










 Serviços customizados
Serviços customizados Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1.-INTRODUCCIÓN
Para prevenir enfermedades congénitas que afectan el sistema metabólico humano y que causan problemas posteriores como retardo mental e incluso la muerte, se recomienda realizar el tamizaje neonatal a todos los recién nacidos. El tamizaje neonatal es una prueba que consiste en hacer una pequeña punción en el talón para tomar unas pocas gotas de sangre del recién nacido. Estas gotas son colocadas en un papel especial y son analizadas en el laboratorio en busca de alteraciones metabólicas, inmunológicas o endocrinológicas que pueden afectar el crecimiento del niño y su desarrollo como persona.
El tamizaje neonatal brinda la oportunidad de identificar enfermedades como el Hipotiroidismo Congénito, la Hiperplasia Suprarrenal, la Fenilcetonuria, la Galactosemia, la Fibrosis Quística y otras afecciones, que no permiten el normal funcionamiento de los procesos bioquímicos en el cuerpo y que complicarían el desarrollo del niño. Muchas de estas enfermedades son poco frecuentes pero son tratables si se detectan antes de que se manifiesten y causen daños irreversibles.
La posibilidad de realizar pruebas de laboratorio en una pequeña muestra de sangre que se conserva por largo tiempo en un papel filtro, se desarrolló gracias al trabajo del pionero Robert Guthrie, lo que permitió el inicio de programas como el tamizaje neonatal de forma masiva. En Cuba, desde 1983, se realizan estas pruebas a los recién nacidos y se van incorporando paulatinamente nuevas pruebas para la prevención y tratamiento de las enfermedades congénitas.
En el sistema de salud pública cubano se emplea una tarjeta con papel filtro como la mostrada en la Figura 1. En esta tarjeta se toman las muestras de sangre y posteriormente se lleva esta tarjeta al laboratorio para su análisis por los especialistas. Una de las etapas de este análisis es la identificación de la calidad de las muestras de sangre basándose en la coloración, el secado, la presencia de impurezas, anillos, coágulos y sueros, entre otros elementos analizados. Este proceso requiere de un alto entrenamiento y especialización que permiten a los especialistas determinar la calidad de las muestras con criterios basados en la experiencia, agilidad y memoria visual en la actividad para poder comparar estas muestras con otras analizadas anteriormente.

Estos motivos justifican el procesamiento digital de la tarjeta para eliminar los errores cometidos e identificar de manera automática la calidad de cada muestra de sangre. Este procesamiento estará basado en técnicas de procesamiento digital de imágenes, reconocimiento de patrones y la inteligencia artificial con el aprendizaje profundo. Por tanto, este trabajo tiene como objetivo desarrollar un clasificador basado en redes neuronales artificiales profundas que determine la calidad de las muestras de sangre.
1.1.- TRABAJOS RELACIONADOS
En la medicina actual, los análisis realizados para la detección de enfermedades están validados por normas de calidad o pruebas de calidad desarrolladas por los científicos e investigadores. A continuación se describen algunos trabajos donde se desarrollan estas técnicas o pruebas de calidad.
Por ejemplo, en Brown et. al. se realizan análisis estadísticos de imágenes de microarreglos de ADN [1], mostrando que el conteo de la cantidad de ADN fluorescente está sujeto a una considerable inexactitud, debido a las grandes y pequeñas fluctuaciones de la intensidad en las manchas, a ambientes no aditivos y a los dispositivos de fabricación. Con la realización de pruebas mediante esquemas simples de balanceo basados en estos estimados, se logra un mejoramiento significativo de la calidad de la imagen de la mancha y, por consiguiente, mejorar la calidad de los datos del microarreglo.
En Chen et. al. se plantea que para cada mancha en un microarreglo se deben extraer de sus respectivos fondos las señales en dos canales [2], (las señales de las intensidades de los colores rojo y verde), por eso enfocan el trabajo en la estimación de las señales de los dos canales y su significado, fundamentalmente en el efecto de una baja razón señal/ ruido. Con estos datos, se crea una métrica para determinar la calidad de las manchas, que es usada para determinar si se elimina o no una proporción de datos y para reflejar más confianza en la calidad de las mediciones. Además, se desarrollan métricas para medir la calidad de la intensidad fluorescente, la calidad del área de la mancha y la calidad de la señal.
En Smyth et. al. se plantea que existen dos grandes aproximaciones para la medición de la calidad de manchas individuales en los microarreglos de ADN [3]. La primera es acertar la calidad de una mancha de acuerdo a sus características físicas (como el área de la mancha, perímetro, localización, heterogeneidad, circularidad, etc). La segunda es determinar la calidad de la mancha de acuerdo a una comparación empírica con otras ya conocidas del mismo gen estudiado. Se plantea que una aproximación integral de la calidad de la mancha en el microarreglo de ADN debe tomar ambas aproximaciones.
En Chimka et. al. se realiza la descripción de parámetros físicos que están asociados a los datos de la mancha del microarreglo en la imagen [4] como el fondo que recubre el centro, la diferencia de la intensidad de los pixeles entre el fondo y el primer plano de la imagen, entre otros. Con estos datos se realiza la estimación de parámetros límites para determinar los errores de clasificación de los modelos independientes de medición de calidad. Por otra parte, Wu y Chimka [5] muestran una descripción de un método multivariable basado en regresión logística y análisis de curvas de ROC, que distingue entre imágenes digitales de manchas utilizables y otras con baja calidad, de acuerdo a los datos asociados al microarreglo de ADN.
Soloviev y Timothy [6] realizan una revisión de más de 20 métodos, herramientas y expresiones para la medición de la calidad de las manchas de ADN en un microarreglo, brindando especial atención al método de la matriz de expresión de control de calidad como un método universal para el control de calidad, tomando en cuenta las diversas maneras de expresar los datos.
En Yu et.al. se utiliza una delgada capa de cromatografía y técnicas simples de procesamiento digital de imágenes para evaluar la calidad e identidad de los medicamentos para diferenciarlos de aquellos que son falsos [7]. Se concluye que la calidad del fármaco es evaluada por la intensidad de la mancha en la imagen de acuerdo a la concentración del componente activo, pues mientras mayor sea la intensidad de la mancha mayor será la concentración del componente activo.
Los trabajos anteriores se basan en la detección de la calidad de la mancha por sus características físicas y la intensidad de la mancha en su generalidad. Este trabajo realiza una propuesta basada en las relaciones estadísticas de los momentos de color y las componentes de HSV junto a un autocodificador profundo para determinar la calidad de la mancha analizada. Se introducen las componentes de HSV y el aprendizaje profundo como elementos novedosos en estos análisis de calidad.
2.- MATERIALES Y MÉTODOS
2.1.- METODOLOGÍA
La Figura 2 muestra la metodología utilizada para el logro de la identificación de la calidad de las muestras de sangre. La imagen de la tarjeta es tomada por una cámara digital de resolución estándar y es almacenada en el espacio de color RGB para su procesamiento.
Después de obtenida la imagen de la tarjeta, se realiza el proceso de segmentación para la identificación y extracción de las imágenes de las muestras de sangre en la tarjeta. En esta etapa se identifica la región de interés de trabajo dentro de la tarjeta y se realiza el proceso de detección de bordes de las muestras de sangre, utilizándose para ello el algoritmo de Canny y la transformada circular de Hough para la detección de la forma elíptica de las muestras.
En la Figura 3 (a) se encuentran representadas cada una de las cuatro regiones de interés, así como las muestras de sangre encerradas en la forma elíptica como resultado de la transformada de Hough. Por otra parte, la Figura 3 (b) muestra la imagen de la tarjeta en la máscara binaria, filtrada y libre de ruido.
La sangre tiene un color predominantemente rojo en su estado natural, con rangos propios de valores de matiz, saturación y valor de brillo. Sin embargo, cuando la sangre contiene coágulos, sueros y demás impurezas, su color puede variar, así como sus componentes de matiz, saturación y valor de brillo. En ocasiones, las variaciones de estas propiedades son apreciables por el especialista y desecha la muestra, pero en otras no se notan con facilidad pues pueden ser poco perceptibles por el ojo humano, por lo que se puede incurrir después en un error de diagnóstico. De ahí que las características extraídas de las imágenes de las muestras de sangre para la clasificación de la calidad sean, en lo fundamental, los momentos de color y las componentes de matiz, saturación y valor de brillo. Con estas propiedades del color de la sangre se logra determinar con buena precisión la calidad de las muestras de sangre. Por esta razón se escogen como los elementos para el aprendizaje de las redes neuronales profundas que realizarán la clasificación de las imágenes de las muestras de sangre.
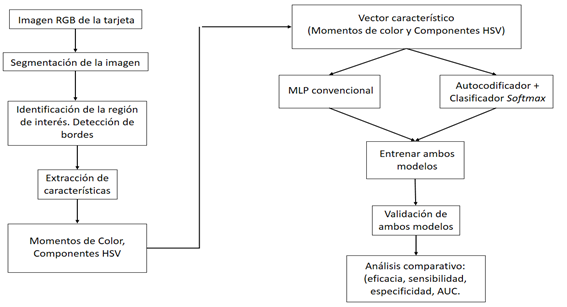

Figura 3 Proceso de segmentación de la imagen de la tarjeta. (a) Identificación de las muestras de sangre. (b) Resultado de la segmentación utilizando la transformada circular de Hough.
Todo este proceso de segmentación, de identificación de las regiones de interés, de aplicación de la transformada circular de Hough y la extracción de características de las imágenes de las muestras de sangre, se realiza empleando técnicas y métodos presentes en la librería de código abierto EMGU CV (versión 3.1). Esta biblioteca se especializa en el procesamiento digital de imágenes para el desarrollo de aplicaciones en lenguajes de alto nivel como C# y es muy utilizada por las potencialidades y la robustez de sus métodos.
El resto del trabajo se organiza de la siguiente manera: en la sección 2.2 se describen las premisas teóricas de los momentos de color, utilizados para la caracterización de las imágenes mediante el color. En la sección 2.3 se describen las componentes de matiz, saturación y valor del brillo para la descripción del color de las imágenes en un espacio de color más cercano al ojo humano. La sección 2.4 describe los principales elementos de una red neuronal perceptrón multicapa convencional. La sección 2.5 describe las características fundamentales de los autocodificadores profundos. Por último, la sección 3 establece los fundamentos teóricos fundamentales sobre el análisis de las curvas de característica de receptor operativo, así como de los índices estadísticos de sensibilidad, especificidad, eficacia y área bajo la curva, utilizados para determinar el rendimiento de los clasificadores basados en inteligencia artificial. Además aquí se exponen los principales resultados obtenidos en el trabajo.
2.2.- MOMENTOS DE COLOR
La caracterización del color es una de las técnicas visuales más usadas en el análisis de imágenes debido a su simplicidad y rápido poder de cálculo [8]. Uno de los principales aspectos de la extracción de propiedades de color es la elección de un espacio de color, como el espacio RGB, que asigna a cada pixel un vector con tres elementos que poseen las intensidades de color de cada uno de los tres colores primarios: Rojo, Verde y Azul. Este espacio describe completamente los valores de todos los colores visibles y constituye un espacio útil en la representación de las propiedades de una imagen. El color no depende del tamaño de la imagen y brinda una medida de la similitud entre dos o varias imágenes [9,10].
Cada distribución de color puede ser caracterizada por sus momentos y la mayor parte de la información está concentrada en los momentos de orden bajo. Solo el primer momento (Media), el segundo momento (Desviación estándar) y el tercer momento (Oblicuidad) son tomados como los vectores característicos y se calculan para cada uno de los canales de la imagen [11]. Luego, en el espacio RGB una imagen está caracterizada entonces por nueve momentos de color, tres momentos por cada uno de los colores primarios que la componen.
El principio básico de los momentos de color está en que asumen que la distribución de colores de una imagen puede ser interpretada como una distribución de probabilidades. Si los colores de una imagen siguen una cierta distribución de probabilidades, los momentos de esa distribución pueden ser usados como propiedades para identificar a esa imagen basadas en el color [11].
Los momentos centrales media (
2.3.- COMPONENTES DE MATIZ, SATURACIÓN Y VALOR DE BRILLO
El modelo de color HSV define el color en término de 3 componentes: matiz (en inglés hue), saturación (en inglés saturation) y el valor (en inglés value). Este modelo de color es aproximadamente un espacio de color de percepción uniforme que se relaciona muy bien con el sentido humano de percepción del color [8,13].
El matiz (H) representa un color verdadero como el rojo, verde, amarillo, etc y sus valores puros contienen los colores primarios, secundarios y las combinaciones lineales de ellos para formar otros colores. Como una medida física, el matiz es relacionado con la longitud de onda de la luz [13].
La saturación (S) representa la pureza del color y brinda una medida de la cantidad de color verdadero que ha sido diluido por el blanco. La diminución de la saturación viene en correspondencia con un aumento directo del color blanco [13].
El valor (V) es una componente análoga al brillo. Esta componente brinda una medida de la separación del color verdadero sobre el negro. Una disminución del valor del brillo corresponde con un aumento de la oscuridad [13].
El espacio de color HSV fue diseñado como una deformación del cubo de color RGB. En otras palabras, es un sistema de coordenadas diferentes describiendo el modelo RGB, pero que se acerca más a la forma de pensamiento humano en cuanto a la identificación del color se refiere.
2.4.- REDES NEURONALES ARTIFICIALES
Una red neuronal es un sistema adaptativo que puede cambiar los parámetros de su estructura para clasificar un problema basado en la información interna o externa que fluye a través de la red. Una red neuronal también puede clasificarse como un instrumento de modelación no lineal y puede usarse para modelar sistemas con entradas y salidas complejas, por lo que existen numerosas conexiones entre los nodos de los datos [14,15].
Las redes perceptrón multicapa (MLP) son las redes neuronales feedforward más comúnmente usadas debido a su rápida operación, fácil implementación y requieren pequeños conjuntos de datos para el entrenamiento. Una red feedforward está compuesta por una o más capas de neuronas con un alto grado de interconectividad: la capa de entrada, las capas ocultas y la capa de salida. La propagación de la información fluye en un solo sentido: desde la capa de entrada hacia las neuronas de la capa de salida [14,16].
Considérese una red feedforward de una sola capa oculta con
Donde:
x j 0 |
- número de neuronas de entrada, |
j |
=1,2,…,u, |
xi 1 |
- número de neuronas ocultas, |
I |
=1,2,…, r, |
w ru 1 |
- pesos entre la capa de entrada y la capa oculta, |
f |
- función de activación de las neuronas ocultas, |
r, u |
- tamaños de la capa oculta y de entrada respectivamente. |
La función
Los algoritmos de entrenamiento son una parte importante de las redes neuronales. Una estructura apropiada puede fallar en dar un modelo mejor a menos que sea entrenada por un algoritmo de entrenamiento adecuado Uno usado muy frecuente para el entrenamiento de las redes MLP es el algoritmo de retropropagación del error, a pesar de que no garantiza encontrar el error mínimo global de la función desde que el gradiente desciende porque puede quedarse atascado en un mínimo local donde permanece indefinidamente. Por lo tanto, muchas variaciones para mejorar este algoritmo y su convergencia han sido propuestas, como los métodos de segundo orden (gradiente conjugado, quasi-Newton, Levenberg-Marquardt) que han sido muy utilizados en los últimos tiempos.
2.5.- AUTOCODIFICADORES PROFUNDOS
Las redes neuronales profundas son redes perceptrón multicapa con muchas capas ocultas, cuyos pesos están completamente conectados y son frecuentemente inicializados usando técnicas de pre-entrenamiento supervisadas o no supervisadas [18].
Un autocodificador es un tipo especial dentro de las redes neuronales profundas, cuyos vectores de salida tienen la misma dimensión que los vectores de entrada. Es usado frecuentemente para el aprendizaje de una representación o la codificación efectiva de datos originales. Los autocodificadores son métodos de extracción de características no lineales sin el uso de etiquetamiento de clases, en los que los datos en la salida se corresponden con los de la entrada, a pesar de ser un modelo de aprendizaje no supervisado [18,19].
Un autocodificador típicamente posee una capa de entrada, que representa los datos o características originales en forma de vectores de entrada, una o más capas ocultas que representan la transformación de los datos y una capa de salida que se empareja con la capa de entrada para la reconstrucción. Cuando el número de capas ocultas es superior a uno, el autocodificador es considerado profundo y se entrena usualmente con uno de los tantos algoritmos de retropropagación del error [18].
La red codificadora es definida explícitamente como una función codificadora
La red decodificadora se define como una función de reconstrucción
Los conjuntos de parámetros del codificador y el decodificador son aprendidos al mismo tiempo durante la tarea de reconstruir tan bien como sea posible la entrada original, intentando cometer el menor error posible de reconstrucción
Las formas más usuales del codificador y el decodificador son funciones de mapeo seguidas casi siempre de no linealidades. Las ecuaciones siguientes muestran estos mapeos [20]:
3.- RESULTADOS Y ANÁLISIS
3.1- ANÁLISIS DE CURVAS DE ROC
Una curva clásica de Característica de Receptor Operativo (ROC por sus siglas en inglés) es generada al representar los valores de las proporciones de verdaderos positivos en el eje vertical contra los valores de las razones de falsos positivos en el eje horizontal para varios valores del conjunto de prueba. Esta curva es invariante ante estrictos aumentos o cambios de las razones de verdaderos positivos [21-23].
La curva de ROC brinda una vista simple de forma gráfica del espacio posible de decisión de una determinada variable y, además, el poder de discriminación de una variable ante la detección de entradas positivas/negativas independientemente del rango del evento. Por eso, se utiliza la curva de ROC como una técnica para visualizar, organizar y seleccionar clasificadores de acuerdo a sus rendimientos [24].
Los índices de verdaderos positivos (TP) y verdaderos negativos (TN) representan “el acuerdo” en la clasificación del experto humano y el clasificador. Los índices de falsos positivos (FP) y falsos negativos (FN) representan “los desacuerdos” en la clasificación. Al final de cada época de entrenamiento, cuando todos los patrones de clasificación son presentados al clasificador neuronal, los índices estadísticos de la época (e) son calculados para cada umbral (t), incluyendo la sensibilidad y especificidad [17,25], representadas en las ecuaciones (11) y (12):
La sensibilidad es la habilidad del clasificador de identificar los patrones positivos dentro de todos los patrones verdaderos positivos [26]. La sensibilidad puede variar entre 0 y 1, alcanzando valores cercanos a 1 cuando disminuye el número de falsos negativos.
Por otra parte, la especificidad es la habilidad del clasificador de identificar los patrones negativos dentro de todos los patrones verdaderos negativos [26]. La especificidad varía entre 0 y 1, alcanzando valores próximos a 1 cuando disminuye el número de falsos positivos.
De esta manera se puede plantear que el gráfico de ROC es una unión de todos los pares de sensibilidad/especificidad como resultado de la variación continua del umbral sobre el rango completo de resultados observados [23].
La ecuación (13) muestra la eficacia de un clasificador de acuerdo a los índices de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos, logrados durante el proceso de entrenamiento de la red [25].
Una vez obtenida la eficacia del clasificador se puede calcular el error de clasificación buscando la diferencia de esta eficiencia con la clasificación perfecta:
El valor más comúnmente usado para determinar la precisión o exactitud del clasificador es el área bajo la curva (AUC por sus siglas en inglés) de ROC. Por definición, el AUC es un valor entre 0 y 1 y corresponde con la probabilidad de que una muestra positiva cualquiera sea ubicada por encima de una muestra cualquiera escogida negativa. Mientras mayor sea el valor de AUC mayor será la precisión del clasificador [21-23].
El área bajo la curva de ROC puede ser pensada como una medida simple de probabilidad de ubicar correctamente un par de decisión positivo/negativo [23]. Existen diferentes métodos para determinar el área bajo la curva de ROC, siendo el método binormal uno de los más usados.
La ecuación (15) representa el modelo matemático de la curva de ROC [22] en el método binormal:
Donde:
Φ |
- función de distribución normal acumulativa, |
Φ |
-1 - función inversa de distribución normal acumulativa, |
a |
=(μ1-μ0)/σ1 , |
b |
=σ0/σ1 , |
μ 0 |
- media de los valores de los eventos negativos, |
μ 1 |
- media de los valores de los eventos positivos, |
σ 0 |
- desviación estándar de los valores de los eventos negativos, |
σ 1 |
- desviación estándar de los valores de los eventos positivos. |
Por su parte, la ecuación (16) plantea la forma de realizar el cálculo del área bajo la curva de ROC [22] en el método binormal. Nótese que tanto la modelación de la curva de ROC como su área se determinan mediante el cálculo de la distribución normal acumulativa.
3.2- DISCUSIÓN DE LOS RESULTADOS
La realización de los experimentos estuvo compuesta por dos etapas: el entrenamiento y la validación de la red neuronal perceptrón multicapa convencional y el entrenamiento y validación de los autocodificadores en cascada más el clasificador softmax. La red feedforward está compuesta por una capa de entrada con 12 neuronas, una capa oculta con 24 neuronas y una capa de salida.

Figura 4 Sistema de clasificación de aprendizaje profundo formado por dos autocodificadores en cascada y un clasificador softmax en la salida.
La Figura 4 muestra el sistema de clasificación obtenido por los autocodificadores junto al clasificador softmax. Ambos codificadores presentan ocho capas ocultas. En el primer codificador se procesan los vectores de entrada formados por los momentos de color y las componentes de matiz, saturación y valor de brillo, mientras que en el segundo codificador se descifra el mapeo generado por el primero. La salida del segundo codificador se conecta a un clasificador softmax y se logra entonces la clasificación final de las imágenes de las muestras de sangre con buena calidad o no.
Para el aprendizaje de la red se utilizaron los momentos de color y las componentes de matiz, saturación y valor de brillo de 720 imágenes de muestras de sangre, de las cuales 249 tienen la calidad requerida y 471 presentan limitaciones para proseguir con los análisis. El entrenamiento y validación de la red convencional, así como del clasificador de aprendizaje profundo se realizaron mediante la validación cruzada, dividiéndose el total de muestras en cinco bloques de datos para ello.
Tabla 1 Resultados obtenidos de la validación de la red feedforward convencional.
| Eficacia (%) | Sensibilidad (%) | Especificidad (%) | AUC | |
|---|---|---|---|---|
| 1 | 94.3 | 91.3 | 96.7 | 0.9601 |
| 2 | 90.2 | 83.6 | 94.8 | 0.9199 |
| 3 | 92.9 | 89.7 | 95.4 | 0.9389 |
| 4 | 91.8 | 86.9 | 95.8 | 0.9323 |
| 5 | 93.5 | 90.7 | 93.4 | 0.9429 |
| Media | 92.54 | 88.44 | 95.22 | 0.9388 |
La Tabla 1 muestra los resultados de la etapa de validación de la red feedforward convencional. Esta red presenta buenos valores de eficacia, comportándose generalmente sobre el 90%, con una eficacia media de 92.54%. Este valor muestra una buena capacidad de la red para clasificar las muestras en positivas o negativas, aunque incurre en un error medio de clasificación de 7.46%.
Los valores de sensibilidad de la red durante la validación varían entre el 83% y el 91%, alcanzando el valor más bajo en el segundo experimento. La sensibilidad media del clasificador en esta etapa es de 88.44%, lo que indica la habilidad media de la red para identificar los patrones positivos dentro de todos los patrones entrados para la clasificación.
La especificidad tiene un comportamiento con poca variación en esta etapa, manteniendo los valores entre 93.4% y 96.7%, con un valor medio de 95.22%. Este valor medio de especificidad representa la habilidad media del clasificador para identificar los patrones negativos dentro de todos los patrones sometidos a la clasificación.
Por otra parte, los valores de área bajo la curva de ROC se comportan entre 0.9199 y 0.9601, con una media de 0.9388 en la etapa de validación de la red. Este índice brinda una precisión media para el clasificador de un 93.88%, indicando la capacidad de la red para ubicar correctamente los pares de decisión positivos/ negativos.
Tabla 2 Resultados obtenidos de la validación del clasificador basado en autocodificadores.
| Eficacia (%) | Sensibilidad (%) | Especificidad (%) | AUC | |
|---|---|---|---|---|
| 1 | 97.5 | 96.4 | 99 | 0.985 |
| 2 | 96.6 | 95.3 | 98.1 | 0.9799 |
| 3 | 99.1 | 100 | 98.4 | 0.9963 |
| 4 | 97.4 | 96.6 | 100 | 0.9839 |
| 5 | 98.3 | 98.9 | 95.8 | 0.9921 |
| Media | 97.78 | 97.44 | 98.26 | 0.9874 |
La Tabla 2 muestra los resultados obtenidos en la etapa de validación del clasificador de aprendizaje profundo. La eficacia se comporta entre el 97% y el 99%, con un valor medio de 97.78%. Este valor es aproximadamente unos 5 puntos porcentuales superior al obtenido con la red feedforward convencional, por lo que este clasificador posee un rendimiento superior al de la red perceptrón multicapa, incurriendo en un error medio para la clasificación de solo 2.22%.
Los valores de sensibilidad del clasificador de aprendizaje profundo oscilan entre 95% y el 100%, con una valor medio de 97.44%, mostrando una mejoría de aproximadamente 9 puntos porcentuales respecto a la red perceptrón multicapa convencional. Este valor medio de sensibilidad muestra una magnífica habilidad para detectar los patrones positivos dentro de todos los patrones en la entrada del clasificador.
La especificidad de este clasificador oscila entre 95% y el 100%, teniendo un valor medio de especificidad de 98.26%, mostrando mejoría de aproximadamente 3 puntos porcentuales respecto a la red feedforward. Con este valor de especificidad, el clasificador posee una estupenda habilidad para identificar los patrones negativos dentro de todos los patrones entrados al clasificador.
Los valores del área bajo la curva de ROC están comprendidos entre 0.9799 y 0.9963, teniendo un valor medio de AUC de 0.9874, siendo aproximadamente 5 puntos porcentuales por encima del valor medio de AUC para la red feedforward. El valor medio de AUC indica un 98.74% de precisión del clasificador para ubicar correctamente los pares de decisión positivos/ negativos.
La Figura 5 (a) muestra un gráfico de las eficacias obtenidas durante la validación de la red perceptrón multicapa y del clasificador basado en autocodificadores profundos. Las barras azules representan las eficacias obtenidas para la red neuronal convencional, mientras que las barras rojas corresponden con las eficacias obtenidas para el clasificador basado en autocodificadores. Aquí se observa que el experimento con menor valor de eficacia para ambos modelos corresponde con el experimento 2, mientras que la mayor diferencia en puntos porcentuales corresponde también con el experimento 2, con una diferencia por encima de 6.4 puntos porcentuales del clasificador basado en autocodificadores respecto a la red feedforward convencional.
La Figura 5 (b) muestra las áreas bajo la curva de ROC en las etapas de validación para ambos modelos de clasificación. Nuevamente, el experimento 2 registra la mayor diferencia en puntos porcentuales de AUC del clasificador basado en autocodificadores respecto a la perceptrón multicapa convencional, además de poseer también la menor tasa de valor de AUC para ambos clasificadores.
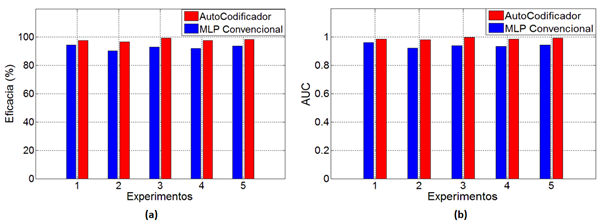
Figura 5 Gráficos de la eficacia y el área bajo la curva de ROC del clasificador basado en autocodificadores y la red feedforward convencional. (a) Eficacia, (b) AUC.
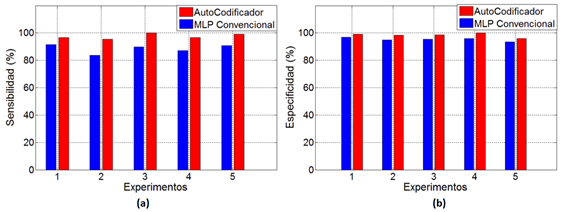
Figura 6 Gráficos de la sensibilidad y especificidad del clasificador basado en autocodificadores y la red feedforward convencional. (a) Sensibilidad, (b) Especificidad.
La figura 6 muestra los gráficos de sensibilidad y especificidad para las etapas de validación del clasificador basado en aprendizaje profundo y la red neuronal convencional. La sensibilidad presenta la mayor diferencia en puntos porcentuales entre ambos clasificadores en el experimento 2, esta diferencia adquiere el valor de 11.7 puntos porcentuales.
Por su parte, la especificidad toma los valores más bajos en el experimento 5 para ambos clasificadores, aunque la mayor diferencia en puntos porcentuales se obtiene en el experimento 4, con un valor de 4.2 puntos porcentuales por encima del clasificador de aprendizaje profundo sobre la red neuronal perceptrón multicapa convencional.
4.- CONCLUSIONES
La importancia de desarrollar el clasificador de muestras de sangre mediante redes neuronales profundas radica en que se logra eliminar los errores cometidos al obtener las muestras de sangre. Este clasificador neuronal discrimina con buena eficacia aquellas muestras que presentan limitantes como coágulos, presencia de anillos, sueros, etc. de aquellas que poseen una buena calidad para proseguir con los análisis especializados en el laboratorio médico.
El clasificador obtenido es una red neuronal profunda compuesta por dos autocodificadores y un clasificador softmax. Esta red neuronal profunda es entrenada para que reconozca patrones de propiedades que describen las imágenes. Los parámetros de entrada a la red son los momentos de color y las componentes de matiz, saturación y valor de brillo.
Este clasificador posee una estupenda eficacia para detectar la calidad de las muestras de sangre, aunque se pueden probar otros métodos basados también en aprendizaje profundo, como las redes neuronales convolucionales, que pueden mejorar el procesamiento de las imágenes de muestras de sangre, pues estas redes realizan todo el procesamiento de extracción de características y aprendizaje de los patrones extraídos.

