










 Servicios personalizados
Servicios personalizados Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCTION
Demand forecasting can be summarized as an estimation of a supply chain constituent’s (such as warehouse and end sale point) expected sales during a specified future period (Islek and Oguducu, 2017). Forecasts are a tool that provide a quantitative estimate of future events (Contreras et. al., 2016) and constitute a fundamental input into decision-making processes (Rojo, Carvajal and Velásquez, 2015; Kourentzes and Petropoulos, 2016). Making accurate forecasts offers various benefits to companies, improves their production plans (Vitri, 2014), reduces rebates and product wastage (Derks, 2015) and is a key factor for business competitiveness (Slimani et al., 2015).
Forecasting future values is an important topic applied in areas such as economics, production planning, sales, inventory control, in data centers and for the supply of water and electricity (Ponce, 2017; Tugay and Gündüz, 2017). In the literature consulted, we identified that in the last five years there has been a predominance of research on the application of forecasting models to predict phenomena such as: electricity demand (Winter et al., 2015; Gil, 2016; Oscullo and Haro, 2016; Berk, Hoffmann and Müller, 2018), water demand (González et al., 2016; Dariane and Azimi, 2016), the demand for spare parts (Matsumoto and Ikeda, 2015; Martinov et al., 2015; Morales, 2016; Hemeimat et al., 2016; Ponce, 2016), river flows (Rojo, Carvajal and Velásquez, 2015), plant and crop blooms (Álvarez and Salazar, 2015 and Salazar et al., 2018), drug demands (Kim et al., 2015; Lao et al., 2017) among other phenomena. There are also various forecasting studies conducted in the manufacturing retail sector (Vitri, 2014; Derks, 2015; Slimani et al., 2015; Ma, Fildes and Huang, 2016), to predict food demand (Eksoz et al., 2014; Sivanandam and Ahrens, 2015; Pereira et al., 2016), beverages (Kourentzes and Petropoulos, 2016; Kazeem et al., 2016), and fashion pieces (Choi et al., 2014; Ferreira et al., 2015). Accuracy in making forecasts is essential in decision-making processes, so developing efficient and effective forecasting models is a challenge (Sulandari and Yudhanto, 2015).
The food market has a high impact on the economic development of a specific area, region or country and determines its level of food security (Pavlovna and Grigorievna, 2015). One of the biggest challenges in this market is to adjust production and stocks to minimize product losses due to their short duration (Barbosa, Christo and Costa, 2015). Research in the field of predictions of food demand and sales is abundant, however, its number is lower compared to other fields of application (Sivanandam and Ahrens, 2015). Moreover, there is no universal forecast model with a precise yield applicable to all the problems of reality, this condition causes the need to investigate more suitable models for each specific situation or phenomenon (Ponce, 2016; Pereira et al., 2016; Aras et al., 2017).
This research aims to analyze forecasting models and techniques to determine the demand for perishable food products in small and medium sized food retail business. Small and medium-sized enterprises (SMEs) have economic, structural and organizational characteristics that put them at a disadvantage compared to large corporations (Erum, Rafique and Ali, 2017). In addition, SMEs make up the majority of the global business sector and constitute an important source of employment and income, primarily for developing economies (Gutiérrez and Nava, 2016).
Emerging economies suffer structural changes more frequently than developed economies, making it difficult to make accurate forecasts (Aye et al., 2015; Ghalehkhondabi et al., 2017). To be successful in business, companies operating in these economies must quickly adjust to these changes, predict market events, and anticipate customer needs (Aras et al., 2017). The application of accurate forecasting models in small and medium enterprises engaged in the marketing of food of short duration, will contribute to raise their economic profits, increase their competitiveness in the market and the economic development of the region or country where they live.
We identified five review articles in the research: four on electricity demand forecasts (Kumar, et al., 2013; Qamar and Khosravi, 2015; Estupiñan et al., 2016; Ghalehkhondabi et al., 2017) and one on perishable food demand forecasts (Eksoz et al., 2014). In his research Eksoz et al. (2014), makes a theoretical approach based on a review of the literature about problems in collaboration between partners in a supply chain. His study does not contemplate the application of forecasting models in small and medium business environments.
METHOD OF ANALYSIS
This research constitutes a systematic review of the literature on the main models and techniques for forecasting the demands for products or services. The analysis focuses on forecasts of perishable food demand in small and medium-sized enterprises. Literature Systematic Reviews are secondary and integrative scientific research studies that provide a reliable, valid and up-to-date summary of the best available scientific evidence on a given topic (Ramírez, Meneses and Floréz, 2013). These revisions make it possible to improve the knowledge base on a given topic (Eksoz et al., 2014).
We use to search information the Google Scholar (GS) database, because according to Gehanno, Rollin and Darmoni (2013) is very sensitive, easy to investigate and could be the first option for systematic reviews or meta-analysis. Shah, Mahmood and Hameed (2017), emphasize that GS is superior to its likes Scopus and Web of Science because it is a free search engine, geographically neutral and encompasses a lot of information.
The literature consulted includes journal articles, conferences, master’s and doctoral thesis in English and Spanish. We made the selection of the bibliography through an inclusion and exclusion process where it was guaranteed that there were no duplicate bibliographic sources. This process was realized in two fundamental steps: the first step made it possible to select those sources with titles and abstracts linked to the research topic with a publication date between 2013 and 2018. In a second moment only the literature was selected that allowed its consultation in an integral and free way. A total of 83 bibliographic sources were obtained linked to the forecasts of demands.
Findings
In this section, we analyzed and classified the results obtained from the study of the literature consulted. The results were classified according to the distribution of publications by year, countries and geographical regions of the authors, research methods used, models and forecast algorithms used and their fields of application.
Distribution of publications by year
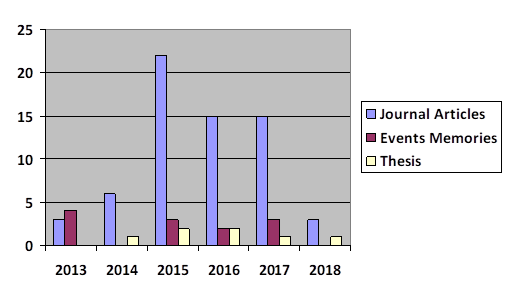
Figure 1 shows the number of publications during the period analyzed, from 2013 to August 2018. The year 2015 stands out for the number of publications (24.36 %) of the total of the published works during the period of analysis, after this year the researches and scientific publications decreased visibly. In 2014 the published works about forecast models are minimal in comparison with the rest of the years of the period studied and during 2018 only 4 works were identified up to the date of carrying out this research. Scientific journals were the most widely used publishing media (77.11%), followed by scientific event memories (14.28%) of total publications.
Distribution of publications by country and geographical area
To carry out this analysis, the nationality of the main author of each bibliographic source was taken as the country of origin of the publication. Figure 2 shows the number of publications by geographical region. In this regard, Asia and Latin America are the regions with the highest number of publications, both with 34.94% and the country with the most papers is China (10.84%) of the total of identified works.

Distribution of publications according to research methods
The research methods used in the literature consulted were: empirical studies, through experiments and specific case studies and systematic reviews of the literature. Empirical studies were highlighted as the most used research method, this type of study was applied in 93.98 % of the analyzed publications. Systematic reviews of the literature were the least widespread type of study in the period, with only 6.02 % of the articles constituting research of this type.
Distribution of publications according to forecasting models used
Forecasting models are classified into two groups: qualitative and quantitative methods (Derks, 2015; Slimani et al., 2015; Morales, 2016; Garcete et al., 2017). Qualitative methods uses expert judgment to make the forecast (Derks, 2015; Verma et al., 2017); they use models such as expert consensus, visionary forecasts and the delphi method (Morales, 2016; Garcete et al., 2017).
Quantitative methods bases their analysis on past data to make future forecasts (Derks, 2015; Garcete et al., 2017). According to Kumar et al. (2013), quantitative forecasting methods are classified into traditional methods, modified traditional methods, and soft computing methods. Sivanandam and Ahrens (2015), considers that quantitative methods are grouped into causal models, time series techniques and hybrid models. Morales (2016) classifies quantitative methods into time series analysis methods, causal models, and soft computing methods. In their study Tugay and Gündüz (2017) classifies quantitative methods into statistical models, artificial intelligence models and hybrid models.
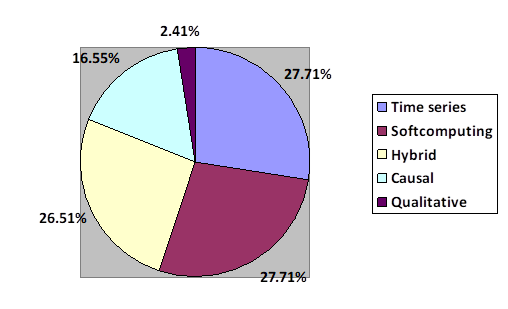
The authors of this research classifies quantitative forecasting methods into causal models, time series methods, soft computing methods, and hybrid models. Causal models analyze the relationship between the cause and effect of independent variables on the parameter to be predicted (Sivanandam and Ahrens, 2015). Time series methods analyze the historical behavior of past data series to predict future patterns and behaviors (Garcete et al., 2017). Soft computing techniques are based on artificial intelligence and automatic learning techniques (Morales, 2016). Hybrid models combine two or more types of algorithms to make forecasts (Sivanandam and Ahrens, 2015; Qamar and Khosravi, 2015). Table 1 groups the different forecast models identified in the literature according to the proposed classification.

Figure 3 shows the level of use of each type of forecast model in the literature consulted according to the classification proposed by the authors of this paper. Forecast models based on soft computing techniques and time series are the most used in the bibliography, both used in 27.71% of the analyzed works. Qualitative models are the least used, only 2.41% of publications base their study on this type of forecast model.
Distribution of publications by field of application
Figure 4 shows the distribution of each publication according to its fields of application. Defining and grouping the areas of application of the models developed is a complex task because the works are aimed at different branches of society. However, the main fields of application identified in the literature were the financial sector, hydrology and water supply, medicines, tourism, food, electricity, retail trade and mechanics. Each defined field includes at least two works related to the subject matter. There are studies that not belong to any of these groups, the authors of this investigation decided to group them in a field called: Other fields. This group includes topics such as sports, education, minerals and precious metals, digital signals, heating and inventories in warehouses.
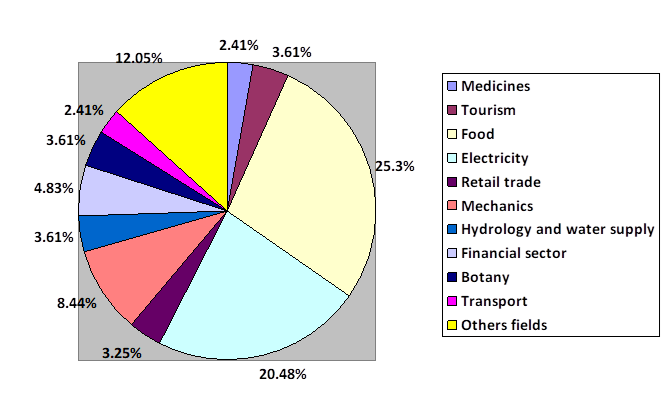
The largest number of studies on forecast models was realized in the field of food, with 25.3% of the total works identified in the literature. This field is composed by studies on crop and sowing forecasts, beverage demands, and short- and long-term food demands. Studies on forecasts of perishable food demand constitute only 7.23% of the total research consulted. Forecasts of demand in the electric power sector are also notable during the period analyzed, 20.48% of total publications.
DISCUSSION
The results obtained make it possible to identify a series of aspects that constitute the fundamental axis to make the analysis of the different forecast models during the period 2013-2018. These aspects are: analysis of the consulted bibliography, characteristics of the main models and forecasting techniques to predict the demand of perishable food products, research limitations and suggestions for future research.
Discussion of the results of the analysis of the consulted bibliography
Eksoz et al. (2014) identifies in his research that the year with the highest number of publications on collaborative forecasts in food supply chains is 2011 and 2013 is one of the years with the lowest number of such studies. Ghalehkhondabi et al. (2016) determined in his article that the year with the most publications on forecast models was 2014. Contrary to these studies, the authors of this research determined that the year with the least number of publications was 2014 and the year with the most researches was 2015.
Eksoz et al. (2014), states that the United States and the United Kingdom are the countries with the greatest contributions in the field of forecasting during the period 2011-2013. This research determined that during the period 2013-2018, China is the country with the largest number of publications on demand forecasts and that the Latin American and Asian regions are the leading geographic areas in this regard.
Eksoz et al. (2014) in his analysis explains that surveys are the most commonly used research methods. Ghalehkhondabi et al. (2016) states in his review that case studies are the most commonly used research methods. The present study identified empirical studies as the research methods most used by authors during the period 2013-2018.
Kumar et al. (2013) and Qamar and Khosravi (2015) highlight the widespread use of soft computing methods and that there is also a clear trend towards the use of hybrid models. Estupiñan et al. (2016) argue that soft computing models, specifically the algorithms of vector support machines, are widely used. In accordance with the results obtained by these authors, in the present research we determined that models based on time series and soft computing techniques are widely used. In addition, there is a considerable amount of researches where hybrid models are applied.
Regarding the fields of application, the authors of this research determined that the studies on forecast models during the period 2013-2018 focus their application on topics related to food, electricity and retail trade. In accordance with Sivanandam and Ahrens (2015), we identified that recently researches on forecasts of perishable product demands is insufficient.
Characteristics of the main models and forecasting techniques for predicting the demand for perishable food products
This section is about the main characteristics of forecasting models and techniques to predict the demand for perishable food products used in the consulted literature. The analysis focuses on the following aspects: factors that influence the demands of perishable products, input variables used in the models consulted in the literature, forecasting horizons, forecasting models used and main methods to calculate the accuracy of these models. It also describes some considerations made by different authors on strengths and weaknesses of the main quantitative forecast models.
Factors influencing perishable product demands
Forecasting the demand for perishable agricultural products is a complicated task, due to the influence of factors such as climate change, holidays and changing consumer preferences (Leung et al., 2013). Eksoz et al. (2014) considers that the short shelf-life of these foods, price changes related to product’s deterioration levels, volatile demand and climatic conditions, obstruct forecasts of perishable products.
Variations in customer’s demand make it difficult for sellers to make forecasts (Sivanandam and Ahrens, 2015). According to Sivanandam and Ahrens (2015), these variations can be classified into short-term fluctuations (holidays, promotions), medium-term seasonal patterns (school holidays, etc.) and long-term trends (economic situations).
According to Pavlovna and Grigorievna (2015), price dynamics, population indices and the purchasing power of the population are among the factors that most affect the demand for food. Kotaro (2015), argues that food sales are influenced by environmental factors such as climate, advertising campaigns and local events.
The factors that influence the object to be predicted allow us to determine the patterns and algorithms that best fit the predictions to be made (Kotaro, 2015). In order to improve the accuracy of forecasts, it is important to consider these factors as part of the input variables of the applied models (Sivanandam and Ahrens, 2015; Ma et al., 2016).
Input variables used in the models analyzed
Leung et al. (2013) uses two types of independent variables to predict the demands of perishable agricultural products: historical sales data and uncertain data, the latter is relating to climate, temperature values, holidays and the characteristics of past days and weeks. Historical sales data is obtained through time series analysis. In the analysis of these data, Leung et al. (2013) applies smoothing and normalization methods to eliminate singular and out-of-range values. Leung et al. (2013) uses fuzzy logic methods to analyze uncertain data.
Eksoz et al. (2014), in his research argues that the integration of supply chain partners in the perishable products market, as well as the exchange of accurate information, is the key to improving collaborative forecasting. In his study, it proposes a collaborative working environment that uses information shared between partners in perishable food supply chains as a fundamental input parameter.
Pereira et al. (2014), uses as input data time series of daily demands of perishable products in a Brazilian company during the period 2005-2013. In his study, he tries to predict future daily demands for this company.
Sivanandam and Ahrens (2015) use as input variables time series of historical data and external factors such as holiday effects, weather factors, promotional effects and price discounts. The time series used by Sivanandam and Ahrens (2015), in their study collect daily banana sales in a German store.
Kotaro (2015) uses historical sales data as well as climatological, sporting, cultural and promotional factors as independent variables in its study.
van Donselaar et al. (2016), extracts the independent variables of his model from information of 407 perishable products in a German retailer. The data he uses as input parameters are: sales made during promotions, number of purchases of a certain product, holidays, product prices, and variations in prices and promotional periods. van Donselaar et al. (2016), uses the adjusted R2 method to determine the level of correlation between the independent variables and the dependent variable.
In its research Pereira et al. (2016) uses time series of historical sales of dairy-derived beverages in a Brazilian multinational company during the period 2005-2013.
Huber et al. (2017) proposes a model that uses as input data, time series with information of 16 products of a bakery business. He uses the k-means method to cluster sales data from each structural hierarchical level of the organization. According to Huber et al. (2017), this process facilitates analyzing the sales of the different categories of products and efficiently capturing buyer behavior patterns in situations such as product unavailability and substitutions.
Forecast horizons
Forecast horizons encompass three fundamental periods: long-term forecast period, medium-term forecast period, and short-term forecast period (Qamar and Khosravi, 2015; Ghalehkhondabi et al., 2016). According to Qamar and Khosravi (2015) in the field of electricity, long-term forecasting periods comprise forecasts from 1 to 10 years into the future, medium-term forecasting periods comprise forecasts from 1 month onwards to 1 year and short-term forecasting periods from 1 hour, 1 day and up to 1 week. Ghalehkhondabi et al. (2016) considers long-term forecasting periods to include forecasts from 5 to 20 years, medium-term forecasting periods from 1 month to 5 years, and short-term forecasting periods from 1 hour to a week.
Forecast horizons are determined based on product and market characteristics, in the case of food products that are of short shelf life and must remain fresh during sale, their forecasts are based on short periods of time (Eksoz et al., 2014). In the food retail industry, the estimation of the forecast interval is very important (Sivanandam and Ahrens, 2015). According to Vitri (2014), the time series are used for short term forecasts and the causal methods for medium and long term forecast horizons.
Forecast models used
Leung et al. (2013), in its research, uses a model based on vector support machines (SVM) to forecast the demand for perishable agricultural products. SVMs are very resilient to the problem of over-adjustment and achieve high generalization performance by solving problems of time series analysis and forecasting and statistical learning (Leung et al., 2013). This author argues that SVM solutions are unique, optimal and provide better performance and accuracy than Artificial Neural Networks (ANN).
Eksoz et al. (2014), proposes a theoretical collaborative working environment where producers and sellers interact in various processes of exchange of information and individual forecasts to improve their integration into perishable food supply chains. Eksoz et al. (2014), argues that combined forecasting methods and their subsequent adjustment perform better than simple forecasting models.
Pereira et al. (2014) establishes a comparison between two time series models to forecast the daily demands of perishable products in a Brazilian company. In its study, Pereira et al. (2014), determines that the Holt-Winters method obtains better results than the integrated autoregressive method of moving averages (ARIMA), because it has a better adjustment and efficiently captures the linear behavior of the analyzed time series.
Sivanandam and Ahrens (2015), proposes a time series model that combines the integrated autoregressive model of seasonal moving averages with external variables (SARIMAX) and quantile regression (QR) to forecast daily demands for perishable products in a German company. The model makes it possible to determine the effects of factors influencing demand for different periods of time and obtain more accurate forecasts than ARIMA models and Artificial Neural Networks such as Multilayer Perceptron.
Kotaro (2015) in his article uses a hybrid soft computing model based on automatic learning to predict the demands of fresh foods. The model proposed by Kotaro (2015) also allows suppliers request automatically those products needed to meet demand and avoid the lack of availability of products required by customers. In addition, this model contributes to reducing food waste due to its deterioration and employs low computational costs.
van Donselaar et al. (2016) proposes a regression model that is adjusted (quadratic or linear) according to the categories of perishable products for which their demands will be predicted. This model demonstrates high accuracy in forecasting perishable food demands under the influence of promotional factors.
Pereira et al. (2016), proposes the application of an independent soft computing model that uses Wavelets Neural Networks to predict the demands of dairy products. Pereira et al. (2016), demonstrates that this model has better forecast accuracy than the results obtained by the Takagi-Sugeno Fuzzy System, Holt-Winters and ARIMA methods. In addition, his model is applicable to time series that have seasonal characteristics regardless of whether they are stationary or not.
Huber et al. (2017), uses the integrated autoregressive method of moving averages with external variables (ARIMAX) to forecast short-term demand in a bakery business. This author makes the forecast at each of the points of sale that make up the structure of the organization, in order to obtain a more accurate prediction. The model proposed by Huber et al. (2017), allows the reduction of computational costs and increases the scalability of the system due to the use of input data clustering. It also makes it possible to improve the availability of products and avoids their loss due to their deterioration.
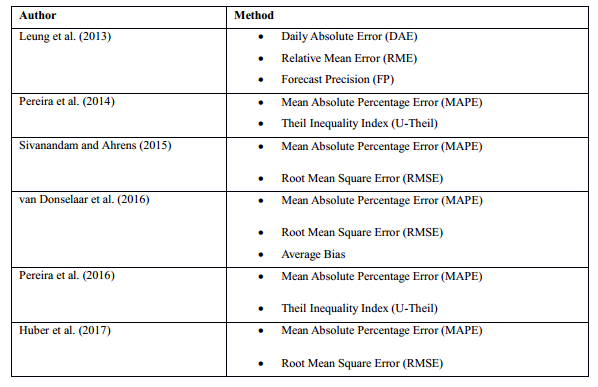
Table 2 shows the methods used in the literature to calculate the accuracy of the models proposed by the authors. The most commonly used methods for calculating the accuracy of the models were the Mean Absolute Percentage Error (MAPE) and the Root Mean Square Error (RMSE).
Strengths and Weaknesses of Quantitative Forecasting Models Analyzed in the Literature
Each forecast model has strengths and weaknesses and each situation to forecast is limited by constraints of data, time, capabilities and cost (Sivanandam and Ahrens, 2015). For the realization of a suitable forecast the characteristics of the object to be forecasted, the factors influencing the variation of the demands and the horizons of the forecast must be taken into account. In addition to these elements, it is necessary to consider the strengths and weaknesses of the different existing models according to their capacities to detect behavior and patterns in the analyzed data. According to the criteria of the authors in the literature consulted, we show below some advantages and disadvantages of the main forecasting models used.
Time series methods
Advantages
Time series methods capture demand patterns in past data and predict their future behavior by extending those patterns (Leung et al., 2013; Kim et al., 2015). According to Kim et al. (2015), these models are useful for making short-term forecasts and provide an accurate prediction with a relatively limited amount of data. These models are easy to implement and their cost is low (Pereira et al., 2016).
Disadvantages
Their main disadvantage is that they depend solely on the persistence of the time series and on the behavior of the data being repeated in the future (Rojo, Carvajal and Velásquez, 2015; Pereira et al., 2016; Garcete et al., 2017). It is not recommended to apply them to the forecast of elements that can be influenced by very changing external factors such as: climatic factors, preferences of people and promotional events, because the error in their predictions can be high (Leung et al., 2013; Qamar and Khosravi, 2015; Kourentzes and Petropoulos, 2016). These methods do not perform adequately when input data have nonlinear and irregular characteristics (Wan, 2013; Pereira et al., 2016). In addition, time series models require sufficiency and continuity of historical data (Fang and Lahdelma, 2016).
Causal Models
Advantages
They make it possible to identify external factors that affect the demands and causal relationships between these factors (Kim et al., 2015). Among the main advantages of these models are the parsimony of input data and their simplicity (Fang and Lahdelma, 2016).
Disadvantages
Ferreira et al. (2015) argue that regression models based on regression trees are prone to over-adjustment due to too large tree growth. The predictive capacity of causal models is limited by their linear behavior, and therefore, they are not always satisfactory (Aye et al., 2015; Ponce, 2016).
Soft computing models
Advantages
These models, specifically ANNs, do not consider human experience and show solid behavior in different scenarios (Qamar and Khosravi, 2015). ANNs have the capacity to learn, identify and approximate the characteristics of a time series, this allows simulating the non-linear and intrinsic relationships of the data that compose said series, and in addition, they do not have limitations in the number of input variables (Oscullo and Haro, 2016). Qamar and Khosravi (2015); Rojo, Carvajal and Velásquez (2015) and Contreras, et al., (2018), argue that soft computing models provide higher performance compared to time series models for non-linear inputs because they have the ability to improve the relationship between input and output data.
Disadvantages
Soft computing models based on ANN suffer from excessive adjustment because ANNs capture noise in the data, leading to a poor level of generalization (Leung et al., 2013). According to Leung et al. (2013), the performance of neural networks in terms of generalization for off-sample data not used in network training is always below than the performance with training data.
Hybrid models
Advantages
According to Leung, et al. (2013); Derks (2015); Aye et al. (2015); Qamar and Khosravi (2015); Aras et al. (2017) and Islek and Oguducu, (2017) combined forecasting methods get more accurate forecasts than individual methods.
Disadvantages
Consist in determining how to combine individual models to obtain a more accurate forecast (Aras et al., 2017).
Limitations of the investigation
Determining the scope of scientific databases is a controversial issue among researchers today. Bramer et al. (2016) considers that the use of a single database is not sufficient to support systematic literature searches. The present investigation was realized by means of the analysis of the literature consulted in GS, due to this, the main limitation of this study is due to the scope of this database.
Suggestions for future research
The results obtained in this study as well as its limitations constitute a basis for future research on models to predict the demand for perishable products in SMEs of the retail industry. We recommend using other scientific databases such as Scopus and Web of Science in future researches, in order to cover more information and enrich the results achieved in this study. Future research may focus on the application of combined forecasting models to predict the demands of perishable food products. We recommend studying the application of soft computing methods, mainly emotional neural networks and deep neural networks for the realization of forecasts.
CONCLUSIONS
In this research, we made an analysis of the existing literature in the GS database, referring to the main models for forecasting the future demands of different products and services during the period 2013-2018. The analysis focused on forecasts the perishable food product demands in small and medium-sized enterprises. These models contribute to improve the production plans of organizations, reduce product losses and increase customer satisfaction.
The research determined that the Asian continent and Latin America are the geographic areas with the greatest number of publications on forecasting models during the period. However, the number of studies on this subject in the field of perishable foods is smaller than other fields of application.
This paper addresses some significant elements for forecast perishable food demands. We identified in the bibliographic that climatic factors, promotional events and seasonal patterns are the key elements influencing variations in short-term food demands. Historical data through the analysis of time series and uncertain variables that collect the influence of external factors are the main input variables used in the analyzed forecast models. In addition, soft computing and time series techniques are the most forecasting models used in the literature, and the most commonly used methods for calculating their accuracy are the Mean Absolute Percentage Error and the Root Mean Square Error.

