










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
I. INTRODUCCIÓN
En el contexto de integración de datos, ha surgido en la última década, el enfoque de Datos Empresariales Enlazados (LED por sus siglas en inglés) o “Linked Data in Business” como lo nombran unos pocos [1, 2, 3, 4, 5]. LED, derivación para la empresa del término Linked Data acuñado por Berners Lee, es un enfoque novedoso para la integración de datos en el contexto empresarial, que integra los datos con independencia de su procedencia, para crear un espacio de información global y unificado [4, 6, 7]. Al igual que la web tradicional enlaza páginas web, LED enlaza los datos de la empresa en el nivel más detallado , considerando su significado y contenido [9, 10].
LED refiere un marco para incorporar los beneficios de la web semántica en el sistema de información de la empresa [11, 12, 13, 14]. Específicamente utiliza las herramientas y técnicas de la Web Semántica para conectar, publicar y usar datos de la empresa ; y publica los datos, siguiendo los principios de los Datos Enlazados o Linked Data , . El “backbone” técnico de este enfoque, lo constituyen las tecnologías URI (Uniform Resource Identifiers), RDF (Resource Description Framework)1, Ontologías, Linked Data y SPARQL (SPARQL Protocol y RDF Query Language) 2.
El URI proporciona una forma genérica de identificar algo en la web [14]. El modelo RDF es un modelo de datos para la web que permite expresar información sobre recursos que ha sido adoptado como modelo de intercambio de datos para la web semántica y facilita la tarea de integrar datos procedentes de múltiples fuentes [14, 15]. Las ontologías pueden captar eficazmente la semántica de los datos, así como integrar datos de forma eficiente [16]. Linked Data crea enlaces explícitos entre los conjuntos de datos y proporciona un conjunto de buenas prácticas para la publicación y vinculación de los datos estructurados en la web , , conocido como los principios de linked data [6, 15,17, 18]. SPARQL es un lenguaje estandarizado para la consulta de grafos RDF [17] .
LED proporciona beneficios relacionados con el acceso y utilización de los datos en el contexto empresarial [1]. LED aporta una manera de utilizar los datos de forma eficiente y entre sus beneficios está la integración de aplicaciones existentes en el nivel de datos , que no se logra fácilmente en enfoques anteriores[19, 20]. Permite crear de forma ágil, nuevas aplicaciones que utilicen los datos existentes sin alterar los modelos de datos residentes en las aplicaciones que funcionan [21] . Con LED se mejora la interoperabilidad de los datos y el valor de cada información mejora por sus enlaces a datos complementarios , con lo cual se potencia la toma de decisiones bien fundamentadas [ 22, 23].
Otros beneficios de utilizar este enfoque en la integración de los datos en la empresa son [12]:
Define de forma precisa la semántica contenida en los datos empresariales
Facilita la creación de taxonomías empresariales con estándares como SKOS3 para la estructuración de grandes cantidades de documentos que se producen diariamente como correos electrónicos, directivas empresariales, entre otros [24]
Mejora la búsqueda de información al interior de la empresa, con resultados más precisos en relación al tema buscado [24]
Facilita el acceso a los datos vía web [24]
Facilita la integración de los datos estructurados con datos no estructurados y semiestructurados [22]
Permite la creación de nuevas informaciones a partir inferencias utilizando los datos existentes [22]
Todos los beneficios anteriormente descritos, tributan a una mejor gestión de información en las empresas y contribuyen a una toma de decisiones más rápida y con más fundamentación, tributando entonces a una mejor adaptabilidad y sostenibilidad de las empresas en el mercado que compiten.
La problemática de integración de datos está presente en la Empresa de Mensajería y Cambio Internacional (EMCI), siendo esta, uno de los principales problemas detectados en un diagnóstico reciente sobre gestión de información .
La EMCI integrada al Grupo Empresarial Correos de Cuba, brinda servicios de intercambio y tratamiento internacional de correspondencia y encomiendas postales del servicio postal universal; así como servicios de mensajería y paquetería. La actividad postal constituye una de sus principales actividades y genera diariamente un gran volumen de información asociado al manejo de las operaciones relacionadas con los conceptos de Operaciones Postales, Telegráfica, y de Prensa. El Grupo Empresarial Correos de Cuba ha desarrollado algunas soluciones que responden a la evolución de los requerimientos informacionales de la organización ; sin embargo, existen algunas carencias informacionales, como es el caso de la información para la planificación de los recursos.
La Dirección de Operaciones de la EMCI (DOEMCI) recibe diariamente un volumen considerable de información adelantada, procedente de las 36 agencias internacionales de viaje con las que se tienen contratos, referente a los bultos que serán trasportados en el próximo período. Las prealertas o Manifiesto, como se nombra esta información, constituyen la base para planificar los recursos en la planta de operaciones.
Las prealertas se reciben en la empresa de forma dispersa, con variados formatos y con variación en el contenido, según la agencia de viaje que la envíe. La empresa no cuenta con ninguna herramienta que procese de forma integrada los datos contenidos en las prealertas con la consecuencia negativa que no se puede prever para un período de tiempo cuál sería el volumen de operación para la planta y por tanto no se planifican proactivamente los recursos para las operaciones. Esta situación trae como consecuencia que la planta de procesamiento se sobresature en algunas oportunidades, siendo esta una de las causas que no se cumplan los tiempos de entrega para los envíos, afectando finalmente los indicadores de calidad establecidos para esta actividad.
Considerando las ventajas del enfoque LED para lograr una efectiva integración de los datos y que a pesar de sus beneficios su aplicación en las empresas todavía es limitado ,existiendo autores que lo declaran como una idea abstracta o ideal [7, 16, 27] ; así como las dificultades de integración de prealertas existentes en la DOEMCI, se declara el objetivo del artículo como aplicar el enfoque LED en la EMCI para integrar los datos de las prealertas. En el método se expone el Procedimiento empleado para la aplicación del enfoque LED y en los resultados y la discusión se describen los pasos que se han llevado a cabo en dicha empresa, lo que demuestra la aplicabilidad y beneficios que genera.
II. MÉTODOS
Para aplicar el enfoque de los Datos Empresariales Enlazados en la EMCI se utiliza un procedimiento diseñado para tales efectos, que cumple de forma general con el ciclo de vida de LD, incluyendo las actividades que de forma regular se ejecutan en este ciclo , , y se le han incorporado aspectos propios del contexto empresarial, tales como:
Estar orientado a procesos desde el inicio: A diferencia de la otras metodologías de Datos Enlazados que suelen estar basados en el análisis de los datos en sí mismos o en el conocimiento del dominio que tengan las comunidades , enlazar datos en una empresa debe seguir un riguroso enfoque orientado a procesos. Dicho enfoque debe garantizar la alineación de la capa de información a los objetivos estratégicos del negocio; así como de los intereses de las personas a las políticas organizacionales.
Considerar tanto datos internos de la organización como externos (accesibles desde la web).
Aunque se interpreta con frecuencia, en etapas tempranas de este proceso, que enlazar datos empresariales implica a los recursos informacionales internos solamente, la propia capacidad del enfoque enlazado posibilita enriquecer los datos que se generan en la empresa con otros datos del cliente, el proveedor o el contexto donde se desenvuelve la misma. Con esto mejorar la capacidad del proceso de decisión basado en datos. En estos entornos se recomienda usar la anotación semántica para enlazar otros recursos de datos que complementan los datos estructurados en forma relacional en la empresa. Esos otros datos (externos) pueden estar públicos como datos enlazados (ej. el proyecto Linked Open Data) o en múltiples fuentes abiertas de la Web (ej. la información proveniente de redes sociales).
Aprovechar enfoques clásicos de integración de datos a nivel empresarial. Sin alejarse de los principios de los Datos Enlazados, este requerimiento busca utilizar los enfoques que proporcionan los sistemas de información ejecutivos de la empresa para simplificar la tarea de crear redes de ontologías o enlazar los RDF generados. Un ejemplo se puede ilustrar con la potencialidad que pudiera ofrecer un ETL4 Semántico al enlazado de datos empresariales, un concepto heredado de la Inteligencia de Negocio.
Estructuralmente, el procedimiento consta de cinco etapas como se muestran en la figura 1.
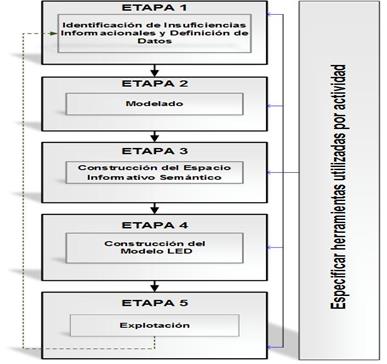
Las etapas están integradas por diferentes actividades, que representan los pasos que deben realizarse en el proceso de integración. A continuación, se describe de forma general el objetivo de cada etapa y se precisan algunas de las herramientas que pudieran utilizarse.
Etapa 1: Identificación de Insuficiencias Informacionales y Definición de Datos
La primera etapa del procedimiento tiene como objetivo precisar carencias informacionales que limitan el funcionamiento de uno o varios procesos de la empresa, así como especificar las fuentes de datos que deben integrarse para dar solución a la problemática de integración. Se debe precisar qué informaciones no se obtienen en uno o varios procesos de la empresa y que para su obtención se deba consultar datos dispersos en las diferentes fuentes existentes. Se define el para qué de la integración, siempre considerando mejorar la operatividad de los procesos. La etapa también identifica y selecciona las fuentes de datos que deben ser integradas para dar solución a las carencias detectadas. Se trata del con qué de la integración, a partir de considerar sistemas informáticos y fuentes de datos en general, que se utilicen en el funcionamiento de los procesos. Las herramientas que se pueden utilizar en la etapa son: entrevistas, análisis de documentos, análisis del mapa de procesos, inventario de los sistemas de información, Modelaciones BPM (Business Process Management), diagnósticos de gestión de información efectuados en la organización, Modelo de Negocios, entre otras.
Etapa 2: Modelado
Se modela la semántica contenida en las fuentes de datos, partiendo primero de modelar el dominio de actuación y su posterior representación ontológica. Da como resultado un modelo ontológico a utilizar. Se incluye el mapeo lógico entre las fuentes de datos identificadas en la primera etapa y el modelo ontológico resultante; así como el diseño de los URI para identificar los recursos en la web. En la etapa se deben utilizar herramientas para el desarrollo y edición de ontologías, así como herramientas de modelación de información.
Etapa 3: Construcción del Espacio Informativo Semántico
El espacio informativo semántico es la representación en el modelo RDF de cada fuente de datos especificada en la etapa 1, definir la semántica contenida en los datos de las diferentes fuentes. El objetivo de la etapa es transformar al modelo RDF cada fuente de datos involucrada. Tal como ocurre en un ETL semántico, que se incorpora las tecnologías semánticas en la fase de transformación del proceso ETL . En esta etapa se toma como base el modelo ontológico definido en la etapa anterior, para transformar cada fuente de datos a su correspondiente modelo RDF, haciendo corresponder las tablas y los campos de las fuentes de datos, con las clases y propiedades del modelo ontológico. Inicialmente, en la etapa se analizan los formatos y la información contenida en las fuentes de datos, para preparar tanto como sea posible los conjuntos de datos (eliminar inconsistencias; completar datos, extraer datos, eliminar duplicados, etc) previo a la transformación al modelo RDF. Luego con la herramienta de transformación que se utilice se ejecuta la transformación. En esta etapa se deben utilizar las herramientas que permitan transformar o preparar, de ser necesario previo a su transformación, los conjuntos de datos; así como las herramientas para la Transformación a RDF de las fuentes de datos.
Etapa 4: Construcción del Modelo LED
Esta etapa tiene como objetivo enlazar los modelos RDF obtenidos en la etapa anterior, teniendo en cuenta las necesidades informacionales que se definieron en la primera etapa de este procedimiento, obteniendo un conjunto de grafos RDF enlazados, nombrado en la literatura sobre el tema como “Dataset” , , . En esta etapa, debe considerarse el enlace con un modelo LOD (Linked Open Data) exterior a la empresa. Por último, se almacena y se publica el Dataset, en un almacén de tripletas RDF o “triple store” para su posterior consumo y/ explotación , , . Con esta etapa quedan integrados los datos en la empresa. Se utilizan herramientas para enlazar los modelos RDF y herramientas para almacenar y publicar el modelo RDF enlazado.
Etapa 5: Explotación
Esta es la etapa con el objetivo de utilización o consumo de la capa de datos enlazados para proporcionar fácil acceso a la información integrada y potenciar la toma de decisiones en la empresa, desarrollando por ejemplo aplicaciones Web. Las aplicaciones que utilizan o consumen los datos enlazados publicados pueden ser desarrolladas con el uso de diferentes librerías, según sea el lenguaje de programación, tal como se refleja en . Se utilizan herramientas como frameworks de desarrollo de software, CMS semánticos, API REST.
III. RESULTADOS
La aplicación de procedimiento se enmarca dentro del contexto de los envíos postales que son gestionados en la Dirección de Operaciones de la EMCI (DOEMCI) y tiene como objetivo integrar la información de las prealertas que se reciben de las diferentes agencias de viaje, para obtener datos relevantes que contribuyan al proceso de planificación de las operaciones de la planta de procesamiento.
Etapa 1: Identificación de Insuficiencias Informacionales y Definición de Datos
La DOEMCI recibe diariamente un volumen considerable de información adelantada referente a los bultos que serán trasportados en el próximo período. Las prealertas o manifiesto, como se nombra esta información, se envían por las diferentes agencias de viaje y contiene la individualización de cada una de las Guías Courier que transporta un mensajero internacional, sea por vía aérea o terrestre, mediante el cual las mercancías se presentan y entregan a la Aduana. Las Guías Courier contienen información sobre la cantidad de bultos que contiene el envío y su peso en kilogramo; la agencia que lo envía, la línea área que lo transporta, el número de vuelo y el país origen; de cada envío en particular contiene un número identificativo, su peso individual, fecha, datos del remitente como nombre y número de identidad; y datos del destinatario como nombre, carnet de identidad, dirección, provincia y municipio.
Las prealertas son enviadas por: los operadores internacionales, la DOEMCI y la dirección de la planta. A partir del recibo de las prealertas pueden realizar la planificación de los medios y recursos materiales y humanos (transporte, operarios, combustible, servicios aduanales y transitarios, entre otros) que garanticen en tiempo y forma el desarrollo exitoso de las operaciones. Se tiene en cuentaque los operadores postales deben cumplimentar con indicadores relacionados con el servicio de entrega de los productos.
A partir de un estudio informacional en la DOEMCI no existe ninguna herramienta que brinde una visión unificada de todas las prealertas. En la empresa, esta información se procesa de forma separada por distintos especialistas, y no se procesa de forma integrada. Además, que según sea la agencia que envíe las prealertas, varía el formato y el conjunto de información que contienen. En específico se carece de datos relacionados con:
Resúmenes de tipo de carga
Resúmenes de vía de transportación (área, marítima)
Total de envíos para un periodo
Total de Envíos para una provincia
Volumen total de operación
Volumen total de operación por provincia
Peso total para un periodo
Lo anterior, deriva en una consecuencia negativa para la empresa dado que no se puede prever para un período de tiempo cuál sería su volumen de operación y por tanto no planifica adecuadamente los recursos para sus operaciones. Esta situación trae como consecuencia que la planta de procesamiento se sobresature, siendo esta una de las causas que no se cumplan los tiempos de entrega para los envíos.
Los problemas con la integración de la información de las prealertas, ocasionan carencias informacionales que limitan el proceso de planificación de los recursos para la planta de operaciones.
La tabla 1 muestra las fuentes de datos de interés para el proceso de integración de información, así como el formato en el cual las mismas están disponibles.
Etapa 2: Modelado
En esta etapa se debe modelar información relacionada con las prealertas. Las prealertas, como se menciona anteriormente en general contiene información sobre los envíos, sus destinatarios y remitentes. La figura 2 refleja el modelo de dominio correspondiente a la situación anterior:
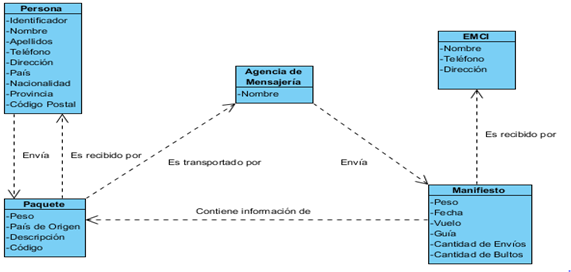
Tomando en consideración el modelo de dominio, se crea una red de ontologías, a partir de la reutilización de clases y propiedades de los vocabularios foaf y vcard y de la creación de una ontología propia para estos efectos, la ontología emciop.
Del vocabulario FOAF5, se utilizan clases y propiedades en la modelación de personas que representan a los remitentes y destinatarios. Del vocabulario VCARD6, se utilizan las propiedades para completar la modelación de los datos de las direcciones de remitentes y destinatarios. La Tabla 2 muestra las clases y propiedades que se reutilizan de cada vocabulario.
Tabla 2 Clases y propiedades que se reutilizan de cada vocabulario
| Vocabulario | Término | Tipo | Descripción |
|---|---|---|---|
| foaf | Person | Clase | Identifica a una persona |
| name | Propiedad | Un nombre para alguna cosa | |
| familyName | Propiedad | Identifica los apellidos de una persona | |
| vcard | has_key | Propiedad | Identificación de una persona |
| region | Propiedad | Identifica la provincia de una persona | |
| country_name | Propiedad | Identifica el nombre de un país | |
| has_postal_code | Propiedad | Identifica el código postal | |
| has_telephone | Propiedad | Identifica el teléfono |
Las clases propias de la ontología creada permiten modelar lo relacionado con paquete y manifiesto. El modelo ontológico resultante se muestra en la figura 3.
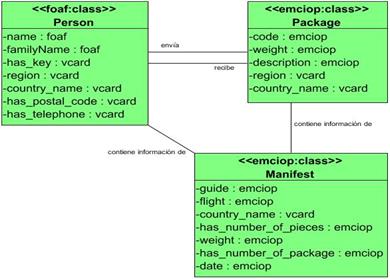
El resultado de la actividad relacionada con el mapeo lógico entre la fuente de datos XML y las clases del modelo ontológico utilizado según se muestra en la tabla 3. Una tabla similar se realizó para el mapeo de la fuente de datos XLS.
Tabla 3 Diseño lógico del mapeo Fuentes de datos Vs Ontologías para la fuente de datos en XML
| Fuente de datos | Tipo de entidad en la Fuente de datos | Ontología/Vocabulario | Término | Tipo de entidad en la ontología | Descripción |
|---|---|---|---|---|---|
| Pack | Tabla | emciop | Package | Clase | Identifica a un paquete |
| AirwayBillNumber | Columna | emciop | code | Propiedad | Identifica el Número de guía. |
| ShipmentOriginCountry | Columna | vcard | country_name | Propiedad | Identifica el nombre de un país |
| ShipmentWeight | Columna | emciop | weight | Propiedad | Identifica el peso de un paquete |
| ShipperName | Columna | foaf | name | Propiedad | Un nombre para alguna cosa |
| ShipperPostCode | Columna | vcard | has_postal_code | Propiedad | Identifica el código postal |
| ShipperProvince | Columna | vcard | region | Propiedad | Identifica la provincia de una persona |
| ShipperPhoneNumber | Columna | vcard | has_telephone | Propiedad | Identifica el teléfono |
| ConsigneeName | Columna | foaf | name | Propiedad | Un nombre para alguna cosa |
| ConsigneePostCode | Columna | vcard | has_postal_code | Propiedad | Identifica el código postal |
| ConsigneeProvince | Columna | vcard | region | Propiedad | Identifica la provincia de una persona |
| ConsigneePhoneNumber | Columna | vcard | has_telephone | Propiedad | Identifica el teléfono |
En relación al diseño de los URI para identificar las prealertas en la red, se sigue un patrón que combina un prefijo común http://emci.correos.cu/ con las clases y propiedades del modelo ontológico, tal como se muestra en la Tabla 4.
Tabla 4 Patrón URI
| Descripción | Patrón | Ejemplo |
|---|---|---|
| Vocabulario | http://{uri-base}v/{project-name}/schema# | http://emci.correos.cu/operaciones/shema# |
| Clases | http://{uri-base}/{project-name}/schema#{class} | http://emci.correos.cu/operaciones/shema#Manifest |
| Propiedades | http://{uri-base}/{project-name}/schema#{property} | http://emci.correos.cu/operaciones/shema#has_number_of_package |
Etapa 3: Construcción del Espacio Informativo Semántico
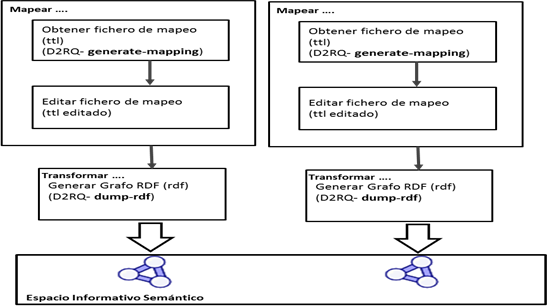
En esta etapa se transforman al formato RDF las fuentes de datos de las prealertas en formato XLS y las prealertas en formato XML. Dada la variedad en el formato, se decide primero transformar ambas fuentes a un formato relacional, para lo cual se utiliza como administrador de bases de datos Navicat 7. Se extraen en un fichero sql, sólo los campos que resultan de interés para el caso que se ejecuta.
Para la transformación se utiliza la plataforma D2RQ 8, herramienta que exporta el contenido de una base datos relacional a un grafo RDF . Para cada fuente de dato, se ejecuta el flujo de trabajo según se muestra en la figura 4, obteniéndose el correspondiente grafo RDF de cada fuente y dando lugar al Espacio Informativo Semántico.
Etapa 4: Construcción del Modelo LED
La actividad de enlazado se realiza con la herramienta Silk (Link Discovery Framework)9, herramienta para el descubrimiento de enlaces entre grafos RDF . Las relaciones seleccionadas para el enriquecimiento de los datos son: vcard:region, vcard:country_name, rdf:type. En la tabla 5, se presentan algunas de las tripletas enlazadas y sus relaciones.
Tabla 5 Ejemplo de Tripletas enlazadas
| <http://localhost:2020/resource/pack/9> | vcard:region | <http://localhost:2020/resource/paquete/CG910083211PA> |
| <http://localhost:2020/resource/pack/2> | vcard:country_name | <http://localhost:2020/resource/paquete/CG910085212PA> |
| <http://localhost:2020/resource/pack> | rdf:type | <http://localhost:2020/resource/paquete> |
La publicación del conjunto de datos resultante se publica con el almacén de tripletas Apache Jena Fuseki, que además proporciona un endpoint SPARQL, desde donde se pueden realizar consultas sobre las tripletas almacenadas.
En esta aplicación del enfoque LED no se enriquece el modelo LED con datos externos, quedando esto como recomendación para próximas aplicaciones.
Etapa 5: Explotación
Para el uso y exploración de la capa de datos enlazados se ha desarrollado una aplicación web, con el objetivo de mostrar de forma amigable, información adelantada sobre los envíos que deben recibirse por la empresa en un determinado período de tiempo. Las funcionalidades de una primera versión de la aplicación, de forma general son:
Datos informativos generales de la EMCI
Nombres y datos informativos de las Agencias u Operadores Internacionales
Volumen de operación Total (cantidad de bultos; cantidad de envíos; peso en kg) de un período determinado
Listar las provincias que deben recibir envíos en el período de un período determinado
Navegar por los Envíos de una Provincia de un período determinado
Volúmenes de operación previstos por Provincia.
IV. DISCUSIÓN
La aplicación del enfoque LED, a través del procedimiento, ha permitido integrar de forma factible la información de las prealertas procedente de orígenes distintos y con distintos formatos. Posibilitando obtener una herramienta informática que ofrece datos globales sobre los volúmenes de operación para un período determinado y facilita por tanto el proceso de planificación de los recursos para las operaciones en la planta. La mejor planificación de los recursos impacta positivamente en el cliente final de los servicios de mensajería y paquetería dado la mejoría que se obtiene en los tiempos de entrega de los envíos.
Para la EMCI, el enfoque LED abre el uso de las tecnologías semánticas en la empresa, lo cual incide en la problemática de integración de información, sin afectar el despliegue actual de aplicaciones y tecnologías informáticas en uso por la misma. Ello ha sido posible con la generación de una capa independiente de datos enlazados de prealertas provenientes de diferentes fuentes y con distintos formatos, quedando disponibles dichos datos para ser consumidos por otras aplicaciones, lo cual posibilita la obtención de nuevas informaciones para mejorar el proceso de toma de decisiones.
En general se han tenido que abordar algunas barreras que limitaban su aplicación, tales como:
Escasa cultura para acceder a los modelos de datos subyacentes a las aplicaciones informáticas.
Poca disponibilidad de conjuntos de datos externos relevantes al contexto empresarial para enlazar y enriquecer el modelo LED interno de la organización.
Para que el procedimiento sea gestionado habitualmente en la empresa, es preciso facilitar una adecuada gestión de conocimientos hacia el cliente interno sobre las herramientas y tecnologías que son esenciales en el procedimiento. Para habilitar este objetivo en un futuro cercano, se cuenta con un grupo de investigación de la empresa que ha estado inmerso en las bases conceptuales y prácticas que sustentan el procedimiento. Dicho grupo tiene la responsabilidad de desplegar las herramientas informáticas asociadas, así como ofrecer las capacitaciones en los niveles requeridos.
V. CONCLUSIONES
LED es un enfoque novedoso y actual para la integración de datos e información en el contexto empresarial. Su aplicación en la EMCI, ha permitido la integración de los datos de las prealertas, proporcionando datos globales para el proceso de planificación de las operaciones en la planta. Para lo cual se diseñó un procedimiento, que transita desde la identificación de las insuficiencias informacionales, el modelado, la construcción del espacio informativo semántico y del modelo LED, hasta la explotación.
La aplicación desarrollada proporciona a la empresa una nueva capacidad en relación a la gestión de información: analizar información adelantada para realizar una mejor planificación de los recursos según el volumen de operación que se prevé. Esta nueva capacidad, tributa directamente a mejorar los tiempos de entrega de los envíos, cumplimentando con los indicadores de calidad establecidos para la actividad postal. Se prevé la aplicación del enfoque LED en otras problemáticas de integración de la empresa, como por ejemplo la integración de datos relacionados con los operadores internacionales (contratos, facturación, etc).
El procedimiento puede ser aplicado en otras empresas que demanden también la integración de fuentes de datos heterogéneas. Como recomendación para trabajos futuros, se considera el tema de integrar los datos internos de la empresa con datos públicos en ese dominio de actuación.

