










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La comunicación aumentativa y alternativa (CAA) es un área de la práctica clínica que complementa o compensa las deficiencias en la producción y/o comprensión del habla y el lenguaje, incluidos los modos de comunicación hablados y escritos. La CAA cae bajo el paraguas más amplio de tecnología de asistencia, tal como el uso de cualquier equipo, herramienta o estrategia para mejorar la vida diaria funcional en personas con discapacidades o limitaciones.1 El objetivo de la CAA es lograr la comunicación más efectiva para el individuo con el fin de maximizar su potencial, independencia e inclusión social, para llevar la mejor calidad de vida posible.
La CAA utiliza una variedad de técnicas y herramientas tecnológicas o no tecnológicas para ayudar al individuo a expresar sus pensamientos, deseos y necesidades, sentimientos e ideas. 1) Una de esas técnicas es el uso de tableros de comunicación con imágenes o pictogramas que representan un objeto, persona, lugar o concepto. Los sistemas informáticos construidos con esta técnica son ampliamente llamados “Pictotraductores”, puesto que su función principal es traducir texto a pictogramas.
La RAE 2 define el pictograma como “signo de la escritura de figuras o símbolos”. Los pictogramas fueron diseñados por Roxana Mayer Johnson en 1981; y se utilizan como sistemas alternativos a la comunicación oral.3 Es la representación del lenguaje mediante objetos reales, fotos, dibujos o pictogramas. En algunos casos se coloca con la palabra correspondiente en la parte superior y en cartulinas de diferentes colores.4 El método de los pictogramas es uno de los programas más efectivos que se usan en la enseñanza estructurada, ofrece a las personas con autismo las guías que necesitan para saber qué es lo que van a hacer, cómo, con quién y cuánto tiempo van a estar en esa actividad.
El análisis semántico es una característica esencial del enfoque de procesamiento del lenguaje natural (PLN). 5 Indica, en el formato apropiado, el contexto de una oración o párrafo. La semántica trata sobre el estudio de la significación del lenguaje. El análisis semántico en estos sistemas significa entregar el pictograma correcto según el significado de cada palabra o expresión, dependiendo del contexto del texto de entrada, lo que lo hace crucial para la obtención de mejores resultados en las traducciones.
En la presente investigación se analizan los pictotraductores en idioma español: Pictotraductor, Ara Traductor y Pictar. Pictotraductor recibe como entrada texto plano en español, y devuelve una traducción en pictogramas que consiste prácticamente en una traducción palabra por palabra.6 Por su parte, AraTraductor es un traductor de texto español a pictogramas que se apoya en técnicas de Procesamiento del Lenguaje Natural (PLN) para mejorar la traducción final obtenida. La traducción de texto a pictogramas consta de cuatro pasos diferentes: análisis sintáctico, preprocesamiento, consulta a la base de datos y procesamiento de n-gramas.7 Por último, Pictar recibe el texto y realiza primeramente un análisis morfológico del mismo para obtener las categorías gramaticales y lemas de las palabras. La importancia de conseguir el lema de las palabras reside en cómo se organiza la base de datos, ya que por lo general cada pictograma está relacionado sólo con el lema de una palabra. Una vez realizado el análisis, para cada palabra se almacena su lema y su categoría gramatical. En lugar de realizar una simple correspondencia palabra-picto, se realiza un tratamiento adicional de posibles n-gramas.6
Los tres sistemas mencionados fueron desarrollados en España, pero a pesar de que compartimos el mismo idioma, su cultura no necesariamente aborda un lenguaje que pueda ser comprendido por una persona con dificultades del lenguaje en Cuba, debido a que algunas terminologías no están presentes en el lenguaje cotidiano de un cubano. (8), (9 En consecuencia, es costoso para el interlocutor de la persona con necesidades especiales de comunicación encontrar la palabra adecuada, por ejemplo: taza-retrete, llave-grifo, por otro lado, si el pictograma muestra la palabra grifo dificulta la enseñanza de la lectura en este tipo de personas.
Otra de las problemáticas que se presentan tocante al tema, es el relativo a las palabras homógrafas que se escriben igual, pero tienen significados diferentes, por ejemplo: la palabra “banco” tiene disímiles acepciones en el diccionario de la lengua española. A continuación, se muestran cinco de ellas:
1. m. Asiento, con respaldo o sin él, en el que pueden sentarse dos o más personas.
2. m. Madero grueso escuadrado que se coloca horizontalmente sobre cuatro pies y sirve de mesa para labores de carpinteros y otros artesanos.
3. m. En los mares, ríos y lagos navegables, bajo que se prolonga en una gran extensión.
4. m. Conjunto de peces que van juntos en gran número.
5. m. Empresa dedicada a realizar operaciones financieras con el dinero procedente de sus accionistas y de los depósitos de sus clientes.
Es por ello, que la palabra “banco” se puede encontrar en varios contextos y, por tanto, al traducir dicha palabra a pictograma, esta debe hacer alusión a imágenes muy diferentes.
Por tanto, el objetivo de la presente investigación es desarrollar un analizador semántico para aminorar la ambigüedad e incoherencia semántica en las traducciones en un pictotraductor cubano.
Método
Crisp-DM (Cross-Industry Standard Process for Data Mining en inglés y Proceso estándar entre industrias para la minería de datos en español) es una metodología que trata de desarrollar los proyectos de minería de datos bajo un proceso estandarizado de definición y validación de tal forma que se desarrollen proyectos minimizando los costos implicados y con un alto impacto en el negocio. (10
Según Contreras Arteaga y Sánchez Cortina CRISP-DM proporciona el documento modelo de referencia que describe las fases, tareas generales y salidas de un proyecto de minería en general. 11 La metodología CRISP-DM estructura el ciclo de vida de un proyecto de minería de datos en seis fases (Fig. 1), que interactúan entre ellas de forma iterativa durante el desarrollo del proyecto:
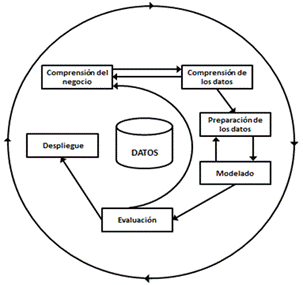
Comprensión del negocio
Esta primera fase es probablemente la más importante y aglutina las tareas de determinación y comprensión de los objetivos, evaluación de la situación: conocimiento previo, volumen de los datos, requisitos del proyecto desde una perspectiva de negocio, conversión de los objetivos en metas de la minería y realización del plan de proyecto.
En consecuencia, con los elementos analizados durante el epígrafe anterior se proponen como tareas del procesamiento del lenguaje natural los siguientes pasos:
Compresión de los datos
Esta segunda fase comprende la recolección inicial de los datos con el objetivo de establecer un primer contacto con el problema, familiarizarse con ellos, identificar su calidad y establecer las relaciones más evidentes que permitan definir las primeras hipótesis. Esta fase junto a las dos siguientes fases son las que demandan el mayor esfuerzo y tiempo en un proyecto de minería de datos.
Los datos fueron recopilados desde la API de ARASAAC. Estos datos son referentes a pictogramas que incluyen variadas informaciones como puede ser, los identificadores, nombres, descripciones, categorías, etiquetas, etc., en total son 19 características por pictograma, es importante señalar que sólo las palabras claves se muestran en español. Estos datos fueron almacenados como un dataframe de pandas en un fichero “csv”, donde las columnas representan las características y las filas los registros/pictogramas (Fig.2).

Preparación de los datos
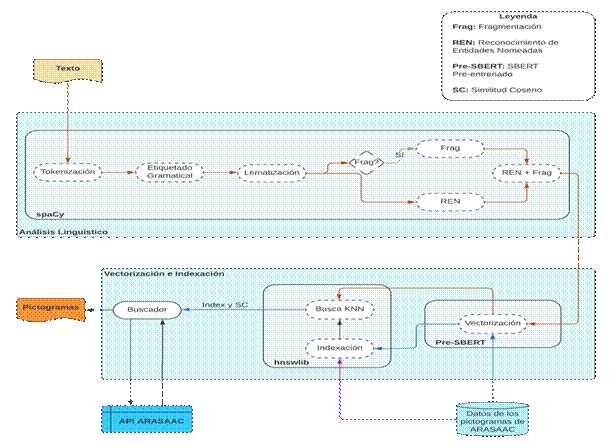
Una vez efectuada la recolección inicial de los datos, se procede a su preparación para adaptarlos a las técnicas de minería de datos que se van a utilizar posteriormente. En la presente investigación se seleccionan solamente dos características para la modelación, de las 19 características por pictogramas de ARASAAC: nombre y descripción; debido a que el resto de las características están en inglés. Una vez seleccionadas dichas características se procede a eliminar todos los registros donde el nombre o la descripción son nulos, debido a que carece de sentido incluir un pictograma sin alguna de estas características. Terminada esta fase crucial se procede a explicar el análisis lingüístico de la propuesta de solución. El análisis lingüístico es crítico para estudiar y entender la estructura, la forma y las características lingüísticas del texto.
Tokenización: La tokenización es el primer paso en la mayoría de los trabajos de procesamiento de texto. (12 La tokenización se utiliza para convertir textos en unidades más pequeñas (tokens). (13 Un token equivale a una palabra, de modo que la oración “Mamá está en la cocina” está compuesta por 5 tokens. Estos tokens son posteriormente pasados para el etiquetado gramatical.
Etiquetado Gramatical: En el PLN, el etiquetado de parte del discurso (Part of Speech - PoS), o también etiquetado gramatical, es una tarea de clasificación de tokens que predice la etiqueta gramatical de cada palabra en contexto. (14 Además, es el proceso en el que a cada palabra de una oración se le asigna una categoría gramatical. (15 En la figura 3, se observa un ejemplo para la oración “Mamá está en la cocina” donde cada palabra recibe su clase gramatical.

El etiquetado gramatical es importante en la solución de esta investigación en dos etapas, para identificar los Chunks/fragmentos que se explican más adelante y al final para determinar cuál de los dos embeddings (nombres o descripciones) se debe usar como mecanismo de búsqueda dependiendo de la categoría gramatical que tenga la palabra. Se usarán los embeddings de los nombres para los artículos definidos, preposiciones, verbos, sustantivos y pronombres y para las demás categorías gramaticales se usarán los embeddings de las descripciones.
Lematización: La lematización 16 es el proceso de encontrar la forma morfológica básica de una palabra. Un lematizador utiliza una base de conocimiento de sinónimos de palabras y terminaciones de palabras para garantizar que solo las palabras que significan cosas similares se consoliden en un solo token; este token es el utilizado para el análisis. Por ejemplo, en inglés “soy,” “eres'', “es”, “era”, “éramos”, se tratarán todos de la misma manera que "ser" por un lematizador, aunque tengan significados diferentes.
Fragmentación: La fragmentación de texto se refiere a la tarea de dividir una cadena de información textual en grupos de unidades relacionadas que no se superponen. Este es un problema fundamental en numerosos campos donde es relevante comprender la relación entre unidades de datos secuenciales. (17 En lugar de simples símbolos que pueden no representar el significado real del texto, es recomendable utilizar frases como "La Habana" como una sola palabra en lugar de las palabras separadas "La" y "Habana".
Modelado
En esta fase de CRISP-DM se seleccionan las técnicas de modelado más apropiadas para el proyecto de minería de datos específico. Debido a que se va a implementar un mecanismo de búsqueda semántica, se debe utilizar una técnica con un enfoque basado en la similitud semántica. Se ha escogido SBERT 18 una adaptación del modelo BERT 19 pre-entrenado en los diferentes algoritmos, modelos y técnicas existentes para la similitud semántica.
Vectorización: Las computadoras no pueden procesar los textos en su formato original. Es sabido que las computadoras funcionan con representaciones numéricas, si se profundiza más funcionan con señales eléctricas. Para procesar textos es necesario convertirlos en números.
La ingeniería de atributos (feature engineering) en el procesamiento del lenguaje natural (PLN) implica la creación de funciones numéricas específicas para representar aspectos destacados del texto, como la proporción de sustantivos a pronombres. Este enfoque a menudo requería un conocimiento de dominio significativo y un esfuerzo para identificar características significativas. Por el contrario, los word embeddings se pueden aprender directamente de un corpus de texto y no requieren ningún etiquetado manual o feature engineering, es decir, se pueden aprender sin supervisión. (20
Word Embeddings consiste en un conjunto de lenguajes de modelado y técnicas de aprendizaje donde las palabras que tienen un mismo significado semántico tienen una representación similar. (21 Finalmente, la arquitectura final del analizador semántico estará compuesta por un análisis lingüístico, un mecanismo de búsqueda semántica, una predicción en el modelo pre entrenado SBERT y una búsqueda en la API de ARASAAC como se puede muestra en la figura 4.
Despliegue o implantación
En esta fase, y una vez que el modelo ha sido construido y validado, se transforma el conocimiento obtenido en acciones dentro del proceso de negocio, esto puede hacerse por ejemplo cuando el analista recomienda acciones basadas en la observación del modelo y sus resultados, o por ejemplo aplicando el modelo a diferentes conjuntos de datos o como parte del proceso (en análisis de riesgo de créditos, detección de fraudes, etc.). Generalmente un proyecto de minería de datos no concluye en la implantación del modelo, ya que se deben documentar y presentar los resultados de manera comprensible para el usuario con el objetivo de lograr un incremento del conocimiento. Por otra parte, en la fase de explotación se debe asegurar el mantenimiento de la aplicación y la posible difusión de los resultados.
RESULTADOS
Para verificar que, con la implementación del analizador semántico, se aumenta la ajustabilidad de los pictogramas al contexto y a la semántica se emplea el método Delphi y el método científico cuantitativo de experimento descrito por Hernández Sampieri. (22
El diseño experimental consiste en manipular intencionalmente una acción para analizar sus posibles resultados. Según Hernández Sampieri un diseño experimental debe cumplir con tres requisitos: la manipulación intencional de una o más variables independientes, medición del efecto que la variable independiente tiene en la variable dependiente y control o la validez interna de la situación experimental. 22
Por otro lado, el método Delphi consiste en la selección de un grupo de expertos a los que se les pregunta su opinión sobre cuestiones referidas a un problema definido, se clasifica como uno de los métodos generales de prospectiva, que busca acercarse al consenso de un grupo de expertos con base en el análisis y la reflexión de dicho problema. (23 Para la aplicación del método se siguieron las siguientes etapas:
Elección de expertos
Según las fuentes referenciadas, un experto es una persona, grupo de personas u organización con conocimientos amplios en un área particular del conocimiento, capaces de valorar, formular conclusiones objetivas y dar recomendaciones acerca del problema en cuestión.
En el caso de esta investigación, los expertos se seleccionaron teniendo en cuenta que cumplieran con los criterios siguientes:
Especialista en enseñanza de personas con dificultad del habla.
Profesor/a de la lengua española.
Familiar de persona con dificultad del habla.
Conocimientos de PLN.
Finalmente, se escogieron ocho expertos, considerando la presencia de un especialista en enseñanza de personas con dificultad del habla, dos profesores de la lengua española, cuatro familiares de personas con dificultad del habla y un profesor con conocimientos de PLN.
Preparación del instrumento
Una vez seleccionados los expertos, se elaboró un documento con diez oraciones que fue sometido a la consideración de los expertos con el objetivo de validar los indicadores de la propuesta de solución. Por ser un experimento a base de hipótesis, las oraciones son traducidas por dos de los sistemas homólogos Pictar, Pictotraductor (Aratraductor no se incluyó debido a que no fue posible acceder a dicho sistema) y por la presente propuesta de solución Pictobana. Los expertos tienen la tarea de evaluar las traducciones de los tres sistemas.
La evaluación de una oración es efectuada de la siguiente manera:
Primero, se evalúa cada token traducido en pictograma. Se evalúa cada token de la oración procesada (que pasó por el análisis lingüístico) traducido en pictograma. Si el pictograma se ajusta al contexto de la oración obtiene un valor de 0.5, de lo contrario obtiene un valor de 0. Si el pictograma se ajusta semánticamente al token traducido obtiene un valor de 0.5, de lo contrario obtiene un valor de 0. Para saber si un token fue correctamente traducido se suman los dos valores anteriores, el resultado 0 indica que el token no cumple con ninguno de los indicadores, 0.5 indica que cumple con uno de los indicadores y 1 indica que cumple con los dos indicadores, lo que quiere decir que la traducción está libre de incoherencia y ambigüedad semántica. Este cálculo se hace para cada token traducido.
Segundo, se calcula el porcentaje de acierto de traducción de la oración. El porcentaje de acierto de traducción de una oración, se calcula mediante la fórmula:
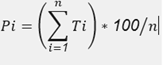
Donde:
Pi = Porcentaje de acierto de traducción de la oración i.
Ti = Traducción del token i.
n = Cantidad de tokens de la oración pos procesamiento (análisis lingüístico).
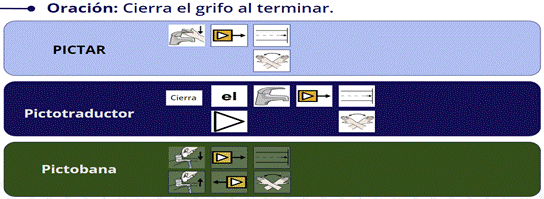
Los pictotraductores analizados y la solución propuesta, devuelven más de una ocurrencia para cada traducción de un token, con el objetivo de seleccionar el pictograma ideal, si este no está en la primera ocurrencia. En la figura 5, se observa una traducción con 2 resultados. Por lo que se ha evaluado el porcentaje de acierto del primer resultado (primera fila) que devuelve el sistema, con el objetivo de analizar la efectividad del sistema al devolver la traducción correcta en el primer resultado, y también se evaluó el porcentaje de acierto dentro de los 5 primeros resultados.
La cantidad de tokens de la oración después del análisis lingüístico puede variar, siendo este valor menor o igual a la cantidad de tokens inicial de la oración. Como se observa en la figura 5, la oración inicial tiene cinco tokens y la traducción de Pictar y Pictobana consta de tres pictogramas representando tres tokens pertenecientes a las cadenas: “cierra el grifo”, “al” y “terminar”. Eso significa que Pictar y Pictobana realizaron la fragmentación. En este caso “n” es igual a tres. Para Pictotraductor la cantidad de tokens es igual a 5, la misma cantidad que la oración inicial (antes del análisis lingüístico).
Tercero, se calcula el promedio de acierto del sistema para las diez oraciones. El promedio de acierto del sistema, se calcula mediante la fórmula:
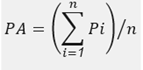
Donde:
PA = Promedio de acierto del sistema.
Pi = Porcentaje de acierto de traducción de la oración i .
n = Cantidad de oraciones.
En la tabla 1 se observan los resultados de la evaluación.
Promedio de las evaluaciones y concordancia de los expertos
Los criterios de evaluación de las oraciones son aprobados por los expertos, por lo que hubo un consenso sobre el método a usar para la validación de las mismas. Por este motivo no hubo necesidad de determinar mediante cálculos el nivel de concordancia de las evaluaciones de los expertos. En la tabla 1 se muestra el resultado final de las evaluaciones.
Reporte de los resultados
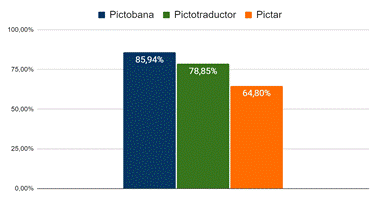
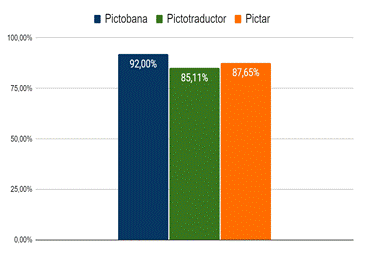
La tabla 1 muestra los resultados detallados para cada oración, las figuras 6 y 7 muestran los resultados finales de los sistemas homólogos y de la solución propuesta para los resultados en la primera posición (Fig. 6) y en las cinco primeras posiciones (Fig. 7).
Como se evidencia en los resultados, Pictobana pudo hacer 5 fragmentaciones correctas (es decir que no distorsionan el significado de la oración), terminó con 85,94% de precisión para los resultados en la primera posición y 92,00% teniendo en cuenta las cinco primeras posiciones. Precisión superior a Pictar y Pictotraductor. Este resultado permite aceptar la hipótesis planteada inicialmente.
A continuación, se presentan las diez oraciones que fueron objeto de análisis por los expertos y los resultados de la evaluación se pueden apreciar en la tabla de la figura 8.
Cierra el grifo al terminar
Lava tus palmas y dedos de las manos
Enciende el televisor
Escribe sin romper las hojas
Yo me siento bien para descansar
El niño corre la cortina
El conejo va a dormir
El fuego devora la madera
La niña tiene ojos café y pelo negro
El papá corta el árbol con su hacha
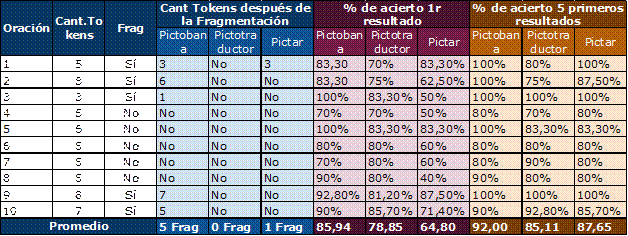
Fig.8 -Tabla que muestra los resultados de la evaluación de Pictobana en comparación a Pictar y Pictotraductor.
Resulta relevante señalar que, para dar continuidad con la presente investigación se deben revisar y editar las características de algunos pictogramas de tal manera que se correspondan mejor al contexto cubano, también vale la pena traducir otras características de los pictogramas del dataset de ARASAAC al español y utilizarlas para reforzar la comprensión de los pictogramas. En adición, almacenar las oraciones entradas por el usuario para usarlas como datos de entrenamiento del modelo y brindar la posibilidad al usuario de opinar sobre la traducción obtenida constituyen elementos que pudieran utilizarse para la implementación de un aprendizaje reforzado. (24
Conclusiones
El desarrollo del analizador semántico para un Pictotraductor permite arribar a las siguientes conclusiones: con el estudio de los sistemas homólogos se detectaron las funcionalidades básicas de un pictotraductor y su analizador semántico. Además, el empleo de la metodología CRISP-DM, permitió implementar un sistema que cumpliera con los estándares del desarrollo de proyectos de minería de datos y PLN. Es importante destacar que el análisis exploratorio de los datos recopilados, permitió identificar las características de los pictogramas más propicias para el analizador semántico, así como también percibir algunos inconvenientes propios de las diferencias culturales que disminuyen la eficacia de la solución propuesta. Sin embargo, el sistema desarrollado proporciona a las personas con dificultades del habla en Cuba y a sus familiares una herramienta que ayuda a promover las competencias y habilidades de estas personas. Finalmente, las pruebas realizadas mediante experimentos y criterio de expertos, validaron que el sistema desarrollado, aumenta la ajustabilidad de los pictogramas al contexto y a la semántica, aminorando la incoherencia y la ambigüedad semántica del sistema.

