










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkI. Introducción
Las pruebas de software son procesos orientados a demostrar que un programa realiza las funciones para las cuales fue construido [13]. Las pruebas son exitosas cuando detectan defectos o fallos, por lo que tributan a la calidad dentro del proceso de desarrollo de software [14, 25, 30]. No obstante, las pruebas son costosas y a menudo abarcan más del 50% de los costos totales de desarrollo [2, 11, 25]. Debido a esto, se hace necesario y es de gran beneficio, la automatización del proceso de pruebas con el objetivo de disminuir su costo e incrementar su efectividad [23, 33].
Actualmente múltiples investigadores centran su atención en el proceso de desarrollo de pruebas de software, ocupando un lugar fundamental en los trabajos científicos [10, 15, 17]. Se mantienen como problemáticas la generación de caminos y valores de pruebas para apoyar el diseño de los casos de prueba [12, 16, 25, 33].
Existen diferentes herramientas como JUnit, NUnit y PHPUnit que permiten ejecutar pruebas unitarias de forma automática, pero carecen de funcionalidades que asistan al desarrollador en el diseño de los casos de pruebas [24]. En la actualidad existen propuestas de herramientas para la generación de código de pruebas unitarias en diferentes formatos de salida [5, 27, 28, 32]. Sin embargo, todas no son libres, y la mayoría se centran en un lenguaje de programación por lo que sería necesario utilizar diferentes herramientas en una misma empresa de desarrollo de software que utiliza diferentes lenguajes de programación en correspondencia con los requisitos del cliente, para la automatización de las pruebas unitarias. En la actualidad existen varios modelos para la automatización de pruebas de software [1, 3, 6, 7, 33]. El Modelo para la Generación Automática de Pruebas basado en Búsquedas (MTest.search) definido por los miembros del grupo de investigación Calidad y pruebas de software de la Cujae, cuenta con mecanismos de extensión para los modelos de dominio, de prueba y de ejecución [1, 19]. La contribución fundamental de MTest.search está en la propuesta de modelos de optimización que permiten diseñar casos de pruebas con combinaciones de valores reducidos y que tienen un soporte automatizado que puede ser fácilmente integrado a ambientes de trabajo. Dada la necesidad de mejorar la efectividad de las suites de pruebas generadas para detectar defectos o fallos, en el grupo de investigación se propuso incluir la significación de los valores de prueba que se obtienen, y de los caminos/escenarios de la unidad bajo prueba. Sin embargo, MTest.search no cuenta con mecanismos de extensión del modelo de reducción basado en búsqueda, lo que imposibilita la incorporación de nuevos criterios a tener en cuenta para elevar la efectividad de las pruebas.
Este artículo presenta mecanismos para extender el modelo de reducción basado en búsquedas, así como, extensiones de los componentes de dominio y de ejecución para la generación automática de pruebas unitarias a partir de código fuente Java. Los componentes permiten generar casos de pruebas a partir de código fuente que contengan objetos y conjuntos. Se incluye el componente de extensión del modelo de reducción basado en búsquedas implementado, para potenciar la detección de errores a partir de la significación de los valores y caminos/escenarios, en dependencia de la técnica de diseño de casos de pruebas empleada en cada caso.
II. Métodos
La propuesta se basa en componentes de extensión de MTest.search para la generación de código de prueba teniendo en cuenta los objetos y conjuntos involucrados en el código fuente y la significación de las variables y caminos que intervienen. Se realizaron revisiones de la literatura y se diseñaron casos de estudios para validar la propuesta a partir del análisis cualitativo de los resultados obtenidos durante la generación de código de prueba con los componentes que se presentan.
Modelo para la Generación Automática de Pruebas basado en Búsquedas
Durante el proceso de desarrollo de software se utilizan modelos para la representación de los artefactos necesarios para la descripción del producto que se está desarrollando. Con anterioridad se han definido modelos para el proceso de pruebas de software. MTest.search, consta de flujos de trabajo para la ejecución de pruebas tempranas en el entorno de producción, Modelos de Optimización para reducción de casos de pruebas funcionales y unitarias, y Herramientas Automatizadas Integradas que dan soporte a la ejecución de los flujos de trabajo [1]. El MTest.search cuenta con mecanismos de extensión, que permiten la adaptación de sus modelos y herramientas, tanto por desarrolladores avanzados como principiantes, a diferentes entornos productivos y empresariales [19].
MTest.search contiene los siguientes elementos:
a. Modelo de Dominio, con sus respectivos modelos de descripción de dominios fuente.
b. Modelo de pruebas y Modelo de pruebas reducido.
c. Modelo de reducción basado en búsquedas.
d. Modelo de ejecución, con sus respectivos modelos de descripción de código destino.
Se han desarrollado herramientas que dan soporte a MTest.search permitiendo:
la generación de valores significativos para la prueba teniendo en cuenta diferentes técnicas de diseño de casos de pruebas [19; 20]
la creación de casos de pruebas con el Generador de Casos de Pruebas (GeCaP), para satisfacer la técnica del camino básico, a partir de los valores previamente generados [4, 20, 21, 22, 26, 31].
Sin embargo, las propuestas anteriores no se centran en el análisis de significación de los valores según las técnicas aplicadas para su obtención, ni incluyen criterios para determinar cuáles son los caminos más importantes. Darles solución a las limitaciones antes mencionadas durante el proceso de generación de las suites de pruebas, tributará a la detección de defectos o fallos. Se tiene en cuenta el análisis gramatical del código fuente Java para generar un Árbol de Sintaxis Abstracta (AST, por sus siglas en inglés), a partir del cual se genera el Grafo de Control de Flujo (CFG, por sus siglas en inglés) correspondiente, que constituye el lenguaje intermedio [8, 9]. Por último, el componente Generador de Código de Prueba (GeCodP) integra los componentes mencionados anteriormente para la generación de código de pruebas unitarias a partir de código fuente en lenguaje Java [9, 18, 34,35]. Estas propuestas solo tienen en cuenta la entrada de variables de tipo de datos simples (numérico, lógico y cadena), lo que constituye una limitación.
Las herramientas están organizadas mediante el patrón Arquitectura basada en componentes y está orientado a la experticia del usuario de MTest.search. Se expresa a través de una arquitectura compuesta por tres capas: capa de generación de suite de pruebas, capa de extensión y capa de entorno usuario. La arquitectura de las herramientas de soporte al modelo MTest.search, se observa en la figura 1, donde se señalan los componentes de la capa de extensión en los que se trabajará [9, 19].

Mecanismos de extensión del modelo de reducción basado en búsqueda
Para extender el modelo de reducción basado en búsqueda es necesario implementar en la capa de Extensión un componente (GeVaUExt) que extienda al componente Generador de Valores GeVaU (contiene el modelo de optimización), que se encargue de incorporar los nuevos criterios a tener en cuenta para influir en la efectividad de los casos de pruebas que se generen. Para esto se debe crear una interface en GeVaU que se establezca la comunicación entre ambos componentes. Aquí se incluyen los métodos que deben ser redefinidos por la extensión, según los nuevos criterios a tener en cuenta en el análisis de los valores y las modificaciones al modelo de optimización que se deseen adicionar. Todas las clases deben implementar dicha interface.
Para incluir las modificaciones realizadas por la extensión de GeVaU es necesario implementar un componente de extensión (GeCaPExt) del componente Generador de Casos de Pruebas (GeCaP) que posee la clase ObtainValues encargada de iniciar el proceso de generación de valores significativos de las variables. Se debe crear una clase en GeCaPExt que herede de ObtainValue e implemente una interfaz de GeCaP para redefinir los métodos encargados de construir los ficheros de intercambio entre los componentes, con la información de los valores de las variables involucradas. Luego, el componente GeCodP debe importar la extensión de GeCaP, para poder acceder a los métodos modificados. Para integrar los componentes GeVaUExt y GeCaPExtension es necesario crear una componente de servicio que logre la comunicación entre la capa de Extensión y la de Entorno de usuario.
Componente para la generación del CFG a partir de código fuente en lenguaje Java (CFG_ANTLRGenerationExt)
El componente que se presenta en este trabajo constituye una solución a la generación del CFG a partir de código fuente Java para el tratamiento de tipos de datos objeto y conjunto. Los requisitos de CFG_ANTLRGenerationExt se muestran en la figura 2, a través de un diagrama de casos de uso del sistema.
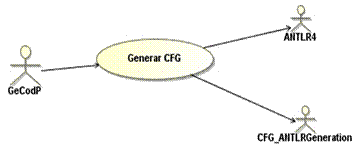
Para generar el CFG se parte del código fuente en Java, este es procesado por la herramienta ANTLR4 [29] detectando elementos de la gramática y generando el árbol de sintaxis correspondiente (ATN, por sus siglas en inglés). Posteriormente, se determina cuáles son los parámetros de entrada y se genera el fichero con la información de estos. Luego, el componente a partir del análisis del ATN detecta las llamadas a métodos y a atributos de objetos y de conjuntos existentes, pasándole la información a GeCodP.
El componente CFG_ANTLRExt recibe cuatro ficheros: Llamadas.txt, ParametrosEntrada.txt, ParametrosEntradaObjetos.txt y ParametrosEntradaConjuntos.txt. Con el procesamiento de la información contenida en Llamadas.txt, se genera un código copia (codigoCopiaA), en el que se sustituyen las llamadas indicadas por el usuario, por el valor fijo correspondiente, según la descripción dada. A partir del análisis de la descripción de los objetos y conjuntos que constituyen parámetros de entrada, se transforma el método y se crea otro método copia (codigoCopiaB) donde se sustituyen a los objetos por sus atributos de dominios simples (lógico, cadena y numérico). En este punto, ya el codigoCopiaB puede ser procesado por el componente CFG_ANTLRGeneration para la generar el CFG.
Componente para la generación de código de pruebas unitarias en lenguaje Java (TestCodeGenerationExt)
Para generar código de pruebas unitarias en Java que pueda ser ejecutado en JUnit, se parte del CFG generado por el componente CFG_ANTLRGenerationExt con variables de dominios de entrada de datos simples. Luego GeCaP se comunica con el resto de los componentes y se encarga de diseñar los casos de pruebas. A partir de las combinaciones de valores para cada caso de prueba, TestCodeGeneration genera código de prueba correspondiente a partir de la información de los ficheros ParametrosEntradaObjetos.txt, ParametrosEntradaConjuntos.txt y CodigoCopiaB.txt (Código del método con la transformación de tipos de datos complejos a simples).
Si existen parámetros de entrada de dominios complejos, se modifican los métodos de prueba generados por TestCodeGeneration, en función de los parámetros originales, cuya información aparece recogida en los ficheros de textos antes mencionados. TestCodeGenerationExt modifica el código de prueba generado por TestCodeGeneration teniendo en cuenta la creación de instancias de tipos de datos complejos, con los valores generados, para la ejecución de este código de prueba en JUnit, en dependencia de lo que desea probar el usuario. En la figura 3 se observa un diagrama de CUS del componente TestCodeGenerationExt
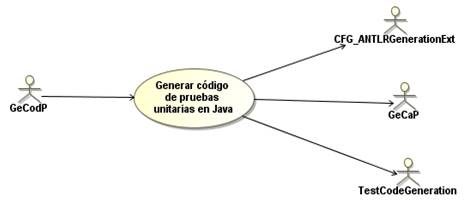
El componente CFG_ANTLRExt integra el análisis de la gramática del código fuente en lenguaje Java a partir del procesamiento que realiza la herramienta ANTLR v4. Para ello, se ha definido la gramática Java para ANTLR4.
En la figura 4 se muestra un fragmento del fichero JavaLexer.g que contiene los elementos léxicos del lenguaje Java.
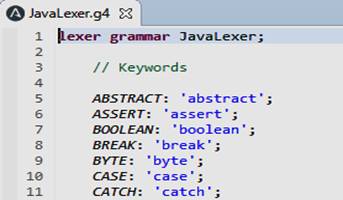
En la Figura 5 se muestra un fragmento del fichero JavaParser.g4 que contiene estructuras gramaticales implementadas para el procesamiento de código fuente en Java y su transformación en un ATN.

Luego de transformar el código fuente Java a un ATN, el componente determina cuáles son los parámetros de entrada del método que se desea probar. Esta información se almacena en el fichero ParametrosEntrada.txt (Ver Figura 6) con el identificador y el tipo de dato Java de los parámetros.

El componente CFG ANTLRExt recibe información de los parámetros de entradas de dominio objeto y conjunto, para la transformación de las variables de dominios de entrada de datos complejos (objeto y conjunto) en variables de dominios de entrada de datos simples (lógico, cadena y numérico), a través de los ficheros ParametrosObjetos.txt y ParametrosConjuntos.txt.
El componente CFG_ANTLRGeneratorExt genera el fichero CodigoCopiaB.txt, para ser procesado por el resto de los componentes de MTest.search.
Componentes de extensión del modelo de reducción basado en búsqueda
A partir de los mecanismos propuestos para extender el modelo de reducción basado en búsquedas, se implementaron los componentes GeVaUExt, GeCaPExt y GeneracionCasoPruebaServicio (Figura 1), para incorporar los criterios de significación de los valores y de los caminos o escenarios, durante la generación de las suites de pruebas. Para ello se ha implementado el componente GeVaUExt que extiende al componente GeVaU. En el grupo de investigación se definieron criterios de significación de los valores para las variables de dominios: numérico, cadena, enumerado, fecha, lógico y conjunto. La significación es un valor numérico en el intervalo [0,1], depende de las técnicas utilizadas para generar los valores iniciales, como por ejemplo la técnica de partición de equivalencia y valores límites, que contiene un conjunto de clases de equivalencia definidas. La significación de cada clase de equivalencia depende de las transformaciones que se les hace a los valores límites según el dominio de la variable. Mientras más cercano a 0, el valor de las variables es menos significativo, de lo contrario si está más cerca a 1 mayor significación tiene. Para los valores propuestos por el usuario la significación es 1. En la tabla 1 se refleja la significación de los valores utilizando las técnicas de partición de equivalencia y valores límites para las variables numéricas.
Tabla 1 Significación de valores utilizando técnicas de partición de equivalencia y valores límites para las variables numéricas
| Dominio | Clases de equivalencia | Transformación | Significación |
|---|---|---|---|
| Numérico | 11 | V = (MaxIntervalo(y) - MinIntervalo(y))/2 | 0.5 |
| 12 | V = add(MinIntervalo(y), -1 | 0.8 | |
| 12 | V = add(MaxIntervalo(y), 1) | 0.8 | |
| 15 | V = MinIntervalo(y) | 1.0 | |
| 15 | V = MaxIntervalo(y) | 1.0 |
El componente GeVaUExt recibe tres ficheros: VariablesValores.txt, Condiciones.txt y Caminos.txt, que permite la generación de las combinaciones de los valores que cubren un camino o escenario determinado según las condiciones que presente. El fichero VariablesValores.txt contiene las variables de entrada, los valores de cada una y su significación, como se observa en la figura 7.
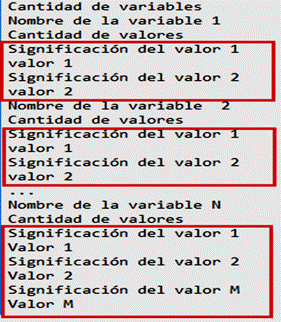
En esta extensión se definió que la significación de cada camino (valor numérico en el intervalo [0,1]) dependerá de la cantidad de condiciones contenidas, es el resultado de dividir la cantidad de condiciones en el camino entre la cantidad total de condiciones. En la Figura 8 se muestra la estructura del fichero Caminos.txt que contiene la información de los caminos independientes.

Para poder generar la suite de prueba se hizo necesario implementar el componente GeCaPExt encargado de crear los ficheros de entrada del GeVaUExt. A partir del análisis de la significación de los valores y de los caminos se generan los casos de pruebas, dándole prioridad a los caminos con más condiciones y empleando valores más significativos para detectar mayor cantidad de errores.
III. Resultados
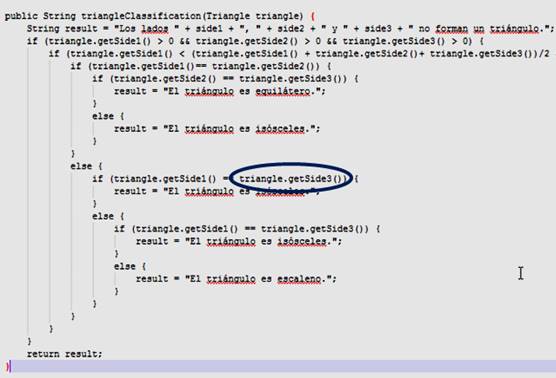
Para evaluar el valor práctico de la generación del código de prueba por los componentes desarrollados, se definieron dos casos de estudio como mecanismo de validación, a partir de dos métodos (triangleClasification y getSamplesAsBytes) de proyectos reales. El método triangleClasification es una implementación en Java del algoritmo clásico del problema de clasificación de triángulos según las longitudes de sus lados, mientras, getSamplesAsBytes pertenece a la biblioteca de proyectos Apache Commons JXPath. En las figuras 9 y 10 se muestran los códigos correspondientes a los métodos, que se sometieron al proceso de generación de código de prueba con la solución propuesta, en los casos de estudio.

En las figuras 11 y 12 se muestran fragmentos del código de prueba JUnit generado por los componentes desarrollados, para los métodos Java de los casos de estudio.

Fig. 11 Fragmento de la clase de prueba JUnit generada por TestCodeGenerationExt para probar el método getSamplesAsByte
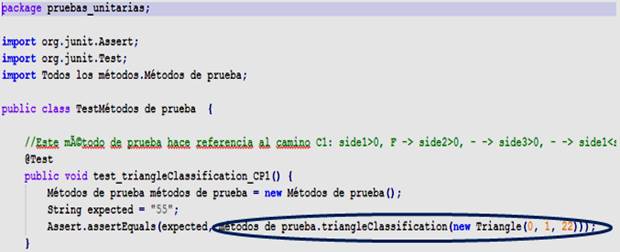
Fig. 12 Fragmento de la clase de prueba JUnit generada por TestCodeGenerationExt para el método triangle Clasification
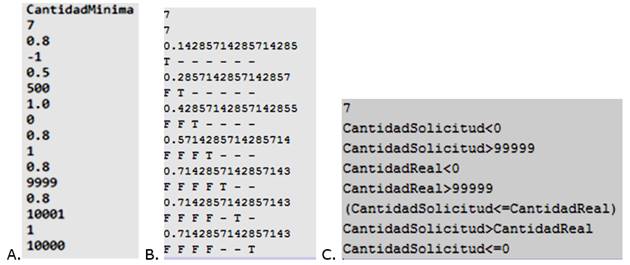
Para validar la extensión del modelo de reducción basado en búsquedas se empleó el método reservarProducto, perteneciente a un proyecto de comercio electrónico, en él intervienen 5 variables de interés (tres de dominio numérico: cantidadMinima, cantidadMaxima, cantidadReal, cantidadAReservar; y una de dominio cadena (caracteres): idProducto). Este método se encarga de verificar la disponibilidad del producto que se desea reservar. En la Figura 13A se muestra un fragmento del fichero VariablesValores.txt con los valores generados para la variable cantidadMinima y la significación asignada a cada valor, en correspondencia con la técnica empleada. A partir de la estrategia definida para asignar el valor de significación para cada camino, en la Figura 13B se muestra el fichero Caminos.txt que recoge la estructura y la significación de cada camino del método bajo prueba y en la Figura 13C se muestran las condiciones.
IV. Discusión
Generación de código de prueba JUnit para el método getSamplesAsBytes
Para validar la transformación del código fuente en Java con variables de tipo conjunto, a un código copia con variables simples, se utilizó el método getSamblesAsBytes, cuyo código fuente se muestra en la Figura 7. Este método tiene dos conjuntos (result y bitsPerSample) y un objeto (bis) como parámetros de entrada.
A partir de la descripción de los objetos y conjuntos dada por el usuario, se modifica el código fuente original transformando las variables complejas en variables simples.
A partir del código fuente original modificado, TestCodeGeneration genera los métodos de pruebas. A partir de estos métodos de pruebas, TestCodeGenerationExt obtiene la clase JUnit de la Figura 9. Cada método de prueba se modifica en correspondencia con las especificaciones dadas por el usuario. Se crea dentro del método de prueba una instancia de BitInputStream y dos listas. Además, se van insertando los elementos a cada conjunto en correspondencia con los datos de pruebas generados. Antes de ejecutar el código de prueba generado, el programador tendrá que importar la biblioteca java.util para garantizar el trabajo con colecciones de datos, y la clase BitInputStream, haciendo referencia al paquete en que se encuentra dentro del proyecto bajo prueba.
Generación de código de prueba JUnit para el método triangleClasification
La implementación del método de clasificación de triángulos seleccionada recibe como parámetro un objeto de tipo Triangle que tiene como atributos las longitudes de sus lados y se accede a ellos a través de llamadas. Por tal motivo ha sido escogido para mostrar la generación de código de pruebas unitarias correspondiente a tipo de datos objetos de la figura 8.
Se detectaron tres llamadas a métodos, pero el usuario especifica que hacen referencia a los atributos del objeto triangle. En correspondencia con lo anterior, se genera CodigoCopiaB.txt con los atributos de triangle como parámetros de entrada y las llamadas sustituidas por los atributos respectivos.
TestCodeGeneratioExt procesa los métodos de pruebas generados por TestCodeGeneration y crea una instancia de Triangle, para pasársela como parámetro al método original, con los valores de pruebas generados. En la Figura 10 se muestra el código de pruebas JUnit generado por TestCodeGenerationExt, que es el que realmente se devuelve al usuario para su ejecución en JUnit.
Tratamiento de la significación de valores y caminos del método reservarProducto
El método posee 5 variables numéricas, 7 caminos independientes (Ver Figura 7 condiciones, donde las cuatro primeras comprueban si los valores se encuentran entre 0 y 99 999 y las últimas verifican si la solicitud se puede reservar satisfactoriamente. GeVaUExt incorporó la significación de los valores en función de las técnicas aplicadas para generar los valores. En el caso del valor 0, que constituye el límite inferior del intervalo, tiene el máximo valor de significación. El componente GeCaPExt incorpora en el fichero Caminos.txt la significación de cada camino, en función de la cantidad de condiciones en el caso del primer camino la significación tiene valor 1/7, debido a que tiene una sola condición.
Los mecanismos de extensión propuestos permiten la generación de suites de pruebas reducidas a partir de criterios de significación de atributos y caminos/escenarios incluidos en el modelo de optimización de MTest.search. Las suites de pruebas generadas contienen un grupo de casos de pruebas que contribuyen a detectar defectos o fallas, sin necesidad de generar una cantidad elevada de casos de pruebas. Los componentes de MTest.search se pueden extender de forma independiente, sin tener que modificar el resto. La posibilidad de extensión e integración de estos componentes en diversos entornos de desarrollo, contribuye a elevar la eficiencia del proceso de aseguramiento de la calidad del producto de software en las empresas desarrolladoras de softwares.
En trabajos futuros se debe evaluar la efectividad de las suites de pruebas generadas para proyectos reales incluidos en bibliotecas internacionales, así como definir nuevos mecanismos para MTest.search, que permitan independizar la prueba unitaria de un método, esta propuesta podría basarse en la generación de objetos simulados.
V. Conclusiones
El presente trabajo facilita el proceso de pruebas durante el desarrollo de productos de software, contribuyendo al proceso de automatización de la etapa de diseño de casos de pruebas.
Los mecanismos propuestos para extender el modelo de reducción basado en búsquedas permiten a los desarrolladores, reutilizar los componentes desarrollados con anterioridad, e incorpora solamente en las extensiones los nuevos criterios de análisis a tener en cuenta para la generación de suites de prueba.
Muestra de ello, es la implementación de componentes de extensión que introducen la significación de valores y caminos/escenarios de la unidad específica a probar, a partir de criterios definidos.
Se desarrollaron componentes que garantizan el tratamiento de las variables de tipos de datos complejos objetos y conjuntos y pueden ser desplegadas en entornos productivos para tributar a la calidad del producto de software.

