social de entidades inteligentes y se ocupan, principalmente, de estudiar modelos de comportamiento, estrategias de cooperación y coordinación, optimización del desempeño de tareas, aprendizaje a partir de experiencias propias, formación de coaliciones, etcétera.
El paradigma de la orientación a agentes (17) prescribe un conjunto de estructuras para el estado de un agente y su entorno, por lo que permite simular un modelo de relaciones a partir de su análisis conceptual y matemático
Al tomar en cuenta las dificultades e inconvenientes del uso de los paquetes estadísticos, se plantea la opción de apoyar la modelación utilizando los SMA, debido a las bondades de los mismos para simular el comportamiento de las plagas que se analizarán (18).
Una de las principales arquitecturas en que se están desarrollando los SMA en la actualidad es la Arquitectura Creencias, Deseos e Intenciones (BDI); es una arquitectura deliberativa que se caracteriza por el hecho de que los agentes que la implementan están dotados de estados mentales (19):
Creencias (belief): forma de representar el estado del entorno, lo cual apoyaría el desarrollo de un modelo matemático descrito específicamente para una determinada plaga en un determinado cultivo.
Deseos (desire) u objetivos: representa un estado final deseado. Permite estudiar el estado de equilibrio donde la plaga está por debajo del umbral económico.
Intenciones (intentions): conjunto de caminos de ejecución (threads) que pueden ser interrumpidos de una forma apropiada al recibir información acerca de cambios en el entorno.
Los SMA están siendo muy empleados para simular comportamientos emergentes de sistemas complejos, pues solo exigen que apenas se modelen las entidades básicas que forman el sistema y sus relaciones bajo el supuesto: “El comportamiento colectivo de la población emerge de la interacción entre los individuos” (20).
PASOS A SEGUIR EN LA SIMULACIÓN DE POBLACIONES
El término simulación ha sido interpretado por varios autores desde su formación y conocimiento. A partir de sus inicios se definió como una técnica numérica para la realización de experimentos en un computador digital, con ciertos tipos de modelos lógicos que describen el comportamiento de un sistema económico con el fin de entender el comportamiento del sistema real o evaluar varias estrategias para la operación del sistema (21).
La meta es modelar el mundo real y reducirlo a una estructura más simple (modelo) mediante el uso de la computadora, que corresponde a una representación limitada de la realidad, atendiendo los propósitos claramente definidos para el estudio o la aplicación (21).
De los planteamientos anteriores se adoptó la siguiente definición de simulación: es una herramienta que permite representar, analizar y comprender un sistema o proceso en el mundo real valiéndose de la imitación del mismo en una computadora, a través de un software en el que se realizan pruebas o experimentos a distintos escenarios del sistema, con el fin de analizar los resultados arrojados y obtener así conclusiones que sirvan como apoyo para la toma de decisiones en el sistema real (21).
Mucho se ha escrito sobre las etapas a seguir para realizar una simulación (22); no obstante, la mayoría de los autores coincide que los pasos son:
Definición del sistema: para tener una definición exacta del sistema que se desea simular es necesario hacer, primeramente, un análisis preliminar del mismo, con el fin de determinar la interacción de otros sistemas, las restricciones, las variables, etcétera.
Formulación del modelo: una vez que estén definidos con exactitud los resultados que se esperan obtener del estudio, el siguiente paso es definir y construir el modelo con el cual se obtendrán los resultados deseados.
Colección de datos: es posible que la facilidad de obtención de algunos datos, o la dificultad de conseguir otros, pueda influir en el desarrollo y la formulación del modelo; por consiguiente, es muy importante que se definan con claridad y exactitud los datos que el modelo va a requerir para producir los resultados deseados.
Implementación del modelo en la computadora: con el modelo definido, el siguiente paso es decidir si se utiliza algún lenguaje como Foltran, Basic, algol, etc., o algún paquete estadístico, como SPSS o SAS, para procesarlo en la computadora u obtener los resultados deseados.
-
Validación: es una de las principales etapas de un estudio de simulación. A través de esta etapa es posible detallar deficiencias en la formulación del modelo o en los datos alimentados al modelo. Las formas más comunes de validar un modelo son:
La opinión de expertos.
La exactitud con que se predicen datos históricos.
La exactitud en la predicción del futuro.
La comprobación de falla del modelo al utilizar datos que hacen fallar al sistema real.
La aceptación y la confianza en el modelo de la persona que hará uso de los resultados que arroje el experimento de simulación.
Experimentación: la experimentación con el modelo se realiza después que este ha sido validado. Consiste en generar los datos deseados y en realizar análisis de sensibilidad en los índices requeridos.
Interpretación: en esta etapa se interpretan los resultados que arroja la simulación y, sobre la base de esto, se toma una decisión.
Documentación: dos tipos de documentación se requieren para hacer un mejor uso del modelo de simulación. La primera es del tipo técnico, es decir, a la que el departamento de procesamiento de datos debe tener del modelo. La segunda referida al manual de usuario, con el cual se facilita la interacción y el uso del modelo desarrollado, a través de una terminal de computadora (22).
EXPERIENCIA DE CUBA EN LA MODELACIÓN Y SIMULACIÓN DE LA DINÁMICA DE POBLACIONES
Dada la experiencia alcanzada por los investigadores cubanos en la simulación (23) y modelación (24) de la dinámica de poblaciones, son varios los resultados en esta materia; entre ellos vale destacar el empleo de modelos, como el de Lotka-Volterra de competencia interespecífica (25), para el estudio de diferencias en la abundancia de plagas en cultivos de interés económico (26) o los modelos no lineales para estimar parámetros epidemiológicos (27).
Además, se evidencian los avances en la modelación de interacciones hospedante-parasitoide (28); estos modelos logran simular con mayor exactitud el crecimiento de ambas poblaciones, al incluir las tasas intrínsecas de incremento en condiciones de campo, mediante el empleo de métodos de regresión paramétrica y no paramétrica (29).
Cabe destacar también los resultados en la modelación de interacciones tritróficas cultivo-plaga-agente de control biológico (11), que constituyen los modelos más usados para la simulación de dinámica de poblaciones.
Una de las tendencias que está tomando fuerza en los últimos años es el empleo de métodos estadísticos flexibles, como son el Modelo de Efectos Aditivos e Interacción Multiplicativa (AMMI) (30,31), para evaluar la resistencia de los cultivos.
CONCLUSIONES
A pesar de los logros alcanzados en materia de simulación y modelación matemática, y que los diferentes modelos existentes permiten, entre otras funcionalidades, simular la dinámica de poblaciones y se pueden elaborar otros en correspondencia con los cambios en el ecosistema o agregando nuevas variables, todavía son insuficientes el estudio de todas las bondades que brindan estos modelos, así como trabajos que representen bibliografía para futuros investigadores.
En este sentido, el apoyo que pudieran suponer los paquetes estadísticos convencionales se reduce, ya que la mayoría son privativos o su complejidad en lenguaje de programación dificulta la utilización de los mismos, lo que los convierte en una solución poco recomendable.
Teniendo esto en cuenta, los Sistemas MultiAgentes suponen un aliciente para el desarrollo de modelos, pues presentan una arquitectura de programación que permitirá simular sistemas complejos como es el cultivo-plaga-agente de control biológico, de manera fácil y agradable, ya que no se precisa un alto nivel de conocimiento de programación y son totalmente libres.
Por lo tanto, el desarrollo de modelos para la simulación de la dinámica de poblaciones, apoyados en Sistemas MultiAgentes, constituye en la actualidad la mejor apuesta para alcanzar logros significativos en esta materia.

