










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Cubana de Salud Pública
versión On-line ISSN 1561-3127
Rev Cubana Salud Pública v.34 n.2 Ciudad de La Habana abr.-jun. 2008
REVISIÓN
Estado de salud y su relación con los determinantes: procedimientos de análisis
Health status and its relation with health determinants: analysis procedures
Cándido M. López Pardo
Dr.C. de la Salud. Universidad de La Habana. La Habana, Cuba.
RESUMEN
Objetivos Exponer procedimientos de análisis clasificados en las categorías de "procedimientos generales de la estadística y de la epidemiología", y "otros procedimientos" que posibilitan evaluar el estado global de salud e identificar las relaciones entre el estado de salud de la población y sus determinantes.
Fuentes de los datos Se revisaron 18 libros, ocho artículos de revista e igual número de documentos de organismos internacionales, un documento de organismo gubernamental, dos monografías, tres manuales de paquetes de programas, y un resultado de investigación. De ellos, un artículo fue tomado de Internet. De las fuentes utilizadas, 18 fueron publicadas entre el 2000 y el 2007, y nueve en la década anterior. Los trabajos anteriores a 1990, son obras clásicas de la estadística, la epidemiología y la salud pública de imprescindible referencia.
Síntesis de los datos Entre los procedimientos que se examina en el presente trabajo agrupado en "procedimientos generales de la estadística y de la epidemiología" se encuentra las pruebas de hipótesis clásicas y no paramétricas, el análisis de regresión mínimo cuadrática y tipo Poisson, el análisis de correlación y las tablas de contingencia. Entre los que se agrupan en "otros procedimientos" se considera los indicadores basados en la noción de entropía.
Conclusiones El artículo da continuidad a otro donde se presenta los procedimientos de análisis que se agrupan en otras cinco categorías de procedimientos. Se concluye que existe un variado número de procedimientos de uso habitual con diferentes fines que hace posible valorar el estado de salud de la población e identificar las relaciones que hay entre tal estado y sus determinantes, muchos de ellos de escaso uso en los trabajos que abordan este asunto. Por la vigencia y trascendencia del tema es recomendable profundizar en su estudio.
Palabras clave: Estado de salud, determinantes, medición.
ABSTRACT
Objectives To present the analysis procedures classified into the categories of "general procedures of statistics and of epidemiology" and, "other procedures" that make it possible to evaluate the global health status and set the relationship between the population´s health status and its determinants.
Data sources Eighteen books, eight journal articles and eight international body documents, one governmental agency document, two monographies, three software manuals and a research result were reviewed. Of these papers, one article was taken from Internet. Eighteen of the used sources were published from 2000 to 2007 whereas nine had been published in the last decade of the last century. Those papers made before 1990 are classical works of statistics, epidemiology and public health of compulsory reference.
Data synthesis Among the procedures under examination in the present paper and grouped into "general procedures of statistics and of epidemiology", there appear the classical and non-parametric hypothesis tests, the Poisson-type minimum square regression analysis, the correlation analysis and the contingency tables. Among those grouped into "other procedures", entropy notion-based indicators were included.
Conclusions This article follows a previous paper in which the analysis procedures were grouped into other five categories. It was concluded that there is a varied number of regular uses with different purposes, which makes it possible to assess the population's health status and to identify the relation of the health status and its determinants, many of which are barely used in other papers devoted to the same topic. Because of its validity and significance, it is recommended to further delve into the study of this subject.
Key words: Health status, determinants, measurements.
INTRODUCCIÓN
En un trabajo previo 1 se expuso los propósitos generales y específicos de la cuantificación del estado global de salud y de la identificación de las relaciones entre el estado de salud de la población y los determinantes, entendiendo por estado de salud de la población los niveles o patrones de mortalidad o morbilidad, y por estado global de salud, tanto el estado de salud de la población como sus determinantes.
En el propio trabajo se expresa que los propósitos específicos se cumplimentan mediante procedimientos de análisis que pueden clasificarse en siete categorías según su uso habitual con otros fines, y se examina los procedimientos de análisis agrupados en las cinco primeras. En el presente trabajo se ofrece una visión general de los procedimientos que se agrupan en las dos últimas categorías.
VISION DE ALGUNOS PROCEDIMIENTOS DE ANÁLISIS
En el recuadro 1 se muestra los procedimientos agrupados bajo los rubros de procedimientos generales de la estadística y de la epidemiología, y de otros procedimientos, señalándose el propósito específico que posibilita cumplimentar 1 y a continuación, para cada procedimiento se ofrece una descripción de su empleo, se brinda referencias para extender el conocimiento sobre ellos, se da ejemplos de su utilización y se señala el programa computacional con el se que puede ejecutar o se facilita su realización.
Recuadro 1. Procedimientos de análisis y propósitos específicos que posibilitan cumplimentar
| Procedimientos de análisis | Propósito específico que permite cumplimentar |
| Procedimientos generales de la estadística y de la epidemiología | |
| " Indicadores apropiados | 1.1, 2.1 |
| " Pruebas de hipótesis - clásicas - de distribución libre | 1.5, 2.6 |
| " Análisis de regresión | |
| - Análisis de regresión mínimo-cuadrática | 3.1 |
| - Cociente entre las pendientes de las rectas de ajuste de los valores del indicador de mortalidad o morbilidad (variable dependiente) y valores del determinante (variable independiente) - Regresión tipo Poisson - Otras medidas basadas en el análisis de regresión |
3.6 |
| " Análisis de correlación | 3.1 |
| " Tablas de contingencia | 3.1 |
| " Diferencias absolutas y relativas de tasas | 3.2 |
| " Riesgo Atribuible Poblacional del valor global del indicador de mortalidad o morbilidad respecto al estrato de mejor condición del determinante (RAPGLOBAL) u otro estrato de referencia. | 3.3 |
| " Cambio absoluto basado en el RAPGLOBAL obtenido | 3. |
| " Riesgo Atribuible Poblacional del indicador de mortalidad o morbilidad de cada estrato respecto al estrato de mejor condición del determinante (RAP estrato j) u otro estrato de referencia. | 3.4 |
| " Cambio absoluto basado en el RAPestrato j obtenido | 3.4 |
| Otros procedimientos | |
| " Indicadores basados en la noción de entropía | 3.1 |
| " Comparación del indicador Brecha con valores críticos (Decil 1, Cuartil 1, Cuartil 3, Decil 9) | 1.2, 2.2 |
| " Paridad Absoluta y Paridad Ponderada | 7.1 |
| Propósitos específicos | |
|
1.1 | Determinar los niveles de mortalidad o morbilidad generales y por causas definidas. |
| 1.2 | Identificar los territorios con un exceso significativo de mortalidad o morbilidad de las enfermedades o daños a la salud. |
| 1.5 | Identificar diferencias significativas entre agrupaciones de territorios en indicadores de mortalidad o morbilidad. |
| 2.1 | Caracterizar los niveles y formas de distribución de los indicadores de recursos y servicios en salud y de otros determinantes. |
| 2.2 | Identificar los territorios con una privación significativa de recursos y servicios en salud, |
| 2.6 | Identificar diferencias significativas entre agrupaciones de territorios en indicadores de los determinantes de la salud. |
| 3.1 | Determinar el efecto que tienen los niveles de los determinantes sobre los niveles de mortalidad o morbilidad. |
| 3.2 | Determinar las diferencias absolutas y relativas de mortalidad o morbilidad entre cada estrato y el estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.3 | Evaluar el cambio proporcional y absoluto en los niveles globales de mortalidad o morbilidad si todos los estratos experimentaran el riesgo del estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.4 | Evaluar el cambio proporcional y absoluto en los niveles de mortalidad o morbilidad de cada estrato si todos los estratos experimentaran el riesgo del estrato de mejor condición del determinante u otro estrato de referencia. |
| 3.6 | Determinar las variaciones relativas entre los cambios promedios del indicador de mortalidad o morbilidad entre intervalos sucesivos de valores del indicador del determinante. |
| 3.7 | Evaluar los riesgos relativos de mortalidad o morbilidad en cada estrato respecto al estrato de mejor condición del determinante ajustado a factores que pudieran confundir el efecto de las variables tenidas en cuenta. |
| 7.1 | Determinar el nivel de disparidad entre grupos humanos respecto a indicadores que los caractericen, |
Procedimientos generales de la estadística y de la epidemiología
El abordaje del tema de los indicadores, tanto para medir el estado de salud de la población, como la situación de los determinantes, entraña una extensión que escapa a los objetivos de la presente discusión y es extensa la literatura que existe sobre el tema.2-9
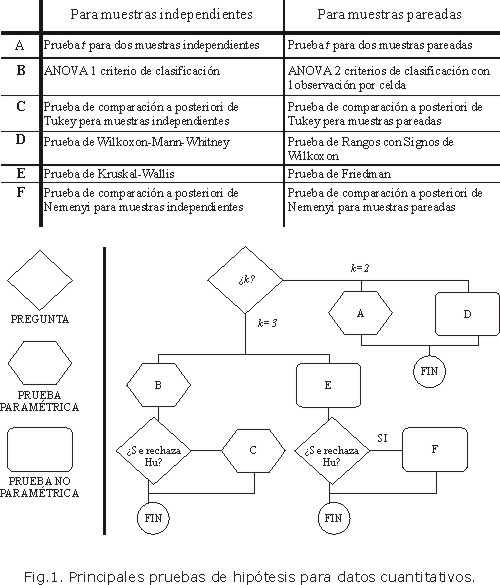
Un procedimiento con gran potencial para la cuantificación del estado de salud de la población y en la identificación de sus relaciones con los determinantes, son las pruebas de hipótesis. Se asume en lo adelante que el lector domina el concepto básico de lo que es una prueba de hipótesis. En la figura 1 se presenta un resumen que facilita determinar el empleo de las principales pruebas de hipótesis para datos cuantitativos para muestras independientes o muestras pareadas, señalándose cuáles pertenecen al dominio de las dócimas clásicas o paramétricas y cuáles al de las pruebas no paramétricas. La selección de cuál tipo de prueba realizar depende en gran parte de la experiencia del analista. Siempre que exista la posibilidad de seleccionar entre el empleo de una prueba clásica y una no paramétrica para docimar hipótesis similares se ha recomendado: 10 si las muestras son pequeñas, debe efectuarse una prueba no paramétrica a menos que se tenga seguridad del cumplimiento de todos los supuestos para realizar su equivalente paramétrica; si se conoce con certeza que se cumplen los supuestos para la prueba paramétrica, debe hacerse tal prueba cualesquiera sean los tamaños de muestra; si se conoce que no se cumplen los supuestos para la dócima paramétrica, debe realizarse la prueba no paramétrica para cualquier tamaño de muestra; y si las muestras son grandes y se duda del cumplimiento de los supuestos de la prueba paramétrica, debe analizarse en detalle cuál conducta seguir, dependiendo de cuán grande son las muestras y cuánto se conoce del cumplimiento de los supuestos.
Seguidamente se presenta un ejemplo del uso de la ruta que muestra la figura 1. Asuma que se tiene la siguiente información que se presenta en la tabla 1. ¿Es igual, como promedio, el porcentaje de viviendas con acceso a agua potable en los cuatro niveles socioeconómicos?
Si se tiene en cuenta que las muestras son independientes y que el número de muestras (k) es igual a 4, debe analizarse inicialmente estos resultados a través del Análisis de Varianza (ANOVA) de 1 criterio de clasificación o de la prueba de Kruskal-Wallis. Si adicionalmente se considera que las muestras son pequeñas y que se tiene escasa información sobre el cumplimiento de los supuestos para realizar la prueba clásica de ANOVA 1 criterio de clasificación (que las 4 poblaciones subyacentes se distribuyen normalmente con igual varianza), debe entonces realizarse la prueba no paramétrica de Kruskal-Wallis. Esta prueba docimaría las siguientes hipótesis:11
• Hipótesis nula: como promedio es igual el porcentaje de viviendas con acceso a agua potable en los cuatro niveles socioeconómicos.
• Hipótesis alternativa: al menos uno de los niveles socioeconómicos difiere como promedio de los restantes en el porcentaje de viviendas con acceso a agua potable.
Como resultado de la prueba de Kruskal-Wallis se rechaza la hipótesis nula a favor de la hipótesis alternativa (Asymp Sig. = 0,007, menor que el nivel de significación habitual de 0,05). De no haberse rechazado la hipótesis nula se concluiría el análisis, pero la hipótesis alternativa no es concluyente, ¿cuáles niveles socioeconómicos difieren significativamente como promedio de los otros? Para responder a esta pregunta se realiza la prueba de comparación a posteriori de Nemenyi para muestras independientes que da como resultado que difiere significativamente el nivel "muy alto" con el "medio", y el " muy alto" con el nivel "bajo."
En el recuadro 2 se muestra para cada uno de las pruebas de hipótesis presentadas una selección de la bibliografía que se puede consultar para conocer sus características y el programa en que pueden ejecutarse o facilitarse su realización.
Recuadro 2. Pruebas de hipótesis: bibliografía y programas en que se pueden ejecutar
| Prueba | Referencia | Programa (a) |
| Muestras independientes | ||
| Pruebas clásicas | ||
| Prueba t para dos muestras independientes | 11 - 14 | Excel, SPSS |
| ANOVA 1 vía | 11 - 15 | Excel, SPSS |
| Prueba de comparación a posteriori de Tukey | 11,13,15 | SPSS |
| Pruebas no paramétricas | ||
| Prueba de Wilcoxon-Mann-Whitney | 11,16,17 | SPSS |
| Prueba de Kruskal-Wallis | 11,16,17 | SPSS |
| Prueba de comparación a posteriori de Nemenyi | 15 | [SPSS] |
| Muestras pareadas | ||
| Pruebas clásicas | ||
| Prueba t para 2 muestras pareadas | 11-14 | Excel, SPSS |
| ANOVA 2 criterios con 1 observación por celda | 12,13,15 | Excel, SPSS |
| Prueba de comparación a posteriori de Tukey | 15 | [Excel] |
| Pruebas no paramétricas | ||
| Prueba de rangos con signo de Wilcoxon | 11,16,17 | SPSS |
| Prueba de Friedman | 11,16,17 | SPSS |
| Prueba de comparación a posteriori de Nemenyi | 15 | [SPSS] |
| (a) Aquellos programas que facilitan realizar la prueba, pero no directamente la realizan, se enmarcan entre corchetes. | ||
La regresión mínimo-cuadrática como uno de los procedimientos empleados para el análisis de series históricas fue considerada en un trabajo previo.1 Aquí se examinará esta técnica en su empleo más general. El objetivo del análisis de regresión es establecer una función -usualmente llamada ecuación de predicción o ecuación de regresión- que permita estimar el valor de una variable cuantitativa (dependiente) en función de otras variables cuantitativas (independientes). La ecuación se construye basado en un conjunto de observaciones en las que se registró el valor de la variable dependiente y de las independientes. El análisis se conoce como de regresión simple cuando hay una sola variable independiente, y como de regresión múltiple cuando son dos o más las variables independientes. En líneas generales los pasos para realizar un análisis de regresión simple -tipo de análisis al que se limita esta discusión- son los siguientes:
1. Identificar la función que se quiere ajustar.
Pudiera ser que tal función es del tipo ![]() , donde
, donde ![]() es el valor estimado de la variable dependiente para un cierto valor xi de la variable independiente, siendo zi una transformación de los valores de esta variable tal como xi, xi2,Öx, ln xi o 1/xi; en el caso de que zi = xi la ecuación resultante es la recta. A su vez, b0 y b1 son valores que hay que calcular. Habitualmente entre las diversas transformaciones consideradas se selecciona aquella que genera el mayor Coeficiente de Determinación, como previamente fue señalado,1 calculado a partir de los valores observados de la variable dependiente y de la transformación en cuestión.
es el valor estimado de la variable dependiente para un cierto valor xi de la variable independiente, siendo zi una transformación de los valores de esta variable tal como xi, xi2,Öx, ln xi o 1/xi; en el caso de que zi = xi la ecuación resultante es la recta. A su vez, b0 y b1 son valores que hay que calcular. Habitualmente entre las diversas transformaciones consideradas se selecciona aquella que genera el mayor Coeficiente de Determinación, como previamente fue señalado,1 calculado a partir de los valores observados de la variable dependiente y de la transformación en cuestión.
2. Calcular los valores de b0 y b1.
3. Determinar si es o no válida la ecuación obtenida para realizar las estimaciones, ya que la mejor ecuación (la obtenida con la mejor transformación de la variable independiente) no necesariamente tiene que ser una buena función para hacer las estimaciones. En términos no absolutamente formales, pero más comprensible a los efectos de la presente discusión, la prueba F asociada al análisis de regresión docima las siguientes hipótesis:
• Hipótesis nula: la ecuación obtenida no es válida para estimar la variable dependiente en función de la variable independiente.
• Hipótesis alternativa: la ecuación obtenida es válida para estimar la variable dependiente en función de la variable independiente.
Para profundizar sobre los aspectos expuestos, y otros, del análisis de regresión, puede consultarse diversas obras que abordan el asunto.12,13,18 Un programa particularmente útil tanto para la obtención de la ecuación de regresión, previo análisis de la transformación a utilizar, así como para la realización de la prueba F, es Econometric Views (EViews).
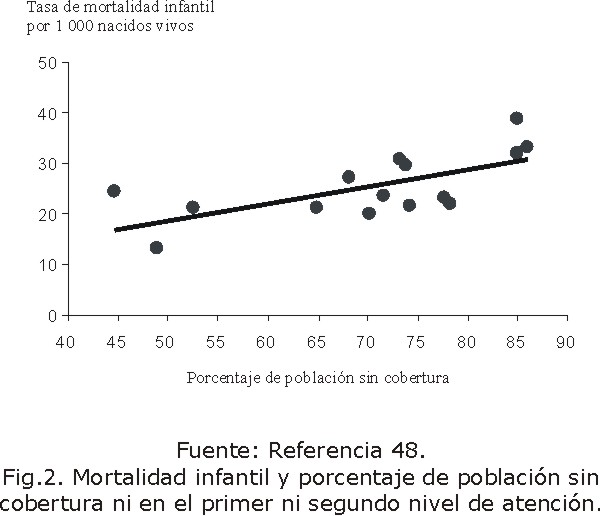
La figura 2 muestra la relación entre los valores de mortalidad infantil y el porcentaje de población sin cobertura ni en el primer ni segundo nivel de atención médica en municipios de un área de salud de Guatemala.19 La ecuación resultante es TASAMIEST = 2,036 + 0,334 SINCOB12, donde
TASAMIEST denota el valor estimado de la tasa de mortalidad infantil a través de la ecuación y SINCOB12 el porcentaje de población sin cobertura ni en el primer ni segundo nivel de atención médica.
Del valor de la pendiente de la recta, también denominada Índice de Efecto Absoluto,20 se puede establecer que, como promedio, la tasa de mortalidad infantil aumenta en 0,334 por 1 000 nacidos vivos por cada incremento de un punto porcentual del porcentaje de población sin cobertura. O sea, por ejemplo, por cada disminución del 10 % de población sin cobertura, disminuiría como promedio la tasa de mortalidad infantil en 0,334 por 1 000 nacidos vivos. El valor obtenido del estadístico F (F0=9,94 p =0,0008) permite decir que la ecuación dada es válida para estimar el valor esperado de mortalidad infantil según los valores de porcentaje de población sin cobertura de atención médica.
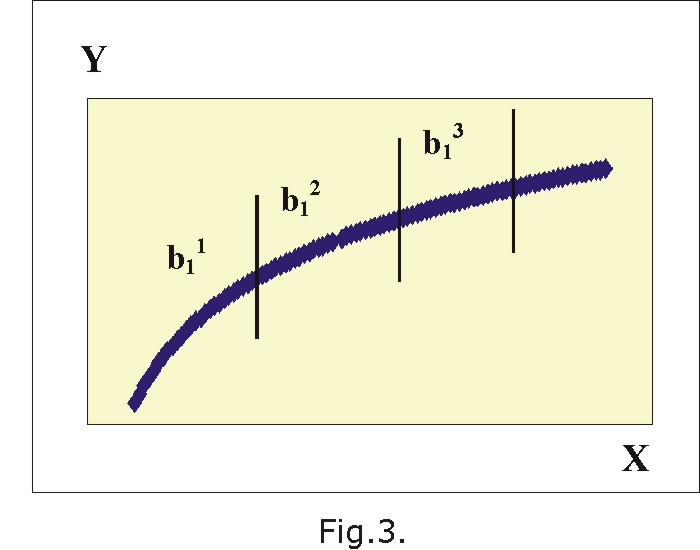
Con frecuencia21-23 la relación que media entre un indicador positivo de salud o un indicador de bienestar (Y) -por ejemplo, la tasa de alfabetización en adultos- y una variable independiente de recurso (X) -por ejemplo, el gasto en educación per capita- es del tipo ![]() como se muestra en la figura 3, o puede transformarse en esta función, que traduce un efecto decreciente de X en Y.
como se muestra en la figura 3, o puede transformarse en esta función, que traduce un efecto decreciente de X en Y.
En estos casos, una manera sencilla de analizar los cambios en Y a distintos niveles de X es particionar la curva en sectores que pueden corresponder, por ejemplo, con intervalos en que se ha estratificado X, como se ilustra en la propia figura 3. Así, si para cada intervalo (estrato) se pudiera ajustar una recta, para k estratos las pendientes b11, b12, ..., b1k, en general b1i, darían los incrementos promedios de Y por cada unidad de cambio de X. A su vez, el cociente entre las pendientes b1i y b1i+1 (por ejemplo, b12 / b13) informaría cuántas veces más es el cambio promedio de Y por cada unidad de cambio de X en el estrato i comparado con el estrato i + 1.24
La regresión tipo Poisson es similar a otros métodos de regresión, con la particularidad de que el modelo se basa en las propiedades de la distribución de Poisson. El método es particularmente preciso cuando el número de casos del problema de salud considerado es pequeño comparado con el tamaño de la población expuesta.25 Por ejemplo, pudiera obtenerse los riesgos relativos a una muerte materna de varios estratos socioeconómicos respecto al de mejor condición socioeconómica ajustado al número de médicos por habitante.
El Índice Relativo de Desigualdad y el Índice de Desigualdad de la Pendiente se obtienen mediante un análisis de regresión del indicador del estado de salud de la población sobre un indicador de la posición relativa acumulada de cada grupo con respecto a una variable socioeconómica, y ambos toman en cuenta tanto la situación socioeconómica de los grupos como el tamaño de la población. El resultado del Índice Relativo de Desigualdad se interpreta como la razón de las tasas del problema de salud considerado de aquellos en el nivel socioeconómico más deprimido comparado con aquellos en el más alto nivel socioeconómico. El Índice de Desigualdad de la Pendiente se interpreta de forma similar, pero considerando la diferencia de tasas en lugar de la razón; también se interpreta como el cambio promedio en el porcentaje de regular o pobre salud en toda población ordenada por nivel socioeconómico.8,20,26
El análisis de correlación posibilita estudiar el tipo y la intensidad de la relación que hay entre dos variables cuantitativas. En este tipo de análisis, a diferencia del análisis de regresión, ninguna de ambas variables es definida como dependiente o independiente. Si es posible asumir que se está en presencia de pares aleatorios de observaciones provenientes de una distribución normal bivariada, el tipo y la intensidad de la relación lineal que existe entre las variables puede establecerse mediante el Coeficiente de Correlación Lineal (r), o Coeficiente de Correlación de Pearson, entre otras maneras de llamar a este coeficiente. r puede tomar valores entre -1 y 1. Un valor de r = 1 denota una perfecta correlación lineal positiva, en tanto un valor de -1 traduce una perfecta relación lineal negativa; un valor de r = 0 informa sobre una ausencia de relación lineal entre las variables. Si se considera que los valores observados provienen de una determinada población, puede ponerse a prueba la hipótesis nula de que r= 0, siendo r el Coeficiente de Correlación Lineal poblacional, versus la hipótesis alternativa de que r¹0.13,27 El cálculo de r y la prueba de significación puede realizarse mediante el programa SPSS.
El Coeficiente de Correlación de Rangos de Spearman asimismo identifica el tipo de relación existente entre las dos variables tenidas en cuenta y cuantifica la intensidad de la asociación entre ellas, pero en lugar de calcularse a partir de los valores observados, se sustenta en la diferencia de los rangos asignados a los valores. Para utilizar este coeficiente no se requiere asumir que los datos provienen de una distribución normal bivariada; asimismo, puede utilizarse cuando las observaciones tienen un orden verdadero. Ciertos autores14 consideran que este coeficiente se utiliza en lugar del Coeficiente de Correlación Lineal cuando cada valor en sí no es tan importante como su situación respecto a los restantes. La interpretación de este coeficiente es igual que la del Coeficiente de Correlación Lineal, y de la misma manera su valor y su significación puede calcularse utilizando el programa SPSS.
La llamada tabla de contingencia está compuesta por C columnas y F filas de valores numéricos (tabla C x F). A los fines de la presente discusión se considerará que las tablas de contingencia pueden ser empleadas con dos propósitos: evaluar la asociación entre dos variables, o determinar la relación entre la exposición a un cierto evento y la presencia de un problema de salud.
En el recuadro 3 se muestra ciertas medidas de asociación y de significación de la asociación que pueden obtenerse en tablas de contingencia; para cada una se señala una bibliografía básica y el paquete de programa estadístico que posibilita su cálculo cuando existe, entre un conjunto de programas considerados. Si bien alguna medida pudiera ser útil en más de un tipo de tabla, se consideró en lo que pareciera ser su uso más frecuente. Posteriormente se comenta cada una de las medidas.
Recuadro 3. Medidas de asociación y de significación de la asociación calculables en tablas de contingencia
| Tipo de tabla | Medida de asociación o de significación de la asociación | Referencia | Programa que posibilita su calculo |
| C x F Ambas variables nominales | Coeficiente Phi Coeficiente V de Cramer Coeficiente de Contingencia C de Pearson Coeficiente T de Chuprov Coeficiente Tau de Goodman-Kruskal Prueba Ji-cuadrado Prueba exacta de Fisher-Irwin | 28,29 14,30 29,30 29 30 16,17,28 17,28 | SPSS EPIDAT 3.1, SPSS EPIDAT 3.1, SPSS EPIDAT 3.1 EPIDAT 3.1, SPSS EPIDAT 3.1, SPSS |
| C x F Ambas variables ordinales | Coeficiente D de Sommers Coeficiente Gamma de Goodman-Kruskal Coeficiente Tau-b de Kendall Coeficiente Tau-c de Kendall Prueba Ji-cuadrado Prueba exacta de Fisher-Irwin | 14,30 14,30 14,30 14,30 14,30 14,30 | EPIDAT 3.1, SPSS EPIDAT 3.1,SPSS EPIDAT 3.1,SPSS EPIDAT 3.1, SPSS EPIDAT 3.1, SPSS EPIDAT 3.1, SPSS |
| C x 2 Variable en la columna ordinal | Prueba de Bartholomew | 28 |
El Coeficiente Phi mide el grado de asociación entre dos variables nominales. Es una medida derivada del valor del estadístico de prueba Ji-cuadrado, pero independiente del número de observaciones. Valores del coeficiente cercanos a 0 indican escasa asociación entre las variables, en tanto valores próximos al valor modular de 1 indican una alta asociación.28,29 El Coeficiente V de Cramer mide asimismo el grado de asociación entre dos variables nominales. En tablas 2 x 2 toma valores entre -1 y 1, y en cualquier otro caso entre 0 y 1. Un valor de -1 o de 0, según sea el caso, se interpreta como que no existe asociación y un valor de 1 como que existe una fuerte asociación entre las variables.14,30 El Coeficiente de Contingencia C de Pearson es otra medida de asociación aplicables a datos nominales, y toma valores entre 0 y un valor máximo (CMAX). Valores del coeficiente cercanos a 0 indican no asociación entre las variables y valores próximos a CMAX señalan una fuerte asociación. El valor de CMAX depende del tamaño de la tabla, por lo que no se puede comparar los resultados en tablas que tienen diferente número de filas y columnas.28,30 Para superar esta limitación, Chuprov definió un Coeficiente T que toma un valor igual a 1 cuando la asociación es máxima entre las variables si C=F; no obstante esta propiedad no se logra si C¹F.29 Cuando una de las variables puede considerarse como independiente y la otra como dependiente puede calcularse el Coeficiente Tau de Goodman-Kruskal para valorar en qué medida la primera predice a la segunda. El coeficiente toma valores entre 0 y 1, y serán más cercanos a 1 cuanto mayor es la capacidad de predecir sin error la variable dependiente, mientras que un valor cercano a 0 traduce que la variable independiente no tiene capacidad para predecir la variable dependiente.30
El Coeficiente D de Sommers posibilita realizar un análisis de la relación de dependencia entre dos variables ordinales. Este coeficiente asimismo toma valores entre -1 y 1, pero muestra el inconveniente de que se pueden alcanzar estos valores extremos en situaciones donde no existe una total asociación.14,30 El Coeficiente Gamma de Goodman-Kruskal adopta valores entre -1 y 1, indicando, respectivamente, una fuerte asociación negativa y positiva entre las variables, en tanto valores cercanos a 0 traducen la no existencia de asociación, pero, asimismo, puede tomar valores de -1 o 1 cuando la asociación no es perfecta.14,30 El Coeficiente Tau-b, a diferencia del Coeficiente Gamma, sólo alcanza valores de -1 o 1 cuando la asociación es perfecta en uno u otro sentido, pero muestra la limitante que tales valores solamente pueden obtenerse cuando la tabla es cuadrada (C=F).14,30 El Coeficiente Tau-c es una corrección de Tau-b para el caso de variables con diferente número de categorías (C¹F), salvo pequeñas discrepancias cuando el tamaño de la muestra no es un múltiplo del mínimo entre C y F, pero tiende a subestimar el verdadero grado de asociación entre las variables.14,30
Todos los coeficientes que se ha examinado son una medida de la asociación que existe entre las variables, pero no de la significación de la asociación. Tiene sentido interesarse por la significación del coeficiente obtenido si se trabaja con muestras obtenidas de una población definida, o si se considera que existe un superuniverso de unidades de observación. Según Silva,31 un superuniverso ha sido definido como un conjunto infinito de posibilidades formado por todos los universos finitos que pudieran haberse producido en el momento de la observación y del cual la población finita puede considerarse una muestra aleatoria. De otra forma dicho, se asume que las unidades de observación analizadas, municipios por ejemplo, constituyen una muestra aleatoria de todos los municipios a los cuales se pueden inferir los resultados. De interesar sólo la asociación entre las variables consideradas para los municipios observados y en un determinado momento, carece de sentido preocuparse por la significación del valor hallado del coeficiente. La significación de la asociación puede determinarse mediante la prueba Ji-cuadrado. En la prueba Ji-cuadrado la corrección de Yates se utiliza para incrementar la precisión en tablas 2 x 2, esencialmente cuando los valores de las celdas son pequeños. Si bien algunos consideran que la corrección tiende a emplearse ahora menos que antes porque no mejora la precisión tanto como se creía,32 otros son del pensar 28que en tablas 2 x 2 debe siempre utilizarse. La prueba de Fisher-Irwin es otra alternativa que se considera más exacta para poner a prueba la significación de la asociación en tablas 2 x 2.17,28
En el caso de una tabla C x 2, cuando la variable que se asigna a las columnas es ordinal, puede ejecutarse la dócima de Bartholomew que posibilita determinar si existe un gradiente significativo de incremento, o decremento, en la proporción de ocurrencia de un hecho, de acuerdo a los C niveles de la variable ordinal.25
Si en un estudio una variable puede considerarse como la exposición a un problema de salud con dos o más categorías o niveles, y otra variable la presencia de tal problema de salud, igualmente con dos o más categorías o niveles, son posibles tres diseños para identificar la relación entre la exposición al problema y el problema en sí: "estudios transversales" donde sólo se delimita el tamaño global del grupo de unidades de observación en estudio; "estudios de cohorte" donde se establecen tamaños de grupos para las diferentes categorías o niveles de exposición; y "estudios caso-control", en los que se fijan los tamaños de los grupos para las diferentes categorías o niveles del problema de salud. Frecuentemente, la exposición al problema de salud y la presencia de tal problema se dicotomizan: si/no exposición, si/no problema de salud. Cada modalidad de estudio admite determinados tipos de análisis. Las ventajas relativas de estos diseños se consideran en diversas obras.33-35 En el recuadro 4 se presenta medidas de riesgo y de su significación para determinar la relación entre la exposición a un cierto evento y la presencia de un problema de salud calculables en tablas 2 x 2 (2 categorías de presencia del problema de salud y 2 categorías de exposición) todas ellas obtenibles mediante el programa EPIDAT 3.1. Si bien alguna medida pudiera ser válida en más de un tipo de estudio, se consideró en el que pareciera ser su empleo más provechoso; ejemplo de ello, es el Odds Ratio que sólo se tuvo en cuenta en los estudios caso-control cuando también es calculable en estudios transversales y de cohorte no pareado, o pareado. El caso más general C y/o F diferente de 2, y otras medidas y análisis, puede verse en la obra de Fleiss.25 En el examen de los trabajos donde se abordan estas medidas, debe prestarse atención a las diferentes formas que un mismo concepto o método puede ser nombrado.
Recuadro 4. Medidas de riesgo y de su significación en tablas 2 x 2 para determinar la relación entre la exposición a un cierto evento y la presencia de un problema de salud
| Diseño | |||||
| Transversal | De cohorte | Caso control | |||
| No pareado | Pareado | ||||
| Prevalencia de la enfermedad (o riesgo) | en expuestos | X | X | ||
| en no expuestos | X | X | |||
| Razón de prevalencia de la enfermedad en expuestos respecto a no expuestos (o Riesgo Relativo) | X | X | |||
| Prevalencia de la exposición | en enfermos | X | |||
| en no enfermos | X | ||||
| Razón de prevalencia de la exposición en enfermos respecto a los no enfermos | X | ||||
| Prueba Ji-cuadrado de significación de la asociación | X | X | X | ||
| Prueba de Fisher-Irwin | X | X | X | ||
| Diferencia de riesgo en expuestos respecto a los no expuestos | X | ||||
| Fracción atribuible en expuestos | X | X | |||
| Fracción atribuible poblacional | X | X | |||
| Proporción de | casos expuestos | X | X | ||
| controles expuestos | X | X | |||
| Odds ratio | X | X | |||
| Prueba de McNemar | X | ||||
Seguidamente se amplía sobre algunas de estas medidas menos intuitivas. Considérese que se realiza un estudio de cohorte para determinar la relación entre la existencia o no de sala situacional de la salud materno-infantil y la alta o no mortalidad materna en un conjunto de municipios, seleccionándose 50 que no tienen sala situacional y otros 50 que la tienen, como se muestra en la tabla 2.
Los principales resultados obtenidos a través de EPIDAT 3.1 se muestran en el Cuadro 1
Tabla 2. Datos del estudio de cohorte
| Existencia de sala situacional | Mortalidad materna | Total | |
| Alta | No alta | ||
| No | 48 | 2 | 50 |
| Si | 4 | 46 | 50 |
| Total | 52 | 48 | 100 |
Cuadro 1.
| Estimación | IC (95,0 %) | ||
| Riesgo en expuestos | 0,960000 | - | - |
| Riesgo en no expuestos | 0,080000 | - | - |
| Riesgo relativo | 12,00000 | 4,679726 | 30,771030 (Kats) |
| Diferencia de riesgos | 0,88000 | 0,787238 | 0,972762 |
| Fracción atribuible en expuestos | 0,916667 | 0,786312 | 0,967502 |
| Fracción atribuible poblacional | 0,846154 | 0,613604 | 0,938745 |
| Prueba Ji-cuadrado de asociación | Estadístico | Valor p | |
| Sin corrección | 77,5641 | 0,0000 | |
| Corrección de Yates | 74,0785 | 0,0000 | |
| Prueba exacta de Fisher | |||
| Unilateral | 0,0000 | ||
| Bilateral | 0,0000 | ||
La fracción atribuible en expuestos representa la fracción de daño que pudiera ser evitada entre los expuestos si se eliminara totalmente la exposición; luego, entre los municipios sin sala situacional alrededor de un 92 % de la alta mortalidad materna se evitaría si se instalara la sala situacional. La fracción atribuible poblacional es una medida del impacto potencial que tendría la eliminación de la exposición en toda la población; por tanto, alrededor de un 85% de la alta mortalidad materna en la población de municipios se pudiera explicar por la no existencia de la sala situacional. Tanto la fracción atribuible en expuestos, como la fracción atribuible poblacional, son aplicables a exposiciones que sean totalmente reversibles asumiendo una relación de causalidad, y en cualquier situación tiene un valor teórico en la medida que cuantifica, supuestamente, el peso etiológico de un determinado factor en términos de la salud pública.35
En todos los casos, el intervalo de confianza proporciona un recorrido de valores en el cual se espera con cierta confianza (generalmente 95%) que se encuentra el verdadero valor de la medida que se considera. Por ejemplo, el verdadero Riesgo Relativo (o el Riesgo Relativo en la población de la cual se obtuvo la muestra estudiada, el "parámetro") muy probablemente se encuentre entre 4,7 y 30,8. El hecho de que el límite inferior del intervalo sea mayor que 1 (es decir, muy probablemente el verdadero valor del Riesgo Relativo no es igual a 1), está diciendo que el riesgo en los expuestos es "significativamente" superior que entre los no expuestos, en este caso, que el riesgo a una alta mortalidad materna es significativamente mayor en los municipios sin sala situacional comparado con el riesgo en los municipios que cuentan con sala situacional de la salud materno-infantil. El resultado "significativo" del Riesgo Relativo debe de coincidir con el resultado de las pruebas de hipótesis Ji-cuadrado o de Fisher de significación de la asociación. Sin embargo, el sólo hecho de que la asociación sea significativa (resultado de la prueba Ji-cuadrado o de Fisher) no indica que la presencia de la exposición esté directamente asociada con la presencia del problema de salud, dado que tal significación de la asociación resulta también cuando la no exposición se encuentra directamente relacionada con la presencia del problema de salud (o lo que es lo mismo, la exposición está directamente relacionada con la no presencia del problema de salud). Si este fuera el caso (sólo redefiniendo los valores de la tabla 2: 2 y 48 en la primera fila, y 46 y 4 en la segunda) se halla los mismos valores para las pruebas Ji-cuadrado y Fisher, pero un Riesgo Relativo igual a 0,043 y un intervalo de confianza (95 %) de 0,011 a 0,169, informando de una relación significativa en sentido contrario a la esperada: el riesgo a una alta mortalidad materna en los municipios con sala situacional es significativamente mayor que en los municipios sin sala situacional.
Por otro lado, tiene sentido construir, o tener en cuenta, un intervalo de confianza, o realizar las pruebas Ji-cuadrado o de Fisher, como ya se expuso, si se puede considerar que el grupo de unidades de observación estudiadas (en este caso, municipios) es una muestra del conjunto de todas las posibles unidades de observación a las cuales se pueden inferir los resultados. Una discusión sobre cómo examinar los resultados de las pruebas de hipótesis y de los intervalos de confianza se realiza por Clark.36
En estudios sobre la relación entre la exposición a un cierto evento y la presencia de un problema de salud, una variable confusora (en inglés, confounding variable) es una variable que se encuentra asociada tanto con la variable independiente (la exposición) como con la variable dependiente (el problema de salud).37 Luego, la asociación real entre la exposición y la presencia del problema de salud puede distorsionarse si no se controlan las variables confusoras. Una de las formas de eliminar, o al menos reducir, el efecto de estas variables es mediante el pareamiento. Por ejemplo, es de interés determinar la relación entre la realización o no de análisis de situación de salud (ASIS) y la existencia o no de alta mortalidad infantil en distritos rurales con escasos recursos de atención médica, pero se considera que la presencia de al menos un médico en el distrito es una variable de confusión en tanto se halla asociada tanto con que se realice o no el análisis de situación de salud como con los niveles de mortalidad infantil, por lo que es oportuno realizar un estudio caso-control con pareamiento El grupo de "casos" está constituido por 15 distritos con alta mortalidad infantil en los últimos tres años, y para cada distrito-caso se seleccionaría como control otro distrito con no alta mortalidad infantil según si el distrito-caso contara o no con al menos un médico, hallándose los valores que se muestra en la tabla 3. Observe que el gran total (15) representa el número de pares, a la vez que el número de distritos-caso y distritos-control estudiados, en tanto las cifras marginales de filas y columnas informan sobre el número de distritos-caso y distritos-control, respectivamente, en los que se ha realizado o no ASIS, mientras los valores en las celdas son el número de pares que presentan la característica reflejada (por ejemplo, en 10 pares de distritos no se ha realizado ASIS en los distritos-caso y se ha realizado ASIS en los distrito-control). Los resultados obtenidos con el empleo de EPIDAT 3.1 se muestran en el Cuadro 2
Tabla 3. Datos del ejemplo sobre el análisis de la situación de salud (ASIS) y la existencia o no de alta mortalidad
| Distritos-casos | Distritos-control | Total | |
| No ASIS | Si ASIS | ||
| No ASIS | 2 | 10 | 12 |
| Si ASIS | 2 | 1 | 3 |
| Total | 4 | 11 | 15 |
Cuadro 2.
| Estimación | IC (95%) | ||
| Proporción de casos expuestos | 0,800000 | - | - |
| Proporción de controles expuestos | 0,266667 | - | - |
| Odds ratio | 5,00000 | 1,065528 | 46,932835 |
| Prueba de asociación | Valor p | ||
| Exacto | 0,03886 | ||
El cálculo e interpretación de los "odds ratios" -llamados en español, entre otras formas como "razón de posibilidades" , en estudios caso-control no pareados o con pareamiento, se ilustra seguidamente.38 Asuma que se realiza un estudio caso-control sin pareamiento para determinar la relación entre existencia o no de sala situacional y la alta o no mortalidad materna en un conjunto de municipios obteniéndose los mismos resultados que en el estudio de cohorte presentado previamente; o sea, se estudian 52 municipios con alta mortalidad materna y 48 sin alta mortalidad materna. Para estos valores se halla un odds ratio igual a 276 que se interpreta como que el número de municipios con alta mortalidad materna respecto al número sin alta mortalidad materna es 276 veces más alto en aquellos municipios expuestos (los que no tienen sala situacional) que en los no expuestos [(48/2) / (4/46)]. En los estudios caso-control con pareamiento, como el considerado previamente (tabla 3), el odds ratio se obtiene como el cociente entre el número de pares donde los casos estuvieron expuestos (no se realiza análisis de situación de salud) y simultáneamente el número de controles no lo estuvieron, situación a favor de que la exposición aumenta la presencia de la alta mortalidad infantil, (10 pares), y el número de pares donde los casos no estuvieron expuestos (se realiza análisis de situación de salud) y a la vez el número de controles que lo estuvieron, situación que indica lo contrario (2 pares).
La significación de la asociación en estudios con pareamiento con variable dicotómica se pone a prueba a través de la dócima de McNemar.17,28
Para un conjunto de territorios agrupados en estratos de acuerdo a niveles de un cierto indicador de un determinante, para un estrato en particular la diferencia absoluta del valor del indicador de mortalidad o morbilidad (tj) respecto a un valor de referencia (t0) -habitualmente el valor del indicador en el estrato de mejor condición del determinante-viene dada por Dj = tj - t0 y la diferencia relativa por Rj = tj / t0. El valor resultante de la diferencia absoluta se interpreta como cuánto más (si la diferencia es positiva) es el valor del indicador de mortalidad o morbilidad del estrato en particular respecto al valor de referencia, y está dado en las mismas unidades de medida del indicador de mortalidad o morbilidad considerado. La diferencia relativa se interpreta como cuántas veces más es el valor del indicador de mortalidad o morbilidad del estrato considerado en relación con el valor de referencia del indicador, y el valor que resulta es adimensional, es decir, no está dado en las unidades de medida del indicador tenido en cuenta.20 Si, por ejemplo, el indicador es la tasa de mortalidad infantil y para un determinado estrato es igual a 13,0 por 1 000 nacidos vivos (tj), y la tasa en el estrato de mejor condición del determinante (t0) es igual a 5,2 por 1 000 nacidos vivos, la diferencia absoluta es igual a 7,8 por 1 000 nacidos vivos; es decir, en el estrato considerado la tasa de mortalidad infantil es 7,8 por 1 000 nacidos vivos más que en el estrato de mejor condición del determinante, mientras que la diferencia relativa es igual a 2,5, o sea, la tasa de mortalidad infantil en el estrato en cuestión es 2,5 veces más alta que en el estrato de mejor condición del determinante. Se recomienda que las diferencias deben ser medidas tanto en términos absolutos como relativos con el fin de entender mejor sus magnitudes, especialmente cuando se hacen comparaciones a través del tiempo o para diferentes áreas geográficas o poblaciones.8
El Riesgo atribuible poblacional global (RAPGLOBAL) viene dado por RAPGLOBAL = [(tg - t0) / tg] x 100, donde tg es la tasa global observada del indicador del estado de salud de la población y t0 la tasa del indicador para el estrato de mejor condición del determinante o para otro estrato de referencia. Se interpreta como qué porcentaje menor fuera el valor global del indicador si todos los estratos experimentaran el riesgo del estrato de referencia.20,26Por otra parte, el Riesgo atribuible poblacional para un estrato cualquiera - en general, el j-ésimo estrato (RAPestrato j) viene dado por:
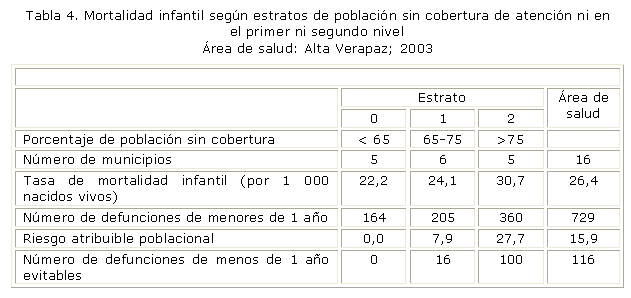
RAPestrato j = [(tj - t0) / tj] x 100, siendo tj la tasa para el estrato en cuestión, y se interpreta como qué porcentaje menor fuera el valor del indicador para el estrato en particular si experimentara el riesgo del estrato de referencia.20 El número de defunciones o casos evitables, global o para cada estrato, se obtiene mediante la relación [(RAP x número de defunciones o casos)/100]. Salvo ajuste de redondeo de cifras, la suma del número de defunciones o casos evitables en cada estrato debe ser igual al número de defunciones o casos evitables globalmente. En la tabla 4 se muestra los resultados hallados en un área de salud en Guatemala.19
Si todos los estratos tuvieran la tasa de mortalidad infantil del estrato de menor porcentaje de no cobertura (estrato "0"), la tasa de mortalidad infantil del área de salud se reduciría en 16 % y se evitarían 116 defunciones de menos de 1 año en el área de salud; si los estratos "1" y "2" tuvieran los porcentajes de no cobertura del estrato "0", reducirían su tasa de mortalidad infantil en alrededor del 8 % y el 28 %, y disminuirían en 16 y 100, respectivamente, el número de sus defunciones de menos de 1 año.
Otros procedimientos
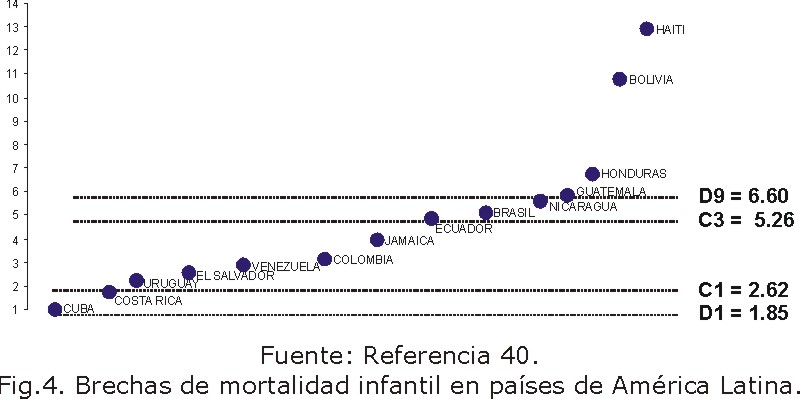
Bacallao y otros demuestran las ventajas de las mediciones de carácter social de las desigualdades de salud basadas en índices sustentados en la noción de entropía.39 Otra manera de evaluar el estado de salud de la población o de sus determinantes de un cierto territorio cuantificado a través de un determinado indicador, es mediante la diferencia relativa, o brecha, que separa al territorio en cuestión del territorio con el mejor valor del indicador considerado. Cuando se aspira a disminuir el valor del indicador, la brecha vendrá dada por el cociente: valor del indicador para el territorio/valor mínimo observado del indicador; en tanto, cuando es deseable incrementar el valor del indicador, se obtiene mediante la relación: valor máximo observado del indicador/valor del indicador para el territorio. De esta manera, las brechas tomarán siempre valores mayores o iguales a 1 (brecha mínima). Se han establecido cinco niveles de brechas, dados por intervalos expresados en términos de cuartiles de las brechas observadas (B): Muy Baja: B < Decil 1; Baja: Decil 1£ B < Cuartil 1; Mediana: Cuartil 1£ B < Cuartil 3: Alta: Cuartil 3 £ B < Decil 9: Muy Alta:
B ³ Decil 9.40 La figura 4 presenta las brechas de mortalidad infantil para un conjunto de países de América Latina y el Caribe.
Entre un conjunto de territorios, para uno de ellos cualquiera, la Paridad absoluta de un cierto grupo 1 respecto a un grupo 2 en relación con un aspecto en particular cuantificable a través de una tasa o cualquier otro indicador, donde, mientras más alto es el valor del indicador, mayor es el logro en el aspecto considerado, viene dada por Paridad absoluta=(Valor del indicador para el grupo 1 / Valor del indicador para el grupo 2) x 100. Por tanto, la Paridad absoluta mide para ese territorio en particular la desigualdad relativa del grupo 1 respecto al grupo 2 en el logro del aspecto considerado. No obstante, tal paridad puede ser buena, eventualmente igual o mayor a 100 % y, sin embargo, ser los valores del indicador en ambos grupos relativamente bajos respecto a un valor posible de obtener. Por ello, se ha propuesto un indicador que pondera la Paridad absoluta con el éxito relativo. Así, para un determinado territorio y para un indicador en particular, la Paridad ponderada viene dada por Paridad ponderada=Paridad Absoluta x Coeficiente de exito, donde el Coeficiente de éxito se halla a través de la relación Coeficiente de éxito=(Valor global del indicador del territorio / Valor global del indicador máximo registrado en el conjunto de territorios). Luego, a igual Paridad absoluta, la Paridad ponderada concede más peso al territorio que tiene mayor éxito relativo. Debe considerarse, no obstante, que una alta Paridad absoluta pudiera generar un alto valor de Paridad ponderada en presencia de un escaso éxito relativo.41
Considérese que en tres provincias de un país se registran los porcentajes que se dan de acceso a agua potable, global en el país, y en las áreas rural y urbana (tabla 5). Luego, la Paridad absoluta, el Coeficiente de éxito y la Paridad ponderada para cada provincia son las que se presentan.
Tabla 5. Datos sobre el acceso a agua potable en el país y en áreas rural y urbana
| Provincia | Porcentaje de población con acceso a agua potable | Paridad absoluta | Coeficiente de éxito | Paridad ponderada | ||
| Global | Rural | Urbano | ||||
| Alta Gracia |
93,1 | 87,0 | 95,2 | 91,4 | 0,988 | 90,3 |
| Buenaventura | 83,2 | 80,5 | 84,6 | 95,2 | 0,883 | 84,1 |
| Cifuentes | 94,2 | 90,2 | 96,8 | 93,2 | 1,000 | 93,2 |
Como se ve, la provincia de Buenaventura es la de mayor Paridad absoluta (en donde es menor la diferencia entre el porcentaje de acceso a agua potable en la zona rural respecto al porcentaje en la región urbana) en tanto la provincia de Cifuentes es la de mayor Paridad Ponderada, aunque con menor Paridad absoluta, dado por el alto Coeficiente de exito que registra esa provincia (es la de mayor porcentaje global de acceso a agua potable).
Síntesis de lo expuesto
En el recuadro 5 se muestra la bibliografía que se puede emplear para ampliar sobre los procedimientos presentados y los programas que se pueden utilizar para su ejecución.
Recuadro 5. Procedimientos de análisis para la cuantificación del estado global de salud y de la identificación de las relaciones entre el estado de salud y los determinantes: bibliografía y programas en que se pueden ejecutar
| Procedimientos de análisis | Referencias (a) | Programa (b) |
| Procedimientos generales de la estadística y de la epidemiología | ||
| Indicadores apropiados | 2 - 9 | [Excel] |
| Pruebas de hipótesis - clásicas - no paramétricas | 11-15 11,15-17 | Excel, SPSS SPSS |
| " Análisis de regresión - Análisis de regresión mínimo-cuadrática | 12,13,18 | EViews, SPSS, Excel |
| - Cociente entre las pendientes de las rectas de ajuste de los valores del indicador de mortalidad o morbilidad (variable dependiente) y valores del determinante (variable independiente) - Regresión tipo Poisson - Otras medidas basadas en el análisis de regresión | 24 25 8,20,26 | [EViews, SPSS, Excel] SSS [EViews, SPSS, Excel] |
| " Análisis de correlación | 13,14,27 | EViews, SPSS, Excel |
| " Tablas de contingencia | 14,16,17,28-30,33-35 | EPIDAT 3.1, SPSS, Excel |
| " Diferencias absolutas y relativas de tasas | 20 | [Excel] |
| " Riesgo atribuible poblacional del valor global del indicador de mortalidad o morbilidad respecto al estrato de mejor condición del determinante (RAPGLOBAL) u otro estrato de referencia | 20,26 | [Excel] |
| " Cambio absoluto basado en el RAPGLOBAL obtenido | 20,26 | [Excel] |
| " Riesgo atribuible poblacional del indicador de mortalidad o morbilidad de cada estrato respecto al estrato de mejor condición del determinante (RAP estrato j) u otro estrato de referencia | 20 | [Excel] |
| " Cambio absoluto basado en el RAPestrato j obtenido | 20 | [Excel] |
| " Otros procedimientos | ||
| " Indicadores basados en la noción de entropía | 39 | [Excel] |
| " Comparación del indicador Brecha con valores críticos (Decil 1, Cuartil 1, Cuartil 3, Decil 9) | 40 | [Excel] |
| " Paridad absoluta y Paridad ponderada | 41 | [Excel] |
(a) Se relacionan los trabajos donde se presentan las ideas centrales del procedimiento y/o se exponen resultados aplicando el procedimiento.
(b) Los programas que facilitan ejecutar el procedimiento, pero no directamente lo ejecutan, se enmarcan entre corchetes.
REFERENCIAS BIBLIOGRÁFICAS
1. López Pardo CM. La medición del estado de salud de la población y su relación con los determinantes. Rev Cubana Salud Pública. 2007 [serie en Internet]; 33(1) [citado 21 Feb 2008]. Disponible en: http://bvs.sld.cu/revistas/spu/indice.html
2. WHO. Development of indicators for monitoring progress towards Health For All by the Year 2000. Geneva: WHO;1981.
3. Rojas F, López C, Silva LC. Indicadores de salud y bienestar en Municipios Saludables. Washington, D.C.: OPS/OMS; 1984. (Documento HPP/HPS/94.30).
4. Braveman P. Monitoring equity in health: a policy-oriented approach in low-and-middle income countries. Geneva: WHO;1998. (Documento WHO/CHS/HSS/98.1)
5. Canadian Institute for Health Information (CIHI). National Consensus Conference on Population Health Indicators, Final Report. Ottawa: CIHI;1999.
6. OPS. Propuesta de indicadores básicos para el monitoreo de la situación de salud de las mujeres. Washington, D.C.: OPS;2002.
7. WHO. Millennium Development Goals. The health indicators: scope, definitions and measurement methods. Geneva: WHO;2003.
8. Keppel K. Methodological issues in measuring health disparities. Vital and Health Statistics 2005. Series 2, No. 141.
9. López C. La medición del desarrollo. En: García M, editor. Las teorías acerca del subdesarrollo y el desarrollo: una visión crítica. La Habana: Editorial Félix Varela;2006.
10. López C, Romero O. Dócimas de hipótesis no paramétricas para diseños experimentales, quasi-experimentales y analíticos. Revista Estadística. 1989;21:106-27.
11. Kanji GK. 100 statistical tests. London: SAGE Publications;1993.
12. Dixon WJ, Massey FJ. Introduction to statistical analysis, 3rd ed. New York: McGraw-Hill; 1969.
13. Steel RGD, Torrie JH. Principles and procedures of statistics with special reference to the biological sciences. New York: McGraw-Hill;1960.
14. Ferrán M. SPSS para Windows; análisis estadístico. Madrid: McGraw-Hill;2001.
15. Kirk RE. Experimental design: procedures for the behavioral sciences. Belmont, California: Brooks/Cole Publishing Company;1968.
16. Mosteller F, Rourke REK. Sturdy statistics; nonparametrics and order statistics. Reading, Massachusetts: Addison-Wesley;1973.
17. Siegel S. Nonparametric statistics for the behavioral sciences. New York: McGraw-Hill;1956.
18. Weiss NA. Elementary statistics, 2nd ed. Reading, Massachusetts: Addison-Wesley; 1993.
19. Representación de la OPS/OMS en Guatemala. Análisis de situación de salud. Area de salud: Alta Verapaz. [Documento de trabajo]. Ciudad Guatemala: Representación de la OPS/OMS en Guatemala;2006.
20. Schneider MC. Métodos de medición de las desigualdades en salud. Revista Panamericana de Salud Pública. 2002;12:398-414.
21. López C, Calvo A. Indice de Salud Municipal. La Paz: OPS; 2001. (Serie Documentos Técnicos No. 4).
22. López C. Desarrollo humano en América Latina y el Caribe. Revista Economía y Desarrollo. 2002;130:11-37.
23. Spiegel JM, Yassi A. Lessons from the margins of globalization: appreciating the Cuban health paradox. J Public Health Policy. 2004;25(1):85-110.
24. Ramírez A, López C. Propuesta de un sistema de monitoreo de la equidad en salud en Cuba [tesis]. La Habana: MINSAP, Escuela Nacional de Salud Pública;2003.
25. Division of Surveillance and Epidemiology, CDC. Statistical software for public health surveillance. Atlanta: Division of Surveillance and Epidemiology, CDC; s/f.
26. Kunst E, Mackenbach JP. Measuring socioeconomic inequalities in health. Copenhagen: WHO Regional Office for Europe; s/f.
27. Yamane T. Statistics: an introductory analysis. 2nd ed. La Habana: Instituto del Libro;1970.
28. Fleiss JL. Statistical methods for rates and proportions, 2nd ed. New York: John Wiley and Sons;1981.
29. Osipov G, editor. Libro del trabajo del sociólogo. La Habana: Editorial de Ciencias Sociales;1988.
30. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington, D.C.: Xunta de Galicia, OPS; 2006. Ayuda: Tablas de contingencia/Tablas generales/Tablas M x N.
31. Silva LC. Diseño razonado de muestras y captación de datos para la investigación sanitaria. Madrid: Díaz de Santos;2000.
32. Vogt VP. Dictionary of statistics and methodology. Newbury Park: SAGE Publications; 1993.p.247.
33. Schlesselman JJ. Case-control studies: design, conduct, analysis. New York: Oxford University Press;1982.
34. de Almeida N, Rouquayrol MZ. Introdução à epidemiologia moderna. 2da ed. Belo Horizonte: CCOPMEDIA/APCE/BRASCO;1992.
35. Xunta de Galicia, OPS. EPIDAT 3.1. A Coruña, Washington, D.C.: Xunta de Galicia, OPS; 2006. Ayuda: Tablas de contingencia/Tablas de asociación: exposición-enfermedad/Tablas 2 x 2.
36. Clark ML. Los valores p y los intervalos de confianza: ¿en qué confiar? Revista Panamericana de Salud Pública. 2004;15:293-6.
37. Susser M. Causal thinking in the health sciences. New York: Oxford University Press;1973.
38. Gloepi. Bol Oficina Sanit Panam. 1994;117(3):245-57.
39. Bacallao J. Indices para medir las desigualdades de salud de carácter social basados en la noción de entropía. Revista Panamericana de Salud Pública. 2002;12:429-35.
40. Torre de la E, López C, Márquez M, Gutiérrez JA, Rojas F. Salud para todos sí es posible. La Habana: Sociedad Cubana de Salud Pública; 2004.
41. CIEM. Investigación sobre desarrollo humano y equidad en Cuba 1999. La Habana: Editorial Caguayo;1999.
Recibido: 11 de abril de 2007.
Aprobado: 20 de abril de 2007.
Cándido M. López Pardo. Facultad de Economía, Universidad de La Habana. Calle L No. 353 e/ 21 y 23, piso 13. La Habana 10400, Cuba. E-mail: clopez@infomed.sld.cu


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}