










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La diabetes es una enfermedad crónica que afecta actualmente a más de 425 millones de personas a nivel mundial y se prevé que este número aumente considerablemente en los próximos 25 años (Cho et al., 2018). La enfermedad se debe a problemas en el páncreas para sintetizar la insulina necesaria que el cuerpo necesita, lo que provoca un gran número de complicaciones en los pacientes. Una de las complicaciones más graves es la úlcera del pie diabético (DFU) (Armstrong, Boulton y Bus 2017). La DFU se caracteriza por una disfunción celular y un desequilibrio bioquímico, cuya principal manifestación es el retraso del proceso de cicatrización. Esto puede dar lugar a infección e isquemia, pudiendo provocar la amputación de la extremidad donde se encuentra la lesión, y en los casos más graves conducen incluso a la muerte del paciente.
En la actualidad se trabaja para mejorar la atención a los pacientes y reducir la presión sobre los sistemas sanitarios. Para ello, la detección temprana de las DFU y el seguimiento regular constituyen una tarea primordial., Dentro de las estrategias utilizadas para estos fines aparece una basada en técnicas de visión por computadora. Las investigaciones recientes se han centrado en la creación de algoritmos de detección que podrían utilizarse como parte de una aplicación móvil que capacite a los propios pacientes o a un cuidador/pareja en este sentido (Goyal et al., 2019). Estas técnicas han sentado las bases para crear los primeros conjuntos de imágenes de paciente con DFU a ser usados en tareas de visión por computadora. Los principales esfuerzos se han realizado en la identificación de las lesiones y la segmentación de las mismas, sobre todo a partir del DFU Challenge 2020 (Cassidy et al., 2021; Yap et al., 2020).
Por otro lado, el tema de la clasificación automática de estas imágenes ha sido menos abordado, razón por la cual se lanza el reto DFUC2021 . Es decir, solo se reportan escaso trabajos que realizan clasificación de las lesiones de DFU. Por ejemplo, en el trabajo de (Goyal, Reeves, Davison, et al., 2020) se propone una nueva arquitectura de CNN para abordar un problema de clasificación binaria de las lesiones en normal y anormal., Se compararon además otras CNN pre-entrenadas como LeNet, AlexNet, GoogleNet así como otras variantes de métodos de extracción de rasgos como Local Binary Pattern (LBP), Histogram of Oriented Gradient (HOG) y basados en color usando los espacios RGB, HSV y LUV. Por otro lado, en (Goyal, Reeves, Rajbhandari, et al., 2020) es la primera vez que se intenta clasificar en isquemia e infección, pero en tareas disjuntas. Es decir, se evalúan dos tareas de clasificación automática binarias. Para ello se utilizó un nuevo descriptor basado en el color de las imágenes luego de aplicar una segmentación usando SLIC Superpixel. Además, se utilizaron rasgos basados en textura como LBP y HOG, así como rasgos basados en el color en los espacios RGB y CIELAB. También se evaluaron distintas arquitecturas de redes neuronales de convolución (CNN) como InceptionV3, ResnNet50 e InceptionResNetV2. Los mejores resultados se alcanzaron usando la combinación de las CNN. Recientemente en (Yap et al., 2021), por primera vez se realiza la clasificación como un problema multiclase. Las clases fueron infección, isquemia, ambas y nada. Este problema se abordó utilizando solamente el enfoque de aprendizaje profundo. Para ellos se evaluaron las redes VGG16, ResNet101, InceptionV3, DenseNet121 y EfficientNet. Los mejores resultados se alcanzaron para las dos últimas redes antes mencionadas utilizando técnicas de aumento de datos. Se reporta un macroF1score de 0.55, una precisión de 0.57 y una sensibilidad de 0.58. Más recientemente en el trabajo de (López-Cabrera et al., 2021) se obtuvieron mejores resultados. En dicho estudio se exploraron distintas estrategias de extracción de rasgos, basadas en color, basadas en el descriptor SURF (Bay, Tuytelaars y Van Gool 2006) y usando la red DenseNet201 como método de extracción de rasgos. Se reportó un macroF1score máximo de 0.681 para un clasificador SVM.
Tomando como referencia el trabajo de (López-Cabrera et al., 2021) en el cual se analizó el papel que juegan por separado las distintas estrategias de extracción de rasgos en la tarea de clasificación. En este artículo, se explora la combinación de estas estrategias de extracción de rasgos para la clasificación automática en cuatro clases de imágenes de DFU. Se investigan la fusión a nivel de rasgos y a nivel de decisión. La fusión a nivel de rasgos combina diferentes vectores de rasgos en un único vector de rasgos. Por otro lado, la fusión a nivel de decisión se realiza sobre los resultados probabilísticos de cada proceso de clasificación individual y combina las distintas decisiones en una final., Asimismo, se exploran dos estrategias de selección de rasgos para obtener aquellos que arrojen los mejores resultados. Según nuestro conocimiento este es el primer estudio que reporta la combinación a distintos niveles, como métodos para la clasificación de imágenes DFU. De esta manera, los resultados obtenidos sobrepasan los reportados en la literatura.
Materiales y Métodos
Conjunto de imágenes usados
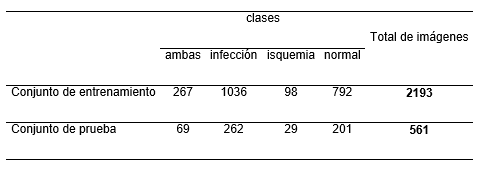
Las imágenes usadas en esta investigación son fotografías recopiladas de los Hospitales Docentes de Lancashire, Reino Unido y pertenecen a pacientes con DFU. Una descripción más detallada sobre el conjunto aparece en (Yap et al., 2021). A partir de la imagen original se extraen las regiones de interés (ROIs) que se corresponden con las lesiones encontradas. En el propio proceso de extracción de las ROIs se realiza un aumento natural del conjunto de imágenes. Este proceso consistió en recortar las imágenes en distintos tamaños. Finalmente, todas las imágenes fueron redimensionadas a 224x224x3 píxeles. Este conjunto de imágenes pertenece a DFUC2021. Es importante señalar que, en esta investigación solamente se utilizará una porción del conjunto de entrenamiento proporcionado para el DFUC2021, pues hasta el momento este conjunto es el único que contiene la clase a la que pertenece cada imagen. Es decir, el conjunto de validación y prueba aún no ha sido liberado. La Tabla 1 muestra el contenido del conjunto de imágenes utilizado en este trabajo. Se dividió aleatoriamente las imágenes por clase en aproximadamente un 80% para el entrenamiento y un 20% para la prueba. De esta forma, se utilizó como hold out estrategia para la evaluación de los clasificadores. El conjunto de imágenes contiene las mismas particiones que las utilizadas en (López-Cabrera et al., 2021).
Técnicas de extracción y codificación de rasgos
En este estudio se utilizan tres estrategias para la extracción de rasgos, las cuales coinciden con el trabajo de (López-Cabrera et al., 2021). La primera se basa en el color, pues en los trabajos de (Goyal, Reeves, Rajbhandari, et al., 2020; Goyal, Reeves, Davison, et al., 2020) se han usado con éxito variantes de conversión entre espacios de color como rasgos para realizar la clasificación. La segunda variante se basa en la extracción de rasgos locales. Para ello se utilizó el método SURF (Bay, Tuytelaars y Van Gool, 2006), el cual es uno de las más ampliamente usado en tareas de clasificación de imágenes (Arora et al., 2020). Estas dos primeras variantes se basan en rasgos diseñados a mano (handcrafted), mientras la tercera variante se basa en la CNN, DenseNet201 (Huang et al., 2019).
Las dos primeras variantes de extracción de rasgos poseen alta dimensionalidad. Una de las técnicas para abordar este problema que ha mostrado aumentar los índices de desempeño en las tareas de visión por computadora es Bag of Word (BoW) (Fei-Fei, Fergus y Perona, 2006). En este estudio se utilizó un vocabulario visual de 1000 palabras, el cual arrojó los mejores resultados luego de un pequeño experimento variando las palabras entre 500 y 1500.
Algoritmos de clasificación y medidas de desempeño.
En la etapa final de este estudio se realiza la clasificación automática de las imágenes. Para ello se evalúan tres variantes del clasificador SVM los cuales han mostrado buenos resultados en tareas genéricas de clasificación (López-Cabrera y Pereira-Toledo, 2018), así como en tareas similares de clasificación de imágenes de DFU (López-Cabrera et al., 2021). Es decir, se utilizaron tres kernel, el cuadrático, el gaussiano y el lineal.
El conjunto de imágenes que se utiliza en la investigación tanto para entrenamiento como para validación, está desbalanceado. Por tanto, para determinar la efectividad de los clasificadores se deben usar medidas de desempeño que tengan en cuenta este problema y poder realizar un análisis por clases. En aras de comparar nuestros resultados con los obtenidos en (Yap et al., 2021; López-Cabrera et al., 2021), se decidió utilizar algunas de las mismas medidas usadas en estos estudio. Por tanto, se utilizó el F1score por clase, así como su promedio, llamado macroF1score. Además, se utiliza el macroAccuracy como métrica global.
Estrategias de fusión y métodos de selección de rasgos
En este estudio se investigan dos estrategias de fusión, a nivel de rasgos y a nivel de decisión. La primera variante de fusión es una de las más usadas en tareas de clasificación de imágenes (Pereira et al., 2020). Esta consiste en agrupar diferentes técnicas de extracción de rasgos en un solo conjunto, el cual se utiliza como entrada a un algoritmo de clasificación. Sin embargo, esta estrategia puede presentar como desventaja que al combinar múltiples conjuntos de distinta naturaleza (color, textura, etc) se presenten incompatibilidades al generar un espacio de rasgos altamente no lineal., Asimismo, al realizar la unión de varios conjuntos de rasgos, el conjunto final aumenta su cardinalidad. La alta dimensionalidad en los conjuntos de rasgos deteriora la efectividad de los clasificadores (Keogh y Mueen, 2017), así como eleva el costo computacional del mismo en la etapa de entrenamiento.
Para contrarrestar este efecto, se analiza el efecto de dos métodos de selección de rasgos (FSM). Estos métodos pretenden de forma general, seleccionar un subconjunto de los rasgos pertenecientes al conjunto original, que logre el máximo rendimiento con el mínimo esfuerzo en las tareas de clasificación. Uno de los principales problemas al aplicar FSM es seleccionar un método apropiado para un problema dado. Cada FSM tiene sus fortalezas y debilidades, siendo su desempeño dependiente de los datos y de restricciones propias relacionadas con el escenario donde serán usados (exactitud, tiempo, costo). No obstante, a pesar de la disponibilidad y el incremento de estos métodos, los investigadores concuerdan que no existe uno ideal para todos los escenarios. Por tanto, en este estudio se seleccionan dos de los métodos que reportan muy buenos resultados en la literatura científica (Bolón-Canedo y Remeseiro, 2019).
El primer FSM usado fue ReliefF (Kononenko, 1994). Este evalúa la calidad del atributo muestreando repetidamente casos y determinando el valor del atributo dado usando los vecinos más cercanos de su clase y de otras clases. A partir de esto se le asigna un peso a cada rasgo. De esta forma, un rasgo útil debe diferenciar entre casos de diferentes clases y tener valores similares para casos de la misma clase. La segunda variante de FSM fue MRMR (Minimum Redundancy Maximum Relevance) (Peng, Long y Ding, 2005). El método se basa seleccionar rasgos que tengan alta relevancia con respecto a su clase y sean mínimamente redundantes. Se seleccionan los rasgos que sean lo más disimilares posible entre ellos. Para realizar la optimización del conjunto con máxima relevancia y mínima redundancia se utiliza información mutua.
Ambos FSM devuelven un peso para cada rasgo, que indica su relevancia. Es decir, los rasgos aparecen ordenados en dependencia del criterio utilizado. Por tanto, es necesario establecer un umbral para determinar la cardinalidad del conjunto final., Encontrar este valor no es trivial y varias han sido las heurísticas estudiadas por distintos autores que abordan el tema, sin que exista un consenso (Bolón-Canedo y Alonso-Betanzos 2018). Por tanto, en este estudio se evaluarán conjuntos de rasgos que incrementen su cardinalidad de 100 en 100.
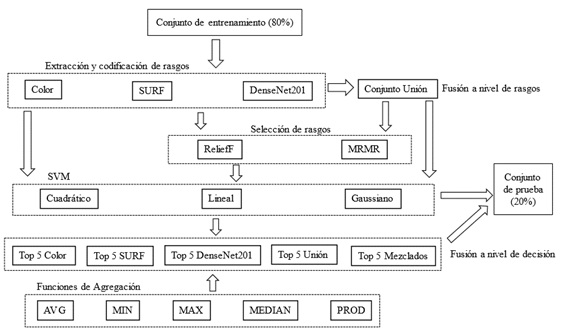
Por otro lado, la fusión a nivel de decisión se realiza sobre los resultados probabilísticos de cada proceso de clasificación individual y combina las distintas decisiones en una final (Snoek, Worring y Smeulders 2005). Esta estrategia puede lograr resultados prometedores en escenarios en los que hay complementariedad entre las salidas (Kittler et al., 1998). En estos casos, los clasificadores no hacen la misma clasificación errónea y, por lo tanto, cuando se combinan, pueden ayudarse mutuamente para mejorar la predicción. En este estudio se hace uso de cinco funciones de agregación simple, ampliamente utilizadas en la literatura científica (Kuncheva 2014). Estas fueron, promedio (AVG), mínimo (MIN), máximo (MAX), mediana (MED) y producto (PROD). El cálculo de estas medidas se realiza a partir de los valores de probabilidad a posteriori que devuelven los clasificadores y que se interpretan como la pertenencia de una imagen a una clase. El proceso general de la estrategia de reconocimiento de patrones seguida en la investigación aparece en la Figura 1.
Resultados y discusión
En esta sección se presentan los resultados alcanzados para las mejores variantes de métodos de extracción de rasgos.
Rasgos basados en CNN
La Figura 2 presenta los resultados obtenidos usando como método de extracción de rasgos a DenseNet201. Esta red devuelve un total de 1920 rasgos. En el eje de las abscisas se muestra el número de rasgos usados para realizar la clasificación. Los mejores resultados se obtienen para el conjunto de 800 rasgos seleccionados por ReliefF y usando el kernel Gaussiano con 0.7314 de macroF1score. Por otro lado, al usar el FSM MRMR se alcanzan también mejores resultados que al usar el conjunto completo de rasgos. Para este FSM el mejor valor de macroF1score aparece para el clasificador SVM Gaussiano con 0.7221 con 500 rasgos.
Fusión a nivel de rasgos
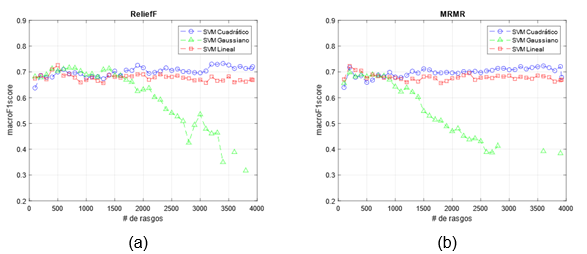
En esta etapa se realiza la unión de los conjuntos de rasgos. Ahora se cuenta con un nuevo conjunto de rasgos que posee 3920 rasgos. De ellos 1000 pertenecen a los rasgos de color, 1000 a los rasgos SURF y 1920 a los rasgos de DenseNet201. La Figura 3 presenta los índices de desempeños alcanzados para los tres clasificadores al realizar la selección de los mejores rasgos usando las dos variantes de FSM. El mejor valor de macroF1score fue de 0.7326 usando el FSM ReliefF y el clasificador SVM con kernel Cuadrático con 3400 rasgos. Nótese que para el clasificador SVM Gaussiano aparecen conjuntos de rasgos para los cuales está indefinida la medida macroF1score (espacios en blanco en la Figura 3). Esto se debe a que la medida F1score se indefine, al tener en el denominador a precision y recall.
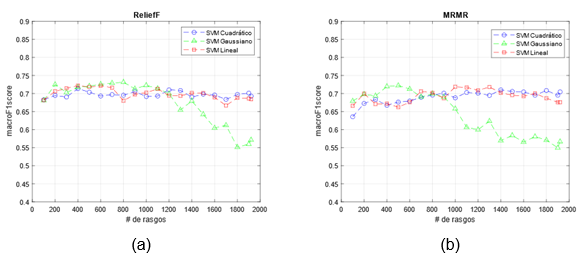
Fig. 2 Resultados para las tres variantes de SVM usando conjuntos de rasgos basados en DenseNet201. En (a) utilizando el FSM ReliefF y en (b) MRMR.
Fusión a nivel de decisión
La Tabla 2 presenta los resultados alcanzados para las distintas estrategias de fusión a nivel de decisión. En esta etapa se seleccionaron los 5 mejores clasificadores para cada una de las distintas estrategias de evaluadas en las secciones anteriores, usando como medida el macroF1score.
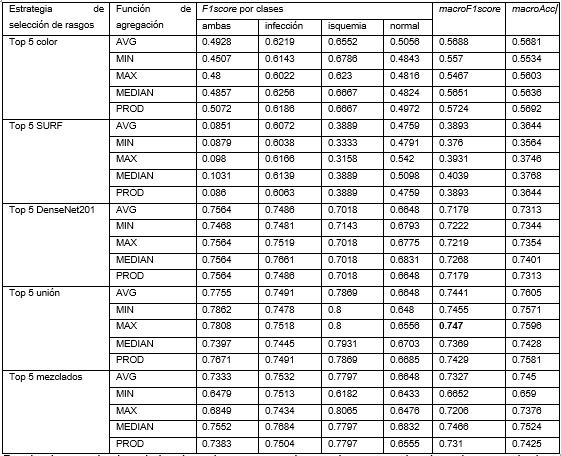
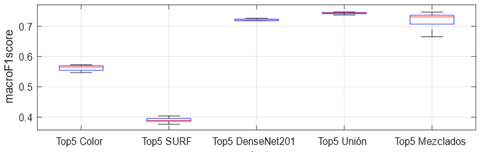
Desde el punto de vista de los tipos de rasgos usados se observa que los de mejores resultados se reportan en este orden, Top 5 unión, Top 5 mezclados, Top 5 DenseNet201, Top 5 color y Top 5 SURF (ver Figura 4).
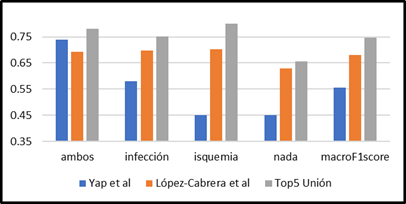
Comparación con los métodos reportados en la literatura
La Figura 5 presenta una comparación con los trabajos reportados en la literatura (López-Cabrera et al., 2021; Yap et al., 2021) y la mejor variante reportada en esta investigación. Se aprecia que, el método propuesto supera tanto en F1score por clases como en macroF1score a los resultados reportados en trabajos anteriores. Esto demuestra que la combinación de la estrategia de fusión a nivel de rasgos y luego a nivel de decisión dotan a este modelo de mejor desempeño en la tarea de clasificación automática de imágenes DFU.
Conclusiones
En este estudio se realizó el análisis de varias estrategias de fusión de rasgos para aumentar los índices de desempeño en la clasificación automática de imágenes DFU. Se demostró que el uso de los FSM en todos los casos aumentó el desempeño de los clasificadores. Asimismo, la estrategia de fusión a nivel de rasgos logró aumentar los índices de desempeño comparada con las estrategias individuales y combinadas con los FSM. Por otro lado, los mejores resultados se obtuvieron para la estrategia de fusión a nivel de decisión. Específicamente la combinación de clasificadores basados en la estrategia de fusión a nivel de rasgos fue la de mejores resultados. Este resultado sobrepasa los resultados reportados hasta el momento en tareas similares a esta.

