










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Cubana de Informática Médica
versión On-line ISSN 1684-1859
RCIM vol.8 supl.1 Ciudad de la Habana 2016
ARTÍCULO ORIGINAL
Algoritmos de aprendizaje automático para la clasificación de neuronas piramidales afectadas por el envejecimiento
Machine learning algorithms for classification of pyramidal neurons affected by aging
Duniel Delgado Castillo,I Rainer Martín Pérez,II Leonardo Hernández Pérez,IIIRubén Orozco Morález,IV Juan Lorenzo GinoriV
I Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI), Universidad Central de Las Villas (UCLV), Villa Clara, Cuba. E-mail: duniel.delgado@etecsa.cu
II Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI), Universidad Central de Las Villas (UCLV), Cuba. E-mail: rainer.martin@etecsa.cu
III Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI), Universidad Central de Las Villas (UCLV), Cuba. E-mail: leonardo.hernadez@etecsa.cu
IV Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI), Universidad Central de las Villas (UCLV), Cuba. E-mail: rorozco@uclv.edu.cu
V Centro de Estudios de Electrónica y Tecnologías de la Información (CEETI) Universidad Central de las Villas (UCLV), Cuba. E-mail: juanl@uclv.edu.cu
RESUMEN
Una caracterización morfológica precisa de las múltiples clases neuronales del cerebro facilitaría la elucidación de la función cerebral y los cambios funcionales que subyacen a los trastornos neurológicos tales como enfermedades de Parkinson o la Esquizofrenia. El análisis morfológico manual es muy lento y sufre de falta de exactitud porque algunas características de las células no se cuantifican fácilmente. Este artículo presenta una investigación en la clasificación automática de un conjunto de neuronas piramidales de monos jóvenes y adultos, las cuales degradan su estructura morfológica con el envejecimiento. Un conjunto de 21 características se utilizaron para describir su morfología con el fin de identificar las diferencias entre las neuronas. En este trabajo se evalúa el desempeño de cuatro métodos de aprendizaje automático populares en la clasificación de árboles neuronales. Los métodos de aprendizaje de máquinas utilizadas son: máquinas de vectores soporte (SVM), k-vecinos más cercanos (KNN), regresión logística multinomial (MLR) y la red neuronal de propagación hacia atrás (BPNN). Los resultados mostraron las ventajas de MLR y BPNN con respecto a los demás para estos fines. Estos algoritmos de clasificación automáticaofrecen ventajas sobre la clasificación manualbasada en expertos.Mientras que la neurociencia está pasando rápidamente a datos digitales, los principios detrás de los algoritmos de clasificación automática permanecen a menudo inaccesibles para los neurocientíficos, lo que limita las posibilidades de avances.
Palabras Clave: neuronas, neuroinformática, aprendizaje automático, clasificadores.
ABSTRACT
Accurate morphological characterization of the multiple neuronal classes of the brain would facilitate the elucidation of brain function and the functional changes that underlie neurological disorders such as Parkinson's diseases or Schizophrenia. Manual morphological analysis is very time-consuming and suffers from a lack of accuracy because some cell characteristics are not readily quantified. This paper presents an investigation in the automatic classification of a data set of pyramidal neurons of young and adult monkeys, which degrade his morphologic structure with the aging. A set of 21 features were used to describe their morphology in order to identify differences between neurons. Thispaper evaluates the performance of four popular machine learning methods, in the classification of neural trees. The machine learning methods used are: support vector machines (SVMs), k-nearest neighbors (KNN), multinomial logistic regression (MLR) and back propagation neural network (BPNN). The results showed the advantages of MLR and BPNN with respect to others for this purposes. These automatic classification algorithms offer advantages over manual expert based classification. While neuroscience is rapidly transitioning to digital data, the principles behind automatic classification algorithms remain often inaccessible to neuroscientists, limiting the potential for breakthroughs.
Key Words: neurons, neuroinformatics, machine learning, classifiers.
INTRODUCCIÓN
La comprensión de cómo funciona el cerebro es, sin duda, uno de los desafíos más grandes para la ciencia moderna. La adquisición de un conocimiento profundo de la estructura, la función, y el desarrollo del sistema nervioso son de importancia crucial en el tratamiento de trastornos neurológicos y psiquiátricos. Una caracterización morfológica precisa de las múltiples clases neuronales del cerebro facilitaría la elucidación de la función cerebral y los cambios funcionales que son la base de los trastornos neurológicos. Los cambios morfológicos sutiles están a menudo correlacionados con el estado funcional de las neuronas, y por lo tanto con la enfermedad asociada.
Los neurobiólogos clasifican imágenes de microscopía de forma manual, pero en casi todos los casos, la precisión no es alta, debido a que algunas características de las células son difíciles de reconocer a través de un análisis manual. Además, algunas de las características no parecer ser eficaces en la clasificación, pero desempeñan un papel esencial como un componente de un conjunto de características eficaces.1 La clasificación manual también consume mucho tiempo; por lo tanto es costosa para los expertos a los efectos de clasificación. Técnicas de aprendizaje automático se utilizan comúnmente para resolver problemas de clasificación en una gran variedad de campos. Estudios recientes que aplican técnicas de aprendizaje automático para problemas de neurobiología muestran su ventaja significativa. Por ejemplo aplicar BPNN en un problema de selección de genes muestra un nivel relativamente alto de exactitud.2 Un MLR modificado alcanzó un en 92 % de precisión en la clasificación de las células normales/tumorales en el colon;3 y un SVM modificado clasificó los datos de expresión génica de tejido de cáncer con un alto nivel de precisión.4 La clasificación puede hacerse rápidamente y con precisión utilizando técnicas de aprendizaje de máquina, proporcionando así una significativa ventaja para la investigación neurobiológica.
Materiales y Métodos
Las técnicas de aprendizaje automático utilizadas en la clasificación de los árboles neuronales son máquinas de soporte vectorial, k vecinos más cercanos, regresión logística multinomial y red neuronal de propagación hacia atrás. La base de datos utilizada en la clasificación consiste en un conjunto de neuronas provenientes de monos adultos y otro conjunto de monos jóvenes, las mismas están disponibles en http://neuromorpho.org
Máquinas de soporte vectorial (SVM)
Las máquinas de vectores soporte tienen una fundamentación matemática pura dentro de la teoría estadística de aprendizaje, a pesar de esto, la implementación básica cuenta con algunas limitaciones puesto que están diseñadas originalmente para problemas de clasificación binarios (dos clases),5 y además tienen como limitante que su algoritmo básico de entrenamiento genera gran cantidad de vectores soporte lo que ocasiona lentitud en la clasificación. Sin embargo constituyen una poderosa y robusta herramienta destinada a labores de clasificación. La misma ha sido usada en el campo de la neuroinformática como se puede ver en.1
Este algoritmo se basa en mapear los puntos de entrenamiento a un espacio vectorial de una dimensión mayor, construir hiperplanos en un espacio multidimensional para separar los puntos en sus clases respectivas y clasificar un punto nuevo de acuerdo a su ubicación con respecto al hiperplano de separación.6
Los k vecinos más cercanos (KNN)
El método de los k vecinos más cercanos (KNN, K Nearest Neighbors, en inglés) estima directamente la probabilidad a posteriori de la clase, o sea, asigna la muestra x a la clase más frecuente de entre sus k vecinos más cercanos, según una cierta medida de similitud o distancia.7 La fase de entrenamiento del algoritmo consiste en almacenar los vectores característicos y las etiquetas de las clases de los ejemplos de entrenamiento. En la fase de clasificación, la evaluación de un ejemplo del que no se conoce su clase, es representada por un vector en el espacio de rasgos. Se calcula la distancia entre los vectores almacenados y del nuevo vector y se seleccionan los k ejemplos más cercanos, una distancia alta entre individuos nos indica que son muy diferentes y una baja que son muy similares. El nuevo ejemplo es clasificado con la clase que más se repite en los vectores seleccionados.
Dentro de las distancias que se han seleccionado para el cálculo se encuentra:
La métrica Euclidiana definida como:
![]() (1)
(1)
Donde p y q son puntos del espacio n-dimensional. Y la métrica City Block, también conocida como métrica de Manhattan, es una función de distancia definida como:
![]() (2)
(2)
El KNN es uno de los clasificadores más utilizados por su simplicidad. La principal dificultad de este método consiste en determinar el valor de k, ya que si toma un valor grande se corre el riesgo de hacer la clasificación de acuerdo a la mayoría (y no al parecido), y si el valor es pequeño puede haber imprecisión en la clasificación a causa de los pocos datos seleccionados como instancias de comparación.
Regresión logística multinomial (MLR)
MLR es un popular modelo de clasificación probabilística discriminativo que tiene buenos resultados en los problemas de clasificación de bioimágenes.8,2 Regresión logística es considerada como uno de los mejores clasificadores probabilísticos. Mide dos primeros mejores y registra la pérdida de precisión de clasificación a través de un número de pasos.
![]() (3)
(3)
Donde i={2…m}, y m representa el número de clases de salida. Si m = 2 (problemas binarios) la técnica se conoce como Regresión logística, mientras que cuando m> 2 la técnica es conocido como MLR.9 Usando MLR, la probabilidad de que x pertenece a la clase i es:
![]() (4)
(4)
Donde como resultado de la normalización:
![]() (5)
(5)
En la fórmula anterior, P es la variable de la predicción, Wi denota el vector de peso, y el superíndice ![]() es el vector transposición.9
es el vector transposición.9
Red neuronal de propagación hacia atrás (BPNN)
Las redes neuronales artificiales son interconexiones paralelas masivas de neuronas simples que funcionan como un sistema colectivo.10
BPNN se considera un método de clasificación de gran alcance y es una popular técnica de clasificación basada en red neuronal artificial (RNA), el algoritmo BP es un estimador no paramétrico.11
El algoritmo de propagación hacia atrás aprende los pesos para una red de múltiples capas, dada una red con un conjunto fijo de unidades e interconexiones. Emplea gradiente descendente con el objetivo de minimizar el error cuadrático entre los valores de la salida de la red y los valores objetivos para estas salidas.
Es BPNN es un algoritmo supervisado que utiliza comúnmente como función de activación en el proceso de cálculo función sigmoidal debido a su capacidad para manejar exitosamente señales pequeñas y grandes con control automático de ganancia.1
Diseño Experimental
Para cada una de las cuatro técnicas de clasificación antes descritas se examinaron todos los parámetros relevantes para asegurar su máxima eficiencia. Con el objetivo de seleccionar el mejor vector de características dos selectores de atributos fueron usados.
En esta investigación el software WEKA fue el utilizado para entrenar los clasificadores. Podremos ver a continuación como utilizar estos clasificadores. En esta investigación utilizamos el algoritmo de optimización mínima secuencial (SMO) de John Platt para entrenar máquinas de soporte vectorial.1
Optimización mínima secuencial (SMO) es un algoritmo simple que puede resolver rápidamente el problema de programación cuadrática (QP) sin ningún tipo de almacenamiento de la matriz extra y sin usar pasos numéricos de optimización de QP en absoluto.El entrenamiento de máquinas de apoyo vectorial requiere la solución de un gran problema de optimización de programación cuadrática (QP). SMO rompe este gran problema de QP en una serie de pequeños posibles problemas de QP. Estos pequeños problemas son QP resueltos analíticamente, que evita el uso de una optimización numérica QP de mucho tiempo como un lazo interior. La cantidad de memoria necesaria para SMO es lineal en el tamaño del conjunto de entrenamiento, que permite SMO para manejar grandes conjuntos de formación. KNN es proporcionada por Weka como "IBK". Utiliza distancias normalizadas para todos los atributos para que los atributos en diferentes escalas tengan el mismo impacto en la función de distancia. Se puede devolver más de k vecinos si hay vínculos en la distancia.
El aprendizaje basado en instancias genera predicciones de clasificación utilizando instancias únicamente. Algoritmos de aprendizaje basados en instancias no mantienen un conjunto de abstracciones derivado de casos específicos. Este enfoque se extiende el algoritmo del vecino más cercano, que necesita grandes requisitos de almacenamiento.12 MLR es proporcionada por Weka como Logistic, este mejora la eficiencia del mismo mediante la aplicación de un estimador de cresta.1
Los estimadores de cresta pueden ser utilizados en la regresión logística para mejorar las estimaciones de los parámetros y para disminuir el error cometido por nuevas predicciones.1
BPNN está implementado por WEKA como Multilayer Perceptron. El Perceptrón multicapa consiste en múltiples capas simples, de dos estados, nodos o neuronas que interactúan mediante conexiones ponderadas. Después de una capa de entrada más baja por lo general hay cualquier número de capas intermedias, u ocultas, seguido por una capa de salida en la parte superior. Los pesos miden el grado de correlación entre los niveles de actividad de las neuronas que se conectan.10
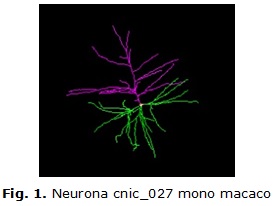
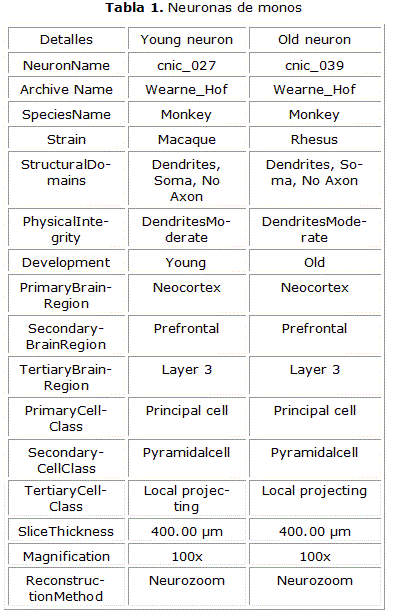
Para aplicar estas herramientas se utilizó una base de datos de 37 neuronas de monos descargadas de la web http://neuromorpho.org provenientes del archivo de Wearne_Hof. De estas 37 neuronas 17 eran de monos adultos y 20 de monos jóvenes. La imagen de una neurona de las que se utilizó se puede ver en la figura. 1 y detalles de dos neuronas, una de mono joven y una de mono adulto se puede ver en la tabla 1.
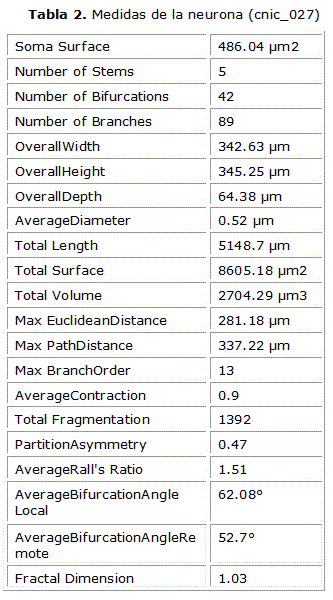
En la tabla 2 se pueden ver algunas de sus características. Cada neurona posee un conjunto de 21 atributos. Estas mediciones son tomadas por el autor de la base de datos y las brinda junto a las neuronas trazadas.
RESULTADOS Y DISCUSIÓN
Cuatro populares técnicas de clasificación (KNN, BPNN, MLR y SVMs) fueron comparadas, usando un conjunto de 37 neuronas. Cada neurona con un conjunto de 21 atributos de tipo continúo. Se utilizó validación cruzada 10 veces para determinar al azar los conjuntos de entrenamiento y prueba. El objetivo de estos experimentos es comparar las técnicas de clasificación automáticas. Para que puedan ser de utilidad para los expertos humanos en su habilidad de usar las diferencias morfológicas para discriminar entre neuronas sanas y enfermas.
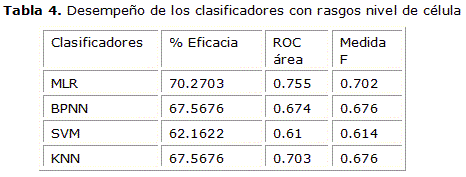
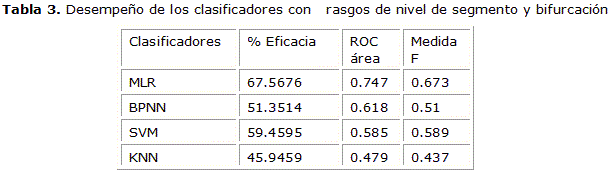
Para analizar el funcionamiento de los clasificadores primeramente se dividió los atributos en 2 grupos, en el primer grupo los que fueron extraídos de las características a nivel de segmento y bifurcación, rasgos del 14 al 21 y en el segundo grupo los que fueron extraídos a nivel celular, rasgos del 1 al 13. Los resultados para los 4 clasificadores se pueden apreciar en la tabla 3 y en la tabla 4.
En un segundo momento se evaluaron los clasificadores para tres conjuntos de rasgos. En el primer grupo están todos los atributos, en el segundo están 6 atributos los cuales fueron obtenidos por el selector de atributos de Weka, en este caso SVMAttributeEval como evaluador y Ranker como método de búsqueda, los atributos en este grupo son pk_classic, soma_surface, bif_ampl_remote, bif_ampl_local, width y partitionasymetry. El tercer grupo de 2 rasgos fue seleccionado por CfsSubsetEval como evaluador de atributos y GreedyStepwise como método de búsqueda, en este grupo fueron seleccionados Partition_asymmetry y Pk_classic.
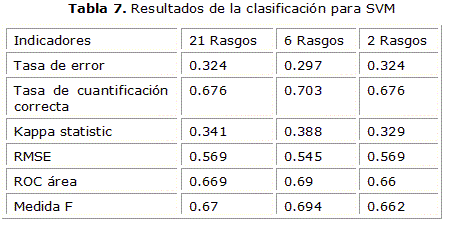
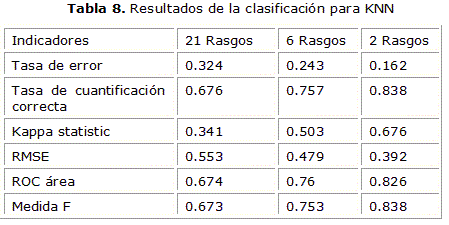
En las tabla 5 se puede ver los resultados para el MLR y así sucesivamente en la tabla 6 para BPNN, en la tabla 7 para SVM y en tabla 8 para KNN.
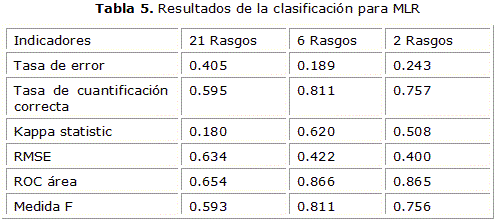
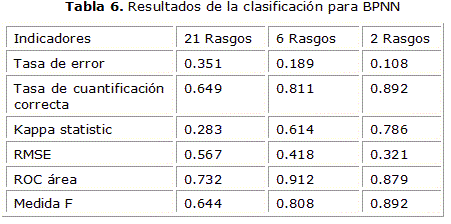
La figura 2 ilustra los resultados de la clasificación automática de las neuronas de mono cuando los rasgos se separaron en los tomados del nivel de célula y los tomados del nivel de segmento y bifurcación. La misma muestra en todos los casos un mejor resultado con los rasgos a nivel celular lo cual demuestra que con el deterioro morfológico de la neurona estas características son las más afectadas.

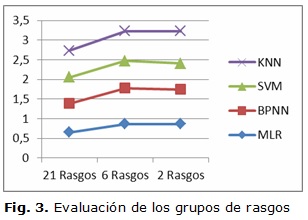
A continuación hace una comparación entre los tres grupos de rasgos, para hacer esta comparación se usó el área bajo la curva ROC de cada uno de los clasificadores. Como se puede ver en la figura 3 los mejores resultados se obtuvieron para el conjunto de 6 rasgos y 2 rasgos, aunque el mejor desempeño se obtuvo con el SVMAttributeEval del software Weka.
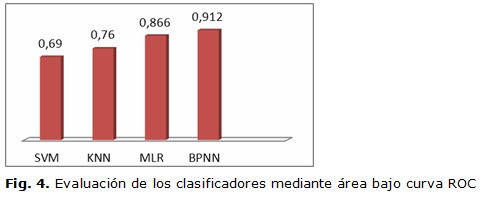
Por último se muestra en la figura 4 los resultados de cada clasificador para el grupo de 6 rasgos, mediante el área bajo la curva ROC. Como se puede apreciar el mejor desempeño lo obtuvieron los clasificadores BPNN y MLR.
CONCLUSIONES
El objetivo primario de esta investigación fue buscar de los métodos de clasificación automática cuales tienen los mejores resultados para este tipo de datos, además de un estudio de los rasgos para lograr una correcta selección y que los clasificadores puedan mejorar su desempeño. Esto les servirá de utilidad a los expertos en la materia. Para esto fueron utilizadas neuronas piramidales de mono a las que se les había extraído 21 características.
Los resultados obtenidos en la clasificación de estas neuronas muestran a los métodos de clasificación MLR y BPNN con los mejores resultados de área bajo la curva ROC (0.866 para MLR y 0.912 para BPNN). También se pudo apreciar que los resultados fueron mejores usando los conjuntos de 6 rasgos y 2 rasgos con valores promedio de área bajo la curva ROC para los todos los clasificadores de (0.807 y 0.791 mientras que sin selector de rasgo solo se obtuvo un 0.682). Además se debe mencionar que el conjunto de rasgos a nivel celular resultó más ventajoso en la clasificación de los dos grupos de neuronas que los rasgos tomados del nivel de segmento y bifurcación.
La exactitud de los datos y la sensibilidad de las técnicas de aprendizaje automático son de gran importancia para el análisis morfológico de las neuronas y pueden ser muy útiles para múltiples aplicaciones en futuros estudios. Esto incluiría la diferenciación entre las etapas de desarrollo específicas de las neuronas y sus respuestas a la ambiente de crecimiento, y la definición de los cambios celulares dentro de los cerebros normales y enfermos.
AGRADECIMIENTOS
Los autores desean agradecer al proyecto NeuroMorpho.org y en especial al profesor Giorgio A. Ascoli por brindar las reconstrucciones digitales de neuronas utilizadas en este trabajo así como el conjunto de métricas de las mismas.
REFERENCIAS BIBLIOGRÁFICAS
1. Alavi A, Cavanagh G, Tuxworth A, Meedeniya A, Blumenstein M. Automated Classification of Dopaminergic Neurons in the Rodent Brain, In, 81-88. Doi: 10.1109/IJCNN, 2009.
2. Zhaung J, Liu S, Wang Vue. Gene association study with SVMS, MLP and cross-validation for the diagnosis of disease. Progress in Natural Science, vol. 18, Issue.6, 2008.
3. Guo-Liang T, Tangb M, Fanga H, Tana M. Efficient methods for estimating constrained parameters with applications to regularized (lasso) logistic regression. Computational Statistics & Data Analysis, vol. 52, Issue 7, 2008.
4. Lewicki DG, Sane AD, Chen Z, Li J, Wei L. A multiple Kernel support vectormachine scheme for feature extraction from gene expression data of cancer tissue. Artificial Intelligence in Medicine, vol. 41, Issue.2, pp.161-175, 2007.
5. Wernick M, et al. Machine Learning in Medical Imaging. Signal Processing Magazine, IEEE, vol. 27, pp. 25-38, 2010.
6. Betancourt GA. Las máquinas de soporte vectorial (svms). Scientia et Technica, vol. 1, pp. 67-72, 2005.
7. Seco FM. Clasificadores eficaces basados en algoritmos rápidos de búsqueda del vecino más cercano. Departamento de Lenguajes y Sistemas Informáticos. Universidad de Alicante. 2004.
8. Boland B, Murphy R. A neural network classifier capable of recognizing a pattern of all majors subcellular structures in fluorescence microscope images of Hela cell. Bioinformatics. vol. 17, No. 13, pp.1213-1223, 2001.
9. Cessi Le, Houwelingen LC. Ridge Estimators in Logistic Regression Applied Statistics. Vol. 41, No.1, pp. 191-201, 1992.
10. Pal SK, Mitra S. Multilayer perceptron, fuzzy sets, and classification, IEEE Transactions on Neural Networks. vol.3, no 5, pp.683-697, sep.1992.
11.Wasserman PD. Neural Computing Theory and Practice. New York: Chapman & Hall,1989.
12. Aha D, Kibler D. Instance-based learning algorithms, Machine Learning. vol.6, pp. 37-66, 1991.
Recibido: 22 de marzo de 2016.
Aprobado: 12 de mayo de 2016.


{kind=link}