










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroduccio´n
Las redes son estructuras frecuentes que describen feno´menos relacionales de la naturaleza tales como las actividades sociales humanas, las comunicaciones, sistemas computacionales y redes biolo´gicas por tan solo mencionar algunos. En estos sistemas, la interaccio´n entre los componentes constituyen la red, la cual puede denominarse red de informacio´n sin pe´rdida de generalidad. Cuando la informacio´n que se maneja por las entidades o sus relaciones presentan diferencias en su tipo se puede afirmar que es una red de informacio´n heteroge´nea (Chuan Shi and Yu, 2017) (llamada ”Heteregeneous Information Network”, HIN, por sus siglas en ingle´s) o red heteroge´nea. Las redes heteroge´neas describen sistemas complejos, e´stas han incrementado los intereses investigativos de cient´ıficos de distintas a´reas por su relevancia en sistemas reales como world- wide web (Deng, 2020), transportacio´n (Chen et al., 2020), biolog´ıa (Liu et al., 2020) y sistemas sociales (Balakrishnan and TV, 2020).
En las redes heteroge´neas existe una subcategor´ıa particular donde hay solo un tipo de objetos pero ma´s de un tipo de relacio´n entre objetos, esta se denomina red multirrelacional (M. K.-P. Ng and Ye). La red multirrela- cional tambie´n es conocida como red multicapa donde cada capa representa un tipo de relacio´n.
La determinacio´n de la relevancia de los ve´rtices o entidades que conforman la red es un crucial y retador tema que permite entender la estructura topolo´gica y el proceso de cambio de los sistemas complejos de redes (Matos et al., 2018; Smolyak et al., 2020). Existen distintas medidas de centralidad basadas en un criterio ya sea estructural (tales como el grado y el coeficiente de agrupamiento), orientadas a las rutas que sigue la comunicacio´n (como la Intermediacio´n o Cercan´ıa) y otros criterios ma´s refinados (como el Vector Propio, PageRank y Katz). Las medidas de centralidad ayudan a una mejor identificacio´n de los individuos que difun- den y propagan la informacio´n en la red (Ribeiro et al., 2020), optimizar el uso de los recursos para facilitar la propagacio´n de la informacio´n (Alshahrani et al., 2020), controlar el flujo de movilidad y reducir el impacto de la propagacio´n de enfermedades (Jadidi et al., 2021), entre otras aplicaciones.
Las relaciones que se establecen entre entidades en una red suelen estar denotadas de distintas formas, lo que representa aristas de diferentes tipos, siendo este un sistema multirrelacional o multicapa. En los u´ltimos an˜os, las estrategias para manejar las redes multicapas combinan las mu´ltiples interacciones entre los ve´rtices considerando los tipos de aristas (Chuan Shi and Yu, 2017; De Bacco et al.; Kumar Behera et al.; Chen et al.;M. Wu and Poor). Varias medidas de centralidad en redes homoge´neas han sido extendidas para identificar los nodos principales en redes multicapas tales como la medida de centralidad de grado, el PageRank y el Vector Propio.
En la u´ltima de´cada, las redes sociales han crecido significativamente en cuanto a taman˜o y actividad (di- namismo), provocando que los algoritmos esta´ticos para el cálculo de la centralidad sean muy costosos en tiempo. Ante la dificultad que implica el tiempo de ca´lculo de las medidas de centralidad en redes de grandes dimensiones, este trabajo se propone como objetivo construir una herramienta para el ana´lisis eficiente de estas medidas en una red multicapa.
Me´todos o Metodolog´ıa Computacional
Las principales funciones de una red social son: conectar a los usuarios y permitir la centralizacio´n tanto de informacio´n, como de recursos (fotos, videos, opiniones y otros), en un u´nico lugar de fa´cil acceso e intercambio. Sin lugar a dudas las redes sociales han marcado una nueva pauta en la comunicacio´n entre las personas, ya que e´stas se han convertido en su principal medio de difusio´n, ya sea de sus actividades, como de su estado de a´nimo. En este tipo de red existen mu´ltiples tipos de conexiones entre las entidades que la conforman, lo cual la clasifica como una red multirrelacional o multicapa.
Una red multicapa se modela como una combinacio´n de grafos que pertenecen a distintos niveles, los cuales se denominan capas, denota´ndose como L m = {l 1 , ..., l m } donde G L m = {(V α , E α ) L m } representa el grafo en la capa α. Generalmente, el conjunto de usuarios es el mismo en las distintas capas; ejemplo: V α = V β = V, ∀α, β ∈ L m . Por otra parte, una coleccio´n de aristas E α ⊆ V α ×V α representan la interaccio´n de una relacio´n peculiar entre usuarios, tales como enlaces familiares, de amistad o colaboracio´n (Chen et al.). Las relaciones pueden o no tener un nivel de relevancia o significacio´n, lo cual se representa con un peso en la arista, este tipo de grafo se denomina grafo pesado o ponderado.
Medidas de Centralidad
Las medidas de centralidad denotan la importancia de las entidades, es decir, los ve´rtices dentro de la red. Existen distintas medidas de centralidad que cuantifican la importancia de los nodos en cuanto a la cantidad de conexiones, con quie´nes se conectan y papel que juegan en las comunicaciones. La identificacio´n de indi- viduos centrales en redes multicapas es una tarea investigada con intensidad, extendiendo el ana´lisis cla´sico de las medidas de centralidad desde las redes de una sola capa.
La centralidad de Grado es la medida que posiciona a los ve´rtices considerando el nu´mero de conexiones con otros ve´rtices en la red. En los grafos dirigidos se definen dos medidas de centralidad de grado distintas, correspondientes al grado de entrada y al de salida. De forma ana´loga existen variantes de esta medida para grafos donde las aristas tienen un peso o importancia.
La medida de centralidad de Vector Propio es una medida de la influencia de un nodo en una red (Bonacich, 1987). Esta medida tiene un alto contraste con respecto a la centralidad de grado pues no todos los vecinos de un nodo son considerados como equivalentes. Los nodos tienen distintas relevancias y en esa medida contribuyen a la relevancia de otros nodos de la red. Una puntuacio´n alta de Vector Propio significa que un nodo esta´ conectado a muchos nodos que tienen puntuaciones altas. En grafos dirigidos puede calcularse utilizando la estrategia propuesta por (Newman, 2018), pero tiene como limitacio´n que los nodos fuera de las componentes fuertemente conexas tengan centralidad igual a cero.
La medida de centralidad de Katz (Katz, 1953) es empleada para cuantificar el grado relativo de influencia de un actor en una red social. Tiene una idea conceptual muy parecida a la medida de Vector Propio, mas solventa la limitacio´n de esta en redes orientadas. La medida garantiza que los nodos tengan un nivel de importancia distinto de cero sin importar si esta´n dentro de una componente fuertemente conexa.
La medida de centralidad de PageRank es un modelo que tiene distintas interpretaciones (Gleich and Saun- ders, 2009). Se basa en la idea de que en una matriz estoca´stica, idealmente, la importancia de los nodos es proporcional al Vector Propio dominante que no es u´nico. PageRank modifica este problema para producir un nuevo problema con una u´nica respuesta. Como contraste a la centralidad Katz, el PageRank intenta diluir la importancia de un nodo con el resto de sus vecinos.
La medida de centralidad Cercan´ıa , describe cua´n cerca se encuentra un ve´rtice de los otros nodos en la red. En redes donde existan elementos en distintas componentes conexas, se tiene que la distancia entre dichos ve´rtices es infinita. Existen otras alternativas para remplazar la distancia infinita entre dos ve´rtices de componentes distintas, como lo es centralidad armo´nica (Rochat, 2009).
La Intermediacio´n al igual que la Cercan´ıa define la importancia de un ve´rtice evaluando su papel en las comunicaciones, cuantificando las mejores rutas en las que aparece un nodo. Esta medida es tiene un alto costo computacional debido al ca´lculo que implica calcular todos los caminos m´ınimos, el algoritmo de Brandes (Brandes, 2001) es la estrategia o´ptima reportada para su ca´lculo.
Existen distintos enfoques para calcular las medidas de centralidad en redes multicapas, que se pueden clasi- ficar en 3 categor´ıas principales (Chen et al.):
Los que suman la informacio´n de las distintas capas y luego estiman la medida de centralidad en tal red (F. Battiston and Latora; M. De Domenico and Arenas).
Aquellos que tratan de forma independiente las capas y evalu´an la centralidad en cada capa (De Dome- nico et al., 2015).
Los que consideran la interaccio´n entre capas (Reiffers-Masson and Labatut; M. Wu and Poor).
Herramientas
El lenguaje Scala se desarrollo´ en el 2001 en la universidad EPFL (Escuela Polite´cnica Federal de Lausana en Suiza). Scala ha experimentado un acentuado crecimiento que ha hecho que este lenguaje pase de ser utilizado de un modo muy acade´mico y orientado a la investigacio´n, a convertirse en un esta´ndar para muchas empresas (algunas de la envergadura de Twitter o BBVA, empresas en creacio´n y universidades de todo el mundo.
Apache Spark es un framework de co´digo abierto para almacenar y procesar grandes cantidades de infor- macio´n distribuida en un clu´ster de ordenadores. Spark puede realizar todas las operaciones en memoria, pudiendo llegar a operar hasta 100 veces ma´s ra´pido que Apache Hadoop (Xu et al., 2017). Adema´s de las operaciones Map y Reduce, Spark incluye una nueva estructura de datos: Resilient Distributed Datasets o RDD sobre la cual Apache Spark realiza todas las operaciones de forma paralela y distribuida.
Spark utiliza otra abstraccio´n computacional, las variables compartidas, que pueden ser utilizadas en opera- ciones paralelas. Las variables compartidas es el mecanismo que se emplea para enviar los datos necesarios a los nodos ejecutores o entre ejecutor y driver. En Spark existen dos tipos de variables compartidas: las broad- cast, las cuales pueden ser utilizadas como cache´ en la memoria de todos los nodos, y los acumulator, los cuales son variables que solo se les puede incrementar como contadores o sumadores.
Las transformaciones son computadas de modo perezoso (lazy), es decir, solo cuando una accio´n es invocada, la cual desata el ca´lculo de las transformaciones luego de que Spark cree el plan f´ısico de ejecucio´n. En Spark los datos no son generalmente distribuidos en particiones de modo que este´n en el lugar justo para una operacio´n espec´ıfica. El shuffling consiste en localizar todos los valores para una clave que no residen en la misma particio´n o en la misma ma´quina.
Disen˜o de la propuesta
Enelc´alculodelamedidadecentralidadseempleaunacombinaci´ondelosenfoques:(1) tratar la centralidad por capa independiente y (2) analizar la suma de información de las capas. Dada la medida de centralidad φ, el vértice xi y una selección Ls en un grafo multicapa GLm ={(V,E)l1,...,(V,E)lm}={(V,E)Lm} donde Lm ={l1,...,lm}y Ls ⊆Lm, denotaremos la medida de centralidad del vértice en la selección como:
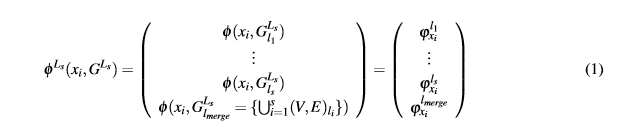
en dondeφ(xi,GLs lj ) =ϕlj xi representa la centralidadφ para el v´ertice xi en el grafo homog´eneo formado por la capa lj ∈Ls, mientras queφ(xi,GLs lmerge) =ϕlmerge xi lo es para el grafo homog´eneo de la uni´on de las capas Ls.
El principal propo´sito de emplear Scala usando el framework Spark es aprovechar las ventajas que nos brinda para el co´mputo paralelo y distribuido. Las distintas medidas que son expuestas en este documento se calculan de forma paralela y distribuida, con el empleo de la estructura de grafo propuesta en GraphX. La estrategia consiste en distribuir el co´mputo de las medidas en distintas unidades de co´mputo, donde cada ejecutor efectu´a el ca´lculo de forma seriada por cada nodo, tal como se muestran en el algoritmo 1.

Evaluacio´n
Para la evaluación de las medidas de centralidad implementadas se emplearon colecciones de grafos multi- capas de distintas naturaleza (tabla 1). La red ARABIDOPSIS esta´ conformada por diferentes tipos de interacciones gene´ticas (BioGRID1) (Stark et al., 2006). Las colecciones NYCLIMATE y CANNES fueron obtenidas de la red social Twitter considerando diferentes tipos de relaciones sociales entre usuarios (Omodei et al., 2015).
Tabla 1 Propiedades de los grafos multicapas y su transformacio´n para la experimentacio´n.
| Nombre de la Coleccio´n | Naturaleza de la Red | Nu´mero de Nodos | Nu´mero de Aristas | Nu´mero de Capas | Nu´mero de Nodos a Analizar | Nu´mero de Aristas a Analizar | Nu´mero de Capas a Analizar |
|---|---|---|---|---|---|---|---|
| ARABIDOPSIS | Biolo´gica | 6 980 | 18 655 | 7 | 55 840 | 37 310 | 8 (7 + Capa Mezcla) |
| NYCLIMATE | Social | 102 439 | 353 495 | 3 | 409 756 | 706 990 | 4 (3 + Capa Mezcla) |
| CANNES | Social | 438 537 | 991 854 | 3 | 1 754 148 | 1 983 708 | 4 (3 + Capa Mezcla) |
Al evaluar algoritmos paralelos y distribuidos hay que considerar la aceleracio´n y escalabilidad (Gil, 2005):
T dist : La duracio´n del algoritmo paralelo y distribuido propuesto, considerada como el tiempo transcu- rrido desde que se inicia su ejecucio´n hasta que finaliza el u´ltimo de sus procesos.
T sec : La duracio´n del algoritmo secuencial para resolver el problema tratado. En nuestro contexto, se utilizo´ la implementacio´n propia en el lenguaje Scala con un u´nico nu´cleo.
Aceleracio´n: A = Tsec , mide el incremento de velocidad obtenido con el algoritmo paralelo y distribuido.
En el caso ideal crece linealmente con el nu´mero de los recursos.
Escalabilidad vertical: Cuando al an˜adir ma´s recursos a los nodos del sistema hay un incremento de velocidad en el algoritmo.
Escalabilidad horizontal: Cuando al agregar ma´s nodos al sistema el rendimiento del algoritmo mejora.
Para la ejecucio´n de los distintos experimentos realizados se utilizo´ el Supercomputador de la Universidad de Oriente, en particular el clu´ster Big Data. Este clu´ster, especializado en el co´mputo de grades volu´menes de datos, virtualmente se compone de 3 unidades de co´mputo formadas por 64 nu´cleos y 64GB de memoria RAM donde cada una tiene 600GB de almacenamiento. El clu´ster Big Data cuenta con la versio´n 2.11.8 del lenguaje Scala y el framework Spark en su versio´n 2.3.2.1www.thebiogrid.org
Resultados y discusio´n
Con el propo´sito de analizar el comportamiento de los algoritmos implementados se emplearon las distintas colecciones anteriormente mencionadas y se ejecutaron un conjunto de pruebas. De igual manera se evaluo´ el rendimiento de las diferentes medidas sin considerar el peso de las aristas.
Cada uno de los experimentos realizados se ejecuto´ en el ambiente del Supercomputador de la Universidad de Oriente. En los experimentos efectuados con cada una de las diferentes me´tricas se emplearon configuraciones de 1, 2, 4, 8 y 16 nu´cleos utilizando 3GB de memoria RAM en un u´nico esclavo, con el propo´sito de evaluar la escalabilidad vertical. En las configuraciones de 32, 64 y 128 se emplearon 2, 4 y 8 esclavos respectivamente empleando 3GB de memoria RAM en cada esclavo, con el objetivo de evaluar la escalabilidad horizontal de la solucio´n propuesta.
En las distintas colecciones se realizaron experimentos donde se analizaron todas las capas adema´s de su mezcla. Lo anteriormente mencionado implica calcular para cada ve´rtice su relevancia en todas las capas, este ca´lculo se realiza de forma paralela y distribuida empleando los algoritmos de menor complejidad compu- tacional reportados en la literatura.
Experimentos con la me´trica Cercan´ıa
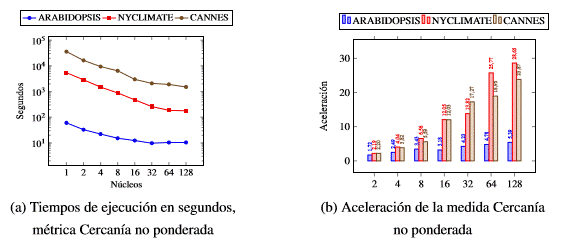
Los experimentos realizados con la medida de centralidad de Cercan´ıa en las distintas colecciones descritas en la tabla 1 se pueden ver en las siguientes tablas. En la tabla 2, así como en la figura 1a se muestra el comportamiento de los tiempos de ejecucio´n de la me´trica de Cercan´ıa sin el peso de las arista.
Tabla 2 Tiempos en segundos para la ejecucio´n de la me´trica de Cercan´ıa sin el peso de las aristas.
| Nombre de la Coleccio´n | 1 Nu´cleo 1 Ejecutor | 2 1 Ejecutor | 4 Nu´cleos 1 Ejecutor | 8 Nu´cleos 1 Ejecutor | 16 Nu´cleos 1 Ejecutor | 32 Nu´cleos 2 Ejecutores | 64 Nu´cleos 4 Ejecutores | 128 Nu´cleos 8 Ejecutores |
|---|---|---|---|---|---|---|---|---|
| ARABIDOPSIS | 35.237 | 20.497 | 14.161 | 10.288 | 11.073 | 8.328 | 7.366 | 6.542 |
| NYCLIMATE | 3519.209 | 1604.342 | 871.457 | 536.832 | 292.003 | 254.561 | 136.548 | 122.829 |
| CANNES | 36178.061 | 16479.062 | 9459.235 | 6474.781 | 3006.591 | 2094.340 | 1908.696 | 1515.883 |
La tabla 2 refleja el comportamiento del tiempo para la medida de Cercan´ıa sin el peso de las aristas. Se puede apreciar que al aumentar las capacidad de co´mputo se reduce el tiempo de ejecucio´n, ver figura 1a. Los tiempos en un ejecutor con 1, 2, 4, 8 y 16 nu´cleos muestran que al aumentar los recursos del ejecutor se reduce el tiempo, lo que evidencia que escala verticalmente. De forma similar sucede que al aumentar la cantidad de ejecutores se reduce el tiempo de co´mputo, por lo que podemos afirmar que escala horizontalmente.
En la figura 1b se grafica el comportamiento de la aceleracio´n para la me´trica de Cercan´ıa en las tres coleccio- nes para la variante sin peso. En las figura la coleccio´n ARABIDOPSIS es la de peor desempen˜o, alcanzando una aceleracio´n de 5.38 veces con 128 nu´cleos para la variante sin analizar el peso de las aristas, esto se debe al intercambio de informacio´n entre ejecutores y el driver. Por otra parte, en la figura 1b se obtiene una ace- leracio´n de 28.65 y 23.86 veces en las colecciones de NYCLIMATE y CANNES respectivamente ambas con 128 nu´cleos distribuidos en 8 esclavos
Experimentos con la me´trica Intermediacio´n
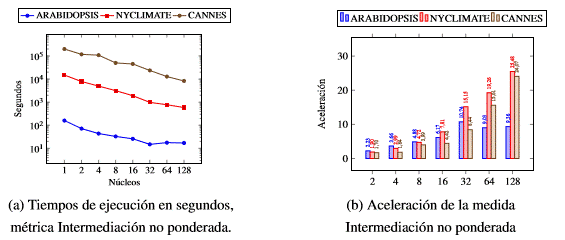
La tabla 3 y la figura 2a refleja el comportamiento del tiempo en la medida de Intermediacio´n sin el peso de las aristas. Al aumentar la capacidad de co´mputo se reduce el tiempo de ejecucio´n para la mayor´ıa de las colecciones, excepto en ARABIDOPSIS que con 64 nu´cleos en 4 ejecutores tiene un desempen˜o menor que con 32 en 2 ejecutores. En la coleccio´n ARABIDOPSIS no se logra acelerar ma´s luego de 32 nu´cleos y esto ocurre debido al costo que tiene la intercomunicacio´n entre los ejecutores. De forma general, los tiempos en un ejecutor con 1, 2, 4, 8 y 16 nu´cleos demuestran que al aumentar los recursos del ejecutor se reduce el tiempo, lo que evidencia que escala verticalmente. De forma similar sucede que al aumentar la cantidad de ejecutores se reduce el tiempo de co´mputo, por lo que podemos afirmar que escala horizontalmente.
Tabla 3 Tiempos en segundos para la ejecucio´n de la me´trica de Intermediacio´n no ponderada.
| Nombre de la Coleccio´n | 1 Nu´cleo 1 Ejecutor | 2 Nu´cleos 1 Ejecutor | 4 Nu´cleos 1 Ejecutor | 8 Nu´cleos 1 Ejecutor | 16 Nu´cleos 1 Ejecutor | 32 Nu´cleos 2 Ejecutores | 64 Nu´cleos 4 Ejecutores | 128 Nu´cleos 8 Ejecutores |
|---|---|---|---|---|---|---|---|---|
| ARABIDOPSIS | 160.630 | 71.948 | 43.923 | 32.940 | 26.040 | 14.955 | 17.783 | 17.170 |
| NYCLIMATE | 14968.183 | 7886.632 | 5002.114 | 3174.521 | 1917.524 | 987.726 | 777.116 | 587.399 |
| CANNES | 200657.657 | 118017.119 | 109113.904 | 50254.848 | 45350.050 | 23765.894 | 12851.306 | 8338.010 |
En la figura 2b se muestra el comportamiento de la aceleracio´n para la me´trica de Intermediacio´n en las tres colecciones para la variante sin peso. La coleccio´n ARABIDOPSIS es la de menor desempen˜o, consiguiendo una aceleracio´n de 9.35 veces con 128 nu´cleos. Se alcanzan los valores de aceleracio´n de 24.06 y 25.48 veces en las colecciones de NYCLIMATE y CANNES respectivamente, ambas con 128 nu´cleos distribuidos en 8 esclavos con 16 nu´cleos cada uno.
Experimentos con la me´trica Vector Propio
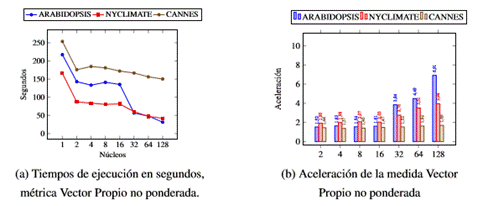
En la tabla 4 y figura 3a esta´ reflejado el comportamiento del tiempo en la medida de Vector Propio sin el peso de las aristas, en donde se puede apreciar que al aumentar la capacidad de co´mputo se reduce el tiempo de ejecucio´n. Los tiempos en un ejecutor y las distintas configuraciones de nu´cleos ilustran que al aumentar los recursos del ejecutor se reduce el tiempo, lo que evidencia que escala verticalmente. De forma similar sucede que al aumentar el nu´mero de ejecutores se reduce el tiempo de co´mputo, por lo que podemos afirmar que escala horizontalmente.
Tabla 4 Tiempos en segundos para la ejecucio´n de la me´trica de Vector Propio sin considerar el peso de las aristas.
| Coleccio´n | Nu´cleo(s) | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|---|---|---|
| Ejecutor(es) | 1 | 1 | 1 | 1 | 1 | 2 | 4 | 8 | |
| ARABIDOPSIS |
217.26 165.88 253.64 |
143.03 | 133.35 | 141.08 | 135.34 | 56.57 | 48.38 | 31.43 | |
| NYCLIMATE | 87.12 | 83.76 | 80.28 | 81.84 | 60.12 | 47.30 | 42.06 | ||
| CANNES | 175.85 | 184.72 | 180.98 | 172.08 | 166.723 | 156.234 | 150.284 | ||
En la figura 3b se grafica el comportamiento de la aceleracio´n para la me´trica de Vector Propio en las tres co- lecciones. La coleccio´n ARABIDOPSIS es la de mejor desempen˜o a diferencia de lo que hab´ıa ocurrido con las me´tricas anteriores. Este desempen˜o se debe a que solo el 29 % de sus nodos tiene relevancia nula mientras que para las otras dos colecciones este valor es del 89 % aproximadamente, por lo que en ARABIDOPSIS existe una mayor cantidad de elementos a computar de forma paralela y distribuida. En ARABIDOPSIS se alcanza una aceleracio´n de 6.91 con la configuracio´n de 128 nu´cleos entre 8 ejecutores.
El desempen˜o de la me´trica en la coleccio´n NYCLIMATE consiguio´ una aceleracio´n para la variante sin considerar el peso de las aristas de 3.94 veces con 128 nu´cleos en 8 ejecutores. La coleccio´n CANNES alcanza una aceleracio´n de 1.69 veces con el empleo de 128 nu´cleos en 8 ejecutores, tal como se ilustra en la figura 3b. Aunque esta medida escala horizontal y verticalmente su naturaleza secuencial dificulta que se alcancen mejores rendimientos en su implementacio´n paralela y distribuida.
Conclusiones
En este trabajo se desarrollo´ una herramienta para la evaluacio´n de las medidas de centralidad en redes mul- ticapas. La principal utilidad de la propuesta es obtener niveles de relevancia en correspondencia del nivel sema´ntico definido por los tipos de aristas y su combinacio´n en un tiempo o´ptimo. Para la optimizacio´n del tiempo de co´mputo se empleo´ el lenguaje Scala con el framework Spark para el co´mputo paralelo y distribuido de las medidas, empleando los algoritmos de menor complejidad computacional reportados en la literatura.
Como parte de los experimentos desarrollados se evaluo´ el desempen˜o de estas medidas en el ambiente del Supercomputador de la Universidad de Oriente. En los experimentos efectuados con las diferentes me´tricas se emplearon configuraciones de 1, 2, 4, 8 y 16 nu´cleos utilizando 3GB de memoria RAM en un u´nico esclavo, los cuales demostraron que las medidas de centralidad implementadas escalan verticalmente. Adema´s, en las configuraciones de 32, 64 y 128 se emplearon 2, 4 y 8 esclavos respectivamente con 3GB de memoria RAM en cada uno, demostrando tambie´n que las medidas logran escalar horizontalmente.
En los experimentos realizados se acelero´ el tiempo de co´mputo para la me´trica de Cercan´ıa unas 28.65 veces, empleando 128 nu´cleos en 8 esclavos con 3GB de memoria RAM cada uno. De similar forma, la medida de Intermediacio´n acelera 25.48 veces con igual configuracio´n de recursos. Por otra parte y en menor medida se acelero´ el co´mputo de la me´trica de Vector Propio con una aceleracio´n de 6.91 veces, esta menor aceleracio´n se deben a la naturaleza secuencial de su co´mputo y al feno´meno del shuffling.

