










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
En la actualidad una de las más importantes fuentes de generación de energía eléctrica es la energía solar fotovoltaica, clasificada en el campo de las energías limpias y renovables. La dependencia que tiene la energía eléctrica generada en un parque fotovoltaico de las condiciones meteorológicas, y la alta variabilidad de estas, hacen que el problema de la predicción de la energía generada en el mismo sea una labor compleja [1].
No obstante, está demostrado la necesidad de estimar la producción de energía eléctrica por esta vía dado lo que significa para la correcta planificación y estabilidad del sistema eléctrico. Con ello se logra un aumento del nivel de penetración del sistema fotovoltaico masi como reduce el costo de mantenimiento de los dispositivos auxiliares. Por lo tanto los sistemas de predicción de la generación eólica se fortalecen para contribuir a este objetivo. Además, es una acción de gran importancia y ayuda a los operadores y diseñadores del sistema de energía a modelar y gestionar las plantas solares fotovoltaicas de manera eficiente [2].
Actualmente se trabaja intensamente en la aplicación de herramientas de la Inteligencia Artificial (IA) para el desarrollo de estos tipos de modelos, basado en la demostrada capacidad de estas técnicas en el manejo de información contenida en grandes volúmenes de datos obtenidos de los sistemas objeto de trabajo. Se presentan en la literatura especializada varios métodos de resolver este problema. Algunos usan métodos de predicción indirecto de la potencia fotovoltaica generada, que se basa en realizar la predicción de algunos parámetros meteorológicos (fundamentalmente la irradiación solar) y posteriormente a partir de estas predicciones y mediante un modelo de la planta fotovoltaica que generalmente es un modelo paramétrico, realizan la predicción de la potencia fotovoltaica generada. Se ha trabajado en aplicación de redes de gran memoria a corto plazo (LSTM por sus siglas en inglés) [3], para la predicción de la irradiación solar del día siguiente usando como variables de entrada la temperatura, la velocidad del viento, entre otras.
Se obtiene un error cuadrático medio inferior a 19 %. Otros métodos aplican una metodología espacio-temporal para pronosticar la producción de energía de una planta específica [4, 5]. Obteniéndose un error medio normalizado de un 20 % en promedio. Otros métodos también proporcionan predicciones con similares índices de exactitud. El método basado en ejes de regresión adaptativa [6]. Se ha aplicado un modelo de regresión de vectores de apoyo(SVR por sus siglas en inglés) para predecir la potencia de una planta fotovoltaica para un horizonte de tiempo de corto plazo de 15 minutos hasta 5 horas [7]. Utiliza como entradas mediciones de potencia fotovoltaica y pronóstico de la irradiancia solar. El modelo es capaz de generar buenas predicciones para condiciones de cielo claro y nublado con un valor del RMSE menor de 15%. Se han desarrollado métodos plazo basados en diversas estructuras de redes neuronales artificiales y la lógica difusa, en el cual se usa como variables de entrada la temperatura, el punto de rocío, la velocidad y dirección del viento y la irradiación solar.
En algunos casos con muy buenos índices de exactitud, por ejemplo 10% de error medio absoluto [8], otros con indicadores menos favorables con error medio absoluto de 30 % [9]. En específico existen varias referencias de uso de LSTM en sistemas de predicción de potencia fotovoltaicas, con distintos valores de índices de exactitud; 21% de error medio cuadrático [10]; 11, 8 % de error medio absoluto [11]; con redes neuronales de convolución profunda, 12% de error medio absoluto [12]. Dando continuidad a esta labor reflejada en estas referencias en este trabajo se aplican las técnicas basadas en redes LSTM y redes de convolución con aprendizaje profundo (LSTM y CNN) para realizar la predicción directa de la potencia fotovoltaica generada utilizando solamente un conjunto de mediciones históricas de las plantas analizadas.
Este trabajo se diferencia de los anteriores en la metodología utilizada y en la estructura del modelo predictivo que se propone para realizar la predicción de la potencia fotovoltaica generada, sin necesidad de disponer de predicciones de modelos meteorológicos o de otros modelos de predicción. También se diferencia en la estructura y el tratamiento de los datos históricos recopilados. Además, el método de predicción propuesto permite obtener resultados satisfactorios en cuanto a la calidad de las predicciones realizadas.Todo el trabajo realizado ha estado enmarcado y forma parte del proyecto “Perfeccionamiento del sistema de pronóstico energético para plantas eólicas y fotovoltaicas conectadas el sistema eléctrico nacional”, proyecto perteneciente al Programa Nacional de Ciencia y Técnica Desarrollo Energético Integral y Sostenible.
Desarrollo
Se desarrolla esta experiencia de predicción a un conjunto de 23 plantas fotovoltaicas, ubicadas en diferentes zonas del país. El método general empleado es:
Obtención de todos los datos históricos en un periodo de 2 años de las principales variables en todas las plantas en donde se empleará el método de predicción. Variables: Irradiancia, Temperatura ambiente, potencia generada.
Caracterización y preprocesamiento de los datos históricos en un periodo de 2 años. Variables: Temperatura ambiente, potencia generada. Eliminación de valores anormales y completamiento.
Aplicación del método LSTM/CNN desarrollado para la predicción de generación fotovoltaica [13]
Postprocesamiento de los resultados de la predicción.
Comparación con los métodos actualmente empleados.
A continuación se presentan el desarrollo de estos aspectos.
Caracterización de los datos
Durante el desarrollo de este trabajo, se encontró que la calidad de los datos reales obtenidos de las plantas no era buena, presentando valores faltantes y algunos valores que no tenían sentido, lo que podía afectar negativamente la precisión de la predicción. Para abordar este problema, se implementaron varios métodos de pre procesamiento de datos para mejorar la calidad de los datos y hacerlos más útiles para la predicción.
Mediante el análisis de los datos se evidencia que estos presentan anormalidades en sus valores numéricos y faltantes de datos, por lo que se eliminaron los días en que las mediciones se encontraban completamente en cero, y a los datos que presentaban problemas locales (ej. alguna temperatura en cero, algún valor de irradiación por encima de lo normal) se estimaron mediante la función de MatLabmisdata [14].
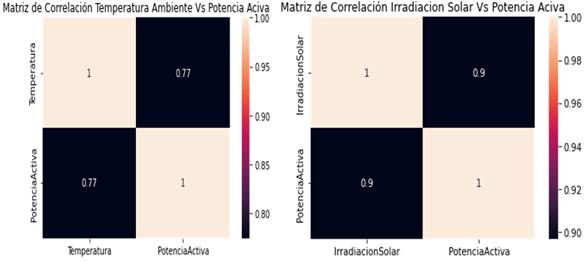
Debido a que la irradiación solar (variable principal de entrada al modelo) es nula en horas de la noche, al igual que la variable potencia activa (salida del modelo), se decidió tomar doce horas del día en las cuales estas variables presentaban una dinámica no nula. Se corrobora que la principal correlación de la potencia generada es con irradiación y con temperatura de los módulos, lo cual se aprecia en la figura 1, [14].
Una vez en el System Identification Toolboox del Matlab los datos fueron preprocesados, removiendo tendencias y eliminando medias, además fueron divididos en dos conjuntos de datos; 75% para identificación y 25% para la validación del modelo.
Los datos fueron organizados de la siguiente forma atendiendo a la estructura del modelo:
La transformación de los datos primarios se realiza en varias etapas de preprocesamiento:
Eliminación de los atributos que no aportan información relevante
Sustitución de valores inconsistentes (nulos y no numéricos) por el valor promedio del atributo al que correspondiera
Normalización de los valores
Se emplearon tres métodos para este procesamiento:
Reemplazar los datos faltantes por los promedios de los días anteriores. Calcular los promedios en cada una de las horas, que luego se utilizan para reemplazar los valores ausentes en el conjunto de datos.
Como inicio al proceso de explotación de los modelos seleccionados se tuvo que conformar un conjunto de entrenamiento, para el cual se tomaron datos de la fecha, la irradiación solar, la temperatura ambiente, la temperatura del módulo y la potencia real para cada una de las horas necesarias que van desde las 7:00:00 am hasta las 18:00:00 pm. De esta forma, se creó un conjunto de entrenamiento para cada uno de los parques seleccionados, los cuales se eligieron teniendo en cuenta la calidad de los datos dados en cuanto a cantidad de valores faltantes.
Una vez conformados los conjuntos de entrenamiento se entrenaron modelos por cada uno de los parques y se guardaron dichos modelos una vez entrenados para luego ser usados en la realización de las predicciones. Como principal conclusión de la implementación de los programas de preprocesamiento se obtiene una significativa mejoría de la calidad de los datos y la precisión de la predicción. Estos resultados demuestran la importancia de la calidad de los datos y la implementación adecuada de métodos de pre procesamiento de datos en proyectos de aprendizaje automático y análisis de datos.
Modelo de predicción
Los principales parámetros de cada modelo implementado se resume en las tablas 1 y 2, respectivamente
Tabla 1 Parámetros del modelo LSTM
| Parámetros del modelo | Descripción |
|---|---|
| Número de capas | 4 |
| Neuronas en la primera capa | 64 |
| Neuronas en la segunda capa | 32 |
| Neuronas en la tercera capa | 19 |
| Neuronas capa de salida | 1 |
| Función de activación capa salida | Lineal |
| Tasa de aprendizaje inicial | 0.01 |
| Función objetivo | mse |
| Optimizador | |
| Épocas de entrenamiento | 30 |
| Tamaño del lote | 256 |
Tabla 2 Parámetros del modelo CNN
| Parámetros del modelo | Descripción |
|---|---|
| Capa Conv1D | Filters =50, kernel_size = 20 |
| Capa Maxpooling1D | Pool_size = 2 |
| Capa Dense | 50 neuronas |
| Capa Dense | 1 neurona |
| Función de activación | RELU |
| Tasa de aprendizaje inicial | 0.01 |
| Función objetivo | mse |
| Optimizador | |
| Épocas de entrenamiento | 200 |
| Tamaño del lote | 256 |
Evaluación del programa de predicción
La evaluación del programa de predicción se comenzó en el mes de febrero 2023 aplicando el programa a la predicción de generación de varias plantas (3 plantas inicialmente y luego se extendió a 23 plantas). El programa toma los datos 14 días anteriores a la fecha actual Con estos datos, preprocesados previamente, se forma un conjunto de datos cuyas columnas son: fecha, irradiación, temperatura del módulo, temperatura ambiente y la potencia generada, en cada una de las horas usadas (de las 07:00:00 a las 18:00:00). Una vez pasados los datos, al modelo del parque correspondiente, éste devuelve las predicciones de los 14 días posteriores, de las cuales solo se toman las del día deseado (día siguiente al día actual), esto se repite para cada uno de los parques de los cuales se cuenta con modelos y luego se pasan dichas predicciones a un documento csv.
Se confeccionó un programa para la lectura de este fichero Excel, el cálculo del error medio porcentual de estimación en cada dia y por cada hora, usando la ecuación (1):
 (1)
(1)
Se calcula además el error medio en el día, promediando el error (valor absoluto) obtenido en cada una de las horas del día.
Resultados
En las siguientes figuras se muestran los resultados obtenidos para la predicción de la generación para los primeros 20 días del mes de agosto de este año 2023, para tres de las 23 plantas analizadas. En la figura 2, se compara la predicción básica que de la potencia generada realiza el modelo, comparada con los valores reales, para las distintas horas prácticas o útiles, o sea de 7.00 a las 18.00 horas. Como se aprecia existe una diferencia notable entre la predicción básica y los valores reales, lo cual justifica el necesario postprocesamiento de estas predicciones. Como criterio para la estimación de la corrección se usó el propio error obteniéndose la ley de comportamiento del mismo, la cual se muestra en la figura 3.
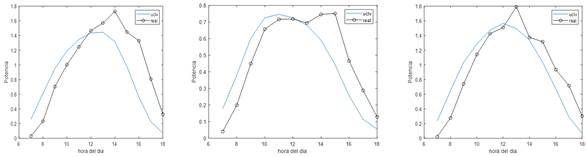
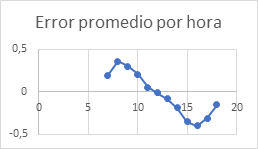
Considerando el comportamiento del error de predicción como variable de ajuste en el modelo, retroalimentando la misma, en el modelo de convolución se obtiene una nueva predicción, o predicción ajustada, la cual se muestra en la figura 4, para estas mismas plantas.

Se puede apreciar la significativa mejoría en la predicción. En la figura 5 se muestra como es el error de predicción (en unidades de potencia generada) para esta predicción ajustada. Se aprecia que se cumple que para la primera mitad del dia la predicción es superior al valor real, invirtiéndose esta relación en la segunda mitad del dia, En todos los casos se aprecia que el error está por debajo de 0.1 MW para prácticamente todo el día. Si consideramos que 1 MW es un valor estándar para la generación de cualquiera de esta plantas, entonces el error relativo obtenido está en el orden del 10 % lo cual es comparable y en algunos casos mejor que los métodos presentados en la literatura. Particularmente se analiza continuación el error relativo que se presenta en las horas centrales del día útil, o sea entre las 10.00 y las 14.00 horas.En la figura 6 se muestra el error para estas horas. Aplicando el programa y método de predicción en el resto de las plantas analizadas se obtienen similares resultados, por lo que se concluye la validez y generalidad del método


Conclusiones
El método desarrollado, hasta donde está ajustado en la parte del preprocesamiento de los datos para el aprendizaje y el postprocesamiento tiene un comportamiento en general similar al actualmente empleado, con una marcada mejoría en las horas centrales del día (las de mayor generación de potencia). Esto motiva la conclusión que el método es factible de aplicarse a gran escala como un segundo método de predicción en plantas fotovoltaicas del país. Estos resultados de la evaluación indica además la necesidad de continuar mejorando el postprocesamiento de la predicción.

