










Meu SciELO
 Serviços customizados
Serviços customizadosServiços Personalizados
Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO
Compartilhar

 Permalink
PermalinkIngeniería Industrial
versão On-line ISSN 1815-5936
Ing. Ind. vol.34 no.3 La Habana set.-dez. 2013
ARTÍCULO ORIGINAL
Apoyo a la toma de decisiones en un Observatorio Tecnológico incorporando proactividad
Decision-making support in a Technology Observatory by incorporating proactivity
Mailyn Moreno-EspinoI, Alternán Carrasco-BustamanteII, Alejandro Rosete-SuárezI, Martha Dunia Delgado-DapenaI
I Instituto Superior Politécnico José Antonio Echeverría, Cujae. Facultad de Ingeniería Informática. La Habana, Cuba.
II Complejo de Investigaciones Tecnológicas Integradas (CITI). La Habana, Cuba.
RESUMEN
Buscar y procesar información tiene un gran impacto en varias profesiones, es por ello que recuperarla y compartir los resultados se convierte en un tema esencial. Actualmente la cantidad de información es cada vez mayor y difícil de encontrar debido a su heterogeneidad, sus cambios y la diversidad de las fuentes. Los Observatorios Tecnológicos resuelven de alguna forma el problema planteado anteriormente, aunque los mismos no siempre tienen en cuenta la necesidad de que su proceso de vigilancia se haga proactivamente. Este trabajo presenta un Observatorio Tecnológico con comportamientos proactivos con el objetivo de mantener a los usuarios actualizados de sus intereses. Se utilizó una arquitectura de agentes que emplea patrones de implementación para desarrollar un observatorio proactivo que apoye a la toma de decisiones. Se hace una descripción de los resultados en una prueba piloto, donde los usuarios recibieron correos con documentos de su interés.
Palabras clave: observatorio tecnológico, proactividad, agentes, patrón de implementación, plataforma de desarrollo de agentes en Java (JADE).
ABSTRACT
The process of finding and processing information is very important for many professionals. Therefore, information retrieving and sharing are key issues. At present, the quantity of information is growing and it is difficult to find it, due to its heterogeneity, its constant change and the diversity of data sources. Technological observatories solve this problem in some way, although they do not always take into account the necessity to make the monitoring process proactively. This paper shows how the inclusion of proactive behaviors into a technological observatory using the agent’s philosophy and the implementation patterns can improve its performance and keep users updated if their interests are known. The test pilot results are described, where the users received mails according to their interests.
Key words: technology observatory, proactivity, agents, implementation pattern, Java Agent Development Framework (JADE).
INTRODUCCIÓN
El gran número de fuentes de información y su crecimiento acelerado hacen complejo el encontrar la información deseada. Es preciso hallar una manera de identificar las intenciones y necesidades de los usuarios para disminuir el trabajo de búsqueda de información y que la misma se pueda obtener de forma más rápida y precisa. La vigilancia tecnológica es una de las formas de gestionar conocimiento, más específicamente es la gestión de la información generada y necesaria para la investigación y el desarrollo. "La Vigilancia Tecnológica está basada en la captación y análisis sistemático de informaciones disponibles en fuentes de información gratuitas o comerciales. Se trata de un método claro, riguroso y neutro de alerta temprana para la dirección" [1: 10].
La proliferación de computadoras personales (PC), la demanda de servicios avanzados a través de sistemas informáticos y el auge de Internet han puesto de manifiesto la necesidad de desarrollar aplicaciones que exhiban un cierto nivel de inteligencia en el proceso de recuperación de la información, donde la interacción con el usuario y la conectividad de diferentes sistemas deben ser aspectos especialmente relevantes. Para lograr estos objetivos existen algunos enfoques fundamentales, entre los que se encuentran los mecanismos y técnicas para recuperar información de la web a través de la adquisición de recursos y de su almacenamiento estructurado, para luego realizar búsquedas [2].
Un Observatorio Tecnológico (OT) es una aplicación que permite hacer vigilancia tecnológica y es una solución a la problemática anteriormente planteada. Aunque no existe un concepto unificado que se pueda utilizar, varios investigadores han hecho sus aportes y brindado sus apreciaciones del significado de un OT. De forma general se dice que un OT mide y procesa elementos concernientes a fuentes de información deseadas, para aliviar el trabajo de buscar información relevante que tribute al trabajo o intereses personales de los usuarios, gracias a la integración de información circunscrita a temas determinados, que provee de informes, resúmenes y alertas, que permiten a los usuarios tomar decisiones [3]. Otros autores lo ven como una herramienta que reconoce cambios en las fuentes de información que procesa, gestiona y observa; por lo tanto, puede avisar de ciertas variaciones o diferencias en los parámetros que evalúa, generando información valiosa con un alto nivel de importancia al ser actual y novedosa, que puede ser utilizada por los receptores que tengan interés en dicha información [2; 4; 5].
Como se plantea, un OT funciona principalmente para dar respuesta a los intereses de sus usuarios. Cuando se desea construir un OT es esencial estudiar mecanismos que permitan responder a los intereses de los usuarios con la menor intervención humana. La mayoría de los OT operan gracias a las personas que trabajan dándoles soporte, buscando, procesando, resumiendo, colocando noticias en los sitios web e informando a los clientes de sus descubrimientos. Un ejemplo lo constituye ESTO (European Science and Technology Observatory) [6], una red de 18 organizaciones europeas con experiencia en el campo científico y tecnológico, que funciona bajo la Comisión de las Comunidades Europeas, y opera como un instituto virtual. Otros OT con esta característica se dedican al tratamiento de información centrada en dominios específicos, como son: Observatorio Chileno de Ciencia, Tecnología e Innovación (KAWAX) [7], Observatorio del Plástico [8] y Observatorio Tecnológico de la Soldadura [9]; los cuales tienen un personal extenso que estudia estas ramas del mercado y analizan las noticias que se publican relacionadas a sus temas. Como sus respectivos nombres lo indican, cada OT es una referencia en el tema que procesa, dando a cada sector del mercado información confiable e importante para los usuarios, de forma dinámica, periódica y actualizada. Pero esta información no es personalizada, es para usuarios con objetivos comunes y no con objetivos específicos particulares [3].
Cuando se requiere un OT que apoye la toma de decisiones de un número elevado de usuarios, los cuales tienen objetivos diversos y se nutren de fuentes de información diferentes, y no se cuenta con la cantidad y el nivel académico del personal que lo sustente, entonces surgen problemas [3]. Estos se deben a que la mayor parte de los OT, como ya se mencionó con anterioridad, deben su funcionamiento al personal académico que los sustenta y no se logran personalizar las respuestas para un número elevado de usuarios y con intereses disímiles. Se debe tener en cuenta además que se desea un OT capaz de indicar y enfocar las decisiones de sus usuarios con solo tener sus intereses y que lo haga sin que medie siempre una petición del usuario [10]. La tecnología de agentes es una tecnología que permite desarrollar un enfoque orientado a metas a partir de las necesidades de sus usuarios, personalizar el procesamiento y apoyo a la toma de decisión e incorporar proactividad.
Los agentes inteligentes son un nuevo paradigma de desarrollo de software. Según Wooldridge (2009), los agentes inteligentes han sido tema de intensas investigaciones con el paso de los años y constituyen uno de los enfoques computacionales más prometedores, siendo capaces de abordar cuestiones que requieren un modelado flexible, abstracto y un razonamiento elevado [11]. Algunas aplicaciones que gestionan información para beneficio de un usuario final son modeladas bajo el paradigma de agentes. Los agentes agilizan la búsqueda de información, se apoyan en técnicas de procesamiento del lenguaje natural y facilitan al usuario la extracción, análisis e integración de información como apoyo al proceso de toma de decisiones [2; 12]. Por otra parte, el éxito de los agentes inteligentes para gestionar información y apoyar a la toma de decisiones, de forma general, ha sido demostrado en sistemas reales que han planteado arquitecturas que contienen entidades con cierto grado de autonomía, responsabilidades y objetivos a cumplir [13; 14]. Se han documentado aplicaciones punto a punto [15] y sistemas distribuidos [16] que utilizan los beneficios de la tecnología de agentes, donde se tienen en cuenta la organización de las entidades y la descomposición de tareas entre las mismas, haciendo uso de la Ingeniería de Software Orientada a Agentes [17].
Los Sistemas Multi-Agente (SMA) están compuestos por agentes que tienen conocimiento sobre su entorno, que persiguen metas determinadas por sus responsabilidades [11]. Dichos agentes pueden interactuar entre ellos informando y consultando a otros agentes teniendo en cuenta lo que realiza cada uno de ellos. Los agentes llegan a ser capaces de conocer el papel que tienen todos dentro del sistema según la capacidad que cada uno tenga de actuar y percibir [11]. La proactividad es una característica que distingue a los agentes, les permite no solo actuar en respuesta de un ambiente sino que sean capaces de tener comportamientos orientados a metas y en función del entorno, así como observar situaciones que les permiten cumplirlas.
En este trabajo se describe la arquitectura de un SMA para apoyar el funcionamiento de un OT en el apoyo a la toma de decisiones. Se aprovechan las ventajas que proveen los agentes para que los procesos que se ejecutan y el trabajo que se realiza sean más rápidos y personalizados. La utilización de los agentes es considerada en la solución propuesta por las facilidades que brinda en la búsqueda y recuperación de información para el apoyo a la toma de decisiones de muchos usuarios de forma proactiva y sin personal académico que lo sustente. En el artículo se presentan los conceptos de agentes de información, proactividad y SMA; se explica la arquitectura y funcionamiento del sistema propuesto, haciendo uso de un patrón de implementación para incluir el comportamiento proactivo que apoye a la toma de decisiones. Además, se ilustra con un ejemplo práctico la ejecución del OT con proactividad y se mencionan al final los beneficios que aporta a los usuarios.
MÉTODOS
A continuación se definen elementos teóricos considerados importantes para presentar la propuesta de inclusión de la proactividad como parte de un Observatorio Tecnológico.
Observatorio Tecnológico
Un OT es una herramienta que apoya la vigilancia tecnológica, reconoce cambios en el dominio de información que procesa, gestiona y observa; por lo tanto, teniendo en cuenta comportamientos previos, puede avisar con antelación de ciertas variaciones o diferencias en parámetros que evalúa. Un OT genera un conocimiento con un alto nivel de importancia, al ser actual y novedoso, que puede ser utilizado por los receptores que tengan interés en esa información [3].
Según Bouza (2010) un OT captura informaciones externas con el propósito de transformarlas en conocimientos específicos que conduce a sus usuarios a tomar decisiones [10]. Un OT es un sistema de alerta para identificar y recopilar aquellos datos e informaciones que pueden ser fuente de amenaza u oportunidad.
Si se toman como base las definiciones anteriores, se puede concluir que un OT mide y procesa elementos concernientes a un tema y alivia el trabajo de buscar información relevante que tribute a los intereses de los usuarios, gracias a la integración en una herramienta que busca información circunscrita a temas determinados, que provee de informes, resúmenes y alertas que permiten a los usuarios tomar decisiones.
Muchos OT deben su funcionamiento al personal que trabaja tras el sistema y son estas personas las encargadas de buscar información y utilizan parte del sistema para la indexación y catalogación de la información. Esto no permite que el sistema se pueda enfocar hacia metas específicas de cada usuario. La forma de entregar la información no es suficientemente rápida y el dominio en el que se trabaja está limitado al conocimiento del personal [1; 3; 18].
Los agentes
La Fundación para Agentes Inteligentes Físicos (FIPA, por sus siglas en inglés), expone que los agentes son una entidad de software con un grupo de propiedades, entre las que se destacan: ser capaz de actuar en un ambiente, comunicarse directamente con otros agentes, estar condicionado por un conjunto de metas u objetivos, manejar recursos propios, ser capaz de percibir su ambiente y tomar de él una representación parcial, ser una entidad que posee habilidades y ofrece servicios, entre otras [19].
Los agentes brindan una solución efectiva para descomponer los sistemas complejos, son una vía natural de modelarlos y su abstracción para tratar las relaciones organizacionales es apropiada para estos sistemas [16].
Las propiedades de los agentes que se destacan son: ser autónomos, reactivos, proactivos y tener habilidad social; las cuales se resumen a continuación [11]:
Autónomos: actúan sin la intervención directa de los usuarios, tienen control sobre sus acciones y estados internos.
Reactivos: perciben del entorno y responden a los cambios de éste.
Proactivos: no sólo actúan en respuesta a su ambiente sino que son capaces de tener comportamiento orientado a metas.
Habilidad social: tienen la capacidad de interactuar con otros agentes mediante algún mecanismo de comunicación, lo que les permite lograr objetivos que por sí solos no pueden lograr.
El concepto de agente ha encontrado aceptación en varias sub-disciplinas de tecnologías de la información incluyendo redes de computadoras, ingeniería de software, programación orientada a objetos, inteligencia artificial, interacción hombre-máquina, sistemas concurrentes y distribuidos y soporte a la toma de decisiones.
La proactividad es una característica muy interesante, ya que es sinónimo de tomar iniciativa y permite dotar a las aplicaciones de propiedades que apoyan el proceso de toma de decisiones.
Los agentes en la gestión de la información
Para muchos usuarios de Internet, la mayor dificultad que se les presenta al buscar información es la sobrecarga de la misma, razón por la cual es difícil determinar qué recursos aportan algo de valor. Las herramientas de búsqueda como Yahoo! y Google tratan de aliviar este problema, sin lograr aún los resultados esperados, ya que indexan grandes cantidades de información no estructurada, sobre todo en formato textual, ofrecen resultados muy grandes y que no apoyan a la toma de decisiones según las demandas particulares de los usuarios.
Un agente de información es una entidad que puede acceder al menos a una y potencialmente a varias fuentes de información, con la habilidad de comparar, filtrar y manipular los datos obtenidos para responder a los pedidos de los usuarios [11]. Es posible modelar un agente de información de manera que trabaje teniendo en cuenta los intereses del usuario y capture las acciones, pedidos y respuestas de este al interactuar con el agente. Un ejemplo de ello puede verse en un sistema creado para adquirir, modelar y utilizar las preferencias del usuario para guiar el trabajo del SMA, con agentes que interactúan con el usuario, ejecutan tareas y buscan información en fuentes de información heterogéneas, para apoyar la toma de decisiones de los mismos [20].
Se han identificado dos áreas fundamentales en que las bases de los SMA pueden tener un impacto en la gestión de la información. La primera es la identificación de las partes distribuidas del sistema que se comunican entre sí y la segunda, es la gestión de las necesidades de los usuarios que permita obtener de forma precisa y rápida los recursos de información que les interesan, basados en la gestión del perfil de usuario. Se entiende por perfil de usuario los datos inherentes a cada usuario [21]. Los SMA son una comunidad de agentes que colaboran entre ellos y pueden dar respuesta a un requisito de búsqueda.
Un ejemplo de sistema que utiliza agentes inteligentes es el llamado JITIK (Just-In-Time Information and Knowledge) [22]. Este sistema está orientado a hacer más efectivo el conocimiento de las organizaciones, integrando las diversas fuentes y destinatarios de la información para hacerla llegar, de forma altamente personalizada, a los diversos integrantes de la organización. Estos interactúan con los sistemas existentes en la organización para obtener la información de diversas fuentes, la procesan con el fin de reconocer la nueva información que resulte más relevante para los perfiles de usuario y la distribuyen a través de diversos medios como el correo electrónico, Short Message Service (SMS) y la web, según las preferencias del usuario.
Ruey-Shun (2008) ha propuesto una solución que permite al usuario acceder a recursos de información a través de los servicios de un SMA [2]. El mismo define un Observatorio Virtual que representa a los usuarios, realiza comparaciones entre los pedidos de los mismos y mejora las respuestas que provee, los asiste en su trabajo mediante una interfaz web que sirve de acceso a la plataforma de agentes. Esta interfaz web permite tener separado el sistema del usuario, permitiendo que todos los que deseen utilizar los servicios del observatorio puedan hacerlo desde cualquier navegador web.
El análisis de las propuestas de otros autores permitió identificar un conjunto de características a tener en cuenta en el diseño de la arquitectura de un SMA que soporte la implementación de un OT, entre ellas que:
- El despliegue de la plataforma de agentes debe lograr una alta cohesión y un bajo acoplamiento [23; 24].
- La recuperación e indexación de recursos de información deben estar encapsuladas en el comportamiento de un agente de software [2; 25].
- La información debe distribuirse por la plataforma de agentes [21; 26].
- Cada usuario debe ser representado por un agente [2; 22].
- El SMA debe encargarse del envío de notificaciones como parte del comportamiento proactivo del sistema [21; 25].
Esta última característica es la más relevante para el presente trabajo. Según un estudio desarrollado por Fernández (2007), donde se consultaron un conjunto de expertos en ciencias de la información, se identifica la necesidad de los sistemas de gestión de información de tener proactividad. Esto implica que los sistemas deben ser capaces de adelantarse a las solicitudes de información de los usuarios, proveyéndoles de información precisa, siguiendo sus metas [21]. Para garantizar la proactividad con los niveles de escalabilidad que han de caracterizar a un OT, la arquitectura del software que se utilice deberá ser lo suficientemente flexible como para adaptarse a la variabilidad de los intereses de los usuarios y de las fuentes abiertas de información disponibles [24; 25].
Aunque existen SMA que responden a los intereses de un OT, las propuestas carecen de una documentación detallada de la arquitectura del SMA, lo que dificulta su utilización como base para realizar la propuesta que es objeto de este trabajo.
Arquitectura propuesta para el Observatorio Tecnológico
La construcción de un OT sigue una serie de pasos y consta de un conjunto de módulos que soportan su funcionamiento, pero las arquitecturas propuestas por muchos observatorios, como se evidenció anteriormente, no tienen o no conciben un comportamiento proactivo para apoyar la toma de decisiones. A continuación se describe el sistema propuesto y todos los detalles que se tuvieron en cuenta para incorporar proactividad y que la misma apoye el proceso de toma de decisiones.
Para proponer la arquitectura del SMA se tuvieron en cuenta un conjunto de características identificadas en la sección de los agentes en la gestión de la información.
En la figura 1 se muestra la arquitectura del OT basada en un SMA. El OT está compuesto por una capa cliente y una capa para el SMA. En la capa cliente está la interfaz gráfica. La capa del SMA está compuesta por un repositorio y cuatro tipos de agentes: agente personal (AP), agente de confianza (AC), agente analista (AA) y agente fuente de datos (AFD). El SMA además consta de tres módulos en los que se apoyan el AP y AFD, estos son: LuceneIndex, URLDownloader y Search Docs.

Como se muestra en la figura 1, el usuario accede a los datos que el SMA gestiona y salva en el repositorio. Cuando el usuario ejecuta la interfaz gráfica, se levanta un AP que lo representará dentro del SMA. El despliegue concebido del SMA implica un AP por cada usuario del sistema. Cada AP está a cargo de la gestión de los recursos de información disponibles, se tiene en cuenta el perfil y el comportamiento del usuario ante la interfaz gráfica. El perfil del usuario se guarda en el repositorio, lo cual permite que cuando el usuario se conecte desde cualquier PC, obtenga todos los datos que le corresponden, una vez que se autentique en el sistema. El perfil de usuario le permite al SMA atender y responder a las necesidades independientes de cada uno.
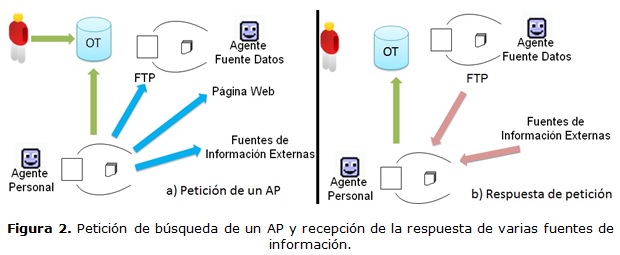
En sentido general, cada AP se dedica a buscar, descargar e indexar la información procedente de fuentes abiertas externas que el usuario solicita consultar, recuperar y compartir con otros AP, teniendo en cuenta las políticas de colaboración establecidas por el usuario y su perfil que es traducido en metas del AP. Cada AFD está alerta para atender los pedidos del AP para buscar y descargar del File Transfer Protocol (FTP) que monitorea. Existe un AFD que analiza el repositorio que forma parte del OT. El AFD indexa la información que está en el FTP y crea índices más fáciles de consultar. En la figura 2 a la izquierda se puede ver cómo un AP, a partir del perfil de usuario, realiza una petición de búsqueda a un AFD, a una página web y a fuentes de información externas. La figura 2 a la derecha muestra las fuentes de información que dan respuesta, no todas dieron resultados.
El AC escucha los mensajes que se envían entre los agentes del SMA y guarda una traza de esta comunicación. Las trazas las utiliza el AA para determinar, mediante procesos de minería de datos, por ejemplo, qué usuarios son especialistas en un tema o cuáles están trabajando en temas similares. El AA además puede preguntar al AC la cantidad de recursos de información de una temática que ha enviado cada AP del SMA o algún aspecto más general, como la cantidad de mensajes relacionados con un tema que ha enviado cada AP, ya sean mensajes de recuperación o de contribución de contenido.
La arquitectura propuesta es flexible, ya que al SMA se le pueden incluir agentes con otros roles y se pueden además monitorear nuevos FTP. También el SMA separa su funcionamiento de la forma en que las aplicaciones acceden a los datos y a la información que sirve para el apoyo a la toma de decisiones de los usuarios. De esta manera, cualquier aplicación externa que se quiera implementar puede acceder al OT de otras maneras, ya sea con otra interfaz gráfica con tecnología Java u otras, ya que es posible implementar un componente para ambas tecnologías que sirva de interfaz para ejecutar dichas funciones, y así utilizar las potencialidades de la mensajería entre agentes. Estas aplicaciones externas deben seguir parámetros y formalidades, que explican cómo mostrar y gestionar la información, dónde encontrar lo que desea mostrar al usuario y de qué manera acceder a esos datos.
En la construcción de un SMA se deben manejar aspectos relacionados con la comunicación entre los agentes, el control de los agentes, entres otros. También hay que tener un proceso de observación proactivo que le permita al OT el apoyo a la toma de decisiones para lograr el OT deseado. Para resolver estos problemas se desarrolló un patrón de implementación que maneja los agentes. Todo el SMA utiliza como base el patrón y se desarrolló además un componente de observación periódica, los cuales se describen a continuación.
Descripción del patrón de implementación desarrollado para los Sistemas Multi-Agente
La incorporación de comportamientos proactivos es un trabajo engorroso por la naturaleza abstracta de los agentes, por lo que se desarrolló un patrón de implementación que permite a los desarrolladores de una forma sencilla incorporar dicho comportamiento.
Un patrón de implementación es un módulo de software único en un lenguaje de programación en particular, que tiene una serie de pasos que ayudan en un problema determinado. Una característica crucial es que son fácilmente reconocibles por el software, lo que facilita la automatización [27].
Cuando un SMA es implementado, los desarrolladores necesitan cumplir con algunas funcionalidades que son de vital importancia para la ejecución del sistema. Entre las más comunes están las siguientes:
1. Ejecución y control de la plataforma que contiene a los agentes.
2. Gestionar el ciclo de vida de los agentes, metas y objetivos.
3. Comunicarse con los agentes que viven dentro del sistema.
3.1. Enviar y recibir mensajes desde y hacia otros agentes.
3.2. Procesar el mensaje y tomar acciones dependiendo de su contenido.
4. Comunicarse con los agentes coordinadores de la plataforma.
4.1. Ver el estado de algún módulo del sistema.
4.2. Buscar un agente para ver su estado.
Específicamente, el patrón que aquí se describe se nombra Implementation_JADE e implementa estas características, para que los desarrolladores puedan hacer uso de la tecnología de agentes de una forma más sencilla. Este patrón utiliza Java Agent DEvelopment Framework (JADE) [28] para el trabajo con los agentes y es una capa abstracta que media con las funcionalidades que implementa JADE. El patrón contiene siete grupos de operaciones y las clases que las ejecutan se muestran en la figura 3. El mismo utiliza la clase Agent de JADE para sustentar sus operaciones, las cuales se enuncian a continuación:
1. Inicialización de la plataforma de agentes JADE, manejada por la clase Init_Platform.
2. Unión a una plataforma ya existente, manejada por la clase Join_Platform.
3. Conexión a un agente que ha perdido la plataforma que lo gobierna, manejado por la clase Behaviour_ReconnectToPlatform.
4. Implementación de un comportamiento cíclico para poder procesar los mensajes que recibe un agente determinado, manejado por la clase Behaviour_Receive_Msg.
Con esta operación se pueden cambiar los objetivos de los agentes, que unido a un comportamiento, les permiten ser proactivos.
5. Manejar el trabajo relacionado con enviar mensajes hacia los agentes, manejado por la clase Work_ACL.
Para cumplir sus metas los agentes necesitan comunicarse con otros agentes que en cooperación ayudan a cumplimentarlas.
6. Trabajo con el Agent Management Service (AMS), manejado por la clase Work_ AMS.
Este servicio es el que controla los atributos del agente. También es el que está encargado de saber dónde están los agentes para comunicarse con ellos.
7. Trabajo con el agente Directory Facilitator (DF), manejado por la clase Work_ DF.
El control que tiene el DF sobre los agentes es comparado con el de las páginas amarillas. Con el DF se puede encontrar un agente que cumpla con un atributo determinado, siempre y cuando ese agente se haya registrado con el DF.
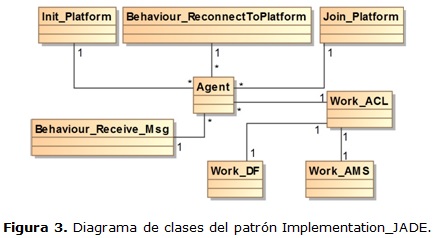
Este patrón encapsula la capa de abstracción que es utilizada por el componente propuesto para la observación periódica. Su objetivo es simplificar el desarrollo de un conjunto de agentes, al tiempo que garantiza el cumplimiento de los estándares a través de un amplio conjunto de servicios del sistema y los agentes con JADE. El mimo permite que los desarrolladores puedan hacer uso de la tecnología de agentes de una forma más sencilla.
Componente propuesto para la observación periódica
En el desarrollo del componente Observador se utilizó como base el patrón de implementación. El componente permite la observación periódica de las fuentes de información que maneja el OT y de esta forma, incorpora un comportamiento proactivo más marcado hacia la gestión de la información requerida y deseada por los usuarios.
El objetivo de este componente es que los AP que representan los intereses del usuario puedan tramitar todos estos intereses y estar al tanto de los cambios del entorno que puedan contribuir a cumplimentar sus objetivos. Esto le da al OT un marcado comportamiento proactivo que ayuda de forma efectiva a sus usuarios en el apoyo a la toma de decisiones.
Este componente incluye dos entidades: “Observable” y “Observer”.
La entidad “Observable” se encarga de:
- Censar el ambiente cada determinado tiempo para detectar algún cambio.
- Gestionar una lista con los observadores que se subscriban.
- Notificar a los observadores los datos encontrados en el cambio ocurrido.
La entidad “Observer” se encarga de:
- Implementar el proceso de subscripción a la lista del “Observable”.
- Actualizar su estado interno.
- Permitir realizar una acción cuando se le notifique del cambio.
En la figura 4 se puede ver un diagrama de actividad que muestra el flujo de trabajo de la entidad “Observable” y la entidad “Observer”. Entre las funcionalidades más importantes de este componente Observador se encuentra el permitir que el OT gestione los FTP a observar. El OT es la entidad “Observable” y para esto utiliza el AFD. El AP es la entidad “Observer”. Todos los cambios significativos del entorno para un AP (dígase metas del usuario) que encuentra el OT son informados al AP y éste a su vez, a través de la interfaz gráfica y el correo electrónico, lo entrega a su usuario.

RESULTADOS
A continuación se exponen los resultados del despliegue del OT con el SMA y los obtenidos en encuestas realizadas durante una prueba piloto del despliegue del OT.
Despliegue del componente Observador
Antes de hacer una prueba piloto del funcionamiento del OT se hizo una prueba de la utilización del patrón de implementación con el componente Observador. A continuación se explica cómo fueron utilizados.
1. El observatorio utilizó las operaciones del patrón Implementation_JADE para ejecutar la Plataforma JADE, para inicializar los agentes, con el fin de comunicarse con los agentes del servidor JADE (AMS y DF); además enviar y recibir los mensajes entre agentes.
2. Se desplegó un agente FTP_Agent que extendió las funcionalidades de la entidad “Observable”. Dadas las características del OT la función de este agente consistió en gestionar FTP. También se implementó un agente Personal_Agent que extendió las funcionalidades de la entidad “Observer”, que en este sistema atiende a los usuarios.
El AP solicitó la búsqueda de documentos, que respondan a los intereses del usuario y a los AFD del sistema. Los AFD realizaron búsquedas en sus correspondientes FTP y devolvieron una lista de aquellos documentos que cumplían con dichos intereses.
Al utilizar el componente Observador un AP se subscribió a un AFD, consiguiendo que el AFD que gestiona un FTP pudiera enviar resultados nuevos al AP según los intereses del usuario que representa. El AP envió un correo electrónico con los resultados nuevos encontrados, acción que se realizó proactivamente, ya que el usuario no tuvo que realizar una búsqueda. El usuario obtuvo información nueva que apoyó a su proceso de toma de decisiones con sólo poner sus intereses. En la figura 5 se muestra un ejemplo del correo enviado por el AP a un usuario.

Despliegue del Observatorio Tecnológico
Para ver el OT en funcionamiento con el SMA desplegado, se desarrolló una prueba piloto con 38 usuarios. Las 38 personas escogidas son graduados de Ingeniería Informática y tienen experiencia en desarrollar búsquedas de información para enfocar sus investigaciones.
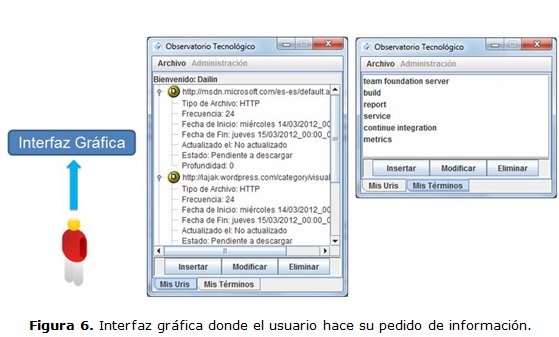
Los usuarios interactúan con la interfaz gráfica como se muestra en la figura 6. Aquí el usuario especifica las palabras claves que quiere que aparezcan dentro de los documentos, además puede especificar las Uniform resource identifier (Uris) que desea que sean revisadas. Esta información se recoge en el perfil del usuario, el cual puede ser actualizado y cambiado.
Los usuarios recibieron un correo electrónico con los resultados de la búsqueda, los cuales se obtienen de una iteración completa de búsqueda. El AP tiene un comportamiento proactivo y cada cierto tiempo revisa las fuentes de información de interés para el usuario, para lo cual el OT se apoya en el componente Observador. Cuando ocurren cambios en dichas fuentes de información relevantes a los intereses del usuario, el AP envía un nuevo correo electrónico con los hallazgos sin que medie una petición. Además, si el usuario cambia sus intereses, comienza todo el proceso de búsqueda sin hacer una petición. De esta forma el OT explota su comportamiento proactivo para apoyar en la toma de decisiones.
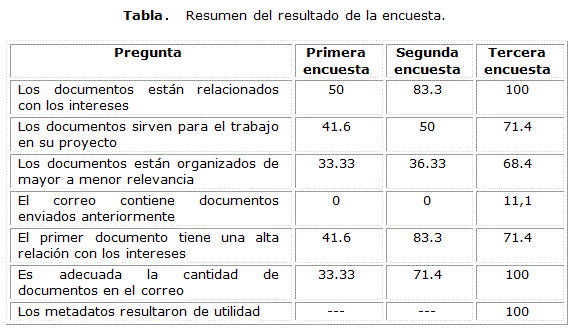
En la prueba piloto se realizó una encuesta por cada correo electrónico enviado a los usuarios, teniendo en cuenta los tres primeros correos. Las encuestas tenían como objetivo evaluar el funcionamiento del OT en varios aspectos: si los resultados responden a los intereses del usuario, que los resultados no se repitan, que los documentos se organicen de mayor a menor relevancia, regular el tamaño de los resultados obtenidos, periodicidad de la búsqueda, entre otros.
Las encuestas se diseñaron para que las afirmaciones fueran clasificadas como verdaderas (“V”) o falsas (“F”). En la tabla se muestra un resumen de los resultados de la encuesta aplicada a los 38 usuarios que participaron en la prueba piloto. En la tabla se muestran las preguntas y los resultados en cada una de las iteraciones de la encuesta realizada. Los resultados se exponen con el porcentaje de las veces que tuvieron una evaluación “V”.
Durante la prueba piloto y como resultado de las encuestas se realizaron actualizaciones en la implementación y ajustes en las configuraciones de los AP que a continuación se enumeran:
1. Enviar un máximo de 50 documentos en cada correo.
2. Los documentos que se envíen deben tener cada uno un valor numérico que represente la relevancia del documento.
3. No se envía como adjunto el documento más relevante.
4. Enviar un correo por cada semana.
5. Enviar metadatos extras de interés para cada documento en el correo (autor, total de páginas, fecha de creación y modificación, palabras claves y un resumen del texto donde se resaltan las palabras buscadas).
6. Cambiar el formato e implementación de envío del correo.
7. Tener un fichero local por cada usuario para no reenviar documentos que fueron enviados antes.
DISCUSIÓN
El SMA implementado como escenario de validación de resultados permite la vigilancia de diversas fuentes de información, con la correspondiente alerta a los usuarios sobre recursos de información potencialmente de su interés. Un beneficio fundamental de la propuesta de solución está precisamente en la simbiosis que logra SMA+OT.
Con el desarrollo del OT con la arquitectura de un SMA, se logra tener una aplicación con un comportamiento proactivo para apoyar la toma de decisiones. Este comportamiento apoya sustancialmente a los usuarios del OT. Cada usuario tiene un AP que busca y sugiere los documentos que deben estudiar y los que pueden ser más relevantes en su tema. Todo esto se obtiene de forma proactiva, ya que el usuario sólo debe poner sus temas y palabras claves de interés. El AP que representa al usuario utiliza el componente Observador, que le permite encontrar cambios en las fuentes de información de interés. Cuando hay un cambio, el usuario recibe un correo con lo nuevo encontrado en las fuentes de información o lo que ha socializado otro agente.
Como se puede ver en los resultados del despliegue del OT, una vez que los usuarios llenan su perfil, los AP que lo representan están en una constante observación de su ambiente para de esta forma entregarle a su usuario la información que responda a los intereses. Cada vez que se encuentra un documento nuevo, que puede sea resultado del cambio en una fuente de información o sea resultado de la búsqueda tramitada por un AP que representa a otro usuario, se le informa al mismo, quien decide si lo utiliza o no, sin tener que buscarlo directamente.
Si el OT se hiciera sobre una filosofía no proactiva, se necesitaría personas que estén buscando cada cierto tiempo esta información. Con la solución propuesta no es necesario este personal, además que el usuario evita invertir tiempo en la búsqueda. Con las soluciones no proactivas los usuarios siempre tendrían que pedir la documentación que necesitan. Sin embargo, con este enfoque proactivo el usuario siempre está alerta de los cambios que ocurren y que responden a sus intereses.
La encuesta devela que una gran cantidad de las personas que participaron en la prueba piloto tienen un nivel de satisfacción alto con los resultados que se les enviaron a partir de sus perfiles.
Al ser una implementación Java, la plataforma JADE se integra de forma natural a otras tecnologías. La flexibilidad que esto permite garantiza, de forma natural, la adición de nuevas funcionalidades o agentes que incrementen las prestaciones del sistema diseñado.
Del mismo modo, el trabajo presentado está en sintonía con otras propuestas que vinculan la investigación en web semántica y SMA al servicio de los sistemas de recuperación de información [2; 25; 29]. La consulta de otras propuestas reafirman la relevancia del tema y el valor de la solución que se presenta en este trabajo para garantizar la flexibilidad y escalabilidad que requiere el desarrollo de un Observatorio Tecnológico.
CONCLUSIONES
1. Los Observatorios Tecnológicos soportan la gestión de información en medio de la creciente demanda de información, en tanto se encargan de buscar información catalogada y relevante para sus usuarios.
2. La mayor parte de los Observatorios Tecnológicos no pueden atender muchos usuarios con intereses diferentes, debido a que su funcionamiento se basa en un elevado número de personal académico que abarcan un resultado más general.
3. Una gran parte de los observatorios no se construyen teniendo en cuenta la proactividad, a pesar de que esta propiedad resulta muy relevante para este tipo de sistemas.
4. Los agentes tienen como propiedad la proactividad, por lo que la construcción de un observatorio con una arquitectura de agente puede permitir incluirle características proactivas.
5. La inclusión de características proactivas en un Observatorio Tecnológico mejora su rendimiento, ya que el sistema es capaz de responder las solicitudes de información de los usuarios, proveyéndoles de información precisa a partir de su perfil y lo apoya en la toma de decisiones.
6. La arquitectura aquí planteada y la forma de incluir la proactividad puede ser reutilizada en otros sistemas de búsqueda de información, incluso en el mismo OT desde otras interfaces.
7. El patrón de implementación propuesto simplifica el desarrollo de un conjunto de agentes, al tiempo que garantiza el cumplimiento de los estándares a través de un amplio conjunto de servicios del sistema y los agentes con JADE.
REFERENCIAS
1. REY, L., Informe APEI sobre vigilancia tecnológica, Gijón (España), Asociación Profesional de Especialistas en Información, 2009, ISBN 978-84-692-7999-1.
2. RUEY, C.; DUEN, C., «Apply ontology and agent technology to construct virtual observatory» Expert Systems with Applications, 2008, vol. 34, no. 3, pp. 2019–2028, ISSN 0957-4174.
3. DE LA VEGA, I., «Tipología de Observatorios de Ciencia y Tecnología. Los casos de América Latina y Europa» Revista Española De Documentación Científica, 2007, vol. 30, no. 4, pp. 545-552, ISSN 0210-0614.
4. PIÑEIRO, M.; MACÍAS, A.; GUERRA, C.; MORALES, A.; AGUIRRE, M., «El observatorio de la producción científica de la UPV/EHU» Revista Española De Documentación Científica, 2010, vol. 33, no. 1, pp. 145- 161, ISSN 0210-0614.
5. MATSATSINIS, N.; MORAITIS, P.; PSOMATAKIS, V.; SPANOUDAKIS, N., «An agent-based system for products penetration strategy selection» Applied Artificial Intelligence, 2003, vol. 17, no. 10, pp. 901–925, ISSN 0883-9514.
6. WAGNER, V.; DULLAART, A.; BOCK, A. K.; ZWECK, A., «The Emerging Nanomedicine Landscape» Nature Biotechnology, 2006, vol. 24, no.10, pp. 1211-1217, ISSN 1087-0156.
7. FARCAS, A., «KAWAX. Observatorio Chileno de Ciencia, Tecnología e Innovación. Estado actual y perspectivas», en II Seminario Internacional sobre Indicadores de Ciencia, Tecnología e Innovación Santiago de Chile, editor, 2006, [consulta: 2012-11-11]. Disponible en: <http://www.cincel.cl/documentos/Recursos/Alan_Farcas.ppt>
8. VILLANUEVA, P., Extrusión: Informe de vigilancia tecnológica [en línea], 2012 [consulta: 2012-08-29]. Disponible en: <http://www.avep.es/uploads/noticias/IVT-Extrusion_FINAL.pdf>
9. PEÑA, R., Estudio de mercado. El sector de componentes de automoción en Rumanía [en línea], 2012 [consulta: 2012-08-29]. Disponible en: <http://www.icex.es/icex/cma/contentTypes/common/records/viewDocument/0,,,00.bin?doc=4646021>
10. MORCILLO, P., «Vigilancia e inteligencia competitiva: fundamentos e implicaciones», Revista de Investigación en Gestión de la Innovación y la Tecnología [en línea], 2003, vol. Vigilancia Tecnológica, no. 17, [consulta: 2012-10-14], ISSN 1725-5821. Disponible en: <http://www.madrimasd.org/revista/revista17/tribuna/tribuna1.asp>
11. WOOLDRIDGE, M., An Introduction to MultiAgent Systems, 2nd. ed., Chichester, John Wiley & Sons, 2009, ISBN 978-0470519462.
12. VAN DER HOEK, W.; WOOLDRIGE, M., «Multi-Agent Systems», B. PORTER; V. LIFSCHITZ; F. V. HARMELEN, Handbook of Knowledge Representation, Amsterdam, Elsevier Science, 2008, ISBN 978-0444522115.
13. SANTOS, D.; RIBEIRO, M.; BASTOS, R., «Developing a Conference Management System with the Multi-Agent Systems Unified Process: A Case Study», M. LUCK; L. PADGHAM, Agent-Oriented Software Engineering VIII, Berlin, Springer Berlin Heidelberg, 2008, ISBN 978-3-540-79487-5.
14. ZHANG, Y.; VOLZ, R., «Forming Proactive Team Cooperation by Observations», R. KHOSLA; R. HOWLETT; L. JAIN, Knowledge-Based Intelligent Information and Engineering Systems, Berlin, Springer Berlin Heidelberg, 2005, ISBN 978-3-540-28894-7.
15. SCHOLLMEIER, R., «A definition of peer-to-peer networking for the classification of peer-to-peer architectures and applications», en First International Conference on Peer-to-Peer Computing Linkoping, 2001, pp. 101-102. [consulta: 2012-09-25]. Disponible en:
<http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=990434&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D990434>
16. JENNINGS, N., «An agent-based approach for building complex software systems» Communications of the ACM, 2001, vol. 44, no. 4, pp. 35–41, ISSN 0001-0782.
17. COSSENTINO, M.; GLEIZES, M.; MOLESINI, A.; OMICINI, A., «Processes Engineering and AOSE», M. P. GLEIZES; J. GÓMEZ-SANZ, Agent-Oriented Software Engineering X, Berlin, Springer Berlin Heidelberg, 2011, ISBN 978-3-642-19207-4.
18. ROMERO, S.; PARRA, P.; SOTO, R.; XÓCHITL, M.; MALPICA, A., «Observatorio de propiedad intelectual universitario» Ars Pharm, 2010, vol. 51, no. 2, pp. 201-208, ISSN 0004-2927.
19. FIPA Agent Management Specification. 2003, [fecha de consulta: 2012-12-19]. Disponible en: http://www.fipa.org/specs/fipa00023/XC00023H.html
20. LI, J.; FENG, Y., «Construction of Multi-Agent System for Decision Support of Online Shopping», H. DENG; D. MIAO; F. WANG; J. LEI, Emerging Research in Artificial Intelligence and Computational Intelligence, Berlin, Springer Berlin Heidelberg, 2011, ISBN 978-3-642-24281-6.
21. FERNÁNDEZ, F., «Un Modelo de Sistema de gestión Documental Colaborativo y Supervisado (SICLOS)», [tesis doctoral], La Habana, Instituto Superior Politécnico José Antonio Echeverría, Cujae, Facultad de Ingeniería Informática, 2007.
22. CEBALLOS, H.; BRENA, R., «Combinando acceso local y global a Ontologías en Sistemas Multiagentes» Revista Iberoamericana de Sistemas, Cibernética e Informática, 2005, vol. 2, no. 1, pp. 13-22, ISSN 1690-8627.
23. BAOUSIS, V.; ZAVITSANOS, E.; SPILIOPOULOS, V.; HADJIEFTHYMIADES, S.; MERAKOS, L.; VERONIS, G., «Wireless web services using mobile agents and ontologies», en International Conference on Pervasive Services 2006, pp. 69-77. [consulta: 2012-06-25]. Disponible en: <iit.demokritos.gr/~vspiliop/ICPS2006.pdf>
24. SHOHAM, Y.; LEYTON, K., Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations, 1st. ed., Cambridge, Cambridge University Press, 2008, ISBN 978-0521899437.
25. HAMDI, M. S., «MASACAD: A multi-agent approach to information customization for the purpose of academic advising of students» Applied Soft Computing, 2007, vol. 7, no. 3, pp. 746-771, ISSN 1568-4946.
26. MIN, D.; CHUN, L.; JIN, D.; GUEY, C.; CHORNG SHYONG, O., «Designing an Ontology-Based Intelligent Tutoring Agent with Instant Messaging», en Fifth IEEE International Conference on Advanced Learning Technologies ICALT´05 Kaohsiung, 2005, pp. 318-320. [consulta: 2012-09-01]. Disponible en: <http://iasl.iis.sinica.edu.tw/webpdf/paper-2005-Designing_an_Ontology-basedIntelligentTutoringAgentwithInstantMessaging.pdf>
27. KENT, B., Implementation patterns, 1st. ed., Boston, Addison-Wesley, 2008, ISBN 978- 0321413093.
28. BELLIFEMINE, F.; CAIRE, G.; GREENWOOD, D., Developing Multi-Agent Systems with JADE, 1st. ed., Chichester, John Wiley & Sons, 2007, ISBN 978-0470057476.
29. PAL, A.; HARPER, F.; KONSTAN, J., «Exploring Question Selection Bias to Identify Experts and Potential Experts in Community Question Answering Expert» 2012, vol. 30, no. 2, pp. 1–28, ISSN 1046-8188.
Recibido: 07/02/2013
Aprobado: 16/05/2013
Mailyn Moreno-Espino. Instituto Superior Politécnico José Antonio Echeverría, Cujae. Facultad de Ingeniería Informática. La Habana, Cuba.
E-mail: my@ceis.cujae.edu.cu


{kind=link}