










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
El término de hipertensión arterial (HTA) y su identificación como factor de riesgo cardiovascular es actualmente muy común en nuestra sociedad. Sin embargo, no siempre es trasladada esta preocupación sobre los niños. Las guías de la Sociedad Europea de Hipertensión (ESH) y de la Sociedad Europea de Cardiología (ESC) del tratamiento de la HTA, publicadas en 2003 y actualizadas en 2007, no incluían ninguna sección dedicada a la HTA en niños y adolescentes.1 Es en 2009, cuando se publican las primeras recomendaciones de la ESH para el manejo de la HTA en niños y adolescentes y en 2016 se actualizan las nuevas guías clínicas.2
Se ha demostrado que la HTA en la infancia es un factor de riesgo independiente para la hipertensión en la edad adulta y está asociada con marcadores precoces de enfermedad cardiovascular como hipertrofia ventricular izquierda, espesor de la íntima-media, complianza arterial, ateroesclerosis y disfunción diastólica.3 El diagnóstico de hipertensión en niños es complicado porque los valores normales y anormales de la presión sanguínea varían con la edad, el sexo y la talla, con un amplio rango descrito en tablas y por tanto son difíciles de recordar. Considerando que la morbilidad y la mortalidad a largo plazo están asociadas a la hipertensión arterial, un componente importante para la salud de los niños y de los adolescentes es intervenir a tiempo.4
En los últimos años, se han desarrollado varios métodos computarizados para la estimación del riesgo cardiovascular total. El modelo Systematic COronary Risk Evaluation (SCORE) se ha desarrollado basándose en grandes aportes de estudios europeos. Este modelo permite estimar el riesgo de muerte por enfermedad cardiovascular en 10 años, no solamente por enfermedad coronaria, sino también por edad, sexo, hábitos de consumo de tabaco, colesterol total y presión arterial sistólica.5 En otras investigaciones realizadas, se han obtenido soluciones informáticas con buenos resultados según la exactitud de la clasificación pero en muchos de ellos es difícil extraer información relacionada con el conocimiento extraído para entender el comportamiento de las variables medidas en la aparición de hipertensión arterial.4,6,7
La teoría de los conjuntos borrosos en lógica difusa - donde cada elemento tiene un grado de pertenencia asociado, en un intervalo entre 0 y 1-, ofrece un grupo de herramientas que posibilita trabajar con tal información, y se aplican cálculos numéricos usando etiquetas lingüísticas formadas a partir de la definición de funciones de membresía. La selección de reglas difusas del tipo if-then son el principal componente de un sistema de inferencia borroso que pueda emular la experiencia humana en una aplicación específica. Lo anterior unido a la estructura conexionista de las redes neuronales y las ventajas de los algoritmos evolutivos, hacen que la utilización de un sistema neuroborroso asegure, en muchos casos, un buen desempeño y una fácil interpretación del conocimiento adquirido durante el aprendizaje.8 Los sistemas neuroborrosos también han sido aplicados en varias ocasiones al estudio y diagnóstico de esta enfermedad, así como sistemas de inferencia borrosos 6,9,10,11. No obstante, en muchos de ellos la cantidad de datos con los que se efectúa la experimentación es relativamente pequeño y el estudio es efectuado en personas adultas, no en menores de edad.
El objetivo del presente trabajo es utilizar diferentes algoritmos neuroborrosos para modelar el diagnóstico de riesgo de HTA en menores como un problema de clasificación y además utilizar las reglas difusas resultantes para la interpretación de la influencia de las variables medidas en dicho diagnóstico.
Métodos
Los datos usados en esta investigación fueron tomados a partir de los estudios efectuados en el proyecto PROCDEC de escolares de Santa Clara, Cuba. Agrupan las mediciones realizadas en 626 niños en las edades de 8 a 11 años. Originalmente los niños eran clasificados en Normotensos, Pre-hipertensos e Hipertensos. Para el trabajo con los niños, se requirió la firma de consentimiento informado de los padres y la asistencia voluntaria del sujeto. A todos los sujetos se les preguntó verbalmente su asentimiento y aquellos que rechazaban ser evaluados fueron excluidos.
Con el objetivo de facilitar la interpretación de los resultados y enfocar el estudio en un sector específico de la muestra estudiada, se decidió considerar si un niño era Normotenso o estaba en riesgo de presentar HTA (los Pre-hipertensos más los hipertensos). La proporción final fue de 372: 254 respectivamente para estas clases.
En la Tabla 1 puede observarse una descripción de las 24 variables medidas en cada niño. Las variables nominales fueron convertidas en variables numéricas de forma que, si la variable está presente en el paciente, toma valor 1 y 0 en otro caso. Dado que la variable edad toma 4 valores posibles, fue transformada creando tres variables adicionales para considerar si el paciente tenía 8, 9, 10 o 11 años. Finalmente, fue representada mediante las variables AGE_8, AGE_9, AGE_10 y AGE_11; una para cada edad.
Tabla 1. Descripción de las variables medidas en los niños que conformaron la muestra de estudio.
| Variable de medición | Tipo | Descripción |
|---|---|---|
| Sex | Nominal | Sexo del niño (F, M) |
| Raza | Nominal | Raza del niño (Blanco o no) |
| Age | Nominal | Edad del niño |
| SOD | Numérico | Antioxidante superóxido dismutas |
| CAT | Numérico | Actividad de Catalasa |
| GSH | Numérico | Concentración de GSH |
| Colesterol | Numérico | Concentración de colesterol |
| TGA | Numérico | Triglicéridos |
| HDL | Numérico | Concentración de lipoproteínas de alta densidad |
| LDL | Numérico | Concentración de lipoproteínas de baja densidad |
| AUrico | Numérico | Concentración del ácido úrico |
| Mg | Numérico | Concentración de Magnesio |
| K | Numérico | Concentración de Potasio |
| Ca | Numérico | Concentración de Calcio |
| Na | Numérico | Concentración de Sodio |
| Cu | Numérico | Concentración de Cobre |
| Zn | Numérico | Concentración de Zinc |
| PNacer | Numérico | Peso del niño al nacer |
| PesoKg | Numérico | Peso del niño durante el estudio (Kg) |
| CCintura | Numérico | Circunferencia de la cintura |
| Cadera | Numérico | Circunferencia de la cadera |
| ICC | Numérico | Índice cintura-cadera |
| IMC | Numérico | Índice de masa corporal |
| ICCC | Nominal | Clasificación del índice cintura-cadera (Normal, Alto) |
| Class | Nominal | Clasificación en Normotenso o en riesgo de padecer HTA |
Algunas de estas variables presentaban gran cantidad de valores perdidos, por lo que se cree que los bajos porcientos de clasificación al aplicar los algoritmos de clasificación usados en otras investigaciones se debiera a esto.12 Por ello, los algoritmos que a continuación se muestran fueron seleccionados teniendo en cuenta su tolerancia a valores perdidos en los datos.
Se utilizó la herramienta Keel para modelar el problema de predicción del riesgo de hipertensión arterial en menores de edad. Se aplicaron tres algoritmos neuroborrosos tolerantes a la existencia de valores perdidos en los datos, pero diferentes en la forma de construir las reglas de decisión.13
El algoritmo propuesto por Ishibuchi examina el desempeño de un método de aprendizaje automatizado difuso basado en Algoritmos Genéticos para problemas de clasificación de patrones multidimensionales con atributos continuos.14 Desde el punto de vista de la implementación, las funciones de pertenencia pre-establecidas favorecen la simplicidad computacional del método. De hecho, la sencillez en la implementación y la interpretación lingüística de las reglas difusas generadas son las principales características del método.
El segundo algoritmo aplicado (FH-GBML) fue propuesto también por Ishibuchi en 2005 e incluye una combinación de los enfoques de Pittsburgh7 y Michigan15 para construir una base de reglas borrosas para problemas de clasificación.16
Finalmente, el algoritmo NSLV propuesto en 2009 por González fue diseñado a partir de una modificación realizada al algoritmo de aprendizaje SLAVE.17,18 NSLV hereda gran parte de la funcionalidad de SLAVE, pero extiende su esquema iterativo genético para aprender una regla completa en cada iteración.19
De forma general, el objetivo de los métodos neuroborrosos es encontrar el conjunto de reglas difusas que mejore su ajuste a los datos de entrenamiento.
Para la ejecución de los algoritmos descritos en el apartado anterior, en el ambiente experimental ofrecido por Keel se importaron los datos al formato de este programa y se diseñaron los experimentos, manteniendo la configuración de los parámetros sugerida por los autores. A partir de la matriz de confusión resultante de ejecutar cada algoritmo, son calculadas la sensibilidad (razón de verdaderos positivos), la especificidad (razón de verdaderos negativos), y los valores predictivos y positivos.
Los algoritmos fueron evaluados aplicando la validación cruzada de k campos, k=10 y el análisis de diferencias significativas fue obtenido a partir del propio análisis efectuado por la herramienta usada (T-Student con 99% de significación al comprobarse la existencia de normalidad e igual varianza en los datos).
Resultados
De forma general, los mejores resultados fueron obtenidos con los algoritmos NSLV e Ishibuchi99 de acuerdo a las métricas de evaluación mencionadas anteriormente (Tabla 2).
Tabla 2. Comparación del desempeño de los métodos neuroborrosos utilizados según las medidas de evaluación aplicadas. Los valores de la matriz de confusión fueron obtenidos a partir de la validación cruzada de k campos (k=10).
Tabla 2. Comparación del desempeño de los métodos neuroborrosos utilizados según las medidas de evaluación aplicadas.
| Ishibuchi99 | FH-GBML | NSLV | ||||
|---|---|---|---|---|---|---|
| %Train | %Test | %Train | %Test | %Train | %Test | |
| Sensibilidad | 99.85 | 98.66 | 93.12 | 89.42 | 94.00 | 83.60 |
| Especificidad | 5.95 | 2.76 | 21.33 | 15.32 | 51.09 | 31.50 |
| VPP | 60.86 | 59.77 | 63.43 | 60.45 | 73.79 | 64.12 |
| VPN | 96.45 | 58.33 | 67.90 | 50.00 | 85.32 | 56.74 |
Los mejores resultados en el conjunto de prueba se destacan en negrita
Al analizar los resultados de la clasificación de los tres algoritmos (clase predicha en cada conjunto de validación) se determinó que existían diferencias significativas (con un 99% de significación utilizando el T de Student al determinarse que los resultados seguían una distribución normal y poseían igual varianza) entre el algoritmo NSLV y FH-GBML (p.value=0.0209); no siendo así entre Ishibushi99 y FH-GBML (p.value=0.1279); y entre Ishibushi99 y NSLV (p.value=0.0977).
Según los resultados obtenidos con el algoritmo NSLV y discutidos más adelante, se selecciona este para estudiar las reglas formadas y analizar la relevancia de las variables medidas en su construcción.
En la Tabla 3 se resumen la cantidad de reglas obtenidas para cada partición formada durante la evaluación de NSLV. La clase 1 se corresponde con los niños Normotensos y la clase 2 con los niños que tienen riesgo de padecer HTA. Como promedio, fueron generadas un mayor número de reglas que se corresponden con el diagnóstico del riesgo de HTA en menores.
Tabla 3. Cantidad de reglas formadas con el algoritmo NSLV que predicen cada una de las clases definidas en la modelación del problema.
| Partición | Cantidad de reglas | ||
|---|---|---|---|
| Predicen la clase 1 | Predicen la clase 2 | Total | |
| 1 | 4 | 3 | 7 |
| 2 | 9 | 16 | 25 |
| 3 | 4 | 2 | 6 |
| 4 | 5 | 10 | 15 |
| 5 | 6 | 10 | 16 |
| 6 | 6 | 9 | 15 |
| 7 | 3 | 10 | 13 |
| 8 | 6 | 7 | 13 |
| 9 | 4 | 6 | 10 |
| 10 | 9 | 14 | 23 |
| TOTAL | 56 | 87 | 143 |
Al analizar la presencia de cada una de las variables medidas en el estudio, en las reglas que predecían el riesgo de HTA; se determinó que la edad, la concentración de GSH, la concentración de antioxidantes de superóxido dismutas (SOD) y de Colesterol, el peso al nacer y la presencia de Cinc y Potasio en los análisis de sangre eran las que más se utilizaban. Sin embargo, el índice de masa corporal, el índice cintura-cadera y las concentraciones de Magnesio fueron las variables que menos se incluían. El comportamiento de las restantes variables en la predicción de riesgo de HTA puede ser observado en la Fig. 1. También puede observarse que la medición del índice cintura-cadera era más utilizada como variable nominal y no como variable numérica.
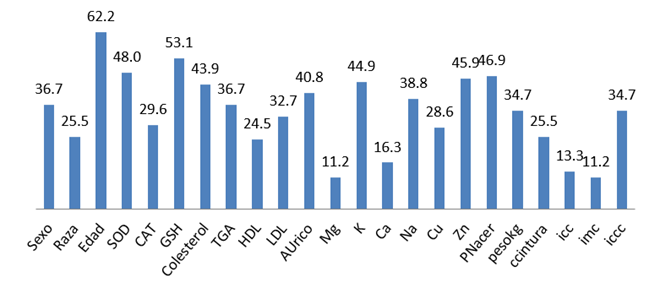
Fig. 1. Presencia de las variables medidas en las reglas que predecían el diagnóstico de riesgo de HTA en los menores. Las variables que no aparecen tienen valor cero
En la Fig. 2 puede observarse la influencia de cada una de las variables medidas en la predicción del riesgo de padecer o no HTA, al entrenar el algoritmo NSLV. Para obtener dicha relación fue utilizado el software Concept Explorer20, donde los objetos se corresponden con las reglas y los atributos con las variables medidas en el estudio.
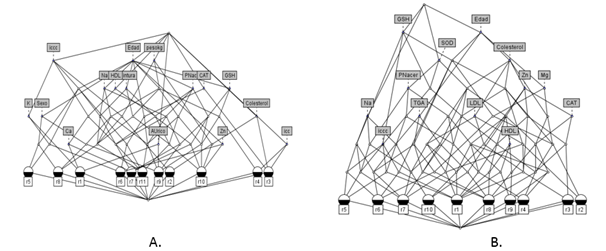
Fig. 2. Relación de las variables en la A. Predicción de un niño Normotenso y B. Predicción de un niño con riesgo de HTA.
En este caso, se puede observar que nuevamente la edad, la concentración de GSH y SOD y el colesterol eran las variables que se utilizaban para predecir el riesgo de HTA. En cambio, para el diagnóstico de un niño Normotenso, los criterios de edad, peso y la clasificación del índice cintura-cadera eran los más utilizados.
Discusión
De acuerdo a los valores obtenidos en las métricas evaluadas, las reglas construidas con el algoritmo Ishibushi99 son capaces de predecir con un mayor grado de certeza (98.66%) el riesgo de HTA en los niños cuando realmente la padezcan, mientras que los mayores casos en los que se predecía un estado saludable eran obtenidos usando el algoritmo NSLV. Sin embargo, la precisión obtenida por NSLV es mayor que el resto de los algoritmos, por lo que es muy probable que los niños que son diagnosticados con HTA usando este algoritmo sean realmente portadores de esta enfermedad. Esto es contrastado con el hecho de que la mayor probabilidad de que un niño realmente no padezca HTA cuando es diagnosticado como tal, es alcanzada con el algoritmo Ishibushi99. Dado que la sensibilidad y especificidad son valores intrínsecos al test diagnóstico; o sea, son valores teóricos que no varían entre poblaciones; para los resultados obtenidos es mejor utilizar los valores predictivos (positivos o negativos) como criterio para seleccionar el mejor algoritmo. Esto se debe a que ellos evalúan el comportamiento de la prueba diagnóstica en una población con una determinada proporción de enfermos, por lo que sirven para medir la relevancia de la sensibilidad y especificidad en la población.
Por ello, NSLV ofreció los mejores resultados según la precisión del algoritmo que reflejaba una alta probabilidad de que un niño padeciese realmente la enfermedad cuando era diagnosticado con ella.
A diferencia de otros algoritmos, NSLV forma las reglas utilizando las etiquetas lingüísticas de los conjuntos borrosos y no el rango en el que se mueve cada variable dentro del conjunto borroso. Las posibles etiquetas lingüísticas para las variables numéricas son VeryLow, Low, Medium, High y VeryHigh de acuerdo a los extremos de los valores medidos. Esto hace que el criterio del especialista juegue un papel decisivo en aceptar o no la regla que se propone. En cambio, reglas construidas utilizando los extremos de los conjuntos borrosos darían un enfoque más preciso en el momento de tomar una decisión, pero se vería limitado ante valores nuevos que no se encuentran dentro del rango inicial de la variable. Para las variables nominales, el algoritmo mantiene los valores especificados en la definición de ellas. Por ejemplo, en la Fig. 3 se pueden observar tres reglas difusas, de las 21 construidas por el algoritmo entrenado con todos los datos. Según la segunda regla, se puede concluir que, si el niño no es de raza Blanca, tiene altas concentraciones de superóxido dismutas, la concentración en sangre de GSH es baja y la de Sodio es muy alta, el peso al nacer es muy alto y la clasificación del índice cintura-cadera es Alto entonces es muy probable que pueda padecer HTA con grado de certeza 1.0. De la misma forma se pueden realizar conclusiones sobre la influencia de otras variables en este diagnóstico.

Este conocimiento puede ayudar a los especialistas a diagnosticar esta enfermedad en los niños y orientar mejor los exámenes médicos a realizar. Se recomienda como trabajo futuro extender el estudio a otros grupos de edades y considerar nuevas variables que están siendo relacionadas en las últimas investigaciones con la hipertensión.
Conclusiones
En el presente trabajo se analiza la aplicación de sistemas neuroborrosos para diagnosticar el riesgo de padecer hipertensión arterial en niños. De los tres algoritmos analizados, fue determinado que con la aplicación del algoritmo NSLV se obtienen mejores resultados en la clasificación en términos de especificidad y los valores predictivos positivos. Además, se obtienen un conjunto de reglas que facilitan el diagnóstico del riesgo de hipertensión arterial. Por último, se distinguieron un grupo de variables que pueden ser consideradas para asistir el diagnóstico de los especialistas.

