










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería Industrial
versión On-line ISSN 1815-5936
Ing. Ind. vol.38 no.3 La Habana set.-dic. 2017
ARTÍCULO ORIGINAL
Estudio estadístico del efecto de la similaridad entre rankings en la selección de personal en un contexto competitivo
A statistical study about the effect of the ranking similarity in the personnel selection in a non-cooperative context
Marilyn Bello, Rafael Bello, María M. García, Gladys Casas
Universidad Central Marta Abreu de Las Villas. Villa Clara, Cuba
RESUMEN
La conformación de equipos de trabajos en el contexto de los procesos de selección de personal es relevante para el desempeño de las organizaciones. El proceso de selección usualmente se realiza a partir de un orden de preferencia definido por el decisor. Cuando dos decisores deben elegir a partir de un mismo conjunto de candidatos surge, un conflicto de interés que afecta el resultado de la selección. En este artículo se analiza estadísticamente, como la similaridad entre los ordenamientos de dos decisores afecta el resultado final de la selección de candidatos. El análisis estadístico realizado utilizando la herramienta software SPSS confirma que mientras mayor similaridad entre los órdenes de preferencia definidos por los decisores, menor debe ser la medida en que los equipos resultantes se acercan a las preferencias expresadas en sus ordenamientos.
Palabras clave: selección de personal, toma de decisiones, ordenamientos.
ABSTRACT
The formation of teams in the context of personnel selection processes is relevant to the performance of organizations. The selection process is usually done using an order of preference defined by the decision maker. When two decision makers must choose from the same set of candidates, a conflict of interests that affects the result of selection arises. In this article is statistically analyzed how the similarity between the rankings of preferences of two decision makers affects the final result of the selection of candidates. The statistical analysis developed using the tool SPSS confirms that while more similarity between the rankings of preference established by the decision makers, less similarity between the desired and real selection performed by decisors.
Key words: personnel selection, decision-making, rankings.
INTRODUCCIÓN
El turbulento entorno socio-económico en que actualmente se encuentran las empresas, motivado por la fuerte globalización de los mercados y la rápida aceleración del cambio tecnológico, lleva a éstas a la necesidad de operar en forma de organizaciones más ágiles y flexibles. De esta forma, pueden ser más competitivas para sus clientes e innovar mediante el desarrollo o mejora de procesos. Uno de los factores de éxito para las empresas está muy relacionado con la selección de personal por parte de los directivos, ya que los empleados pueden ser una importante fuente de ventaja competitiva a largo plazo.
La selección de personal es el proceso mediante el cual se elige una o varias personas que mejor se ajusten a las características del trabajo [1; 2; 3; 4].
En los últimos años se consideran los recursos humanos como un recurso estratégico, por lo que una buena gestión persigue crear valor para la empresa, más que reducir costes [5; 6].
La selección de personal determina la calidad del personal que se incorpora, por eso desempeña una función importante en la gestión de recursos humanos. El futuro de la empresa dependerá principalmente de la contribución de su personal, con el objetivo de mantener un lugar en el mercado. En general, la selección de personal depende de criterios específicos, de la disponibilidad de medios y de las preferencias de los que toman las decisiones (decisores o empleadores), siendo un problema altamente complejo [7].
La selecciónde losempleadosestá dentro de los problemas de decisión de la vida real; es un proceso que se espera sea capaz de colocar el empleado correcto, en el puesto correcto y enel momento oportuno. En la actualidad, muchas herramientas y técnicas se utilizanen este problema específico de toma de decisiones [8; 9; 10; 11].
Cualidades personales de los empleados, tales como:suconocimiento, capacidades, y habilidades sonvitales para eléxito de una organización. La naturaleza multicriterio y la presencia de factores tanto cuantitativos como cualitativos hacen la selección de personal considerablemente más compleja.
Los métodos de toma de decisiones multicriterio (Multi-Criteria Decision Making, MCDM) resultan ideales para este propósito. Estos métodos se relacionanconel problema de seleccionar las mejores soluciones a partir de un conjunto de candidatos de acuerdo a los objetivos [12; 13].
Consecuentemente, los métodos MCDM se han aplicado en muchos estudios relacionados con la selección de personal, en los cuales se usaronlos métodos de MCMD para evaluarlos candidatos a partir del grado en que satisfacenlos requisitos o criterios de evaluación [14; 15; 16; 17]. Conocidos métodos de ayuda a la toma de decisiones como TOPSIS, ELECTRE, PROMETHEE y AHP se han utilizado para ayudaren esta problemática [18; 19; 20; 21].
Los MCDM se dirigen a determinar las preferencias globales entre las alternativas posibles. De acuerdo con ese objetivo, puedenusarse para ordenar las alternativas (construir unranking) o tomar una decisión final.
El ordenamiento de alternativas es una tarea común en la toma de decisiones [22]. El ordenamiento de un conjunto de candidatos en la de selección del personal definido segúnalgunaclase de relación de preferencias se conoce como ranking. Para obtener este se evalúan múltiples puntos de vistas considerados relevantes en el proceso de selección.
Obtenerunranking de candidatos es especialmente interesante cuando la gestión de los recursos humanos está dirigida a organizar, gestionar y conducirun equipo de trabajoen lugar de seleccionar un empleado para una simple vacante. Esto contribuye al éxito del proyecto y crea una ventaja competitiva para la organización [23; 24; 25].
La mayoría de los estudios existentes en la selección de personal ignoran el conflicto de preferencias y las interacciones estratégicas entre los decisores, debido a sus intereses en competencia. Este tipo de problema puede surgir en diferentes contextos. Por ejemplo, cuando se tiene un conjunto de jugadores y se quiere formar dos equipos que compitan entre sí, los dos directores de los futuros equipos establecen un ordenamiento según sus preferencias y luego deben escoger uno a uno a sus jugadores. Otro ejemplo puede presentarse en una empresa de software, donde se tienen que conformar dos equipos de proyectos a partir de los recursos humanos de la empresa para desarrollar solicitudes de software de clientes diferentes.
En este artículo, se aborda el problema de la selección de personal para equipos de trabajo en un ambiente competitivo, o sea, cuando dos o más decisores quieren integrar sus equipos de trabajo a partir de un mismo conjunto de candidatos. En este marco de trabajo surge un conflicto de intereses que afecta el resultado de la selección. Por lo anterior, el propósito de esta investigación es: mostrar, desde el punto de vista estadístico, que mientras más similares sean los rankings elaborados por los decisores, mayor será la diferencia entre la selección deseada y la selección alcanzada.
MÉTODOS
Con el propósito de conformar los equipos de trabajo, dos decisores elaboran un escalafón u ordenamiento (ranking) de los N candidatos de acuerdo a sus intereses; donde todos los candidatos serán seleccionados por uno de los dos decisores. Los métodos de toma de decisiones antes mencionados se pueden utilizar para construir los rankings.
Posteriormente, cada decisor selecciona de forma alterna a los candidatos para integrar los equipos de trabajo que estarán constituidos por N/2 miembros. Para ello, tiene en cuenta su orden de preferencias y que el candidato no haya sido seleccionado por el otro decisor. El propósito de cada decisor es obtener un conjunto candidatos que sea lo más similar posible a los que aparecen en las primeras N/2 posiciones del ranking definido por él.
Sin embargo, teniendo en cuenta que ambos decisores seleccionan desde un mismo conjunto de candidatos, existirá probablemente un conflicto de intereses entre ambos.
Formalmente se enuncia la problemática de la siguiente forma:
Se tiene un conjunto de candidatos C= {c1, c2,…, cN}, cada decisor tiene que seleccionar desde este conjunto de candidatos para formar un equipo de trabajo con N/2 miembros (N es número par).
Dos rankings R= {R1, R2} se forman a partir del conjunto de candidatos C, teniendo en cuenta diferentes preferencias para evaluar los candidatos desde la perspectiva de cada decisor. Un decisor D1 define un ranking de los candidatos R1= {r11, r12,…, r1N} y otro decisor D2 define otro ranking R2= {r21, r22,…, r2N} ordenados por orden de preferencia decreciente, o sea r11 ≥ r12 ≥… ≥ r1N y r21 ≥ r22 ≥… ≥ r2N.
Estos rankings reflejan las preferencias de los decisores, y para conformarlos se pueden tener en cuenta diferentes criterios. Los decisores pueden o no conocer el ordenamiento que define su contraparte. Ellos tienen que escoger del conjunto de candidatos C alternadamente D1, D2, D1, D2,…;. Es decir, el primer decisor D1 elige un candidato de acuerdo a su ranking R1, luego el segundo decisor elige otro candidato teniendo en cuenta su ranking R2 y que no haya sido elegido por D1, y así sucesivamente; los decisores quisieran escoger lo más cercano posible a su ranking.
Como resultado construyen dos rankings R1*= {r11, r12,…, r1m} y R2*= {r21, r22,…, r2m}, donde m=N/2. Como los rankings R1 y R2 pueden tener coincidencias, es altamente probable que no sea posible que los decisores puedan escoger los candidatos que desean. En este estudio se muestra que mientras más similares sean los rankings elaborados por los decisores mayor será la diferencia entre el ordenamiento dado y la selección resultante.
Un ranking de N candidatos es una permutación de N valores, de modo que la similaridad entre rankings se puede estimar usando distancias entre permutaciones [26; 27]. Una de las medidas de distancia más frecuentemente utilizada es la distancia de Spearmanfoot rule, ver expresión 1. [28]. La complejidad temporal para computar esta distancia entre dos rankings es lineal, por eso fue seleccionada para la investigación, como se muestra en la ecuación 1.

Dónde: σ y τ representan los rankings generados a partir de un conjunto finito de objetos U, σ (i) representa la posición (u orden) de i en σ y τ (i) la posición de i en τ.
A partir del procedimiento SPC (Selección de Personal en Competencia) se realiza la selección de los candidatos y se determina cuanto dista la selección obtenida de las preferencias de cada decisor. Para ello, se toma como entrada los ordenamientos de N candidatos elaborados por cada decisor y se va conformando la lista de candidatos seleccionados. Este procedimiento además, calcula las distancias entre los rankings establecidos por ambos decisores R1 y R2 (denotada por d(R1, R2)), y la suma de las distancias entre R1* y R1, y R2* y R2, (denotadas por d(R1*, R1) y d(R2*, R2) respectivamente).
Algoritmo SPC:
Entrada: ordenamientos R1 y R2.
Salida: lista de candidatos seleccionados por cada decisor R1*, R2* y distancias entre ordenamientos deseados y computados.
P1: Calcular la distancia entre R1 y R2, d (R1, R2) usando la expresión 1.
P2: i1=1, i2=1, j1=1, j2=1
P3: Repetir hasta que la lista de candidatos C esté vacía (todos los valores de C son 0):
P31: Seleccionar desde C el elemento indicado por R1 [i1], si ese elemento no ha sido seleccionado (quiere decir el valor de C en esa posición es diferente de 0) poner el valor R1 [i1] en R1*[i2], colocar en la posición que estaba en C el valor 0, i1=i1+1, i2=i2+1; sino i1=i1+1 y repetir P31.
P32: Seleccionar desde C el elemento indicado por R2 [j1], si ese elemento no ha sido seleccionado (quiere decir el valor de C en esa posición es diferente de 0) poner el valor R2 [j1] en R2*[j2], colocar en la posición que estaba en C el valor 0, j1=j1+1, j2=j2+1; sino j1=j1+1 y repetir P32.
P4: Calcular la distancia entre R1* y R1, y R2* y R2 usando las expresiones 2 y 3, y la suma de ambas distancias utilizando la expresión 4.

Dónde: b(R1*(i), R1)indica la posición que tiene el candidato que está en la posición i de R1* en el ranking R1 y b(R2*(i), R2) indica la posición que tiene el candidato que está en la posición i de R2* en el ranking R2.
RESULTADOS
A continuación, se analiza estadísticamente la correlación que existe entre las variables X= d (R1, R2) e Y= Sd que representan la distancia entre los rankings establecidos por ambos decisores R1 y R2 y la suma las distancias entre R1* y R1, y R2* y R2 respectivamente.
Se realiza una simulación del proceso de selección de candidatos en la cual se generan aleatoriamente dos rankings R1 y R2 de N elementos y con ellos se ejecuta el algoritmo SPC. En el estudio se consideraron los valores 6, 12 y 18 para N, que se consideran dimensiones bajas y medias, pero son las más usuales en el proceso de evaluación de alternativas en los procesos de toma de decisiones. La Tabla 1 muestra los resultados alcanzados después de aplicar el algoritmo SPC 20 veces para N=6, N=12 y N=18.

Para analizar la posible relación lineal entre las variables X e Y se decidió calcular coeficientes de correlación. La correlación indica la fuerza y la dirección de una relación lineal entre dos variables aleatorias. Existen varios coeficientes con este fin reportados en la literatura: Pearson, que se utiliza cuando las variables son cuantitativas y Spearman y Tau-b de Kendall, que se utiliza mayormente en variables ordinales. En nuestro caso, las variables X e Y en estudio tienen orden, así que se decidió analizar los resultados de los tres coeficientes de correlación. Se utiliza el procedimiento de Correlaciones bivariadas de la herramienta de software SPSS, que calcula el coeficiente de correlación de Pearson, Spearman y Tau-b de Kendall [29; 30].
La Tabla 2 recoge la información referida a los coeficientes de correlación de Pearson, Spearman y Tau-b de Kendall. Cada celda contiene dos valores referidos al cruce entre las dos variables X e Y para cada valor de N: 1), el valor del coeficiente de correlación y 2) el nivel crítico bilateral que corresponde a ese coeficiente (Sig. bilateral). El nivel crítico permite decidir sobre la hipótesis nula de independencia lineal. Se rechazará la hipótesis nula de independencia (y se concluirá que existe relación lineal significativa) cuando el nivel crítico sea menor que el nivel de significación establecido. (** La correlación es significativa al nivel 0.01)

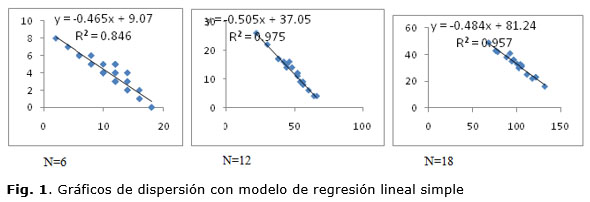
Con el objetivo de medir el grado de asociación entre las variables X e Y, se obtuvieron las ecuaciones de regresión lineal simple para N=6, N=12 y N=18. En la figura 1 se muestran los gráficos de dispersión asociados a estas tres ecuaciones. Se coloca la variable dependiente Y en el eje de las ordenadas y la variable independiente X en el eje de las abscisas. En todos los casos se muestra el valor del coeficiente de determinación R2 en la regresión lineal.
DISCUSIÓN
Como puede observarse en la tabla 2, en todos los casos existe correlación significativa entre las variables X e Y. La correlación es negativa, es decir, que la relación entre las variables es inversa. Esto quiere decir que a medida que aumenta el valor de una variable disminuye el de la otra, o sea, a medida que aumenta la similaridad de los rankings elaborados por los decisores disminuye el grado en que los equipos resultantes del proceso de selección se parecen a estos. Esto se ratifica por los resultados mostrados en la figura 1, donde los tres gráficos de dispersión muestran que la pendiente de las rectas es negativa, por lo que existe una relación inversa entre X e Y.
Como los decisores eligen desde un único conjunto de candidatos, la selección que haga uno puede afectar al otro. Los casos extremos en esta problemática, si los ordenamientos son totalmente diferentes, no existirá afectación de uno en otro; si por el contrario son idénticos, existirá interferencia en el proceso de selección; también pueden existir muchos casos intermedios donde hay solapamiento parcial de los ordenamientos. Precisamente en estos casos, la investigación muestra que hay una correlación negativa significativa entre la distancia entre los dos rankings iniciales establecidos por los dos decisores y el grado en que cada decisor logra formar su equipo según sus preferencias.
En la figura 1 se observa que la relación que existe entre las variables X e Y es lineal. En el primer caso el valor de R2es de 0.846, en el segundo caso es de 0.975 y en el tercer caso es de 0.957 lo cual significa que la variable independiente (X) es capaz de explicar hasta un 84.6%, 97.5 %, 95.7 % de la variabilidad observada en la variable dependiente (Y) para el primero, segundo y tercer caso respectivamente.
En la medida en que la distancia entre los rankings elaborados por los decisores crece, decrece la distancia entre el ordenamiento deseado y el equipo seleccionado, es decir, se logra una mayor satisfacción de los intereses de ambos decisores.
CONCLUSIONES
1. La selección de personal es una actividad relevante para el desempeño de las organizaciones. En este trabajo se abordó la problemática de la formación de equipos de trabajo en un contexto de competencia, es decir, cuando dos decisores tienen que formar sus equipos a partir de un mismo conjunto de candidatos.
2. Para realizar el proceso de formación de los equipos cada decisor ordena a los candidatos según un orden decreciente de las preferencias. Los decisores alternan en la selección de los candidatos tratando de seguir el orden de preferencias establecido, pero lógicamente puede ser que cuando seleccionan un candidato ya este haya sido seleccionado por el otro decisor. Estos conflictos de intereses hacen que al final el equipo seleccionado pueda diferir del que hubiera preferido cada decisor. En este artículo se analizó esta interferencia en el proceso de selección.
3. El estudio estadístico realizado confirma que mientras más similares sean las preferencias de los decisores sobre los candidatos a seleccionar, menor será la posibilidad de que los candidatos seleccionados sean los deseados.
REFERENCIAS
1. Nankervis AR, Compton RL, Mccarthy TE. Strategic Human Resource Management. South Melbourne, Australia: Thomas Nelson Australia; 1993.
2. Valles RJ. La gestión estratégica de los recursos humanos. Wilmington, Delaware: Addison-Wesley Iberoamericana; 1995.
3. Kangas A, Kangas J, Pykalainen J. Outranking methods as tools in strategic natural resourcesplanning. Silva Fennica. 2001;35(2):215-27.
4. Robertson IT, Smith M. Personnel selection. Journal of Occupational and Organizational Psychology. 2001;74(4):441-72.
5. Huselid MA. Theimpact of human resource management practice son turnover, productivity, and corporate financial performance. Academy of Management Journal. 1995;38(3):635-72.
6. Alles MA. Dirección estratégica de recursos humanos. En: Gestión por competencias. Barcelona, España: Editorial Granica; 2000.
7. Liang SL, Wang MJ. Personnelselectionusingfuzzy MCDM algorithm. European Journal of Operational Research. 1994;78(1):22-33.
8. Canós L, Liern V. Softcomputing-based aggregation methods for human resource management. EuropeanJournal o Operational Research. 2008;189(3):669-81.
9. Canós L, Casasús T, Lara T, et al. Modelos flexibles de selección de personal basados en la valoración de competencias. Rect@. 2008;9:101-22.
10. Canós L, Casasús T, Crespo E, et al. Personnel selection based on fuzzy methods. Revista de matemáticas. 2011;18(1):177-92.
11. Canós L, Casasús T, Liern V, et al. Soft computing methods for personnel selection base don’t the valuation of competences. International Journal of Intelligent Systems. 2014;29(12):1079-99.
12. Lai YJ. IMOST: interactive multiple objective system technique. Journal of Operational Research Society. 1995;46(8):958-76.
13. Figueira J, Greco S, Ehrgott M. Multiple criteria decisión analysis: State of the art surveys series. Boston: Springer; 2005.
14. Zhang S, Liu S. A GRA base dintuitionistic fuzzy multicriteria group decisión making method for personnel selection. Expert Systems with Applications. 2011;38(8):11401–5.
15. Balezentis A, Balezentis T, Brauers KM. Personnel selection based on computing with words and fuzzy Multimoora. Expert Systems with Applications. 2012;39(15):7961-7.
16. Kabak M, Burmaoglu S, Kazançoglu Y. A fuzzy hybrid MCDM approach fo rprofessional selection. Expert Systems with Applications. 2012;39(3):3516-25.
17. Gilan SS, Sebt MH, Shahhosseini V. Computing with words for hierarchical competency based selection of personnel in construction companies. Applied Soft Computing. 2012;12(2):860-71.
18. Alecos K, Dimitrios A. A new TOPSIS-basedmulti-criteria approach to personnel selection. Expert Systems with Applications. 2010;37(7):4999-5008.
19. Afshari AR, Mojahed M, Yusuff RM, et al. Personnel selection using Electre. Journal of Applied Sciences. 2010;10(23):3068-75.
20. Brans JP, Mareschal B, Vincke PH. PROMETHEE: A new family of out ranking methods in multicriteria analysis: Universite Libre de Bruxelles; 1984.
21. Güngör Z, Serhadlioglu G, Kesen SE. A fuzzy AHP approach to personnel selection problem. Applied Soft Computing. 2009;9(2):641-6.
22. Lotfi FH, RostamyMalkhalifeh M, Aghayi N, et al. Anim proved method for ranking alternatives in multiplecriteria decision analysis. Applied Mathematical Modelling. 2013;37(1):25-33.
23. Amit R, Belcourt M. Human resourcemanagementprocesses: a valuecreatingsource of competitiveadvantage. European Management Journal. 1999;17(2):174-81.
24. Huemann MK, A, Turner JR. Human resourcemanagement in theproject-orientedcompany: a review. International Journal of Project Management. 2007;25(3):315-23.
25. Thomas S, Tang Z. Labour-intensive construction sub-contractors: their critical success factors. International Journal of Project Management. 2010;28(7):732-40.
26. Aledo JA, Gámez JA, Molina D. Tackling the rank aggregation problem with the volutionary algorithms. Applied Mathematics and Computation. 2013;222(632-644).
27. Van Zuylen A, Schalekamp F, Williamson DP. Popular ranking. Discrete Applied Mathematics. 2014;165(11):312-6.
28. Liviu PD, Manea F. Anefficienta pproach for the rank aggregation problem. Theoretical Computer Science. 2006;359(1):455-61.
29. Siegel S, Villalobos JA, Cruz López RV. Diseño experimental no paramétrico: aplicado a las ciencias de la conducta, Trillas; 1970.
30. Sheskin DJ. Parametric and Nonparametric Statistical Procedures. Third Edition ed: Chapman & Hall/CRC; 2004.
Recibido: 8 de mayo de 2015.
Aprobado: 6 de octubre de 2016.
Marilyn Bello, Universidad Central Marta Abreu de Las Villas. Villa Clara, Cuba
Correo electrónico: mbgarcia@uclv.cu


{kind=link}