










 Servicios personalizados
Servicios personalizados Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCTION
Person re-identification (Re-id) aims to identify a person within camera networks, with non-overlapping viewpoints and in different moments. Also, the Re-id is categorized as single-shot (only a person image per camera is used) or multiple-shot (if multiple person image per camera are used). In real world, there is a great variety of smart video surveillance centers using Re-id algorithms to increase security in train stations, markets, public places, etc. However, in these places or scenes there are different conditions that affect the performance of the computer vision algorithms. General speaking, the Re-id is a challenge task. The problems are usually illumination changes (see Figure 1), pose, occlusion and low resolution (Kansal et al, 2019).
To face these issues aforementioned, in recent years the research has been focused in three aspects. First, to look for hand-crafted features that are robust to the illumination or pose changes (Liao et al, 2015). Second, to learn a metric (no euclidean) such as Mahalanobis distance where the difference inter-class increase and decrease the relation intra-class (Jia et al, 2017). Third, the features are automatically learned using deep learning based on convolutional neural networks (Wang et al, 2017).
Nowadays, in the Re-id algorithms have been applied different saliency detection methods. Saliency detection task aims to detect relevant information and reject the redundant information (Álvarez et al, 2018). Zhao (Zhao et al, 2013) use two independent methods to obtain salient region on person image based on KNN (K-Nearest Neighbor) and SVM (Support Vector Machine) of one class. Here, it is used different soft-features, as color histogram and SIFT (Scale Invariant Features Transformation). Niki (Niki et al, 2014) proposed to learn a distance function from a sub-set of multiple metric learning for features. A salient map is obtained based on graph theory and a color histogram is weighted. Huo (Huo et al, 2015), proposed a weight for the saliency direction trained with a SVM. Li (Li et al, 2018) extract optimal regions with high similarity from person image. After, the salient maps is built into these regions.
On the other hand, the use of the salient information obtained by traditional methods together with deep learning method has good results in the Re-id performance.Li (Li et al, 2018b proposed to learn a Harmonious Attention Convolutional Neural Networks for salient maps with global and local features. Rahimpour (Rahimpour et al, 2017) use a triplet architecture to deep learning where first block is used to obtain a salient map of the person and in second block is obtained the feature representation.
This paper is different to other works, because is developed a method for person re-identification based on detection of salient regions combined with deep learning without fine-tuning. It permits to obtain a final unsupervised salient map. For feature extraction are used the traditional methods. The major contribution of this work is a salient map to obtain a weighted person images (WPI) by the combination of two saliency maps, one from deep learning (VVG-F) and another from FqSD algorithm.
COMPUTATIONAL METHODOLOGY
Our Approach
The method is shown in Figure 2; a convolutional neural network is used to obtain a filter that represent a region salient in the image. This filter is combined with other salient map obtained from FqSD algorithm. Finally, a final salient map is used to weight the information in a person image.

Fig. 1 Samples of different pedestrians captured by two cameras on the VIPeR (Gray et al, 2007)and PRID2011 (Hirzer et al, 2011) datasets. First row is camera A and second row is camera B. Each column indicate the images of the same person.
Weighted Person Image
In deep learning is very known that last convolutional layer represents salient information of the image (Zeiler et al, 2011). The VVG-F is a model (Chatfield et al, 2014) from the Return of the Devil (CNN-F), which were trained with ImageNet dataset (1.2 million of images). During the step of training the filters are learned and named coefficient or weight. For general, these weights learned tend to show semantic information present in an image. In person re-identification, the datasets are homogeneous because only has person images. For the aforementioned the filters in last convolutional layer (in ours experiment are the filters in layer five) generally represent the salient regions of a person.
The VVG-F in layer five has 64 filters. We observe that specifically the filter 38 has the best representation of saliency for person image. The feature map (filter 38) is improved using the transforms, as follows:

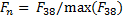 (1)
(1)
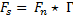 (2)
(2)
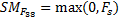 (3)
(3)
Where, F38 is the filter 38 in layer five using the VVG-F, Γ is a radial filter and (⋆) convolutional product. SMF38 is a salient map using filter 38.
Other method to obtain salient map used is the FqSD algorithm (Guerra et al, 2018). This algorithm is based on following aspect: a Gaussian pyramid is applied to get several images with low resolutions. All images are processed to build salient maps using spatial and frequency information in the domain of the quaternions. This algorithm has as output a salient object, we modified it to obtain a salient map of whole person image. In step of the image fusion of the FqSD algorithm is applied a normalization as follows:
 (4)
(4)
Where, SMFqSD is salient map obtained, IF is the salient map obtained in image fusion step from FqSD algorithm. To obtain a salient map improved, is necessary to make a fusion between each element obtained in SMF38 and SMFqSD as show the expression (5).
 (5)
(5)
Where, m and n are spatial coordinates of the image. Finally, SMI(m,n) is multiplied with each channel of the original image to obtain a weighted person image (WPI), see Figure 3.
Experimental design
Our goal is to validate the performance of the developed method on a complex person dataset, applying different mechanics in the extraction of features. VIPeR dataset: It has 1264 images of 632 persons, which were captured by two cameras in an outdoor academic environment. Only one image of the same person appear by camera (see Figure 1). Some characteristic challenges into dataset are: different pose, high illumination changes, background clutter and all person images have size 48x128. Also the images captured have variations from 0 degree to 90 degree (camera A) and from 90 degree to 180 degree (camera B).
To validate the performance of our method is applied the next protocol: The Cumulative Matching Characteristic curve (CMC) is used because provide rank-k recognition rate. The dataset is divided to apply the metric learning in training (316)/test (316) and all experiments were run 10 times. To learn a distance based on Mahalanobis are used Keep It Simple and Straightforward Metric (KISSME) (Koestinger et al, 2012) and Cross-view Quadratic Discriminant Analysis (XQDA) (Liao et al, 2015) approaches. KISSME is a method to obtain a distance from a statistical inference with equivalence constraints and XQDA is an extension of KISSME based cross-view quadratic discriminant analysis, where the metric is learned.
Implementation details: A feature vector (FV1) is formed from features map in VVG-F using the layer five. Before building the FV1 is realized a pre-processing to improve these maps as follows:

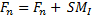 (6)
(6)
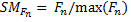 (7)
(7)
Where, Fn are the feature maps present in layer five, n :{ 1,…,64} and SMFn salient maps improved. After, each SMFn is divided into eight horizontal rectangular strips and a score (value of saliency) of this area is obtained. Finally, FV1 has a dimension of 512, note 8x64 = 512.
A second feature vector FV2 is built using color histograms and Local Binary Patterns (LBP). The color space used are RGB, HSV, normlizedRGB, Lab and Ycbcr. Note, that there are 15 channel, in each one is built a histogram of 256 bins. Moreover, to work with LBP is only used the color space RGB, HSV, normlizedRGB where is built a histogram by color channels but with 64 bins. Equal to FV1 the images are divided in eight regions, but are only used six regions (first and eighth regions are reject because there is not important information, for example, head and foot). The FV2 has a dimension of 35 328. In the methods (WIP + Original) is applied the FV1 and FV2 an original image and WIP.
RESULTS AND DISCUSSION
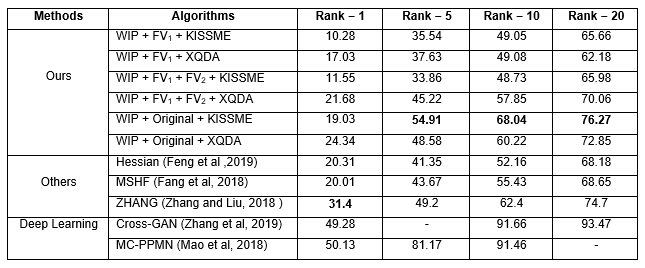
We can observe in table 1, using only FV1 that represent the salient information in each one feature maps of the layer five in VVG-F is obtained a value of 10.28% (KISSME) and 17.03% (XQDA) in rank-1. This result is possible by the intrinsic characteristics that there are in last layer where a similarity with the visual attention mechanism of the human brain has. When the FV2 is concatenated together with FV1 the best result is obtained applying XQDA metric with value of 21.68%, but using KISSME the increase in the values is not significant. This result is because the XQDA has major stability for large dimension vectors of features against KISSME especially for the first rank. On the other hand, is not always possible to ensure that the salient region can be visible in each camera viewpoint. We solve this using the combination (WIP + Original). Table 1 shows how the results increase up 19.03% (KISSME) and 24.34% (XQDA). However, the best results to ranks 1, 5, 10 and 20 is to KISSME metric and only rank 1 is to XQDA. In other words, is necessary work with original and WIP person images information to obtain robust features in different cameras.
The comparison with others state of the art algorithms shown that our proposal is competitive in terms of the CMC. Our results are among the last reports in Re-id. However, the best results are obtained with deep learning algorithms for person re-identification using training. Note that our proposal is used deep learning without training. The main advantage of the proposed method is to avoid a lot of training time and high dependence of amount data used. But, the disadvantage is the decrease in accuracy in the first rank of the CMC.
CONCLUSIONS
Without the need to perform a training or fine-tuning for use the VVG-F architecture was possible to extract features to implement a person re-identification algorithm. A final salient map of person image is obtained using a combination between the features maps in layer five of the VVG-F and the improved FqSD algorithm. The extraction features in original and WIP image is the best option to increase performance of the algorithm in VIPeR dataset. In future works, a new combination and feature descriptors will be to increase robust in different scenes. Further, an experiment will be developed with other datasets and different deep learning architectures.

