










 Serviços customizados
Serviços customizados Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Los sistemas recomendadores (RSs) se han vuelto una tecnología de internet pertinente para superar el problema de carga excesiva de información. (1 Considerando que la información disponible está creciendo continuamente en la internet y otros escenarios similares, cada día se hace más difícil para los usuarios acceder a aquella información que mejor se corresponde con sus necesidades y preferencias. La naturaleza de los ítems de información es muy heterogénea: estos pueden ser tan diversos como los productos en una tienda electrónica, paquetes turísticos proporcionados por una agencia de viaje, música para escuchar en un sitio electrónico, materiales de aprendizaje electrónico, artículos científicos para leer, o tratamientos específicos para una persona enferma.
La mayoría de los sistemas recomendadores individuales y grupales asumen que las preferencias de los usuarios están libres de inconsistencias. Sin embargo, varios trabajos de investigación han apuntado que tales preferencias pueden contener “ruido”, y que ese “ruido”, denominado “ruido natural”, puede afectar negativamente el desempeño del sistema de recomendación. En los últimos años, se ha determinado que los ratings de los usuarios pueden ser inconsistentes, ruidosos o estar sesgados 2,3 y que tales inconsistencias son causadas por factores como condiciones personales, influencias sociales, contextos, o determinadas escalas de ratings. 4 Todo lo anterior, hace que el tratamiento de preferencias inconsistentes en sistemas recomendadores sea un aspecto clave para mejorar su desempeño. El objetivo de esta investigación es desarrollar nuevos métodos de preprocesamiento para la eliminación de inconsistencias de tipo “ruido natural” en sistemas recomendadores de filtrado colaborativo, que contribuyan a mejorar la eficacia de las recomendaciones generadas.
MÉTODOS
Este trabajo presenta inicialmente 4 nuevos métodos para la corrección de preferencias inconsistentes en sistemas recomendadores de filtrado colaborativo. 5
Corrección de preferencias inconsistentes en recomendación individual
Inicialmente se presenta 1 nuevo método para corregir preferencias inconsistentes en recomendación individual. Estos resultados han sido previamente presentados en Yera et al.,3 en la revista Knowledge-Based Systems.
En este método, partiéndose de lo planteado por Amatriain et al.6 sobre la presencia de ratings extremos (tanto bajos como altos) y de ratings medios, se propone clasificar cada rating en 3 clases diferentes acordes a su valor:
Siendo U e I el conjunto de usuarios e ítems, se propone agrupar las preferencias para cada usuario u, en los siguientes conjuntos Wu, Au y Su
Conjunto de ratings débiles provistos por el usuario u, Wu:
Conjunto de ratings medios provistos por el usuario u, Au:
Conjunto de ratings fuertes provistos por el usuario u, Au:
Del otro lado, para cada ítem i, las preferencias son agrupadas en los conjuntos Wi, Ai y Si:
Conjunto de ratings débiles asignados al ítem i, Wi:
Conjunto de ratings medios asignados al ítem i, Ai:
Conjunto de ratings fuertes asignados al ítem i, Si:
Considerando estos conjuntos y las clases de los ratings, formalmente se definen nuevas clases asociadas a cada tendencia de usuario e ítem (tabla 1).
Una vez que cada rating, usuario e ítem ha sido clasificado, esta información se usa para encontrar ratings ruidosos analizando la presencia de contradicciones entre las clases. Con este propósito, se definen 3 grupos de clases análogas respectivamente asociadas a usuarios, ítems y ratings (tabla 1). En este sentido, se espera que si para un rating se cumple que su usuario y su ítem corresponden al mismo grupo, entonces el rating también pertenezca a este grupo. De lo contrario, es posiblemente ruidoso.
Tabla 1 Clases análogas
| Clases de usuario | |||
|---|---|---|---|
| Grupo 1 | Crítico | Débilmente preferido | Débil |
| Grupo 2 | Promedio | Medianamente preferido | Medio |
| Grupo 3 | Benevolente | Fuertemente preferido | Fuerte |
Una vez que el método ha detectado los posibles ratings ruidosos, la siguiente fase manipula estos ratings. Se propone una estrategia que modifica cada posible rating ruidoso r(u,i), a través del cálculo de un nuevo rating r*(u,i) para el correspondiente usuario e ítem, a través de un algoritmo de filtrado colaborativo tradicional tomando como base los ratings disponibles. 7,8 En caso de cumplirse la condición
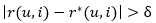 (siendo δ un umbral), entonces r(u,i) se reemplaza por r*(u,i). De lo contrario, r(u,i) mantiene su valor original.
(siendo δ un umbral), entonces r(u,i) se reemplaza por r*(u,i). De lo contrario, r(u,i) mantiene su valor original.
Corrección de preferencias inconsistentes en recomendación individual usando lógica difusa
Esta sección presenta un nuevo método para el tratamiento de ruido natural en sistemas recomendadores individuales, usando herramientas difusas 9 para lidiar con la incertidumbre asociada a este proceso (NNM-FT). Los resultados presentados en esta sección han sido previamente publicados en Yera et al.5 y Yera et al.. 10
La propuesta se compone de las siguientes fases: a) perfilamiento difuso, b) detección de ruido, y c) corrección de ruido.
El perfilamiento difuso se enfoca en la modelación de las preferencias de los usuarios a través de una representación lingüística difusa que permite obtener perfiles difusos de usuarios, items y ratings. Estos perfiles son transformados a través del uso de computación con palabras, hacia perfiles modificados que resaltan sus tendencias a través de una manera flexible.
La fase de detección de “ruido” se enfoca en chequear si un rating rui dado es ruidoso, a través del análisis de la tendencia de evaluación por parte de los usuarios asociados u e i. Específicamente, los perfiles difusos son usados para identificar si el valor del rating coincide con las tendencias de su usuario y su ítem correspondiente, o si yace fuera de las tendencias detectadas. En este último caso, el rating es considerado como ruidoso.
La fase de corrección de ruido se centra en la corrección de los valores de los ratings identificados como ruidosos en la fase previa, basándose en el valor de su grado de “ruido”. Estos grados de “ruido” consideran cuán cerca está el perfil difuso del rating en relación con los perfiles difusos de usuario y de ítem. Una mayor brecha entre dicho perfil de rating y los perfiles de usuario y de ítem, implicaría un mayor grado de ruido por parte del rating asociado.
Corrección de preferencias inconsistentes en recomendación grupal
Esta sección se enfoca en la presentación de métodos para el tratamiento de “ruido natural” en un sistema de recomendación grupal. Los métodos construidos toman como referencia el método de tratamiento de “ruido natural” para recomendación individual, presentado previamente. Estos métodos han sido publicados en Castro et al., 11 en la revista Decision Support Systems.
Dos de los enfoques que se presentan, se centran en el preprocesamiento de datos a nivel local. Estos son el método de tratamiento de “ruido natural” a nivel local basado en información local del grupo (NNM-LL), y el método de tratamiento de ruido natural a nivel local utilizando información global de los usuarios. Un tercer enfoque propone realizar la corrección a nivel global de las preferencias de los usuarios, sin considerar el grupo al que pertenece (NNM-GG). Finalmente, se propone un cuarto enfoque que introduce una hibridación en cascada, donde primero se corrige a nivel global y posteriormente de manera local al nivel del grupo (NNM-H).
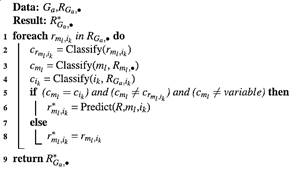
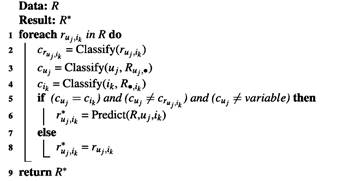

El algoritmo 1 formaliza la corrección en el enfoque NNM-LL. En este caso, para todos los ratings RGa* de cada grupo Ga, se realiza un proceso de preprocesamiento de datos utilizando el esquema de la subsección anterior, considerando sólo los ratings del propio grupo para caracterizar los usuarios y los ítems.
La corrección en el enfoque NNM-GG es esbozado en el algoritmo 2. En este caso, se realiza una corrección de “ruido natural” a nivel global, utilizando toda la información disponible para perfilar los correspondientes usuarios e ítems y detectar las inconsistencias. Este preprocesamiento se realiza previo a la construcción del modelo de recomendación, para realizar la recomendación grupal.
Finalmente, el algoritmo 3 presenta el método NNM-H utiliza los métodos de corrección presentados en los algoritmos 1 y 2. Específicamente, primero realiza una corrección global previa a la construcción del modelo de recomendación, y en un segundo momento realiza una corrección local para corregir alguna inconsistencia que no se haya corregido en el primer momento.
Corrección de preferencias inconsistentes en recomendación grupal usando lógica difusa
En este último resultado se obtuvo un método para el tratamiento de ruido natural en sistemas de recomendación grupales usando lógica difusa (NNMG-FT). Los resultados presentados en esta sección han sido previamente publicados en Castro et al.. 12
NNMG-FT analiza la base de datos de ratings para detectar ratings ruidosos y corregirlos para reducir su impacto en un sistema de recomendación grupal. NNMG-FT tiene 3 fases:
Perfilamiento difuso: Genera una representación para los usuarios, ítems y ratings para caracterizarlos y facilitar su análisis en una fase siguiente. En adición a los perfiles generados en NNM-FT, también incluye un perfilamiento del ítem basado en el grupo para modelar las preferencias del grupo considerando un ítem específico.
Tratamiento global del “ruido”: Basado en los perfiles modelados en la fase previa, esta fase manipula el “ruido natural” de la base de datos del rating a un nivel global. Esta fase está conformada por las fases 2 y 3 del enfoque NNM-FT.
Tratamiento local del “ruido”: Utiliza la información corregida que se obtuvo en el paso previo, para llevar a cabo un tratamiento de “ruido natural” enfocado en los ratings del grupo. Esta fase también está compuesta por las fases 2 y 3 del enfoque NNM-FT, pero tomando en consideración el nuevo perfil del ítem basado en grupo, en vez del perfil del ítem utilizado en NNM-FT.
Como resultado, se obtiene una base de datos de ratings sin ruido natural, la cual puede ser utilizada luego por un sistema de recomendación grupal.
Un recomendador para el juez en línea de programación
Los jueces en línea de programación son herramientas informáticas que contienen una gran colección de ejercicios de programación a ser resueltos por sus usuarios (generalmente estudiantes). Su propósito fundamental es el de automatizar el proceso de compilación y evaluación a las soluciones dadas por los estudiantes a los problemas propuestos. Esta sección propone el desarrollo de un método de recomendación de problemas a resolver para jueces en línea de programación. Este resultado ha sido presentado en Yera y Martínez, 13 en la revista Applied Intelligence. En adición, una versión inicial del trabajo fue publicada en Yera y Caballero. 14
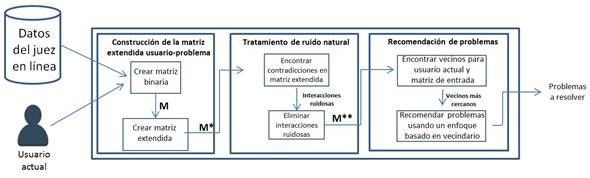
La figura 1 presenta el esquema del sistema recomendador que se propone para los jueces en líneas de programación. Este recomendador está compuesto por 3 etapas:
Construcción extendida de la matriz usuarios-problemas. Se propone la creación de una matriz binaria usuario-problema, donde M[u,p]=1 si el usuario u resolvió el problema p, y 0 de lo contrario. Posteriormente está matriz se enriquece con la información sobre los intentos fallidos de los usuarios de resolver cada uno de los problemas, acorde a la siguientes ecuaciones, en las que D(u,p).n es la cantidad de intentos fallidos del usuario u resolviendo el problema p. Los parámetros λ son determinados experimentalmente.

Tratamiento de “ruido natural”. Se aplica el enfoque presentado en la sección 2, realizando la corrección acorde a las siguientes ecuaciones:

Asumiendo que: C1 u = {p | M*[u, p] = 3}, C2 u = {p | M*[u, p] = 4}, C1 p = {u | M*[u, p] = 3}, y C2 p = {u | M*[u, p] = 4}.
Recomendación de problemas. Utilizando la matriz M**, para recomendar problemas a resolver a un usuario, se buscan los k vecinos más cercanos tomando como base una versión modificada del coeficiente de coincidencia simple. 13 La similitud entre los usuarios así como el hecho de haberlo resuelto o no, se utiliza para ponderar cada problema a resolver, acorde a la siguiente ecuación:
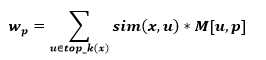
El listado de recomendaciones finales se obtiene ordenando de forma descendente los problemas no resueltos acorde a su valor wp. Una extensión de esta propuesta, integrando lógica difusa para una representación más precisa de la información, se desarrolló en Yera et al.. (15)
RESULTADOS Y DISCUSIÓN
La presente sección se centra en hacer una breve referencia a los resultados experimentales asociados a la evaluación de las presentes propuestas, realizándose de manera sintética por una cuestión de límite de espacio. Para más detalles, consultar las referencias asociadas a los métodos presentados. 3,11,13
Se desarrollaron evaluaciones experimentales utilizando datasets bien conocidos en el área del conocimiento:
Movielens 100K. Está compuesta por 100000 ratings dados por 943 usuarios sobre 1682 filmes. Están en el rango [1; 5].
MovieTweeting, (16 compuesta por alrededor de 140000 ratings provistos por 21018 usuarios sobre 12569 ítems, y en este caso los ratings están en el intervalo [0, 10].
Netflix Tiny, compuesta por 4427 usuarios, 10000 filmes, y 561236 ratings. Es una versión pequeña del dataset Netflix.
Estas bases de datos son preparadas acorde al procedimiento propuesto por Gunawardana y Shani 17 para construir conjuntos de entrenamiento y prueba. En adición, el desempeño del método propuesto se evalúa utilizándose el protocolo definido previamente por Yera et al. 3 para sistemas recomendadores individuales.
Este protocolo se utiliza para comparar la propuesta inicial de preprocesamiento de datos presentados, contra trabajos de referencia previamente desarrollados. Se compara la propuesta de Yera et al. (3) contra O’Mahony et al. 18 y Li et al., (19) mostrándose el efecto posterior de la utilización de los datos corregidos, en modelos tradicionales de recomendación. En todos los casos la propuesta presentada, da lugar a un error medio absoluto menor en las recomendaciones.
Este protocolo se utiliza también para comparar el método NNM-FT con trabajos previamente relacionados. Específicamente, se compara contra los enfoques de O’ Mahony (18 (DiffBased), Li et al. 19 (NNMU), y Yera et al. 3 (NN-Crisp), y un trabajo base que no considera ningún tratamiento de ruido natural. NNM-FT alcanza el mejor resultado en todos los casos, y prueba que se supera el desempeño de otros trabajos previos que no consideran el uso de la lógica difusa para el modelamiento de las preferencias de los usuarios.
Además, se realiza la evaluación de los métodos NNM-LL, NNM-LG, NNM-GG, NNM-H, presentados en Castro et al., 11 y del método NNMG-FT, 12 presentado previamente. Con este fin, se utiliza el protocolo definido por De Pessemier et al., 20 específicamente para recomendación grupal.
Para medir el desempeño de cada método, se compara el desempeño (MAE) de varios recomendadores grupales usando los datos de preferencias después de la aplicación de estos métodos. Específicamente, se evalúan utilizando recomendadores grupales basados en agregación de recomendaciones, 20 e incorporan las estrategias de agregación promedio y “miseria mínima” por cada una de estas estrategias de agregación.
En la primera evaluación, el método NNM-H obtiene los mejores resultados para la mayoría de los escenarios. Sin embargo, es destacable que el método NNM-LG es también capaz de mejorar el método base, realizando únicamente la corrección a nivel de grupo y por tanto con mejor costo computacional.
En el caso del trabajo que considera el uso de técnicas difusas, se comparan 3 enfoques de tratamiento de “ruido natural” en recomendación grupal: a) NNMG-Crisp, centrado en tratamiento de ruido natural usando técnicas “duras”, b) Base, que considera el uso del dataset original, y c) la presente propuesta NNMG-FT.
En el esquema de agregación de las recomendaciones usando la estrategia promedio, la mejora relativa de NNMG-FT en relación con el resto de los métodos fue uniforme para todos los tamaños de los grupos. En el caso de la agregación de recomendación con la estrategia de “miseria mínima”, la mejora fue más grande que en el caso de la estrategia promedio debido a la mayor sensibilidad al “ruido” por parte de dicha estrategia. Específicamente, la mayor mejora fue obtenida para el caso de grupos grandes.
Para la evaluación del método para el juez en línea, se construyó una base de datos proveniente del Juez en Línea Caribeño, compuesta por 1910 usuarios, 584 problemas, y más de 148000 intentos de los usuarios de resolver problemas. Esta base de datos es preparada también acorde al procedimiento propuesto por Gunawardana y Shani 17 para construir conjuntos de entrenamiento y prueba. En este caso, como se trata de la tarea de recomendar un listado de ítems, se utilizan la métrica F1 para evaluar la eficacia de las recomendaciones.
Tabla 2 Evaluación del método de recomendación para jueces en línea de programación, utilizando la métrica F1
| 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | |
| Proposal | 0,3875 | 0,3933 | 0,3784 | 0,3582 | 0,3397 | 0,3220 | 0,3055 | 0,2916 |
| Binary | 0,3614 | 0,3687 | 0,3540 | 0,3352 | 0,3189 | 0,3026 | 0,2895 | 0,2767 |
| UCF-OJ | 0,3833 | 0,3899 | 0,3736 | 0,3543 | 0,3367 | 0,3194 | 0,3035 | 0,2890 |
| ICF-OJ | 0,3602 | 0,3624 | 0,3494 | 0,3348 | 0,3191 | 0,3058 | 0,2932 | 0,2808 |
Tomado de Yera y Martínez. 13
La tabla 2 presenta la evaluación de la propuesta, así como su comparación con otros trabajos del estado del arte, 21 utilizando 130 vecinos para la generación de la recomendación. Se muestra que el método propuesto supera a otros trabajos del estado de arte por un amplio margen. Más detalles sobre este proceso de evaluación puede ser consultado en Yera y Martínez. 13
Conclusiones
Esta memoria ha propuesto 4 métodos para la corrección de ratings inconsistentes en sistemas recomendadores, 2 de los cuales utilizan técnicas difusas para una representación más flexible de la información. Posteriormente, se construye un método de recomendación para un juez en línea de programación, tomando como base estos métodos. Los trabajos futuros están centrados en la incorporación de la dinámica temporal de las preferencias de los usuarios dentro de los modelos presentados.

