










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Durante la última década, la estimación del riesgo cardiovascular individual se ha convertido en la piedra angular de las guías de prevención para el manejo global de los factores de riesgo en la práctica clínica. El riesgo cardiovascular establece la probabilidad de sufrir un episodio cardiovascular en un determinado período, generalmente 5 o 10 años.1
El cálculo del riesgo cardiovascular individual, tiene importancia clínica por los siguientes motivos: a) es una herramienta útil para identificar a los pacientes de riesgo alto, que merecen atención e intervención intensas y precoces; b) sirve para motivar a los pacientes en el cumplimiento de las medidas higiénico-dietéticas y farmacológicas; c) sirve para modular la intensidad de los esfuerzos en el control de los factores de riesgo cardiovascular según la evolución del riesgo en el tiempo.2
En la actualidad se dispone de múltiples sistemas de estimación de riesgo cardiovascular como: tablas de riesgo basadas en las ecuaciones de Framingham clásica (1973) y sus versiones por categorías, adaptadas a las recomendaciones del National Cholesterol Education Program (NCEP) y el V Joint National Committee (V JNC), de Anderson (1991), Wilson (1998), Grundy (1999) y de D’Agostino (2000), el algoritmo denominado Systematic Coronary Risk Evaluation (SCORE) (2003), el modelo de Prospective Cardiovascular Münster (PROCAM) entre otras.3)
Estos modelos matemáticos asignan diferentes pesos a cada uno de los factores de mayor riesgo (sexo, edad, tensión arterial, tabaquismo, diabetes, niveles de colesterol total, LDL y HDL), de desarrollar enfermedad cardiovascular dentro de un determinado lapso de tiempo.
Las ecuaciones de predicción de riesgo derivadas de estudios en poblaciones totalmente caucásicas y urbanas, gozan de gran aceptación y se usan ampliamente en el mundo, pero existen múltiples evidencias que demuestran que no se pueden aplicar directamente en todas las poblaciones.
Se han descrito diversas causas por las cuales un modelo no funciona de forma adecuada en todas las poblaciones, entre ellas, diferencias en la carga genética, nivel socioeconómico y hábitos dietéticos o variaciones en los sistemas de salud.4 Esto trae consigo la necesidad de realizar una validación externa de todos los modelos de predicción en una población diferente a aquella en la que se desarrollaron inicialmente, mediante la valoración de la calibración y la capacidad de discriminación.
Urge realizar investigaciones para validar el índice pronóstico de morbilidad y mortalidad por enfermedad cardiovascular, asociada con factores de riesgo aterogénico (IRECVA),5 como estimador de riesgo global de enfermedad cardiovascular aterosclerótica en la población general. Existen razones para pensar que el riesgo de enfermedad cardiovascular es sistemáticamente diferente a la población en el que se obtuvo, si se tienen en cuenta las marcadas diferencias demográficas y estilos de vida entre ambas poblaciones.
El objetivo de este estudio es evaluar la validez externa de la ecuación de predicción IRECVA en una muestra representativa de población general.
MÉTODOS
Se realizó un estudio de validación externa en una cohorte poblacional prospectiva de 10 años de seguimiento (2009 - 2019). Se reclutó una muestra de 700 pacientes portadores de hipertensión arterial esencial, libres de eventos cardiovasculares ateroscleróticos al ingreso, atendidos en el Hospital Militar Central “Dr. Luis Díaz Soto”.
Para el cálculo del tamaño de la muestra se consideraron los siguientes los factores:
Riesgo relativo (RR) importante a detectar 3,5
Incidencia de la enfermedad en los grupos menos expuestos 0,008 (p1)
Valor α = 0,05 en hipótesis bilateral para 95 % de confianza
Valor α = 0,20 para un 80 % de potencia
Proporción de la población prevista (p) - 0,30
Precisión absoluta necesaria a ambos lados de la proporción (en puntos porcentuales) (d) - 0,30
El modelo IRECVA permitió la distribución de la muestra en dos grupos de riesgo: grupo de “alto riesgo” (0,21 - 1,0 puntos) y grupo de “bajo riesgo” (0 - 0,20 puntos).
Se realizó para mejor estudio de la relación causa - efecto, la estratificación de la muestra en gradientes de exposición, que se resumieron en 10 deciles de riesgo, según la siguiente distribución: deciles de bajo riesgo 1 y 2, y deciles de alto riesgo, del 3 al 10.
Para evaluar la calibración (precisión de la estimación del riesgo absoluto para compararlas con las tasas de incidencia reales) se compararon los eventos esperados con los eventos observados. La capacidad de discriminación del modelo en la población, se valoró en función del nivel de sensibilidad y especificidad alcanzado en cada subgrupo de exposición. Se representó mediante el área bajo la curva ROC (Receiver Operating Characteristics) con valores deseables > 0,75.
Para el cálculo de la sensibilidad y especificidad de la prueba se contrastaron los casos esperados por el gradiente de riesgo con los observados durante el tiempo de seguimiento, que son resumidos en los siguientes indicadores:
VP = casos del grupo “alto riesgo” que enferman (verdaderos positivos).
FN = casos del grupo “bajo riesgo” que enferman (falsos negativos).
VN = casos del grupo “bajo riesgo” que no enfermaron (verdaderos negativos).
FP = casos del grupo “alto riesgo” que no enfermaron (falsos positivos).
La proporción de individuos enfermos y sanos que el gradiente de exposición es capaz de identificar, se determinó mediante el cálculo de:
Se consideraron como mejores valores aquellos tan próximos al 100 % como sea posible.
La probabilidad del daño se determinó mediante el cálculo de la densidad de incidencia por 100 pacientes - años de seguimiento en cada estrato de la muestra, como expresión de la velocidad de ocurrencia del evento. La fuerza de asociación causal e impacto del riesgo individual y combinado se expresó mediante las estimaciones de riesgo relativo (RR) y fracción etiológica de riesgo (FER) según las siguientes expresiones:
Este último es el límite teórico en que la enfermedad puede ser eliminada si los factores de riesgo no ocurrieran o se redujeran, y tiene en cuenta la proporción de expuestos (Pe) en cada gradiente de la población diana, por lo que es además un indicador de prioridad epidemiológica.
La densidad de incidencia se cuantificó en paciente -años de seguimiento de cada paciente, como expresión de la velocidad de ocurrencia del evento en los estratos de exposición.
Para el control de sesgos se adoptaron las siguientes medidas durante el desarrollo del estudio:
Estratificación de la población por sexos, grupos de edades y determinar la significación estadística de las diferencias.
Riguroso monitoreo de la exposición a riesgos por cada paciente para detectar posibles modificaciones que influyeran en la homogeneidad interna de las cohortes. Un cambio significativo en la clasificación individual de un paciente, se consideró como criterio de exclusión del estudio.
Para evitar el sesgo de información se aseguró la recolección homogénea de los datos en los grupos seleccionados, los cuales fueron igualmente encuestados, examinados y monitorizados.
Un equipo médico del Hospital Militar Central "Dr. Luis Díaz Soto”, en función de observadores independientes, corroboró la calidad del diagnóstico.
El personal participante no conocía la pertenencia de los pacientes a los grupos de estudio, lo cual aseguró condiciones de enmascaramiento necesarias.
Para minimizar el error de medición se validaron los instrumentos utilizados: cuestionarios, pruebas psicométricas, esfigmomanómetros, balanzas y técnicas de laboratorios.
Para el análisis de los datos se utilizaron medidas de resumen de las variables cuantitativas en (deciles) y las cualitativas en (razones, proporciones, así como tasas de prevalencia y densidad de incidencia x 100 y 1000 pacientes - años). Se emplearon medidas de tendencia central (medias) y de dispersión (varianzas y amplitud). Se realizaron estimaciones puntuales y por intervalo, con un nivel de confianza del 95 % (IC 95 %).
De acuerdo al carácter dubitativo de la normalidad de las variables, para el contraste de las hipótesis de homogeneidad e independencia entre los estratos, se utilizó el test de chi cuadrado de Mantel y Haenszel, para variables cualitativas independientes y el Kruskal Wallis para variables cuantitativas independientes. Se tomó un alfa < 0,05 para determinar la significación estadística de los resultados.
Se empleó el análisis de correlación no paramétrica de Kendall para 2 colas, para determinar relaciones entre el gradiente de exposición y la incidencia de enfermedad cardiovascular.
Se calcularon los RR crudos y ponderados, mediante el estadístico de Mantel y Haenszel, para definir asociación causal entre exposición a riesgo y la incidencia de daño, así como el riesgo atribuible (RA) para estimar su impacto en los grupos de población expuestos.
Se compararon las curvas de vida libre de eventos cardiovasculares, con ataques a órganos diana, mediante el análisis de fallos acumulativos de Kaplan - Meier. Se presenta una graduación logarítmica estratificada según grupos de alto y bajo riesgo.
La información recogida fue introducida en una base de datos creada al efecto en el programa SPSS para Windows versión 20. Los resultados se llevaron a tablas para su mejor análisis y comprensión.
La investigación se realizó conforme a los principios éticos recogidos en la declaración de Helsinki y revisiones posteriores.
RESULTADOS
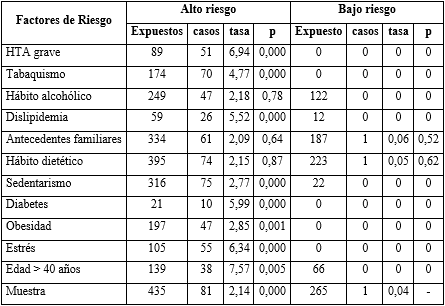
En la tabla 1 se muestra el análisis univariado de la asociación causal entre los factores de riesgo individuales y la enfermedad cardiovascular ateroesclerótica. Se puede apreciar que destacó el grupo de “alto riesgo” como el de mayor incidencia con 2,14 enfermos x 100 paciente - año. Fueron más significativos: la edad (7,5 x 100), la hipertensión arterial (HTA) grave (6,9 x 100), el estrés (6,34 x 100), la diabetes mellitus (5,9 x 100) y la dislipidemia (5,5 x 100).
No alcanzaron el nivel de significación establecido, el consumo de alcohol, los antecedentes familiares y los malos hábitos dietéticos. Del total de factores de exposición del grupo “bajo riesgo”, solo hubo manifestación de la enfermedad en un paciente con antecedentes familiares y malos hábitos dietéticos, lo cual fue estadísticamente no significativo.
Tabla 1- Incidencia de la enfermedad cardiovascular ateroesclerótica en pacientes expuestos a factores de riesgo
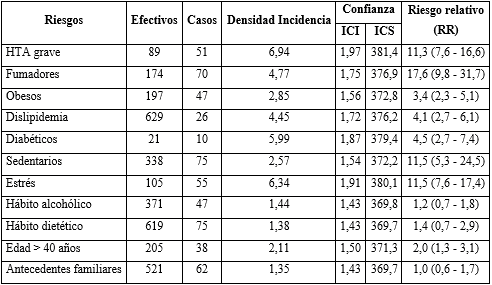
En la tabla 2 se resumen que las mayores tasas de incidencia de la enfermedad cardiovascular aterosclerótica se presentaron en los pacientes expuestos a hipertensión arterial grave (6,94 x 100 paciente - año), estrés (6,34 x 100 paciente - año) y la diabetes mellitus (5,9 x 100 paciente - año). En cuanto a la fuerza de asociación causal, la mayor probabilidad de enfermar en los pacientes expuestos, se localizó en los fumadores (17,6 veces), sedentarios con estrés (11,5 veces cada uno) y la hipertensión grave (11,3 veces). No alcanzaron un nivel de significación estadística en su asociación al daño aterogénico, los antecedentes patológicos personales y familiares, los hábitos dietéticos y el hábito alcohólico.
Tabla 2- Incidencia de factores de riesgo en pacientes con hipertensión arterial y fuerza de asociación a la enfermedad ateroesclerótica
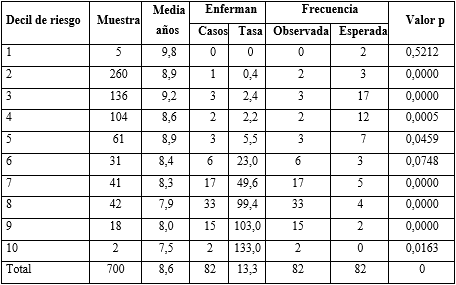
En la tabla 3 se muestra que la tasa de incidencia de enfermedad cardiovascular ateroesclerótica en la muestra, es de 13,3 x 100 paciente - años, para un acumulado de 82 casos. Se observa la ausencia de homogeneidad de la incidencia en los gradientes de riesgo, los cuales reflejan diferencias significativas entre los casos observados y esperados, con la particularidad de que en el grupo de bajo riesgo, de 5 esperados, solo alcanza el 2,5 %, situación que se invierte en el grupo de “alto riesgo”, en el cual de 50 eventos esperados, se incrementa 1,62 veces (81 enfermos).
El cálculo de los valores esperados, refleja la ausencia de homogeneidad entre los estratos y el incremento ascendente del riesgo de enfermar, que se manifiesta de manera significativa en los 4 primeros deciles (excepto el primero). La casuística se eleva pero es inferior a las cifras esperadas para su grupo. A partir del decil 6, se invierte y predominan los valores observados, con mayor diferencia en los deciles 8 y 9, que superan 8 y 7 veces los casos esperados.
Se acumularon 4 fallecidos, para una tasa de 0,06 x 100 pacientes - años, que se produjeron en los gradientes 8 (0,6 x 100), 6 (0,38 x 100) y 7 (0,29 x 100). Las causas de muerte fueron: la enfermedad cerebrovascular (2), infarto del miocardio (1) e insuficiencia renal crónica (1).
Tabla 3- Porcentaje de la casuística observada y esperada según gradientes de riesgo de los pacientes con hipertensión arterial
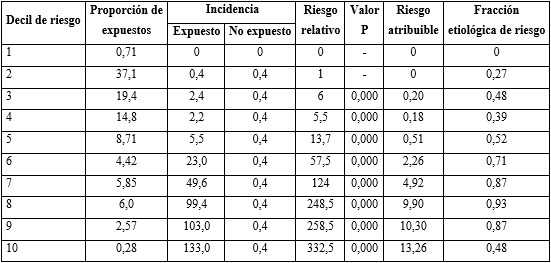
En la tabla 4 se refleja que la proporción de expuestos muestra la variabilidad de individuos sometidos a riesgo que predominan en el decil 2, con el 37 % de la población. El RR destacó la extraordinaria fuerza de asociación causal en los deciles de “alto riesgo” (3 - 10) que expresan un incremento en la probabilidad de enfermar de 6 - 332,5 veces mayor que en el grupo de “bajo riesgo”. En este, la distribución también resultó directamente proporcional al gradiente calculado. El RA permitió establecer el exceso en las tasas de incidencias, que pueden ser eliminadas, de intervenir sobre los factores de riesgo. El exceso de la tasa varió de 2 a 13,26 afectados x 1000 efectivos, con igual distribución proporcional a los gradientes de riesgo.
Los impactos del daño en los niveles de exposición fueron resumidos en la fracción etiológica de riesgo que es un indicador de gravedad y prioridad del problema. Se destacan los estratos de alto riesgo como los de mayor nivel de afectación, en particular en los deciles 8 (93 %), 7 y 9 (87 % cada uno).
La probabilidad acumulada (Kaplan - Meier) de enfermedad cardiovascular, en la cohorte, a los 5 años fue de 5,5 % (IC 95 %: 4,2 - 7,0 N5 = 534) y a los 10 años de 9,4 % (IC 95 %: 6,9 - 12,8 N10 = 110).
Tabla 4- Estimación del riesgo absoluto y relativo de enfermar según gradientes de riesgo de los pacientes con hipertensión arterial
En la tabla 5 se muestra que el análisis de discriminación diagnóstica mediante el índice de riesgo, se basó en los conceptos de sensibilidad y especificidad. Permitieron verificar la capacidad del gradiente de exposición, para expresar la probabilidad de enfermar en función del efecto acumulativo de sus factores causales. Para ello se comparó el resultado esperado, con la realidad reflejada por las tasas de incidencia durante el periodo de observación.
Se observó una elevada proporción de casos verdaderamente positivos en el grupo de “alto riesgo”, principalmente los deciles del 6 al 9, que superan el 80 %. Este resultado depende de los grupos de mayor riesgo, ya que la sensibilidad está condicionada por el largo periodo de latencia de las enfermedades no trasmisibles.
En el caso de la especificidad, se midió la proporción de casos verdaderamente negativos del grupo de pacientes ubicados en los gradientes de bajo riesgo, que fueron confirmados como tales. La especificidad se incrementó en relación directa y proporcional con el gradiente de riesgo ante la tendencia de disminución de este índice, por el incremento de la incidencia de la enfermedad en el transcurso del tiempo.
El área bajo la curva ROC fue de 0,78 (IC 95 %: 0,66 - 0,79), muy similar a la capacidad de discriminación del modelo en la población en la cual se desarrolló inicialmente (0,77) y superior a la que se consideró como aceptable de 0,75.

DISCUSIÓN
La validez es el grado en que un instrumento de predicción mide lo que realmente pretende o quiere medir. Para ello se suele comparar con un estándar de referencia (gold standard). En este trabajo se contrastan los resultados de la aplicación del modelo IRECVA a una población general con las ecuaciones de riesgo validadas en poblaciones distinta a la que le dio origen, las cuales idealmente muestran la verdadera proporción de acontecimientos cardiovasculares durante un período en un conjunto (cohorte) de personas.
Al igual que lo observado en la calibración del modelo de Framingham y el modelo de PROCAM para hombres y mujeres ajustados en la población colombiana, la función de riesgo IRECVA sobrestima el riesgo de presentar enfermedad cardiovascular aterosclerótica en todas las categorías de riesgo en la población estudiada. Esta sobrestimación es mínima en las categorías de bajo riesgo: la relación entre la proporción de eventos esperados y observados fue de 2,5 % (5 eventos esperados / 2 eventos observados), por lo cual se considera que el modelo está calibrado para estos subgrupos de riesgo. En el caso de los pacientes de alto riesgo, se encontró una diferencia muy amplia entre el porcentaje de eventos esperados y el observados (31 %), a partir de lo cual se concluyó que el modelo no está calibrado para este grupo de exposición al daño.4
Los resultados demuestran que la sobreevaluación del riesgo de presentar enfermedad cardiovascular aterosclerótica por el IRECVA, es similar a la reportada en estudios de validación externa -en población distinta a la que se desarrolló- por la función de Framingham y el modelo de PROCAM. La calibración inadecuada del modelo IRECVA en el subgrupo de alto riesgo en la población estudiada, pudiera encontrar explicación en el bajo tamaño de la muestra analizada, la pequeña cuantía de pacientes de alto riesgo que entraron a la cohorte y la escasa cantidad de eventos fatales observados, como forma más confiable de medir el riesgo cardiovascular durante su seguimiento.6
La aceptable capacidad de discriminar entre los pacientes con y sin enfermedad cardiovascular, medida como área bajo la curva de eficacia diagnóstica ROC por el modelo IRECVA, fue análoga a la encontrada en la población en la que se desarrolló el modelo, a pesar de la baja cantidad de eventos fatales en la población de estudio y a la declarada por ecuaciones de riesgo estandarizadas y validadas como Framingham, REGICOR y SCORE calibrada, Pooled Cohort Studies Equations, CUORE, Globorisk.7)
En lo que respecta a la sensibilidad y especificidad para la detección de individuos con riesgo cardiovascular, el IRECVA mostró valores similares en el grupo de bajo riesgo y valores superiores en el grupo de alto riesgo, con respecto a la obtenida por ecuaciones de predicción de riesgo cardiovascular como CUORE, Framingham, Globorisk y Pooled Cohort Studies Equations, particularmente la ecuación de Framingham, la cual mostró el valor más elevado para sensibilidad (81 %) y CUORE para especificidad (69 %).7)
En conclusión, el modelo evaluado calibra inadecuadamente porque sobrestima el riesgo cardiovascular al aplicarlas en otra población, aunque discrimina apropiadamente a las personas clasificadas como alto riesgo para adquirir una enfermedad cardiovascular aterosclerótica.
Se recomienda la realización de nuevos estudios con refinados controles de sesgos y basados en el seguimiento de cohortes poblacionales suficientemente grandes, para proporcionar estimadores de riesgo con la precisión adecuada, que reduzcan la incertidumbre predictiva en población de alto riesgo.

