










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El aprendizaje ensemble se refiere a la generación y combinación de múltiples modelos para resolver una tarea de aprendizaje en particular. Esta metodología imita la naturaleza de los seres humanos de buscar varias opiniones antes de tomar una decisión crucial, como escoger un determinado tratamiento médico por ejemplo (Lundberg et al., 2020). El principio fundamental del ensemble es darle un peso a cada una de las opiniones individuales y combinarlas todas con el objetivo de obtener una decisión que sea mejor que las obtenidas por cada uno de ellas por separado (Polikar, 2006).
Existen diferentes métodos de construcción de bosques de decisión usando un método ensemble general como Adaboost (Freund et al., 1996), el cual puede ser utilizado con cualquier algoritmo de aprendizaje base o usando un método ensemble específicamente diseñado para la construcción de bosques de decisión como Random Forest (Breiman, 2001). Los algoritmos más utilizados en la construcción de bosques de decisión son:
Bagging: escoge aleatoriamente las instancias que forman parte del conjunto de entrenamiento con el cual se construye cada árbol (Breiman, 1996).
Random Subspaces: construye cada árbol utilizando una muestra aleatoria de los atributos (Ho, 1998).
Random Forest: tiene dos procesos que inyectan aleatoriedad, el primero es escoger aleatoriamente las instancias que forman parte del conjunto de entrenamiento con el cual se construye cada árbol y el segundo consiste en escoger el mejor split posible entre una muestra de los atributos en vez de considerar todos los atributos (Breiman, 2001).
Se ha mostrado repetidamente que el aprendizaje ensemble mejora el poder predictivo de un modelo indivi dual, este trabaja particularmente bien cuando son usados arboles de decisión como modelos bases (Polikar, 2006). De esta idea, de combinar el aprendizaje ensemble con los arboles de decisión surge la noción de los bosques de decisión (Lundberg and Lee, 2017).
En la construcción de un buen bosque de decisión se deben cumplir los principios de diversidad y poder predictivo. Un bosque es diverso cuando cada árbol de decisión individual es lo suficientemente diferente de los demás (Mitchell, 1980; Molnar, 2018). A su vez, el poder predictivo de cada árbol debe ser el mejor posible o al menos mejor que un modelo aleatorio. La combinación de ambos principios tiene como objetivo hacer los bosques de decisión más eficaces.
Existen diferentes acercamientos para lograr diversidad en un ensemble (Ali and Pazzani, 1995; Lundberg et al., 2018) por ejemplo: manipular el conjunto de entrenamiento. En este caso se varía la entrada que es usada por el algoritmo; cada árbol es entrenado con un conjunto diferente de entrenamiento. Este método es útil para modelos en los cuales pequeños cambios en el conjunto de entrenamiento pueden provocar grandes cambios en ellos.
Existen dos maneras obvias de dividir el conjunto de datos original, horizontal y verticalmente. En la divi sión horizontal el conjunto de datos original es dividido en muchos subconjuntos que contienen los mismos atributos que el original, cada uno conteniendo un subconjunto de las instancias del original (Chawla et al., 2004). En la partición vertical el conjunto original es dividido en muchos subconjuntos que tienen la misma cantidad de instancias que el conjunto original, cada uno conteniendo un subconjunto de los atributos del original (Rokach, 2008).
Otra manera de lograr diversidad es manipulando el algoritmo de aprendizaje. En este acercamiento, se ma nipula la manera en la que el algoritmo de construcción de árboles es utilizado. Una variante es alternar la forma en la que el algoritmo atraviesa el espacio de hipótesis, logrando así, que se construyan arboles de decisión diferentes (Brown et al., 2005). También se puede buscar diversidad mediante la manipulación de los parámetros del algoritmo. Estos algoritmos normalmente son controlados por un conjunto de parámetros, tales como la altura del árbol y la cantidad mínima de instancias para una hoja. Ejecutar el algoritmo con diferentes configuraciones de estos parámetros produce arboles diferentes (Lin and Chen, 2012).
Luego de analizar el comportamiento de los algoritmos existentes para construir bosques de decisión, se identificó que en muchas ocasiones los atributos de mayor relevancia aparecen en la mayoría de los arboles construidos, lo que hace que los arboles construidos no sean tan diferentes y por tanto, la diversidad del bosque de decisión se ve afectada (Fan, 2022). Adicionalmente se inyectan uno o varios procesos aleatorios en la construcción del bosque, lo que trae como consecuencia que no se puedan entender del todo los resultados obtenidos y que se afecte la eficacia de la clasificación.
Con el objetivo de controlar la diversidad que se genera en el bosque de decisión se identificaron tres aspectos del proceso de construcción de los árboles en los cuales se podría introducir un componente de control: instancias, split y atributos. El trabajo con las instancias fue explorado en (Freund et al., 1996), con los split y los atributos se trabaja en (García-Borroto et al., 2015). En el trabajo presentado en (García-Borroto et al., 2015) se introduce un método de control de diversidad en el cual, los atributos que hayan formado parte de un árbol de decisión no pueden volver a utilizarse para construir los arboles de decisión siguientes. Este algoritmo tiene un inconveniente, para bases de datos con pocos atributos, el conjunto de árboles que puede construirse es muy pequeño. Además, ha demostrado ser menos eficaz que los métodos para construir bosques de decisión que generan diversidad a través de los split. Por ello, se consideró que podría realizarse una mayor investigación en la cual los atributos fueran el centro de atención.
Teniendo en cuenta lo planteado en estos trabajos se desarrolló el algoritmo Proactive Forest presentado en (Cepero-Perez et al., 2018). El algoritmo Proactive Forest construye el bosque de manera secuencial. En cada iteración se construye un árbol de decisión, luego se calcula la importancia de los atributos en el bosque construido hasta el momento y se actualizan las probabilidades de los atributos de acuerdo a su importancia. De esta forma se logra balancear el impacto de los atributos más relevantes en el bosque de decisión y con ello se genera una diversidad más controlada (Cepero-Perez et al., 2018).
Se realizaron varios experimentos en los cuales se determinaron los factores que estarían presentes en la función de actualización y por tanto afectarían como se realiza la actualización de probabilidades. Los factores identificados son (Cepero-Perez et al., 2018):
alpha, es el parámetro de diversidad que define cuán rápido se quiere que las probabilidades de los atributos más importantes disminuyan.
iter/cant árboles, es el control de construcción que se utiliza para que la actualización de las probabili dades se haga en correspondencia con el proceso de construcción del bosque.
Inicialmente el valor de alpha fue definido en 0.1, pero del mismo modo en que no se puede definir que un clasificador sea mejor que otro porque en dependencia del tipo de problema uno obtiene mejores resultados que otro, se plantea la necesidad de analizar experimentalmente el impacto de alpha en la eficacia de la clasificación. Partiendo de la idea de que no es correcto fijar este valor para todos los problemas.
Análisis sobre la generalización del parámetro de diversidad
Para realizar los experimentos se utilizaron bases de datos de diversas características extraídas del reposi torio UCI Machine Learning, las cuales son consideradas estándares para evaluar soluciones de aprendizaje automático (Dheeru and Karra Taniskidou, 2017). Las bases de datos contienen desde 3 hasta 64 atributos, desde 2 hasta 26 clases y desde 106 hasta 20000 instancias. En la Tabla 1 se presentan con más detalles las características de las bases de datos utilizadas.
En los análisis se utiliza la validación cruzada para evaluar la eficacia de la clasificación, en el impacto de la generalización del parámetro de diversidad del algoritmo Proactive Forest, con k-iteraciones (k = 10), en la que los datos se separan en k subconjuntos, uno de los cuales se utiliza como conjunto de prueba y los restantes k-1 como datos de entrenamiento con el objetivo de que el proceso de validación sea más robusto. Esto garantiza que los resultados son independientes de la partición entre los datos de entrenamiento y los datos de prueba.
Tabla 1 Descripción de las bases de datos utilizadas.
| Base de Datos | Instancias | Atributos | Clases | Bases de Datos | Instancias | Atributos | Clases |
|---|---|---|---|---|---|---|---|
| Balance scale | 625 | 4 | 3 | Molecular | 106 | 58 | 2 |
| Car | 1728 | 6 | 4 | Nursery | 12960 | 8 | 5 |
| Cmc | 1473 | 9 | 3 | Optdigits | 5620 | 64 | 10 |
| Credit-g | 1000 | 20 | 2 | Page blocks | 5473 | 10 | 5 |
| Diabetes | 768 | 8 | 2 | Pendigits | 10992 | 16 | 10 |
| Ecoli | 336 | 7 | 8 | Segment | 2310 | 19 | 7 |
| Flags religion | 194 | 29 | 8 | Solar flare 1 | 323 | 12 | 6 |
| Glass | 214 | 9 | 6 | Solar flare 2 | 1066 | 12 | 6 |
| Haberman | 306 | 3 | 2 | Sonar | 208 | 60 | 2 |
| Heart-statlog | 270 | 13 | 2 | Spambase | 4601 | 57 | 2 |
| Ionosphere | 351 | 34 | 2 | Tae | 151 | 5 | 3 |
| Iris | 150 | 4 | 3 | Vehicle | 846 | 18 | 4 |
| KR-vs-KP | 3196 | 36 | 2 | Vowel | 990 | 13 | 11 |
| Letter | 20000 | 16 | 26 | Wdbc | 569 | 30 | 2 |
| Liver | 345 | 6 | 2 | Wine | 178 | 13 | 3 |
| Lymph | 148 | 18 | 4 | - | - | - | - |
Experimento: Análisis general del comportamiento de la eficacia
El objetivo de este experimentó es demostrar la variabilidad de la eficacia generada en dependencia del parámetro de alpha que se utilice. Para la ejecución del experimentó se utilizaron las bases de datos des critas anteriormente, para cada una se calculó la eficacia de su clasificación utilizando los valores de alpha desde 0.1 hasta 0.9. En el siguiente seudocódigo se muestra la secuencia de pasos a seguir para la ejecución del experimento:
entrada bases de datos a clasificar(datos) salida modelo de clasificación(modelo)
alpha
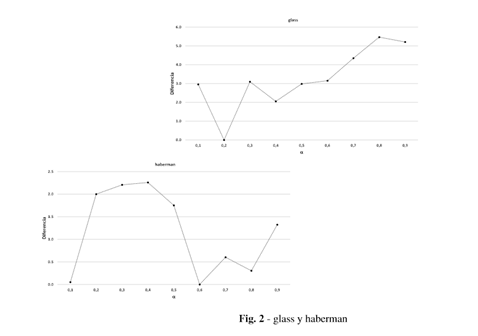
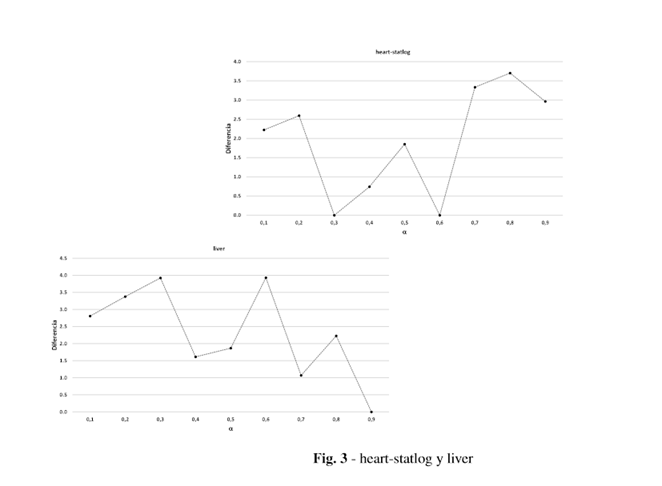
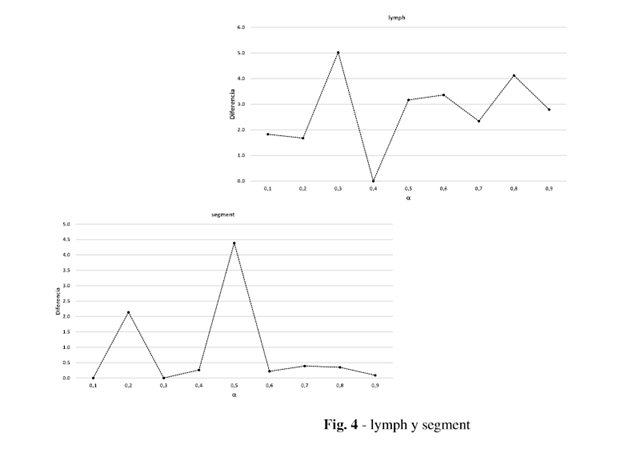
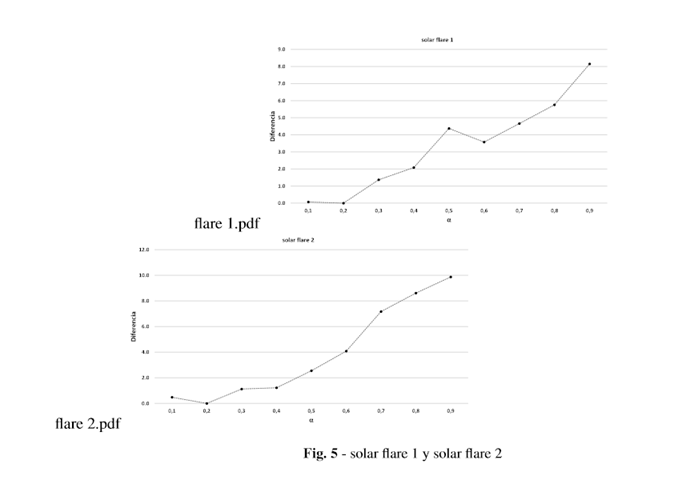
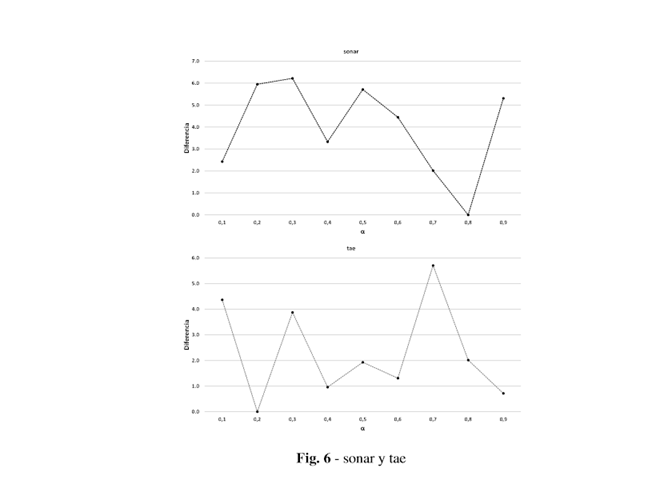
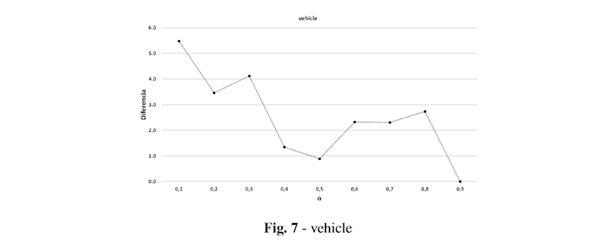
Posteriormente se seleccionó el mejor valor de eficacia generado por cada valor en cada base de datos y se calcularon las diferencias entre ese valor y los demás. En la Figura 1 se presentan una muestra de estas bases de datos, que evidencian la diferencia entre usar un valor de alpha u otro.
Resultados y discusión
El estudio experimental desarrollado permitió comprender el impacto real que tiene la definición del parámetro de diversidad en la eficacia de la clasificación. A continuación, se presentan los principales resultados obtenidos:
El comportamiento óptimo de alpha está estrechamente relacionado con las características de los datos, en función del conjunto de datos es mejor definir un valor u otro para alpha, cada problema de clasificación es diferente y la forma de resolverlo por tanto lo es; de ahí la importancia de definir un valor correcto de alpha en función del problema de clasificación a resolver.
Conclusiones
Para construir bosques de decisión eficaces se debe lograr que cada árbol de decisión individual tenga el mejor poder predictivo posible y que a su vez sea lo suficientemente diferente de los demás. La generación de la diversidad y la eficacia de la clasificación están estrechamente relacionadas por lo que es importante lograr un balance entre ambas para obtener mejores bosques. Los estudios presentados en este trabajo permitieron determinar que la generalización de un único valor para el parámetro de diversidad del algoritmo Proactive Forest no es correcto, debido a que cada valor tiene un comportamiento optimo en función del conjunto de datos que está procesando. Partiendo de estos estudios se desarrollará un mecanismo que permita aprender las características de las bases de datos y en función de esas características definir de manera automática que valor utilizar en la clasificación usando Proactive Forest.

