










 Servicios personalizados
Servicios personalizados Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroduction
The software development complexity can be analyzed in terms of essential complexity and arbitrary complexity (Brooks). The essential complexity is inherent to the process (i.e. enterprise management processes, health management processes, etc.). This complexity is inevitable because it is not related to the software development process (Selic, 2008).
On the other hand, the arbitrary complexity is focused on the internal software development process. This complexity considers the technologies and methods used in a software development project as well as the developers' skills. Hence, reducing arbitrary complexity is a common concern of software managers. In that sense, it is critical to adopt the appropriate technologies and methods. For example, adopting a tool that automatically generates some part of the source code will reduce the complexity of the coding stage and, consequently, increase the productivity of the software developers. On the contrary, adopting a method with a high learning curve may reduce the productivity of the process. In general, a high essential complexity increases the need to reduce the arbitrary complexity.
During the architecture design phase, the high-level abstraction components to satisfy the clients' requirements are identified (Al-Jamimi & Ahmed, 2013). Hence, the decisions made in this phase have a considerable influence on the subsequent development phases. The characteristics of complex systems, for example, enterprise management systems, determine a high essential complexity for this phase. Therefore, it is suitable to adopt those technologies and methods that contribute to reducing the arbitrary complexity. Thus, the productivity of architects will be increased, and less time will be necessary to carry out this phase (Al-Jamimi & Ahmed, 2013).
Commonly, this phase is carried out intuitively, depending on architects’ creativity (Al-Jamimi & Ahmed, 2013), but no formal guidance or adequate means to check the quality of the resulting design are adopted. These issues lead to frequent redesigns to fix those errors generated in the design phase but detected in subsequent phases. The redesign increases software development time, affects software quality, and increases project costs. Fixing post-implementation errors cost 100 times more than those detected at the design stage (Boehm, 1981; Moreno, Snoeck, Reijers, & Rodríguez, 2014; Sánchez, García, Ruiz, & Mendling, 2012).
The incorrect business process modeling and the correspondence between business processes and design commonly affect the quality of software systems Barjis (2008), especially those with high complexity. In that sense, business process models are the base artifact for architecture design. However, some researchers have demonstrated that business process models usually have errors (Mendling, 2009; Moreno et al., 2014). The incorrect validation of business process models lead to the propagating of their errors to the subsequent phases. This insufficiency increases the costs and efforts to fix those mistakes (Moreno et al., 2014; Sánchez et al., 2012; Sánchez, Ruiz, García, & Piattini, 2013; Wand & Weber, 2002).
On the other hand, Model Driven Development (MDD) paradigm is acknowledged as an alternative to reduce the arbitrary complexity of the software development process by means of increasing the abstraction level to improve the human communication and analysis (Mohagheghi et al., 2011).
Model Driven Architecture (MDA) is the most prominent MDD-based methodology. MDA organizes the software development in three abstraction levels: Computer Independent Models (CIMs), Platform Independent Models (PIMs), and Platform Specific Models (PSMs).
Taking into account the aforementioned benefits of MDA, we developed a MDA-based approach to support the architecture design phase. In that sense, this paper aims to describe the results of an experiment conducted to demonstrate the impact of the developed approach to enhance the architecture design of enterprise management systems. Our approach is based on MDA and ontologies, and a tool was developed to support the transformation and validation of models. The experiment yielded empirical evidence that corroborates the approach's applicability and impact.
The rest of the paper is structured as follows. Next section presents the methods adopted in this research. Then, the main components of our approach are introduced. In the Result section the results of the experiment are analyzed. Finally conclusions and future work are presented.
Methods or computational methodology
Model Driven Architecture (MDA)
MDA is a methodology promoted by the Object Management Group (OMG). It is a model-driven proposal because it defines models as the main artifacts for understanding, designing, developing, implementing, and maintaining systems (OMG, 2003).
MDA aims to develop systems with high flexibility in implementation, integration, maintaining, and testing. Portability, reusability and interoperability are the three main MDA principles. As we mentioned above, three types of models are defined in MDA: Computer Independent Models (CIMs), Independent Platform Models (PIMs) and Platform Specific Models (PSMs).
A CIM is a view of the business, regardless of system specifications. Bridging the gap between business experts and software developers is the main goal of this type of model. A PIM is a system view that does not include platform specifications. This type of model contributes to separating the logical design concerns from the platform-specific concerns. Whereas, a PSM is a view of the system that includes the details of a specific platform.
Model transformations is the other key component of MDA. A model transformation consists of generating a new model from others of the same system. Achieving the automatic model transformation is the aim of the scientific community to increase the productivity in the software development process and enhance the software quality.
Several studies have demonstrated the positive impact of MDA-based approaches to improve the productivity of the software development process and the quality of the resulting software (Bocanegra, Peña, & Ruiz Cortés, 2008), (Singh & Sood, 2010) (De Castro, Marcos, & Vara, 2010; Kharmoum, Ziti, Rhazali, & Fouzia, 2019; Melouk, Rhazali, & Youssef, 2020; Mora et al., 2008; Sánchez Vidales, Fermoso García, & joyanes Aguilar, 2008).
Ontologies
An ontology is a formal and explicit description of a discourse domain concepts (classes), the properties of each concept, attributes, and restrictions (Noy & McGuinness, 2001). The ontologies have been extensively exploited to represent and analyze knowledge in several domains (Bencharqui, Haidrar, & Anwar, 2022; Bouzidi, Nicola, Nader, & Chalal, 2019; Freitas, Canedo, & Jesus, 2018; Keet & Grütter, 2021; Nicola, Melchiori, & Villani, 2019; Silega & Noguera, 2021; Xinga, Zhonga, Luoa, Lic, & Wua, 2019; Yang, Cormicana, & Yub, 2019). The application of ontologies in the MDA context may enable the models consistency checking and validation. This new approach has been named Ontology Driven Architecture (ODA) (W3C, 2006). We found several MDA-based works (Kharmoum et al., 2019; Melouk et al., 2020) which include models to represent and validate processes through formal models (Laaz, Kharmoum, & Mbarki, 2020; Laaz, Wakil, Gotti, Gotti, & Mbarki, 2019; Li, Zhou, & Ye, 2019).
Some of the most important languages to represent ontologies are: Ontolingua, XML Schema, RDF (Resource Description Frame-work), RDF Schema (o RDF-S), and OWL (Xing & Ah-Hwee, 2010). OWL includes a set of operators to represent different types of relations, such as intersection, union, and negation. Since OWL is based on description logic, it is possible to employ reasoners to automatically check the models consistency. In addition, the tool Protégé supports the management of ontologies in OWL.
The benefits of adopting OWL ontologies have been extensively demonstrated (Pahl, Giesecke, & Hasselbring, 2009), (Bo & Li-juan, 2009), (Chengpu, Rob, & Xiaodong, 2010), (Chungoora & Young, 2008) y (Kruchten, 2004). Considering these advantages, we adopted an ontology-based approach to carry out the architecture design. We carried out an analysis of some important methodologies to develop ontologies (Kotis, Vouros, & Spiliotopoulos, 2020; Kumar, 2017). Finally, the methodology of Noy and McGuinness was adopted to develop our ontology. This methodology has been extensively adopted to guide the development of ontologies (Sattar, Surin, Ahmad, Ahmad, & Mahmood, 2020).
An approach based on MDA and ontologies to support the architecture design
In this section, we briefly introduced an approach to support the architecture design. A detailed description of this approach is presented in (Silega, Noguera, & Macias, 2016). Figure 1 depicts an overall view of the proposal. In Fig. 1, the rectangles represent the types of models, and the arrows represents the transformations. Three CIMs and two PIMS are included in the proposal. In addition, four models transformations are included as well. Previous works have described the aim of each model (Silega, Loureiro, & Noguera, 2014; Silega, Macías, Matos, & Febles, 2014).
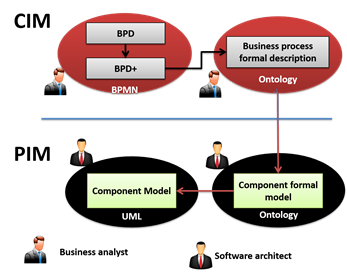
Computer Independent Models
BPD: This model allows creating business processes descriptions so that it can be easily understood by both business specialists and software developers. However, some particular domain concepts cannot be represented in this model. Therefore, the following CIM was included in this level.
BPD+: It is an intermediate model to extend the BPD with the particular-domain information that the BPD could not represent.
Ontological model: This ontology includes classes, properties, and restrictions to represent a business process. Some classes are related to BPMN concepts, such as Activity, Processs, FlowElement, Event, Gateway, and Object. The ontology also includes object properties to relate individuals.
Platform Independent Models
At this level, a high-level architecture view is provided. This view includes the components and their relationships. This representation aims to show how the system components are coordinated to meet the business needs. The most significant concepts are Component, Service, and Functionality.
Ontological component model: The ontology includes classes and properties to represent the system architecture. Some relevant classes are Component, Service, and Functionality. A set of object properties were defined to relate the model concepts. For example, it was stated that a Service is provided by a Component and a Component implements some Functionalities. Furthermore, some classes to classify the components were included, for example, BusinessComponent, DomainComponent, and TechnologyComponent.
UML component model: Representing the component model by means of an ontology provides the benefits that were mentioned above. However, this type of model is not easy to understand for those who are non-experts with these technologies. Hence, it is suitable to include a model that is easy to understand by software developers. In that sense, the UML component model has been adopted. This is a well-known model and it is interpreted by a wide variety of modeling tools. As Fig. 1 shows, the PIM level is composed of an ontological model and an UML component model.
Results and Discussion
A tool to support the transformations
The tool that we developed to support the approach is described below. This tool was created as a Protégé plugin to automate the three transformations that the approach includes. These transformations are:
BPD -> BPD+: In this step, the BPD is extended with the specific domain information.
BPD+ -> Ontological business process model: With this transformation, an ontological representation of the processes is generated from the BPD. A set of transformation rules were defined to generate this model.
Ontological business process model -> Ontological component model: This is a CIM to PIM transformation. In this case, a component model is generated from the business process model. Both models are represented by means of ontologies.
Ontological component model -> UML component model: A UML component model is generated from the ontological component model in this transformation.
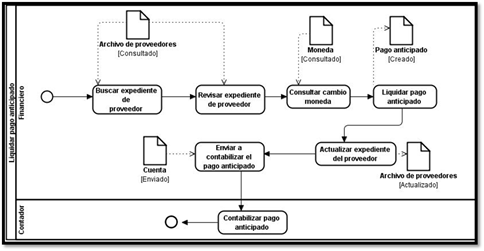
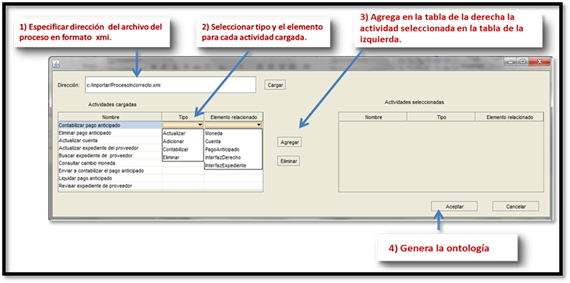
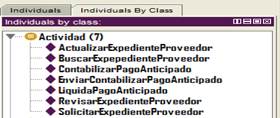
Considering that the main goal of this paper is to present the results of two experiments conducted to demonstrate the impact of our approach and the participants in this experiments speak English, we show a picture with the Spanish version of the plugin. Likewise, the models generated during the experiments are shown in the Spanish language. Figure 2 depicts the basic view of the plugin, which includes three functionalities. Functionality Importar supports the transformation one and two. Whilst the functionalities Transformar and Exportar support the transformations three and four, respectively. To illustrate how the tool works, we present the results of a study case. A BPD of the process Liquidar pagos anticipados is the first model (Figure 3). The functionality Importar opens the interface shown in Figure 4. In this window, the activities of the BPD will be listed. It is possible to add the domain-specific information for each activity. Fig. 4 shows the activities of the BPD that was depicted in Fig. 3. Figure 5 shows the activities generated in the ontology after executing the transformation.
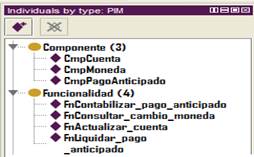
Once the ontological business process model has been generated, it is possible to transform it into the component model (Transformation 3). To carry out this transformation, the functionality Transformar is executed. After executing this functionality, the ontological component model is automatically generated. Fig. 6 shows the instances of the classes Component and Functionality that was created in the ontology.
Once the business process formal model has been generated, it is possible to transform it into a component model (Transformation 3). The functionality Tranformar of the plugin is employed to carry out this transformation. After executing this functionality, a component model is generated. Figure 6 depicts the generated instances of the classes Component and Functionality.
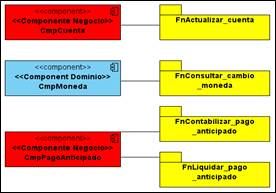
Once the ontological component model has been created, it is possible to transform it into a UML component model (Transformation 4). The functionality Exportar will automatically generate this new model. Figure 7 shows the generated component model. In this model, the unimplemented functionalities are highlighted with yellow color. Whilst the business components and domain components are highlighted with the color red and blue, respectively. Using different colors according to the characteristics of the model elements will facilitate its analysis.
Assessing the impact of our approach
To assess the impact of our approach, two (cuasi) experiments were conducted: (1) to evaluate the capacity to detect mistakes in the business process models and (2) to assess the capacity to avoid mistakes in the component models. The participants in these experiments were members of a project to develop an enterprise management system.
Assessing the capacity to detect mistakes in the business process models
The participants in this experiment were nine engineers and three students with experience modeling business processes. We provided the participants with a description of the process Liquidar cobro anticipado. Since we wanted to assess the capacity of the participants to detect mistakes, we included ten mistakes in this BPD. The participants were asked to review this BPD and to identify mistakes (if exist). Table 1 depicts the number of mistakes detected by each participant. In a second measurement, we reviewed the BPD applying our approach. At this time, all mistakes in the BPD were detected.

Assessing the capacity to avoid mistakes in the component models
The second experiment was conducted with 11 participants who had at least 2-year experience as architects or programmers. The participants received the right description of the process Liquidar pago anticipado and were asked to elaborate a proposal of architectonic design based on the design practices defined in their projects. Table 2 shows the number of mistakes that each participant made. The minimum number o mistakes made by an architect was two, and the medium of errors was 4,27. The following are some of the most common mistakes:
The design does not cover the activities of the process. Hence, the design does not meet the user's needs.
Some components do not have a well-defined responsibility. This problem leads to unnecessary integrations and consequently to the system performance and reuse.
Violations of design rules that lead to high coupling and low cohesion. Hence, two of the most important design principles are not met (Larman, 1999).

We used our proposal to carry out the architectonic design for the second measurement. As a result, no mistakes were made, thus demonstrating the positive impact of our proposal. The use of ontologies and automated transformations are two of the main factors contributing to these results.The experiments also provided evidence that our proposal contributed to homogenizing the design. Only two design proposals at the first measurement have high similarity. However, using our proposal, the resulting design was always the same.
Conclusions
This paper introduced an approach based on MDA and ontologies to support the architecture design. We briefly described a tool that includes the functionalities to support the creation and automated transformation of models. The use of this tool increases the productivity of the software development process and contributes to ensure the software quality. To demonstrate the impact of or proposal, two (cuasi) experiments were conducted. These experiments provided evidence that demonstrates the good performance of this approach to detect mistakes in business process models, reduce the number of mistakes during the architectonic design, and homogenize the design rationale. We are currently working to extend the proposal to cover other views of the software development process. Likewise, we are designing new experiments to provide new evidences that demonstrate the impact of our proposal on different variables of the software development process.

