










 Serviços customizados
Serviços customizados Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Mediante la World Wide Web (www) se puede acceder a diversas páginas web, ubicadas en disímiles partes del mundo. Estas páginas comparten conocimiento respecto a las distintas formas en que la tecnología puede facilitar el acceso universal a la educación. Con el uso de herramientas cada vez más sofisticadas y la información brindada en estos servidores, ha aumentado progresivamente la creación de Recursos Educativos (Camilleri & Camilleri, 2016) (Cacheiro González, 2011) (Alonso et al., 2020).
Teniendo en cuenta la gran cantidad de recursos educativos y las diferentes utilidades para las que son creados, estos recursos se vuelven cada vez más complejos. Siendo esto un problema difícil de superar para desarrolladores inexpertos o con poco tiempo para dedicar al desarrollo de los mismos. Esto conlleva a que los diseñadores (que pueden ser cualquier persona) pueden tener dificultades a la hora de lograr que el recurso final satisfaga el objetivo con el que fue creado dejando una brecha para que surjan problemas de diseño (Begoña et al., 2016) (Hernández Aracil et al., 2015) (Valdés Avilés et al., 2018).
Los problemas de diseño de recursos educativos pueden dificultar el entendimiento de los mismos por parte del estudiante provocando que no cumplan con los objetivos para los que fueron creados. Por tal motivo para la creación de estos recursos educativos se recomienda el empleo de patrones de diseño de recursos educativos, para potenciar en estos, características como mejor estructura y reusabilidad (L. M. Terry & Terry, 2018) (Alexander, 1977) (Alexander et al., 2017).
Debido a la gran variedad de recursos educativos, sus disímiles características, y fuentes de almacenamiento a los diseñadores se les dificulta la selección de los patrones de diseño de recursos educativos. Los sitios en que son almacenados no cuentan con mecanismos adecuados que apoyen la selección por parte de los usuarios. Además, aunque mayormente siguen la misma estructura para los patrones, se muestran en disímiles formatos de presentación y organización.
Mayormente las personas que actúan como diseñadores de recursos educativos no conocen de la existencia de las fuentes que almacenan patrones de diseño. También ocurre que, a pesar de conocer la utilidad de la aplicación de patrones, el proceso para acceder a ellos se torna engorroso debido a que tendría que seguir un grupo de pasos que va desde el acceso a la fuente, hasta la consulta manual de cada uno de los patrones que podrían serle de interés. Esto puede extenderse en periodos de tiempo indefinidos, los cuales pueden multiplicarse si el diseñador revisa más de un repositorio. Por ello, la duración de la consulta, sumado a otras factoras que pueden complejizarla tales como la conectividad, o el dominio del idioma en que estén redactados los patrones. Todos estos factores hacen que el proceso de búsqueda y selección de un patrón o un conjunto de ellos pueda llegar a tener un elevado costo temporal.
El Grupo de Tecnologías de Apoyo a la Educación GITAE de la Facultad 4 de la Universidad de las Ciencias Informáticas UCI desarrolla como parte de una de sus investigaciones un Entorno para la Gestión de Patrones de Diseño EGPat. Con esto se busca crear una vía que permita la revisión de recursos educativos, la gestión y revisión de patrones de diseño y además permita la consulta de los mismos en una forma más simple. Sin embargo, persisten los problemas del tiempo y complejidad de consultas dado que, aunque haya patrones accesibles en una fuente local, la búsqueda de cuál(es) puede ser el más adecuado para el recurso educativo que se está diseñando sigue manteniendo el mismo procedimiento que se mencionaba anteriormente (LLull et al., 2020).
Además, puede igualmente darse el caso que dentro de los patrones almacenados localmente en EGPat no haya ninguno que se adapte a las necesidades del usuario, provocando que este tenga que consultar nuevamente alguno de las fuentes disponibles online. Por ello, se requiere incluir un módulo que permita extraer patrones desde repositorios y recomendarlos a los usuarios adaptándose a las necesidades que puedan tener los mismos. El presente artículo recoge los detalles de la implementación de un módulo para EGPat que permita dado un problema recomendar los patrones más adecuados para su tratamiento analizando todas las fuentes posibles.
MÉTODOS O METODOLOGÍA COMPUTACIONAL
Durante el desarrollo de la investigación fueron utilizados los métodos siguientes: análisis-síntesis, para el estudio de las fuentes bibliográficas existentes referente al tema, identificando los elementos más importantes y necesarios para dar solución al problema planteado; inductivo-deductivo, para el análisis de las principales formas de recomendación de información proveniente de diferentes fuentes, incorporando las más viables a la presente investigación; el histórico-lógico, con el fin de realizar un estudio de las fuentes en que se encuentran disponibles los patrones de diseño; modelación, para la representación explícita de la solución a través del flujo que conforma el módulo de recomendaciones dentro de EGPat, así como las ideas y definiciones y conceptos extraídos de las fuentes bibliográficas consultadas; experimentación para probar el funcionamiento del sistema con datos reales, análisis documental, en la consulta de la literatura especializada en las temáticas afines de la investigación.
Para avanzar en la investigación se hace necesario la comprensión de los conceptos de recursos educativos y patrones de diseño.
Recursos educativos
Los recursos educativos son cualquier instrumento u objeto que pueda servir como recurso para que, mediante su manipulación, observación o lectura, se ofrezcan oportunidades de aprender algo, o bien con su uso se intervenga en el desarrollo de alguna función de la enseñanza. Son los medios que vehiculizan un mensaje con fines de enseñanza. Los materiales educativos presentan contenidos a través de uno o más medios. Se entiende por recurso educativo a un objeto que facilita una experiencia de aprendizaje, es decir, una experiencia de cambio y enriquecimiento en algún sentido: conceptual o perceptivo, afectivo, de habilidades o actitudes (Castillo & Brenda, 2017).
Son recursos interactivos y dinámicos, ya que presentan diferentes elementos multimediales como las imágenes, sonidos, videos, animaciones, entre otros. La innovación tecnológica ha permitido tener disponible una diversidad de recursos digitales para fines de aprendizaje. Es así como en la actualidad docentes y estudiantes acceden tanto a software educativo como a sitios web educativos, con la finalidad de fortalecer, mejorar y contextualizar sus prácticas educativas (Mishra, 2017) (Hidalgo Navarrete & Aliaga Zegarra, 2020).
Patrones de diseño
Se define como un patrón de diseño a una solución probada para un problema en un contexto. Cada uno documenta una solución reutilizable, encapsula el conocimiento sobre la práctica exitosa y proporciona información sobre su utilidad y sus compensaciones. Algunos patrones han sido catalogados en colecciones o bibliotecas de patrones (Alexander, 1977) (Alexander et al., 2017) (L. M. Terry & Terry, 2018). Los patrones de diseño de recursos educativos se pueden almacenar en repositorios, con el objetivo de prestar servicios a los usuarios que deseen acceder a ellos. En la actualidad, existen varias fuentes de este tipo, destacando en ellas: Pedagogical Pattern (PPP), E-LEN, PCeL, y P-REPLIKA.
Durante la investigación fueron encontradas un grupo de fuentes de las cuales se hace un análisis de fortalezas y debilidades en el campo del aprendizaje colaborativo. En la Tabla 1 se recogen los detalles respecto a los siguientes aspectos:
Disponibilidad Online: Si la fuente está disponible de forma Online en internet para su utilización.
Libertad de uso: Si la fuente es liberada para todos los usuarios o posee algún costo de utilización.
Idiomas disponibles: Los idiomas en que se encuentra disponible la fuente.
Tratamiento de agrupaciones (catálogos y/o lenguajes): Si la fuente incluye agrupaciones de patrones tanto en catálogos como en lenguajes.
Buscador: Si posee algún buscador que facilite la búsqueda de un patrón específico.
Buscar y recuperar información de estas fuentes es una tarea que puede complejizarse, por lo que con EGPat se busca mejorar el acceso a las mismas para la búsqueda de patrones. Dentro de los mecanismos de búsquedas
más comunes están los buscadores tales como Google. Aunque como formas de acceder a información específica están de moda los sistemas recomendadores. Por ello se decide incluir en la Arquitectura de EGPat un módulo para la recomendación de patrones de diseño. Para ellos se debe analizar también los conceptos y las clasificaciones de los sistemas recomendadores.

Sistemas de remendaciones
Los sistemas de recomendación surgieron a mediados de la década de los 90 con el fin de brindarles a los usuarios aquellos resultados de búsquedas de información cercanos a sus necesidades. Un sistema de recomendación puede realizar predicciones a partir del hecho que a un usuario le guste o no cierto ítem al que podría acceder. Los sistemas de recomendación tienen la capacidad de identificar preferencias y sugerir ítems relevantes para cada usuario; para ello se necesita de perfiles que almacenen la información y las preferencias de cada usuario (Ricci et al., 2011) (Kulkarni & Rodd, 2020) (Srivastav & Kant, 2019).
Además, los sistemas de recomendación intentan determinar qué productos o servicios más adecuados se basan en las preferencias y limitaciones del usuario. Con el fin de completar las tareas de computación, los sistemas de recomendación recogen del usuario sus preferencias, que se expresan explícitamente, por ejemplo, como calificaciones de los productos, o se deducen interpretando las acciones del usuario (Kulkarni & Rodd, 2020) (Bárbaro et al., 2017) (M. E. Charnelli et al., 2018).
La finalidad de un sistema de recomendación es predecir la valoración que un usuario va a hacer de un ítem que todavía no ha evaluado. Esta valoración se genera al analizar una de dos cosas, o las características de cada ítem, o las valoraciones de cada usuario a cada ítem, y se usa para recomendar contenido personalizado a los usuarios (Kulkarni & Rodd, 2020)(M. E. Charnelli et al., 2018) (Mendoza Olguín, 2019). Existen varias clasificaciones de los sistemas de recomendación:
Filtrado colaborativo: utiliza la información de preferencias y calificación de un grupo de usuarios respecto a los ítems de un repositorio, con el fin de predecir o inferir la preferencia de un usuario en particular sobre un ítem y a partir de esto generar una recomendación acertada (Cataldi et al., 2018) (Bárbaro et al., 2017) (Mendoza Olguín, 2019).
Basado en contenido: los objetos de interés se definen por sus características asociadas. Un recomendador basado en contenido aprende de un perfil de los intereses del usuario basado en las características presentes en los objetos que el usuario ha calificado Al igual que en el caso de colaboración, los perfiles de usuario basados en el contenido son modelos a largo plazo y se actualizan a medida que se observan más pruebas sobre las preferencias del usuario (ACM, 2013)(Gómez Velasco, 2018).
Basado en conocimiento: intenta sugerir objetos basados en inferencias sobre las necesidades y preferencias de un usuario. Los enfoques basados en el conocimiento se distinguen porque tienen conocimiento funcional: tienen conocimiento sobre cómo un artículo en particular satisface una necesidad particular del usuario y, por lo tanto, pueden razonar sobre la relación entre una necesidad y una posible recomendación (Gálvez Lio, 1998) (Bárbaro et al., 2017) (LÓPE1, 2019) (Oliveira et al., 2020).
Sistemas Híbridos: Son sistemas que combinan diferentes técnicas de recomendación para dar solución a un determinado problema (Ricci et al., 2011) (Gordillo et al., 2017) (Khanal & Prasad, 2019).
Para la investigación del presente trabajo se tuvo en cuenta lo expuesto por (Kulkarni & Rodd, 2020),(Konstan & Riedl, 2012),(M. E. Charnelli et al., 2018),(Liu et al., 2018),(Kaur et al., 2018),(García Rodríguez, 2018) y (Bárbaro et al., 2017) que realizan estudios en el área de los sistemas recomendadores principalmente en el área de la educación. Dentro de estos (Kulkarni & Rodd, 2020) y (M. E. Charnelli et al., 2018) realizan estudios de revisión del estado del arte dejando de manifiesto las tendencias más actuales. En función de ello se determinó que para la investigación lo más factible era la implementación híbrida de un sistema basado en el conocimiento potenciado con técnicas de filtrado colaborativo.
Al adoptar la implementación híbrida antes mencionada se puede acoger la utilización de los patrones disponibles en las fuentes (Tabla 1) como base de conocimiento para entrenar el sistema adoptando un algoritmo similar a un sistema basado en casos como propone (Y. Terry et al., 2016). Al combinarlo con el filtrado colaborativo se puede aprovechar la información disponible en la fuente respecto a la interacción de los usuarios con los patrones y/o lenguajes descargados.
Una vez analizados los métodos y definiciones anteriores; revisadas las fuentes, y seleccionado el tipo de recomendación a utilizar se puede pasar a la descripción del módulo.
RESULTADOS Y DISCUSIÓN
El entorno para la gestión de patrones de diseño EGPat está diseñado en forma modular (Figura 1), donde cada módulo asume diferentes responsabilidades. El módulo de detección de problemas permite detectar problemas de diseño en recursos educativos mediante el análisis de sus metadatos. El módulo de recomendaciones se encarga de la comunicación con fuentes externas que contengan información de interés (metadatos de recursos educativos o patrones de diseño), extraer dicha información, y almacenarla. Además de procesarla mediante técnicas de inteligencia artificial y recomendarla en el caso de que sea aplicable a alguno de los problemas detectados en el módulo de detención de problemas u otro entrado por el usuario. Cuenta también con un módulo de Gestión, el cual ofrece al usuario posibilidad de consultar y editar patrones almacenados, así como de crear nuevos patrones (LLull et al., 2020).
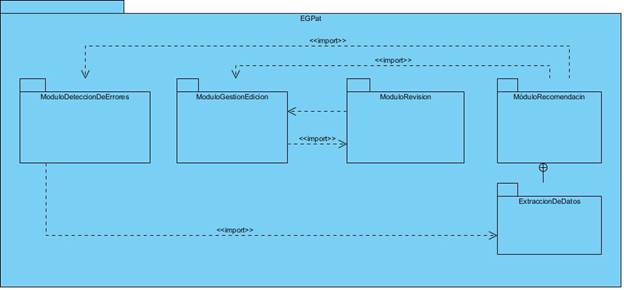
Fuente: Elaboración Propia.
El módulo de recomendaciones como se mencionaba anteriormente trabaja con la lógica de un sistema de razonamiento basado en casos con la particularidad de que solo cuenta con un problema descrito textualmente para suplir los rasgos predictores y los patrones que puedan dar solución a ese problema pasarían a ser los rasgos objetivos. Para realizar el proceso de recomendaciones se sigue un grupo de pasos teniendo en cuenta el ciclo de vida de un sistema basado en casos, pero para ello además de rasgos predictivos y objetivos se debe contar además con una base de conocimiento, una interfaz visual además de todos los elementos para realizar un adecuado proceso de inferencia (Russell & Norvig, 2010)(Oliveira et al., 2020).
Tanto el rasgo predictor como los objetivos son descripciones en forma de cadenas de texto. Esto implica que para obtener la información necesaria para realizar el proceso de inferencia se debe procesar adecuadamente el texto. Para ello se hace necesario crear una variante para el razonamiento basado en casos que funcione de manera textual aplicando para ello técnicas de Minería de Texto a lo cual (Y. Terry et al., 2016), (Funk, 2013), (E. Charnelli et al., 2017) y (Oliveira et al., 2020) se refieren como CBR Textual (abreviatura de Razonamiento basado en Casos Textual). Esta rama del razonamiento basado en casos plantea varias cuestiones: cómo hacer similitud entre casos textuales, cómo adaptar casos textuales o cómo generar automáticamente representaciones textuales de los casos. Estas y otras cuestiones se resuelven con técnicas de recuperación de información. Estas técnicas trabajan con textos no estructurados, consultas en lenguaje natural y realizan una recuperación aproximada.Figura 2

Para ello se adoptan los algoritmos propuestos por (Y. Terry et al., 2016) y (Arteaga et al., 2015) donde basándose en la estructura que presentan los patrones de diseño de recursos educativos aplican la técnica de los n-gramas contextuales para comparar el problema entrado por el usuario con otros patrones a través de la descripción del problema que resuelve cada uno de ellos. Con ellos se puede suplir las funciones de semejanza de rasgos y casos que normalmente se utilizan.
Los n-gramas contextuales reciben este nombre por su capacidad de representar la esencia del contexto con un reducido número de caracteres. Son el resultado de agrupación de n palabras en un texto, siendo n la cantidad de palabras que se decidan agrupar, después de la previa eliminación de las palabras vacías y caracteres aislados, extracción del lexema (stem) y ordenación interna de cada n-grama. Estudios anteriores sobre la conveniencia del grado de n-gramas manifestaron que los bigramas y trigramas son las mejores opciones. Se demostró, además, que el mejor resultado se obtenía mediante n=3, con significativa mejor cobertura, precisión y granularidad que mediante el empleo de n=2 (Piedrahita-, 2018) (Arteaga et al., 2015) (LLull et al., 2020).
El uso de trigramas constituye el eje fundamental en las investigaciones previas al presente trabajo. Esto permite explotar el trabajo con la descripción de los problemas, pero no explota otros aspectos que pueden aumentar la precisión de las recomendaciones.
Fase de recuperación de información
Para recuperar la información se deben realizar dos tareas Identificación de características y Emparejamiento.
Identificación de características:
Para la identificación de características se utilizó la técnica de n-gramas contextuales ya mencionada. Para conseguir que el n-grama contenga la mejor dentición de la esencia del contexto y sea especialmente útil para comparar dos textos se realizaron los siguientes pasos: Recuperación de la información e Identificación de características. A continuación, se explican cómo se ejecutan estos pasos:
Emparejamiento:
La selección de los casos de la base de conocimiento semejantes al problema del patrón actual se realizó utilizando el método por analogía. Para determinar si el problema entrado “s” puede ser semejante a la descripción del patrón o lenguaje almacenado en la base de casos “d” se utilizaron las medidas de semejanza (S) y contención(C). Para la implementación de estas medidas se definió el método de semejanza() cuando los conjuntos de trigramas a comparar provienen de textos de longitud equiparable. La semejanza se define por medio de la ecuación:
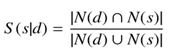
N(d) es el conjunto de trigramas en la cadena de texto “d” de la base de casos y N(s) es el conjunto de trigramas en la cadena de texto “s” que será entrada en el módulo. Una vez que se cuenta con los trigramas la medida de semejanza sería el resultado de dividir la intersección de los trigramas entre la unión de estos. En el caso que los trigramas obtenidos no provengan de textos de longitud equiparable, se definió el método de contencion(). La contención se define por medio de la ecuación:

N(m) es el conjunto de trigramas de mayor tamaño si se compara N(d) con N(s). La medida de contención sería el resultado de dividir la intersección de los trigramas entre el trigrama de mayor tamaño. Para la selección de los patrones y/o lenguajes semejantes al problema textual descrito inicialmente se tomó como índice para los métodos semejanza() y contencion(), valores iguales o superiores a 0.5 y 0.8 respectivamente, estos índices fueron definidos por (Arteaga et al., 2015) y (Y. Terry et al., 2016).
Fase de reutilización
Una vez obtenidos los casos más semejantes en la fase de recuperación, se selecciona de este conjunto de candidatos a aquel caso más propenso a ser una buena solución para el problema. Para ello se pondera los casos por el cálculo de calidad percibida por otros usuarios. Esta ponderación se realiza teniendo en cuenta el impacto que pueda haber generado ya el patrón ya sea, positivo o negativo. Esto puede medirse a través de las descargas (número de descargas realizadas al patrón), recomendaciones (si el patrón ha sido recomendado o no) y evaluación personal de un usuario (criterio de usuarios sobre determinado patrón) (Bergin et al., 2017).
Para obtener la información de los parámetros se realiza a través de los resultados de interacción de los usuarios con determinado patrón de diseño mediante un indicador de interacción. El cálculo de este indicador fue guiado por los aportes dados en (Begoña et al., 2016) y (Bergin et al., 2017) teniendo en cuenta lo planteado originalmente por (Alexander, 1977) y se calcula de la siguiente forma:
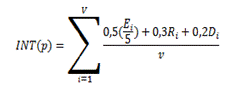
Donde: v es la cantidad de veces que el patrón ha sido visualizado por un usuario, E es la evaluación otorgada al patrón por el usuario en la visualización i, toma valor entero entre 1 y 5; R y D toman valor 1 si el usuario ha recomendado y descargado, respectivamente, el patrón en la visualización i y valor 0 en caso contrario.

Para la reutilización fue implementada la función SimilitudEntreCadenas() que mide la similitud de los casos recuperados teniendo en cuenta las fórmulas de semejanza y contención explicadas anteriormente. Posteriormente se realiza el cálculo del índice de interacción de los usuarios con determinado patrón, para establecer un orden de prioridad a la hora de mostrarle finalmente a los usuarios cuales son los lenguajes, patrones pertenecientes a un catálogo y patrones independientes que le dan solución al problema de diseño introducido por ellos. Para ello se aplica a siguiente fórmula:
Donde Sf se refiere al valor final de semejanza, S a la semejanza obtenida a través de la función similitud entre cadenas e INT es el cálculo de calidad percibida. En el caso de los patrones y lenguajes procedentes de la fuente Pedagogical Patterns no fue posible realizar en análisis para el cálculo de INT dado que no cuenta con una gestión de usuarios, por ello se realiza solamente una proporción entre la cantidad de descargas y visualizaciones.

Finalmente, según el valor final obtenido se ordenan de forma descendente los casos reutilizados recomendándole al usuario diez primeros. De esta forma le son visualizados los patrones o lenguajes más afines al problema planteado inicialmente.
Validación del Módulo
Para validar la propuesta de la presente investigación se tiene en cuenta los principales aspectos que debe mejorar para la gestión de patrones: el tiempo que tarda un usuario en buscar y seleccionar un patrón y la complejidad asociada a este procedimiento. Para ello fue aplicada la técnica de Iadov (Zelkowitz, 2008) a un total de 100 usuarios de los cuales 60 mostraron un máximo de satisfacción, 20 más satisfechos que insatisfechos, 10 no definidos o contradictorios, 10 más insatisfechos que satisfechos y ninguno con total insatisfacción. Estos resultados aportaron un índice de satisfacción grupal de 0.65 el cual es favorable de acuerdo a la escala de Iadov.
Fueron realizadas además pruebas de experimentación offline (Pertinencia y Validación de La Ciencia, 2009) donde se asumieron como métricas la precisión, exhaustividad, utilidad de vida y confianza de las recomendaciones realizadas por el mismos Para ello fue utilizados el mismo conjunto de prueba antes mencionado. Como resultado se probó la capacidad del módulo para realizar recomendaciones confiables y exactas. Además de que logra reducir el tiempo y complejidad para el acceso y selección de un patrón de diseño.
El funcionamiento correcto del sistema fue revisado mediante la aplicación de pruebas de software a través de los métodos de caja blanca y caja negra. Con el método de caja blanca fueron realizadas pruebas unitarias haciendo uso de la técnica del camino básico. Para el método de caja negra fue utilizada la técnica de partición de equivalencia, así como pruebas de aceptación. También fueron aplicadas pruebas de integración para validar el funcionamiento del módulo dentro de EGPat.
CONCLUSIONES
La utilización de patrones de diseño constituye un importante apoyo para los diseñadores de recursos. Estos generalmente no los utilizan por desconocimiento o por la dificultad del acceso a los mismos. En esta investigación se logró determinar las principales fuentes para su consulta, así como las desventajas y potencialidades de las mismas. Con la implementación de la solución propuesta en la presente investigación se dotó a EGPat de un módulo que permite a los usuarios obtener patrones de diseño adecuados para un determinado problema descrito en forma textual. Para llegar a la solución se logra combinar dos tipos diferentes de recomendación con la lógica de un sistema de razonamiento basado en casos textuales requiriéndose además de la técnica de minería de texto n-gramas contextuales. La solución fue validada mediante pruebas de software, pruebas de validación offline y la técnica de Iadov los cuales mostraron resultados satisfactorios.

