










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
La detección de anomalías es una técnica de Minería de Datos con un amplio espectro de aplicaciones enfocadas en la seguridad social, como, por ejemplo: el análisis de redes informáticas y sociales, análisis de transacciones bancarias, y análisis de datos sensoriales, entre otros (Chandola et al., 2009; Kumar, 2005; Aleskerov et al., 1997; Fujimaki et al., 2005; Spence et al., 2001). Esta técnica permite el reconocimiento de patrones que no se comportan de la manera esperada en los datos (Kesavaraj and Sukumaran, 2013; Chandola et al., 2009). En una red informática, patrones de comportamiento inusual podrían significar que una computadora pirateada está enviando datos confidenciales a un destino no autorizado (Kumar, 2005). Diferentes comportamientos en los datos de transacciones con tarjetas de crédito podrían indicar el robo de identidad o de la tarjeta de crédito (Aleskerov et al., 1997). Las lecturas de comportamientos inusuales de un sensor de nave espacial podrían significar un error en algún componente de la nave (Fujimaki et al., 2005). Incluso al trabajar con imágenes médicas, un cambio abrupto en la intensidad de los píxeles en lugares inesperados, puede indicar la presencia de tumores malignos (Spence et al., 2001). Todos estos patrones que no siguen el funcionamiento esperado son conocidos como anomalías y su detección permite la prevención de nuevos ataques, malos funcionamientos, así como la detección a tiempo de tumores. En la Figura 1 se muestran varios de los campos donde se realiza la detección de anomalías.
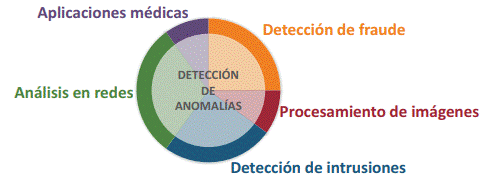
Entre los campos nombrados en la Figura 1, los más tratados son los de detección de fraude y detección de intrusiones, lo que los convierte en los de mayor interés para su análisis en este trabajo. La detección de fraude, según (Chandola et al., 2009), se refiere a la detección de actividades delictivas que ocurren en organizaciones comerciales como bancos, compañías de tarjetas de crédito, agencias de seguros, compañías de teléfonos celulares y mercado de valores, entre otros. La detección de intrusiones está enfocada en la detección de actividad delictiva (robos, hackeo, ataques informáticos, entre otros) en un sistema informático (Phoha, 2002). Ambos, detección de fraude y detección de intrusiones, pueden ser tratados de dos formas diferentes, detección de uso indebido y detección de anomalías (Javaid et al., 2016; Ahmed and Garcia, 2005; Aravindh et al., 2012). La detección de uso indebido solo puede identificar patrones de ataques ya conocidos mediante la correspondencia de reglas establecidas y patrones, mientras que la detección de anomalías aprende nuevos patrones de ataques basado en comportamientos normales (o anómalos) de los datos (Kwon et al., 2017; Yu et al., 2017b). Debido a la naturaleza cambiante de los ataques, en este trabajo, nos enfocamos en la detección de anomalías porque permite ajustarse a los cambios en los datos.
Las anomalías han sido definidas de diferentes formas por la comunidad científica a lo largo de los años (Dixon, 1950; Grubbs, 1969; Elashoff, 1972; Barnett and Lewis, 1978). En (Dixon, 1950), los autores refieren una anomalía como un valor que es dudoso a los ojos del analista. En (Grubbs, 1969), una anomalía se definió como una observación que parece desviarse notablemente de otros miembros de la muestra en la que ocurre. Elashoff (Elashoff, 1972) definió una anomalía como una observación que es extrema en algún sentido o viola el patrón aparente de las otras observaciones. Barnett (Barnett and Lewis, 1978) presentó una anomalía como una observación (o subconjunto de observaciones) que parece ser inconsistente con el resto de los datos. En (Hawkins, 1980), una anomalía se definió como una observación que se desvía tanto de las otras observaciones como para despertar sospechas de que fue generada por un mecanismo diferente. Otra definición de anomalía se presentó como un punto de datos que es significativamente diferente de los datos restantes (Aggarwal, 2017). Todas estas definiciones de anomalías comparten el mismo núcleo de funcionamiento. Por lo tanto, en este trabajo, utilizamos la siguiente definición genérica: una anomalía es una instancia de datos que contiene valores muy diferentes al resto del conjunto de datos analizado.
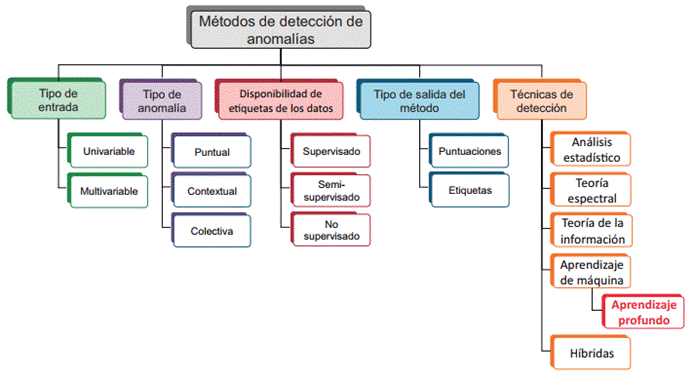
Los métodos de detección de anomalías pueden ser clasificados acorde a la naturaleza de la entrada, el tipo de la anomalía, el etiquetado de los datos, o el tipo de salida que devuelve el método (Chandola et al., 2009; Baddar et al., 2014). La entrada de estos métodos es una colección de instancias (objetos, registros, puntos, patrones, entre otros) (Tan et al., 2005) la cual puede ser univariable o multivariable (Chandola et al., 2009). Los tipos de anomalías son tres, puntuales, contextuales y colectivas (Chandola et al., 2009; Baddar et al., 2014; Parmar and Patel, 2017). Dependiendo del grado de disponibilidad de las etiquetas, los métodos de detección de anomalías también se pueden clasificar en uno de los tres modos siguientes: detección de anomalías supervisadas, semi-supervisadas y no supervisadas (Chandola et al., 2009). Otra forma pudiera ser según la forma de retornar la anomalía detectada, usualmente, se hace en forma de puntuaciones o etiquetas (Chandola et al., 2009). Por último, una de las clasificaciones más comunes es de acuerdo con las técnicas utilizadas para la detección de anomalías, tales como análisis estadístico, aprendizaje automático, teoría de la información y teoría espectral, entre otras (Chandola et al., 2009; Baddar et al., 2014). En busca de una mejor asimilación de lo antes mencionado, en la Figura 2 se muestra una distribución de las clasificaciones para los métodos de detección de anomalías.
Entre las técnicas de aprendizaje automático, el aprendizaje profundo ha tomado gran popularidad en la comunidad científica, debido a los muy buenos resultados alcanzados en disimiles temas como el procesamiento de imágenes, el procesamiento de rostros (Sun et al., 2014), dígitos (Lecun et al., 1998), texto (Jaderberg et al., 2014) y tipos de letras (Wang et al., 2015), así como en la detección de anomalías (Kwon et al., 2017; Kakanakova and Stoyanov, 2017; LeCun et al., 2015). Estas razones aumentan nuestro interés en el estudio y análisis del uso de esta técnica.
Los algoritmos basados en la técnica de aprendizaje profundo están motivados por el campo de la inteligencia artificial, y tratan de emular la habilidad cognitiva del cerebro humano (Najafabadi et al., 2016). Comúnmente estos algoritmos hacen uso de la estructura de datos conocida como red neuronal (Rumelhart et al., 1985), a la cual se le han realizado modificaciones creando nuevos tipos de redes destinadas a trabajar con diferentes tipos de datos o funcionalidades específicas. Entre estas nuevas estructuras podemos mencionar: los AutoEncoders (AEs), las Deep Neural Networks (DNN) (Goodfellow et al., 2016; Chollet, 2017; Bengio, 2009), las Restricted Boltzmann Machines (RBM) (Smolensky, 1986; Wang and Raj, 2017), las Deep Belief Networks (DBN) (Wang and Raj, 2017; Hinton et al., 2006), las Convolutional Neural Networks (CNN) (Wang and Raj, 2017; Hubel and Wiesel, 1962), y las Recurrent Neural Networks (RNN) (Wang and Raj, 2017). Aunque estas estructuras sean diferentes, todas son redes neuronales porque mantienen la estructura básica de neuronas, capas y conexiones entre neuronas utilizando funciones de activación lineales y no lineales. Estas redes trabajan con más de dos capas de profundidad (Patterson and Gibson, 2017) donde la combinación de varias capas de activación, representación y muestreo (pooling en inglés) permiten la extracción automatizada de representaciones de datos complejos a altos niveles de abstracción (Najafabadi et al., 2016; Bengio, 2009; Bengio et al., 2013; Bengio, 2013).
Las redes antes mencionadas, además de ser utilizadas por sí solas, pueden ser combinadas para un mejor comportamiento. Una de las estrategias más utilizadas es la GAN (de sus siglas en inglés Generative Adversarial Network) (Goodfellow et al., 2014), la cual consiste en vincular dos redes donde la salida de la primera es la entrada de la segunda. Usualmente la primera red es conocida como generador y la segunda como discriminador. La red generadora, provee datos en el espacio de los datos de entrenamiento y trata de confundir al discriminador el cual a su vez aprende a identificar las muestras falsas. Esta relación interactiva entre ambas redes logra una optimización simultánea a través de un juego de minimax para dos jugadores (en inglés twoplayer minimax game).
Por las razones antes mencionadas, este documento se enfocó en el estudio de los trabajos de detección de anomalías basados en la técnica de aprendizaje profundo, para los temas: detección de fraude y detección de intrusiones. Las contribuciones de este trabajo son una revisión del estado-del-arte de la detección de anomalía y un análisis crítico del mismo.
MATERIALES Y MÉTODOS
En esta sección se realiza un análisis de los trabajos más recientes relacionados a la detección de anomalías, específicamente la detección de fraude e intrusiones, que se basan en técnicas de aprendizaje profundo. Para esto se inicia con una breve explicación del funcionamiento de los métodos para la de detección de anomalías.
Un flujo de funcionamiento para los métodos de detección de anomalías parte de un conjunto de datos, los cuales son representados de la forma más adecuada para su análisis, llámese extracción de características. Con estas nuevas representaciones se hace el análisis de los datos y entrenamiento de los algoritmos para que sean capaces de discriminar entre datos anómalos y normales. Estos modelos entrenados son capaces de discriminar nuevos datos en un futuro. En la Figura 3 se muestra un ejemplo de este flujo de funcionamiento tomando como datos transacciones de tarjetas de créditos.
Detección de fraude
El fraude, de acuerdo a la Asociación de Examinadores de Fraude, se define como el uso de la propia ocupación para el enriquecimiento personal a través del uso indebido deliberado o la aplicación de los recursos o activos de la organización empleadora (Kou et al., 2004; Richhariya and Singh, 2012). También, el Concise Oxford Dictionary definió el fraude como un engaño criminal, el uso de representaciones falsas para obtener una ventaja injusta. Hay dos formas de combatir los fraudes: prevención de fraude y detección de fraude (Bolton and Hand, 2002; Sohony et al., 2018). La prevención de fraude consiste en un conjunto de medidas, reglas, procedimientos y protocolos para evitar que ocurran, cuando por otro lado, la detección de fraude consiste en identificar los fraudes lo más rápido posible cuando la prevención ha fallado y se han cometido fraudes (Bolton and Hand, 2002; Sohony et al., 2018). Existen varios tipos de detección de fraude que se han investigado, como detección de fraude con tarjeta de crédito, detección de fraude en teléfonos móviles, detección de fraude en reclamos de seguro, y detección de tráfico de información privilegiada (Chandola et al., 2009; Kou et al., 2004).
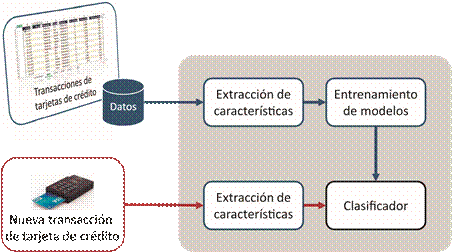
Fig.3 Flujo de un método de detección de anomalía tomando como datos transacciones de tarjetas de créditos.
Los AEs han sido de gran utilidad para la detección de fraude no supervisado, por lo que han sido utilizados en varios trabajos (Seng and Wong, 2017; Pumsirirat and Yan, 2018; Zheng et al., 2018b,a). En (Seng and Wong, 2017) se propuso un método basado en un enfoque de aprendizaje sensible a costos donde se utiliza un tipo de AE conocido como Stacked Denoising Autoencoders (SDAE) (Vincent et al., 2008) para identificar transacciones fraudulentas en un problema de detección de fraudes financieros. En este trabajo se realiza una básica selección de instancias en el paso de extracción de características teniendo en cuenta la cantidad de atributos no nulos de las transacciones. Además, introducen una modificación a la función de costo del SDAE con el objetivo de minimizar el costo de la clasificación errónea. De esta forma se identifican transacciones fraudulentas de manera eficaz y eficientemente. Los autores de (Pumsirirat and Yan, 2018) propusieron un método para la detección de fraude en tarjetas de crédito. Este método consiste en clasificar una petición de transferencia bancaria en tiempo real usando un AE, el cual se entrena teniendo en cuenta la información de transacciones realizadas con anterioridad. Los autores de (Zheng et al., 2018b) proponen 3 método para la detección de fraude en transacciones bancarias utilizando AEs. Entre las tres combinaciones la primera es un AE para la extracción de características y un clasificador tradicional y las otras dos AE-AE, AE-SDAE bajo la estrategia GAN, donde la primera red funge como extractora de características y la otra como el clasificador. En (Zheng et al., 2018a) se propone un método que usa un AE en el paso de extracción de características y siguen una estrategia GAN para la detección de fraude. En este trabajo se utiliza un AE para lograr una representación de los usuarios no maliciosos teniendo en cuenta la actividad de estos en línea (en inglés: online). Luego generan otra representación ficticia de usuarios no maliciosos mediante una DNN que se usa como la red generadora de la GAN. Finalmente, mediante otra DNN (conocida como la discriminadora de la GAN) aprende a identificar los usuarios no maliciosos reales. De esta manera al procesar los datos reales, el método es capaz de separar los usuarios no maliciosos del resto.
En (Fu et al., 2016) se propuso un Framework para la detección de fraudes de tarjetas de crédito. En este trabajo, los autores introdujeron un nuevo tipo de característica basada en la ganancia de entropía durante un período de tiempo. Usando esta característica de entropía y otras siete características tradicionales, los autores construyeron una matriz de características como resultado del paso de extracción de características. Debido al desbalance existente en los datos, en este trabajo se propone un método de muestreo, que resuelve este problema, basado en el repoblado de las transacciones. Este aumento de datos ponderados tiene como objetivo evitar el sobre entrenamiento de la red hacia solo un tipo de datos. Estas matrices de características se utilizan como entrada de una CNN, la cual tiene como objetivo clasificar las transacciones como anómalas o normales.
Otras de las redes utilizadas para la detección de fraude son las conocidas RBMs (Pumsirirat and Yan, 2018; Luo et al., 2017). El método propuesto en (Pumsirirat and Yan, 2018), utiliza una RBM para la clasificación de fraude en tarjetas de crédito. En este método se valida una petición de transferencia bancaria en tiempo real entrenando la RBM teniendo en cuenta la información de transacciones realizadas con anterioridad. Los autores del trabajo (Luo et al., 2017) realizan un estudio comparativo entre algunos métodos de clasificación tradicionales (regresión logística multinomial, perceptrón multicapa y máquina de soporte vectorial) y un método basado en DBN con un RBM. En este trabajo se mostró la superioridad en eficacia del método que utiliza RBM para la clasificación de fraudes crediticios.
En (Wang and Xu, 2018) se propuso un Framework para la detección de fraudes en seguros de autos mediante una combinación de una técnica de minería de textos basada en LDA (del inglés: Latent Dirichlet Allocation) (Blei et al., 2003), información de datos categóricos y datos numéricos, así como una DNN. En este framework se usa una técnica de segmentación de palabras para el procesamiento de los textos y un modelo LDA para la extracción de los tópicos de los textos segmentados. Con estos tópicos, información categórica y numérica se confeccionan las características que se le pasan a la DNN para que aprenda de estas. De esta manera se identifica si una reclamación de accidente de auto es fraudulenta.
Detección de intrusiones
La detección de intrusiones es uno de los retos más tratados en la seguridad de las redes en sistemas informáticos y su objetivo es la identificación de actividad inusual o ataques a la seguridad de redes internas (Kwon et al., 2017). Con este fin se han desarrollado sistemas de detección de intrusiones que proveen tempranas alertas ante intrusiones que permiten prevenir o minimizar el daño (Sultana et al., 2018; Hodo et al., 2017; Lee et al., 2018; Yan et al., 2018). Los daños pueden ser causados por cuatro tipos principales de ataques: DoS (del inglés: Denial of Service), Probe, R2L (del inglés: root-to-local) y U2R (del inglés: user-to-root) (Lee et al., 2018). Un ataque DoS consiste en sobresaturar todos los servicios y por lo tanto se deniegan todos los pedidos de acceso a la computadora. Un ataque de tipo Probe es cuando el atacante hace un escaneo de la computadora en busca de debilidades o vulnerabilidades que pudiera usar luego para comprometer el sistema. Un ataque R2L es cuando se envían paquetes desde una computadora remota a un usuario local con diferentes privilegios de uso para determinar la vulnerabilidad de la computadora local y colapsar los privilegios de acceso del usuario. Un ataque U2R es cuando el atacante comienza con una cuenta de usuario normal e intenta abusar de la vulnerabilidad del sistema para obtener privilegios de súper usuario.
Existen varios trabajos donde se proponen métodos para la detección de intrusiones basado en AEs (Javaid et al., 2016; Yu et al., 2017b; Farahnakian and Heikkonen, 2018). En (Javaid et al., 2016) se utilizan los AEs para la representación de los datos mediante las capas codificadoras de los mismos y así poder identificar ataques de tipo DoS. En este proceso de representación se propuso una modificación a los AEs profundos tradicionales, que consiste en la eliminación de la capa decodificadora. A estos AEs modificados los llamaron AEs profundos asimétricos (NDAEs, de sus siglas en inglés: Nonsymmetric Deep AutoEncoders). La estructura final del proceso de representación está formada por dos NDAEs en cadena utilizando como entrada del segundo NDAE la salida del primero. Luego de obtenida la representación de los datos utilizando la cadena de NDAEs anterior, se utiliza un clasificador tradicional (específicamente un Random Forest) para la identificación de las intrusiones. Los AEs también han sido usados para la detección de ataques de tipo U2R (Yu et al., 2017b). En este trabajo se utiliza los ya mencionados SDAEs para lograr una representación de los datos con baja dimensionalidad. Este SDAE se compone por tres AEs estructurados en cadena y entrenados previamente de manera no supervisada y posteriormente mediante un ajuste (en inglés: fine-tunning). Luego se utilizó un clasificador Softmax para identificar los ataques. De manera muy similar, en (Mighan and Kahani, 2018) se utiliza un SDAE para la representación reducida de los datos y luego mediante una máquina de soporte vectorial se realiza la clasificación de los ataques en redes de tráfico como PU-IDS Dataset (Singh et al., 2015). Los autores de (Farahnakian and Heikkonen, 2018) utilizan un AE profundo entrenado de manera glotona (en inglés: greedy) por capas para evitar el sobreajuste y los óptimos locales. De esta manera logran alta eficacia en la clasificación de los diferentes tipos de ataques.
Los trabajos (Roy et al., 2017; Kim et al., 2017b) muestran que también se pueden utilizar las redes del tipo DNN para la detección de intrusiones. En ambos trabajos se realizó un estudio del desempeño de este tipo de redes en el tráfico de una red física entre computadoras para la clasificación de cada uno de los tipos de intrusiones.
Otros trabajos parten del uso de las DBN para la detección de intrusiones (Zhao et al., 2017; Qu et al., 2017). En (Zhao et al., 2017) se reduce la dimensión de los datos mediante una representación obtenida con una DBN, en la cual se utiliza una cantidad óptima de neuronas para las capas ocultas. Esta cantidad de neuronas fue definida mediante el uso de un algoritmo genético basado en enjambre. De esta manera se mejora el rendimiento del proceso de aprendizaje de la red. Luego, haciendo uso de una red neuronal probabilística como clasificador se identifican cada uno de los tipos de ataques a una red. En (Qu et al., 2017) también se hace uso de una red DBN con un clasificador probabilístico al final, para la etapa del fine-tunning, que realiza la clasificación de los datos. La cantidad de neuronas en las capas ocultas y entrada-salida fueron determinadas en este trabajo de forma empírica.
Los autores de (Vinayakumar et al., 2017; Yu et al., 2017a) se basaron en las CNNs para la detección de intrusiones. En (Vinayakumar et al., 2017) se evaluó la efectividad de la combinación de las CNNs y métodos de modelado secuencial de datos en el análisis y clasificación de todos los tipos de ataques a una red. Específicamente se utilizaron las siguientes combinaciones: CNN-RNN, CNN-LSTM (de sus siglas en inglés: long-short term memory (Sak et al., 2014)) y CNN-GRU (de sus siglas en inglés: gated recurrent unit (Chung et al., 2014)). De estas combinaciones la que mayor rendimiento reportó una CNN-LSTM, con la CNN de tres capas ocultas. En (Yu et al., 2017a) proponen una variante de las CNN, que nombraron como AEs convolucional dilatado (DCA del inglés: Dilated Convolutional Autoencoders), donde aprovechan las ventajas de los Autoencoders apilados, del inglés Stacked Autoencoders y las CNNs. La idea de este trabajo es realizar la disminución y recomposición de los datos, conocido como una convolución y deconvolución. Esta red sustituye las capas de agrupamiento por una convolucional dilatada. Esta variante no necesita de datos etiquetados para el entrenamiento, por lo que posteriormente se le realizó un fine-tunning utilizando una capa con un Softmax para la clasificación en los diferentes tipos de ataques.
Las RNN también han sido usadas para la detección de intrusiones (Loukas et al., 2018; Yin et al., 2017; Tang et al., 2018). En (Loukas et al., 2018) se propone un método para la detección de intrusiones en vehículos robóticos basado en RNN. Los autores de este trabajo extienden la RNN tradicional mediante la sustitución de la función de activación por un LSTM para evitar la pérdida de información cuando el gradiente se acerca a cero. Mediante esta modificación RNN-LSTM se representan los datos y luego se utiliza un perceptrón multi-capa profundo como clasificador. De esta manera se identifican los ataques de tipo DoS, de inyección y malwares. Otro trabajo basado en RNN es el propuesto por Tang et al. (Tang et al., 2018), donde se combina una RNN con un método de modelado secuencial de datos (GRU). Haciendo uso del GRU-RNN son capaces de clasificar con alta eficacia los diferentes ataques de intrusiones realizados sobre una red de softwares. En (Yin et al., 2017) se utilizó una RNN como un clasificador sin modificación alguna a la misma para la detección de los diferentes tipos de intrusiones. Nuevamente en (Kim and Kim, 2015) combinan una red RNN con un modelo secuencial de datos el LSTM usando un optimizador de descendente de gradiente estocástico y luego esta combinación fue mejorada en (Kim et al., 2017a) utilizando la misma combinación, pero con un optimizador Nadam.
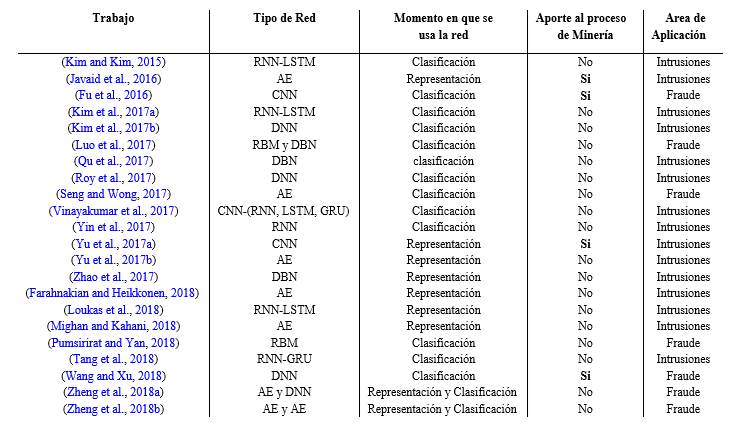
Finalmente, en la Tabla 1 se muestra un resumen comparativo de las características de los trabajos relacionados.
RESULTADOS Y DISCUSIÓN
El uso del aprendizaje profundo ha ganado importancia debido a su eficacia evaluando la seguridad de las redes. Esto ha permitido la inclusión de este tipo de aprendizaje en la mayoría de las aplicaciones de reconocimiento de patrones y minería de datos, mejorando considerablemente los resultados obtenidos con métodos tradicionales en diferentes tareas como la detección de anomalías. Además, cuando se desarrolla un método para la detección de anomalías existen varios retos a tener en cuenta debido a que la naturaleza de las anomalías es dinámica. Por lo que se necesita adaptabilidad en el método de detección, característica que está presente en las redes neuronales profundas.
En la literatura, como se describieron brevemente en la sección anterior, se han reportado numerosos trabajos donde se han dado evidencias del uso de los diferentes tipos de redes neuronales profundas para la detección de anomalías (Javaid et al., 2016; Yu et al., 2017b; Seng and Wong, 2017; Pumsirirat and Yan, 2018; Zheng et al., 2018b,a; Fu et al., 2016; Luo et al., 2017; Yu et al., 2017a; Farahnakian and Heikkonen, 2018; Mighan and Kahani, 2018; Roy et al., 2017; Kim et al., 2017b; Zhao et al., 2017; Qu et al., 2017; Vinayakumar et al., 2017; Loukas et al., 2018; Wang and Xu, 2018; Yin et al., 2017; Tang et al., 2018; Kim and Kim, 2015; Kim et al., 2017a). En estos trabajos se pudo observar el uso de las redes neuronales profundas para tareas como la reducción de dimensionalidad y/o la representación de los datos y además como clasificador para la detección de anomalías, ya sea como fraudes en redes bancarias o ataques de intrusiones en redes de tráficos de datos.
La mayoría de los trabajos, analizados en la revisión presentada en este reporte y resumidos en la Tabla 1, hacen uso de los AEs profundos tradicionales y sus variantes. En esta misma tabla se puede notar que los AEs en la detección de fraudes fueron mayormente usados para la clasificación de los datos ya que en la mayoría de los casos la clasificación es binaria; mientras que en la detección de intrusiones fueron utilizados para lograr una representación más compacta y robusta de los datos. Esto último se debe a que en la detección de intrusiones la clasificación es multi-clase y no está demostrado el buen uso de los AEs para este tipo de clasificación.
Por otro lado, se puede mencionar que la estrategia GAN ha sido poco utilizada a pesar de los buenos resultados que se logran con su uso. Esto se debe a la complejidad que conlleva su implementación y entrenamiento. Sin embargo, fue mostrado el uso de varios tipos de redes como en (Zheng et al., 2018b) donde se utiliza la combinación de un AE profundo y un SDAE; y en (Zheng et al., 2018a) se combina un AE con una DNN separando los usuarios no maliciosos de los que sí lo son.
Finalmente, con la excepción de los trabajos (Javaid et al., 2016; Fu et al., 2016; Yu et al., 2017a; Wang and Xu, 2018), no existe un aporte científico desde el punto de vista de la Minería de Datos en los trabajos analizados en este reporte (ver Tabla 1). El aporte de los autores en (Javaid et al., 2016; Yu et al., 2017a) está enmarcado en la propuesta de nuevas alternativas de redes para un tipo de ataque específico en la detección de intrusiones. En (Fu et al., 2016) el aporte está en la proposición de nuevas características basadas en entropía y en (Wang and Xu, 2018) el aporte está enfocado en la selección de tópicos para el procesamiento del lenguaje natural. El resto de los trabajos (Yu et al., 2017b; Seng and Wong, 2017; Pumsirirat and Yan, 2018; Zheng et al., 2018b,a; Luo et al., 2017; Farahnakian and Heikkonen, 2018; Mighan and Kahani, 2018; Roy et al., 2017; Kim et al., 2017b; Zhao et al., 2017; Qu et al., 2017; Vinayakumar et al., 2017; Loukas et al., 2018; Yin et al., 2017; Tang et al., 2018; Kim and Kim, 2015; Kim et al., 2017a) solo proponen nuevas configuraciones obtenidas empíricamente para la optimización de las redes sobre los tipos de datos analizados.
CONCLUSIONES
En este reporte se presenta una revisión de los métodos reportados para la detección de anomalías, específicamente detección de fraudes e intrusiones, basados en aprendizaje profundo y se enfatiza en el aporte científico brindado por estos métodos en el proceso de la detección de anomalías. En esta revisión se categorizaron los métodos reportados según el tipo de DNN usada. Esta categorización permitió identificar que los AEs profundos han sido los más usados, tanto para la representación de los datos como para la clasificación de los diferentes tipos de anomalías. Además, se encontraron evidencias de la aplicación exitosa de todas las redes neuronales profundas actuales en tareas de detección de anomalías. Sin embargo, según la discusión realizada en este reporte, se puede llegar a la conclusión de que aún queda mucho por hacer e investigar para lograr un aporte significativo en la minería de datos, específicamente en la detección de anomalías, mediante el uso del aprendizaje profundo. Esto se debe a que solo unos pocos métodos aportan mejoras en el proceso de minería, más allá del uso directo de las redes neuronales profundas y sus configuraciones.
Por otro lado, no se encontró en el estado del arte un trabajo como este reporte, que realizara una revisión sobre la detección de anomalías basada en aprendizaje profundo desde el punto de vista de minería de datos. Por este motivo, se considera que mediante este reporte se brinda información valiosa que puede tomarse como guía para nuevas investigaciones sobre el tema.

