










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería Mecánica
versión On-line ISSN 1815-5944
Ingeniería Mecánica vol.14 no.2 La Habana Mayo-ago. 2011
ARTÍCULO ORIGINAL
Estudio comparativo de clasificadores empleados en el diagnóstico de fallos de sistemas industriales
A comparative study of clasification methods used in the fault diagnosis of industrial systems
José M. Bernal-de LázaroI, Alberto Prieto-MorenoI, Orestes Llanes-SantiagoI, Emilio García-MorenoII
I Instituto Superior Politécnico José Antonio Echeverría. Facultad de Ingeniería Eléctrica. La Habana. Cuba.
II Universidad Politécnica de Valencia. Departamento de Ingeniería de Sistemas y Automática. Valencia. España
RESUMEN
En este artículo se presenta un estudio comparativo del desempeño de cuatro de las técnicas de clasificación más usadas para el diagnóstico de fallos en procesos industriales. Dentro de las técnicas seleccionadas se encuentran los clasificadores Vecinos más Cercanos (VMC), Mínimos Cuadrados Parciales (MCP), Redes Neuronales Artificiales (RNA) y Máquinas de Soporte Vectorial (MSV). El estudio comparativo se realiza con el objetivo de determinar las técnicas con mayor capacidad para clasificar de forma correcta los patrones que identifican fallos en procesos industriales a partir de los datos históricos provenientes de los mismos. Para el estudio se utilizaron los datos obtenidos de la simulación del modelo del proceso industrial Tennessee Eastman. La comparación permitió comprobar cómo la capacidad de generalización de las técnicas de clasificación se incrementa con el aumento de la complejidad en los clasificadores sin que esto implique necesariamente un mayor esfuerzo computacional en el diagnóstico.
Palabras claves: procesos industriales, diagnóstico de fallos, mantenimiento industrial, máquinas de soporte vectorial, redes neuronales artificiales, mínimos cuadrados parciales, vecinos más cercanos.
ABSTRACT
This paper, presents a comparative study of the performance of four classification techniques very used in fault diagnosis of industrial processes. The selected techniques were: k-Nearest neighbor (k-NN), Partial least-squares (PLS), Artificial Neuronal Networks (ANN) and Support Vector Machines (SVM). The comparison is based in the classification capacity of the historical data and the generalization using new observations. The four techniques are applied to historical data of the known benchmark Tennessee Eastman industrial process. The comparison permitted to prove as the generalization capacity of the classification techniques grow with the complexity of classifiers without to increase the computational effort in the fault diagnosis.
Key words: industrial process, fault diagnosis, industrial maintenance, support vector machines, artificial neural networks, partial least-squares, k-nearest neighbor method.
INTRODUCCIÓN
En los últimos 30 años, el diagnóstico de fallos ha adquirido gran importancia debido a las ventajas potenciales que pueden obtenerse en la reducción de los costes de mantenimiento y reparación, el mejoramiento de la productividad y el aumento de la seguridad y disponibilidad de los procesos industriales. En este sentido, una rápida detección del problema puede ayudar a tomar decisiones correctivas y reducir el daño potencial que los fallos pueden ocasionar al sistema. Para estos casos, las técnicas de diagnóstico permiten mejorar no sólo la eficiencia del proceso, sino además, la operatividad, mantenibilidad y fiabilidad de dichos sistemas.
Al revisar la literatura propia de este tema, se pueden encontrar múltiples enfoques los cuales puede ser clasificados de manera general en métodos basados en modelos [1, 2] y métodos basados en datos históricos [3, 4].
Debido al avance de la automatización en la industria, los métodos basados en datos históricos adquieren una gran importancia por la elevada cantidad de información que existe de los procesos, almacenada en las bases de datos de los sistemas de supervisión, control y adquisición de datos (SCADA por sus siglas en inglés). Dado que existe una gran cantidad de métodos para el análisis de la información almacenada, es importante realizar un estudio comparativo entre las técnicas de clasificación más utilizadas históricamente para el diagnóstico de fallos en procesos industriales, y otras técnicas de reciente surgimiento con excelente desempeño en el reconocimiento de patrones. El objetivo es determinar las técnicas con mayor capacidad para clasificar de forma correcta patrones de fallos en los procesos industriales a partir del análisis de los datos históricos provenientes de los mismos. Lo anterior permitirá a los especialistas ganar en elementos para evaluar y decidir qué técnica utilizar a partir de la aplicación que se esté analizando.
Para realizar este estudio comparativo, se emplearon cuatro herramientas de clasificación muy difundidas en la literatura: Vecino más Cercano (VMC) [5], Mínimos Cuadrados Parciales (MCP) [3], Redes Neuronales Artificiales (RNA) [6, 7, 8, 9] y Máquinas de Soporte Vectorial (MSV) [10] y se utilizó el conocido caso de prueba Tennessee Eastman Process (TEP). [3]
La estructura de este artículo es la siguiente, en la sección 2 se aborda las características generales de los clasificadores usados para el diagnóstico. En la Sección 3 se presentan los elementos fundamentales del problema de prueba que se usa para evaluar el comportamiento de los clasificadores. En la sección 4 se realiza el análisis del desempeño de los diagnosticadores y finalmente se presentan las conclusiones y recomendaciones para trabajos futuros.
Clasificadores para el diagnóstico
Para lograr diagnosticar el estado actual de un proceso es necesario realizar tareas de clasificación. Para esto, un patrón de las variables representando la operación actual, es clasificado como: normal, defectuoso u operación desconocida. La clasificación involucra la comparación de los patrones actuales con los patrones que son representativos de cada uno de los fallos conocidos. De esta manera, se clasifica el patrón actual de acuerdo con el tipo de fallo con el que tiene mayor similitud.
El proceso de clasificación no es más que decidir a cuál de las clases disponibles pertenece un patrón determinado. Esto es, a partir de particionar el espacio característico de las observaciones en i = {1,..., p} preregiones mutuamente excluyentes, asignar la observación actual a la región que más se parece.
Desde el punto de vista del diagnóstico de fallos, el diagnosticador es un clasificador que asigna a un patrón específico una determinada etiqueta que identifica el estado de funcionamiento actual. Para lograr esto son necesarias dos etapas: aprendizaje y reconocimiento. Dada la disponibilidad de datos históricos, que reflejan todos los estados que se desean diagnosticar, el aprendizaje de los clasificadores seleccionados es conocido como aprendizaje supervisado.
A continuación se presentan las características fundamentales de 4 de los clasificadores utilizados en la literatura para el diagnóstico de fallos.
Vecino más cercano
La clasificación mediante este algoritmo es una de las primeras investigaciones que proporciona reglas basadas en métodos no paramétricos para la manipulación de un conjunto de datos. Actualmente, es una de las más utilizadas en reconocimiento de patrones, principalmente por su simplicidad conceptual y por la sencillez de su implementación [5]. La idea básica del método considera la utilización de un conjunto de patrones históricos como todo el conocimiento a priori del sistema. Esta regla basa su operación en el supuesto de considerar a los patrones cercanos, como aquellos que tienen la mayor probabilidad de pertenecer a la misma clase. El método común para realizar la búsqueda del vecino más cercano consiste en realizar la clasificación de un nuevo caso mediante el cálculo de la distancia entre y los patrones contenidos en el conjunto de datos históricos , guardando aquel que es más cercano hasta el momento. Al concluir el proceso se asigna la etiqueta correspondiente al patrón que obtuvo la menor distancia a g. Ver figura 1. Matemáticamente lo anterior se expresa como:
![]()
donde dist es cualquier medida de similaridad, g es la observación actual no evaluada por el clasificador, y xi es el conjunto de observaciones históricas con i = {1,..., n}. Entre las medidas de similaridad más frecuentes se encuentran: la Distancia Euclídea, la Distancia Manhattan y la Distancia Hamming. Para este trabajo se seleccionó la Distancia Euclídea por el bajo costo computacional, la sencillez de su implementación y los tipos de datos utilizados.

Mínimos Cuadrados Parciales
La herramienta de MCP puede ser considerada como una metodología matemática usada para establecer un modelo que relacione la información de dos conjuntos de datos que presentan una relación subyacente. El modelo de MCP encuentra las variables latentes que maximizan la covarianza entre dos conjuntos de datos X y Y o sea, la varianza explicada de X y Y, más la correlación entre X y Y [3].
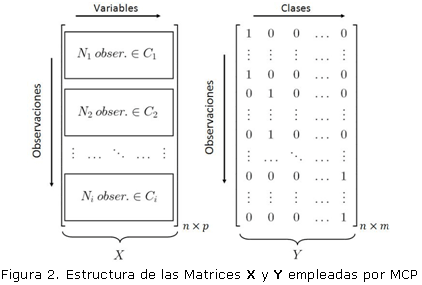
MCP como herramienta discriminante selecciona la matriz X ordenada de una forma particular, como se ilustra en la figura 2. Es decir, para p clases que representan diferentes estados de funcionamiento, las observaciones de cada clase se agrupan de forma tal que N1 representa las observaciones para el estado 1, N2 representa las observaciones para el estado 2 y así sucesivamente para el resto de los estados. Luego, para identificar la clase a la que pertenece una observación, se simula una matriz Y. Existen dos métodos conocidos como PLS1 y PLS2 [3], para modelar el bloque previsto Y. En PLS1, cada una de las p variables previstas es modelada separadamente, resultando en un modelo para cada clase. En PLS2, todas las variables previstas son modeladas simultáneamente tal como se ilustra en la figura 2.
Redes Neuronales Artificiales
Las RNA son herramientas de aprendizaje y procesamiento automático que imitan a las neuronas del cerebro humano, haciendo uso de modelos matemáticos que forman un sistema de procesamiento de información paralelo capaz de obtener soluciones adaptivas luego de sucesivas etapas de aprendizaje. Este conocimiento es captado mediante el ajuste de los parámetros libres de la red, concretamente de sus pesos, minimizando de forma simultánea el error existente entre la salida de la red neuronal y el objetivo asociado. Algunas características fundamentales de estos sistemas son su capacidad para generalizar la información y su tolerancia al ruido, razones por las cuales en el reconocimiento de patrones son consideradas herramientas efectivas para manejar datos incompletos, ambiguos e imperfectos. En adición, se puede decir que son computacionalmente eficientes y requieren de poca capacidad de memoria.
Las cualidades anteriormente descritas son aprovechadas para el diagnóstico, ya sea a través de la implementación de algoritmos de reconocimiento de patrones correspondientes a situaciones de fallos, o como sistema de evaluación de los residuos sensibles a los diferentes modos de fallo [6, 7]. En cualquiera de los dos casos, las etapas de aprendizaje y reconocimiento, se combinan para lograr el diagnóstico deseado.
Existen diversos algoritmos de aprendizaje y estos pueden clasificarse básicamente en dos grandes categorías: Aprendizaje supervisado y Aprendizaje no supervisado. En muchos casos, la propia arquitectura de la red seleccionada está directamente relacionada a un algoritmo de aprendizaje, dando lugar a un modelo de red neuronal. Entre estos, podemos destacar por su importancia y uso en el diagnóstico de fallos, las arquitecturas de Perceptrón Multicapa y la de Redes competitivas o de Kohonen [7, 8].
Adicionalmente, es posible encontrar aplicaciones en las que según el objetivo y el tipo de problema a resolver se empleen otras arquitecturas como las redes de base radial o las redes Hopfield. Siguiendo el criterios de los autores [8, 9], en cuanto a la capacidad de generalización y buenos resultados en el entrenamiento, se seleccionó como una tercera opción para llevar a cabo el experimento, una red "feedforward" con estructura multicapa
Máquinas de Soporte Vectorial
Los fundamentos teóricos de las MSV se encuentran en los trabajos de Vapnik sobre la teoría de aprendizaje estadístico [10]. Las MSV son consideradas algoritmos de cómputo emergente que han demostrado un excelente desempeño en aplicaciones de clasificación y regresión.
La idea que hay detrás de la clasificación binaria con MSV consiste en hallar una superficie de decisión que maximice la distancia m (margen) entre los patrones clasificados con el mínimo error de generalización. Por tanto, hallar el hiperplano de separación óptimo equivale a minimizar la norma euclídea de w que representa la distancia entre el hiperplano y las clases.
De manera que el problema de hallar el hiperplano equidistante a dos clases se reduce a encontrar la solución del siguiente problema de optimización con restricciones:
![]()
A diferencia de las ya conocidas RNA, las MSV implementan el principio de minimización del riesgo estructural (Rest) el cual busca minimizar un límite superior del error de generalización en lugar del principio de minimización de riesgo empírico (Remp ), que minimiza el error de entrenamiento usado en RNA. El Rest permite que las MSV logren una estructura de red óptima con un balance muy preciso entre el error empírico y el intervalo de confidencia o dimensión de Vapnik-Chervonenkis [10]. El funcional que debe minimizar la MSV es convexo con restricciones lineales, por ello su solución es única, sin mínimos locales a diferencia de las RNA que durante el entrenamiento requieren optimización no lineal, corriendo el riesgo de ser atrapadas por mínimos locales.
Cuando el conjunto de muestras etiquetadas no es linealmente separable, el objetivo será, transformar mediante funciones kernel los vectores de entrada xi de n-dimensiones en vectores de dimensión más alta donde las clases puedan ser linealmente separables. Ver figura 3.
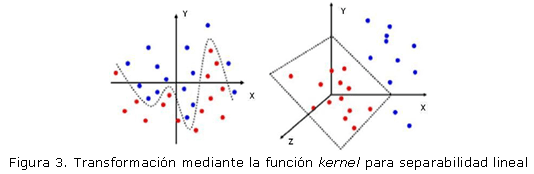
Algunas de las funciones kernel que frecuentemente son encontradas en la literatura son: kernel polinomial, kernel gaussiano y kernel sigmoidal.
Las MSV han sido aplicadas con éxito a un gran número de esferas técnicas [11, 12]. Recientemente se han publicado trabajos que incorporan las MSV al diagnóstico de fallos, tales como [13, 14, 15, 16, 17, 18], donde las MSV se estudian a partir de distintos enfoques. Otros trabajos como [19] muestran resultados prometedores en cuanto a la clasificación de patrones de fallos en procesos industriales complejos.
Descripción del problema de prueba
El modelo del proceso industrial de prueba (TEP) de Tennessee Eastman constituye un problema de control de una planta química hipotética que la compañía de Eastman Chemical desarrolló con el objetivo de evaluar técnicas de control de procesos y métodos de supervisión y diagnóstico. En la planta se representa un proceso químico formado por varias unidades de operación, entre ellas: un reactor, un condensador, un compresor, un generador de vapor, y un separador que se interconectan según indica el diagrama tecnológico de la figura 4. Los objetivos de control, sugerencias de aplicaciones potenciales y características de la simulación del proceso se describen con más detalle en [3].
En el proceso se obtiene un subproducto, F y dos productos, G y H, partiendo de cuatro reactivos: A, C, D y E, más un componente inerte B. La simulación de la planta proporciona un total de 52 variables: 22 variables de proceso, 19 variables de estado y 11 variables manipuladas. A partir de distintas perturbaciones al sistema, el TEP puede generar 21 tipos de fallos diferentes. El conjunto de datos usado para llevar a cabo los experimentos se presentan en la tabla 1.

Análisis del desempeño de los diagnosticadores
Herramientas para evaluar el desempeño del diagnosticador
Cada uno de los ocho conjuntos de datos de que se dispone, representa uno y sólo uno de los posibles estados de la planta que son los siete estados de fallo y el estado de funcionamiento normal (EFN). Estos conjuntos están formados por 480 valores muestreados que por las características del proceso son suficientes para asegurar la validez del análisis. Por lo anterior se decidió usar 240 muestras para entrenar y otras 240 muestras para realizar la validación de los diagnosticadores. La selección de las muestras se realiza de forma aleatoria de forma tal que al finalizar el proceso de selección, tendremos un total de 1920 observaciones de entrenamiento y 1920 observaciones de prueba que representan los ocho estados que se desean detectar.
Tanto en la etapa de aprendizaje como en la de validación, es necesario contar con elementos que permitan evaluar la eficiencia de los diagnosticadores. Para realizar este análisis, se emplean métodos conocidos como estimadores del error. Su objetivo es calcular la proporción de los patrones discriminados de forma incorrecta por el clasificador. Lo más común es utilizar la precisión general para evaluar el desempeño del mismo. No obstante, este criterio no debe ser el único empleado para cuantificar la eficiencia o no del diagnosticador. Para encontrar la precisión general, se hace uso de la media aritmética de los p patrones presentados para clasificar, teniendo en cuenta los e patrones correctamente clasificados:
![]()
A pesar de que este criterio de evaluación resulta sencillo en su principio e implementación, resulta poco adecuado por considerar de manera conjunta las precisiones individuales de las clases, por lo tanto se recomienda que sea acompañado por el análisis de la Matriz de Confusión [3]. Esta última, es ampliamente utilizada para la presentación y el análisis del resultado de una clasificación, por su capacidad de plasmar los conflictos entre las clases. La matriz de confusión, no sólo muestra el porcentaje correcto de clasificación, sino además la fiabilidad para cada una de las clases y las principales confusiones entre ellas.
En esta matriz, a lo largo de la diagonal principal, se indican los patrones que fueron clasificados de manera correcta. En la columna "Cant" se presenta el total de patrones de cada clase que fueron evaluados por el diagnosticador. La columna "% de Aciertos" (%A) indica el porcentaje de patrones asignados de forma correcta de esa clase.
Análisis de cada diagnosticador de forma individual
A continuación se presentarán los resultados del análisis realizado con cada una de las técnicas utilizadas para el diagnóstico de los fallos del TEP enunciados en la tabla 1.
Es necesario precisar que como se conoce, las técnicas de Mínimos Cuadrados Parciales, Redes Neuronales y Máquinas de Soporte Vectorial necesitan un entrenamiento previo para el ajuste de sus parámetros. Es por esta razón que en el caso de estas técnicas aparecerán dos matrices de confusión, una que evalúa el nivel de clasificación si se utiliza el conjunto de datos de entrenamiento y otra que evalúa el nivel de clasificación cuando se utiliza el conjunto de datos de validación.
Como en el caso de Vecinos más cercanos no hay entrenamiento previo solo se presenta la matriz de confusión del conjunto de datos escogidos para la validación.
Vecinos más cercanos 1-NN
El resultado que se presenta a continuación corresponde a la Regla de clasificación 1-NN implementada utilizando como función de similitud la Distancia Euclídea. Esta se seleccionó después de comprobarse que no había diferencias sustanciales en la clasificación cuando se usaban otros tipos de distancias o diferentes cantidades de vecinos lo cual aumentaba el tiempo de cómputo. Finalmente los resultados que se muestran en la tabla 2 corresponden a la clasificación de los datos durante la etapa de validación del diagnosticador.

Un enfoque individual de los resultados permite detectar que en los Fallos 3, 4 y 5 el error de la clasificación es muy elevado, llevando el porciento de acierto por debajo de 70%. En la fila uno correspondiente a dicha matriz, se refleja que el diagnosticador emite una clasificación tipo "Fallo" en un 63.33% cuando realmente no ha ocurrido ninguno.
Mínimos Cuadrados Parciales
El algoritmo de PLS2 empleado en este trabajo, corresponde a un método multivariado de regresión que es ampliamente utilizado para la clasificación de fallos en procesos industriales [7]. La tabla 3 presenta la Matriz de Confusión (MC) obtenida cuando se clasificó el conjunto de datos usados en el entrenamiento y la tabla 4 la MC cuando se clasificó el conjunto de datos seleccionados para la validación.


La precisión individual por clase, evidencia que cuando se clasificó el conjunto de datos de entrenamiento los estados que presentaron más dificultades en la clasificación fueron: el Estado Estable y el Fallo 3.
Al verificar la fila uno en la MC correspondiente a la validación (tabla 4) se determina que el diagnosticador continúa clasificando observaciones del Estado Funcionamiento Normal como Fallos cuando no ha ocurrido ninguno, sin embargo, como consecuencia de un incremento en la robustez, la cantidad de falsos fallos es menor que los emitidos por el diagnosticador anterior.
Redes Neuronales Artificiales
Para ejecutar la variante de RNA, se seleccionó una Red Feed-Forward con estructura multicapa y aprendizaje conocido como propagación del error hacia atrás. Como principio de diseño de la RNA, se decidió mantener un compromiso entre error de entrenamiento y capacidad de generalización, intentando que esta última fuese lo mayor posible. Se evaluaron varias arquitecturas de este tipo de red, obteniéndose los mejores resultados con la configuración de 7 neuronas en la capa oculta y 8 neuronas en la capa de salida que permite discriminar entre el EFN del sistema y 7 fallos. La tabla 5 presenta la MC obtenida al clasificar el conjunto de datos de entrenamiento y la tabla 6 muestra la MC resultante de la clasificación del conjunto de datos de validación.


El valor total de aciertos durante la clasificación con el conjunto de datos de entrenamiento es de 91,3%, lo que supone una mejor desempeño con respecto a MCP. Un estudio de la precisión individual por clase ilustra que el diagnosticador tiende a confundir el EFN con el Fallo 3, presentando una certeza de clasificación suficientemente elevada en el resto de los casos. Comparando ambas MC (Tabla 5 y 6) se refleja una similitud entre la clasificación correcta por clase cuando se utilizan los conjuntos de datos de entrenamiento y los de validación. Como resultado, el porciento de certeza del diagnosticador con el conjunto de datos de validación aumenta a un 87.40%, superando a los anteriores.
Máquinas de Soporte Vectorial
Tradicionalmente, cuando se realiza el desarrollo teórico de una Máquina de Aprendizaje, si ésta ha sido especialmente diseñada para casos binarios como las MSV, la solución a problemas que requieren clasificación de múltiples patrones, se aborda suponiendo que el mismo está formado por la fusión de clasificaciones binarias de menor tamaño. Este tipo de problemas puede resolverse empleando técnicas tales como 1 vs. 1 o 1 vs. all [10]. Para el caso en cuestión, se empleó la variante 1 vs. 1 situando L clasificadores del tipo MSV.
![]()
donde NC representa las clases a diagnosticar. Cada Máquina es entrenada con sólo dos de las NC implicadas, emitiendo un voto de clasificación. Por último se aplica una técnica de conteo de votos por mayoría simple que permite asignar la etiqueta de tipo Fallo a la clase que mayor número de votos obtuvo. Es importante destacar que se evaluaron varias funciones kernel para las MSV, obteniéndose los mejores resultados con un kernel gaussiano de base radial, cuyo parámetro varía de acuerdo a la naturaleza de los datos. La tabla 7 presenta la MC obtenida con la clasificación del conjunto de datos de entrenamiento y la tabla 8 muestra la MC de la clasificación del conjunto de datos de validación.

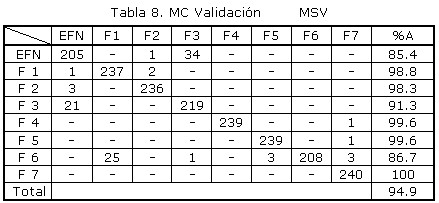
Los resultados de clasificación del conjunto de datos de entrenamiento son muy satisfactorios, con un 99.84% de acierto del diagnosticador. Igualmente altos, son los porcientos de clasificación para cada fallo individual durante esta etapa. A partir del análisis de la MC obtenida para la etapa de validación, el diagnosticador basado en MSV presenta una precisión individual para cada clase superior a los diagnosticadores anteriores. En cuanto a la robustez, se logra disminuir el porciento de clasificaciones erróneas en el EFN a un 14.6%. Adicionalmente, el número de fallos no detectados por ser considerados como EFN también disminuye.
Análisis conjunto
Posterior al análisis de los diagnosticadores de forma individual, se realiza un breve análisis de los resultados obtenidos de forma global. En la tabla 9 se muestra las respuestas de los diagnosticadores implementados respecto a la clasificación obtenida cuando se utilizó el conjunto de datos de entrenamiento y el conjunto de datos de validación respectivamente.

Como puede apreciarse, el clasificador VMC no presenta resultados con el conjunto de datos de la fase de entrenamiento. Esto se debe al principio de funcionamiento de este clasificador, el cual, para ser aplicado, no necesita una fase previa de estimación de parámetros.
Los resultados durante la etapa de validación de los diagnosticadores, refleja el poder de generalización de cada uno de ellos y la robustez frente a nuevas observaciones. En este caso, las MSV reflejan una mayor robustez que permite al diagnosticador realizar una mejor clasificación de patrones de fallos no vistos durante el entrenamiento.
CONCLUSIONES
En este trabajo se ha presentado una evaluación comparativa de las herramientas de clasificación: VMC, MCP, RNA y MSV. Para esta evaluación se estableció como criterio de comparación: la capacidad de clasificación y el poder de generalización. El estudio realizado mostró el poco poder de generalización que posee el clasificador basado en VMC, ya que, ante nuevas observaciones presentó un desempeño de un 65% de acierto en la clasificación. Por su parte, el clasificador basado en MCP mostró mejores resultados, pero solo alcanzó un 80% de acierto en las pruebas de generalización. Herramientas de clasificación más potentes, como lo son las RNA y las MSV, mostraron mejores resultados como lo demuestran el 87% y el 94% alcanzados por estos clasificadores respectivamente.
Este resultado valida la conveniencia de enfrentar los problemas de diagnóstico por medio de métodos de clasificación más potentes y elaborados, que permitan incrementar el poder de generalización de los sistemas de diagnóstico en procesos industriales. Es necesario destacar que, para los casos particulares de RNA y MSV, no se incrementa grandemente el costo computacional debido a que su complejidad radica en el entrenamiento, fase que se realiza fuera de línea y que no limita el desempeño del diagnosticador en línea.
A partir de los resultados obtenidos es necesario evaluar el comportamiento de estos clasificadores si previamente se aplican técnicas de reducción de datos como podrían ser el Análisis Discriminante de Fisher y Análisis de Componentes Principales. Además es necesario evaluar cuales serían los resultados si se utilizan varios métodos trabajando en forma cooperativa para enfrentar problemas en los que decrezca el porciento de clasificación correcto.
REFERENCIAS
1. Iserman, R. "Process Fault Detection Based on Modeling and Estimation Methods-A Survey". Automatica, 1984, vol. 20, nº. 4, p. 387-404. ISSN 0005-1098+
2. Iserman, R., Ballé, P. "Trends in the Application of Model-Based Fault Detection and Diagnosis of Technical Processes". Control Engineering Practice, 1997, vol. 5, nº. 5, p. 709-719. ISSN 0967-0661
3. Chiang, H. L., Russel, E. y Braatz, D. R. Fault Detection and Diagnosis in Industrial Systems. 1st Edition, Ed. Springer, 2001, 279 p., ISBN 978-1-85233-327-0.
4. Venkatasubramanian, V., Rengaswamy, R. y Kavury, N. S. "A Review of Process Fault Detection and Diagnosis - Part III". Computers & Chemical Engineering, 2003, vol. 27, pp. 327-346. ISSN 0098-1354
5. Cover, M., Hart, P.E. "Nearest neighbour pattern classification". IEEE Transaction on Information Theory, 1967, vol. 13, nº. 1, p. 21-27. ISSN 0018-9448
6. Sorsa, T., Koivo, N. H. "Application of artificial neural networks in process fault diagnosis". Automatica, 1993, vol. 29, nº. 4, p. 843-849. ISSN 0005-1098
7. Demetgul, M., Tansel, I.N. y Taskin, S. "Fault diagnosis of pneumatic systems with artificial neural networks algorithms". Expert Systems with Applications, 2009, vol. 36, nº. 7, p. 10512-10519. ISSN 0957- 4174
8. Patan, K. Artificial neural networks for the modeling and fault diagnosis of technical processes. Ed. Springer, 2008, 206 p., Series Lecture Notes in Control and Information Sciences, ISBN 3540798714
9. Graupe, D. l. Principles of Artificial Neural Networks. 2nd Edition, Ed. World Scientific Publishing, 2007, 319 p.
10. Vapnick, N. V. Statistical Learning Theory. Ed. John Wiley, 1998.
11. Shih, P. y Liu, C. "Face detection using discriminating feature analysis and Support Vector Machine". Pattern Recognition, 2006, vol. 39, nº. 2, p. 260-276. ISSN 0031-3203
12. Drucker, H., Wu, D. y Vapnick, N. V. "Support Vector Machines for Spam Categorization". IEEE Transactions on Neural Networks, 1999, vol. 10, nº. 5, p. 1048-1054. ISSN 1045-9227
13. Kulkarni, A., Jayamaran, V. K. y Kulkarni, B.D. "Knowledge incorporated support vector machines to detect faults in Tennessee Eastman Process". Computers & Chemical Engineering, 2005, vol. 29, nº. 10, p. 2128-2133. ISSN 0098-1354
14. Davy, M., Desobry, F., Gretton, A. et al. "An online support vector machine for abnormal events detection". Signal Processing, 2006, vol. 86, nº. 8, p. 2009-2025. ISSN 0165-1684
15. Hongdong, L., Liang, Y. y Xu, Q. "Support vector machines and its applications in chemistry". Chemometrics and Intelligent Laboratory Systems, 2009, vol. 95, nº. 2, p. 188-198. ISSN 0169-7439
16. Kurek, J. y Osowski, S. "Support vector machine for fault diagnosis of the broken rotor bars of squirrel-cage induction motor". Neural Computing & Applications, 2010, vol. 19, nº. 4, p. 557-564. ISSN 1433-3058
17. Fang, R. "Induction machine rotor diagnosis using support vector machines and rough set". Lecture Notes in Computer Sciences, 2006, vol. 4114, p. 631-636. DOI: 10.1007/978-3-540-37275-2_78
18. Horng-Yuan, W., Chin-Yuan, H., Tsair-Fwu, L., et al. "Improved SVM and ANN in incipient fault diagnosis of power transformers using clonal selection algorithms". International Journal of Innovative Computing, Information and Control, 2009, vol. 5, nº. 7, p. 1959-1974. ISSN 1349-4198
19. Mahadevan, S. y Shah, L. S. "Fault detection and diagnosis in process data using one-class support vector machines". Journal of Process Control, 2009, vol. 19, nº. 10, p. 1627-1639. ISSN 0959-1524
Recibido: 3 de agosto de 2010.
Aceptado: 25 de marzo de 2011.
José M. Bernal-de Lázaro. Instituto Superior Politécnico José Antonio Echeverría. Facultad de Ingeniería Eléctrica. La Habana. Cuba.
Correo electrónico: jose.b@feestudiantes.cujae.edu.cu

{kind=link}