










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El habla es la manifestación acústica del lenguaje y probablemente la principal forma de comunicación entre humanos. El desarrollo de las telecomunicaciones y del procesamiento digital de la información ha demandado esfuerzos por comprender los mecanismos de comunicación mediante habla.
En un mundo cada vez más globalizado, donde las fronteras entre países tienden a desaparecer y las necesidades de comunicación entre personas de distintas lenguas se multiplican, el reconocimiento automático del idioma hablado (RAIH) adquiere cada vez más protagonismo. Sistemas telefónicos multilingu¨es que precisan de la identificación del idioma del hablante para su correcto reconocimiento, sistemas de indexación de con- tenidos multimedia por idioma, enrutamiento de llamadas, sistemas automáticos de traducción de idiomas, entre otros, son los grandes beneficiados de la investigación y avances realizados en este campo durante las últimas dos décadas.
Actualmente los sistemas de RAIH descansan en modelos de aprendizaje profundo, ya sea en la etapa de extracción de características aprendiendo representaciones (Padi et al., 2018), o en arquitecturas de extremo a extremo (E2E de sus siglas en inglés) que agrupan y modelan conjuntamente la extracción de características y la clasificación del sistema (Jin et al., 2017). Hoy las redes neuronales profundas con arquitectura E2E lideran el RAIH, especialmente para señales de corta duración (3 segundos ) (Shon et al., 2018).
No obstante los avances alcanzados, algunas de estas herramientas no generalizan bien a nuevos dominios (Abdullah et al., 2020), hay también evidencias de que la eficacia se degrada cuando se introducen nuevos locutores (Montavon, 2009).
El presente estudio propone un método para el RAIH empleando algoritmos reconocidos por sus potencialidades para la generalización, lo cual representa una característica importante cuando se dispone de pocos datos para el entrenamiento y frente a señales de prueba de corta duración.
El método que se propone en este trabajo posee una arquitectura E2E que parte de una red neuronal convolucional (CNN) pre-entrenada sobre un conjunto de imágenes. La transferencia de conocimiento es la primera técnica de generalización que se aplica, ya que los parámetros de la red inicial son entrenados sobre imágenes de objetos reales muy distintas a los espectrogramas2 que constituyen la entrada al método propuesto y la segunda técnica de generalización que se aplica es la conocida como aprendizaje multitarea, incorporando al RAIH la identidad del locutor como tarea auxiliar.
El reconocimiento automático del idioma hablado
Definimos la tarea del RAIH como un problema de clasificación discriminativa de una secuencia. Primero, una expresión oral de longitud variable es transformada en una secuencia de observaciones acústicas X = (x 1, ..., x T ), donde x t ∈ R k es un vector de rasgos acústicos en el instante de tiempo t. Dada una secuencia X, el objetivo es predecir el idioma hablado yˆ.

Usando una red neuronal profunda como modelo de clasificación, el problema de LID se puede definir como:
donde Y es un conjunto finito de idiomas, θ son los parámetros del modelo y P(y|X; θ ) representa la probabilidad a posteriori de la etiqueta de idioma y.
El aprendizaje no es un proceso fácil, ni para los humanos ni para las máquinas. Es un proceso de trabajo pesado, que consume recursos y tiempo y, por lo tanto, era importante diseñar un método que evitara que un modelo olvidara la curva de aprendizaje que obtuvo de un conjunto de datos específico y también le permitiera aprender más de nuevos y diferentes conjuntos de datos.
La idea inicial detrás de la transferencia de aprendizaje es reutilizar la experiencia o el conocimiento ya obteni- do, para mejorar el aprendizaje de cosas nuevas. La transferencia de conocimiento y al aprendizaje multitarea pueden considerarse como implementaciones particulares de la transferencia de aprendizaje aplicadas en di- ferentes condiciones o de distintas maneras (Bengio, 2012).
Transferencia de conocimiento en modelos convolucionales
Las CNNs han probado ser eficaces reduciendo las variaciones espectrales y modelando correlaciones en rasgos acústicos (Zhang et al., 2017) por lo que se han utilizado en una variedad de tareas de classificación de audio. Hay aproximaciones basadas en CNNs que utilizan como dato de entrada el audio en bruto o apenas preprocesado, valiéndose de convoluciones uni-dimensionales. Sin embargo, la mayoría de los resultados se han obtenido mediante el uso de CNNs en espectrogramas.
La transferencia de conocimiento en tareas de clasificación de audio se ha centrado principalmente en el pre- entrenamiento del modelo sobre corpus de audio significativamente grandes y diversos (Choi et al., 2017) que luego son ajustados a distintas tareas. Un enfoque innovador y diferente fue emplear una CNN entrenada sobre un conjunto masivo de imágenes y adaptarla con espectrogramas al dominio de clasificación en audios.
Trabajos aplicados al RAIH, que empleen modelos pre-entrenados sobre ImageNet (Deng et al., 2009) podrían citarse a Revay and Teschke (2019) y van der Merwe (2020). Estos trabajos presentan propuestas muy simi- lares a la presente investigación: emplean arquitecturas E2E, parten de redes bien establecidas como ResNet y DenseNet y utilizan espectrogramas de señales cortas como entradas a las redes.
Otro ejemplo de modelo para la identificación del idioma desde una perspectiva de visión por computadora es Bartz et al. (2017), que aunque no parte de un modelo previamente entrenado sobre ImageNet, concibe el entrenamiento de una red híbrida CNN recurrente con centenares de miles de espectrogramas.
Aprendizaje multitarea
La mayoría de las técnicas del aprendizaje automático se centran en el aprendizaje de una única tarea aislada, y está claro que este enfoque desestima ciertos aspectos fundamentales del aprendizaje humano. Los seres humanos afrontan cada nueva tarea de aprendizaje equipados con los conocimientos adquiridos en las tareas de aprendizaje anteriores. Además, el aprendizaje humano con frecuencia implica abordar varias tareas de aprendizaje simultáneamente.
La aplicación del aprendizaje multitarea para el RAIH básicamente se ha centrado en relacionar la información fonética con el idioma, ya sea en enfoques E2E (Li et al., 2020) como en la etapa de representación (Zhao et al., 2019). Existen también trabajos donde el reconocimiento del idioma o dialecto es la tarea auxiliar y lo que se busca es relacionarla con los fonemas para mejorar la eficacia del reconocedor de habla (Mendes et al., 2019).
En el caso de tareas correlacionadas negativamente, como el idioma y las diferencia de dominio, se ha aplicado el aprendizaje multitarea adversarial para lograr un modelo que disminuya la dependencia con el dominio (Abdullah et al., 2020). Sobre la línea del aprendizaje adversarial es muy común el empleo de las redes generativas adversariales para el RAIH (Miao et al., 2018).
De acuerdo a Peng et al. (2019), emplear una representación altamente correlacionada con unidades fonéticas e independiente del locutor, favorece el RAIH empleando el enfoque i-vector. Sin embargo de los resultados experimentales del presente trabajo, con un enfoque de E2E y un conjunto cerrado de locutores, asociar el idioma y el locutor parece favorecer el RAIH.
Método propuesto
Arquitectura monotarea
Para inicializar la red fue empleada la red MobileNetV2 (Sandler et al., 2019) haciendo uso de la transferencia de conocimiento. MobileNetV2 fue desarrollada en Google y entrenada sobre el conjunto de datos ImageNet con 1,4 millones de imágenes y 1000 clases de imágenes web. A partir de este modelo pre-entrenado, los parámetros de las capas iniciales son fijados o “congelados” y se definen como entrenables solo las últimas 23 capas de la red.
El modelo propuesto consiste entonces en la MobileNetV2 de 53 capas de profundidad (ver Figura 1a), de las cuales las 30 primeras permanecen congeladas. Este bloque será referido como pre-entrenado G f , y puede ser considerado como un extractor de rasgos de alto nivel de abstracción, que transforma la secuencia de entrada X en un mapa de características f = G f (X; θ f ).
Luego del bloque pre-entrenado siguen las 23 capas del bloque convolucional, que forman parte de la arqui- tectura de la MobineNetV2 pero que a diferencia de las primeras 30 capas, los parámetros de este bloque θ m son aprendidos sobre el conjunto de entrenamiento de la base de datos de idiomas D = {(X i , y i )}N , siendo N la cantidad de muestras etiquetadas. Vale recalcar que como se puede apreciar en la ecuación 2, en la estimación de θ m incide de manera directa el conocimiento codificado en las capas congeladas que es transferido a G m al recibir como entrada las transformaciones que se suceden en el bloque G f .
G m somete a su vez a f a una serie de transformaciones no lineales yˆ = G m ( f ; θ m ) que, seguido de una capa softmax, mapea yˆ en una distribución de probabilidad sobre el espacio de los idiomas.
La función a minimizar durante el aprendizaje resulta entonces:
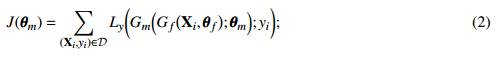
donde L y es el error en la clasificación de idioma.
Arquitectura multitarea
En esta sección se aborda una segunda técnica de generalización, el aprendizaje multitarea. La aproximación propuesta busca mejorar la clasificación de idiomas, incorporando al aprendizaje la información no semántica contenida en la señal relativa a la identidad de los locutores.
Con este objetivo definimos un bloque de capas que serán compartidas, y que coincide con la red MobileNet 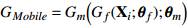 . A este bloque le suceden dos ramas de capas completamente conectadas y sus respectivas capas softmax, una para cada tarea específica (ver Figura 1b).
. A este bloque le suceden dos ramas de capas completamente conectadas y sus respectivas capas softmax, una para cada tarea específica (ver Figura 1b).
Para el entrenamiento empleamos el mismo conjunto de datos 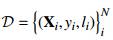 pero esta vez cada muestra
pero esta vez cada muestra 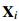 cuenta con una etiqueta de idioma y del locutor. En esta configuracion multitarea la función objetivo a minimizar resulta ser:
cuenta con una etiqueta de idioma y del locutor. En esta configuracion multitarea la función objetivo a minimizar resulta ser:
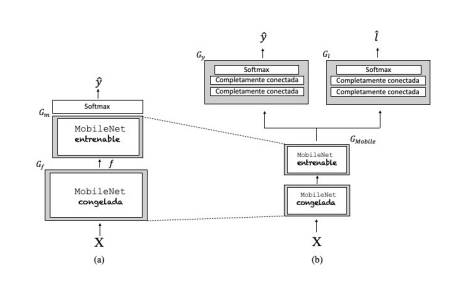
Fig.1 Esquema de las configuraciones propuestas: (a) monotarea y (b) multitarea. Siendo yˆ y lˆ las variables que representan el idioma y el locutor predicho de cada muestra.
Siendo L y y L l los errores de clasificación de idioma y locutor respectivamente; y λ y y λ l pesos no negativos, que ponderan el impacto que la tarea en particular tendrá en la estimación de los parámetros del sistema. Un valor de λ cercano a cero significa que esa tarea no tendrá prácticamente influencia durante el entrenamiento del sistema y viceversa.
Configuración experimental
La base de voces empleada fue VoxForge (MacLean, 2009), un corpus de voces de código abierto que contiene muestras de más de 18 idiomas diferentes . Los datos consisten en archivos de audio de duración aproximada entre 5 y 10 segundos, con la transcripción del texto hablado, así como con etiquetas relativas al idioma, sexo e identidad del locutor. La calidad de las diferentes muestras varía según el equipo de grabación utilizado por el colaborador por lo que constituye un corpus con una gran variabilidad de sesión.
Para la experimentación, definimos un sub-conjunto de VoxForge formado por 5 idiomas: Alemán, Español, Francés, Inglés y Ruso. Aproximadamente 38 minutos por idioma permitieron conformar conjuntos de entre- namiento (60 %), validación (25 %) y prueba (15 %), cuidando que existiera un balance de locutores femeninos y masculinos.
Para la obtención de las imágenes (espectrogramas), primeramente se pre-procesaron los audios eliminando silencios iniciales y finales con Librosa (McFee et al., 2015). A continuación, se extrajeron los rasgos acústicos empleando Kaldi (Povey et al., 2011). Se aplicó un filtro de preénfasis a la señal y fue dividida en tramas de 20 milisegundos (con solape de 10ms). Sobre las tramas se aplicó una función de ventana y se computó la transformada de Fourier de corta duración para obtener el espectro de potencia o periodograma. El último paso consistió en aplicar a dicho espectro de potencia un banco de filtros triangulares (40 filtros) en escala Mel, obteniendo una representación por trama de vectores de 40 dimensiones conocidos como rasgos banco de filtros Mel (Mel-fbank).
Concatenando los 300 vectores iniciales de cada señal se conforma finalmente la matriz de 40 × 300 con la que se crea y salva la imagen en escala de grises, empleando OpenCV para python. De esta forma se utiliza de cada señal solo 3 segundos de audio asegurándose que no contenga silencios, solo pausas.
En la Figura 1 se muestran las dos arquitecturas evaluadas. La arquitectura monotarea se presenta en la Figura 1a, formada por la MobileNetV2 y una capa softmax con 5 clases correspondientes a los idiomas a identificar.
La arquitectura multitarea se ilustra en la Figura 1b y está formada por la MobileNetV2 y dos ramas en paralelo encargadas de modelar de forma conjunta la identificación de idioma (yˆ) y de locutor (lˆ). Las dos ramas son iguales y compuestas por dos capas completamente conectadas que terminan en una capa softmax.
La incorporación del aprendizaje multitarea aumentó en 1millón la cantidad de parámetros entrenables de la red, resultando en aproximadamente 5.5M de parámetros a entrenar en la configuración más compleja, lo que repercutió en menos de un minuto más de entrenmiento en un core i7-4790 con 8 procesadores a 3.60GHz.
La plataforma de trabajo empleada para las técnicas de aprendizaje profundo fue TensorFlow 2.3.0, una de las más utilizadas a nivel global. TensorFlow puede utilizarse en conjunto con diferentes lenguajes de programa- ción, sin embargo presenta mayor soporte para Python.
Resultados y discusión
Para la selección de algunos hiperparámetros de la red evaluamos su comportamiento sobre el set de entrenamiento y validación. Se hizo un análisis del comportamiento de la eficacia durante el entrenamiento y se observa como sobre el conjunto de validación se mantiene oscilando alrededor de un 80 % a partir de la época 20, valor en el que finalmente entrenamos los modelos. De forma empírica definimos la razón de aprendizaje en 10−4 y se aplicó el algoritmo de optimización de Adam.
En la Tabla 1 se presentan los resultados sobre los conjuntos de entrenamiento, validación y prueba de los modelos con ambas arquitecturas monotarea y multitarea (idioma-locutor).

Obsérvese en la Tabla 1 que el valor de eficacia sobre el conjunto de prueba en la arquitectura multitarea es mayor que en la monotarea, por lo que se infiere que la incorporación de la información relativa al locutor en la arquitectura E2E que se propone, favoreció la capacidad discriminatoria del modelo en la tarea de RAIH. Obsérvese también cómo la diferencia en eficacia entre la validación y la prueba disminuye al pasar de la arquitectura monotarea a la multitarea, mostrando mayor capacidad de generalización en esta última.
En la Figura 2 se reportan los valores de precisión y especificidad de los modelos monotarea y multitarea (Idioma-Locutor) para cada uno de los 5 idiomas considerados.
La precisión y la especificidad son dos valores que nos indican la capacidad de nuestro estimador para dis- criminar los casos positivos de los negativos y son métricas que resultan relevantes, y complementarias a la eficacia, en problemas de clasificación con clases desbalanceadas. La precisión cuantifica la cantidad de pre- dicciones positivas que realmente pertenecen a la clase positiva, mientras que la especificidad cuantifica la cantidad de predicciones positivas del total de ejemplos positivos en los datos.
La distribución de las clases en este caso es equilibrada, sin embargo el análisis permite ver para cada idioma las potencialidades y debilidades de los modelos. Por ejemplo de la configuración multitarea se observa que para el idioma inglés se tiene la mayor precisión, por tanto las muestras en ese idioma tienen gran probabilidad de ser detectadas. Por su parte el alemán es el idioma para el cual el modelo multitarea tiene menos falsos positivos.
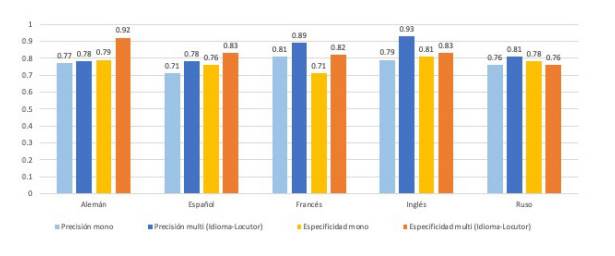
Fig. 2 Precisión y especificidad de los modelos monotarea y multitarea (Idioma-Locutor) sobre el conjunto de prueba.
De acuerdo a lo reportado en la Figura 2, la configuración multitarea exhibe los mejores valores tanto de precisión como de especificidad, para cuatro de cinco los idiomas.
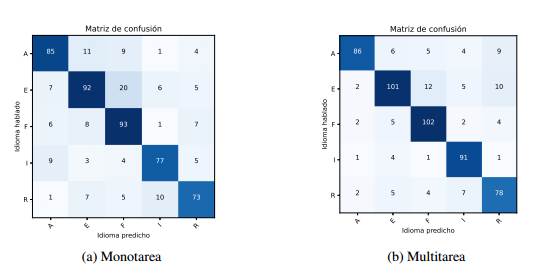
En correspondencia con los valores de eficacia que aparecen en la Tabla 1, las matrices de confusión de la Figura 3 muestran como en la arquitectura multitarea, la confusión entre las etiquetas reales de los idiomas y las predicciones es menor que en la monotarea.
La Figura 3 permite comparar ambas arquitecturas mostrando relaciones entre los idiomas como por ejemplo la cercanía del francés y el ruso con el español. La tasa más alta de predicciones falsas negativas se produjo cuando las muestras españolas se clasificaron como francesas o rusas, esto se corresponde con el hecho de que en la arquitectura monotarea la más baja especificidad la tiene el idioma francés y en la multitarea el idioma ruso lo deplaza.
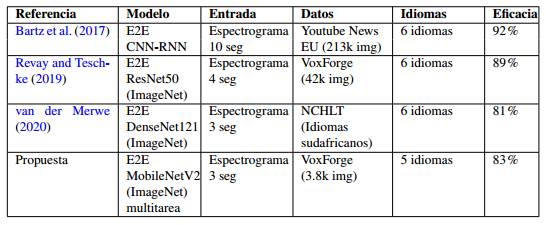
Si bien es cierto que para una comparación justa de algoritmos de reconocimiento de patrones lo ideal es que los experimentos se reproduzcan exactamente en las mismas bases de datos y bajo la mayor igualdad de con diciones posibles, en este caso se han encontrado referencias publicadas recientes, de entornos experimentales muy similares a los del presente artículo.
Los trabajos que se muestran en la Tabla 2 están organizados por fecha, siendo el último la propuesta que nos ocupa. Todos los trabajos abordan el RAIH con un enfoque E2E partiendo de espectrogramas y reconocen en conjuntos de 6 idiomas máximo.
Bartz et al. (2017) es el trabajo que más datos demanda, ya que no parte de una red pre-entrenada sobre Ima- geNet, sino que entrena desde cero la arquitectura que propone. Exhibe el mayor valor de eficacia pero lo hace sobre espectrogramas de 10 segundos, lo que representa una disparidad respecto al resto de los trabajos referenciados, sinembargo Revay and Teschke (2019) se le acerca mucho reconociendo sobre espectrogramas con menos de la mitad de la señal. Revay and Teschke (2019) parte de una Resnet50, que al igual que Den- seNet121 y MobileNetV2 estan entrenadas sobre ImageNet. Un punto en común importante que tiene Revay and Teschke (2019) con este artículo es que ambos emplean VoxForge, aunque nuestra propuesta con aproxi- madamente 10 veces menos datos y espectrogramas sobre señales 1 segundo más cortas, obtiene una eficacia cercana. Por su parte van der Merwe (2020) tiene la complejidad de reconocer idiomas sudafricanos, que son acústicamente muy cercanos, lo que explica la baja eficacia respecto al resto de los métodos.
Conclusiones
Las CNNs pre-entrenadas para el reconocimiento de imágenes han sido empleadas anteriormente para transferir conocimiento al dominio de clasificación en audio, sin embargo la propuesta del presente artículo es original porque lo hace aplicando además el enfoque de aprendizaje multitarea para el RAIH, en señales de corta duración y con significativamente menos datos que los sistemas referenciales. Los autores no encontraron trabajos previos que propusieran esta combinación de técnicas de aprendizaje automático para el RAIH.
Los resultados del presente trabajo no solo muestran que la transferencia de aprendizaje del reconocimiento de imágenes al de idioma funciona. Muestran que la representación que obtiene dicha red luego de incorporar información relativa al locutor aporta información útil para el reconocimiento del idioma, o sea que la identidad del locutor incorporada como tarea auxiliar al RAIH en una arquitectura E2E, favorece el reconocimiento de idiomas alcanzando una eficacia del 83 % sobre muestras de 3 segundos de duración.
La aplicación del enfoque multitarea sobre una arquitectura como la MobileNetV2 destaca como una novedad y significó una mejora de la eficacia de aproximadamente un 7 %.
La existencia de trabajos recientes que aborden el problema del RAIH sobre muestras de corta duración empleando imágenes, habla de la pertinencia y actualidad de la investigación en esta área. En particular, alcanzar soluciones competitivas con un volumen de datos pequeño, induce a pensar que no será complejo adaptar el sistema a entornos nuevos y específicos, con poca disponibilidad de datos.

