










 Servicios personalizados
Servicios personalizados texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
La selección como concepto es el proceso de discriminación de los mejores clones de una población y es a su vez el mayor costo de los programas de mejoramiento. Este es un proceso de varias etapas cuyo objetivo es identificar y extraer individuos superiores tan eficientemente como sea posible maximizando las ganancias genéticas y a menor costo 1.
La elección de progenitores y la predicción de su valor es una de las acciones importantes en cualquier programa de cruzamiento 2. Por ende, el incremento de la selección y la ganancia genética es una medida del éxito de los programas de mejoramiento 3.
Algunos de los programas de mejoramiento genético han priorizado la selección familiar seguida de la individual 4. Una metodología de selección simultánea es necesaria para las primeras etapas, lo cual constituye la base de la determinación de un índice a partir de múltiples caracteres más que la selección intensiva sobre un carácter en particular 5. Este objetivo requiere nuevas estrategias para optimizar las ganancias en los programas de mejoramiento genético de la caña de azúcar 6. En este sentido, una de las direcciones de investigaciones importante es la optimización de métodos de predicción del comportamiento familiar, mediante modelos lineales mixtos generalizados y sus contrapartes bayesianas 7.
El Instituto de Investigaciones de la Caña de Azúcar de Cuba (INICA) desarrolla un programa de mejoramiento genético para la obtención de nuevos cultivares más productivos, resistentes a las principales plagas y adaptados a las diferentes condiciones de explotación comercial 8. Anualmente se trabaja con grandes poblaciones de progenies en diferentes etapas.
Para la gestión de la información que se genera en el proceso de selección, se dispone de un programa informático que permite capturar, almacenar y procesar esta información 9. Esta aplicación informática posee un modelo matemático que permite estimar el valor genético (VGE) de progenitores y cruces. Sin embargo, no se dispone de una metodología que permita predecir la respuesta familiar y su manejo en el programa de selección de la caña de azúcar en Cuba.
El objetivo del presente trabajo fue establecer una metodología de clasificación y manejo de cruces biparentales en el programa de selección genética de la caña de azúcar en Cuba, a partir de la determinación del VGE mediante la evaluación de las progenies en el lote clonal 1.
MATERIALES Y MÉTODOS
Se utilizaron los datos de selección provenientes del lote clonal 1 del programa de selección para la obtención de nuevos cultivares de la caña de azúcar que se desarrolla en la región suroriental de Cuba 10. El período de estudio comprendió 16 años desde el 2000 al 2015.
Los ensayos fueron establecidos en áreas del bloque experimental de la localidad América Libre en el municipio Contramaestre, provincia Santiago de Cuba (-76,2° longitud y 20,3° latitud) sobre un suelo Pardo sialítico 11. Los clones fueron plantados a una distancia de un metro entre clones y 1,6 m entre hileras sin repetición. La evaluación de las progenies se efectuó en la cepa de primer retoño en el mes de enero a los 12 meses de edad. Se utilizó como testigo o control el cultivar comercial C87-51 de alto contenido de sacarosa.
La base de datos comprendió 16 años de selección clonal y se consideraron en el estudio todas las familias con más de 40 individuos evaluados. Se recopiló la información de 24092 clones de 230 combinaciones biparentales. Todos los datos fueron capturados y validados en el software SASEL 12.
Por otra parte, se utilizó información de las etapas de estudios replicados y extensivos del proceso de selección de la caña de azúcar en Cuba, para determinarlos cruces biparentales que aportaron individuos a etapas finales de este proceso.
Modelo matemático utilizado para estimar el valor genético de los cruces
Se utilizó un modelo lineal para cuantificar la interacción existente entre el cruce y el ambiente 9. Se emplearon siete variables evaluadas relacionadas con el contenido de sacarosa de las progenies, componentes del rendimiento agrícola (diámetro y longitud de los tallos) y la resistencia a dos de las principales plagas que afectan al cultivo (Tabla 1).
Los coeficientes de ponderación se ajustaron de acuerdo a la importancia relativa de las variables y la heredabilidad de las mismas. El máximo valor de ponderación se otorgó al porcentaje de selección, por ser esta una variable que abarca las características deseables en las progenies de los cruces.
Tabla 1 Variables evaluadas consideradas en las funciones de relación del modelo matemático para determinar el valor genético estimado (VGE)
| No | Variable | Coeficiente de ponderación |
|---|---|---|
| 1 | Porcentaje de selección | 1 |
| 2 | ºBrix refractométrico | 0,8 |
| 3 | Diámetro del tallo (cm) | 0,8 |
| 4 | Longitud del tallo (cm) | 0,8 |
| 5 | Porcentaje de indivividuo afectados por roya | 0,7 |
| 6 | Porcentaje de indivividuo afectados por carbón | 0,7 |
| 7 | Porcentaje de indivividuo afectados por bajo ºBrix | 0,8 |
Procesamiento estadístico
Para contrarrestar el efecto de la interacción genotipo-ambiente (IGxA) a través de los años, en este caso cruces x series, se procedió a estandarizar el VGE con la determinación independiente de este por cada año o serie estudiada.
La población de familias comprendió 230 cruces biparentales. De estos, evaluados por única vez 204 cruces, los cuales fueron utilizados para la elaboración de la metodología de clasificación y manejo de los cruces. El resto de los cruces (26) evaluados dos o más veces en el período de estudio, se utilizaron para la validación de la metodología propuesta.
Los datos originales del VGE fueron evaluados respecto a su normalidad mediante la prueba de Shapiro-Wilk´s W y cumplieron las exigencias en cuanto a esos parámetros, por lo que en ningún caso se hizo necesaria su transformación. Se realizó un histograma de frecuencia con los 204 cruces que fueron evaluados una vez. El número de clases fueron conformadas de acuerdo a la distribución normal VGE y la homogeneidad en la desviación estándar de los grupos conformados según los intervalos de clases.
Con los valores del VGE de los 26 cruces, evaluados dos o más veces, se realizó la clasificación según los grupos determinados por el histograma de los cruces evaluados una vez. Con esta categorización se determinó la diferencia entre los grupos o repetibilidad entre estos y de esta forma se comprobó la validez del procedimiento.
Se realizó una nueva comprobación de la clasificación de los cruces con el VGE obtenido de las familias que aportaron individuos a etapas finales del proceso de selección (estudios replicados y extensivos). Se determinó la frecuencia absoluta y relativa de cada categoría como criterio de validación de los grupos, a partir de que estuviesen más representados como cruces comprobados.
RESULTADOS Y DISCUSIÓN
El histograma de frecuencia del VGE de 204 cruces permitió obtener siete intervalos de clases (Figura 1). El histograma de frecuencia se ajusta a una curva normal, donde los valores medios se agrupan al centro de la curva. Los intervalos de clases obedecen a que exista entre clases homogeneidad de varianza y la media en la clase del medio. La media del VGE fue de 78,17 % y la clase media oscila desde 76,20 a 80,13 %.
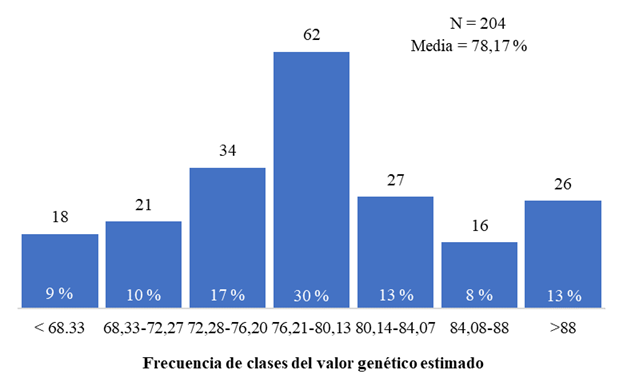
Figura 1 Histograma de frecuencia absoluta y relativa del valor genético estimado (%) para siete grupos de intervalos clases
Los intervalos de clases de la Figura 1 permiten establecer una clasificación del valor de la familia en correspondencia con los resultados de la selección simultánea que se realiza sobre varios caracteres (Tabla 2). Los cruces de la clase media se clasificaron como exploratorios o sin tendencia a definir un valor destacado o no como familia. A partir de este grupo se definió el resto de la clasificación al considerar las clases inferiores a la media con tendencia a ser cruces descartados y clases superiores a la misma como comprobados. Es decir, se establecieron categorías desde moderadamente comprobado a muy comprobado (VGE superior a 80,13 %) y desde moderadamente descartado a muy descartado con valores inferiores a 76,20 %.
Tabla 2 Clasificación del cruce según su valor genético estimado (VGE) y las clases del histograma de frecuencia
| Intervalos de clases del VGE (%) | Grupo | Clasificación del cruce |
|---|---|---|
| < 68.33 | 1 | Muy descartado |
| 68.33-72.27 | 2 | Descartado |
| 72.28-76.20 | 3 | Moderadamente descartado |
| 76.21-80.13 | 4 | Exploratorio |
| 80.14-84.07 | 5 | Moderadamente comprobado |
| 84.08-88 | 6 | Comprobado |
| >88 | 7 | Muy comprobado |
El histograma de frecuencia, de los 26 cruces evaluados dos o más veces en la etapa de lote clonal 1, demostró la efectividad de la clasificación a partir del VGE (Figura 2). En este caso, el 27 % de los cruces mostraron similar VGE y por ende clasificaron en el mismo grupo (diferencia cero). El 35 % mostró diferencias de un grupo, lo que unido al anterior asciende a 62 %. Este valor significa la probabilidad de clasificar una familia y que coincida su categoría o varíe en un grupo. Solo un 38 % cambió la clasificación en dos y tres grupos lo que evidencia la efectividad del método propuesto.
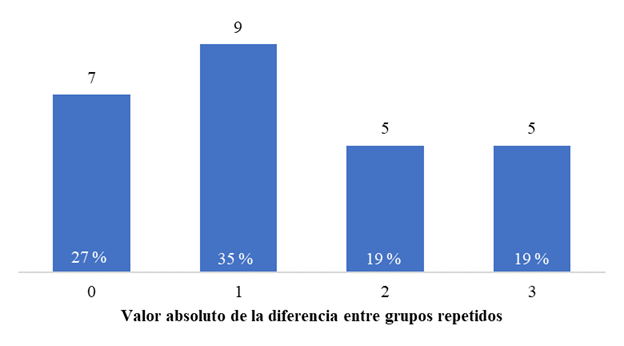
Figura 2 Diferencia de la clasificación entre grupos para los cruces evaluados dos o más veces en el lote clonal 1
Respecto a los cruces evaluados que aporta individuos a estudios replicados, el 67 % clasificaron en los grupos 5, 6 y 7 que van desde modernamente comprobado a muy comprobado (Figura 3). Del grupo 1 (muy descartado) no se cuantificó ningún cruce y de los grupos 2 y 3 (moderadamente descartado y descartado) solamente se encontraron 7 cruces (14 %). El grupo 4 (cruces exploratorios) representó un 19 %, lo que unido a los grupos 5, 6 y 7 sumaron 86 %, lo que evidencia una buena clasificación para establecer un sistema del valor de la familia comprobado o a descartar para el programa de selección genética en la caña de azúcar en Cuba.
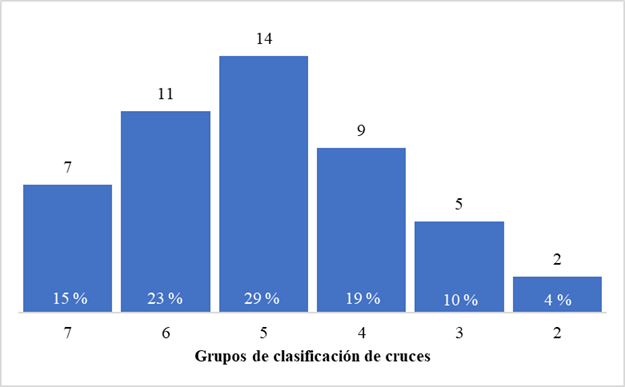 Grupo 2: DescartadoGrupo 3: Moderadamente descartadoGrupo 4: ExploratorioGrupo 5: Moderadamente comprobadoGrupo 6: ComprobadoGrupo 7: Muy comprobado
Grupo 2: DescartadoGrupo 3: Moderadamente descartadoGrupo 4: ExploratorioGrupo 5: Moderadamente comprobadoGrupo 6: ComprobadoGrupo 7: Muy comprobadoFigura 3 Histograma de frecuencia de la clasificación de los cruces por grupos que aportaron individuos a estudios replicados según el valor genético estimado (VGE)
Entre los cruces con individuos en estudios replicados se destacan Co312 x Co6806 y Co740 x CP70-1133 clasificados como muy comprobado (grupo 7) con aporte de seis y tres cultivares respectivamente (Figura 4). Otras familias, destacadas y clasificadas en el grupo 6 (comprobado) fueron: C90-501 x C86-531, C137-81 x C120-78, C229-84 x CP70-1133 y C86-12 x CP70-1133. Esta última aportó el cultivar C00-575 recomendado a explotación comercial por el programa de mejora de la región suroriental, lo que ratificala confiabilidad del procedimiento empleado. El cruce ClonT96-40 x CSG87-508, clasificado en el grupo 5 (moderadamente comprobado), produjo el cultivar C04-553 recomendado a extensión.
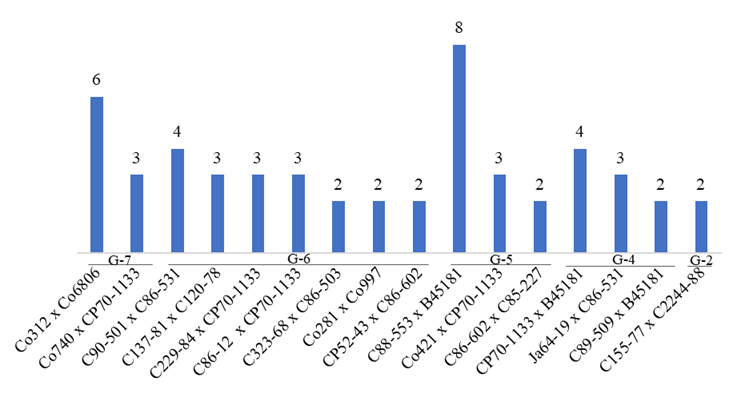 Grupo 2: DescartadoGrupo 4: ExploratorioGrupo 5: Moderadamente comprobadoGrupo 6: ComprobadoGrupo 7: Muy comprobado
Grupo 2: DescartadoGrupo 4: ExploratorioGrupo 5: Moderadamente comprobadoGrupo 6: ComprobadoGrupo 7: Muy comprobadoFigura 4 Frecuencia de individuos por cruces en estudios replicados y clasificación según su valor genético estimado
Estos resultados evidencian la efectividad de la clasificación realizada a los cruces a partir del VGE. De este modo, se propone una metodología o algoritmo para determinar la estrategia a seguir en las campañas de hibridación y selección en el programa de mejora genética de la caña de azúcar en Cuba (Figura 5).
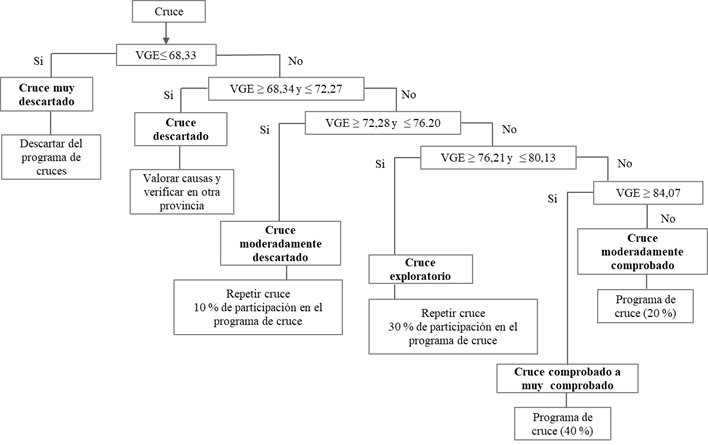
Figura 5 Algoritmo de clasificación y manejo de los cruces biparentales según su valor genético estimado (VGE) en el programa de mejora genética de la caña de azúcar en Cuba
Al determinar el VGE de un cruce si este es inferior a 68,33 % se clasifica como muy descartado y se retira del programa de cruzamientos. A partir de este valor se determinan el resto de las categorías, su manejo y proporción en el programa de cruce. Esta metodología permite darle un mayor peso a la predicción del valor familiar y su conducción en el proceso de mejora, así como reorientar la selección individual en aquellas familias de menor VGE.
En la literatura es frecuente encontrar trabajo relacionados con diferentes métodos de selección, predicción del valor genético o avances en los programas de mejoramiento genético. El uso de los modelos BLUP (Mejor Predictor Lineal no Sesgado) es el procedimiento más habitual. En este sentido se destaca el trabajo realizado en Brasil 13, donde sugieren el uso de los métodos BLUP en la selección familiar seguida de la individual para la identificación de los mejores genotipos. Sin embargo, los métodos BLUP(s) requieren gran cantidad de información de los individuos y de la familia, así como de su evaluación en campo bajo un diseño experimental 6.
En un estudio de selección de progenitores en Brasil, a través del uso de modelos mixtos, se informó que el progenitor CP70-1133 presentó un alto valor aditivo e índice de selección respeto a la variable ºBrix, lo que sugiere su uso en los programas de cruzamiento14. Los datos del VGE obtenidos para este cultivar confirman este resultado.
Otro método empleado en La Florida fue el uso de un índice sobre el vigor de los tallos y el ºBrixpara la selección de progenie en caña de azúcar 15. Estos investigadores sugieren el uso de la selección individual por encima de la selección familiar para encontrar clones con características deseadas.
Por otra parte, se ha informado del uso de un árbol de decisión como herramienta en la selección de familias en la caña de azúcar 6. Estos investigadores proponen este método para superar las dificultades de los métodos BLUP con relación al volumen de información que se necesita evaluar en el campo. Así, recomiendan el uso del árbol de regresión y clasificación para la selección de las mejores familias con una precisión del 74 %. El uso de este procedimiento, también, ha sido informado anteriormente 16,17.
Otros investigadores recomiendan el uso de índices de selección para determinar los mejores progenitores y así obtener progenies con rendimientos superiores 14. No obstante, el uso de uno u otro método o su combinación constituyen herramientas valiosas para evaluar progenitores y progenies y elevar la eficiencia en los programas de mejoramiento genético.
CONCLUSIONES
La determinación del valor genético estimado de los cruces permitió clasificarlos en siete categorías que comprenden los cruces muy descartado, descartado, moderadamente descartado, exploratorio, moderadamente comprobado, comprobado y muy comprobado.
La metodología de clasificación, a partir de la determinación del valor genético estimado de los cruces biparentales, permitió el diseño de la estrategia a seguir en las campañas de hibridación y selección en el programa de mejora genética de la caña de azúcar en Cuba.

