










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El Problema de Agregación de Rankings (RAP) es el proceso de combinar múltiples listas de rankings (anglicismo aceptado por la Real Academia de la Lengua Española), denominados “rankings base” en un solo ranking ordenado, denominado como “ranking agregado” que tiende a ser más confiable que los rankings base (Liu, 2019).
En los últimos años el razonamiento sobre la base de ordenamientos o rankings ha ganado gran atención debido a sus disímiles aplicaciones para solucionar problemas de toma de decisiones (Tao, 2019) y más recientemente, bioinformática (Galdi, 2019; Liu, 2019), metabúsquedas (Galdi, 2019), procesamiento del lenguaje natural (Onan & Korukoğlu, 2017), búsquedas web (Kaur, 2021), bibliometría (Subochev, 2018), entre muchas otras.
Para resolver el RAP se han planteado numerosas soluciones, mediante algoritmos como: Ramas y Cotas, (Ali & Meila, 2012) Método de Borda (Xiao, 2017), Método de Copeland (Lestari, 2018), algoritmos genéticos (Aledo, 2018) o First Order Then Append (FOTA) (Aledo, 2021).
Además, se ha estudiado la posibilidad de usar métodos exactos para su resolución (Ali & Meila, 2012), sobre todo, si se puede reducir la dimensión del problema sin afectar la solución, debido a que las dimensiones de estos problemas tienen una influencia directa en el tiempo de ejecución y los recursos necesarios para resolverlos. En este sentido, en (Rosete-Suárez, 2018) se presenta una reformulación del RAP para la solución a través de PLE que permite reducir de manera notable, tanto las variables como las restricciones del problema. Esto no cambia el orden de complejidad temporal del problema, pero crea posibilidades para enfrentar instancias mayores, con ahorro de recursos computacionales.
Por tanto, este trabajo se centra en demostrar cómo se reducen las variables a la mitad y restricciones a un tercio, aproximadamente, así como la influencia directa de la reducción de las variables y las restricciones en el tiempo de ejecución y los recursos necesarios para resolver el problema, a partir de la reformulación del problema de PLE planteada en (Rosete-Suárez, 2018).
El resto del documento está estructurado de la siguiente manera. A continuación, se define el RAP, además de la formulación de PLE para el RAP y la reformulación planteada en (Rosete-Suárez, 2018). Posteriormente, se presentan los resultados de los experimentos realizados que permiten evaluar la mejora en la eficiencia computacional de la solución del RAP. Por último, se dan a conocer las conclusiones del presente trabajo.
Métodos
El Problema de Agregación de Ranking (RAP, por sus siglas en inglés) tiene el objetivo de encontrar una permutación que minimiza la distancia respecto a un conjunto de rankings que se reciben como entrada (Chatterjee, 2018). En el RAP es usual representar el conjunto de rankings de entrada en una matriz que los resume a todos, comúnmente llamada Matriz de Precedencia (Aledo, 2021).
Problema de Agregación de Ranking (RAP)
Partiendo del hecho que existe una matriz P (Matriz de Precedencia), el RAP pueden ser resueltos a través del método de Programación Lineal Entera (PLE), produciendo una matriz binaria 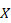 , donde cada celda
, donde cada celda  de la matriz indica la relación de precedencia entre el elemento “u” y el elemento “v”. Si celda
de la matriz indica la relación de precedencia entre el elemento “u” y el elemento “v”. Si celda 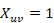 entonces “u” precede a “v” y 0 en el caso contrario. Entonces, el objetivo del problema RAP es (Rosete-Suárez, 2018):
entonces “u” precede a “v” y 0 en el caso contrario. Entonces, el objetivo del problema RAP es (Rosete-Suárez, 2018):
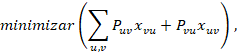
Sujeto a tres restricciones:
Restricción 1: 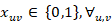
Restricción 2: 
Restricción 3: 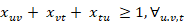
Reformulación del Problema de Agregación de Ranking (RAP)
En (Rosete-Suárez, 2018) se plantea una reformulación del RAP para su la solución por PLE, donde se reducen las variables y restricciones del problema original, planteado anteriormente. A continuación, se detalla la reformulación.
Para la reducción de variables es importante notar que realmente cada variable en la Restricción 2 es dependiente del valor de . Esto implica que se puede rescribir esta restricción de la manera siguiente:
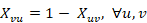
Esto trae consigo dos implicaciones directas. Primero, se elimina la Restricción 2, porque ya no habría que comprobar su cumplimiento (no es posible incumplirla). Segundo, se reduce a la mitad la cantidad de variables, debido a que basta con representar los casos donde u < v, ya que el resto de casos son calculables. De tal forma que ahora la función objetivo podría transformarse de la forma siguiente:
Donde:
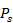 es un valor constante que se corresponde con la suma de los elementos del triángulo superior de la matriz
es un valor constante que se corresponde con la suma de los elementos del triángulo superior de la matriz 
Por otro lado, a partir de un análisis en detalle de la Restricción 3, donde se observa que siguiendo el razonamiento que llevó a la reducción de las variables, ahora se podría expresar en función de las variables 
De esta manera, se reducen a dos restricciones de la forma siguiente para cada una de las combinaciones (u, v, t) tales que u < v, < t.
Diseño experimental
Para comprobar la influencia que tiene la reformulación previamente descrita en la eficiencia de la solución de PLE del RAP, se diseñó un experimento basado en medir la eficiencia computacional de ambas formulaciones en 50 conjuntos de datos (dataset) de rankings reales disponibles en (Mattei & Walsh, 2013). En particular, se descargaron ficheros pwg asociados a los siguientes conjuntos de “Datos de Elección”: ED-00006-Skate Data (3-4, 11-12, 18, 28, 46, 48), ED-00011-Web Search (1-2), ED-00014-Sushi Data (1) and ED-00015-Clean Web Search (1-4, 7, 9,12, 14, 16-20, 23-25, 27, 29-30, 32, 34, 40-42, 44, 46, 48, 50, 54, 55,57, 59, 65-66, 67, 69, 73, 74, 77).
Todos los experimentos fueron realizados en un ordenador personal con un procesador Intel i7 - 4790, 3.60 GHz, 4 núcleos y 4GB de memoria RAM.
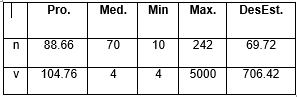
Una descripción general de estos ficheros se muestra en la Tabla 1. Por cada conjunto de datos, se muestra el promedio (Pro), la mediana (Med), los valores mínimos (Min) y máximos (Max) y la desviación estándar (DesEst) del número de elementos del conjunto de rankings a agregar (n) y la cantidad de votantes (v).
Para realizar los experimentos fue necesario implementar varios nodos para la herramienta de minería de datos KNIME (Universidad de Constanza, 2020) que permiten cargar los ficheros PWG y a partir de ellos, generar modelos de PLE para ser ejecutados en dos de las herramientas de software libre que solucionan problemas de optimización (comúnmente llamados “solvers”): LiPS (KONOBEY, 2019) y SCIP (Z. I. Berlin, 2017).
Resultados y discusión
En esta sección se presenta el resultado experimental de las comparaciones entre el Método de Programación Lineal Entera (MPLE) y la Reformulación del Método de Programación Lineal Entera (RMPLE) en cuanto a variables y restricciones. De igual forma, se muestra la factibilidad de resolver con cada uno de los softwares (LiPS y SCIP) los modelos de PLE generados desde los nodos de KNIME desarrollados. Por último, se muestra una comparación entre los tiempos empleados en cada par instancia-solver.
Reducción de variables y restricciones
La Tabla 2 muestra para cada fichero PWG una comparación entre la cantidad de variables para MPLE (v_vn) y la cantidad de variables para RMPLE (v_vr). Además, se comparan la cantidad de restricciones para MPLE (r_vn) y la cantidad de restricciones para RMPLE (r_vr).
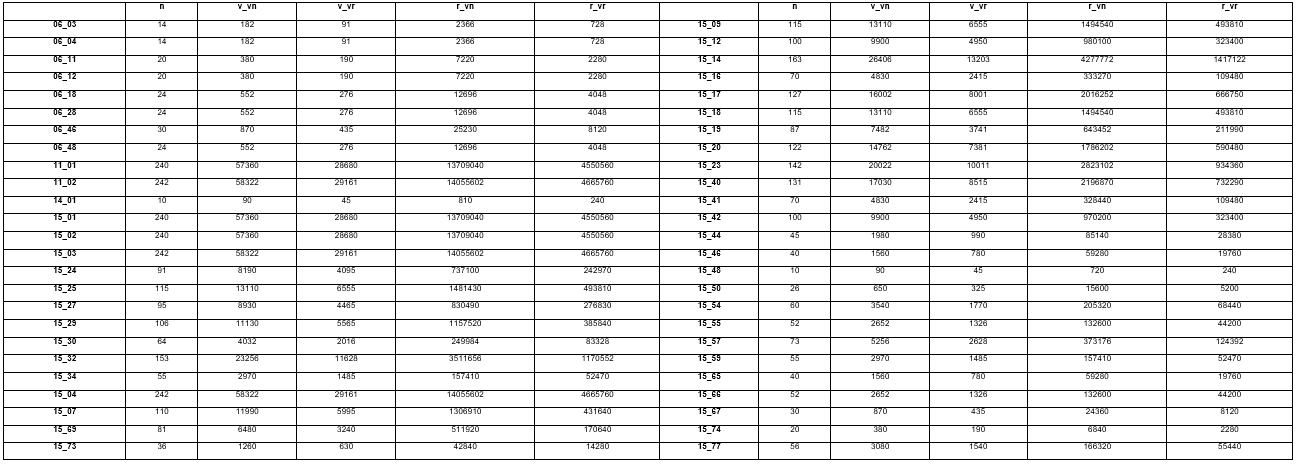
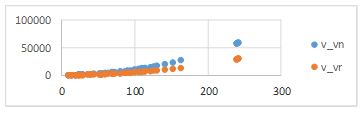
Las Figura 1 y la Figura 2 muestran un gráfico comparativo del crecimiento de la cantidad de variables y restricciones, respectivamente, para MPLE y RMPLE.
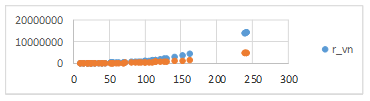
La Figura 3 muestra un gráfico comparativo, con la proporción de la reducción de variables y restricciones en RMPLE según crece n.
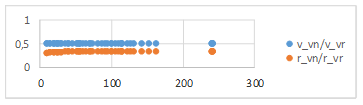
Como se puede apreciar en la tabla comparativa y en los gráficos, con la RMPLE se logra una reducción de la mitad de variables con respecto al MPLE y aproximadamente un tercio de las restricciones.
Influencia en la factibilidad para resolver cada instancia con LiPS y SCIP
La Tabla 3 muestra los valores mínimos (min) y máximo (max) de la cantidad de elementos a ordenar (n), la cantidad de variables (v) y la cantidad de restricciones (r) que se pudieron resolver con LiPS y SCIP respectivamente. Además, se puede apreciar el total de instancias resultas (t) para cada formulación y el porciento (%) que representa del total de instancias.

Como se puede apreciar en la Tabla 3, usando LiPS la reformulación permitió resolver instancias con hasta 24 elementos, mientras que la formulación original solo permitía llega hasta 10. En tanto, con SCIP llegaron a resolver instancias con 240 elementos mientras que la formulación original llegaba hasta 163 elementos.
Influencia en el tiempo para resolver cada instancia con LiPS Y SCIP
La Tabla 4 muestra una comparación en cuanto al tiempo de solución (en segundos) de cada una de las instancias con LiPS para MPLE (LiPS_tvn) y RMPLE (LiPS_tvr) y con SCIP para MPLE (SCIP_tvn) y RMPLE (SCIP_tvr). Las celdas con espacios en blanco son resultado de instancias que no se le pudo dar solución con el solver debido a sus dimensiones.
Tabla 4 Tiempo de solución de cada instancia (en segundos) con LiPS y SCIP para MPLE y RMPLE respectivamente.
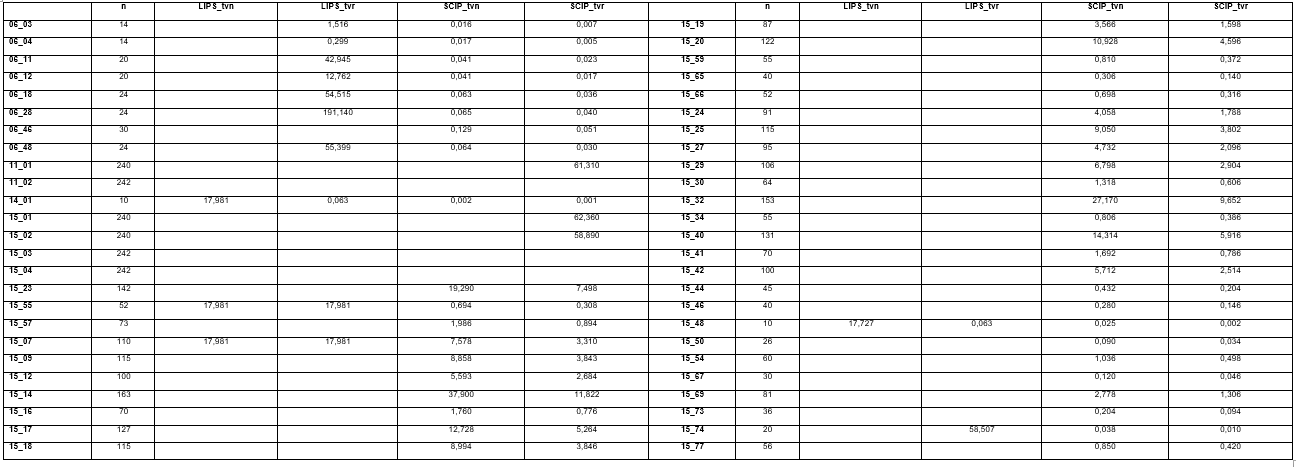
Como se puede apreciar en la tabla 4, se pudieron resolver las mismas instancias en un menor tiempo, o sea, las instancias en las nueva formulación se resolvieron empleando menos del 5% del tiempo para LiPS y menos del 50% para SCIP.
Las Figura 4 y Figura 5 muestran una comparación entre LiPS y SCIP, en cuanto a los tiempos (en segundos) que se demoraron en dar solución a los modelos.
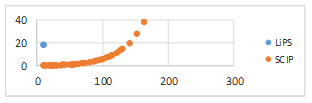
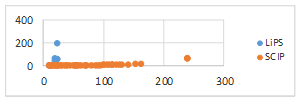
Como se aprecia en la Figura 4 y la Figura 5, el tiempo de ejecución para RMPLE de los modelos aumenta de manera menos notable que el tiempo de ejecución de los modelos para MPLE. Este comportamiento demuestra la mayor eficiencia de RMPLE con respecto a MPLE para ejecutar modelos con un mayor número de elementos del conjunto de rankings a agregar.
Conclusiones
A partir de los experimentos realizados, se puede observar, en primer lugar, cómo el Método de Programación Lineal Entera permite resolver instancias de hasta 10 elementos del conjunto de rankings a agregar usando LiPS y de hasta 163 usando SCIP, mientras tanto, la Reformulación del Método de Programación Lineal Entera, permite resolver instancias con un notable aumento del número de elementos del conjunto de rankings a agregar, hasta 24 usando LiPS y 240 usando SCIP.
Además, en cuanto al tiempo de ejecución de las instancias, también se puede observar que con la Reformulación del Método de Programación Lineal Entera hay una notable mayor eficiencia de las herramientas LiPS y SCIP para resolver cada una de las instancias, ya que a medida que aumentan los elementos del conjunto de rankings a agregar hay un notable aumento del tiempo con el Método de Programación Lineal Entera, sin embargo, no se hace tan notable el aumento del tiempo al analizar los resultados obtenidos con la Reformulación del Método de Programación Lineal Entera.
Entonces, teniendo en cuenta todos los resultados, quedan claras las ventajas de la Reformulación del Método de Programación Lineal Entera para resolver el Problema de Agregación de Rankings con menos recursos computacionales, o bien, resolver instancias que anteriormente no era posible resolver.

