










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La precipitación es uno de los elementos climáticos que más influye sobre la naturaleza y su configuración. Su distribución temporal y espacial condiciona los ciclos agrícolas; así como el desarrollo de las principales especies vegetales y animales. Esta variable influye notoriamente sobre otros rubros de la economía y la correspondiente producción de bienes y servicios, especialmente cuando es escasa (Babel et al.,2021; Bhuiyan, Flügel y Jain, 2019).
Uno de los aspectos más importantes del estudio del clima es la variabilidad espacial y temporal de la precipitación (Zubieta, 2017). En este sentido, la caracterización de su peligrosidad, es un tema ampliamente tratado debido a su implicación en los procesos geo-hidrológicos y los relacionados con la erosión y pérdidas de suelo (Bedoya, Giraldo y Rodelo, 2019).
En la actualidad hay suficientes evidencias que demuestran la existencia de un cambio climático a escala global. Un aspecto que contribuye a demostrar esta situación es el análisis de las tendencias de variables climáticas como las precipitaciones, considerando diferentes escalas de tiempo y espacio (Méndez, De Jesús y González, 2008; Mohajeri et al.,2020; Omran y Negm, 2020). Estos análisis se realizan la mayoría de las veces sobre promedios a distintas escalas de tiempo, debido a que los estudios de las precipitaciones necesitan un mínimo de 20 años para considerarse representativos (Chow, Maidment y Mays, 1994; Fernandez-Lavado, 2008; Stedinger, Vogel y Foufoula-Georgiou, 1993), y cuando se analizan matemáticamente las precipitaciones diarias de varios pluviómetros durante tanto tiempo, el volumen de datos a procesar es enorme para las herramientas que se utilizan en la actualidad. De hecho, los estudios con datos a resolución diaria se pueden observar en la bibliografía solo como casos de estudio puntuales con fines académicos.
Actualmente y a pesar de su inexactitud, la mayor resolución temporal con la que se trabaja en estudios hidrológicos es a nivel mensual. Aunque el promedio mensual de lluvia suministra información valiosa sobre la pluviometría de un territorio, no dice nada acerca de la frecuencia o número de días de lluvia, ni del desglose de la cantidad registrada en los días lluviosos. Todos los parámetros estadísticos que expresan la variabilidad de las precipitaciones, como la varianza, el coeficiente de variación, la desviación estándar y más recientemente, el índice de irregularidad temporal, entre otros, se aplican casi siempre sobre montos mensuales o anuales y raramente a nivel diario (Sarricolea, Herrera Ossandon y Araya Escobar 2013). Así mismo, numerosos estudios de la variabilidad de la precipitación han sido desarrollados empleando datos mensuales mediante técnicas de aproximación estadística(Buytaert et al.,2006; Casimiro et al.,2012; Cerelli et al.,2007; Silva, Takahashi y Chávez, 2008; Zhang et al.,2021; Ngoma et al.,2021); sin embargo, estos estudios no revelan con claridad los eventos extremos, que son a su vez los de mayor interés.
El estudio de la precipitación a resolución diaria es un tema de gran importancia, debido a los problemas hidrológicos derivados de la alta intensidad y la mala distribución temporal de las precipitaciones en distintas regiones del mundo. Por tanto, el interés por el análisis de las lluvias diarias no es meramente climatológico; debido a que esta afecta a otros ámbitos medioambientales y socioeconómicos en ambientes frágiles (Bhuiyan, Flügel y Jain, 2019; Martin-Vide, 2004), donde los principales problemas son los relacionados con los episodios torrenciales, los cuales pueden causar catástrofes naturales como avenidas torrenciales, inundaciones rápidas, alta erosividad del fenómeno sobre el suelo, y una difícil gestión de los recursos hídricos (Babel et al.,2021; Mohajeri et al.,2020; Omran y Negm, 2020). Además, ante los esfuerzos de la sociedad moderna, y Cuba en particular, por aplicar técnicas como la agricultura de precisión en aras de mejorar los rendimientos en las producciones mientras se disminuye en lo posible los efectos nocivos para la naturaleza (Maldonado, Barreiro y Toca, 2017; Perez-garcia et al.,2019), es de suma importancia conocer la información relativa a las precipitaciones en la mayor resolución posible.
Es oportuno señalar que los estudios relacionados con el análisis probabilístico de las precipitaciones constituyen a nivel mundial una herramienta importante para los estudios hidrológicos e hidráulicos relacionados con el balance hídrico, la determinación de la potencialidad de sequías climatológicas, la planificación del recurso hídrico, así como en la elaboración de propuestas de planes de ordenamiento urbanos y agrícolas con fines de abastecimiento e irrigación (Dorado et al.,2006; Opolenko, 2022; Gutiérrez-Moreno et al.,2020).
En Cuba las investigaciones sobre precipitaciones con resolución diaria son escasas, solo se han realizado en el municipio Ciego de Ávila durante el periodo 1983-2012 (Brown Manrique et al.,2017). No obstante, dada la cantidad de datos y la amplitud del área a considerar solo se pudo utilizar un pequeño subgrupo de pluviómetros (considerados representativos) y los valores individuales luego promediados. Este estudio, aunque aportó información de suma importancia, no consideró la totalidad de los valores disponibles ante la falta de herramientas apropiadas, y mucho menos ha podido ser generalizado al resto del país.
Por este motivo surge el proyecto “Metodología para la utilización de fuentes de energías renovables en actividades industriales, agrícolas y abasto de agua en comunidades rurales de las provincias de Ciego de Ávila y Sancti Spiritus”, y como parte del mismo, el presente trabajo. En este se propone una herramienta informática diseñada para ofrecer la oportunidad de realizar una amplia gama de análisis sobre precipitaciones en cualquier resolución temporal, pues permite realizar igualmente los análisis a nivel anual, mensual, estacional u otro, pero permitiendo además manipular datos diarios sin necesidad de estimaciones estadísticas. Adicionalmente, incluye un conjunto de herramientas matemáticas que utilizan exclusivamente información diaria y que hasta ahora solo existen de manera aislada en dependencia de los intereses particulares de investigadores en la comunidad científica.
Materiales y Métodos
Como se ha señalado, realizar un análisis hídrico exhaustivo es una tarea compleja que implica el uso de varias herramientas matemáticas y una gran cantidad de datos. Por esta causa, la mayoría de las investigaciones se limitan a estudios con objetivos específicos, y es raro encontrar en la bibliografía la combinación de varias herramientas para ofrecer una interpretación integral de las condiciones de determinada área de estudio. Con el auge en los últimos años de herramientas informáticas, han surgido varias que sirven de apoyo a los investigadores; pero sus funcionalidades son, como regla, muy específicas y los resultados, difíciles de extraer y utilizar fuera de las aplicaciones.
El resultado ha sido, que la herramienta más difundida entre los científicos que estudian estos temas es la hoja de cálculo, específicamente la implementada por Microsoft Excel. Usando las facilidades que ofrece esta aplicación, es práctica común el intercambio de ficheros con fórmulas y procedimientos ya establecidos, en los cuales los investigadores sustituyen los datos por valores propios, obteniendo los resultados deseados. Incluso, el formato establecido por Microsoft Excel es el utilizado por el Instituto de Meteorología para divulgar la información sobre los registros de determinado pluviómetro o área.
Evidentemente, el uso de hojas de cálculo para la estimación de parámetros hidrológicos tiene varios problemas; uno de los más relevantes es que, aunque el procedimiento para determinado cálculo sea el mismo, los rangos donde se aplican las fórmulas dependen de la disponibilidad de los datos y cuando son demasiados, el investigador debe alterar las ecuaciones para considerar información que se sale del área establecida por el autor del fichero. Cuando se une esto a que, como se ha señalado, realizar un análisis hídrico apropiado requiere registros con un mínimo de 20 años de antigüedad, se llega a la conclusión de que este es el principal motivo por el cual la práctica común es escoger solamente un pequeño subgrupo de pluviómetros, y de ellos, los promedios anuales o mensuales.
Por estos motivos se justifica la creación de un sistema que permita aglomerar las principales herramientas para realizar análisis hidrológicos integrales sobre diversos rangos de tiempo y superficies. Dicho sistema debe cumplir como valor agregado de vital importancia, que presente una interfaz minimalista, intuitiva y atractiva. Como está previsto que debe ser operado principalmente por el personal vinculado directamente a las labores investigativas, es importante que cumpla con los requerimientos de interfaz expresados anteriormente y que sus resultados sean contrastables contra herramientas preexistentes de uso común.
Sistema propuesto
Desde el punto de vista informático, en la implementación del sistema se empleó Scrum para la gestión del proyecto; también es importante remarcar el uso de algunas buenas prácticas propuestas por la metodología XP para el desarrollo. Específicamente, dado el fuerte componente matemático previsto, se utilizó intensamente el Desarrollo Dirigido por Pruebas (TDD) (Blé Jurado, 2010; Wells, 2021); esta combinación ha sido ampliamente empleada durante varios desarrollos, sin violar los principios de ninguna de las dos metodologías (Kniberg, 2007; Maldonado, Barreiro y Toca, 2017; Scrum.org, 2021).
Como lenguaje de programación se usó Python, pues posee de gran cantidad de librerías para procesamiento matemático y estadístico probadas exhaustivamente por la comunidad científica. En el caso de la aplicación, se decidió que fuera web, debido a que así los investigadores tendrían acceso a la misma fácilmente desde cualquier lugar y sin necesidad de instalar ningún software adicional excepto el navegador, que viene preinstalado en la mayoría de los Sistemas Operativos que se utilizan en la actualidad. De esta forma, además se elimina la dependencia de las herramientas propietarias utilizadas hasta este momento y sería más fácil la migración a plataformas libres, prevista como política del país. Para su implementación se decidió utilizar el framework Web2Py; principalmente porque la curva de aprendizaje es relativamente sencilla, lo cual permitió centrar los esfuerzos en la parte algorítmica. Además, ofrece una sintaxis limpia y organizada, que potenció el efectivo intercambio entre los miembros del equipo de desarrollo y los investigadores que colaboraron con el desarrollo del proyecto. Adicionalmente, fue muy importante en la elección de la tecnología el hecho de que hasta la fecha no se han reportado incidentes de seguridad significativos en ningún sitio desarrollado con él (Web2Py Developers, 2021).
Según fue expuesto, el framework escogido para el desarrollo del sistema fue Web2Py, que implementa el patrón arquitectónico Modelo-Vista-Controlador (MVC). Siguiendo esta filosofía, se separaron la persistencia de los datos (Modelo), la presentación de los mismos (Vista) y la implementación de las funcionalidades (Controlador). La única salvedad radicó en que, al ser necesaria una gran cantidad de modelos matemáticos genéricos, que serían necesarios ser probados exhaustivamente y utilizados en diversos contextos dentro de la aplicación, se decidió programarlos como módulos independientes de Python, a los cuales accederían únicamente los controladores. De esta forma, se respetó la arquitectura propuesta por Web2py y se lograron algunas ventajas adicionales. Por ejemplo, dichos módulos podrían ser probados individualmente con baterías de pruebas diseñadas antes de su implementación (recuérdese que se utilizó TDD); diversos controladores podrían acceder a un mismo algoritmo matemático en diferentes situaciones, eliminando la duplicidad en el código; la modificación de alguna funcionalidad en un modelo matemático se podría hacer en un único lugar.
El acceso a la aplicación y sus funcionalidades se diseñó utilizando un mecanismo de autenticación basado en usuarios y roles. Cada usuario autorizado deberá pertenecer a uno o varios de los roles definidos a continuación:
Administrador del sistema: Solo tiene acceso a la asignación de usuarios a roles.
Especialista en Hidrología: Puede solicitar todos los tipos de reportes que maneja el sistema. Tiene además permisos para modificar algunos parámetros de modelos matemáticos utilizados, independientemente de los valores predefinidos.
Administrador de cuencas y áreas de interés: Tiene permisos para modificar y crear cuencas y áreas de interés. Puede solicitar además informes sobre las mismas, pero solo en modo lectura.
Investigador: Tiene los mismos permisos que el Especialista en Hidrología, pero adicionalmente puede crear nuevos modelos matemáticos, subirlos a la aplicación y contrastar sus resultados con los existentes. Aunque los puede subir al sistema, no quedan disponible para el resto de los usuarios hasta que no sea probado y aprobado por un Consejo Científico compuesto mayormente por especialistas en hidrología y ramas de la ciencia afines.
Cliente REST: Este rol está destinado para permitir el acceso de aplicaciones externas a información que pueda ser de dominio público, como algunos parámetros estadísticos o datos de interés para la agricultura u otros sectores estratégicos.
Principales librerías utilizadas
Tal como fue expuesto, tanto la información aportada por el Instituto de Meteorología, como la trabajada por los investigadores, se maneja comúnmente en hojas de cálculo. Además, en este campo de estudio es común el uso de estadística descriptiva; el ajuste de datos a funciones, sean las establecidas por la literatura o encontradas como parte de un proceso investigativo; la interpolación usando diversas distribuciones estadísticas, cuyos parámetros de ajuste deben ser encontrados con técnicas de optimización; la extrapolación de datos a períodos de tiempo definidos arbitrariamente; la graficación de resultados en diversas escalas temporales y en distintos formatos; etc. Estos factores fueron definitorios a la hora de escoger qué librerías serían las más propicias utilizar, sobre todo porque se estableció que el sistema debería ser capaz de generar informes en un formato similar a los que se podría obtener de una hoja de cálculo.
Como resultado de la investigación realizada, se decidió usar como principales librerías de Python:
Pandas: Es una biblioteca que proporciona estructuras de datos y herramientas de análisis de datos de alto rendimiento. Admite la integración con muchos formatos de archivo o fuentes de datos con información tabular (NumFOCUS Project, 2021). En este caso particular, es de señalar que es capaz de leer datos de ficheros de Microsoft Excel sin dificultad, lo cual fue de suma importancia para la lectura desde un fichero Excel de los registros históricos de todos los pluviómetros de la provincia de Ciego de Ávila, de donde se importaron los registros diarios de 60 años como promedio, de 106 pluviómetros.
Numpy: es el paquete fundamental para la computación científica en Python (NumPy Project, 2021). Proporciona un objeto de matriz multidimensional, objetos derivados y varias rutinas para operaciones rápidas en matrices, incluidas las matemáticas, lógicas, manipulación de formas, clasificación, selección, álgebra lineal, operaciones estadísticas, simulación aleatoria y otros. En combinación con la librería Pandas es capaz de realizar eficiente y eficazmente, todas las operaciones que se encontraban en las hojas de cálculo.
Scipy: es una biblioteca compuesta por herramientas y algoritmos matemáticos. Contiene módulos para optimización, álgebra lineal, integración, interpolación, funciones especiales y otras tareas para la ciencia e ingeniería (Enthought 2021). Se basa en el objeto de matriz NumPy y se integra con esta de manera natural. Se utilizó para las tareas relativas a optimización de modelos, ajuste de funciones, integración, derivación, entre otras.
Resultados y discusión
Como se planteó con anterioridad, un sistema informático fue propuesto; del mismo se hicieron dos configuraciones para su despliegue. La primera consistió en la realización de la aplicación como un sistema autónomo, de manera tal que fuera capaz de trabajar sin necesidad de dependencias externas ni comunicación con sistemas de terceros. Para garantizar su funcionamiento, se le proporcionó de manera local una base de datos con la información histórica de la red nacional de pluviómetros del Instituto de Meteorología utilizando SQLite como Sistema Gestor de Base de Datos; también consta de una representación de los mapas de la provincia Ciego de Ávila hasta un nivel de 18 aumentos, que permite la georreferenciación de los pluviómetros en su totalidad, así como la posibilidad de crear polígonos de forma arbitraria para delimitar cuencas de ríos u otras áreas de interés. Así, la aplicación es capaz de obtener y procesar los datos necesarios para la mayoría de sus estimaciones, aunque obviamente, carece del nivel de actualización que es indispensable para que los resultados obtenidos reflejen las condiciones actuales de las variables agrometeorológicas. En la segunda configuración, el sistema está concebido para que constituya un módulo de un sistema más complejo de agricultura de precisión, en cuyo caso el despliegue se haría tal y como se puede observar en la Figura 1.

La Figura 1 muestra todos los componentes que forman parte del despliegue de la aplicación, dentro de un sistema de agricultura de precisión, donde intervienen:
Servidor de geolocalización: Permite la organización, almacenamiento, manipulación, análisis y modelación de la información geoespacial. Es su responsabilidad adquirir información georreferenciada en varios formatos aportados por la empresa Geocuba y hacerlos utilizables por la aplicación.
Servidor de base de datos: Contiene toda la información necesaria para el funcionamiento de la aplicación. Su responsabilidad principal es ofrecer una interfaz con la red de estaciones agrometeorológicas y de pluviómetros provincial para adquirir los datos de manera regular y automática.
Servidor de aplicación: Contiene los modelos matemáticos para los análisis hidrológicos, así como los algoritmos para combinar los datos provenientes de los servidores de base de datos y de geolocalización para generar información utilizable. Este es el núcleo principal del sistema propuesto.
Estación cliente: Se refiere a los usuarios que acceden a la aplicación desde un navegador en cualquier tipo de dispositivo. Es el punto de acceso tanto para las funcionalidades del sistema como para su administración.
API de consumo público: Ofrece una interfaz de comunicación que utiliza la Transferencia de Estado Representacional (REST por sus siglas en inglés) para acceder a información del sistema. Está pensado para ofrecer datos a terceros, sean desarrolladores de software o aplicaciones que deseen utilizar alguno de los servicios públicos del sistema con interés particular o estatal.
Uno de los principales retos en el desarrollo de la aplicación fue cómo lograr su fácil utilización por parte de la gran gama de posibles usuarios, dada la alta complejidad de la mayoría de los análisis realizados. Tomando esto en cuenta se decidió que, independientemente de la modalidad en que se ejecutara, la aplicación debía permitir acceder a cada una de sus funcionalidades tanto desde un mapa, presionando solamente clics, como desde un formato tabular, diseñado principalmente para investigadores y por lo tanto, con un mayor rango de posibilidades.
Así, se logró una interfaz como la mostrada a continuación, en la Figura 2.
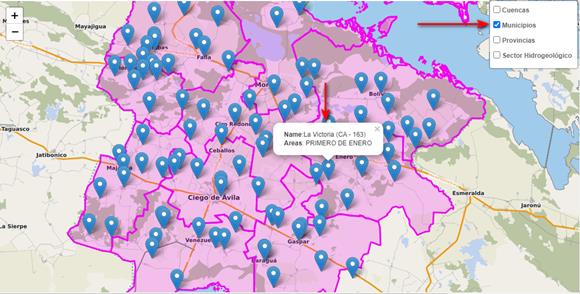
En la misma se pueden observar, con marcadores de color azul, la distribución de los pluviómetros en la provincia de Ciego de Ávila. Además, en la esquina superior derecha y señalado con una flecha roja, se puede ver cómo el usuario, si lo desea, representa en el mapa los distintos tipos de áreas que se encuenten en el sistema. Al seleccionarse uno, se muestran en el mapa las áreas de ese tipo, identificándose las fronteras con color sólido, y el interior del mismo color más atenuado. De igual manera al situar el puntero del ratón sobre un pluviómetro, se muestra información básica sobre el mismo, tal como está señalado con una segunda flecha, situada aproximadamente al centro del mapa. Al darse clic sobre el marcador de un pluviómetro o sobre un área, se despliega una ventana emergente con información más detallada del objeto, y varios botones que dan acceso a cálculos e índices especializados, que se calculan en el momento. Para optimizar el rendimiento general de la aplicación, resultados obtenidos para cada área y pluviómetro se guardan en la base de datos, y si al ser solicitados por un usuario, no han cambiado los datos de orígenes (i.e. no existe ningún nuevo registro ni se especifica ningún rango específico diferente de fechas a considerar), los resultados se muestran directamente de la base de datos, sin realizar nuevamente las operaciones involucradas.
Para ejemplificar, en la Figura 3 se muestra la información generada a partir de invocar el cálculo del Índice de Concentración de Precipitaciones Diarias (CI) para la Cuenca del río Chambas. Dicho índice es de mucha utilidad para estudiar la estructura temporal de la precipitación a nivel diario (Martin-Vide 2004) y se ha utilizado en varios lugares del mundo exitosamente.

En Cuba existen muy pocos trabajos en este sentido, debido a la alta complejidad de los cálculos implicados y el gran volumen de datos que es necesario analizar, de manera tal que, herramientas como las hojas de cálculo resultan de poco provecho. Por ejemplo, para obtener la información representada la figura 3, se consideró una serie de precipitaciones diarias en el periodo comprendido de 1928 al 2013, formada por observaciones sistemáticas en doce estaciones pluviométricas, que promediaron 37 años de registros. En total, fue necesario procesar 160 284 valores, 13 375 para cada mes como promedio. Para realizar el análisis de los CI para esta misma cuenca por la vía actual se utilizan no menos de 4 semanas, donde se calculan los promedios mensuales y anuales de las precipitaciones de cada pluviómetro, a partir de ahí se calculan los valores medios entre todos ellos; luego se estiman por procedimientos estadísticos los 5 más representativos y solo entonces se estima el CI utilizando la media de cada mes según la metodología propuesta en (Benhamrouche y Martín-Vide, 2012). Finalmente se extrapolan los valores al resto de los pluviómetros omitidos, con sus factores de corrección, y se promedian los índices para obtener el valor global de la cuenca. La estimación para cada mes puede ser más compleja aún puesto que al trabajarse con promedios mensuales, es necesario introducir Coeficientes de Desagregación Diarios para simular el comportamiento de la caída de la lluvia durante el mes. Si durante algún paso de este largo proceso se comete un error, es prácticamente imposible de corregir, siendo necesario comenzar nuevamente.
Con la aplicación propuesta, se utilizan todos los datos diarios disponibles, por lo que no hay que estimar ningún valor. Además, se puede calcular el CI real de cada pluviómetro en particular, de la cuenca en su totalidad y para cada mes de manera independiente. Todo el proceso dura solamente 36 125 milisegundos . Como se puede observar, existe una diferencia sustancial entre los tiempos de cálculo. Adicionalmente, todo el procedimiento computacional ha sido validado exhaustivamente y se puede considerar libre de errores humanos, por lo cual los resultados pueden servir de base a la toma de decisiones en el territorio y además fundamentar investigaciones científicas más profundas.
Además del CI, la aplicación actualmente permite obtener información de mucha utilidad tanto académica como práctica. Por ejemplo, sobre las precipitaciones, tanto con resolución tanto anual como mensual: total de lluvia acumulada; el valor máximo registrado para 24 horas; el promedio de precipitaciones respecto al total de días; la cantidad de días con lluvia; el promedio de precipitaciones respecto a la cantidad de días con lluvia; la cantidad de rachas lluviosas; la longitud media de las rachas lluviosas; la cantidad de lluvia aportada por rachas lluviosas respecto al total; la desviación estándar y la varianza. Respecto a otras informaciones de utilidad se calcula: Índice de Concentración de Precipitaciones Diarias; curvas de Precipitación-Frecuencia-Duración (IFD); curvas de Intensidad-Frecuencia-Duración (IFD), Índice de Irregularidad Temporal; índice de Persistencia, utilizando por defecto el índice de persistencia de Besson, aunque se pueden elegir otros; probabilidad de lluvia máxima diaria según diferentes distribuciones de probabilidad y hasta 500 años, entre otras.
Uno de los mayores logros de la aplicación es que brinda la posibilidad de utilizar de manera íntegra la totalidad de los datos disponibles, sin necesidad de trabajar con promedios o con valores “representativos”, lo cual es práctica común debido a los grandes volúmenes a procesar. Por otra parte, permite integrar los diferentes resultados referidos a un área geográfica determinada, o un conjunto de pluviómetros arbitrarios. De esta forma es posible dar una mejor visión sobre los elementos que permiten soportar decisiones referidas a la agricultura, defensa civil, obras de ingeniería civil e hidráulicas, sistemas de alerta temprana ante riesgos de sequías o posibilidad de altas precipitaciones en corto tiempo, entre otros.
Conclusiones
Como resultado de la presente investigación se logró implementar una herramienta que unificó la totalidad de los datos provenientes de los registros históricos de las precipitaciones en los pluviómetros de Ciego de Ávila, aunque está pensado para poder asumir una cantidad arbitraria de registros, según se vayan obteniendo. Dicha herramienta permite, desde una interfaz sencilla e intuitiva, manipular una gran cantidad de datos de manera eficiente, libre de posibles errores humanos y significativamente más rápida que la forma en la que se hace actualmente. De esta forma se puede generar, en muy corto tiempo, información de utilidad tanto para la investigación, como para la toma de decisiones que dependen del comportamiento de las precipitaciones diarias en cuencas hidrográficas. Además, la arquitectura definida permite adicionar, en forma de módulos implementados en el lenguaje de programación Python, nuevas formas de procesar los datos disponibles para satisfacer las nuevas necesidades e intereses que vayan surgiendo. A partir de estos resultados, se impone como trabajo futuro la incorporación de técnicas de inteligencia artificial y aprendizaje automático, que contribuyan sobre todo a mejorar el ajuste de funciones para la estimación de parámetros que intervienen medularmente en la planificación de actividades agrícolas, ingenieriles, así como la mitigación de desastres naturales.

