Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
El nivel de aplicación de la Bioestadística, como herramienta útil y rigurosa en el campo de la investigación, ha sido espectacular.1,2) Ventura-León, colaboradores,3) informan que un análisis del estado de la producción científica en ciencias de la salud, reveló que Latinoamérica había generado el 3.4% de la producción científica mundial, donde la herramienta estadística seleccionada para el análisis de la información garantiza la validez y su calidad, 2-4) aunque abordan contenidos aislados acerca de esta ciencia, sí profundizan en la necesidad de su utilidad para potenciar las investigaciones desde la interpretación y solución de problemas profesionales para arribar a conclusiones válidas y tomar decisiones razonables.2,5,6
El análisis estadístico se divide en dos componentes: 7 el análisis descriptivo y el análisis inferencial, las pruebas estadísticas, se fraccionan en paramétricas y no paramétricas. Sin embargo, la elección de una prueba estadística apropiada, representa un reto. 7,8
Elegir una prueba estadística se basa tres aspectos: el primero es el diseño de investigación. 8,9) El segundo aspecto es la cantidad y grado de independencia de los grupos de comparación, el alcance y tipo de investigación, de la aleatorización, el cálculo del tamaño de la muestra, el número de mediciones de las variables de resultado, que implica analizar de disímiles formas los cambios de una variable a lo largo de un periodo. El tercer aspecto es el tipo y escala de medición de las variables.1,8,9
En entrevistas realizadas a 30 profesionales, el 80% reconoció que no conocían sobre guías que les permitiera escoger el análisis para el tipo de datos (variables) y el diseño de su investigación (análisis univariado, bivariado o multivariable), en más del 95% de sus proyectos de investigación este aspecto era deficiente.
El uso incorrecto de las herramientas estadísticas y metodológicas produce investigaciones con discutible validez, con múltiples errores,10 desestimar este principio puede acarrear graves consecuencias a la calidad de la investigación.1,10,11
El objetivo de este trabajo consiste en proponer una “guía” a aquellos no expertos en bioestadística que les permita escoger un análisis estadístico sin la necesidad de poseer profundos conocimientos teóricos sobre la materia.
Métodos
Se realizó un estudio tipo revisión bibliográfica narrativa.12Para analizar el estado actual de la temática se valoran los artículos publicados en revistas indexadas en las bases de datos: Pubmed/Medline, SciELO, SCOPUS, Springer, Web of Science, EBSCOhost entre otras, entre enero y abril de 2022. En la estrategia de búsqueda se emplearon como descriptores: modelo matemático, análisis de datos, técnicas estadísticas, prueba estadística, gráficos estadísticos y diagrama causal.
Se consultaron 57 bibliografías donde másdel91% pertenece a los últimos cinco años y de ellas más del 75% a los últimos tres años. La selección de la literatura se basó en su carácter científico y actualizado e identificando en ellas regularidades y diferencias que permitieron elaborar los esquemas propuestos (Anexo 1 y Figura 1, Anexo 2 y Figura 2, Anexo 3 y Figura 3, Anexo 4 y Figura 4).
Para determinar la validez, pertinencia y factibilidad del instrumento se utilizó el criterio de expertos, mediante el Método Delphi.13-15) el grupo de expertos quedó conformado por un total de 15, seleccionados por su alto valor del coeficiente de competencia, comprendido en el rango de 0.8 < K< 1. Se apreció que ocho (8) de los expertos son Doctores en Ciencia, profesores o investigadores titulares y auxiliares, para un 53,33%; cinco (5) son Máster en Ciencia, para un 33,33% y los expertos tienen una media de 27,68 años de experiencia, en la investigación y la enseñanza de la Bioestadística; otro indicador fue el número de publicaciones, de participación en eventos y proyectos de investigación gerenciados, donde la media de los expertos es de 26,97;21.89 y 16,75 respectivamente, lo que garantiza su competitividad.
Se presentó la guía diseñada al grupo de expertos y se les entregó una planilla que relaciona cada una de las pruebas estadísticas, las que debían ser evaluados a través de una escala Likert de cinco puntos: 1. Totalmente en desacuerdo, 2. En desacuerdo, 3. Ni de acuerdo ni en desacuerdo, 4. De acuerdo y 5. Totalmente de acuerdo. Además, la concordancia entre los peritos se determinó mediante el coeficiente W de Kendall.16-17
La mayoría de los expertos se mostraron totalmente de acuerdo, al considerar que la propuesta garantiza la coherencia y las expectativas, teóricas y prácticas; así como la concepción estructural y metodológica para seleccionar una prueba, favorece el aprendizaje de la Bioestadísticay es aceptable su generalización en el proceso docente e investigativo, porque contribuye a enriquecer la cultura estadística en este contexto, corroborando su pertinencia.
También, se obtuvo un W de Kendall de 0,758, en el rango de 0,610,80, por lo que los evaluadores tuvieron un nivel de concordancia bueno.16
Además, se realizó una prueba piloto, la guía se aplicó a 92 tesis de especialidad, maestrías y una serie de investigaciones; se obtuvo que al 10,5% de los trabajos no se les realizó análisis estadísticos y en el 17,46% de los casos eran incorrectos o limitados para la complejidad del tema tratado.
A continuación, se indica cómo pueden utilizarse los esquemas (Anexo 1 y Figura 1, Anexo 2 y Figura 2, Anexo 3 y Figura 3, Anexo 4 y Figura 4).
Lo primero consiste en seguir el esquema hasta descubrir cuáles son las técnicas estadísticas apropiadas para una investigación. Luego debe identificar una, dos o más de dos variables dependientes (es decir no métricas: nominal, ordinal y métrica: de razón (son aquellas que poseen un cero real y, de intervalos (poseen un punto cero arbitrario) y una, dos o más variables independientes.
Una vez que haya tomado estas decisiones, el esquema lo conducirá siguiendo el dibujo a una medida de síntesis o a una estimación puntual útil para sus datos que muchas veces va seguida de una clasificación general de las pruebas estadísticas.
En ocasiones, el interés es comprobar si la prueba seleccionada por otros es apropiada, en ese caso el esquema debe seguirse hacia atrás, y determinar si la prueba es una elección lógica para los datos analizados.
Cuando utilice los esquemas (Anexo 1 y Figura 1, Anexo 2 y Figura 2, Anexo 3 y Figura 3) observe que:
Las medidas subrayadas con una sola línea son estimaciones muestrales puntuales (media, mediana, entre otras).
Las técnicas subrayadas con una línea doble se utilizan para realizar pruebas de significación estadística o para construir intervalos de confianza.
El tipo de las pruebas se indica con líneas horizontales por encima y por debajo.
La letra “o” indica que cualquiera de las pruebas es aceptable para responder a la misma pregunta; sin embargo, la prueba situada en primer lugar tiene más potencia estadística o se usa con mayor frecuencia, o ambas cosas a la vez.
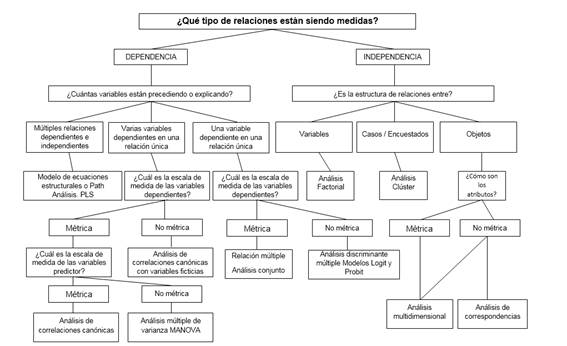
Cuando consideremos la aplicación de técnicas estadísticas multivariables (Anexo 3 y Figura 3 Anexo 4 Figura 4), la primera cuestión que debemos preguntar es:
¿Pueden dividirse las variables mediante clasificación de dependiente e Independiente, basándose esta clasificación en alguna teoría?
La respuesta a esta pregunta nos indica si debemos realizar un análisis de:
Dependencia: Es aquel donde una o un conjunto de variables es identificada como la variable dependiente y que será explicada por otras variables, conocidas como variables independientes.
Interdependencia: Es aquel donde ninguna variable o grupo de variables es definida como dependiente o independiente, más bien, el procedimiento implica el análisis de todas las variables del conjunto simultáneamente.
Si puede hacerse ¿Cuántas de estas variables son tratadas como dependiente en un análisis simple?
¿Cómo son las variables medidas?
Desarrollo
En una investigación aparecen errores:18,19) por falta de conocimiento, de planeamiento, de ejecución y estadísticos, que disminuyen la confiabilidad de los resultados, cancelan tareas, se produce pérdida de tiempo, de recursos humanos, de materiales y lo peor; la no solución de un problema de la ciencia. 1,18,20
Mientras que se comunican disimiles errores dentro de los que se destacan:1,21
Errores al definir la pregunta de investigación, problema del tema de investigación.
Definición de los objetivos, del problema, tipo de variable, la escala de medición, el indicador, del diseño de investigación, forma en que se procesan y analizan los datos.
No se prueban las hipótesis de base (normalidad, homogeneidad de varianza e independencia de errores) en el procesamiento estadístico de datos.
Inadecuada selección y aplicación de pruebas estadísticas, violación de los supuestos al aplicar las técnicas de inferencia estadística, aplicación inapropiada de los diseños muestrales, escasa contextualización e interpretación de los resultados de las técnicas estadísticas utilizadas y dificultades con el uso de los softwares estadísticos. 22
Estas insuficiencias se corresponden con conceptos de cultura estadística, razonamiento estadístico y pensamiento estadístico. (23,24) Esto incluye reconocer y comprender el proceso investigativo completo (desde la pregunta de investigación, como seleccionar la técnica para analizar los datos, probar las suposiciones, con la suficiente honradez científica). (1
Por otro lado, 25) al revisar una serie de investigaciones se obtuvo que al 14,5% de los trabajos no se les realizó análisis estadísticos. En el 16,4% de las publicaciones se hicieron análisis multivariados incluyendo los análisis de regresión y en el 1,8% se aplicó el análisis de superficie de respuesta, útil para el desarrollo y optimización de procesos.26
Otros revelan premisas para realizar los análisis estadísticos de una investigación, 1,21) la pregunta de investigación determinará el tipo de datos que se recolectaran y los análisis estadísticos a realizar, y definir las variables dependientes e independientes, define el uso de dos tipos de análisis estadísticos: la estadística descriptiva y la inferencial.26-29
Estadística descriptiva: describe las características básicas de los datos bajo estudio, proporciona resúmenes simples sobre la muestra y las mediciones realizadas e incluye:
Los estadísticos de tendencia central: describen la localización en la distribución, incluyen la media, mediana y moda.
Entre dichas medidas, la media requiere variables cuantitativas (de intervalo o razón y suele calcularse con datos ordinales). La mediana es un estadístico que requiere variables ordinales, es preferible a la media cuando la distribución es asimétrica. La moda sirve para todo tipo de variables, pero es más apropiada para caracterizar datos categóricos.
Los estadísticos de dispersión, miden la cantidad de variación en los datos, incluyen: desviación típica, varianza, rango, mínimo, máximo y error típico de la media, los dos primeros y el último poseen significado con variables cuantitativas (de intervalo o razón, en ocasiones en datos ordinales). El rango es apropiado para todo tipo de variables, menos para las nominales, donde no tiene sentido hablar de dispersión.1,29-31
La asimetría y curtosis son estadísticos que describen la forma y la simetría de la distribución, solo tiene sentido calcularlos con variables cuantitativas. 1,29-31
Los estadísticos que miden la posición son los percentiles, cuantiles: cuartiles, deciles, percentiles, entre otros y carecen de significado calcularlos para variables nominales.19-21
Las llamadas puntuaciones típicas o puntuaciones z (z scores), expresan el número de desviaciones típicas que cada valor se aleja de su media.1,29-32
Estadística inferencial: describe y hace inferencias sobre la población utilizando una muestra aleatoria de datos extraída de la misma, tiene dos aspectos: (a) se utiliza para estimar los intervalos de confianza y (b) las pruebas de hipótesis para determinar el grado de diferencia o relación que existen entre grupos de variables, donde, se busca determinar si esta diferencia o relación se debe al azar.1,29-33
A su vez, las pruebas de hipótesis se clasifican en: a) las pruebas paramétricas: en las que se realizan presuposiciones sobre la distribución de las variables en las poblaciones que están comparándose; b) las pruebas no paramétricas, menos potentes que las paramétricas; donde la variable respuesta no posee una distribución normal o aquellas en las que no es posible determinar si se cumplen las asunciones. 1,32,33
Las ventajas de las pruebas no paramétricas son:
Sencillas, mediante fórmulas simples.
Fáciles de aplicar, con operaciones de jerarquización, conteo, suma y resta.
Pequeñas, son fáciles de usar.
Se aplican a los grupos mayores de poblaciones.
Son menos susceptibles a la contravención de los supuestos.
Se usan con datos ordinales o nominales.
Cuando la muestra es menor de 10 son sencillas, rápidas y menos eficaces.
Son igual de efectivas una prueba no paramétrica si se cumplen los supuestos de normalidad, independencia de los términos del error, homogeneidad de varianza y aditividad de los efectos de los tratamientos.1,29,32,33
Siguiendo la secuencia de los Anexo 1 y Figura 1, Anexo 2 y Figura 2, Anexo 3 y Figura 3 Anexo 4 y Figura 4, tomando en cuenta la escala de medición de las variables, si se comprueba que los datos no siguen una distribución normal, (ya sean nominales u ordinales) y las cuantitativas discontinuas se elegirá una de las pruebas no paramétricas y para determinarlo existen los test de Shapiro-Wilks (muestras pequeñas < 30), - Kolmogorov-Smirnoff o sesgo de - 0.5 a + 0.5 y curtosis de 2 a 4.1,28-33
Las pruebas de significancia estadística son métodos estadísticos que permiten contrastar las hipótesis para valorar los efectos del azar. 1,26-28) El procedimiento estadístico aplicable al problema de la significancia estadística de una prueba, va a depender de: 29,33
El diseño estadístico seleccionado para la investigación.
La distribución de casos en uno, dos o más grupos.
El tipo de medida o variable a analizar.
La manera en que se distribuyan las variables, la homogeneidad de las varianzas en los grupos, el impacto de los residuos y el tamaño de la muestra.
El poder de la prueba, es decir, la capacidad para aceptar o rechazar la hipótesis nula.
Los autores, 1,29,31-33) comentan algunas pruebas para la comparación de grupos más utilizadas y puede comprobar su uso en el Anexo 1 y Figura 1, Anexo 2 y Figura 2, Anexo 3 y Figura 3, Anexo 4 y Figura 4. Si el investigador quiere comparar dos grupos con variables cuantitativas continuas y con distribución normal, se puede elegir una prueba t (hay diferentes, la más conocida es la denominada t de Student).
Tomando en cuenta lo descrito, esta prueba puede utilizarse en dos escenarios diferentes:
Muestras relacionadas (un solo grupo antes y después).
Muestras independientes (comparación de dos grupos). Ahora bien, si lo que se desea es comparar tres o más grupos (comparación de tres o más promedios) se debe seleccionar una prueba denominada análisis de varianza o ANOVA (del inglés “Analysis of Variance”). 1,29,31,32
De esta última prueba se distinguen dos variantes: ANOVA de una vía, cuando se comparan los promedios de tres o más grupos independientes, y ANOVA de dos vías, cuando se comparan los promedios de muestras relacionadas medidas tres o más veces.1,29,32-34
Cuando la variable dependiente no sigue una distribución normal, hay pruebas estadísticas con las que se comparan las medias. Para la comparación de dos grupos independientes se emplea la U de Mann-Withney.26-28,31,33) En el caso de tres o más grupos independientes se utiliza la prueba de Kruskal-Wallis (la cual es equivalente a ANOVA de una vía),la prueba de Wilcoxon se utiliza para comparar un grupo antes y después (muestras relacionadas) y la prueba Friedman se usa cuando se comparan tres o más muestras relacionadas (equivalente a ANOVA de dos vías).1,29,32,33,35
Como se señala en el Anexo 2 y Figura 2, Anexo 3 y Figura 3, existen pruebas para la comparación de grupos cuando la escala de medición de las variables es cualitativa. En caso de comparar tres o más grupos independientes, se utiliza Ji-cuadrada (X2); en caso de muestras relacionadas, la Q de Cochran. Si emplea las pruebas de comparación de proporciones, cuando el número de datos sea menor a 30 se aplicarán la corrección de Yates, la prueba exacta de Fisher se utilizará en lugar de χ2 cuando se comparan dos grupos independientes si en algunas de las casillas de la tabla de contingencia se encuentra algún valor menor de 5.29,31-33,35
Resumiendo, la aplicación de los test paramétricos presenta requisitos que deben cumplir los datos: independencia, normalidad, homogeneidad de varianzas (homocedasticidad), -Outliers, - No linealidad, - Colinealidad, - Datos perdidos (“Missing” data).1,28,30-35
En el caso del ANOVA, además debe cumplirse que las medias de las poblaciones normales y homocedásticas deben ser combinaciones lineales de los efectos debidos a columnas o líneas, es decir los efectos deben ser aditivos.26-29) No obstante, los test paramétricos suelen ser “robustos” frente a las violaciones de estos requisitos.32,33
La independencia se consigue con un diseño experimental (o de muestreo) adecuado. Si los datos no son independientes hay que utilizar técnicas para analizarlos (modelos mixtos). La normalidad y la homocedasticidad (en el caso de variables continuas) se pueden conseguir a través de transformaciones (por ejemplo aplicando logaritmos). Los errores deben distribuirse aleatoriamente entre las observaciones. Ello implica que la selección de un individuo en la población de estudio no puede influir sobre las probabilidades de inclusión de cualquier otro. El test estadístico para comprobar la independencia de errores es la I de Moran y el test de Durbin-Watson.
Las observaciones deben ser normales, para comprobar se usan los testya señalados y diagnósticos gráficos como: - Boxplots, - Quantile-Quantile (Q-Q) plots.
La homocedasticidad. Para comprobarla utilizar: Test de Bartlett, Test de Levene, Test de Welch (Heterogeneidad de las varianzas) y Diagnósticos gráficos: - Residual pattern.
Las variables implicadas deben haber sido medidas en por lo menos una escala de intervalos de manera que sea posible usar las operaciones aritméticas.
Las alternativas para la falta de normalidad y homocedasticidad, además de las pruebas no paramétricas antes señaladas son: la transformación logarítmica [log (Y) o log (Y +1)], la raíz cuadrada [√Y o √Y+0.5] y el arcseno [arcsen (Y/100)] si la variable dependiente es de datos continuos, de conteos y de proporciones respectivamente; uso de otras distribuciones para datos continuos como: Normal, Lognormal, Gamma y para datos discretos: Poisson, Binomial negativa, Binomial.
Outliers. Valores inusualmente grandes o pequeños respecto al conjunto de los datos observados, se recomienda: identificarlos mediante los test: Dixon’s Q test, Cook’s D statistic y gráficos: boxplot, scatterplot. ¿Qué hacer con ellos?: si estás seguro: ignóralo (queda un diseño desbalanceado); si dudas: comprueba el efecto sobre los resultados.
No linealidad: linealizar mediante la transformación de las variables con la: - Función exponencial: Y = a*exp (b*X) ó Y = log (a*exp (b*X)) = log (a) + b*X. - Función potencial: Y = a*X b ó log (Y) = log (a*X b) = log (a) + log (X b) y usar modelos como Michaelis-Menteny GAM (Modelos Aditivos Generalizados) que capturen la no-linealidad.
Colinealidad de predictores. Para su detección se comprueba el valor de “tolerancia” (o su inversa, “variance inflation factor” o VIF).Soluciones: retener sólo uno de entre un grupo de predictores correlacionados, hacer un ACP (Análisis de Componentes Principales) y trabajar con las variables compuestas.
Cuando se desea analizar (Anexo 2 y Figura 2) la relación de dos variables, se brindan indicaciones para el análisis, 1,26-30) por ejemplo, cuando ambas variables (factores) son:
Cuantitativas continuas con distribución normal, se utilizará el coeficiente de correlación de Pearson (r de Pearson), si una de las dos variables no es normal, se utiliza el coeficiente de correlación de Spearman (rho de Spearman).
Nominal. Para los datos nominales, puede seleccionar el Coeficiente de contingencia, Phi (coeficiente) y V de Cramer, Lambda (lambdas simétricas y asimétricas y tau de Kruskal y Goodman) y el Coeficiente de incertidumbre.
Coeficiente de contingencia. El valor varía entre 0 y 1. El valor 0 indica que no hay asociación entre las variables.
Phi y V de Cramer. Ambas y la anterior son una medida de asociación basada en X2, en el caso de Phi, varía de 0a +1, donde “cero” implica ausencia de correlación entre variables y +1 significa que están correlacionadas perfectamente. V de Cramer es un ajuste de Phien tablas mayores de 2x2, varía de 0a +1 con variables nominales “0” es nula correlación y +1 es correlación perfecta.
Lambda. Medida de asociación que refleja la reducción proporcional en el error cuando se utilizan los valores de la variable independiente para pronosticar los valores de la variable dependiente. Un valor igual a 1 significa que la variable independiente pronostica perfectamente la variable dependiente y si es igual a “0” significa lo opuesto.
Coeficiente de incertidumbre. Medida de asociación que refleja la reducción proporcional en el error cuando se utilizan los valores de una variable para pronosticar los valores de la otra variable. Por ejemplo, un valor de 0,83 indica que conocer una variable reduce en un 83% el error al pronosticar los valores de la otra variable.
Ordinal. Seleccione Gamma (orden cero para tablas de doble clasificación y condicional para tablas cuyo factor de clasificación va de 3 a 10), Tau-b de Kendall y Tau-c de Kendall. Gamma. Medida de asociación simétrica entre dos variables ordinales cuyo valor está entre -1 y 1. Los valores próximos a 1, indican una fuerte relación entre las dos variables. d de Somers. Medida de asociación entre dos variables ordinales que toma un valor entre -1 y 1. Los valores próximos a 1, en valor absoluto, indican una fuerte relación entre las dos variables. La d de Somers es una extensión asimétrica de gamma.
Tau-b de Kendall. Medida no paramétrica de la correlación para variables ordinales o de rangos que tiene en consideración los empates. El signo del coeficiente indica la dirección de la relación y su valor absoluto indica la fuerza de la relación. Los valores mayores indican que la relación es más estrecha. Los valores posibles van de -1 a 1, pero un valor de -1 o +1 sólo se puede obtener, como el siguiente, a partir de tablas cuadradas.
Tau-c de Kendall. Medida no paramétrica de asociación que ignora los empates. El signo del coeficiente indica la dirección de la relación y su valor absoluto indica la fuerza de la relación. Los valores posibles van de -1 a 1, pero un valor de -1 o +1.
El coeficiente Eta cuantifica el grado de asociación entre una variable cuantitativa otra nominal, y el cuadrado se puede interpretar como la proporción de varianza de la variable cuantitativa que es explicada por la nominal. Un coeficiente, con valor 0 y 1 indican que no hay y que existe asociación entre las variables respectivamente.
Kappa. La kappa de Cohen y la w de Kendall miden el acuerdo entre las evaluaciones de dos o más jueces cuando se están valorando el mismo objeto o evalúa el acuerdo existente entre las clasificaciones de jueces diferentes sobre la misma muestra de sujetos. Un valor igual a 1 indica un acuerdo perfecto y un valor igual a cero indica que no hay acuerdo.
Riesgo. Las más empleadas son tres: 1- Riesgo relativo (RR) aplicable a los estudios longitudinales (de seguimiento) ya sean experimentales (ensayos clínicos aleatorios) u observacionales (de cohorte), en los estudios de casos y controles se utiliza el OR que es una estimación indirecta del riesgo relativo y en los estudios de corte transversal se utilizan la razón de prevalencias para enfermedades agudas y la razón de momios de prevalencia para enfermedades crónicas. 2- Riesgo atribuible o diferencia de riesgos: permite diferenciar el efecto absoluto de la exposición y expresa la proporción de individuos expuestos que, por efecto de la exposición, desarrollarán la consecuencia.3- Fracción etiológica o porcentaje de riesgo atribuible: permite estimar la proporción del riesgo o el efecto observado en los sujetos expuestos, que es atribuible a la exposición.
McNemar. Prueba no paramétrica para dos variables dicotómicas relacionadas en los diseños del tipo "antes-después". Para las tablas cuadradas de mayor orden se informa de la prueba de simetría de McNemar-Bowker.
Estadísticos de Cochran y de Mantel-Haenszel. Esta prueba se emplea en tablas 2 x 2 de diseños de cohortes o de caso-control cuando interviene una tercera variable, contrastan la hipótesis de independencia condicional, es decir la hipótesis entre la variable dependiente problemas vasculares y la variable factor tabaquismo, controlando la tercera variable como dieta: alta o baja en grasas.
El procedimiento Distancias,31-34 calcula estadísticos que miden las similitudes o diferencias (distancias), entre pares de variables o entre pares de casos, que después, se utilizan con otros procedimientos, como análisis factorial, análisis de conglomerados o escalamiento multidimensional y ayudar en el análisis de datos complejos.30,31,35-39
Mientras, que la Regresión lineal simple (RLS) permite examinar la relación lineal entre dos variables continuas, normales, independientes y con igual varianza: una respuesta (Y) y un predictor (X). Además, se aclara que aquí se hace referencia al "coeficiente de correlación lineal de Pearson" r, este coeficiente nos da una medida de la fuerza y sentido de la relación lineal entre dos variables, su valor oscila entre -1 y +1, siendo cero cuando las variables no están relacionadas linealmente. También la RLS se utiliza para determinar la cantidad de varianza explicada por la variable dependiente, por ejemplo, si el coeficiente de correlación R es igual a 0.8, la ecuación explica el 0.64 de la varianza (R 2 = 64 %). 35-38
El coeficiente de determinación R2 es una medida de bondad del ajuste y mide cuan bueno es un modelo cualquiera (no necesariamente lineal y no necesariamente con una sola variable independiente o dependiente), representa la proporción de varianza de la variable respuesta explicada por el modelo, su valor oscila entre 0 y 1 aunque se suele expresar en porciento, cuanto más alto su valor, mejor el modelo. Existe también el R2 ajustado que corrige el hecho de que cuanto más variables explicativas, significativas o no, tenga el modelo, más alta va a ser la medida del R2. Es por eso que esta es la medida que se prefiere para comparar los modelos.
Sólo en el modelo lineal simple el coeficiente de determinación R2 coincide con el cuadrado de la correlación lineal de Pearson r2 (R2= r2), y aun así, no representan lo mismo.
La Regresión lineal múltiple (RLM), determina el efecto de más de una variable independiente en una dependiente, y cuando no se cuenta con los controles de los diseños experimentales, se utiliza la RLM para controlar esas diferencias no deseadas.
En la Regresión logística (RL) y de Cox describen la relación entre un grupo de variables independientes y una dependiente de tipo categórico, aquí la variable objeto de estudio puede ser tiempo de supervivencia (y por extensión, tiempo hasta que ocurre un suceso) o categórica dependiente del tiempo y pueden estar o no censurados los datos. Los tipos RL son la: regresión logística binaria; regresión logística ordinal; y regresión logística nominal o multinomial. 30,33,37
Cuando los datos están estructurados de manera jerárquica,27-29,33 el análisis para ese tipo de datos son los modelos lineales multinivel (MLM), también llamados modelos jerárquicos lineales o modelos lineales mixtos. (30,31,37-41
Los MLMx, 1,12-14 (Modelo Lineal Mixto) tienen otras ventajas como: no es necesario tener en cuenta las asunciones de homogeneidad de las pendientes de regresión, los datos no deben ser independientes y para ellos los datos perdidos no son un problema, a diferencia de los distintos tipos de regresiones, test ANOVA, ANCOVA, entre otras. 30,31,33,37,40
Los modelos multinivel, se clasifican en modelos lineales y no lineales, en el primer grupo sitúa modelos con una variable dependiente continua como: los modelos de medias repetidas (que permiten ver las medias de los diferentes niveles), de diseños cruzados (dónde un individuo pertenece a grupos diferentes) y de meta-análisis. 30,33,38-41
En el segundo aúna modelos que contemplan una variable dependiente discreta, se menciona el Modelo Logístico y Regresión Logística Multinivel, 32,38-41) dónde la variable dependiente se expresa en dos valores de forma dicotómica, el Modelo Multinomial dónde la variable es categórica con más de dos valores, el Modelo Poisson que cuenta las veces o situaciones que se da un suceso y los Modelos de Supervivencia que miden un período de tiempo hasta suceder un episodio predefinido como enfermar o fallecer. 37-39
El análisis de sendero (Anexo 4 y Figura 4), es un caso especial de modelización de ecuaciones estructurales (SEM), se utiliza para describir las dependencias directas entre un conjunto de variables. Esto incluye modelos equivalentes a cualquier forma de análisis de regresión múltiple, análisis factorial, análisis de correlación canónica, análisis discriminante, así como familias más generales de modelos en el análisis multivariante de varianza y análisis de covarianza, ANOVA, MANCOVA, entre otros.32,38-41
Los modelos de Regresión de mínimos cuadrados parciales (PLS), combinan el ACP y la regresión múltiple, donde las variables dependientes e independientes pueden ser de escala, nominales u ordinales. La PLS es una técnica de predicción alternativa a la regresión de mínimos cuadrados ordinarios (OLS), a la correlación canónica o al SEM, útil si el número de predictores es superior al número de casos. 30,32
Los métodos multivariados de análisis (MMA) se utilizan con fines de predicción, descripción o de estimación del efecto de las variables independientes controlando las variables confusoras y entre los métodos predictivos conocidos se encuentran la regresión logística y la de Cox. Las técnicas que identifican variables dependientes como independientes (métodos de dependencia) son: el análisis discriminante, el análisis conjunto, los modelos de segmentación jerárquica). 32,38-44
Entre las técnicas descriptivas (métodos de interdependencia) que no distinguen las variables independientes de las dependientes, tenemos: el análisis factorial, el ACP, el análisis de conglomerados, el análisis de correspondencia, los árboles de clasificación y el escalamiento multidimensional. Además, existen métodos de respuesta múltiple, donde se explica más de una variable, como es el caso del análisis canónico.
Las técnicas de análisis que se aplican a la investigación aplicada son: el análisis de la variancia (AVAR), el análisis de la covariancia (ACOVAR), el análisis de la regresión múltiple (ARM), el análisis de series temporales (modelos ARIMA), el análisis multivariado de la variancia (AMVAR), el análisis de correlaciones cruzadas en panel (ACCP), el análisis de la regresión (AR) y los modelos lineales de ecuaciones estructurales (LISREL). 32,33,37-44
Las investigaciones que realizan mediciones repetidas en el tiempo en las mismas unidades experimentales, estas se hallan correlacionadas, y se incumplen los supuestos de independencia, normalidad, homocedasticidad y linealidad. 28-32) se utilizan los Modelos Lineales Mixtos (MLMx) y los Modelos Lineales Generalizados Mixtos (MLGMx), por sus ventajas con respecto a los tradicionales. 30,31,33,37-39) Se obtiene una mayor eficiencia mediante el uso de ecuaciones de estimación generalizada (EEG).30
Los tipos de modelos disponibles se agrupan por el tipo de la variable respuesta o variable dependiente, la cual puede distribuirse según una distribución normal (Modelo Lineal General) o de otro tipo (Modelos Lineales Generalizados). 30
La opción Modelos avanzados del IBM SPSS Statistics proporciona procedimientos que ofrecen opciones de modelado más avanzadas. (30,38
MLG Multivariado amplía el modelo lineal general que proporciona MLG Univariado al permitir varias variables dependientes. Una extensión adicional, GLM Medidas repetidas, permite las medidas repetidas de varias variables dependientes.
Análisis de componentes de la varianza descompone la variabilidad de una variable dependiente en componentes fijos y aleatorios. Este procedimiento es de interés para el análisis de modelos mixtos, como los diseños split-plot, los diseños de medidas repetidas univariados y los diseños de bloques aleatorios.
Los MLMx amplían el modelo lineal general de manera que los datos puedan presentar variabilidad correlacionada y no constante. El procedimiento Modelos lineales mixtos ajusta otros modelos lineales mixtos, incluyendo los modelos multinivel, los modelos lineales jerárquicos y los modelos con coeficientes aleatorios.
Los modelos lineales generalizados (GZLM) relajan el supuesto de normalidad y requieren que la variable dependiente esté relacionada linealmente con los predictores mediante una transformación o función de enlace. El GZLM cubre modelos, como la regresión lineal para las respuestas distribuidas normalmente, modelos logísticos para datos binarios, modelos loglineales para datos de recuento, modelos log-log complementario para datos de supervivencia censurados por intervalos, además de otros modelos especificados a través de la propia formulación general del modelo.
Las EEG amplían los GZLM para permitir medidas repetidas y otras observaciones correlacionadas, como datos conglomerados. La respuesta puede ser de escala, de recuentos, ordinal, binaria o eventos en ensayos.
El análisis loglineal general ajusta modelos a datos de recuento de clasificación cruzada y la selección del modelo del análisis loglineal ayuda a elegir entre modelos.
El análisis loglineal logit permite ajustar modelos loglineales para analizar la relación existente entre una variable dependiente categórica y uno o más predictores categóricos.
Puede realizar un análisis de supervivencia a través de tablas de mortalidad; análisis de supervivencia de Kaplan-Meier y regresión de Cox para modelar el tiempo de espera hasta un determinado evento, basado en los valores de las variables especificadas.
El procedimiento de escalamiento óptimo de datos categóricos, 31,40-44) permiten analizar datos categóricos que son difíciles o imposibles de analizar por los procedimientos estadísticos estándar, datos caracterizados por tener: - Observaciones insuficientes, - Demasiadas variables y - Demasiados valores por cada variable.
Las técnicas que se incluyen en cuatro de estos procedimientos son: Análisis de correspondencias (AC), Análisis de correspondencias múltiple (ACM), Análisis de componentes principales categórico (ACPC) y Análisis de correlación canónica no lineal (ACCNL) corresponden al área del análisis conocido como reducción de dimensiones.
A continuación, se indican normas para cada uno de los procedimientos: 31,32,38,40-44
Utilice la regresión categórica para pronosticar los valores de una variable dependiente categórica a partir de una combinación de variables independientes categóricas.
Utilice el ACPC para tener en cuenta los patrones de variación de un único conjunto de variables con varios tipos de niveles de escalamiento óptimos.
Utilice el (ACCNL) para evaluar el grado de correlación entre dos o más conjuntos de variables de varios tipos de niveles de escalamiento óptimo.
Utilice el análisis de correspondencias para analizar tablas de contingencia de doble clasificación o datos que se puedan expresar como una tabla de doble clasificación, como la preferencia por una u otra marca o datos de opción sociométricos.
Utilice el ACM para analizar una matriz de datos multivariantes categóricos cuando no se está dispuesto a suponer que todas las variables se analizan a nivel nominal.
Utilice el escalamiento multidimensional y el desplegamiento multidimensional para analizar datos de proximidad para buscar una representación de un solo y dos conjuntos de los objetos en un espacio de pocas dimensiones.
El análisis conjunto es una técnica estadística utilizada para analizar la relación lineal o no lineal entre una variable dependiente (o endógena) generalmente ordinal (aunque puede ser métrica) y varias variables independientes (o exógenas) no métricas.45
El Análisis de conglomerados de K medias permite procesar un número ilimitado de casos, pero sólo permite utilizar un método de aglomeración y requiere que se proponga previamente el número de conglomerados que se desea obtener.
Por otro lado, el Análisis de conglomerados jerárquico permite aglomerar tanto casos como variables y elegir entre una gran variedad de métodos de aglomeración y medidas de distancia, siendo su principal diferencia respecto al primero, el hecho de que procede de forma “jerárquica”.45
Los árboles de decisión pertenecen a la minería de datos (Data Mining, DM), se aplican en psicología y medicina, prepara, sondea y explora los datos para sacar la información oculta en ellos, se aborda problemas de predicción, clasificación y segmentación.32
Dentro de los modelos de segmentación se incluyen entre los modelos a priori, el análisis loglineal, la regresión logística o el análisis discriminante, y entre los modelos post hoc, se encuentran el análisis factorial (Q análisis), el análisis clúster, las redes neuronales artificiales, la inducción de reglas o las técnicas de clasificación arborescentes, también denominadas de segmentación jerárquica, como los métodos CHAID, CHAID Exhaustivo, CART, QUEST. 46-47
El último año, para prever la evolución de la COVID-19 se utilizan: modelo de media móvil, integrado regresivo automático (ARIMA), y métodos de suavizado exponencial lineal de Brown / Holt. 48-50
El análisis estadístico implicativo, conocido por las siglas ASI de Analyse Statistique Implicative, es una herramienta de la minería de datos, que ha probado su valía en el estudio de la causalidad en ciencias médicas. 51-54
En una investigación, la elección de un método de análisis adecuado evita llegar a conclusiones erróneas, implica basarse en criterios que dependerán de los objetivos e hipótesis, de la pregunta de investigación, del tipo de estudio: descriptivos o analíticos, el tamaño de la muestra, el método de muestreo, la escala de medida de las variables y del carácter apareado o independiente de los grupos de comparación. 55
Los sesgos pueden ocurrir por un sinfín de causales, se acepta que los más relevantes son aquellos debidos al que mide, lo que se mide y con que se mide. Otra consideración a tener en cuenta es que un error ocurre en cualquier etapa de una investigación, desde la planificación a la presentación y la publicación de los resultados.56
Lo anterior ayuda a comprender lo complejo que resulta la aplicación de la estadística en la investigación biomédica, 57) y del impacto de los errores en la calidad del estudio. (55) No estar consciente de esta realidad acarrea graves consecuencias a la investigación.
La sociedad del conocimiento demanda nuevos procesos de formación, esta herramienta favorece la formación integral, y supone una visión multidimensional del individuo, desarrollando su inteligencia emocional, intelectual, social, ética y material. 55
Todo lo anterior nos motivó a recopilar una serie de herramientas estadísticas y ponerlas al servicio de docentes, estudiantes e investigadores, los tutores de tesis, en forma de guión general como un recurso para su desarrollo profesional sin incurrir en explicaciones teóricas sobre cada instrumento.
Conclusiones
La Estadística proporciona las técnicas adecuadas para la recolección, organización y análisis de los datos. Este estudio es un intento de aportar una guía útil para seleccionar una técnica estadística a partir de las contribuciones procedentes de la revisión bibliográfica y reflexiones nacidas de la experiencia profesional del equipo de investigadores e incorporando las aportaciones del grupo de expertos.