










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Un nuevo coronavirus, anteriormente llamado Síndrome Respiratorio Agudo SeveroCoronavirus 2 (SARS-CoV-2), ahora oficialmente llamado por la Organización Mundial de la Salud (OMS) Enfermedad por coronavirus 2019 (COVID-19), causó un estallido de una atípica neumonía, primero en Wuhan, provincia de Hubei, en diciembre del 2019 y luego se extendió a más de 180 países del mundo con más de 5 millones de casos 1 en poco tiempo, debido a que era contagioso. El virus puede causar la muerte de personas de todas las edades, particularmente aquellas con enfermedades crónicas o personas mayores. 2 El nuevo Coronavirus (COVID-19) ha sido clasificado por la OMS como una emergencia en salud pública de importancia internacional la cual posteriormente el 11 de marzo del 2020 lo consideró como una pandemia global.3
Esta pandemia ha afectado a comunidades y economías sin precedentes en todo el mundo. Los países tardan en tomar una serie de medidas para detenerla, y sus capacidades de atención médica actuales son insuficientes para tratar a los pacientes, (2) aunque cada país ha respondido o está respondiendo a la misma amenaza con diferentes medidas y/o con una temporización diferente. Este hecho hace que las curvas epidemiológicas de los países afectados se estén comportando de manera distinta y que el costo social y económico de las respectivas respuestas pueda ser diferente 3
Durante esta batalla anti epidémica, al lado de médicos y la investigación biológica, los estudios teóricos basados en modelos estadísticos o matemáticos pueden también jugar un papel para nada despreciable en el entendimiento de las características de la epidemia, para la predicción del punto de inflexión, el tiempo final, 4 futuro crecimiento potencial 5), ayuda para estimar el riesgo a otros países6 y en decidir las medidas que contribuyan a frenar la propagación de la enfermedad.4
La estimación de los cambios en la transmisión a través del tiempo puede proveer una comprensión dentro de la situación epidemiológica,7 y la estimación identifica si las medidas de control están teniendo un efecto deseado.8,9
El empleo de modelos estadísticos predictivos en las ciencias de la salud ha crecido significativamente en los últimos años. Estos emergen como un vínculo importante entre la estadística y la práctica médica; son de gran ayuda en la toma de decisiones y permiten la creación de diversos sistemas y herramientas útiles para reducir las incertidumbres, garantizar mejores actuaciones y establecer eficaces medidas de control para la erradicación de las enfermedades10 Los análisis de las predicciones pueden informar acerca del futuro crecimiento potencial 5 y ayuda a estimar el riesgo a otros países. 6)
Se han estado utilizando modelos estadísticos predictivos para las predicciones de la probable evolución de la COVID-19, entre los que se puede encontrar: Modelo de media móvil, integrado regresivo automático (ARIMA), y métodos de suavizado exponencial lineal de Brown / Holt.2,3,11
El objetivo de este trabajo es realizar un análisis de modelación estadística y de pronóstico, combinando 6 modelos para predecir los casos positivos diarios, activos y fallecidos por COVID-19 en Cuba.
Métodos
Se construyeron los modelos usando como datos los reportes estadísticos diarios de los casos positivos, casos activos y fallecidos a la COVID- 19 reportados en el sitio web de CUBADEBATE 12 en el período comprendido desde el 11 de marzo al 25 de mayo. Estos datos fueron utilizados para la estimación y el pronóstico de la aparición de casos positivos diarios, activos y fallecidos por COVID-19 en Cuba hasta el día 22 de julio.
Los casos activos constituyen el total de personas diagnosticadas con la enfermedad hasta ese momento (los “confirmados”), que se le sustrae la cifra de quienes la padecieron y se recuperaron y todos los que fallecieron.
Los datos utilizados fueron procesados y analizados usando Microsoft Office Excel 2016 y el software estadístico STATGRAPHICS. Centurion. XV versión 15.2.14 con un ajuste de raíz cuadrada a los modelos: A: Promedio móvil simple de 2 términos, B: Suavización exponencial simple con alfa = 0.4888, C: Suavización exponencial de Brown con alfa = 0.235, D: ARIMA (2,0,0) con constante. El modelo E ARIMA (2,0,1) x (1,0,0)14 con constante se ajustó por el método de Box Cox con una estacionalidad de 14 y el F: ARIMA(1,1,6) sin ajuste.
Promedio móvil simple de 2 términos
Método para obtener pronósticos o para suavizar una serie de tiempo, en el que como pronóstico para cada periodo siguiente se usa el promedio de los valores de los n (tamaño del subgrupo) datos más recientes de la serie de tiempo. (13) El promedio se “mueve” en el tiempo, en el sentido de que, al transcurrir un período, la demanda del período más antiguo se descarta y se agrega, en su reemplazo, la demanda para el período más reciente, superando así la principal limitación del modelo del promedio simple. 14 Este método considera la media de los datos más recientes, dependiendo del marco de tiempo del fenómeno.
Métodos de suavizado exponencial lineal simple
Se distingue porque da pesos de manera exponencial a cada una de las demandas anteriores de calcular el promedio. La demanda de los períodos más recientes recibe un peso mayor; los pesos de los períodos sucesivamente anteriores decaen de una manera no lineal sino exponencial. 14 El cálculo correspondiente al método de suavización exponencial requiere de dos componentes: el primero es la demanda real del período más reciente. El segundo es el pronóstico más reciente obtenido por este mismo método, es decir el dato pronosticado.
(14)
Estos métodos dan pesos decrecientes a las observaciones pasadas y, por lo tanto, cuanto más reciente sea la observación, mayor será el peso asociado. Este marco permite generar estimaciones confiables rápidamente en la mayoría de las aplicaciones. 14
Suavización exponencial de Brown
Produce una serie de datos suavizada a partir de una serie de datos históricos, ya que la nueva serie está constituida por promedios de valores de la serie original. Es muy importante fijar de manera correcta el parámetro alpha, entre 0 y 1. Si los datos presentan fuertes fluctuaciones o gran aleatoriedad se deben usar valores de alpha cercanos a 0; es decir, que si el parámetro de suavización alpha está próximo a cero, el valor inicial de la serie influirá durante muchos períodos de tiempo. Si alpha tiene valores próximos a uno, desaparecerá rápidamente la influencia del valor histórico. El modelo puede emplearse en series con tendencia, pero sin estacionalidad. (14
Modelo de media móvil integrado regresivo automático (ARIMA)
Modelos paramétricos que tratan de obtener la representación de la serie en términos de la interrelación temporal de sus elementos. Es ampliamente utilizado para series de análisis temporales. Incluye modelos ARIMA aplicados a las series que no son estacionarias pero que se hacen estacionarias con la operación de diferencia de la serie. El método se basa en elegir un modelo ARIMA que incluya el parámetro más adecuado pero limitado entre las diferentes opciones de modelo, dependiendo de la naturaleza de los datos considerados. (14)
Los modelos ARIMA (p, d, q) se obtienen tomando la diferencia de series de (d)grados y agregando al modelo ARMA (p,q) para el proceso de estabilización. En los modelos
ARIMA (p, d, q), p es el grado del modelo autorregresivo (AR), q es el grado del modelo de promedio móvil (MA) y d representa cuántas diferencias se requieren para hacer estacionaria la serie.14)
Procesamiento de los datos
A los modelos estadísticos propuestos (A, B, C, D, E y F) se les comprobó si eran adecuados para los datos, realizándoles cinco pruebas estadísticas: Corridas excesivas arriba y abajo (RUNS), corridas excesivas arriba y abajo de la mediana (RUNM), Box-Pierce para autocorrelación excesiva (AUTO), diferencia en medias entre la 1rª mitad y la 2dª mitad (MEDIA), diferencia en varianza entre la 1rª mitad y la 2dª mitad (VAR). Luego se les calculó a los modelos propuestos el desempeño de estos mediante: el error absoluto medio (MAE), la raíz del error cuadrado medio (RMSE), el error medio (ME) y el ( MAPE),porciento de error absoluto medio para elegir los modelos de mejor pronóstico. Se les realizó la prueba de residuales calculándose la función de autocorrelación regresiva y función de autocorrelación regresiva parcial para conocer si son estacionarios (margen de error en los pronósticos). Los resultados obtenidos se visualizaron mediante gráficas y tablas.
Resultados
Se procesaron los casos positivos a la COVID-19 en Cuba con los 6 modelos estadísticos propuestos (A, B, C, D, E y F).
Las pruebas estadísticas (RUNS, RUNM, AUTO, MEDIA, y VAR) realizadas a los seis modelos propuestos (A, B, C, D, E y F) dieron como resultados que los 6 pasan las cinco pruebas. Puesto que ninguna prueba seleccionada es estadísticamente significativa con un nivel de confianza del 95 % o más, los 6 modelos probablemente sean adecuado para describir los datos.
La tabla 1 resume el desempeño de los modelos en ajustar datos históricos.
Cada uno de los estadísticos está basado en los errores de pronóstico uno-adelante, los cuales son las diferencias entre los datos al tiempo t y el valor pronosticado al tiempo t-1. Los primeros tres estadísticos miden la magnitud de los errores. El último estadístico mide el bias que sugiere la magnitud del sesgo en la predicción de datos futuros.
Tabla 1 Resultados de los cálculos del desempeño para los Modelos estadísticos propuestos
| : Promedio móvil simple de 2 términos | 10,45 | 6,95 | - | 0,40 |
| B: Suavización exponencial simple con alfa = 0.6034 | 10,40 | 7,18 | - | 0,19 |
| C: Suavización exponencial de Brown con alfa = 0.2497 | 10,28 | 6,99 | - | -0,45 |
| D: ARIMA (2,0,0) con constante | 10,31 | 6,88 | - | 0,98 |
| E: ARIMA(2,0,1)x(1,0,0)14 con constante | 13,59 | 8,76 | 5,24 | 0,25 |
| F: ARIMA (1,1,6) | 1,05 | 0,75 | 7,61 | 0,12 |
El modelo que posee el menor valor de RMSE para el comportamiento de los casos positivos diarios es el modelo C con valor de 10.28 que indica la desviación estándar de los errores de pronósticos, lo que significa que este modelo tiene la mejor precisión. Por otro lado, los modelos A B, C y D presentan valores de ME por debajo de 1 indicando el posible menor sesgo en la predicción. A los modelos A, B, C y D no se les reportó el estadístico MAPE al ser valores por debajo de cero.
En el caso de los modelos E y F usados para la describir el comportamiento de los casos activos y fallecidos respectivamente, se usó para evaluar su precisión el valor de MAPE. Ambos modelos tienen una buena precisión al tener valores de MAPE por debajo del 10 %. El valor de ME para ambos modelos estuvieron por debajo de 1, lo que indica un sesgo aceptable en el pronóstico de datos futuros.
En la figura 1 se muestran las autocorrelaciones estimadas entre los residuos a diferentes retrasos. El coeficiente de autocorrelación con retraso k mide la correlación entre los residuos al tiempo t y al tiempo t-k. El coeficiente de autocorrelación parcial al retraso k mide la correlación entre los residuos al tiempo t y al tiempo t+k, habiendo descontado por la correlación a todos los retrasos menores.

Fig. 1 Gráfico de los residuos (1.1) y residuos parciales (1.2) de los modelos estadísticos (A,B,C,D,E,F).
Se pueden utilizar ambos gráficos para juzgar el orden del modelo autoregresivo necesario para ajustar los datos. En este caso, ninguno de los 24 coeficientes de autocorrelación residuales de los 6 modelos son estadísticamente significativos. En la función de autocorrelación parcial residual los modelos C y E solamente un coeficiente de la función de autocorrelación parcial se pasó de los límites al 95 % de confianza. Con lo anterior expuesto las series de tiempo de cada modelo bien pudieran ser evaluadas como estacionarias y tener un buen ajuste.
En la figura 2 se representan los modelos pronósticos para los casos diarios positivos a modo de comparación entre ellos.
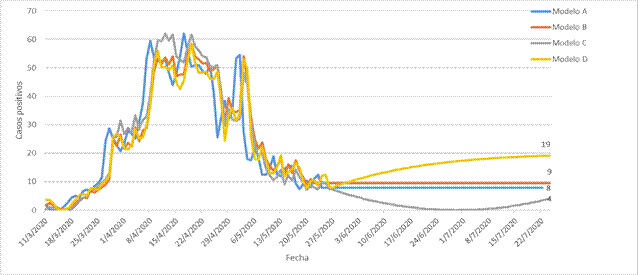
Los modelos A y B dan una tendencia constante de 8 y 9 casos respectivamente para el día 22 de julio. El modelo C indica una ligera disminución de los casos con 4 ese mismo día, y el modelo D una tendencia al aumento con 19 casos. El gráfico muestra que no se puede confiar y que pudiera haber un pequeño repunte de la enfermedad si se relajan las medidas tomadas.
La figura 3 muestra la comparación entre valor del promedio de pronósticos de los modelos (A, B, C y D) con los casos positivos reales diarios.
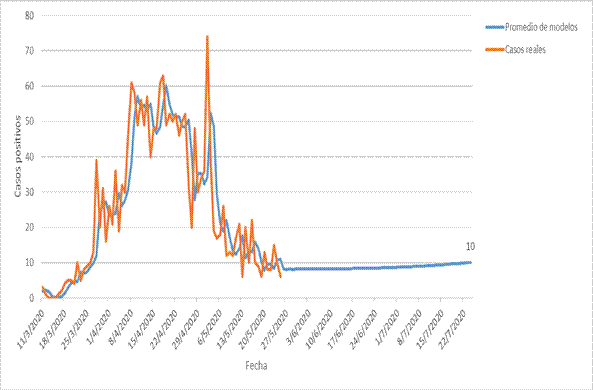
En ella se aprecia la buena concordancia entre lo real y lo predicho entre los dos modelos.
El promedio de los modelos indica una tendencia constante de 10 casos el día 22 de julio. Estos análisis indican que los contagios diarios en nuestro país pueden ser constantes hasta esa fecha, y el virus ser endémico.
La figura 4 muestra el comportamiento de los casos activos y fallecidos en Cuba. En él se compara los valores de los casos reales activos con los valores pronosticado por el modelo E y el número total de fallecidos con los valores pronosticados por el modelo F.
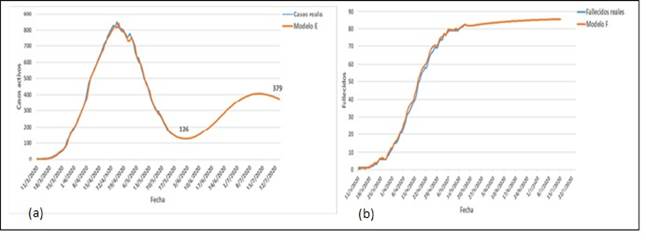
Fig. 4 Comportamiento de (a) casos activos para el modelo E y (b) total de fallecidos para el modelo F.
En la figura (a) se observa una buena relación entre los casos activos reales y lo predicho por el modelo E. Se refleja un mínimo de 126 casos el día 3 de junio y luego un aumento de los casos hasta alcanzar el 22 de julio un valor de 374 casos activos hospitalizados. Es de destacar que en este modelo se usó una estacionalidad de 14 días. Eso se debe a que es el período mínimo de hospitalización de los casos positivos a la COVID-19 en Cuba.
En el caso de los fallecidos, en la figura 4 (b) se aprecia una tendencia a mantenerse constante el número de fallecidos por encima de 80 casos en la primera quincena de julio.
Discusión
La enfermedad COVID-2019 ha sido reconocida como una amenaza global, en la cual ha se han estado usando en todo el mundo modelos predictivos para la tendencia epidemiológica del predominio e incidencia de esta, siendo alguno de los modelos utilizados: Suavización exponencial de Brown usado en Rusia,2 y modelos de series de tiempo (ARIMA) empleado en Turquía, Alemania, Francia,2 Italia, Tailandia, China, Corea del Sur e Irán.15
En este trabajo se emplearon 6 modelos estadísticos en el que los resultados fueron muy cercanos a los obtenidos por varios países. Teniendo como novedad en este trabajo que el modelo E se construyó usando una estacionalidad de 14.
Los pronósticos obtenidos son favorables, destacándose el bajo valor del estadístico MAPE para el modelo E con un valor de 5.24 para modelos ARIMA por debajo de reportados por HANUR JONAR2 y colaboradores que reportaron un valor de 6.38 para describir la epidemia en Alemania .
Si bien no podemos evitar por completo las consecuencias de largo alcance de esta pandemia viral, el modelado que se emplea debe ser capaz de predecir qué esperar, cómo prepararse y manejarlo, siendo la relevancia de todos estos modelos las predicciones de la cantidad de personas que pueden estar infectadas por la enfermedad, un indicador fundamental para el sistema de salud que constituye el eslabón fundamental para la toma de decisiones gubernamentales en el enfrentamiento a la pandemia.
Para la predicción del comportamiento de los casos diarios positivos, activos y fallecidos por COVID-19 en Cuba, se realizó el análisis de modelación estadística y de pronóstico, a los 6 modelos estadísticos propuestos, los cuales cumplieron con los requerimientos de acuerdo a las pruebas estadísticas (RUNS, RUNM, AUTO, MEDIA, y VAR).
El modelo que posee la mejor precisión fue el modelo C con un valor de RMSE de 10.28 para el comportamiento de los casos positivos diarios. Los modelos A B, C y D presentan valores de ME por debajo de 1 indicando el posible menor sesgo en la predicción. En el caso de los modelos E y F los valores de MAPE. estuvieron por debajo del 10 %.
Todos los modelos pasaron la prueba de autocorrelación residual demostrando que las series de tiempo de los modelos pudieran ser evaluada como estacionarias.
Los 6 modelos estadísticos estudiados cumplen con los requerimientos de acuerdo a las pruebas estadísticas, de desempeño, y residuales calculadas para ellos.
Los datos obtenidos de los modelos predictivos fueron útiles porque proporcionan un pronóstico para la epidemia de COVID-2019, lo que representa una herramienta válida y objetiva para monitorear el control de infecciones. Todas las instituciones involucradas en la Salud Pública y el control de infecciones pueden beneficiarse de estos datos porque al usar estos modelos, pueden construir diariamente un pronóstico confiable para la epidemia de COVID-2019.

