










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
En la actualidad se presentan diferentes enfoques de causalidad como, por ejemplo,
el de “los determinantes sociales de la salud” que plantea el hecho de que las personas pobres tienen más privaciones, menos conciencia del riesgo, y a la vez menos posibilidades de acceso a los servicios de salud, aun cuando pudiera expresarse una “resiliencia” que implica una adaptación del individuo mucho mejor que la que cabría esperar dadas las circunstancias adversas. 1
el de “curso de vida” que invoca la participación de las modificaciones epigenéticas, a lo largo de la vida, determinando la expresión o silenciamiento de los genes sin que haya cambios en la estructura del genoma y la transmisión generacional de dichas modificaciones constituyendo al parecer las bases moleculares de muchas enfermedades. 2
Estas consideraciones obligan a los investigadores a estudiar el proceso salud-enfermedad a través de modelos complejos, dinámicos, jerárquicos que tienen en cuenta el papel creativo del desorden, de las inestabilidades, del azar, del caos, de las asimetrías. 2,3
Por otro lado, la sociedad actual genera datos de manera exponencial por lo que se requieren nuevos métodos de análisis que permitan extraer el conocimiento subyacente en dichos datos y ajustarlos a modelos cada vez más cercanos al comportamiento real del proceso salud-enfermedad.
Sin embargo, las investigaciones sobre factores de riesgo iniciadas a mediados del siglo pasado, las cuales sentaron las bases del modelo multicausal, se enmarcan en el enfoque lineal que ha predominado en las ciencias naturales. 4 Así el nexo causa-efecto se ha analizado como una relación lineal, no compleja, unívoca y dimensionable, en el cual la ocurrencia del efecto es una función de la causa.
Es por esta razón que en la actualidad el estudio de la causalidad se torna polémico y controvertido, pues las investigaciones médicas emplean técnicas estadísticas que parten del supuesto de que los problemas de salud son simples y lineales, lo cual conduce a un cierto grado de inexactitud y muchos de los modelos empleados tradicionalmente presentan contradicciones, al no lograr explicar satisfactoriamente determinados procesos.
Por lo antes expuesto estas autoras identificaron la necesidad y las posibilidades de aplicar una técnica estadística renovadora para el estudio de la causalidad en las ciencias biomédicas como el análisis estadístico implicativo, conocido por la sigla ASI de Analyse Statistique Implicative del idioma francés donde se originó. 5
El ASI es una herramienta de la minería de datos, basada en las técnicas estadísticas multivariadas, la inteligencia artificial y el álgebra booleana, para modelar la cuasi-implicación entre los sucesos y variables de un conjunto de datos. 6
Esta técnica fue creada por el francés Régis Gras, 7-9 profesor emérito de la Universidad de Nantes, Francia, quien comenzó sus trabajos en este campo en 1980, y desde entonces ha venido estudiando el fenómeno de la creación de reglas inductivas no simétricas y de la cuantificación de la probabilidad de que se presente la característica b si se ha observado la característica a en la población, tratando de modelar relaciones del tipo "si a entonces casi b".
La cuasi-implicación entre variables es una relación asimétrica, donde los conjuntos de reglas obtenidas pueden conducir a hipótesis de causalidad sin restricción con respecto al número de variables y al tamaño de la muestra. Esta se basa en el número de contraejemplos, tiene capacidad predictiva y sus resultados son extrapolables a distintos tamaños de muestras, encuentra sucesos raros, que pasarían desapercibidos a medidas como el soporte y la confianza, por restringirse a sucesos frecuentes y desoye lo trivial, lo cual constituyen ventajas inminentes sobre las técnicas estadísticas clásicas empleadas para identificar posibles factores causales. 7-9
El ASI se ha empleado con éxito en el diagnóstico y solución a problemas propios de la Didáctica de las Matemáticas, que fue su objetivo inicial, así como en otras áreas. Sin embargo, se ha observado en la práctica que, dado el propósito de su origen para dar solución a problemas en el ámbito de la didáctica de las matemáticas, para lograr su aplicación eficiente en los estudios de causalidad propios de las ciencias médicas se hace necesario contextualizar su análisis e interpretación. Surge entonces, como problema científico la siguiente interrogación ¿cómo lograr una aplicación eficiente del ASI en los estudios para la identificación de factores pronósticos y de riesgo?
Para dar solución a dicha interrogante en este trabajo se formuló como objetivo: diseñar una metodología de contextualización del ASI a las investigaciones médicas de causalidad. En este trabajo se expone una propuesta de la misma.
Métodos
Se realizó una investigación aplicada cuya primera fase conllevó una investigación documental entre julio y diciembre de 2018, en la cual se desarrollaron las etapas de este tipo de investigación:
Diseño o plan de la investigación: para llevar a cabo esta investigación, primeramente, se elaboró un plan.
Búsqueda de información documental: se realizó una amplia revisión bibliográfica donde se aplicaron métodos teóricos para analizar los fundamentos que sustentan la creación de la metodología que se propone, así como los procedimientos de cada una de sus etapas y las recomendaciones para su empleo adecuado.
Registro de información mediante técnica de fichero: se elaboraron fichas resumen donde se identificó el estado de desarrollo alcanzado en torno al tema, se obtuvieron datos relevantes acerca de los enfoques teóricos y disciplinares dados a las técnicas estadísticas, de las tendencias y de las perspectivas metodológicas.
Análisis de la información: luego se evidenciaron los hechos que hacen posible el empleo del ASI en las ciencias biomédicas, para lo cual se realizó una comparativa entre esta técnica y la regresión logística binaria como la mejor propuesta para la identificación de factores pronósticos y de riesgo, donde se tuvieron en cuenta 14 aspectos. También se analizaron las investigaciones de causalidad realizadas en las ciencias médicas donde se empleó el ASI, lo que permitió ir determinando las regularidades que ofrecían las pautas para crear la metodología empleada y definir los cambios que posibilitarán un mejor análisis e interpretación de la misma. Para la identificación de las posibles etapas y sus procedimientos se consultaron otras metodologías, se tuvo en cuenta la literatura, el criterio de expertos, y se elaboró un esquema resumen de la misma. Se seleccionaron los autores destacados en la temática, cuyos trabajos se tomaron como referentes para las propuestas de las interpretaciones de los resultados.
Elaboración del informe final: se redactó una síntesis con los aspectos teóricos que fundamentan la presente propuesta, los cuales fueron objeto de artículos científicos en vía de publicación.
Presentación de resultados: en este trabajo se presenta como resultados las etapas de la propuesta metodológica.
Además del estudio documental, se corroboraron las necesidades de análisis e interpretaciones en los estudios de casos y controles realizados previamente para evaluar la utilidad del ASI en la identificación de factores pronósticos y de riesgo. 10-16 En estos estudios surgieron contradicciones y se fueron restructurando los procedimientos por consenso en las consultas a expertos y a usuarios potenciales. Para hacer las primeras modificaciones, antes de comenzar la validación de la metodología, también se consultó a expertos, lo cual no se expone en el presente trabajo.
Resultados
La propuesta metodológica quedó conformada por 8 fases o etapas, algunas con subetapas. En la figura 1 se presentan dichas etapas, cada etapa sucede a la otra según lo indica la flecha y la flecha en retroceso indica que de la etapa de análisis posteriori se puede retornar a la transformación de datos si fuera necesario.
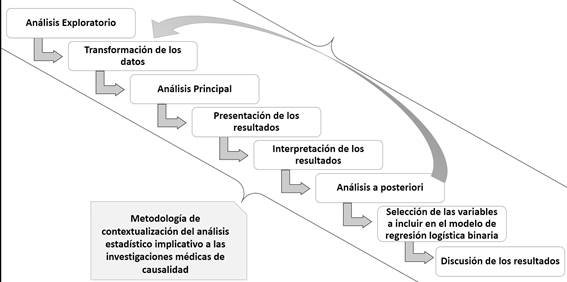
Las etapas se presentan con sus procedimientos a través de figuras y tablas. En la tabla 1 se presentan las dos primeras etapas, previas al análisis principal de los datos.
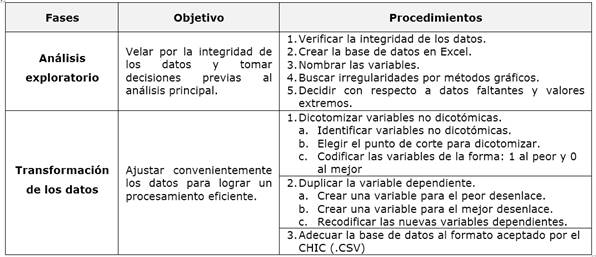
La tercera etapa de procesamiento y análisis de los datos se lleva a cabo según dos variantes en la forma de analizar la variable independiente como se observa en la figura 2.
La etapa 4 consiste en la presentación de los resultados de forma tabular y gráfica. Se tabularán las frecuencias de ocurrencia de cada variable en los casos y controles, los índices de similaridad para las clases formadas y si esta forma parte de una clase mayor que contiene al peor o mejor desenlace y los índices de cohesión para las reglas o metarreglas formadas. Se graficarán el árbol de similaridad, el grafo implicativo general y en modo cono y el árbol cohesitivo.
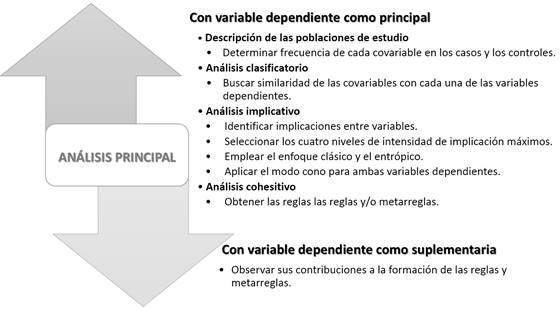
En correspondencia con las tablas y gráficos generados se produce en la quinta etapa la interpretación de los resultados como se aprecia en la figura 3.

El último procedimiento de la interpretación puede conducir a un nuevo análisis, lo cual dependerá de que se encuentren los sujetos típicos, responsables de las relaciones que se producen y en ese caso habrá que retornar a la etapa de transformación, mostrada en el cuadro, para obtener nuevos datos y llegar a nuevos resultados. Finalmente, se seleccionan las variables a integrar el modelo de regresión logística y se discuten los resultados como se aprecia en la figura 4.
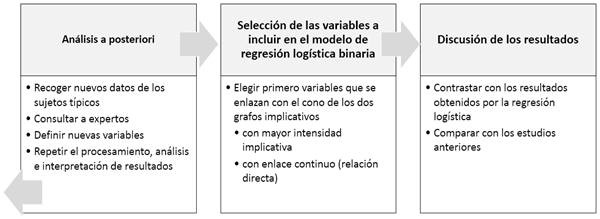
Discusión
Se discuten a continuación los fundamentos por los que se propone cada etapa.
Análisis exploratorio
Se propone esta etapa porque que explorar los datos debe ser la primera fase de todo análisis estadístico. El análisis exploratorio fue propuesto por Tukey en 1977. 17 Se trata de describir el conjunto de datos de cada variable y posteriormente se estudian las relaciones entre ellas.
Esta etapa se realiza con el fin de discernir el comportamiento general de las variables de estudio y observar el tipo de distribución que siguen a través de los estadísticos descriptivos y gráficos que permitan observar el comportamiento de los datos incluyendo la identificación de valores aberrantes. 18
Transformación de los datos
El objetivo de las transformaciones de datos es conseguir alguna ventaja en los análisis, preservando a la vez la información relevante, facilitando la interpretación de los resultados. Existen numerosas transformaciones, que van desde una operación aritmética hasta las puntuaciones de razón, la inversa, las escalas de potencia de Tukey, la logarítmica, etc. Algunas transformaciones permiten, además de simplificar los cálculos, aumentar el nivel de potencia de las pruebas estadísticas, mejorar la simetría de la distribución, comparar valores de distribuciones distintas, acercar la forma de una relación no lineal a una recta al modificar el escalado de la variable o variables, etc., lo que facilita la aplicabilidad de las pruebas estadísticas. 19
La transformación más importante en este estudio es la duplicación de la variable dependiente que se sustenta por el hecho de que el algoritmo empleado en el procesamiento de estos datos sólo analiza la variable codificada con uno.
Análisis principal
Esta etapa se denominó análisis principal porque en la misma se llevan a cabo los análisis propios del ASI y además coexisten otras etapas que también conllevan análisis como el exploratorio y el que se hace a posteriori. El análisis está concebido como la cuarta etapa del método estadístico y junto con la interpretación de los resultados constituyen los aspectos más importantes de la aplicación de cualquier técnica estadística.
Presentación de los resultados
Un aspecto importante en la presentación de resultados de un trabajo de investigación es la representación adecuada y clara de los datos, los cuales pueden ser incluso, imprescindibles para lograr que se acepte su publicación. 20
La organización de los datos en gráficos y tablas es un método invaluable de representación de datos para encontrar relaciones entre las variables con el fin de determinar los patrones, propiedades y relaciones. Es beneficioso para la comprensión del problema complementar la presentación de un análisis formal con una presentación tabular informativa de los datos, ya sea en su forma original o como resumen numérico. 21
Manterola 22 recomienda comenzar la presentación de los resultados por la descripción general de la muestra, que es lo que se hace en esta metodología al mostrar las frecuencias absolutas y relativas de cada variable en casos y controles.
Los gráficos a obtener son los árboles de similaridad y cohesitivo y el grafo implicativo general y en modo cono tal como se describen en Sagaró y Zamora. 23
Interpretación de los resultados
Esta etapa es a juicio de las autoras, la de mayor complejidad. La interpretación de los datos al igual que la habilidad de construir gráficos y tablas, es fundamental en el proceso y producción científica. El creciente énfasis en el desarrollo de habilidades de investigación posiciona la presentación e interpretación de los datos como actividades cada vez más importantes. Tener competencia en interpretar representaciones de datos es esencial para comprender el mundo actual y ser un ciudadano científicamente alfabetizado.24
Un mismo investigador tiene muchas posibilidades de construcciones teóricas. Lo encontrado puede ser interpretado de forma diferente por otros investigadores, considerando el citado carácter polisémico en ciencias humanas. 24 Sistematizar los métodos actuales para el estudio de causalidad en medicina incluyendo el diseño permitió a estas autoras un mejor acercamiento a la correcta interpretación de los resultados. 25
En este trabajo se proponen los criterios que hasta el momento parecen más plausibles, lo que no está exento de cambios a la luz de nuevos conocimientos. Para la identificación de variables confusoras se tomaron como referentes los trabajos de Prado de Cumplido, 26 Reyna, 27 Bacallao 28 y Coscia. 29 Para la clasificación de las cuasi causas se tuvo en cuenta el modelo de Rothman 31,32) y para identificar la interacción los referentes fueron Hernán y Robins 32 quienes también se apoyan en el modelo de Rothman.
Análisis a posteriori
Muchas de las técnicas estadísticas de uso frecuente cuando se trabaja con más de dos muestras requieren un análisis a posteriori, el caso más conocido es el análisis de varianza (ANOVA) que muestre la existencia de diferencias significativas entre los grupos, en cuyo caso, para conocer entre que pares de grupos esta esa diferencia, se requiere de otras pruebas. Las pruebas no paramétricas de Kruskal Wallis, Cochran y Friedman también requieren de pruebas a posteriori por la misma razón.
En esta metodología una vez identificados los sujetos típicos y contributivos, responsables de la formación de las reglas, se continuará el análisis retornando a la etapa de transformación de los datos, ya que se deberán definir nuevas variables que tienen en común los sujetos típicos o contributivos y que no se tuvieron en cuenta en el primer análisis, las cuales podrían ayudar a esclarecer las relaciones encontradas, para lo cual se sugiere consultar a expertos. Por ejemplo, si todos los sujetos típicos son de procedencia urbana, es posible que tener en cuenta como nueva variable: la procedencia, urbana o rural, pudiera explicar la supuesta influencia de algunas relaciones en los resultados.
Selección de las variables a incluir en el modelo de regresión logística binaria
La inclusión de covariables en el modelo de regresión es un tema álgido por cuanto deben cumplir ciertos requerimientos, así Szklo 33 plantea incluir aquellas que: 1) en el análisis bivariado previo demostraron una relación "suficiente" (p<0.25) con la variable dependiente, ya que a pesar de existir una débil asociación en solitario pueden ser fuertes predictoras al analizarlas en conjunto con el resto de las covariables, 2) sean clínicamente importantes, con independencia de si se demostró la significación estadística de la asociación, y 3) por teoría o investigaciones previas se consideren variables confusoras.
Estas autoras proponen que el ASI se realice previo a la regresión logística, ya que sus resultados pueden apoyar en la difícil decisión de cuáles variables incluir en el modelo, sugiriendo que las primeras sean las que se enlazan con el cono de los dos grafos implicativos en modo cono, comenzando por las de mayor intensidad implicativa y las de enlace continuo, que son las que muestran mayor intensidad de asociación y relación directa, respectivamente.
Discusión de los resultados
Esta etapa constituye el cierre de cualquier investigación que permite explicar los resultados. En ella se debe plantear la concordancia o no con trabajos similares y la posible causa de ello, mostrar el porqué de la falta de correlación, delimitar los aspectos no resueltos, exponer las consecuencias teóricas y posibles aplicaciones prácticas. 34
En este caso la discusión se genera luego de la aplicación de la regresión logística binaria a los mismos datos y se contrastan los resultados obtenidos por ambas técnicas, también se comparan los resultados con los procedentes de estudios previos con igual metodología, además de la discusión clásica que se produce en cada investigación original.
Los detalles de cómo aplicar y cómo interpretar esta propuesta se pueden consultar en dos artículos de estas autoras. 35,36
Finalmente, las autoras consideran que la metodología propuesta debe constituir un pilar importante que complemente las técnicas multivariadas empleadas habitualmente en los estudios clínico-epidemiológicos para la identificación de factores pronósticos y de riesgo. Se advierte, además, que dicha propuesta continúa en evolución y seguirá modificándose a solicitud de los investigadores clínicos y bioestadísticos, que son sus principales usuarios.

