










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería Electrónica, Automática y Comunicaciones
versión On-line ISSN 1815-5928
EAC vol.35 no.2 La Habana Mayo.-ago. 2014
ARTICULO ORIGINAL
Método para detección de estados estacionarios: aplicación a unidades de generación eléctrica
Method to steady state detection: application to electrical generation units
MSc. Luis Vázquez Seisdedos, Dr. Rafael A. Trujillo Codorniu, Dra. Yolanda Llosas Albuerne, Ing. David Díaz Martínez
Departamento de Control Automático de la Universidad de Oriente, Santiago de Cuba, Cuba. E-mail: lvazquez@fie.uo.edu.cu , trujillo@edistancia.uo.edu.cu , yolanda@fie.uo.edu.cu , ddiaz@fie.uo.edu.cu
RESUMEN
La detección de ventanas o intervalos en los que un proceso continuo esté operando en un estado estacionario es útil para la monitorización a largo plazo y en especial cuando se tienen modelos de estado estacionario que están siendo usados para la optimización del proceso. En el presente trabajo se presenta un método, bajo el nombre de sigma gamma, basado en ventanas deslizantes, que mejora significativamente los algoritmos existentes. Combina algoritmos basados en el análisis de la desviación estándar de las mediciones con el método de las medias móviles y puede aplicarse no sólo a mediciones contaminadas con ruido blanco; sino también sobre series temporales afectadas por ruido coloreado. Se evalúa su desempeño comparándolo con dos de los métodos más recientes. Las pruebas indican que para los diferentes niveles y tipos de ruido analizados el método propuesto ofrece una reducción estadísticamente significativa de los errores de Tipo I y de Tipo II. Las series temporales que sirven de base a los experimentos de evaluación están relacionadas con los tipos de respuestas esenciales bajo las que operan las unidades de generación eléctrica.
Palabras claves: detector de estado estacionario, series temporales, ruido coloreado, unidad de generación eléctrica.
ABSTRACT
Detecting windows or intervals of when a continuous process is operating in a state of steadiness is useful for long term monitoring and especially when steady-state models are being used to optimize the process or plant on-line. In this paper a method, which is called as sigma gamma, on moving windows based that improves significantly existent algorithms is presented. On the measurements, it combines algorithms based on standard deviation analysis with moving average method and it can be applied not only on measurements which have been corrupted by additive white noise; but also on time series which have been corrupted by additive colored noise. Its performance is evaluated by comparing with two very recent methods. For different levels and noise types, tests point out that proposed method offers a significantly reduction on Type I and Type II errors. The base time series for algorithm's testing are related with the essential waveform's response below electrical generation units' work.
Keywords: steady state detector, time series, hypothesis testing, colored noise, electrical generation unit.
INTRODUCCION
La detección adecuada de los intervalos de tiempo en los cuales un proceso se encuentra en estado estacionario es sumamente importante para el monitoreo y optimización del mismo. Si el proceso 2 no está realmente en estado estacionario (EE), o sea, se encuentra en estado transitorio (ET),la aplicación de modelos de estado estacionario al mismo puede provocar estimaciones incorrectas de parámetros, la toma de decisiones inapropiadas y operación inestable cuando el sistema está operando a lazo cerrado en tiempo real. Recientemente a esta temática se han dedicado numerosos trabajos1,2,3,4,5,6,7,8y existen diversos algoritmos para la detección de segmentos de muestras en estado estacionario.
Los trabajos previos en el área de detección de estado estacionario (DEE) pueden ser clasificados3 en los siguientes casos:
a. Técnica basada en la regresión lineal con el objetivo de determinar el mejor ajuste con tendencia lineal para N valores anteriores de la variable. Heurísticamente, si el proceso está en EE, entonces la pendiente de la línea de tendencia será idénticamente igual a cero. Sin embargo debido a la presencia de ruido en el proceso, la pendiente puede fluctuar con valores cercanos a cero y consecuentemente, un valor de la pendiente desigual de cero, no es razón para rechazar la hipótesis de EE. Para aceptar o rechazar la hipótesis podría usarse una pruebabasada en la estadística t de Student aplicada al cociente entre el valor de la pendiente y el error estándar de ese valor. Si el cociente mencionado excede el valor crítico puede considerarse que hay suficiente evidencia para rechazar la hipótesis de que el proceso está en EE. El trabajo4 se enmarca en este caso.
b. Técnica basada en la evaluación de los valores promedios en ventanas sucesivas de datos. Se calculan estadísticos tales como; el promedio y la desviación estándar de los datos en sucesivos conjuntos de muestras. Si el proceso está en estado estacionario los promedios deben ser iguales en cada ventana. Las diferencias entre dos promedios consecutivos provocadas por la presencia de ruido pueden ser analizadas con una prueba de Student. Los trabajos2,5 son representantes de esta técnica.
c. Técnica basada en el análisis de la varianza (ver los trabajos1,6,7,8) . Se calculan valores de la media y la varianza exponencialmente ponderadas y se aplica una prueba derivada de la prueba de Fisher para aceptar o rechazar la hipótesis de estado estacionario.
Al aplicar estos algoritmos a subconjuntos de observaciones instrumentales de variables seleccionadas con el fin de poder monitorizar las degradaciones, que ocurren a largo plazo, enel proceso de generación de vapor de las Unidades de Generación Eléctrica (UGE) se detectó la inestabilidad de los mismos cuando las muestras están contaminadas con ruido auto-correlacionado (coloreado). Esto ocurre debido a que estos algoritmos generalmente asumen que el ruido presente en las muestras es blanco.
La auto-correlación en las mediciones está típicamente presente en las señales a procesar. Las razones de su presencia1 se atribuyen a la inercia térmica, los filtros en los sensores, la acción de control, etc. En muchas ocasiones se sugiere1 que es más conveniente escoger un intervalo de muestreo que elimine la auto-correlación, que modelar y compensar la auto-correlación por ensayos estadísticos; sin embargo, no siempre es posible escoger el intervalo de muestreo personalizado para cada una de las señales disponibles ya que estas son generadas por procesos de disimiles dinámicas que componen las Unidades de Generación Eléctrica. Consecuentemente se requieren algoritmos que permitan la segmentación de las largas cadenas de muestras adquiridas (series temporales) en subconjuntos que representen las transiciones y los estados estacionarios, aun cuando en las mediciones esté presente un ruido no blanco.
En el presente artículo se propone un método, denominado «sigma gamma», basado en ventanas deslizantes, que mejora significativamente la detección de estados estacionarios con respecto a los algoritmos existentes,al resultar más robusto ante la presencia de ruido correlacionado en las mediciones. Para fundamentar esta aserción se realiza un análisis comparativo de su desempeño con respecto a dos de los métodos más relevantes y actuales mencionados anteriormente. Específicamente se compara con el Método de Rhinehart1,6, y con el método de Jeffrey Kelly y Hedengren2. El algoritmo propuesto resulta una evolución de trabajos anteriores9,10,12,13,14,15aplicados a la monitorización delproceso de generación de vapor de la Central Termoeléctrica (CTE) de Felton (Cuba) y al análisis del ensuciamiento de superficies en un sobrecalentador de techo de la UGE de 200 MW de Detmaroviceen la República Checa11.
La estructura del artículo es la siguiente: En la sección Materiales y Métodos primeramente se caracteriza la operación ininterrumpida de una Unidad de Generación Eléctrica como una secuencia de estados estacionarios que representan las operaciones a diferentes niveles de potencia, lo que subraya la importancia de la correcta detección de los estados estacionarios para el monitoreo a largo plazo de la misma. A continuación se formaliza el método propuesto que consta de 3 etapas y finalmente en lasección de Resultados se realiza la comparación del mismo con el Método de Rhinehart1,6, y con el método de Jeffrey Kelly y Hedengren2. Para esta comparación se utilizan señales sintéticas cuya distribución, en intervalos de muestras de EE y ET, es conocida y se contaminan con ruidos de diferentes características espectrales y amplitud con el objetivo de verificar en qué medida cada método detecta adecuadamente, a pesar del ruido, los segmentos de EE. Para garantizar que las diferencias observadas entre los métodos es estadísticamente significativa se realizan pruebas de significación estadística mediante el análisis de varianza (ANOVA).
MATERIALES Y METODOS
1. Estados estacionarios en la UGE interconectadas a un sistema eléctrico.
El análisis de los datos históricos, almacenados en los sistemas de supervisión (SCADA), de las mediciones de la potencia en UGE operadas en carga base exhibe un patrón caracterizado por la alternancia de estados estacionarios en torno a un nivel central de potencia, ![]() y transiciones entre dichos estados tal y como se muestra en la Figura 1.
y transiciones entre dichos estados tal y como se muestra en la Figura 1.
Estas formas de onda son reflejo de la evolución de un sistema que, como el de suministro eléctrico, es considerado de gran escala y complejo de operar. Este se explica dentro de una estructura jerárquica de tres niveles17 (primario, secundario y terciario) quedando la operación en potencia de la unidad de generación como un proceso de evento discreto entre nivelesrepresentado de modo simplificado en la Figura 2.
En la Figura 2a se distinguen y denotan como aj y bi a dos tipos de segmentos de muestras. Los segmentos aj contienen a un subconjunto de muestras que corresponden a mediciones bajo los efectos del sistema de regulación primario a nivel de la planta. Los segmentos bi contienen a un subconjunto de muestras que corresponden a mediciones bajo los efectos del sistema de control de seguimiento (que al nivel de la planta responde a la imposición por el centro de despacho de un cambio de consigna en potencia). Bajo este rol de nivel secundario (en la jerarquía de distribución de magnitudes de potencia por unidad) es que se explican las formas de onda en transición. Éstas pueden ser disimiles; pero todas están acotadas según la máxima velocidad de subida o bajada de carga (que dependen de la velocidad de respuesta de la generación de vapor).
Los estados A, B, C y D de la Figura 2b están asociados a segmentos de muestras en torno a un nivel central de potencia y unas fluctuaciones definidas por el rol de la unidad generadora como parte del sistema eléctrico. Asimismo las máximas desviaciones y fluctuaciones de las lecturas en condiciones de operación de estado estacionario están normadas17,18,19. Los roles pueden ser:
(i) como generador que le suministra al sistema eléctrico una potencia base,
(ii) como generador que suministra potencia para la regulación secundaria de frecuencia del sistema eléctrico.
2. Método de detección de EE `sigma gamma'.
El método que se propone y que denominamos «sigma-gamma» se basa en la detección desegmentos de muestras de una variableque satisfacen una condición de estacionaridad expresada por un nivel de tolerancia en la variabilidad de la media y la desviación estándar. Su fundamento se resume en los siguientes aspectos:
a) Detección previa del nivel de ruido presente en las mediciones.
b) Segmentación (componente Sigma) basada en cálculo de desviación estándar ![]() .
.
c) Rectificación de coordenadas y verificación de tolerancia para cada segmento candidato (componente Gamma).
A continuación se expone en detalle cada paso.
2.1. Estimación del ruido.
En muchos casos la varianza del ruido que contamina las mediciones no es conocida de antemano y es necesario estimarla a partir de la señal ruidosa. Para la estimación previa del nivel de ruido en las mediciones existen diferentes algoritmos. En 20 se hace un análisis detallado de los mismos en el contexto de la reducción de ruido blanco en imágenes.
Una clase de estimadores hace uso de las características de la transformada wavelet discreta (DWT). La desviación estándar del ruido que contamina una señal puede ser estimada a partir de la mediana de la desviación absoluta (MAD) de los coeficientes wavelets, lo cual se basa en la hipótesis21 de que la MAD de la banda de mayor frecuencia es proporcional a la desviación estándar del ruido. El estimador que se obtiene es: (ecuación 1)

donde ![]() son los coeficientes wavelet de la banda de mayor frecuencia en la DWT. La operación MAD para un conjunto de datos
son los coeficientes wavelet de la banda de mayor frecuencia en la DWT. La operación MAD para un conjunto de datos ![]() es definida como la mediana de las desviaciones absolutas de la mediana del conjunto, o sea: (ecuación 2)
es definida como la mediana de las desviaciones absolutas de la mediana del conjunto, o sea: (ecuación 2)
Este estimador es muy usado en los algoritmos para reducir el ruido blanco gaussiano en mediciones industriales22. Sin embargo, si el ruido no es blanco la densidad espectral del mismo no es constante y por tanto este estimador no nos proporciona un valor correcto del nivel del ruido ya que el mismo sólo contiene información de la potencia del ruido en la frecuencia más alta. Si el ruido es estacionario y correlacionado se ha establecido23, 24 que la varianza del ruido que afecta los coeficientes wavelets depende del nivel de descomposición y la varianza de las primeras bandas puede ser estimada por la fórmula (1), reemplazando los coeficientes de la banda de mayor frecuencia por los coeficientes de la banda a analizar. De esta forma podemos obtener estimaciones del ruido correspondientes a diferentes frecuencias. Si se desconoce la densidad espectral del ruido un estimador global razonable es, sin duda, la media aritmética de los estimadores obtenidos para cada banda. Si se incluyen, por ejemplo, las 4 primeras bandas se obtiene el estimador ![]() que se define como: (ecuación 3)
que se define como: (ecuación 3)
donde ![]() son los coeficientes wavelet de la banda k de la DWT ordenadas en orden decreciente de la frecuencia. Observe que la fórmula (3) representa la media aritmética de las estimaciones del ruido en las 4 primeras bandas obtenidas por la fórmula (1).
son los coeficientes wavelet de la banda k de la DWT ordenadas en orden decreciente de la frecuencia. Observe que la fórmula (3) representa la media aritmética de las estimaciones del ruido en las 4 primeras bandas obtenidas por la fórmula (1).
Otra clase de técnicas de estimación de ruido usa las varianzas locales de la señal20. Para ello a partir de un punto se toma una ventana de longitud impar con centro en el mismo y se calcula la varianza de los valores que caen dentro de la ventana. La ventana se desliza para cada punto de la señal de manera que podamos obtener una varianza local para cada valor de la señal. De esta forma si la ventana se toma de longitud 2m + 1, las varianzas locales serían: (ecuación 4)
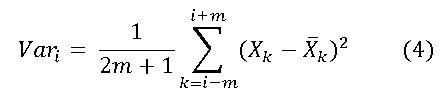
donde ![]() es la media de los valores de la ventana, o sea: (ecuación 5)
es la media de los valores de la ventana, o sea: (ecuación 5)

Obviamente, cuando el punto se encuentra cerca de los extremos de la señal, las sumatorias pueden no incluir todos los 2m+1 valores. A partir de las varianzas locales se pueden definir21 los siguientes estimadores: (ecuaciones 6, 7, 8 y 9)


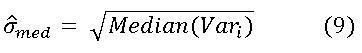
Debe señalarse que los estimadores basados en las varianzas locales dependen del ancho de la ventana deslizante. Si la ventana es muy pequeña puede que no capte la información del ruido en las frecuencias bajas. Por otro lado si la ventana es muy amplia la varianza local puede incluir demasiada información sobre la varianza de la señal base.
Para seleccionar cual estimador del nivel de ruido se utilizaría en el método Sigma-Gamma, se decidió realizar un experimento computacional consistente en tomar una señal base trapezoidal y generar a partir de ella 105 señales contaminadas con ruido blanco y 105 señales contaminadas con ruido coloreado y comparar la varianza del ruido estimado por cada método con la varianza real del ruido agregado. Las 105 señales se dividen en 7 grupos de 15 señales que tienen niveles de ruido similar. La ventana para los algoritmos de varianzas locales se tomó con 13 puntos que fue el ancho de ventana que ofreció mejores resultados en las pruebas realizadas. Para los estimadores ![]() y
y
![]() MAD se utilizó la DWT con la función madre Daubechies 4. En las siguientes Tablas 1 y 2 se muestran las desviaciones promedio del valor
MAD se utilizó la DWT con la función madre Daubechies 4. En las siguientes Tablas 1 y 2 se muestran las desviaciones promedio del valor
real obtenidas en cada grupo para el caso del ruido blanco y del ruido coloreado:
Como se puede apreciar de las Tablas 1 y 2 los estimadores ![]() mean,
mean, ![]() med y
med y ![]() MAD, y ofrecen buenos resultados para el caso del ruido blanco pero disminuyen sensiblemente su precisión en el ruido coloreado mientras que el el estimador
MAD, y ofrecen buenos resultados para el caso del ruido blanco pero disminuyen sensiblemente su precisión en el ruido coloreado mientras que el el estimador ![]() muestra consistentemente buenos resultados tanto para ruido blanco como para ruido coloreado, llegando a estimar el ruido real con un error relativo no mayor al 1,5% en el ruido blanco y no mayor al 3,5% en el ruido coloreado por lo que la conclusión es que la estimación (3) resultó más exacta que las restantes y más robusta cuando el ruido no es blanco.
muestra consistentemente buenos resultados tanto para ruido blanco como para ruido coloreado, llegando a estimar el ruido real con un error relativo no mayor al 1,5% en el ruido blanco y no mayor al 3,5% en el ruido coloreado por lo que la conclusión es que la estimación (3) resultó más exacta que las restantes y más robusta cuando el ruido no es blanco.
2.2. Segmentación (componente Sigma) basada en cálculo de desviación estándar ![]() .
.
El algoritmo de segmentación está basado en el cálculo de parámetros estadísticos sobre ventanas deslizantes de ancho tomadas sobre la serie temporal ![]() .
.
En cualquier instante la media de las muestras más recientes viene dada por: (ecuación 10)
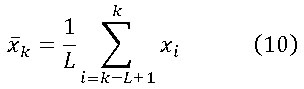
Este valor se conoce como la media de ventana móvil porque el promedio en cada instante k-ésimo se calcula con el conjunto de L valores más reciente. Esta magnitud es equivalente a la producida por un filtro pasa bajo. Las medias móviles pueden obtenerse de manera computacionalmente eficiente a partir de la siguiente expresión que vincula la media de ventana móvil en el instante con la media de ventana móvil en el instante precedente. En efecto de (10) se obtiene: (ecuaciones 11 y 12)
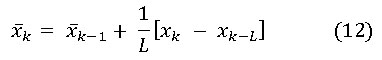
La varianza de la ventana móvil en el instante K es: (ecuación 13)
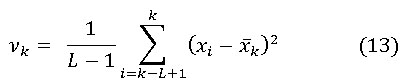
El intervalo de confianza de la varianza ![]() es, como es conocido: (ecuación 14)
es, como es conocido: (ecuación 14)

donde ![]() es el nivel de confianza y
es el nivel de confianza y ![]() es el cuantil
es el cuantil ![]() de la distribución chi cuadrado de Pearson con n grados de libertad. Si las muestras de la ventana pertenecen a un segmento que se encuentra en estado estacionario la varianza de las muestras sólo puede ser provocada por el ruido. Por tanto, si el límite inferior del intervalo de confianza de la varianza es mayor que la varianza estimada del ruido
de la distribución chi cuadrado de Pearson con n grados de libertad. Si las muestras de la ventana pertenecen a un segmento que se encuentra en estado estacionario la varianza de las muestras sólo puede ser provocada por el ruido. Por tanto, si el límite inferior del intervalo de confianza de la varianza es mayor que la varianza estimada del ruido ![]() podemos concluir que, con un nivel de confianza de
podemos concluir que, con un nivel de confianza de ![]() , las muestras no se encuentran en estado estacionario. O sea que la desigualdad: (ecuación 15)
, las muestras no se encuentran en estado estacionario. O sea que la desigualdad: (ecuación 15)
puede ser usada para discriminar segmentos que no están en estado estacionario. Para un nivel de confianza de 95% y ![]() se tiene que
se tiene que ![]() por lo que para simplificar los cálculos se utilizará en lo adelante ese factor. Las consideraciones anteriores pueden resumirse en el siguiente algoritmo:
por lo que para simplificar los cálculos se utilizará en lo adelante ese factor. Las consideraciones anteriores pueden resumirse en el siguiente algoritmo:
Algoritmo 1 Segmentación (componente Sigma) basada en cálculo de desviación estándar ![]()
Entrada: Vector con los datos de la serie temporal ![]() , tamaño de los datos N, anchos mínimo
, tamaño de los datos N, anchos mínimo ![]() y máximo
y máximo ![]() de la ventana deslizante. Para la segmentación el criterio de selección de la longitud
de la ventana deslizante. Para la segmentación el criterio de selección de la longitud ![]() inicial de la ventana es fijar su
inicial de la ventana es fijar su
valor a un número de muestras que sea de 3 a 5 veces mayor que la constante de tiempo (que caracteriza el tiempo de respuesta de la variable) dividida por el periodo de muestreo2. El valor de ![]() se sugiere establecer un 10% por encima de
se sugiere establecer un 10% por encima de ![]() .
.
Salida: Lista LS con los pares de coordenadas ![]() de los segmentos candidatos a estado estacionario.
de los segmentos candidatos a estado estacionario.
1. Inicialización:
1.1. Establecer la desviaciónestándar del ruido (si es conocida de alguna forma «a priori») o tomarla igual a la estimación ![]() (ver fórmula (3)).
(ver fórmula (3)).
1.2. ![]() (Inicio de la ventana deslizante)
(Inicio de la ventana deslizante)
1.3.![]() . (La lista de segmentos candidatos inicialmente está vacía)
. (La lista de segmentos candidatos inicialmente está vacía)
1.4. La longitud inicial de la ventana L se toma igual a ![]()
2. Detección de un segmento candidato:
2.1. ![]() . Si
. Si ![]() finalizar
finalizar
2.2. Calcular la varianza ![]() de la ventana definida por las coordenadas
de la ventana definida por las coordenadas ![]() .
.
2.3. Si ![]() incrementar W1 y saltar al paso 2.1. En caso contrario se encontró un segmento candidato y se pasa al punto 3.
incrementar W1 y saltar al paso 2.1. En caso contrario se encontró un segmento candidato y se pasa al punto 3.
3. Ampliación del segmento candidato.
3.1.![]() (Con esto se marca el inicio del segmento candidato)
(Con esto se marca el inicio del segmento candidato)
3.2. Si ![]() entonces
entonces ![]() en caso contrario incrementar W1
en caso contrario incrementar W1
3.3. ![]() . Si
. Si ![]() entonces LS=LS+{[K1,N]} y finalizar
entonces LS=LS+{[K1,N]} y finalizar
3.4. Calcular la varianza ![]() de la ventana definida por las coordenadas
de la ventana definida por las coordenadas ![]() .
.
3.5. Si ![]() entonces K2=W2-1;LS=LS+{[K1,N]};W1=W2 y salta a 2.1.
entonces K2=W2-1;LS=LS+{[K1,N]};W1=W2 y salta a 2.1.
3.6. Saltar a 3.2. De este primer paso del método se obtiene una lista con las coordenadas que identifican lasecuencia de segmentos aj y complementariamente (por exclusión) los segmentos bi. Como puede apreciarse, los segmentos candidatos se van ampliando muestra por muestra, mientras no se cumpla la condición (15), por lo que la probabilidad de que se incluya en un segmento bi una muestra que realmente pertenece a un estado estacionario es no mayor que 5%. Este tipo de errores en los que una muestra contigua que pudiera incluirse en el segmento de estado estacionario erróneamente se clasifica como perteneciente a un segmento transitorio se conoce como error de tipo I1. Por el contrario en los segmentos candidatos aj obtenidos, pueden aparecer muestras que realmente pertenecen a segmentos bi . Estos casos, en los cuales una muestra que realmente pertenece a un estado transitorio se clasifica como perteneciente a un segmento estacionario se conocen como errores de tipo II. Para disminuir los errores de tipo II a la salida del paso anterior se implementa el siguiente paso del método.
2.3. Rectificación de coordenadas y verificación de tolerancia para cada segmento candidato (componente Gamma).
En la primera etapa de la rectificación para cada segmento candidato ![]() se calcula su media móvil YM con el objetivo de filtrar y suavizar los datos. La media móvil se determina utilizando un ancho de ventana Lf y, a diferencia de la fórmula (10) en que se utilizan las L muestras anteriores, en este caso para el cálculo de la media en el instante k se consideran Lf / 2 valores en instantes anteriores y Lf / 2valores en instantes posteriores. El criterio de selección de la longitud Lf de la ventana es fijar su valor igual a un número de muestras que sea menor que la constante de tiempo (que caracteriza el tiempo de respuesta de la variable) dividida por el periodo de muestreo. Para que el vector de medias móviles resultante tenga la misma dimensión que el vector original se realiza una prolongación simétrica, en forma de espejo, del segmento candidato tal y como se muestra en la Figura 3. Obviamente el vector YM tiene una menor variabilidad que el vector Y.
se calcula su media móvil YM con el objetivo de filtrar y suavizar los datos. La media móvil se determina utilizando un ancho de ventana Lf y, a diferencia de la fórmula (10) en que se utilizan las L muestras anteriores, en este caso para el cálculo de la media en el instante k se consideran Lf / 2 valores en instantes anteriores y Lf / 2valores en instantes posteriores. El criterio de selección de la longitud Lf de la ventana es fijar su valor igual a un número de muestras que sea menor que la constante de tiempo (que caracteriza el tiempo de respuesta de la variable) dividida por el periodo de muestreo. Para que el vector de medias móviles resultante tenga la misma dimensión que el vector original se realiza una prolongación simétrica, en forma de espejo, del segmento candidato tal y como se muestra en la Figura 3. Obviamente el vector YM tiene una menor variabilidad que el vector Y.

Algoritmo 2. Rectificación de coordenadas y verificación de tolerancia para cada segmento candidato.
Entrada: Vector con los datos de la serie temporal ![]() lista de segmentos candidatos LS, máximo error permitido en la rectificación eR, máximo error permitido en la verificación eV.
lista de segmentos candidatos LS, máximo error permitido en la rectificación eR, máximo error permitido en la verificación eV.
Salida: Lista refinada de los segmentos candidatos.
1. Para cada segmento candidato [K1,K2]
1.1. Calcular el vector YM de medias móviles.
1.2. Rectificación de la primera coordenada:
1.2.1. Calcular la media ![]() del vector YM
del vector YM
1.2.2. Si ![]() saltar a 1.3
saltar a 1.3
1.2.3. Incrementar K1. Si K1= K2 eliminar el segmento candidato de la lista y continuar el lazo 1. En caso contrario saltar a 1.2.2
1.3. Rectificación de la segunda coordenada:
1.3.1. Si ![]() saltar a 1.4
saltar a 1.4
1.3.2. Decrementar K1. Si K1= K2 eliminar el segmento candidato de la lista y continuar el lazo 1. En caso contrario saltar a 1.3.1
1.4. Verificación de tolerancia de media móvil:
1.4.1. Recalcular la media ![]() del vector YM en el intervalo [K1,K2]
del vector YM en el intervalo [K1,K2]
1.4.2. Para cada ![]() comprobar si
comprobar si ![]() . Si es así, para algún K, eliminar el segmento candidato de la lista y continuar el lazo 1. En caso contrario continuar el lazo 1.
. Si es así, para algún K, eliminar el segmento candidato de la lista y continuar el lazo 1. En caso contrario continuar el lazo 1.
La configuración del parámetro eR dependerá de la pendiente en subida y bajada de carga con las que típicamente se opera la UGE para transitar de un nivel de potencia a otra. Se sugiere entre 0,2 1. La configuración del parámetro eV depende de la tolerancia que se requiera en la variabilidad de la media calculadadel segmento aj.
RESULTADOS Y DISCUSION.
El diseño del experimento que servirá de base para evaluar comparativamente el desempeño del método sigma-gamma (IME) con respecto al de Rhinehart1,6 (R) y al de Jeffrey Kelly y Hedengren2 (J) se sustenta en los siguientes pasos:
1. Definición de las señales base.
Se definen dos señales base con intervalos de muestras en estados estacionarios conocidos y que reflejan formas de onda típicas de la operación en los procesos de las UGE. Estas señales base son las siguientes:
1.1. Una serie temporal exponencial generada como la respuesta de un sistema lineal de primer orden, con constante de tiempo de 200 s, a una excitación de cambio en escalón (véase ecuación 16). Su caracterización en segmentos de muestras de EE y ET se muestra en la Figura 4. La duración en tiempo de estado transitorio para este tipo de respuesta es típicamente de 3 a 5 veces la constante de tiempo (T) del sistema. En este caso se ha considerado la cota inferior.


1.2. Una serie temporal de forma trapezoidal (véase Figura 5), cuyas pendientes (que están determinadas por la respuesta dinámica del generador de vapor) representan la máxima velocidad de subida o bajada de carga de la unidad 2 de la CTE Felton. En dependencia de los niveles de potencia en que se ejecute la subida o bajada de carga por indicación del despacho nacional de carga así será la máxima pendiente sobre la cual podrá ser llevada a cabo la maniobra de operación. Así, usualmente, la pendiente es de 4.5 MW/min (0.075 MW/s). La ecuación que genera esta serie es la siguiente: (ecuación 17)


2. Generación de las señales de ensayo.
Las señales que se utilizarán para comprobar los algoritmos se obtienen contaminando cada señal base con ruido de diferentes características espectrales y amplitud. Para ello, se genera una base de datos con vectores de ruidos que contiene ruido blanco gaussiano (RB), con los siguientes valores de varianza ![]() = 0.01,
= 0.01,![]() = 0.03 ,
= 0.03 ,![]() = 0.06,
= 0.06,![]() = 0.09,
= 0.09,![]() = 0.12,
= 0.12,![]() =0.25,
=0.25,![]() =0.5 y ruido coloreado. La generación de ruido coloreado (RC) se realiza inyectando ruido blanco a un filtro ARMA (1,1) representado por la siguiente función de transferencia: (ecuación 18)
=0.5 y ruido coloreado. La generación de ruido coloreado (RC) se realiza inyectando ruido blanco a un filtro ARMA (1,1) representado por la siguiente función de transferencia: (ecuación 18)
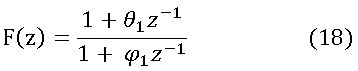
Donde ![]() es el parámetro de la componente de media móvil del filtro (Theta) y
es el parámetro de la componente de media móvil del filtro (Theta) y ![]() el parámetro de la componente auto regresiva del filtro (Phi).Para la generación del RC se emplean tres valores de
el parámetro de la componente auto regresiva del filtro (Phi).Para la generación del RC se emplean tres valores de ![]() y un valor de
y un valor de ![]() . Para cada valor de varianza se generan 15 vectores de RC, de los cuales 5 son para cada valor del parámetro
. Para cada valor de varianza se generan 15 vectores de RC, de los cuales 5 son para cada valor del parámetro ![]() .
.
En total la base de datos de ruidos está compuesta por 210 de vectores de ruido, de ellos 105 vectores de RB y 105 vectores de RC. El efecto del filtro ARMA en la auto-correlación de las muestras puede apreciarse en la Figura 6, con ayuda del comando de MatLab® autocorr. En la primera fila de esta Figura 6 se muestran de tres funciones de auto-correlación típicas para el ruido blanco y en la segunda fila, las funciones de auto-correlación de tres ruidos colorados de varianza similar.
Las señales de ensayo para la evaluación de los 3 métodos resultan de la adición de cada uno de los vectores de ruido a cada una de las dos formas de onda base.En total son 420 señales las que se utilizaron en las pruebas. Debe señalarse quecomo el valor máximo de las dos señales base es 10 las relaciones señal a ruido pico (PSNR) que se obtienen, en base a la varianza del ruido agregado oscilan entre 23 dB y 40 dB lo que es consistente con los ruidos encontrados en los registros industriales de diferentes mediciones reales en la unidad 2 de la CTE Felton.
3. Configuración de los algoritmos
El método sigma-gamma requiere configurar 5 parámetros. De estos; tres (![]() ,
, ![]() y Lf ) toman valores naturales correspondientes al número de muestras y dos de ellos son magnitudes de error (eR y eV ).Los valores fijos configurados son:
y Lf ) toman valores naturales correspondientes al número de muestras y dos de ellos son magnitudes de error (eR y eV ).Los valores fijos configurados son:
1. Para la repuesta a un escalón: ![]() = 638,
= 638, ![]()
2. Para la señal trapezoidal: ![]() = 300,
= 300, ![]()
Para el método J se requiere configurar a 3 parámetros: L (ancho de ventana), ![]() (Valor de umbral critico inferior de Student) y
(Valor de umbral critico inferior de Student) y ![]() (Valor de umbral critico superior de Student). La ventana se desliza en L pasos. Sus parámetros se configuran en los siguientes valores:
(Valor de umbral critico superior de Student). La ventana se desliza en L pasos. Sus parámetros se configuran en los siguientes valores:
1. Para la repuesta a un escalón: L=638. Asimismo, como sugieren sus autores,![]() = 2 y
= 2 y ![]() = 3 .
= 3 .
2. Para la señal trapezoidal: L=300,![]() =2 y
=2 y ![]() = 3.
= 3.
El método R requiere configurar a 3 parámetros: ![]() 1,
1,![]() 2
2![]() 3 y (son factores del filtro que sirven de base al método). Los valores que sugieren sus autores son:
3 y (son factores del filtro que sirven de base al método). Los valores que sugieren sus autores son:![]() 1=0.05 ;
1=0.05 ;![]() 2=0.05 y
2=0.05 y ![]() 3=0.05.
3=0.05.
4. Comparación de los métodos.
Como la distribución de las señales base en intervalos de muestras de EE y ET, es conocida, la comparación entre los métodos se realiza evaluando, para cada señal de ensayo, en cuanto se alejan, los resultados obtenidos por cada método, con respecto a dicha distribución conocida. Esto permite apreciar en qué medida el ruido agregado a las señales base afecta la detección de los estados estacionarios en cada método. Si se parte que de la señal base se conoce el estado de cada muestra, formando parte de un subconjunto en EE o en ET, entonces el método tiene 4 posibilidades al evaluar la condición del proceso en ese instante de tiempo: dos correctas, y dos incorrectas y por tanto un criterio cuantitativo de la calidad de la detección es contar los instantes de tiempo en que el método clasifica incorrectamente la condición del proceso, o sea, contar las muestras que se conoce pertenecen aun segmento de EE pero que el método las coloca en un segmento de ET (Error de Tipo I) y las que se conoce pertenecen a un segmento de ET pero son erróneamente incluidas en un segmento de EE (Error de Tipo II).
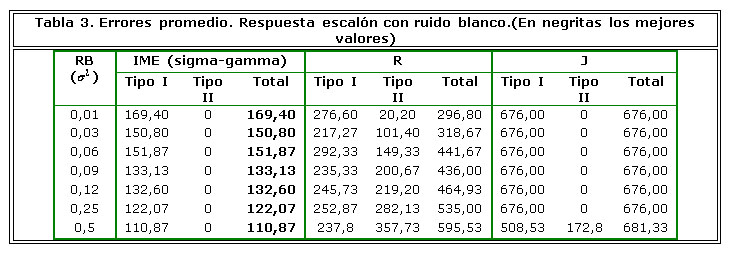
En las Tablas 3, 4, 5 y 6 se pueden apreciar los resultados de los errores promedio obtenidos en las pruebas realizadas. Puede a simple vista apreciarse que el método R, tal y como el autor ha indicado, solo es aplicable si existe certeza de que el ruido es blanco. La Figura 7 muestra que los 3 métodos son relativamente estables al incremento del nivel del ruido presente en las mediciones aunque se aprecia un ligero deterioro en los resultados delmétodo Rcon el incremento de la varianza del ruido. Por otra parte el método Jeff muestra estabilidad tanto para ruido blanco como para ruido coloreado aunque se ve afectado por la manera en que desliza la ventana lo que provoca que cuando comete un error, el mismo se propaga a todas las muestras de esa ventana.
Para verificar que las diferencias observadas entre los métodos sean estadísticamente significativas se utilizó el Análisis de la Varianza (ANOVA). Se confeccionaron 42 tablas con los resultados obtenidos para RB y para RC en los 7 niveles de ruido analizados y para las 3 posibilidades de evaluación de errores (total, Tipo I y Tipo II). Cada tabla se sometió a una comparación múltiple utilizando los comandos de MatLab ®anova1 y multcompare. En todos los casos los promedios de errores del IME son inferiores o iguales al de los restantes métodos. La diferencia es estadísticamente significativa enlas tablas de errores totales y de errores de Tipo I. En los errores de Tipo II en 23 casos ANOVA no arrojó diferencias significativas entre el IME y alguno de los restantes métodos.
CONCLUSIONES
De acuerdo a las pruebas realizadas se ha verificado que el método propuesto es más robusto, basado en los criterios cuantitativos de errores de tipo I y II, que los otros dos métodos seleccionados, en especial cuando el ruido que contamina la señal es coloreado (no blanco). El método de Rhinehart opera sobre los datos secuencialmente sin necesidad de seleccionar un valor de ventana preliminar. Tiene bajos requerimientos de memoria y es computacionalmente simple lo que lo hace ideal para aplicaciones empotradas. Sin embargo, para aplicarlo requiere que no exista auto-correlación en los datos de cada variable. El método determina la condición de estado estacionario por muestra y requiere de la configuración de 3 parámetros. El método Jeffrey Kelly y Hedengren es del tipo basado en ventanas deslizantes. Requiere de la configuración de 3 parámetros y determina la condición de estado estacionario por ventana. Sin embargo, este método tiene el inconveniente que no desliza la ventana muestra a muestra sino que la desliza en el ancho de la ventana lo que implica que un error en la clasificación de la ventana se propaga a todas las muestras de la misma. El método «sigma-gamma» opera sobre ventanas deslizantes y es robusto ante datos correlacionados. Su desplazamiento a un paso permite gran resolución en la detección consecutiva de la mayor cantidad de segmentos de muestras potencialmente en EE y bajo cotas de media móvil definidas por el usuario. En términos de complejidad computacional el método «sigma-gamma» es el de mayores requerimientos pues requiere dos recorridos sobre la serie temporal, uno inicial para la segmentación (componente Sigma) basada en cálculo de desviación estándar ![]() y otro adicional para la rectificación de coordenadas y la verificación de tolerancia de cada segmento candidato basado en medias móviles. Sin embargo, tal y como se refleja en el trabajo2 con la aparición de ordenadores de varios núcleos, la carga computacional de los algoritmos basados en el cálculo de la media, la desviación estándar o de pendientes no representa un problema para los supervisores actuales.
y otro adicional para la rectificación de coordenadas y la verificación de tolerancia de cada segmento candidato basado en medias móviles. Sin embargo, tal y como se refleja en el trabajo2 con la aparición de ordenadores de varios núcleos, la carga computacional de los algoritmos basados en el cálculo de la media, la desviación estándar o de pendientes no representa un problema para los supervisores actuales.
REFERENCIAS
1. RHINEHART, R.R., «Tutorial: Automated Steady and Transient State Identification in Noisy Processes», Proceedings of the 2013 American Control Conference, Washington DC, June 2013, pp. 4477-4493.
2. KELLY, J. D., HEDENGREN J. D., «A steady-state detection (SSD) algorithm to detect non-stationary drifts in processes», Journal of Process Control. 2013, vol 23, p 326 331.
3. MHAMDI, A., GEFFERS, W., FLEHMIG, F., MARQUARDT, W., «On-line optimization of MSF desalination plants», Desalination and Water Resources: Thermal Desalination Processes, EOLSS, 2010, vol. 1, p 136162.
4. LE ROUX,G. A. C., FACCINI, B., et. al.»Improving Steady State Identification.»Proceedings of theEuropean Symposium on Computer Aided Process Engineering», Amsterdam: Elsevier, 2008. vol. 25. p. 459-464.
5. KIM, M., YOON, S.H., DOMANSKI, P., PAYNE W.,»Design of a steady-state detector for fault detection and diagnosis of a residential air conditioner», International Journal of Refrigeration. 2008,vol 31, p 790799.
6. NEHA, S., VILANKAR, K. P., RHINEHART, R.R.»Type-II critical values for a steady-state identifier», Journal of Process Control, 2010;vol 20, p 885-90.
7. MANSOUR, M., ELLIS, J.E., «Methodology of On-line Optimisation applied to a Chemical Reactor», Applied Mathematical Modelling, 2008, vol 32, p. 170-184.
8. YE, L., LIU Y., FEI, Z., LIANG, J., «Online probabilistic assessment of operating performance based on safety and optimality indices for multimode industrial processes», Industrial Engineering Chemistry Research, 2009, vol. 48, No. 24, p 10912-10923.
9. VÁZQUEZ, L., LLOSAS, Y.,et. al.: «El diagnóstico energético de la operación en centrales térmicas con el monitoreo de los índices de sobre-consumo.» Revista electrónica Ciencia en su PC, vol3, 2010. URL: 169.158.189.18/cienciapc
10. VÁZQUEZ, L., LLOSAS, Y., et. al.: «Explorador Industrial Multivariable: Una solución con Matlab para minar series temporales.» Libro de Actas del X Simposio Internacional de Automatización de la XIV Convención y Feria Internacional Informática 2011. Ciudad Habana, Febrero 2011. ISBN: 978-959-7213-01-7
11. OZANA, S., PIES, M., VAZQUEZ, L. «Use of Methods of Statistic Dynamics Applied for Analysis of Steam Superheater». PRZEGLA²D ELEKTROTECHNICZNY (Electrical Review), 2011, vol 87, p 154-158.
12. GUDE, J., VAZQUEZ, L., DIAZ, D. «A tailor made development for time series data pre-processing in power industry».Proceedings of theIEEE-ISSPIT, Dic-2011,Bilbao-España , p 315-321
13. BLANCO, J.M., VAZQUEZ, L., PEÑA, F., DIAZ, D. «New Investigation on Diagnosing Steam Production Systems from Multivariate Time Series Applied to Thermal Power Plants», Applied Energy, vol 101, 2013,p589599.
14. BLANCO, J.M., VAZQUEZ, L., PEÑA, F., DIAZ, D. «Diagnosing steam production systems on their multivariable steady states». Proceedings of the8th Power Plant & Power System Control Symposium - PPPSC 2012, Sept. 2012, Toulouse, Francia.
15. BLANCO, J.M., VAZQUEZ, L., PEÑA, F., «Investigation on a new methodology for thermal power plant assessment through live diagnosis monitoring of selected process parameters; application to a case study», Energy, vol 42, 2012,p170-180,
16. ILIC, M. D., LIU, X., EIDSON, B., VIALASS, C., ATHANS, M.,»A Structure-based Modeling and Control of Electric Power Systems».Automatica, vol.33, 1997, p 515-531.
17. Performance Monitoring Guidelines for Power Plants, Performance Test Code, (PTC-PM), of the American Society of Mechanical Engineers (ASME), EUA, 2010.
18. International Standard. Rules for steam turbine thermal acceptance tests, IEC 953-1, 1990.
19. Fired Steam Generator, Performance Test Code (PTC 4), of the American Society of Mechanical Engineers (ASME), EUA, 1998.
20. LEIGH, A., WONG, A., CLAUSI, D. A., FIEGUTH, P. «Comprehensive analysis on the effects of noise estimation strategies on image noise».Proceedings of the2011 IEEE International Symposium on Multimedia.
21. DONOHO, D. L., JOHNSTONE, I. M.,»Ideal spatial adaptation by wavelet shrinkage» Biometrika, vol. 81, 1994, p 425455.
22. CEDEÑO, A., TRUJILLO, R.»Estudio comparativo de técnicas de reducción de ruido en señales industriales mediante Transformada Wavelet Discreta y selección adaptativa del umbral». Revista Iberoamericana de Automática e Informática industrial, vol 10, 2013, p 143148.
23. JOHNSTONE, I. M. , SILVERMAN B. W., «Wavelet Threshold Estimators for Data with Correlated Noise». Journal of the Royal Statistical Society. Series B (Methodological), vol. 59, 1997, p 319-351.
24. JOHNSTONE, I. M. «Wavelet shrinkage for correlated data and inverse problems: Adaptivity results». Statistica Sinica, vol. 9, 1999, p51-83.
Recibido: Abril 2014
Aprobado: Mayo 2014

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
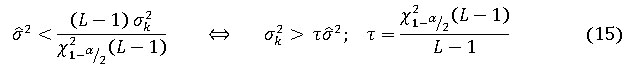{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}