










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Cubana de Informática Médica
versión On-line ISSN 1684-1859
RCIM vol.8 supl.1 Ciudad de la Habana 2016
ARTÍCULO ORIGINAL
Detección de masas en mamografías asistida por computadora
Computer aided mass detection in mammograms
Reinaldo Menéndez Alonso,I Bárbaro López-Portilla Vigil,II Andy Duarte Taño,III Ivis Orea CorderoIV
I Universidad de Pinar del Río, Cuba. E-mail: rey88@upr.edu.cu
II Universidad de Pinar del Río, Cuba. E-mail: barbaro@upr.edu.cu
III Universidad de Pinar del Río, Cuba. E-mail: andy.duarte@estudiantes.upr.edu.cu
IV Empresa de Telecomunicaciones de Cuba S.A. E-mail: ivis.orea@etecsa.cu
RESUMEN
En este trabajo se presenta una herramienta de Diagnóstico Asistido por Computadora (CAD) para la detección de masas en mamografías digitales. Desarrollada en Matlab, aplica sobre las mamografías distintas técnicas de Procesamiento Digital de Imágenes para detectar la presencia de lesiones y aislarlas del resto de las estructuras propias del seno. Binarización, Labeling, crecimiento de regiones, Filtro Iris, entre otras; dan como resultado una imagen en la que se destaca la anomalía presente, facilitando un diagnóstico libre de errores. Se validaron los resultados mediante el uso de mamografías reales previamente diagnosticadas por especialistas y se obtuvieron valores de efectividad acorde con los esperados. El resultado de esta investigación constituye un aporte al diagnóstico temprano de lesiones mamarias que podrían ser mortales en caso de una tardía detección; así como una herramienta útil para el entrenamiento de médicos radiólogos en fase de aprendizaje.
Palabras Clave: diagnóstico, masas, mamografías.
ABSTRACT
In this work a Computer Aided Diagnosis (CAD) tool is presented for mass screening in digital mammograms. Developed in Matlab, it applies different techniques of Digital Image Processing to mammograms to detect the presence of lesions and isolate them from the rest of the structures of the breast. Binarization, Labeling, Seeded Region Growing, Iris filter, among others; result in an image in which the abnormality occurring stands facilitating free fault diagnosis. The results were validated using real mammograms previously diagnosed by specialists and effectiveness values were obtained in line with the expected. The result of this research is a contribution to the early diagnosis of breast lesions which could be fatal in case of late detection; as well as a useful tool for training radiologists in the learning phase.
KeyWords: diagnosis, mass, mammograms.
INTRODUCCIÓN
De las técnicas disponibles para diagnosticar y detectar un cáncer de mama, la mamografía es una de las más eficientes; en especial cuando las anomalías no se pueden determinar mediante el auto examen palpable. Sin embargo, debido al gran número de mamogramas que tiene que analizar un radiólogo al día, existe el riesgo de un diagnóstico erróneo; ya sea por fatiga, falta de experiencia o negligencia. Por este motivo el Diagnóstico Asistido por Computadoras (CAD) ha cobrado gran importancia y los esfuerzos se han encaminado a obtener algoritmos cada vez más eficientes y eficaces, que procesen las mamografías digitales para detectar la presencia de anomalías en las mismas; tratando de reducir al mínimo los errores en este procedimiento.
El Procesamiento y Análisis Digital de Imágenes es el conjunto de técnicas que se aplican sobre una imagen digital con el objetivo de mejorar su calidad y/o analizar su contenido.1 Debido a su efectividad y bajo grado de invasividad, ha sido ampliamente aplicado a otras ramas de la ciencia como la Medicina. En el caso de las mamografías digitales su utilidad radica en el perfeccionamiento de la detección de lesiones mamarias que pudieran ser un posible cáncer. De este modo, a partir de una detección temprana se puede reducir significativamente la mortalidad debido a esta enfermedad en las féminas.
Informes de la Organización Mundial de la Salud indican que por este motivo cada once minutos muere una mujer en el planeta y clasifica entre la primera causa de muerte entre las que tienen entre 35 y 54 años, por lo que es valorada como la neoplasia más común en el mundo occidental. De ahí que este tema posea un gran impacto social, pues cualquier mejora en la precisión diagnóstica, por pequeña que esta sea, podría suponer un enorme beneficio para los pacientes que presentan este tipo de lesiones.
En este trabajo se desarrolló una herramienta de diagnóstico asistido por computadoras para procesar mamografías digitales en busca de lesiones de interés para los especialistas. Las mismas se aíslan del resto de las estructuras del seno para facilitar su análisis. Se empleó una base de datos, ofrecida por MIAS (Mammographic Image Analysis Society), con 322 mamografías previamente diagnosticadas por especialistas, con el fin de validar los resultados obtenidos en este trabajo. Dichas imágenes cuentan con una resolución de 1024x1024 píxeles; la cual representa una excelente calidad para los propósitos de esta investigación. Aunque se ha empleado en esta investigación el software Matlab, herramienta muy potente y con muchas facilidades para el procesamiento de imágenes; es válido aclarar que no se han utilizado funciones propias, lo cual posibilitará la implementación de las técnicas aquí descritas en otros lenguajes y arquitecturas.
PROCEDIMIENTO EXPERIMENTAL
El sistema diseñado se ha concebido en bloques independientes con funcionalidades bien definidas, con el objetivo de facilitar su futura ampliación o perfeccionamiento en trabajos posteriores. Dicha estructura se refleja en la figura 1.
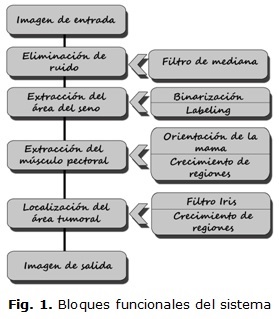
Primeramente es necesario realizar un pre procesamiento de las mamografías digitales con el fin de mejorar su calidad. En ocasiones dichas imágenes están contaminadas con ruido, producto del proceso de adquisición, y esto dificulta en cierta medida las operaciones a realizar sobre las mismas. Es por ello que se aplican filtros específicos para eliminar o reducir al máximo estos efectos. Posteriormente se procede a la extracción del área del seno; etapa en la cual se delimita dentro de la imagen cuál es la región de interés (ROI) y se elimina aquella información sin valor para el diagnóstico. En la siguiente etapa se elimina la zona del músculo pectoral, pues tampoco contiene información con utilidad diagnóstica. Eliminar este tipo de información permite obtener mejores rendimientos ya que el análisis se centra únicamente en aquellos píxeles de la imagen que pueden contener información relevante. Por último se procede a la localización del área tumoral y al aislamiento del mismo en caso de que exista.
Como resultado se obtiene una nueva imagen en la cual se puede percibir el tumor completamente aislado del resto de las estructuras del seno; lo cual facilita su análisis por parte de los especialistas.
Eliminación de ruido
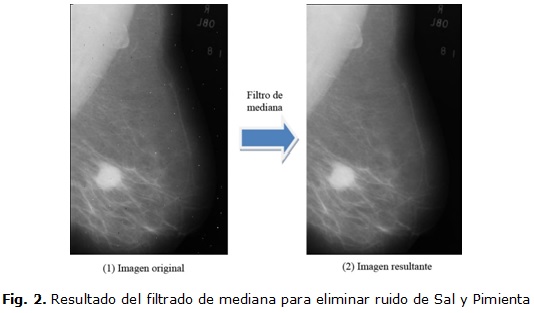
Entre los distintos tipos de ruidos que afectan a las mamografías digitales el más común es el de Sal y Pimienta; heredado en el protocolo de adquisición de las imágenes. Este efecto se caracteriza por la aparición aleatoria de píxeles blancos y píxeles negros en la imagen; de ahí su nombre. Con el fin de minimizar este molesto fenómeno se implementó el filtro de mediana. Para aplicarlo se recorre la imagen de izquierda a derecha y de arriba hacia abajo y los píxeles originales se agruparon bajo una máscara de 3x3; situando en la posición central de la misma el píxel a procesar. En cada iteración se toman los nueve valores bajo la máscara, se ordenan de menor a mayor y el píxel a procesar se sustituye por el valor mediano del arreglo ordenado de píxeles (quinto). Como las muestras de ruido se encuentran al principio o al final del arreglo, debido a sus niveles de gris, es muy efectivo este método para eliminarlas. La efectividad de este procedimiento solo se verá afectada si la cantidad de "píxeles ruidosos" bajo la máscara es mayor que el 50% del total de elementos de la misma.2 Bajo estas condiciones es aconsejable utilizar otros métodos de filtrado. No obstante es muy poco probable que se cumpla esta condición en las mamografías.
Para validar esta etapa se contaminaron algunas de las imágenes disponibles y se pudo comprobar que esta técnica de filtrado posee una excelente respuesta, eliminando el ruido antes mencionado con un nivel de difuminado considerablemente menor que los demás filtros de suavizado. En la figura 2 se muestra uno de los resultados obtenidos. Nótese que la imagen resultante está completamente limpia y con un nivel de difuminado casi imperceptible.
Extracción del área del seno
Una vez que se elimina el ruido presente en las mamografías digitales se procede a analizarlas para detectar el área correspondiente al seno. Para ello se implementaron dos procesos básicos en la segmentación de imágenes: la binarización y el etiquetado.
Binarización
Partiendo de una imagen en escala de grises, se obtiene una imagen binaria mediante algún proceso de abstracción de la información. La manera más simple de abstracción es la binarización.1
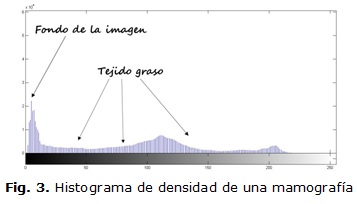
Una característica importante de las imágenes mamográficas es que los contrastes que se presentan en los valores de densidad se deben a que la permeabilidad de los rayos X es diferente en el área del seno y su respectivo fondo. Sin embargo, la alta densidad que se presenta en el músculo pectoral, en tumores y en la composición de la glándula mamaria es producto de la baja permeabilidad de los rayos X. En cambio, la baja densidad que se presenta en el tejido adiposo es producto de la alta permeabilidad de los rayos X.3 Teniendo esto en cuenta, y debido a que el borde entre el fondo y el tejido graso (silueta del seno) no es nítido; se procedió a detectar dicho contorno mediante el método de umbralización binaria fijo, basado en el histograma de densidad de la imagen. Como se puede ver en la figura 3, que se corresponde con el histograma de densidad de una de las imágenes de la base de datos usada (mdb028), el valor de densidad del área del fondo es más bajo que el tejido graso, así como el número de píxeles de dicho fondo es mucho mayor al de tejido graso. El análisis de este histograma permite arribar a conclusiones importantes en el proceso de binarización.
Supóngase una imagen con L niveles de gris. Se define un valor entero T que pertenezca al intervalo [0, L1] el cual se denomina umbral de binarización.1 La umbralización es un proceso de simple comparación. Cada píxel de la imagen original es comparado con el umbral T y se toma una decisión binaria para definir el valor del píxel correspondiente en la imagen resultante. La función de umbralización se representa como:
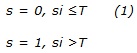
El valor de umbral utilizado es de suma importancia pues controla la abstracción de la información obtenida. En esta investigación se analizaron tres de los métodos más empleados en la bibliografía para la selección del umbral: la inspección visual del histograma, el método de González & Woods2 y el método de Otsu.4
Los últimos dos métodos arrojaron valores de umbral próximos a T=76. Al realizar la binarización con esta referencia se obtuvieron imágenes en las cuales se perdía la información correspondiente al borde de la mama, por lo que la segmentación no era efectiva. Por este motivo se realizó una inspección visual del histograma, basada en las características mencionadas al inicio de esta sección.
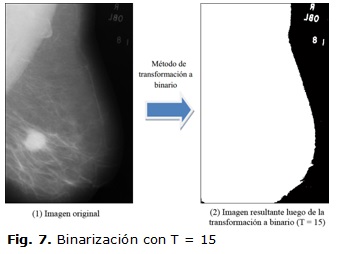
Se realizaron pruebas con distintos valores de umbral y se arribó a las siguientes conclusiones: con valores menores que 15 no se segmenta correctamente el área mamaria pues se incluyen zonas correspondientes al fondo que no resultan de interés. Valores por encima de 40 y cercanos a 76 afectan la zona correspondiente a la silueta del seno, perdiendo píxeles que constituyen parte del contorno del mismo. En las figuras 4, 5 y 6 se puede apreciar el resultado de escoger los valores mencionados como umbral y su influencia negativa en el resultado. Por este motivo se escogió un valor umbral dentro del rango de 15 a 40, en este caso T=15. Como se aprecia en la figura 7 se ha delimitado el área del seno sin afectar la silueta del mismo.



Técnica de etiquetado Labeling
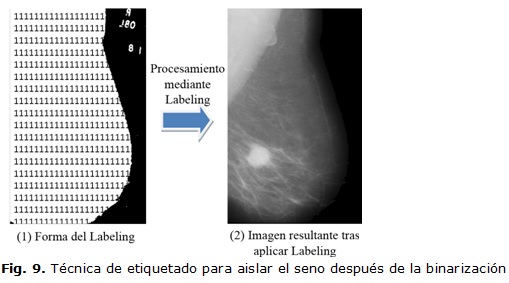
En este punto del procesamiento se ha identificado en la mamografía original el área correspondiente al seno. Si se analiza la imagen mostrada en la figura 7 se puede apreciar que existen caracteres correspondientes a los datos del paciente en la región superior derecha, elementos que no son de interés diagnóstica. Por este motivo fueron extraídos de la imagen. Para ello se aplicó una técnica de etiquetado (Labeling) a la imagen binaria y el área donde el número de píxeles de cierta densidad era máximo se asumió como la región del seno.
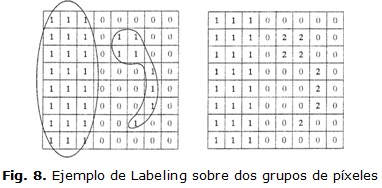
"Labeling" es un procedimiento que permite asignar un mismo número a un conjunto de elementos en común para poder conectarlos entre sí. Un píxel p de coordenadas (x,y) tiene dos vecinos horizontales y dos verticales cuyas coordenadas son (x+1,y), (x-1,y), (x,y+1) y (x,y-1). Además tiene cuatro vecinos en sus diagonales cuyas coordenadas son (x+1, y+1), (x+1, y-1), (x-1,y+1) y (x-1,y-1). Se dice que dos píxeles p y q son vecinos si q tiene las coordenadas de uno de los 8 píxeles vecinos de p.
Un ejemplo de la técnica de etiquetado para dos grupos de píxeles se muestra en la figura 8.
La figura 9 muestra el resultado de aplicar la técnica de Labeling a la imagen de entrada. En la misma se puede apreciar como resultado el total aislamiento de la región mamaria.
Extracción del músculo pectoral
Una vez segmentada la imagen y obtenida el área mamaria hay que eliminar el músculo pectoral. Este no tiene ningún valor a la hora de clasificar la mama y puede producir errores en el diagnóstico y aumentar el tiempo de procesamiento. Esta segmentación es un proceso aún más delicado que el de separar la mama del fondo, por lo que se debe emplear una técnica más compleja que la binarización.
Sea cual sea la estrategia a seguir, el primer paso es decidir la orientación de la mama (si es izquierda o derecha) para saber en qué lugar de la mamografía se encuentra el músculo pectoral. Afortunadamente es un proceso bastante sencillo y con múltiples aproximaciones: desde analizar la curvatura de los dos bordes de la mama hasta calcular el centro de masa del objeto y ver en qué mitad hay más píxeles, pasando por la división de la imagen en regiones y estudiándolas individualmente. El problema es, una vez determinada la orientación, conseguir segmentar de manera adecuada el músculo pectoral.
Como se dijo anteriormente, el tamaño de las imágenes usadas es de 1024x1024 píxeles. Para detectar la orientación de la mama se dividió la imagen en regiones (mitad derecha y mitad izquierda) y se compararon las sumas de los valores de los píxeles de ambas regiones.
Entre las técnicas de segmentación del músculo pectoral, hay autores que utilizan el crecimiento de regiones; tal es el caso de.5,6,7,8 Como su nombre lo indica, es un procedimiento que agrupa píxeles o subregiones dentro de regiones más grandes, basado en un criterio predefinido de crecimiento. Para ello, se planta una semilla en el músculo pectoral y se utiliza un algoritmo de crecimiento de regiones para determinar la zona que pertenece al músculo.
Existen multitud de algoritmos de crecimiento de regiones, tal como el SRG (Seeded Region Growing), crecimiento de regiones por umbralización, por división recursiva, por división y fusión; entre otros. Además se emplean métodos correctores y limitadores para impedir que se incluyan zonas de la mama en la región correspondiente al músculo, como el mencionado en.6
En5 se describe un algoritmo utilizado para la segmentación del músculo pectoral usando SRG. Después de determinar la orientación de la mama en la imagen y realizar un realce de contraste, se planta una semilla dentro del músculo y se aplican cuatro pasos en los cuales la región crece iterativamente.
Otros métodos se basan en el uso de la geometría y la determinación de rectas para eliminar el músculo, pero empleando técnicas más complejas.
En3 se utiliza el método de Aproximación de Mínimos Cuadrados. En este se asume la esquina superior izquierda de la mamografía como la coordenada x;y (0;0), y 'a' como el punto donde el gradiente de concentración es máximo dentro del área del seno en la dirección axial x. Los puntos extraídos fueron sustituidos por el tipo de aproximación de mínimos cuadrados, debido a que el borde que delimita el área del músculo pectoral se puede asimilar bastante a una curva de segundo orden.
El método implementado en esta investigación está inspirado en el expuesto en.2 Después de determinar la orientación de la mama, se decide cuáles serán los puntos semilla (S) iniciales, o sea, niveles de gris. Se escoge como semilla inicial (S1) al píxel ubicado en la posición 5,5 (fila 5 columna 5). Además, se define un determinado número n, por ejemplo n = 70, el cual se va a ir restando y sumando del nivel de gris de la primera semilla (S1) de la siguiente forma: S170, S1-69, …, S1+0, …, S1+69, S1+70. Los píxeles con estos niveles de gris pasarán a formar parte de las semillas iniciales también.
El siguiente paso es escoger un valor umbral T para realizar lo que se conoce como "prueba del umbral". Sea S = a y T = b, se dice que un píxel (con valor de intensidad p) es similar a 'a' si el valor absoluto de la diferencia entre su intensidad p y a es menor o igual que b; o sea ![]() . Además, si el píxel en cuestión p tiene en su vecindad al menos una de las semillas, entonces el píxel es considerado como un miembro de la región. En la figura 10 se muestra el resultado de este procedimiento y es notable su efectividad.
. Además, si el píxel en cuestión p tiene en su vecindad al menos una de las semillas, entonces el píxel es considerado como un miembro de la región. En la figura 10 se muestra el resultado de este procedimiento y es notable su efectividad.
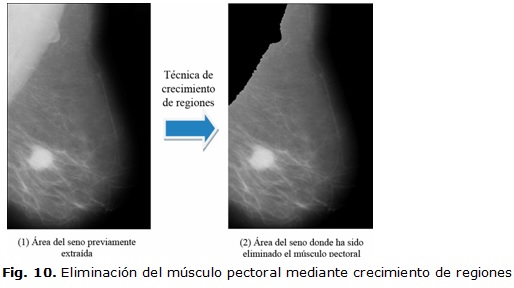
Un aspecto a tener en cuenta es la selección del número de semillas (n) ya que es influyente en la segmentación del músculo. Por ejemplo, un valor pequeño de n para determinada imagen puede acarrear que el músculo pectoral se elimine parcialmente. Por otra parte, un valor elevado de n traerá consigo que se elimine el músculo pectoral y además parte de la mama que no corresponde al músculo; con lo cual se elimina información de la mama que pudiera ser importante. De ahí que este valor dependa en gran medida de las características del músculo pectoral en la imagen que se está procesando.
Para la validación de esta etapa se aplicó el algoritmo a 230 imágenes de la base de datos en las que se podía ver el músculo pectoral. De ellas se segmentaron exitosamente 210 para un 91,10% de efectividad.
Método de localización del área tumoral
En este punto del procesamiento la imagen de entrada está lista para la última etapa que es la locación del tumor. Con este propósito se aplicó el método vector gradiente de densidad y el Filtro Iris.
La particularidad del Filtro Iris es que cuenta con la capacidad de detectar características de bajo contraste, tales como las lesiones incipientes en una mamografía. Recurriendo a esta propiedad del Filtro Iris, se desarrolló un algoritmo que hace visible características de bajo contraste junto con características de alto contraste. Se notó con esta técnica, que el grado de convergencia crece en la región tumoral y en la frontera del área mamaria con su fondo. Luego, el área del tumor fue extraída utilizando un algoritmo de crecimiento de regiones, el cual consta de los mismos pasos que el expuesto anteriormente.
Extracción de la locación del tumor mediante el vector gradiente y el Filtro Iris
Se parte de la premisa de que la apariencia de un tumor en una mamografía consiste en una región más o menos circular con brillo relativamente alto. En estas condiciones, se obtiene un mapa de gradientes de la mamografía, el tumor aparecerá como una región circular con muchos gradientes apuntando hacia el centro. Una manera de evaluar el grado de convergencia del vector gradiente en la vecindad de un píxel de interés es mediante el Filtro Iris descrito en.9, 10
El Filtro Iris está diseñado para detectar regiones en una mamografía digital donde un tumor podría estar presente.9 Este es un algoritmo eficiente para cuantificar estructuras de dos dimensiones como las lesiones de interés para esta investigación. El grado de convergencia está relacionado con que la distribución de la orientación de los vectores gradientes en él se conviertan en máximos. Esto significa que el tamaño y la forma de la región de soporte cambian adaptativamente de acuerdo a la distribución de patrones de los vectores gradientes alrededor del píxel de interés.
En9, 10 se explica el procedimiento que sigue el Filtro Iris para asignar un valor a cada píxel. Este filtro establece medias líneas radiadas del centro del píxel de interés, separadas por un ángulo constante. Se procedió a calcular el mayor grado de concentración, y se asumió como salida los valores de los máximos grados de intensidad. Se fijó el número de medias líneas radiadas M=32, y se calcularon los puntos donde el grado de convergencia era máximo.
Debido a la complejidad del algoritmo, su procesamiento matemático y el tiempo de ejecución de este, se procedió a aplicar el filtro sólo a aquellos píxeles cuyo valor de intensidad fuera mayor o igual que cierto parámetro umbral T. En este caso se escogió T=128 pues el área tumoral presenta píxeles cuyos valores de intensidad superan este umbral. Para valores pequeños de T, el tiempo de ejecución del algoritmo se ve demasiado afectado, y para valores muy elevados se puede perder información acerca de la lesión que se quiere analizar. Cabe destacar que no sólo el tumor presenta píxeles con valores por encima del umbral, también ciertas áreas alrededor del tumor tienen esta característica.
Un ejemplo de la imagen resultante tras aplicar el Filtro Iris se muestra a continuación en la figura 11.
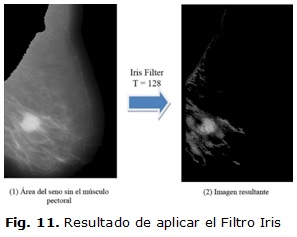
Uno de los parámetros de salida del Filtro Iris son las coordenadas aproximadas del centro del tumor (maxy, maxx). Con el Filtro Iris, la lesión no queda del todo aislada; es decir, hay píxeles cercanos al tumor que no forman parte de este.
Para lograr el completo aislamiento de la lesión se utiliza nuevamente el método de segmentación basado en el crecimiento de regiones descrito en la sección 2.3. A partir de aquí se "plantaron" semillas en los alrededores del centro del tumor (maxy, maxx) obtenido del Filtro Iris; lo que constituyó el punto de partida del algoritmo el cual concluye con la localización y asilamiento del tumor.
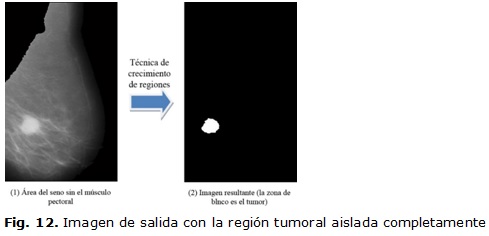
En la figura 12 se muestra la imagen de salida de todo el sistema. Se puede apreciar como resultado relevante el aislamiento del área tumoral y la eliminación de otras estructuras propias del seno que pudieran dificultar un diagnóstico eficaz.
Para estudiar la precisión de todo el sistema se empleó la siguiente expresión:
![]()
donde un TP (true positive) es una marca hecha por el sistema CAD que corresponde a la localización de una lesión; y un FP (false positive) es una marca hecha por el sistema CAD que no corresponde a la localización de una lesión.
Aunque la base de datos disponible tiene una cantidad relativamente grande de muestras, hay que aclarar que solo 28 de estas imágenes presentan el tipo de lesión analizado en esta investigación, los nódulos mamarios o masas.
Sobre esta población se aplicó cada una de las etapas del sistema y se obtuvo un aislamiento correcto de 21 lesiones, mientras que 7 se aislaron incorrectamente; lo cual arroja una precisión de 75 %. Este porciento puede ser mucho mayor ante una población más numerosa de mamografías.
CONCLUSIONES
En este trabajo se ha diseñado un sistema CAD capaz de detectar áreas sospechosas de carcinoma en mamografías digitales. Estas zonas son definidas por el sistema, en base a la presencia de nódulos mamarios.
El sistema puede ser usado indistintamente, bien indicando el área sospechosa para ser evaluada por el radiólogo, o como un sistema de ayuda al diagnóstico tras la extracción de características de las mismas. Además, puede representar una herramienta útil para el entrenamiento de médicos radiólogos en fase de aprendizaje.
Se ha diseñado el sistema modularmente, lo que proporciona una gran flexibilidad, siendo posible la modificación o sustitución en el futuro de alguno de los módulos que lo conforman para mejorar el rendimiento globalmente.
Para la detección de zonas sospechosas se han empleado técnicas basadas en el histograma, junto con algoritmos de segmentación basados en el crecimiento de regiones.
REFERENCIAS BIBLIOGRÁFICAS
1. Gonzalez R, Woods R. Digital Image Processing. Ed. Prentice Hall, New Jersey, 2002.
2. González R. Digital Image Processing using Matlab. Ed. Prentice Hall, New Jersey, 2004.
3. Rodríguez R. Desarrollo de un sistema CAD para detectar y clasificar lesiones mamarias presentes en mamografías digitales. Tesis de Grado, Universidad Simón Bolívar, Sartenejas, 2009.
4. Otsu N. A threshold selection method from gray-level histogram, IEEE Transactions on Systems. Man and Cybernetycs, Vol. 9, No.1, pp. 62-66, 1979.
5. Nagi J, Kareem S, Nagi F, Khaleel S. Automated Breast Profile Segmentation for ROI Detection Using Digital Mammograms. IEEE EMBS Conference on Biomedical Engineering & Sciences, pp 87-92, 2010.
6. Raba D, Martí O, Peracaula J, Espunya J. Breast segmentation with pectoral muscle suppression on digital mammograms. Pattern Recognition and Image Analysis, pp. 471-478, 2005.
7. Alfaro A, Mendoza I. Diseño de un Algoritmo de Segmentación de imágenes aplicando el Funcional de MumfordShah para mejorar el desempeño de los algoritmos clásicos de segmentación. Tesis de Grado, Universidad Nacional de Trujillo, 2006.
8. Adams R, Bischof L. Seeded region growing, Pattern Analysis and Machine Intelligence. IEEE Transactions DE, 16(6), pp. 641-647, 1994.
9. Kobatake H, Murakadami M. Adaptive filter to detect rounded convex regions: Iris filter, Pattern Recognition. Proceedings of the 13th International Conference on Vol 2., pp. 340-344, 1996.
10. Gutierrez L, Alvarez S. Algorithm to enhance low contrast features in digital mammograms. Journal of X-ray Science and Technology, Vol.12, No.3.
Recibido: 22 de marzo de 2016.
Aprobado: 12 de mayo de 2016.

