










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El esfuerzo es una combinación de persona y tiempo. Se refiere a la cantidad de tiempo que una persona necesitaría para completar cierto trabajo productivo (Avellaneda, 2017). En el caso de proyectos de software su estimación juega un papel importante en la calidad y el éxito de su desarrollo (Rekha y Dr. P. K., 2017). Determinar el esfuerzo requerido para llevar a cabo una tarea, es parte de todo el proceso de desarrollo del software. Por tal motivo el uso de valoraciones o métodos formales, basados en la experiencia de los miembros del equipo, juegan un papel importante en este proceso (Méndez, 2018). Dado que las empresas desarrolladoras de software se mueven en un mundo globalmente competitivo, es crucial lograr una estimación precisa de sus proyectos (Matel et al., 2019). Con el avance de la tecnología, la tendencia para lograr una mayor exactitud ha sido combinar diferentes métodos de estimación, apelando a técnicas de inteligencia artificial tales como la lógica difusa, sistemas basados en conocimiento, programación genética y redes neuronales artificiales (Yousef, Alshaer y Alhammad, 2017; Saruwatari et al., 2019; Saini, Ahuja y Khatri, 2018; Sharma y Chaudhary, 2020).
Las redes neuronales artificiales (RNA) imitan la operación básica del cerebro. La información viaja entre las neuronas y, basada en la estructura y ganancia de los conectores neuronales, la red se comporta de manera diferente. En estas redes, cada neurona está conectada con otra por medio de un peso o coeficiente de ajuste (Arnal, 2018; Nielsen, 2018).
El procedimiento de entrenamiento de una RNA consiste en iterativamente suministrar a la red una secuencia de patrones de entrada, y ajustar los pesos de las conexiones en función de las salidas obtenidas. Se distinguen tres categorías de aprendizaje: Aprendizaje supervisado, por refuerzo y no supervisado, estos a su vez utilizan una variedad de algoritmos, dependiendo de la información que se posea sobre los patrones de entrada (Aggarwal, 2019). Las principales ventajas de las redes neuronales artificiales son: su capacidad de generalización, que permite dar una respuesta adecuada a entradas nunca vistas anteriormente; su naturaleza distribuida, que permite la construcción de sistemas eficientes; su capacidad de aproximar funciones no lineales, que resuelven problemas no complejos y su adaptabilidad frente a cambios en el entorno (Asanza y Olivo, 2018).
En los últimos años las ventajas que ofrecen las RNA han sido aplicadas con éxito en campos de la ciencias, tales como: la aeroespacial para los sistemas de control en los aviones (Altun y Efe, 2019); en la automoción, para sistema de frenados automático y sistemas de guiados para automóviles (Raveendran et al. , 2019); en la defensa para el guiado de misiles (Diwani, Chougule y Mukhopadhyay, 2020); en la electrónica y automática para el control de procesos y diseños de circuitos integrados (Rosa, 2018); en las finanzas para la predicción de la rentabilidad de las acciones (Wong et al., 2021); en la medicina para la ayuda en el diagnóstico de enfermedades (Khan et al., 2019; Swietlik y Bialowas, 2019); en la robótica para el control de trayectorias (Bozek et al., 2020), entre otros. En el caso del desarrollo del software son diversos los trabajos vinculados a las RNA para la estimación del costo y esfuerzo. Para proyectar el costo, (González, 2017) realiza una revisión de diferentes técnicas para la predicción en diversos proyectos. (Dhanopiya et al., 2017) utilizan una RNA multicapa y (Venkataiah, Mohanty y M. Nagaratna, 2018) usa una RNA de tipo Spiking, para operar en la misma dirección. En el ámbito de la estimación del esfuerzo constituyen un prolífico campo de estudio. Este trabajo tiene como objetivo demostrar la eficiencia del uso de las RNA cuando es aplicada a la estimación del esfuerzo mediante una revisión de la bibliografía.
DESARROLLO
La investigación realizada sigue la ruta cuantitativa con un enfoque descriptivo según (Hernandez-Sampieri y Torre, 2018). Se realizó una revisión sistemática de la literatura siguiendo la metodología propuesta por (García-Peñalvo, 2019). En este sentido, se recopilaron artículos en inglés y español del periodo comprendido del 2016 al 2020, publicados en revistas indexadas en Springer, Scopus, IEEE y ELSEVIER. El proceso de selección estuvo dado por las siguientes características: artículos centrados en la estimación del esfuerzo en proyectos de software empleando RNA; poseen en común un conjunto de datos (dataset) de proyectos como entradas, de modo que se pueda realizar una comparación del resultado del empleo de RNA utilizando combinaciones de algoritmos para su entrenamiento y aprendizaje; como criterios de evaluación los artículos debían reflejar al menos la magnitud del error relativo (MRE), la magnitud media del error relativo (MMRE) o la mediana del error relativo (MdMRE), y estos valores ser relativamente bajos.
Como resultado del proceso de selección se analizan 5 estudios (Rijwani y Jain, 2016), (Rao, Reddi y Rani, 2017), (Azath, Mohanapriya y Rajalakshmi, 2018), (Kaushik y Singal, 2019) y (Kodmelwar, Joshi y Khanna, 2018), que demostraron la eficiencia en la estimación del esfuerzo haciendo uso de las RNA.
El estudio 1, propone un modelo basado en una RNA Multi Layered FeedForward (MLFFN) entrenada con el algoritmo Back Propagation (BP). Utiliza como entrada 63 proyectos del dataset de COCOMO II, la salida es el esfuerzo de desarrollo medido en meses-hombre. Los criterios para la evaluación se basaron en los resultados MRE y MdMRE. Se eligieron 13 proyectos de manera aleatoria para la realización del experimento (Rijwani y Jain, 2016). El resultado muestra una significativa reducción del error relativo con la propuesta, Tabla 1.
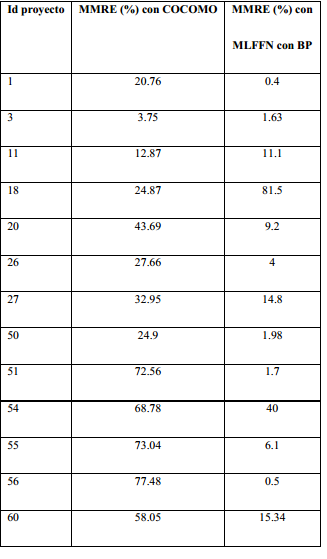
El estudio 2, hace uso de un algoritmo híbrido que combina los principios del algoritmo Colonia de abejas artificiales (ABC por sus siglas en inglés) con los procedimientos de búsqueda local para estimar el esfuerzo, y como red neuronal la MultiLayer Perceptron Neural Network (MLPNN). Para la evaluación se toman 63 proyectos del dataset de COCOMO81 y fueron descritos para la medición 16 atributos. Los atributos fueron transformados utilizando Análisis del Componente Principal (PCA) (Rao, Reddi y Rani, 2017). Los criterios para la evaluación se basaron en los resultados del MMRE y MdMRE. En un inicio y para comparar la eficiencia de la técnica híbrida se hicieron experimentos con diversas técnicas sin el uso de la red, y luego se aplicó el protocolo propuesto. El resultado se muestra la Tabla 2.

La propuesta de optimización del método híbrido para valores MMRE muestra mejores resultados que las otras técnicas, y supera en gran medida los valores de SVM-RBF por 37.34% y a la RNA propuesta por 4.52 %. Sucede igual para valores de MdMRE superando a la técnica SVM-RBF por 21.45% y a la RNA por 0.99%.
El estudio 3, utiliza una clusterización media difusa modificada para los dataset. Una vez realizada la clusterización, se obtienen varias reglas que son ofrecidas como datos de entrada. La red neuronal se optimiza empleando los algoritmos artificiales ABC, cuckoo search (MCS) modificado y el algoritmo híbrido ABC-MCS. Los conjuntos de datos o dataset utilizados pertenecen a Desharnais, COCOMO 81, NASA 60, y NASA 93. NASA60 incluye 60 proyectos con 17 variables autónomas y 15 incondicionales. NASA93, incluye 93 proyectos, 17 variables autónomas y 15 incondicionales. Desharnais, incluye 81 proyectos, 9 variables independientes y 1 dependiente. COCOMO81, incluye 81 proyectos, 17 atributos y 63 instancias (Azath, Mohanapriya y Rajalakshmi, 2018).
Las Figura 1 y Figura 2 muestran los resultados de MMRE y MARE (error relativo medio absoluto) para uno de los dataset y el comportamiento del MMRE de otros métodos en comparación con la propuesta para distintos dataset respectivamente. Las imágenes demuestran la eficiencia del método propuesto en la optimización de la red neuronal para la estimación del esfuerzo.

Fig. 1 Representación gráfica del valor MMRE y MARE después de la optimización para los dataset de Desharnais.

El estudio 4, propone una técnica no algorítmica para la estimación del esfuerzo. Consiste en un modelo híbrido de una red neuronal Wavelet con un algoritmo metaheurístico que combina el algoritmo luciérnaga (FA) y el algoritmo de murciélago (bat). Como función de activación se utilizan 2 variantes: Morlet y Gaussian. Los dataset de China, Maxwell, COCOMO81 y NASA93 son utilizados para evaluar la tecnología propuesta (Kaushik y Singal, 2019). En Maxwell hay 62 proyectos, cada uno con 26 características. COCOMO tiene 63 proyectos y 93 proyectos en la NASA93. Como resultado de las diferentes variantes se obtuvo que para los dataset de COCOMO81, la red Wavelet con el algoritmo bat usando las funciones de activación arriba descritas, tiene un buen rendimiento y supera las otras combinaciones para los valores de MMRE y MdMRE. Para los dataset NASA93 y Maxwell los valores de MMRE son efectivos para la combinación Wavelet con FA. Para el dataset CHINA la combinación Wavelet con FA fue eficiente para ambos criterios. La Figura 3 muestra los resultados relevantes. Se concluye que el uso de metaheurísticas para la red Wavelet es eficaz, pero no se puede determinar qué algoritmo es el mejor para distintos tipos de datos.
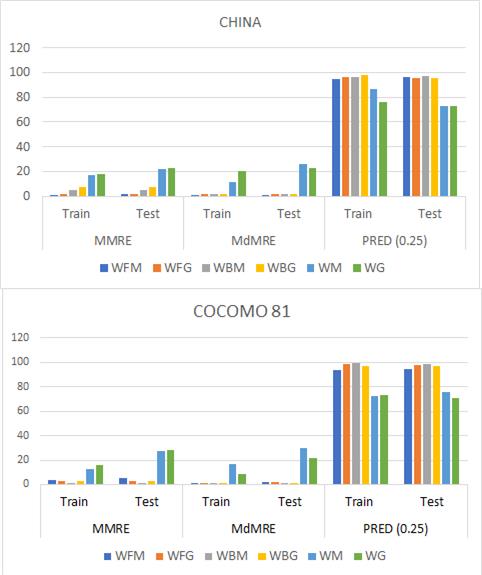
Fig. 3 Comparación de valores MMRE y MdMRE de técnicas diferentes para los dataset de COCOMO81 y CHINA (Estudio 4).
El estudio 5, propone una RNA de tipo Deep learning modificada (DeepMNN) para la estimación eficiente del esfuerzo. Se utiliza el dataset de COCOMO. La red es entrenada utilizando el algoritmo de búsqueda cuckoo search (Kodmelwar, Joshi y Khanna, 2018). El proceso de optimización es ejecutado mientras se seleccionan los pesos, lo que ayuda a mejorar la clasificación del modelo. Se toman 50 instancias para la evaluación, los resultados fueron obtenidos después de la adición de 10 instancias. El resultado se muestra en la Figura 4 para valores de MRE, MMRE, PRED (porcentaje de predicción) y Error relativo, demostrando la efectividad de la propuesta.

RESULTADOS Y DISCUSIÓN
En los estudios abordados en el artículo, se describen algoritmos que permiten la optimización de RNA para la estimación del esfuerzo en proyectos de desarrollo de software. Su eficiencia depende del tipo de arquitectura, el entrenamiento y aprendizaje de la red. Para los ejemplos anteriores, los mejores resultados se obtuvieron a partir del uso de métodos híbridos como muestra la Figura 5.

Fuente: Elaboración Propia.
A pesar de las ventajas que ofrecen las RNA, los resultados muestran que una arquitectura no funciona igual para diferentes conjuntos de datos de entrada. Sin embargo, el uso de algoritmos de optimización basados en el comportamiento de insectos y animales de la naturaleza como ABC, FA, MCS y bat, presentados en el artículo, permiten resolver de manera eficaz problemas complejos como la estimación en proyectos de desarrollo, no solo en la industria del software sino en otros campos de la ciencia mencionados anteriormente.
CONCLUSIONES
Existen en la literatura diversos trabajos relacionados con la estimación del esfuerzo en proyectos de desarrollo de software que emplean RNA. La presente investigación enfatiza en el uso de modelos híbridos para su optimización, aportando una sistematización novedosa en este campo. Este tipo de estudio continúa siendo de interés en el ámbito de la industria de software y la comunidad científica, para lograr precisión en las estimaciones tempranas durante la planificación.
Aunque los modelos paramétricos todavía desempeñan un papel importante, se destaca la tendencia hacia el estudio de las RNA. Los artículos estudiados ponen de manifiesto que, si bien persisten reservas en la precisión de las estimaciones, se aprecian mejoras significativas en este sentido. Los algoritmos de optimización ABC, FA, MCS, bat y BP para el aprendizaje de las RNA, son idóneos y pueden tomarse como referencia para futuras investigaciones, debido a que los valores de MRE, MdMRE y MMRE son bajos y la tasa de exactitud para la estimación es alta.
Los métodos descritos en el artículo resultarán útiles en la estimación del esfuerzo de nuevos proyectos, considerando las características del software y el equipo del proyecto. Esto reducirá la probabilidad de que se produzcan retrasos en los plazos de entrega, y propiciará la satisfacción de los clientes. Este trabajo constituye un punto de partida para el desarrollo de nuevas técnicas de estimación empleando RNA y algoritmos híbridos, dado que la reducción de la incertidumbre en las estimaciones se sostiene como un objeto de estudio para la planificación en la gestión de proyectos.

