










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkACIMED
versión impresa ISSN 1024-9435
ACIMED v.21 n.3 Ciudad de La Habana jul.-sep. 2010
Scopus: la mayor base de datos de literatura científica arbitrada al alcance de los países subdesarrollados
Scopus:The largest database of peer-reviewed scientific literature available to underdeveloped countries
Rubén Cañedo AndaliaI; Roberto Rodríguez LabradaII; Marilis Montejo CastellsIII
ILicenciado en Información Científico-Técnica y Bibliotecología. Departamento Fuentes y Servicios de Información. Centro Nacional de Información de Ciencias Médicas-Infomed. La Habana, Cuba.
IILicenciado en Microbiología. Departamento de Neurofisiología Clínica. Centro para la Investigación y la Rehabilitación de las Ataxias Hereditarias. Holguín, Cuba.
IIITécnico Medio en Información Científico Técnica y Bibliotecología. Centro Provincial de Información de Ciencias Médicas de Holguín. Universidad de Ciencias Médicas de Holguín "Mariana Grajales Coello". Holguín, Cuba.
RESUMEN
Scopus es la mayor base de datos de citas y resúmenes de literatura arbitrada y de fuentes de alta calidad en el Web. Aunque se distribuye mediante suscripción, se encuentra disponible con ciertas limitaciones para los países subdesarrollados por medio de Hinari. A pesar del carácter multidisciplinario de su colección, sus fondos comprenden más de 4 300 revistas en ciencias de la vida y más de 6 800 títulos en ciencias de la salud. Entre sus opciones para la búsqueda bibliográfica, se encuentran la búsqueda por autor y la afiliación de este, así como la búsqueda simple por palabras y frases clave en los campos Título del artículo, Resumen y Palabras clave y la búsqueda avanzada. El presente y el futuro tecnológico inmediato de Scopus se caracterizan por su integración con otros productos clave de Elsevier, como son ScienceDirect y Scirus, con el objetivo de evitar la duplicación del esfuerzo de los investigadores en las labores de búsqueda de la información y acelerar el avance de las investigaciones. El acceso a Scopus por la vía de Hinari coloca a disposición de los países subdesarrollados un poderoso recurso bibliográfico de gran utilidad en las áreas de las ciencias de la salud y de la vida, estas últimas de especial importancia para el desarrollo de las ciencias clínicas en el contexto actual.
Palabras clave: Bases de datos, bibliografía, ciencias de la salud, ciencias de la vida.
ABSTRACT
Scopus is the largest database of citations and abstracts of refereed literature and high quality sources on the Web. Although it is distributed by subscription, is available with certain limitations for developing countries through Hinari. Despite the multidisciplinary nature of its collection, this includes more than 4300 journals in life sciences and more than 6800 titles in health sciences. Among his options for the literature search are searching by author and the author's affiliation, as well as the simple search by key words and phrases in the fields item: Article title, Abstract and Keywords and advanced search. The present and the immediate technological future of Scopus are characterized by its integration with other key products of Elsevier such as ScienceDirect and Scirus, with the aim of avoiding duplication of effort by researchers in the work of finding information and accelerate the advancement of research. Scopus access to the path of Hinari makes available to developing countries a powerful useful bibliographic resource in the areas of health and life sciences, the latter of particular importance for the development of clinical sciences the current context.
Key words: Databases, bibliography, health sciences, life sciences.
Scopus, creada en 2004 por Elsevier B. V., es la mayor base de datos de citas y resúmenes de literatura arbitrada y de fuentes de alta calidad en el Web. Cubre cerca de 18 000 publicaciones seriadas de más de 5 000 casas editoras; 16 500 son revistas arbitradas. Contiene más de 40 millones de registros procedentes de publicaciones seriadas (revistas y series monográficas) y comerciales. Presenta, además, una extensa cobertura de materiales de conferencias (más de 3,6 millones), páginas Web en Internet (unos 318 millones) y patentes (23 millones). A pesar del carácter multidisciplinario de su colección, sus fondos comprenden más de 4 300 en ciencias de la vida y más de 6 800 títulos en ciencias de la salud (alrededor de un 70 %). La retrospectividad del procesamiento de los artículos y sus referencias (necesarias para los análisis de citación) se remonta al año 1996, aunque existe una gran cantidad de artículos fuentes (es decir, sin sus referencias) de fechas anteriores.1
Scopus es la alternativa europea al monopolio que durante más de 40 años ejercieron las bases de datos del antiguo Institute for Scientific Information (ISI -actual Thomson Reuters) en el área de los estudios de citación en el contexto científico internacional, y desde entonces ha suscitado gran interés entre investigadores y académicos, tanto por su cobertura documental como por su amigable interfaz y sus múltiples prestaciones.2 Posee herramientas inteligentes para seguir, analizar y representar el comportamiento de la actividad en la ciencia, en especial con respecto a su consumo, a partir del empleo de los datos de citación de las obras y los autores. Precisamente por esta razón se ha convertido en una contrapartida y competidor de los productos y servicios creados por el ISI.
Si se toma como punto de referencia el universo de revistas científicas arbitradas que componen el Directorio internacional de publicaciones seriadas Ulrich's, el Web of Science procesa solo el 25 % de ellas, mientras que Scopus abarca el 50 %.3,4 El hecho de poseer una mayor cobertura documental otorga a la base de datos europea cierta ventaja competitiva con respecto a su homóloga norteamericana. Sin embargo, la retrospectividad de esta última es mucho mayor y alcanza el año 1900. Scopus procesa el 95 % de las fuentes que ingresan al Web of Science,5 y el ciento por ciento de lo indizado por Medline (Medline a su vez, comprende más del 90 % del total de registros existentes en PubMed),1 la base de datos bibliográfica de literatura médica más utilizada a escala mundial.a Scopus procesa también prácticamente el total de las revistas publicadas por Biomed Central.
Scopus, aunque se distribuye mediante suscripción, se encuentra disponible con ciertas limitaciones para los países subdesarrollados por medio de Hinari, un amplio programa de la Organización Mundial de la Salud y sus organismos asociados, para mejorar el acceso de las instituciones de los países en vías de desarrollo a la información científica al facilitar la consulta libre de los textos completos de miles de revistas arbitradas con información actualizada en el sector de la salud.
Es nuestro propósito con esta contribución exponer, de una forma lo más sencilla posible, la secuencia de pasos necesarios para ejecutar la búsqueda de información de manera efectiva en la base de datos Scopus a través de Hinari, así como exponer el presente y el futuro tecnológico inmediato de la referida base de datos.
LA BÚSQUEDA BIBLIOGRÁFICA EN SCOPUS
A Hinari se accede en Cuba desde la página de Infomed (http://www.sld.cu/). Su enlace se encuentra en el cuadro de Esenciales, que aparece al principio de la columna izquierda de la referida página (figura 1).
Una vez cargada la página de Hinari, debe seleccionarse la opción Scopus (Elsevier) del menú desplegable Database and article searching (figura 2). En unos segundos se nos presentará la página inicial de Scopus (figura 3).
Como puede observarse desde el principio, el sistema ofrece diversas facilidades para la opción de búsqueda (Search) como son la búsqueda por autor (Author Search); la búsqueda por la afiliación del autor (Affiliation Search); la búsqueda simple por palabras y frases clave en los campos Título del artículo, Resumen, Palabras claves (Article Title, Abstract, Keywords); posibilidades para limitar por fecha de publicación y de introducción de los artículos fuentes a la base de datos, por tipo de documento y por grandes áreas temáticas; así como una opción para la búsqueda avanzada (Advanced Search). Posibilita el uso de operadores lógicos (AND, OR, AND NOT) y de proximidadb (PRE/n y W/).
Antes de comenzar a trabajar, y como debemos hacer siempre que los sistemas nos ofrezcan esta posibilidad PubMed y Ebsco, por ejemplo, lo permiten debemos registrarnos como usuarios; esto con frecuencia facilita el acceso a más opciones que a las que pueden acceder los usuarios no registrados, y en general viabiliza el trabajo con los sistemas y recursos.
Ahora bien, con frecuencia quienes conocen menos sobre el uso de las bases de datos utilizan la opción de búsqueda simple o básica. Esto, aunque puede parecer mucho más fácil al principio, tiene también un alto costo en relación con la precisión de los resultados, ya que sus facilidades como interfaz de búsqueda son menores en general. Por eso utilizaremos para la exploración la búsqueda avanzada.
Según las posibilidades que ofrece el sistema para la búsqueda temática, existen tres opciones: emplear solo los términos de indización (INDEXTERMS); utilizar palabras o frases clave en los tres campos que ofrece la base de datos por omisión (TITLE-ABS-KEY) o usar una combinación de ambas (anexo). La decisión, obviamente, dependerá de los requerimientos de las necesidades de los usuarios. La primera opción incrementa significativamente la precisión de los resultados recuperados. Más del 80 % de los materiales procesados para la base de datos Scopus se indiza por profesionales dedicados a esta tarea. En el caso de los materiales pertenecientes a las áreas de las ciencias de la vida y de la salud, se utilizan los tesauros ENTREE utilizado en la indización de los registros de EMBASE,6 la contraparte europea de Medline de Elsevier y MeSH de la Biblioteca Nacional de Medicina de los Estados Unidos.
El uso de los términos controlados aumenta sustancialmente, sin duda, la precisión de los resultados de la búsqueda; pero también puede dejar fuera muchos registros donde el tema recibe un tratamiento colateral, por la existencia de políticas de indización que concentran los esfuerzos de esta actividad en los temas centrales que tratan los documentos. La segunda opción, de palabras y frases clave, de forma general aumenta el recobrado pero disminuye la precisión de los resultados de la búsqueda, y requiere como prerrequisito importante el conocimiento de las formas más comunes con las que se describe la entidad buscada para elevar la cantidad de registros recuperados y evitar la pérdida de información de utilidad como consecuencia de los efectos indeseables de la sinonimia que caracteriza a los lenguajes naturales. El campo KEY, por su parte, combina las palabras clave asignadas por el autor, los términos de indización, los nombres comerciales de productos y servicios y los nombres químicos. La última alternativa, en el caso de términos de indización que comprenden un concepto o condición mucho más amplia que lo que se busca en realidad, sirve para aumentar la precisión de los resultados. Veamos un ejemplo que hemos estado utilizando en los últimos tiempos: el caso de la ataxia espinocerebelosa tipo 2.7 En el estudio realizado se encontraron las formas principales en que se trata esta entidad, a saber:
- SCA2
- SCA 2
- Spinocerebellar ataxia 2
- Spinocerebellar ataxia type 2
- Type 2 spinocerebellar ataxia incluye la subforma Type-2 spinocerebellar ataxia
Esto nos permitiría, de acuerdo con las exigencias de una primera exploración y los recursos que nos ofrece Scopus, plantearnos una estrategia de búsqueda como la siguiente:
TITLE-ABS-KEY("SCA2") OR TITLE-ABS-KEY("SCA 2") OR TITLE-ABS-KEY("Spinocerebellar ataxia 2") OR TITLE-ABS-KEY("Spinocerebellar ataxia type 2") OR TITLE-ABS-KEY("Type 2 spinocerebellar ataxia").
Esta, a todas luces, produce una mayor cantidad de registros aún cuando los resultados de la búsqueda en general sean menos precisos. Por eso, como se dijo antes, la elección depende de los requerimientos de las necesidades. En este caso, como puede observarse, se utilizó la búsqueda por palabras y frases clave del lenguaje natural. Como se dijo, una primera búsqueda puede exigir una mayor exhaustividad que las siguientes en un mismo tema.
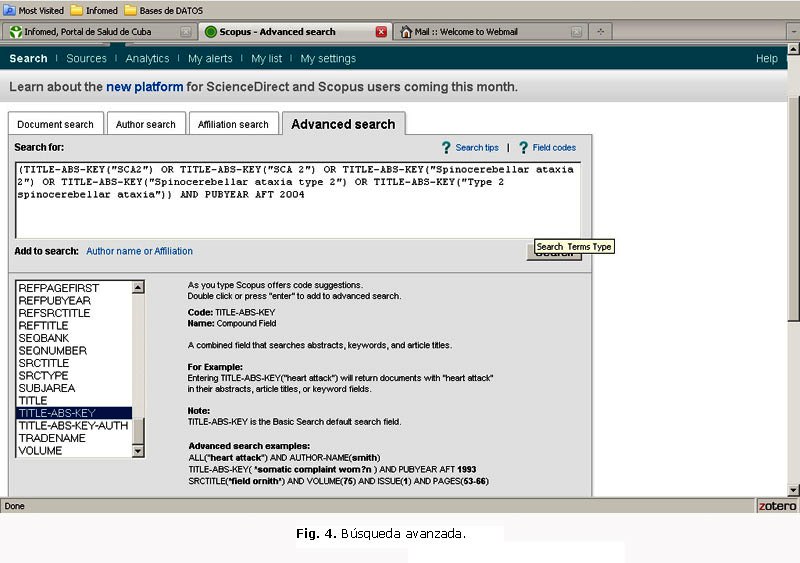
Una vez determinado el contenido temático, es posible seleccionar las fechas de los documentos, los idiomas, el tipo de material, su fuente, la afiliación del autor, los países, entre otros aspectos, todo eso a partir de una potente estructura de campos y la ayuda pertinente que presenta Scopus al usuario. Limitemos sencillamente nuestra búsqueda a los últimos cinco años (2005-2009); introduzcamos entonces la siguiente estrategia para la exploración (figura 4).
(TITLE-ABS-KEY("SCA2") OR TITLE-ABS-KEY("SCA 2") OR TITLE-ABS-KEY("Spinocerebellar ataxia 2") OR TITLE-ABS-KEY("Spinocerebellar ataxia type 2") OR TITLE-ABS-KEY("Type 2 spinocerebellar ataxia")AND PUBYEAR AFT 2004.
Y recordemos que el ingreso completo de una gran parte de los documentos de un año específico a una base de datos puede ocurrir meses después de concluido dicho año. Scopus, por ejemplo, advierte que la mitad de los documentos que debían ingresar a la base durante el 2009 está aún pendiente.
El sistema en unos pocos segundos nos devuelve los resultados de la búsqueda realizada: un total de 241 referencias (8 de septiembre de 2010; 11:00 am), además de un número indeterminado de sitios Web y patentes (figura 5). La pantalla se divide en dos partes. En la primera, una especie de recuadro, aparecen organizados en forma descendente, según su frecuencia de aparición: los títulos de las revistas, los autores, los años, las afiliaciones de los autores y las áreas temáticas. En este mismo recuadro, mediante la opción Add categories, pueden obtenerse los índices de frecuencia de idioma (Languaje), tipo de documento (Document type: artículo, revisión, carta, etc.), palabras clave (Keyword) y clase de fuente (Source type: revista, serie monográfica, material de conferencia, etc.). Esto constituye un soporte importante para un análisis métrico más profundo, no obstante sus limitaciones, así como para refinar los resultados de la búsqueda en caso necesario a partir de las opciones () Limit to y Exclude. El sistema ofrece la posibilidad de mostrar (Display) en la pantalla hasta 160 registros.
La primera columna ofrece una información muy útil. Se trata de un índice de frecuencia de los títulos de revistas organizados en forma descendente según su productividad para el tema objeto de exploración. Esto sirve tanto a autores y lectores como a los profesionales de la información. Conocer cuáles títulos de revistas publican con mayor frecuencia en un área de interés sirve a los autores para determinar cuáles revistas son las más apropiadas para difundir sus trabajos; a los lectores, para enfrentarse a un sistema como Hinari, donde esta es una información imprescindible para explorar con eficacia su extensa colección de revistas (más de 7 000), pues el sistema carece de una interfaz única de búsqueda que posibilite la exploración completa de la referida colección de una sola vez, y a los gestores, consultores, referencistas o consejeros en temas de información y publicación, para orientar a sus usuarios sobre cuáles son las fuentes que mejor pueden servirle en ciertos campos del conocimiento a partir de una base de datos tan amplia como Scopus.
Otros índices, a pesar de los esfuerzos hechos por los creadores de la base de datos, son incapaces de eliminar totalmente los denominados problemas de uniformidad y normalización que, como hemos dicho en otras ocasiones, afectan de manera particular a los autores hispanos. Así tenemos un caso antes referido,7 el del Doctor Luís Velázquez Pérez, que aparece en los primeros 50 registros bajo las formas: Velazquez L (11) y Velazquez-Perez, L (6). Si la normalización fuera la correcta, este autor aparecería empatado en la primera posición con un reconocido experto en la materia: Auburger, G. Algo similar sucede con la afiliación.
En la sección Document results, es posible mostrar junto con las referencias sus resúmenes (Show all abstracts). La barra de opciones que encabeza esta sección permite descargar simultáneamente los textos completosc de las referencias seleccionadas por el usuario en PDF (Download PDF), así como exportar (Export) a un gestor bibliográfico, imprimir (Print), enviar por correo electrónico (Email), crear una bibliografía (Create bibliography) o añadir temporalmente a My List (Add to My List) las referencias escogidas de la relación que presenta el sistema como resultado de la exploración realizada. Además, posibilita obtener información general sobre la citación de uno o varios documentos seleccionados (View citation overview), una lista de las citas recibidas por ellos (View citations) siempre que el valor de la casilla correspondiente al número de citas recibidas por el documento (Citations) sea diferente de cero, así como una relación de las referencias utilizadas por los autores del documento (View references). Estas opciones son especialmente útiles cuando un usuario desea observar el comportamiento que presenta un documento con respecto a su citación o las referencias que se utilizaron en su elaboración. Estas referencias pueden "abrirnos" nuevos caminos hacia la exploración de ciertos aspectos de interés en las áreas temáticas exploradas o facilitarnos la adquisición de bibliografía en el tema central de la búsqueda.
Muchas de las referencias recuperadas ofrecen la posibilidad de acceder al texto completo del artículo mediante la opción View at publisher. Pero eso no significa necesariamente un acceso libre al texto completo del material. En caso de que sus distribuidores exijan la compra, es posible que dicho texto pueda obtenerse a partir de sus datos de referencia en la listas alfabéticas de títulos de revistas que ofrece el propio Hinari en forma libre o mediante el envío de un mensaje de solicitud a alguno de los autores de la contribución que nos interesa.
Al concluir los ajustes necesarios para perfeccionar la estrategia de búsqueda, es posible mediante la opción Set alert (requiere que el usuario se registre previamente en el sistema), ubicada a continuación de la posición que ocupa la estrategia de búsqueda a inicios de la página crear un servicio de alerta que periódicamente nos avisará (diaria, semanal o mensualmente) del ingreso de nuevas referencias a la base de datos que satisfacen nuestra condición o estrategia de búsqueda (figura 6). A diferencia del servicio de alerta, el RSS envía diariamente a nuestro lector de RSS las últimas 20 referencias que ingresaron a la base de datos que cumplen la condición de búsqueda, algo que en el caso de la temática tratada es innecesario por tener un lento crecimiento.
EL PRESENTE Y EL FUTURO TECNOLÓGICO INMEDIATO DE SCOPUS
El 28 de agosto del año en curso, Elsevier presentó SciVerse Hub (figura 7), una plataforma que integra además de los fondos de Scopus (ahora SciVerse Scopus), la colección de ScienceDirect y los contenidos Web de Scirus.8
ScienceDirect
ScienceDirect (ahora SciVerse ScienDirect), fundado en 1999, es un archivo digital multidisciplinario que atesora más de 10 millones de artículos arbitrados a texto completo y partes de libros, procedentes esencialmente de las más de 2 500 revistas (y miles de libros), publicadas por Elsevierd, y un grupo de editoriales e imprentas asociadas, como son: Academic Press, American Psychological Association, Churchill Livingstone, The Clinics of North America, Pergamon, entre otras. En Cuba, a este recurso puede accederse desde el dominio .sld.cu a través de Hinari, específicamente desde el menú SELECT PUBLISHER Elsevier ScienceDirect desde Hinari. Comprende más de una cuarta parte del total de los artículos arbitrados, disponibles a texto completo, publicados en ciencia, tecnología y medicina a escala mundial. Abarca, además, miles de partes de libros electrónicose. Aunque de manera general su retrospectividad alcanza el año 1995, pueden encontrarse artículos publicados antes; esto obedece con frecuencia a la importancia de la revista. ScienceDirect ingresa anualmente alrededor de medio millón de nuevos registros.9
Scirus
Scirus, creado en 2001, es el mayor motor de búsqueda específico de literatura científica en Internet. Posee una colección de más de 410 millones de documentos, integrada, no solo por artículos y otras clases de informes científicos, sino también por patentes (más de 24 millones), informes técnicos y tesis, entre otros. Comprende los más de 10 millones de documentos procesados en la colección de ScienceDirect. En el área de la salud cubre sitios tan importantes como Medline, MD Consult y Biomed Central. El posicionamiento de los sitios o clasificación, es decir, el orden en que estos se listan cuando se realiza una búsqueda, obedece a la frecuencia y ubicación en el documento de los términos solicitados, así como al número de enlaces que recibe la página de otros sitios. A Scirus se accede en forma completamente libre en http://www.scirus.com/.10
NUEVAS HERRAMIENTAS
La cooperación con NextBio ha permitido a Elsevier desarrollar en Sciverse ScienceDirect un servicio único de indización y correlación semántica que provee a los investigadores de los campos de las ciencias de la vida, las ciencias médicas y la química, de las herramientas necesarias para buscar, descubrir, comparar y compartir conocimientos provenientes de diversos recursos, antes sin posibilidad de integración alguna entre ellos.11
Sciverse Hub incorpora ahora tres herramientas nuevas (figura 8):
- La búsqueda de oraciones y párrafos (Matching Sentences).
Asimismo, ahora es posible, identificar (se resaltan automáticamente) las oraciones y párrafos de cada documento recuperado que contienen los términos utilizados en la exploración y esto, sin duda, permite la revisión rápida y la extracción de las ideas fundamentales expuestas, como dijimos, en una colección de oraciones y párrafos relevantes a la estrategia de búsqueda empleada. Se simplifica así la tarea de determinar en cada texto de interés, las partes e ideas de mayor relevancia para el lector.12
- La búsqueda en la sección de Métodos de los artículos (Methods Search).
Entre las nuevas facilidades se destaca la posibilidad de realizar la búsqueda de los términos y frases clave sólo en la sección de Métodos, de los artículos (NextBio facilita también a través de su motor de búsqueda, la correlación de los términos semánticamente significativos en un documento con la información sobre enfermedades, compuestos químicos, tejidos, genes y otras en bases de datos como PubMed, Gene, OMIN… y diversas fuentes de información).
- La identificación de los autores más productivos en los temas de búsqueda solicitados.
SciVerse Hub, además de facilitar a los usuarios la búsqueda bibliográfica a partir de una sola interfaz, permite integrar sus resultados y eliminar las duplicaciones resultantes de la búsqueda por separado en cada uno de ellos.
Pero SciVerse Hub es solo uno de los componentes de un proyecto en curso mucho más amplio y ambicioso denominado SciVerse, que acomete la propia Elsevier, con el propósito de contribuir a solucionar el difícil problema que enfrentan actualmente los científicos para extraer las ideas fundamentales, la esencia, los patrones y las tendencias ocultas bajo un cúmulo inmanejable de información a texto completof; mediante la integracióng en una sola plataforma de herramientas para el descubrimiento del conocimiento y la clasificación, interpretación, síntesis, interrelación y visualización de la información que responde al interés del usuario. Son múltiples los recursos de información pero escasean las plataformas para usuarios capaces de integrar e interrelacionar dichos recursos de manera productiva para ellos. Se impone la calidad, pero es difícil obtener indicadores para medirla. El progreso científico demanda colaboración, pero son escasas las oportunidades de identificar quiénes presentan intereses afines con los nuestros, conectarse, compartir y analizar determinadas cuestiones propias de la investigaciónh. SciVerse se propone crear un ecosistema de conocimiento que integre herramientas y aplicaciones innovadoras, abiertas, inteligentes y confiablesi. Se abre así una puerta a la incorporación de una serie aplicaciones complementarias que aporten un valor añadido a la información que poseen los recursos de información participantes en el proyecto.13
La búsqueda de información basada en texto; el uso de los vocabularios controlados, especialmente las ontologíasj), así como la gestión de los textos, particularmente su enriquecimiento; la interconexión semántica entre la información disponible en múltiples recursos bases de datos bibliográficas, bases textuales de las principales casas editoras o sus repositorios, bases factográficas con información genética, vocabularios controlados, glosarios y otras herramientas lingüísticas, directorios de revistas, instituciones y personalidades, herramientas para el análisis estadístico (recuento) de las principales variables que caracterizan a un flujo o conjunto bibliográfico y para el descubrimiento de nuevos conocimientos, gestores bibliográficosk, sistemas de traducción automática, herramientas para la indización social y comunidades virtuales, entre otros antes dispersos, y el crecimiento de la facilidades para colaborar e intercambiar informaciónl, a todas luces marcan tendencias actuales extremadamente importantes en la práctica de la recuperación de la información, que estremecen y ahondan su teoría en perfecta sintonía con los postulados de una Web 2.0 que se moviliza rápidamente hacia un próximo nivel, el 3.0.
CONSIDERACIONES FINALES
Antes de concluir esta breve exposición, es oportuno señalar que, aún cuando se realizan esfuerzos sistemáticos, tanto por parte de Hinari como de Infomed, en ocasiones se producen fallas en el acceso al sistema. Entonces, es necesario esperar e insistir nuevamente, así como ponerse en contacto con la Biblioteca Nacional de Medicina de Cuba, nuestros proveedores para este servicio.
Aunque con ciertas limitaciones, propias de la etapa inicial de implementación de cualquier nuevo sistema, Hinari provee acceso a SciVerse Hub al tratarse de una nueva plataforma de trabajo que integra pero no agrega recursos de información adicionales a los contratados con Elsevier. Sin embargo, es muy pronto para saber si será posible acceder al total de herramientas que comprende el proyecto de SciVerse, algunas de las cuales no estarán listas hasta el 2011. De momento, aún cuando suponga ciertas dificultades adicionales, podemos consultar cada uno de los recursos integrados en SciVerse por separado, Y esto representa mucho para el avance de la investigación en los países subdesarrollados.
REFERENCIAS BIBLIOGRÁFICAS
1. Scopus. Content coverage guide. Disponible en: http://www.info.sciverse.com/scopus/scopus-in-detail/content-coverage-guide . 2010. Disponible en: http://info.scopus.com/scopus-in-detail/facts/ [Consultado: 30 de septiembre de 2010].
2. Codina Bonilla L. Scopus: el mayor navegador científico de la Web. El Profesional de la Información. 2005;14(1):44-9. Disponible en: http://www.elprofesionaldelainformacion.com/contenidos/2005/enero/7.pdf [Consultado: 6 de mayo de 2010].
3. Grupo SciMago. Análisis de la cobertura de la base de datos Scopus. El Profesional de la Información. 2006;15(2):144-5. Disponible en: http://www.scimago.es/publications/epi1522006.pdf [Consultado: 6 de mayo de 2010].
4. Moya Anegón F, Chinchilla Rodríguez Z, Vargas Quesada B, Corera Álvarez E, Muñoz Fernández FJ, González Molina A, et al. Coverage analysis of Scopus: A journal metric approach. Scientometrics. 2007;73(1):53-78. Disponible en: http://www.scimago.es/benjamin/Coverage%20analysis%20of%20Scopus%20A%20journal%20metric%20approach.pdf [Consultado: 6 de mayo de 2010].
5. Torres Salinas D, Jiménez Contreras E. Introducción y estudio comparativo de los nuevos indicadores de citación sobre revistas científicas en Journal Citation Reports y Scopus. El Profesional de la Información. 2010;19(2):201-7. Disponible en: http://www.elprofesionaldelainformacion.com/contenidos/2010/marzo/torres_jimenez.pdf [Consultado: 5 de mayo de 2010].
6. Elsevier B. V. Scopus. Coverage of metada. Disponible en: http://www.info.scopus.com/scopus-in-detail/content-coverage-guide/metadata/ [Consultado: 11 de junio de 2010].
7. Cañedo Andalia R. Búsqueda bibliográfica, investigación métrica e inteligencia: el caso de la ataxia espinocerebelosa tipo 2 en Cuba. Acimed. 2009;19(2). Disponible en: http://bvs.sld.cu/revistas/aci/vol19_2_09/aci01209.htm [Consultado: 11 de junio de 2010].
8. Universidad de Granada. Sciverse, nueva plataforma que integra Science Direct, Scopus y el contenido web de Scirus. Disponible en: http://biblioteca.ugr.es/pages/tablon/*/nuevos-recursos-electronicos/2010/09/02/sciverse-nueva-plataforma-de-elsevier-que-integra-science-direct-scopus-y-el-contenido-web-de-scirus [Consultado: 30 de septiembre de 2010].
9. Elsevier. ScienceDirect reaches »10 in 10" celebrates Tenth Anniversary and Tenth Millions Milestone. 2010. Disponible en: http://www.info.sciverse.com/sciencedirectnews/sciencedirect-reaches-10-10-celebrates-tenth-anniversary-and -ten-millionth-milesto [Consultado: 30 de septiembre de 2010].
10. Scirus. About as… Disponible en: http://www.scirus.com/srsapp/aboutus/ [Consultado: 28 de septiembre de 2010].
11. Elsevier. NextBio on SciVerse ScienceDirect. Disponible en: http://info.sciverse.com/UserFiles/resource_library/esp/2508.SciVerse.NextBio_ScienceDirect%20Factsheet_ESP.pdf [Consultado: 28 de septiembre de 2010].
12. Business Wire. NextBio launches three new scientific search applications on the Elsevier SciVerse Platform. Disponible en: http://www.businesswire.com/news/home/20100928005264/en/NextBio-Launches-Scientific-Search-Applications-Elsevier-SciVerse [Consultado: 30 de septiembre de 2010].
13. Elsevier. SciVerse. Disponible en: http://www.info.sciverse.com/UserFiles/resource_library_brochures/sciverse-brochure.pdf [Consultado: 28 de septiembre de 2010].
14. Fernández Hernández A, Carbonell de la Fé S. Producción científica sobre ontologías en el Web of Science, 1998 -2007. Acimed. 2009;19(2). Disponible en: http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S1024-94352009000200002&lng=es&nrm=iso&tlng=es [Consultado: 28 de septiembre de 2010].
Anexo. Algunos campos de interés para realizar la búsqueda en Scopus
| Código del campo | Contenido | Observaciones |
| ABS | | La expresión ABS("spinocerebellar ataxia type 2") devolverá los documentos que contengan la frase "spinocerebellar ataxia type 2") en el resumen. |
| AFFIL | Afiliación de los autores | Puede especificarse si se desea que aparezcan todos los términos introducidos para la búsqueda en una sola afiliación. Contiene el nombre de la institución donde labora el autor (AFFILORG), la ciudad donde radica (AFFILCITY) y el país (AFFILCOUNTRY). |
| AUTH | Autores | Combina el contenido de los campos AUTHLASTNAME (último autor) y AUTHFIRST (primer autor). La expresión AUTH(velázquez-pérez) entregará una relación de documentos con autores cuyos apellidos sean los referido |
| DOCTYPE | Tipo de documento | Algunos valores de interés: Artículo-ar / Artículo en prensa-ip / Libro-bk / Material de conferencia -cp / Editorial-ed / Carta-le/ Artículo de revisión-re. La expresión DOCTYPE(bk) entregará solo materiales que se consideren libros por Scopus. |
| INDEXTERMS | Términos de indización | Más del 80 % de los materiales procesados para la base de datos Scopus se indizan por profesionales dedicados a esta tarea. En el caso de los materiales pertenecientes a las áreas de las ciencias de la vida y de la salud se utilizan los tesauros ENTREE de Elsevier y MeSH de la Biblioteca Nacional de Medicina de los Estados Unidos. Comprende términos de los vocabularios controlados mencionados. La expresión INDEXTERMS("Spinocerebellar ataxias") mostrará aquellos documentos que contengan en este campo " Spinocerebellar ataxias ", el término controlado que utiliza el MeSH para indizar los documentos cuyos contenidos traten las alrededor de 30 clases de ataxias identificadas. |
| KEY | Palabras clave | Combina los campos AUTHKEY (palabras claves asignadas por el autor, INDEXTERMS (términos de indización), TRADENAME (nombres comerciales de productos y servicios) y CHEMNAME (nombres químicos). |
| LANGUAGE | Idioma del documento | La expresión LANGUAGE(french) devolverá una relación de documentos originalmente escritos en francés. |
| PUBYEAR | Año de publicación | Algunos valores de interés: BEF - antes de AFT - después de IS - iguaI a La expresión PUBYEAR AFT 1993 entregará los documentos cuyos años de publicación sean posteriores a 1993. |
| SRCTYPE | Tipo de fuente | Algunos valores de interés: Revista- j Libro- b Serie de libros- k Materiales de conferencia- p Informe- r Publicación comercial- d La expresión SRCTYPE(j) mostrará una relación de contribuciones publicadas las fuentes documentales consideradas revistas por la base de datos. |
| TITLE | Título del artículo | La expresión TITLE("neuropsychological evidence") permitirá recuperar los documentos cuyos títulos contienen la frase "neuropsychological evidence"). |
| TITLE-ABS-KEY | Título-Resumen-Palabras clave | La expresión TITLE-ABS-KEY("heart attack") mostrará los documentos que contengan la frase "heart attack") en el título, el resumen o las palabras clave. Cuando se realiza una búsqueda simple son estos los campos que se exploran en busca de los términos indicados por el usuario. |
Recibido: 1 de octubre de 2010.
Aprobado: 19 de octubre de 2010.
Lic. Rubén Cañedo Andalia. Departamento Fuentes y Servicios de Información. Centro Nacional de Información de Ciencias Médicas-Infomed. Calle 27 No. 110 e/ N y M, El Vedado. Plaza de la Revolución. Ciudad de La Habana. Cuba. Correo electrónico: ruben@infomed.sld.cu
aA pesar de que Scopus registra en su colección más del 90% de los fondos de PubMed, se debe ser cuidadoso con respecto a la decisión de consultar Scopus en lugar de PubMed sobre la base de estas cifras. Realmente, existe un alto grado de solapamiento entre la colección de PubMed y la de Scopus, pero difieren por cerca de 1,7 millones de registros, una cantidad nada despreciable cuando se trata de hallar referencias sobre un tema con una escasa literatura. Una búsqueda en PubMed comprende: referencias bibliográficas «en proceso» de inclusión en Medline; referencias a fuentes (revistas esencialmente) que preceden a su fecha de ingreso a la base de datos; referencias a trabajos no cubiertos en Medline; referencias a manuscritos de autores pertenecientes a los Institutos Nacionales de Salud de los Estados Unidos publicados en revistas no procesadas por Medline; así como de algunas revistas en ciencias de la vida; etcétera. Pero además, PubMed es una base de datos especializada en biomedicina y entre otras facilidades presenta una interfaz muy apropiada para la búsqueda de información sobre todo de índole clínica, y ello sin duda ejerce una notable influencia positiva sobre la precisión de sus resultados.
bPRE/n (precedido por). El primer término precede al segundo en un número de palabras que va desde 0 hasta el número indicado como máximo. Por ejemplo, en: behavioural PRE/3 disturbances, el número de palabras máximo es 3. Es decir, el sistema devolverá referencias de documentos donde el término «behavioural» preceda a «disturbances» en una distancia no mayor de 3 palabras.
cDe no estar disponibles estos es posible guardar los resúmenes. Antes de comenzar la descarga (Begin Download), el usuario debe escoger el formato para el nombre de los ficheros (Select PDF file naming) así como el lugar donde se ubicarán en la máquina (Download to).
dElsevier es una de las editoras líderes en la publicación de literatura científica en los campos de la ciencia, la tecnología y la medicina. Es parte de Reed-Elsevier Group PLC, un grupo líder de casas editoras a escala mundial.
e Las cifras con respecto al cubrimiento de la base de datos según tipo de documentos varían considerablemente entre las fuentes consultadas.
fTal vez estemos ante lo que pudiéramos denominar la tercera gran crisis de los científicos ante su literatura. Un primer momento pudo rebasarse con los llamados índices bibliográficos automatizados y los sistemas bibliográficos en línea; el segundo mediante la creación y multiplicación de las bases de datos a texto completo o de plataformas que enlazan las referencias existentes en las bases de datos con dichos textos.
gLa integración cada vez más intensa de recursos de información y herramientas de trabajo en red es el resultado de una creciente interoperabilidad entre ellos, propiciada por la aparición de plataformas y agentes inteligentes, capaces de capturar, procesar y reunir información sin intervención humana.
hUn componente del proyecto, SciVerse SciTopics Beta, con estos fines estará disponible en 2011.
iUn componente del proyecto, SciVerse Applications Beta, con estos fines estará disponible a finales de 2010; puede que implementación definitiva ocurra con cierto retraso.
jLas ontologías constituyen lenguajes y, a su vez, sistemas de representación de la información y del conocimiento, capaces de describir diferentes recursos de información para su posterior recuperación. Las ontologías describen una realidad, dígase dominio -un dominio es simplemente un área de temática específica o un área de conocimiento, como la medicina. Comprenden los conceptos, sus clases y sus relaciones, las funciones, las instancias y las reglas de restricción o axiomas. Ellas mejorarán la recuperación de la información en el Web, en términos de efectividad, rapidez y facilidad de acceso, y forman parte de lo que comúnmente se denomina Web semántica.
kLas tendencias actuales apuntan hacia una integración entre los sistemas autorizados de búsqueda y recuperación de la información y los gestores de referencias bibliográficas, devenidos en los llamados gestores de referencias bibliográficas sociales, que integran las facilidades de los primeros con las que ofrecen las redes sociales. Sistemas como Connotea (http://www.connotea.org/) y CiteUlike (http://www.citeulike.org/home) permiten almacenar, gestionar y compartir referencias bibliográficas de diversos tipos de documentos científicos y técnicos, según grupos temáticos de interés. Su diferencia fundamental con sus predecesores radica en que el objetivo fundamental no es crear y administrar una biblioteca personal sino compartir la información con otros especialistas con intereses similares. A diferencia de una base de datos tradicional donde existe un amplio conjunto de referencias bibliográficas que nunca se utilizan o presentan una pobre demanda; los contenidos distribuidos mediante sistemas como los referidos, muestran solo aquellos documentos que circulan y utilizan por la comunidad científica. Estos además son objeto de una indización social, realizada por los propios consumidores de los documentos.
lPara esto, no sólo se integran productos, servicios y sistemas de información, sino que se intenta crear un entorno completo para el trabajo científico basado en Web que sustituiría al actual, mixto, parte computadora personal, parte Web. A todas luces, se está produciendo una sustitución de las herramientas de trabajo diseñadas para la computadora personal por nuevas aplicaciones soportadas en Web. Ello forma parte de un amplio movimiento de convergencia tecnológica y social que busca «re-soportar» la actividad científica en una nueva Web, que se consolida progresivamente, a partir de la aparición de un número creciente de aplicaciones que facilitan integración del quehacer científico y que, en última instancia, buscan un aumento de la productividad de su trabajo sobre la base de una socialización eficiente e intensa de la información resultante.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}