










 Servicios personalizados
Servicios personalizados Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Desde el inicio de la digitalización de los valores de carga periódica de los alimentadores de circuitos de distribución, la selección de las curvas típicas diaria de estos, constituye una útil herramienta para el cálculo de las pérdidas de energía, reconfiguración, pronósticos de carga [1] y hasta cambios en las tarifas [2] y el sistema de facturación a los usuarios.
Con el incremento de la capacidad de almacenamiento de datos, del número de equipos de medición remota instalados incluso del lado del cliente [3] y de la capacidad de procesamiento de dichos datos, se han implementado varias técnicas de selección, apoyadas en herramientas estadísticas y hasta la inteligencia artificial, sin embargo, son escasas las investigaciones sobre la base de las teorías modernas de la potencia, aunque fenómenos como la asimetría y los armónicos asociadas a estas son comúnmente analizados, pero sin conjugarse en un modelo integrador.
La literatura muestra como se han ido perfilando los estudios en estas vertientes por un lado la modernización de las teorias de la potencia y por otro la construcción y aplicación de las curvas típicas de carga. En el año 1999 Emanuel validó en [4], la otrora criticada potencia aparente de Buchholz, demostrando que elevada a la segunda potencia tiene una relación lineal con las pérdidas de energía ante cargas desbalanceadas y/o distorsionantes, condición que no cumplen ni la forma vectorial, ni aritmética de la potencia aparente, lo que se publicó en el año 2000 en la norma IEEE Std. 1459 en su versión “trial use”, siendo ascendida a “full use” en 2002 y actualizada en 2010. A pesar que define las potencias debidas a las ineficiencias del sistema [5], no logra integrarlas en una ecuación y en la definición de los sistemas de cuatro hilos, sobredimensiona los efectos del conductor neutro sobre el desequilibrio [6] y la distorsión [7, 8], incluyendo un factor de relación entre la resistencia de este último y la de línea, que reconoce que en la práctica es casi imposible de obtener con exactitud.
En 2004 Leonardo Casas y Jorge A. Leyva publican las ventajas de la aplicación informática “radial” [9], destacando entre las ventajas del Software, el cálculo en cada nodo con la curva de carga a partir de las cargas típicas de los bancos y su reajuste a partir de la curva diaria típica del circuito. Mostrando la precisión y robustes de los sistemas backward-forward por lo que continúa siendo muy utilizado en Cuba [10], aunque utiliza en sus cálculos la potencia aparente vectorial (Sv) por lo que no tiene en cuenta la distorsión, solo parcialmente la asimetría.Gemignani My otros en 2009 resumen diferentes metodologías para los procesos de selección de curvas típicas, tanto a nivel de sistema como por clientes [11], donde entre otras se plantea que la técnica denominada “Mayor impacto en el sistema” tiene resultados satisfactorios para curvas con diferentes comportamientos, ya que da el peso adecuado cuando se combinan altas demandas constantes y bajas demandas con factores de carga bajos, por lo que se selecciona para desarrollar este trabajo.
En 2018 Ali Selim y otros [12], proponen un método novedoso para mejorar el backward-forward tradicional con el ajuste a la curva de carga de la subestación alimentadora, mostrando las ventajas en menor carga computacional de la curva de datos de 15 minutos también T. Muttaqi y otros en 2019 [13], trabajaron en ese sentido en este caso potenciando la interacción con la medición remota (AMI) pero introduciendo correcciones por errores en la medición aunque al igual que L. Casas basan sus cálculos solo en las potencias activa y reactiva y no se evalúan otras potencias ineficientes en la red. Diefenthäler AT y colaboradores en 2019 [14], obtuvieron las curvas de carga típicas para cada estación meteorológica de dos circuitos de distribución primaria, utilizando el método de mínimos cuadrados no lineales y las series de Fourier, con una precisión superior al 99% aunque los datos recolectados se refieren a la potencia activa, la que no define la demanda máxima real del sistema. En 2018 González-Cabrera y otros demuestran las ventajas de la curva de carga diaria representativa sobre la curva de duración de carga para la Planificación de Expansión de la Transmisión [15], porque obtiene evaluaciones más cercanas de la variabilidad y espacialidad de la demanda, es decir, estimaciones más cercanas del costo de operación. En 2020 G. Gutiérrez-Alcaraz et al [16], mejoran este modelo utilizando las curvas estacionales seleccionadas mediante la técnica “K-means” pero utilizan las curvas de carga referidas a la potencia activa medida, no tienen en cuenta las potencias no útiles.
En 2020 V. León [17], Replantea la relación de la potencia de Buchholz con 4 potencias donde se define tanto el aprovechamiento de la energía como sus pérdidas por ineficiencias y propone una potencia más, la potencia de desplazamiento del neutro que define la cantidad de energía aparente o impacto en las fuentes y cargas causadas por la operación de la ruta del neutro (real o virtual) en los sistemas de energía de 4 hilos. De esta forma resuelve el problema inconcluso de la IEEE 1459, ya que propone una solución practica para determinar la resistencia del neutro en la red y una ecuación que integra las potencias fundamentales y las ineficientes igualándose a la potencia aparente de Buchholz, aunque se centra en la correspondencia con los valores instantáneos de la potencia propuestos por Steinmetz y es necesaria su validación practica en el dominio del tiempo para el cálculo de las pérdidas de energía.
Materiales y métodos
En las referencias bibliográficas consultadas se utiliza el valor de la potencia activa para definir el día típico, pero además de la potencia útil para la transferencia de energía (o potencia activa), la potencia generada por un sistema eléctrico trifásico incluye componentes no útiles que deben tenerse en cuenta en el análisis de la transferencia de energía pues influyen directamente en las pérdidas y calidad de energía, así como en el perfil de tensión en toda la red. Las diferencias de fase entre la tensión y la corriente dan como resultado una potencia reactiva, y un sistema eléctrico trifásico desequilibrado produce la denominada potencia de desequilibrio.
Además, dichos sistemas eléctricos están diseñados para trabajar con voltajes y corrientes sinusoidales, y el uso de cargas no lineales y/o variantes en el tiempo cada vez más comunes, distorsiona las formas de onda de tensión y corriente, lo que resulta en la creación de componentes armónicos [18]. El análisis de la generación y propagación de componentes armónicos a través de un sistema eléctrico se denomina análisis de flujo de potencia armónico. Aunque aún no existe un consenso total, la mayoría de los autores [4, 17, 19] coinciden con la norma IEEE 1459 en que la potencia aparente total para un sistema desequilibrado, expresada por Buchholz integra todas las potencias presentes en los sistemas eléctricos, esta magnitud, expresada en función de los valores eficaces o RMS, de las tensiones y corrientes de las fases o en función de valores de secuencia, es muy utilizada a nivel de investigación desde hace casi tres décadas.
En el caso de la Empresa eléctrica de Camagüey casi la totalidad de las redes de distribución son de cuatro hilos en estrella, como queremos definir la curva típica de carga desde el lado de la fuente, consideramos que el conductor neutro es un subsistema diferente a la fuente y carga del sistema, la fuente y la carga pueden considerarse como un subsistema de tres puertos [17]. Por lo tanto, la potencia aparente de la fuente se puede expresar de acuerdo con el enfoque de Buchholz de la siguiente manera: vea ecuación (1).
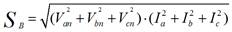 (1)
(1)
donde:
V xn |
es la tensión eficaz entre cada fase y el neutro y I x son las corrientes eficaces de cada fase. |
Adquisición y preprocesamiento de datos históricos
Para el diseño de la aplicación de cálculo e interface con la base de datos se decidió utilizar Python como lenguaje de programación, en su versión 3.7. Apoyándose sobre todo en un “framework” basado en este lenguaje con el nombre de Django. El tema de la autenticación de usuarios fue de mucho peso a la hora de elegir este framework, pues la seguridad era uno de los requisitos para tener acceso a la base de datos del “ION Enterprise”, además se usó la librería de código abierto “Pandas” comúnmente utilizada dentro de los desarrolladores de Python, dentro del ámbito de Data Science y Machine Learning, ya que ofrece unas estructuras muy poderosas y flexibles que facilitan la manipulación y tratamiento de datos, estos son recolectados ejecutando una consulta a través del Framework (marco de trabajo) Django, este lo almacena en una estructura de datos llamado “queryset”, sin embargo, esta estructura de datos no es la óptima para realizar el análisis de los datos, por lo que se convierte mediante la librería pandas en un “dataframe”, que no es más que una matriz de dos dimensiones.
La base de datos de las mediciones empleadas esta alojada en SQL Server 2008 R2, administrada por el softwarede gestión de la energía “PowerLogic ION Enterprise V6”(Usado bajo licencia ION Enterprise 6.0 -OPC-0DL para la Unión eléctrica UNE,Cuba) que encuesta los equipos de medida en un periodo preseleccionado de 15 minutos, todos del mismo fabricante (Schneider), lo que es una ventaja pues se pueden recuperar automáticamente datos almacenados en el equipo de medición, pero que no pudieron ser encuestados en el momento por problemas en las comunicaciones. Con el rápido desarrollo de las tecnologías de almacenamiento digital y comunicación, se ha vuelto más fácil y menos costoso obtener y almacenar cantidades masivas de datos. Con los beneficios también han traído consigo un nuevo problema, es decir, un conjunto de datos más grande tiene una mayor posibilidad de contener errores por lo que es necesario el preprocesamiento que comienza con la limpieza de los datos.
Dos problemas típicos con los datos medidos automáticamente son los valores perdidos y los valores atípicos, por lo tanto, las dos tareas principales de la limpieza de datos son el manejo de los valores perdidos y la detección y eliminación de valores atípicos [20]. Los valores faltantes, ocurren cuando no se almacenan valores de datos para la variable durante un período de tiempo corto debido a fallas del sensor o problemas de comunicación, Los valores faltantes dentro de las 2h (9 registros) se complementaron a través de la interpolación lineal [21], los perfiles de carga diarios con valores faltantes de más de 2 h se eliminaron del conjunto de datos [22]. Los valores atípicos son observaciones que parecen ser inconsistentes con el resto de un conjunto de datos específico.
Los valores atípicos pueden surgir por varias razones, como errores humanos, errores de instrumentos y un cambio repentino en el comportamiento del sistema, en este caso como estamos en presencia de circuitos de distribución radial pero con posibles reconfiguraciones automáticas ante averías, se identificaron las causas comunes, como cambios de esquema, falta de servicio por fallas o déficit de generación, con un típico incremento de la carga por encima de la media.
Una vez se restablece el servicio, estos días se eliminan del estudio y se detectan a partir de la retroalimentación con la base de datos del sistema de gestión de redes (SIGERE) de la Empresa eléctrica de Camagüey que almacena estos eventos en el conjunto de tablas que interaccionan con el módulo denominado “SWICHING” administrado y actualizado por el despacho de cargas (Ver figuras 1a y 1b donde se resaltan en rojo los meses con cambios de esquema en los circuitos).
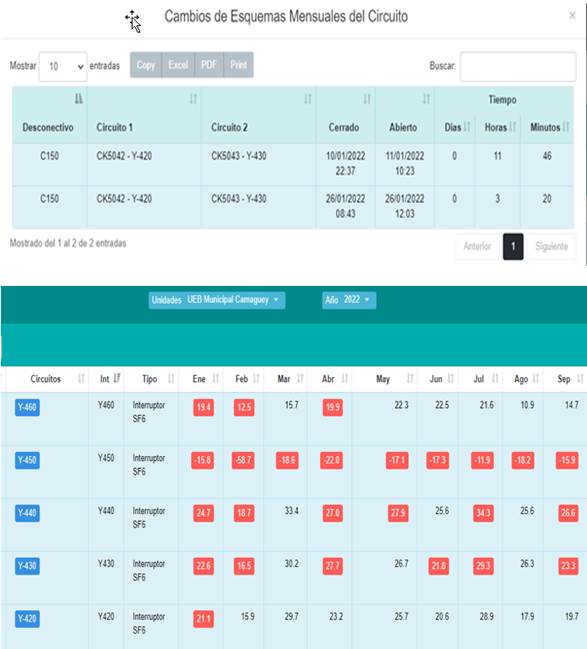 (Fuente : Web Sigere Camagüey 2023)
(Fuente : Web Sigere Camagüey 2023)Fig. 1 a. Descripción de los cambios de esquema señalizados en un mes (Fuente:Web Sigere Camagüey2023). b. Cambio de esquema señalizada en rojo en el mes
El proximo paso consiste en la Partición y Reducción de datos, Los datos operativos de carga generalmente se almacenan en un formato tal que cada columna representa los valores de una variable en instantes de tiempo consecutivos, y cada fila representa una observación muestreada en un instante específico en el tiempo El volumen de los datos almacenados continúa aumentando con el tiempo. Como resultado, los datos operativos de la red se vuelven altamente dimensionales en espacios temporales (número de filas) y espaciales (número de columnas). Las variables redundantes en el conjunto de datos de entrada disminuirán la precisión, la estabilidad y la eficacia del modelo.
La reducción de datos (también llamada ingeniería de características en el análisis de big data) tiene como objetivo identificar los factores/variables más relevantes/influyentes, reducir las dimensiones de los conjuntos de datos, minimizar el riesgo de ajuste excesivo, mejorar la eficiencia del cálculo y, mientras tanto, retener o mejorar el rendimiento del modelo. La base de datos “ION_Data” cuenta con 26 tablas de las cuales solo se usaron 4 para implementar la aplicación, estas son: “Dalalog”, “DatalogStamp”, “Source”, “Quantity”, pues contienen los datos necesarios para implementar los objetivos propuestos.
Para seleccionar los datos que posteriormente van a ser procesados, es necesario primero usar el enfoque de filtro, definir tres parámetros iniciales, la subestación de distribución, el circuito que se desea analizar y el periodo de análisis que aunque es una elección del usuario, se propone en este trabajo dividir el año máximo en 2 periodos correspondientes a los periodos estacionales de Cuba donde el comportamiento de las curvas de carga se separan drásticamente en solo un día, debido al cambio oficial al horario de verano, por lo que inmediatamente se desplaza el pico de consumo y se desplazan las cargas de iluminación del resto, en el año 2022 este horario estuvo vigente desde el domingo 13 de marzo hasta el domingo 6 de noviembre, por lo que tenemos un máximo de 238 días en donde cada día está caracterizado con 96 valores de medidas cuarta horarias, por cada una de las 6 variables a tomar en cuenta, luego se calcula la Potencia aparente de Buchholz(SB) por cuarto de hora reduciendo de 137088 valores a 22848 en el periodo más largo.
El próximo enfoque es adoptar un método de extracción de características, como un análisis de componentes principales, en el que se obtiene un nuevo conjunto de datos con dimensiones más bajas a través de la extracción de características de ingeniería y estadística [20], estos son, la suma (∑SB) y el valor máximo de las potencias aparentes en el día, y su factor de valor atípico local (LOF por sus siglas en ingles), este es una estrategia clásica de detección de valores atípicos [21, 23, 24], aplicable en series temporales con precisión [25], aunque para esta técnica, el concepto de vecindad es más complejo en series de tiempo, porque los datos están ordenados.
Para tener en cuenta la temporalidad debe referirse a un periodo ventana que puede ser móvil [26], en este trabajo su uso una ventana de tiempo fija centrada en la hora de SBmáx con 11 registros, 5 a cada lado de este valor, para un periodo de 2 horas y media, lo que tiene el beneficio de reducir la carga computacional. El grado de anomalía de la carga máxima en el conjunto de datos adyacente se considera atípico si tiene un valor significativamente mayor que 1, un valor de aproximadamente 1 indica que la carga en el momento t está muy cerca de sus vecinos y, por lo tanto, no es una carga anormal. Este factor se determina por la ecuación (2), mediante la herramienta “PyOD” [27].
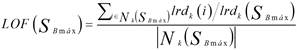 (2)
(2)
donde:
lrd k (i) |
es la densidad de accesibilidad local del k-vecino (objeto i) más cercano del punto que ocupa SBmax |
lrd k (SBmax) |
es la densidad de accesibilidad local de la carga SBmáx en su vecindad de k distancia Nk(SBmáx) |
Nk(SBmáx) |
distancia entre los puntos k de la vecindad. k es el número de puntos mínimos en la vecindad, normalmente establecido en no menos de 10 para eliminar las fluctuaciones estadísticas no deseadas [21]. |
Análisis de datos para la obtención de la curva típica de carga diaria
El enfoque en esta etapa es utilizar un método de selección de características en el que se eligen las variables más relevantes para el problema actual. Uno métodos de selección de características de uso común es el método de filtro, el que se implemento a partir de los datos extraidos. El grado de anomalía de la carga máxima en el conjunto de datos adyacente LOF(SBmáx) se fija para este estudio de forma empirica y se considera atípico si es mayor que 1,5 [28], por lo que los días que tengan asociado este valor atipico se descartaran, con los restantes se calcula el promedio de consumo dividiendo ∑SB entre el numero días seleccionados y se preseleccionan los días que esten dentro del rango de un mas menos 5%, aunque el algoritmo incluye un reajuste incremental de este valor si ninguna curva procesada satisface el requisito.
Por ultimo, de las candidatas disponibles se selecciona automaticamente la que cuente con el mayor valor de potencia aparente (SBmáx) asociado.Este procedimiento final sobre las curvas seleccionables permite detectar el día de mayor impacto sobre las redes de distribución de este circuito, que es equivalente a multiplicar la demanda media con la demanda máxima y seleccionar el mayor valorsegún se plantea en el modelo de “Mayor impacto en el sistema” [11].
Con el día seleccionado se consulta nuevamente la base de datos ION Data y se extraen las potencias activas (P) y reactivas (Q) por fase para el calculo de las pérdidas técnicas, pues hasta el momento del estudio no se encontro una aplicación que utilice la potencia aparente de Buchholz o la variante de la IEEE 1459 como base para la corrida de flujo en redes de distribución. El proceso de selecciónse muestra en la figura 2.
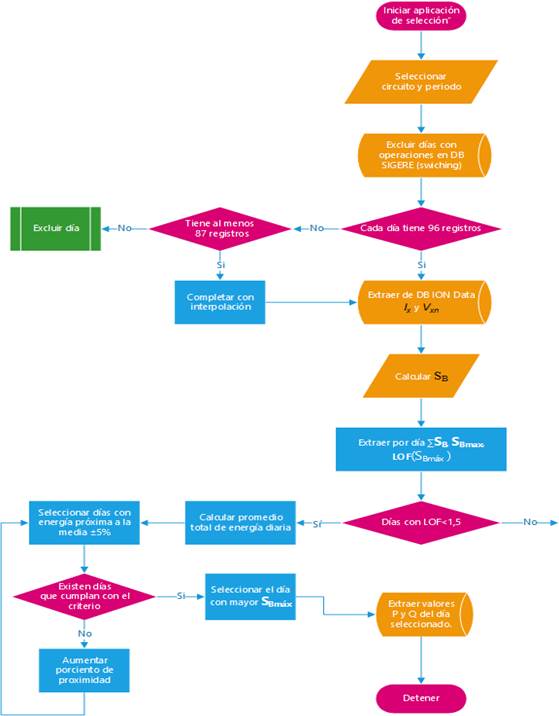
Resultados y(o) discusión
El estudio se implementó en los 24 circuitos de distribución del municipio Camagüey controlados por el ION Enterprise, de los que se muestran los resultados del circuito Y-420, que tiene el menor número de interrupciones (Ver fig. 1b) y tiene un instrumento de medición ION 7350. Es un circuito de 13,2 kV con 3925 clientes en zonas suburbanas y rurales, con 72 bancos de transformadores con 3818.5 kVA instalados en 69 secciones.
El estudio abarco todo el año 2022 para aplicarlo al cálculo de pérdidas técnicas y hacer un balance con las pérdidas no técnicas separando la energía facturada de cada periodo por circuito. En las figuras 3 y 4, se observan las 180 curvas seleccionables después del preprocesamiento de los datos, 64 para los periodos de horario de verano y 116 en el horario normal o periodo invernal y muestran el característico comportamiento residencial al que pertenecen el 97% de los clientes asociados, la aplicación diseñada no muestra estos valores, se extrajeron para verificar el desempeño del proceso y se graficaron en Microsoft Excel.
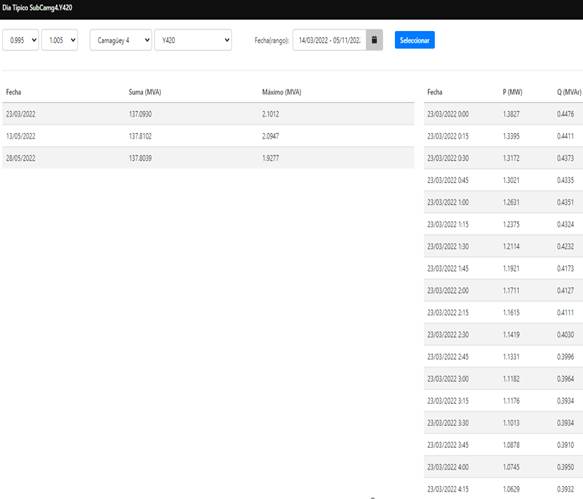
En la figura 5, se muestra el formulario para el interfaz con el usuario, donde en el encabezado se seleccionan la subestación, el circuito, el rango de fechas y porciento de desviación respecto a la media de consumo, aunque la proximidad a la media de consumo tiene el valor predeterminado de ±5 % inicial propuesto, este se puede variar entre un 1% y un 10% según la necesidad de precisión, aunque el algoritmo incrementa el valor prefijado hasta que al menos un día coincida con el criterio, lo que ocurre a medida que se acorta el rango de fechas del periodo a explorar, donde hay más dispersión entre la media de consumo y el real por día.
Debajo, las 3 primeras columnas de izquierda a derecha muestran el día, la suma de la potencia aparente de Buchholz como indicador de consumo y el valor máximo medido de esta potencia respectivamente, estos son los datos de las curvas cuya media está dentro del porciento de desviación y la máxima demanda no era un valor atípico según su factor de valor atípico local, de las cuales el algoritmo selecciona automáticamente el día de máxima demanda mostrando a la derecha la fecha y hora, potencia activa y reactiva en este día cada 15 minutos, exportados en detalle a la tabla 1, ademas se exportan estas potencia las corrientes y las tensiones por fase del circuito en otra pesaña.

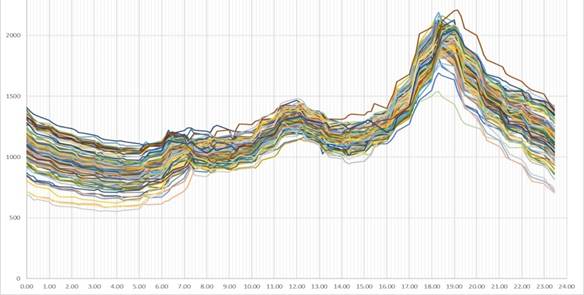
La figura 6, muestra el contraste entre la curva típica obtenida de un día real de la temporada invernal y la curva virtual modelada desde las curvas seleccionables con la tecnica k-means punto a punto, la que muestra practicamente un promedio en cada cuarto de hora, este modelo no es deseable, en la práctica estos valores medios ocultan información sobre desviaciones máximas que se pierden en el propio proceso, como es el caso del pérfil de tensión y es la demanda máxima la que ofrece mayor interés ya que aquí es donde se presenta la máxima caída de tensión en el sistema y por lo tanto cuando se ostentan las mayores pérdidas de energía y potencia.
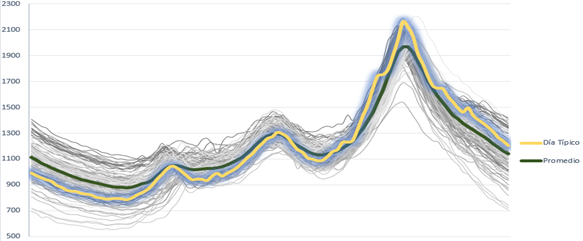
Fig. 6 Carga diaria registrada cada 15 minutos del Circuito primario Y-420 en el periodo de “horario normal o invierno”
Tabla 1 Valores de potencia activa y reactiva en el día seleccionado como típico en verano (Fuente propia)
| Fecha | P (MW) | Q (MVAr) | Fecha | P (MW) | Q (MVAr) | Fecha | P (MW) | Q (MVAr) |
|---|---|---|---|---|---|---|---|---|
| 23/03/2022 0:00 | 1.3827 | 0.4476 | 23/03/2022 8:00 | 1.0004 | 0.4209 | 23/03/2022 16:00 | 1.2894 | 0.5259 |
| 23/03/2022 0:15 | 1.3395 | 0.4411 | 23/03/2022 8:15 | 0.9595 | 0.4104 | 23/03/2022 16:15 | 1.294 | 0.5266 |
| 23/03/2022 0:30 | 1.3172 | 0.4373 | 23/03/2022 8:30 | 0.9797 | 0.4148 | 23/03/2022 16:30 | 1.3072 | 0.533 |
| 23/03/2022 0:45 | 1.3021 | 0.4335 | 23/03/2022 8:45 | 0.9712 | 0.4216 | 23/03/2022 16:45 | 1.3217 | 0.526 |
| 23/03/2022 1:00 | 1.2631 | 0.4351 | 23/03/2022 9:00 | 0.9869 | 0.4236 | 23/03/2022 17:00 | 1.352 | 0.5361 |
| 23/03/2022 1:15 | 1.2375 | 0.4324 | 23/03/2022 9:15 | 0.9748 | 0.4296 | 23/03/2022 17:15 | 1.4029 | 0.5599 |
| 23/03/2022 1:30 | 1.2114 | 0.4232 | 23/03/2022 9:30 | 0.9711 | 0.432 | 23/03/2022 17:30 | 1.4671 | 0.5659 |
| 23/03/2022 1:45 | 1.1921 | 0.4173 | 23/03/2022 9:45 | 0.9852 | 0.448 | 23/03/2022 17:45 | 1.5472 | 0.579 |
| 23/03/2022 2:00 | 1.1711 | 0.4127 | 23/03/2022 10:00 | 0.9974 | 0.4469 | 23/03/2022 18:00 | 1.6018 | 0.5758 |
| 23/03/2022 2:15 | 1.1615 | 0.4111 | 23/03/2022 10:15 | 1.0234 | 0.4558 | 23/03/2022 18:15 | 1.6878 | 0.5739 |
| 23/03/2022 2:30 | 1.1419 | 0.403 | 23/03/2022 10:30 | 1.0493 | 0.4466 | 23/03/2022 18:30 | 1.748 | 0.5759 |
| 23/03/2022 2:45 | 1.1331 | 0.3996 | 23/03/2022 10:45 | 1.115 | 0.4677 | 23/03/2022 18:45 | 1.8293 | 0.5741 |
| 23/03/2022 3:00 | 1.1182 | 0.3964 | 23/03/2022 11:00 | 1.1583 | 0.4974 | 23/03/2022 19:00 | 1.8895 | 0.5851 |
| 23/03/2022 3:15 | 1.1176 | 0.3934 | 23/03/2022 11:15 | 1.1918 | 0.4879 | 23/03/2022 19:15 | 1.9051 | 0.5914 |
| 23/03/2022 3:30 | 1.1013 | 0.3934 | 23/03/2022 11:30 | 1.2367 | 0.4916 | 23/03/2022 19:30 | 1.8954 | 0.5894 |
| 23/03/2022 3:45 | 1.0878 | 0.391 | 23/03/2022 11:45 | 1.2744 | 0.4954 | 23/03/2022 19:45 | 1.9351 | 0.6003 |
| 23/03/2022 4:00 | 1.0745 | 0.395 | 23/03/2022 12:00 | 1.2714 | 0.5032 | 23/03/2022 20:00 | 1.9762 | 0.6077 |
| 23/03/2022 4:15 | 1.0629 | 0.3932 | 23/03/2022 12:15 | 1.254 | 0.4973 | 23/03/2022 20:15 | 1.9536 | 0.6037 |
| 23/03/2022 4:30 | 1.0526 | 0.3929 | 23/03/2022 12:30 | 1.2452 | 0.4963 | 23/03/2022 20:30 | 1.919 | 0.6081 |
| 23/03/2022 4:45 | 1.0571 | 0.3817 | 23/03/2022 12:45 | 1.2428 | 0.4952 | 23/03/2022 20:45 | 1.8443 | 0.6079 |
| 23/03/2022 5:00 | 1.0704 | 0.3922 | 23/03/2022 13:00 | 1.2026 | 0.5101 | 23/03/2022 21:00 | 1.7885 | 0.6085 |
| 23/03/2022 5:15 | 1.0752 | 0.3997 | 23/03/2022 13:15 | 1.1685 | 0.5047 | 23/03/2022 21:15 | 1.7449 | 0.6047 |
| 23/03/2022 5:30 | 1.0955 | 0.4018 | 23/03/2022 13:30 | 1.1784 | 0.4956 | 23/03/2022 21:30 | 1.7365 | 0.6081 |
| 23/03/2022 5:45 | 1.0814 | 0.3945 | 23/03/2022 13:45 | 1.175 | 0.4919 | 23/03/2022 21:45 | 1.7046 | 0.5942 |
| 23/03/2022 6:00 | 1.0988 | 0.392 | 23/03/2022 14:00 | 1.169 | 0.4955 | 23/03/2022 22:00 | 1.664 | 0.5851 |
| 23/03/2022 6:15 | 1.1301 | 0.4075 | 23/03/2022 14:15 | 1.1713 | 0.4952 | 23/03/2022 22:15 | 1.6415 | 0.572 |
| 23/03/2022 6:30 | 1.1522 | 0.4177 | 23/03/2022 14:30 | 1.1798 | 0.4939 | 23/03/2022 22:30 | 1.6347 | 0.5646 |
| Continuación de la Tabla 1 | ||||||||
| 23/03/2022 6:45 | 1.1819 | 0.4289 | 23/03/2022 14:45 | 1.2105 | 0.493 | 23/03/2022 22:45 | 1.6407 | 0.5598 |
| 23/03/2022 7:00 | 1.1428 | 0.4366 | 23/03/2022 15:00 | 1.2211 | 0.5086 | 23/03/2022 23:00 | 1.6196 | 0.5501 |
| 23/03/2022 7:15 | 1.118 | 0.4322 | 23/03/2022 15:15 | 1.2449 | 0.5241 | 23/03/2022 23:15 | 1.5779 | 0.5434 |
| 23/03/2022 7:30 | 1.0694 | 0.4302 | 23/03/2022 15:30 | 1.2469 | 0.5241 | 23/03/2022 23:30 | 1.556 | 0.5342 |
| 23/03/2022 7:45 | 1.0482 | 0.4351 | 23/03/2022 15:45 | 1.2732 | 0.5248 | 23/03/2022 23:45 | 1.5044 | 0.5253 |
Para ilustrar las ventajas del uso de la potencia aparente de Buchholz en el proceso de selección, con respecto a la potencia activa, se implementa la aplicación directamente sobre los valores de potencia activa medidos y no con los valores de corriente y tensión eficaces, lo que arrojo como el día típico de carga el 17/3/2022, debido al instrumento de medición utilizado se aplica la ecuación de la IEEE 1459 epígrafe 3.2.3.1para obtener la potencia no activa (N) mostrada en la ecuación (3).
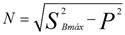 (3)
(3)
obteniéndose los resultados de la tabla 2, donde se observa que, aunque solo hubo un incremento de un 3,6 % de la potencia activa, la potencia no activa lo hace en un 5,7 % y las pérdidas de potencia que son directamente proporcionales a la potencia aparente de Buchholz al cuadrado, se incrementan en un 7,6 % lo que justifica su elección.
Conclusiones
Con la proliferación de la medición inteligente y la infraestructura de comunicaciones se han incrementado los métodos de construcción de curvas de cargas y análisis bottom-up, no sucediendo lo mismo con el perfil de carga de los alimentadores de distribución, donde se enmarca este trabajo proponiendo una variante de obtención de curva típica de carga por el método de “Mayor impacto en el sistema”, ideal para complementar las corridas de flujo interactivas Backward-Forward. Otra ventaja de la medición inteligente es el incremento de los parámetros de medición con los cuales, como se muestra en este trabajo, es posible obtener los efectos totales de las potencias, tanto de la útil como de las que provocan ineficiencias y problemas en la calidad de la energía.
Aunque por deficiencias de las aplicaciones para el cálculo de las pérdidas técnicas actuales finalmente se utilizan los parámetros asociados a la teoría clásica de la potencia, el seleccionar la curva de carga con este método permite encontrar el día real con el comportamiento medio en el periodo seleccionado, pero a la vez con el mayor impacto sobre las pérdidas técnicas, en el sistema a analizar. Para el futuro se está trabajando en el incremento del número de mediciones a un periodo de 5 minutos lo que permite capturar mejor los picos de demanda e incrementar la precisión de detección de valores atípicos al aumentar el número de puntos y por ende la densidad a evaluar en el mismo periodo de tiempo, aunque con el incremento de los requisitos de almacenamiento y de capacidad de cálculo.

