










 Serviços customizados
Serviços customizados Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
La evaluación de la educación tiene funciones instructivas, educativas, de comprobación y control, así como de retroalimentación, cuya finalidad es la obtención de información representativa del estado de desarrollo del aprendizaje individual y grupal de los estudiantes. Estas evidencias posibilitan a docentes y directivos emitir juicios de valor que conduzcan a la toma de decisiones y de reorientación, cuyo propósito esencial resulta el mejoramiento de la calidad de la educación.1,2
En el ámbito educativo la idea de evaluación se encuentra homologada a la de acreditación, la cual está estrechamente relacionada con una nota en escala numérica y con la calificación, pero su finalidad formativa está concebida en función de la mejora de las instituciones y de los agentes y agencias que integran la comunidad académica. La evaluación de la calidad de la educación del estudiante de ciencias médicas pretende contribuir al propósito de alcanzar la excelencia en su formación profesional.3
Se hace evidente la necesidad de mantener altos niveles de calidad en la formación de los profesionales de la salud para lograr y mantener resultados relevantes a nivel social en esta esfera.4) Para alcanzar este propósito es importante monitorear y evaluar de forma continua el proceso educativo de los estudiantes de las ciencias médicas en lo referente a la calidad de los instrumentos de evaluación. La psicometría, dentro de la educación médica, desempeña un papel importante para lograr este objetivo. Esta disciplina investiga cómo medir y evaluar de forma óptima los constructos y atributos centrales en el aprendizaje de los estudiantes, como los conocimientos y las competencias; permite analizar la validez de los instrumentos utilizados para la evaluación educativa; y propicia el desarrollo de ideas o propuestas para mejorar dichos instrumentos.5
Existen dos enfoques principales de la psicometría con esta finalidad: la teoría clásica de los test (TCT) y la teoría de respuesta al ítem (TRI). Ambos proporcionan modelos que orientan la construcción de pruebas con propiedades psicométricas adecuadas. El enfoque de la TCT continúa siendo, por mucho, el más utilizado para la evaluación educativa y su aplicación es accesible a docentes no expertos en psicometría. En el campo de la educación médica la TCT es muy empleada en la construcción de reactivos, generalmente del tipo de opción múltiple.6,7
En nuestro país se han realizado diversos estudios con el propósito de evaluar los instrumentos empleados en exámenes finales de diversas asignaturas, lo que ha posibilitado realizar sugerencias para el mejoramiento de su calidad.8,9,10) Apoyados en los criterios expresados, los autores se propusieron evaluar la calidad de las preguntas de opción múltiple del examen final ordinario de la asignatura Propedéutica Clínica del curso 2018-2019.
Este trabajo tuvo como objetivo determinar la validez de las preguntas de opción múltiple y de los ítems de un examen final, mediante el cálculo de los índices de la teoría clásica de test.
Métodos
Se realizó un estudio analítico de corte transversal con el objetivo de evaluar la calidad de las preguntas de opción múltiple del examen final ordinario de la asignatura Propedéutica Clínica. Se calcularon los índices psicométricos para cada reactivo, lo que incluyó la media, la desviación estándar, el coeficiente de asimetría y la correlación del punto biserial; y se expusieron las propiedades de cada pregunta. Se aplicó la evaluación de los reactivos según la teoría clásica de test para definir la validez de cada uno. A partir del análisis de los resultados se arribó a conclusiones.
Los datos analizados en esta investigación se obtuvieron de los resultados del examen ordinario teórico final de la asignatura Propedéutica Clínica, aplicado a los estudiantes de Medicina de tercer año del Hospital Clínico-Quirúrgico “Joaquín Albarrán” en enero de 2019. El instrumento investigado estuvo conformado por 28 preguntas divididas en cuatro baterías, de las cuales 16 fueron preguntas de test.
El universo de estudio estuvo constituido por la totalidad de los cuestionarios de examen (89); y la muestra, por las preguntas de test incluidas en estos, conformadas por 8 reactivos de opción alternativa, 4 reactivos de verdadero o falso múltiple, y 4 reactivos de emparejamiento.
Análisis y procesamiento de la información
Se realizó el análisis de la información a partir la creación de una base de datos en Microsoft Excel para el cálculo de la media, la desviación estándar y el coeficiente de asimetría de los resultados alcanzados por los estudiantes en los ítems evaluados.
Para obtener el grado de dificultad del reactivo se aplicó la fórmula siguiente:11
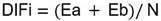
Donde:
Ea y Eb constituyen el número de errores del reactivo i de la población del grupo de rendimiento alto y bajo, respectivamente; y N es el número de sujetos en ambos grupos.
El criterio para valorar cada reactivo y aceptarlo es que tenga un valor entre el 0,20 a 0,80 con un valor óptimo del 0,50 de acierto.
El grado de discriminación del reactivo se estimó según la siguiente fórmula:
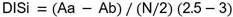
Donde:
Aa y Ab es el número de aciertos de la población del grupo alto y bajo rendimiento, respectivamente en el reactivo i; y N el número de sujetos en la muestra de ambos grupos.
El estadístico DIS varía dentro de un inérvalo de -1 a 1. Valores positivos indican que el reactivo discrimina a favor del grupo superior; y valores negativos, que el reactivo tiene una discriminación inversa a los esperado.12
La correlación del punto biserial (rpbis) se utiliza para saber si las personas “adecuadas” son las que obtienen las respuestas correctas, qué tanto poder predictivo tiene el reactivo y cómo puede contribuir con las predicciones.13
La ecuación para obtener la correlación del punto biserial resultó la siguiente:

Donde:
X1 y X0 es la media de las puntuaciones totales de aquellos que respondieron correctamente e incorrectamente el reactivo i, respectivamente; Sx la desviación estándar de las puntuaciones totales; n1 y n0 el número de casos que respondieron correctamente e incorrectamente el reactivo, respectivamente; y n la suma de n1 y n0.
Resultados
En la figura se expone la frecuencia relativa de la respuesta de los ítems. Se observa por cada ítem el número de sustentantes que respondieron correctamente y su complemento, los que respondieron incorrectamente o no respondieron; por premisa se debían excluir del análisis los reactivos contestados por todos los evaluados correctamente o incorrectamente, situación que no se presentó. También, se aprecia que la no respuesta fue nula. Estos resultados son los esperados para un examen final de asignatura bien confeccionado.

En la tabla 1 se exponen los índices psicométricos calculados para cada reactivo. La media y desviación estándar constituyen índices que guardan estrecha relación con los resultados obtenidos por los estudiantes en cada ítem, pero ninguna con el grado de validez del reactivo. Son un reflejo del resultado general de los puntajes de los ítems evaluados.
La correlación del punto biserial (Tabla 1) dice más sobre la validez predictiva del test que el coeficiente de correlación biserial, ya que este tiende a favorecer los reactivos de dificultad media. La correlación del punto biserial (rpbis) se utiliza para saber si las personas “adecuadas” son las que obtienen las respuestas correctas, qué tanto poder predictivo tiene el reactivo y cómo puede contribuir con las predicciones.14
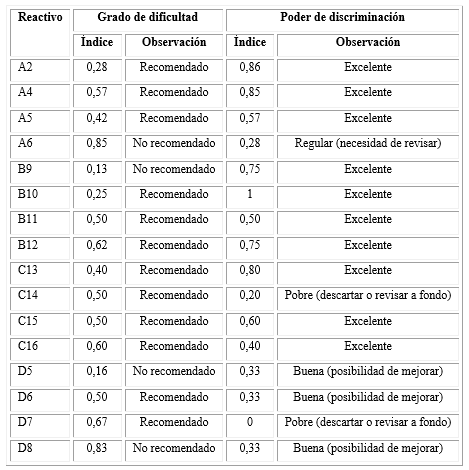
El índice de dificultad de los reactivos está en un rango de 0,13 y 0,85 con una media de 0,49 y una mediana de 0,51. Aun cuando lo ideal resultan los ítems con grado de dificultad alrededor de 0,50, el rango esperado es de 0,20 y 0,80; por ello, los ítems son adecuados con excepción de los reactivos A6y D8 que presentan una dificultad muy alta, y los reactivos B9 y D5, cuya dificultad es demasiado baja; por tanto, 12 de los 16 ítems del examen (75 %) se confeccionaron adecuadamente.
Tabla 1 Índices psicométricos de los reactivos evaluados
| Reactivos | Media | Desviación estándar | Coeficiente de asimetría | Correlación del punto biserial |
|---|---|---|---|---|
| A2 | 4,77 | 0,71 | -1,53 | 0,58 |
| A4 | 4,05 | 2,12 | -0,72 | 0,52 |
| A5 | 4,07 | 1,41 | -0,35 | 0,56 |
| A6 | 3,65 | 2,12 | -0,21 | 0,24 |
| B9 | 4,89 | 0,70 | -2,89 | 1,38 |
| B10 | 4,56 | 1,41 | -1,25 | 0,53 |
| B11 | 3,62 | 2,12 | -0,22 | 0,46 |
| B12 | 3,22 | 2,12 | 0,27 | 0,46 |
| C13 | 4,36 | 1,41 | -0,96 | 0,55 |
| C14 | 4,06 | 2,12 | -0,68 | 0,51 |
| C15 | 3,49 | 2,12 | -0,06 | 0,45 |
| C16 | 3,25 | 2,12 | 0,25 | 0,47 |
| D5 | 4,85 | 0,71 | -2,4 | 0,50 |
| D6 | 4,27 | 2,12 | -0,63 | 0,37 |
| D7 | 3,71 | 2,12 | -0,53 | 0,50 |
| D8 | 3,10 | 2,12 | 0,51 | 0,42 |
En cuanto al índice de discriminación (Tabla 2), dos reactivos tuvieron muy poca capacidad de discriminación (menor que 0,2): C14 y D7, por tanto este indicador fue adecuado en el 87,5% de los reactivos. La capacidad media de discriminación resultó de 0,53; la mínima de 0 y la máxima de 1.
Discusión
La teoría de test proporciona modelos de calificación de las pruebas a partir de matrices de datos que contienen las respuestas a los reactivos. El problema central de esta teoría es la relación existente entre el nivel de capacidad del sujeto (variable latente) y la puntuación observada en el test. Dicho de otro modo, el objetivo de cualquier teoría de test es realizar inferencias acerca del nivel de la habilidad a partir de las respuestas. Por tanto, para estimar la habilidad se necesita relacionar esta con los resultados observables en la prueba. Dicha relación debe estar adecuadamente descrita por una función matemática. Las distintas teorías de test difieren justamente en la función que utilizan para relacionar la actuación observable en la prueba con el nivel del sujeto en la variable inobservable.15
Cano de Becerra16) aconseja que los puntajes tengan una cierta asimetría positiva para los exámenes administrados durante el período de la cursada y negativa en la instancia final. Esta sugerencia se fundamenta en el hecho de que una distribución asimétrica positiva discrimina mejor a los estudiantes con altos rendimientos, lo cual es preferible durante el proceso de enseñanza-aprendizaje para estimularlos a empeñarse más; por el contrario, en el examen final conviene discriminar mejor a los de peor desempeño mediante una distribución asimétrica negativa, de modo que se esté seguro de que desaprueba quien realmente tiene un pobre rendimiento. Las preguntas evaluadas en este estudio tienen en conjunto una marcada asimetría negativa; por ende, una función primariamente certificadora, tal y como se esperaría para un examen final de asignatura.
En la teoría clásica de los test se usan los índices de dificultad y el índice de discriminación para medir la validez de los reactivos que conforman el examen. En general, se espera que los ítems de alta calidad sean contestados por la mitad de los sustentantes, siempre y cuando quienes los aciertan tengan mayor dominio de la habilidad. Los indicadores que permiten valorar estas características psicométricas con el enfoque clásico son los índices de poder de discriminación y del grado de dificultad.17
El índice de dificultad representa la proporción de sujetos con respuesta incorrecta en un determinado reactivo (algunos autores consideran para el cálculo la proporción de respuesta correcta); es válido para pruebas de potencia, donde se espera que los reactivos no contestados reflejen desconocimiento por parte del sujeto.13 En esta investigación se demostró que el 75 % de los reactivos empleados fueron adecuados en relación con su índice de dificultad. Sin embargo, es importante distinguir que, en la Batería D, el 50% de los reactivos no fue adecuado, cifra mayor en esta Batería que en el resto; por ende, existe una deficiencia de estacon relación a las otras.
En la mayor parte de las pruebas convencionales de inteligencia, aptitudes y rendimiento académico, la discriminación del reactivo normalmente se valora con respecto a la puntuación total (criterio interno), con énfasis en la validez de constructo. El ítem que discriminan los encuestados, frente a un criterio externo que la prueba pretende predecir, maximiza la validez; mientras que el reactivo que discriminan, según puntuación total, maximiza la homogeneidad o la consistencia interna de la prueba. Los dos objetivos son deseados, aunque la aplicación de ambos criterios puede llevar a resultados diferentes e, incluso, opuestos. Purificar la prueba de cara a la consistencia interna puede reducir la validez externa.18
El índice de discriminación permite determinar si el reactivo lo aciertan más frecuentemente los sustentantes de alto rendimiento comparados con los de bajo rendimiento. El poder de discriminación es la capacidad del reactivo para diferenciar a los sustentantes que saben de los que no saben.15 En las preguntas evaluadas solo el 12,5 % de los reactivos requería ser descartado y cambiado; pero en general el índice de discriminación fue adecuado para la mayor parte de los reactivos.
Este estudio tiene las limitaciones de no incluir en la investigación las preguntas de desarrollo del examen y que la muestra estudiada estaba distribuida en cuatro baterías.
Los reactivos evaluados según la teoría clásica de los test resultaron aceptables para una prueba de certificación, como es el caso del examen final de una asignatura, aunque presentan deficiencias menores.

