










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkIngeniería Mecánica
versión On-line ISSN 1815-5944
Ingeniería Mecánica vol.20 no.2 La Habana may.-ago. 2017
Artículo Original
Ajuste posinomial combinando Enjambre de Partículas y Métodos de Programación No-lineal
Posynomial fitting combiding Particle Swarm and Nonlinear Programming Methods
Nabote António-MagaiaI, Isidro Luis Alemán-RomeroII, José Arzola-RuizII, Osmel Martínez-ValdésIII
IInstituto Superior Politécnico de Songo. Tete. Mozambique
IIUniversidad Tecnológica de La Habana. Centro de Estudios de Matemática. La Habana. Cuba
IIIEmpresa Acinox Ingeniería S.A. La Habana. Cuba
RESUMEN
El desempeño de los métodos determinísticos de programación no-lineal es altamente sensible de la selección de la aproximación inicial, en particular cuando se trata de la obtención de un óptimo global, como es requerido en el ajuste posinomial. El presente trabajo tuvo como objetivo, generar la aproximación inicial a través de la metaheurística enjambre de partículas, para mejorar el desempeño de los métodos de programación no-lineal en el ajuste posinomial. A partir de pruebas no paramétricas que se realizaron para la comparación de los resultados obtenidos en los problemas considerados, se observó que las diferencias existentes entre los resultados del ajuste posinomial, con y sin la aplicación de la propuesta de mejora, son significativas. Además, se constató que la metodología de mejora desarrollada permite obtener un buen desempeño de los métodos de programación no-lineal en el ajuste posinomial, lo que redunda en la obtención de modelos posinomiales de calidad.
Palabras claves: ajuste posinomial, programación no-lineal, optimización por enjambre de partículas, programación geométrica.
ABSTRACT
The performance of deterministic methods of nonlinear programming is highly sensitive to the selection of the initial approximation, particularly when it comes to obtaining an overall optimum, as required in the posyinomial fitting. The present work aimed to generate the initial approximation through of particle swarm metaheuristic, to improve the performance of non-linear programming methods in posyinomial fitting. From the non-parametric tests performed for the comparison of the results obtained in the considered problems, it was observed that the differences between the results of the posyinomial fitting, with and without the application of the improvement proposal, are significant. In addition, it was found that the improvement methodology developed allows to obtain a good performance of the non-linear programming methods in the posynomial fitting, which results in the obtaining of quality posynomial models.
Key words: posynomial fitting, nonlinear programming, particle swam optimization, geometric programming.
INTRODUCCIÓN
El problema de ajuste posinomial constituye una tarea de optimización no-lineal y no convexa y, por lo tanto, no se garantiza la obtención del óptimo global [1]. La calidad de ajuste posinomial a través de los métodos clásicos (determinísticos) de programación no-lineal (PNL), depende de la aproximación inicial y, desafortunadamente, no existe una forma clara para determinarla. Por otra parte, aunque se considere un espacio amplio de búsqueda, la metaheurística enjambre de partículas permite identificar soluciones próximas al óptimo global, por lo que su utilización en la generación de la aproximación inicial para los métodos de PNL, posibilita una rápida convergencia a soluciones aceptables. Por tanto, la combinación de estos dos métodos mejora el desempeño de los métodos de PNL y, consecuentemente, la calidad de ajuste posinomial. Los posinomiales obtenidos se pueden utilizar con carácter predictivo y en la formulación de problemas de la Programación Geométrica (PG), que tienen muchas aplicaciones en la ingeniería [2, 3].
El ajuste posinomial mediante el empleo de métodos de PNL, se desarrolla en [1], donde se minimiza la suma de cuadrados de los errores relativos. Entre los métodos de PNL más utilizados se encuentran: Gauss-Newton, Quasi-Newton y programación cuadrática secuencial (PCS). En el enfoque propuesto en [1], se propone solucionar el problema de ajuste posinomial mediante la generación aleatoria de varias aproximaciones iniciales y, posteriormente, se selecciona el posinomial que brinde la mejor aproximación [1, 4]. Para determinar las aproximaciones iniciales, primero se realiza un ajuste monomial preliminal, y luego se perturban sus exponentes y su coeficiente de forma aleatoria y, posteriormente, se considera la combinación lineal de los monomiales generados. Además de la cantidad de tiempo que esta estrategia requiere, no se garantiza el logro del óptimo global [4].
Otro enfoque local de ajuste posinomial se basa en la combinación de los algoritmos genéticos (AG) y la programación cuadrática (PC) [5], pero a expensa de un alto costo computacional. Se hace necesario utilizar técnicas modernas que disminuyan el tiempo computacional y que logren buenos resultados, por lo que se decide utilizar la metaheurística enjambre de partículas, que ha brindado buenos resultados en numerosas aplicaciones.
Debido a complejidad de los problemas de ajuste posinomial, es frecuente la utilización de conjuntos de funciones monomiales, o bien, funciones max-monomiales para ajustar funciones convexas [6]. Para mejorar el error de ajuste por funciones max-monomiales, se utilizan en [7] técnicas estadísticas.
Del análisis anterior se constata que los enfoques desarrollados para el ajuste posinomial son locales y se basan en los métodos clásicos de PNL y en las técnicas heurísticas. La calidad de ajuste posinomial a través de los métodos clásicos de PNL, depende de la elección de la aproximación inicial para comenzar el proceso de búsqueda de los parámetros. Sin embargo, en la literatura estudiada no existe una forma clara para determinar una prometedora aproximación inicial para los métodos de PNL.
El objetivo de este artículo es generar una aproximación inicial a través del algoritmo de Optimización por Enjambre de Partículas (OEP) para mejorar el desempeño de los métodos clásicos de PNL en el ajuste posinomial.
Para lograr este propósito, se supone que si se utiliza el algoritmo de OEP para generar el punto de partida para iniciar los métodos de PNL, se podrá mejorar el desempeño de estos métodos y, consecuentemente, la calidad de ajuste posinomial.
Para la generación de la aproximación inicial, se implementa computacionalmente en Matlab, el algoritmo de OEP. Con respecto a los métodos de PNL, se usan las funciones fmincon, fminunc y fminsearch del Matlab, con condiciones impuestas para implementar los métodos de PCS, Quasi-Newton y Simplex, respectivamente.
Se aplican los métodos estadísticos para comparar los resultados de ajuste posinomial, con y sin la aplicación del algoritmo de OEP. Además, se realiza el diseño factorial 34 para obtener los datos que, posteriormente, se ajustan por modelos posinomiales, en el proceso de descripción de los comportamientos de la Eficiencia energética (Ef), Caudal másico (CM) y Temperatura de la zona de pirolisis (TZ), en una instalación experimental de gasificación tipo downdraft.
Se consideran dos ejemplos prácticos, donde se realiza el ajuste posinomial, con y sin la aplicación de la metaheurística. El primer ejemplo se corresponde con el problema de determinación de un modelo posinomial que sustituya al procedimiento de cálculo de la temperatura externa de una pared refractaria. El segundo es de determinación de modelos posinomiales que describan los comportamientos de Ef, CM y TZ. Se realiza la comparación directa de los mejores resultados obtenidos y se observa que la combinación propuesta en el trabajo brinda los mejores resultados de ajuste posinomial. Además, se evidencia, a través de las pruebas no paramétricas de Mann-Whitney, que las diferencias entre los errores obtenidos, son significativas.
En el trabajo, se constata que la generación de la aproximación inicial a través del algoritmo de OEP mejora el desempeño de los métodos de PNL en el ajuste posinomial
MÉTODOS
Considerando que no existe una forma clara para determinar la aproximación inicial en la aplicación de los métodos de PNL en el ajuste posinomial, en este trabajo se pretende analizar el desempeño de estos métodos cuando se considere el algoritmo de OEP para generar la aproximación inicial. Para la realización de esta tarea, se requiere la selección del criterio de proximidad entre las funciones aproximada y aproximante, la implementación del algoritmo de OEP, la especificación de los métodos de PNL a considerar y, por el último, la técnica para la validación de los resultados obtenidos.
La investigación se realiza mediante la combinación de algunos métodos de la investigación teórica y el diseño factorial 34. Se emplea el método de Análisis - Síntesis consistente en el estudio pormenorizado y la descomposición de las teorías sobre el ajuste posinomial. El método Hipotético – Deductivo se emplea para la formulación y la demostración de la hipótesis de investigación a partir de la comparación de los resultados obtenidos. Para la comparación de los resultados se utilizan las pruebas no paramétricas pues, a priori los resultados no siguen ningún tipo de distribución de probabilidad. Se plantean las siguientes hipótesis Ho y H1:
H0: μ1 = μ0
No existen diferencias significativas entre los errores de ajuste posinomial que se obtienen a través de métodos de PNL, con y sin el empleo del algoritmo de OEP para generar la solución inicial.
H1: μ1 ≠ μ0
Existen diferencias significativas entre los errores de ajuste posinomial que se obtienen a través de métodos de PNL con y sin el empleo del algoritmo de OEP para generar la solución inicial.
La regla de decisión consiste en rechazar la hipótesis nula si el valor de la probabilidad asociada es menor que el nivel de significación de la prueba α = 0,05
Con el objetivo de obtener los datos que describan los comportamientos de las variables Ef, CM y TZ, se realizó un diseño factorial 34. Se consideró el análisis de estos tres rendimientos independientes y se tomaron 3 réplicas y 4 factores, denominados: Poder calórico de la biomasa (PC), Humedad de la biomasa (HB), Apertura de la válvula de aire (AV) y la Cantidad de biomasa (CB). Para las variables independientes PC, HB, AV y CB se asumieron los valores de los siguientes conjuntos {4000, 13800, 19000}, {12, 16, 20}, {25, 50, 100} y {1, 3, 5}, respectivamente.
El control local, se garantizó por el medio del control visual, donde se empleó un observador experimentado para verificar el cumplimiento de las operaciones previstas, según lo establecido a través de un checklist.
Ahora bien, para la realización de la tarea de aproximación de funciones, se debe especificar la estructura matemática de la clase de funciones candidatas. En este trabajo, las funciones de aproximación elegidas son los monomiales y posinomiales. Los monomiales se corresponden con la siguiente estructura matemática:
Los posinomiales son modelos matemáticos de la forma:
 (2)
(2) Existen varias normas para establecer la proximidad entre las funciones original y la aproximante g. En el presente trabajo, la proximidad entre y g se instituye a través de la siguiente función:
 (3)
(3) Los métodos de PNL que se consideran para el ajuste posinomial son los implementados en las funciones fmincon, fminunc y fminsearch del Matlab. Para el análisis de los resultados, se consideran dos problemas: el primero es de determinación de un modelo posinomial con dos variables, que sustituya al procedimiento de cálculo de la temperatura externa de una pared refractaria; el segundo es de determinación de modelos posinomiles que describan el comportamiento de tres salidas independientes (Ef, CM, TZ), donde cada una de ellas depende de cuatro entradas (PC, HB, AV, CB), en una instalación experimental de gasificación de biomasa tipo downdraft.
Para la validación de los resultados, se comparan los resultados de ajuste posinomial, con y sin la aplicación de la metaheurística, de los datos correspondientes a los dos problemas anteriormente descritos.
La implementación computacional del algoritmo de OEP, se realizó en Matlab. A continuación se explican y se presentan las componentes de la variante del algoritmo de OEP, que se consideró en este trabajo.
Optimización por enjambre de partículas
El algoritmo de OEP es una metaheurística que frecuentemente se utiliza en la optimización global. Fue desarrollado por Kennedy y Eberhart (1995) y está inspirado en el movimiento colectivo de bandadas de pájaros, cardúmenes de peces o enjambre de abejas. Se desarrollaron varias variantes de OEP para asegurar la convergencia, la estabilidad y el desempeño de esta metaheurística. La convergencia y la estabilidad de OEP estándar dependen de factores tales como la dimensión del problema y la variante de OEP que se considere [8]. Otros factores importantes que influyen en la convergencia del algoritmo de OEP y en la calidad de las soluciones que este método brinda, son la inercia y el tipo de función de distribución de probabilidad que se utilice para la generación aleatoria de los vectores diagonales que multiplican las componentes social y cognitiva, en la ecuación de velocidad de las partículas [9]. Por tanto, se desarrollaron muchos estudios para la mutación de los operadores en la ecuación de actualización de la velocidad de las partículas. Otros estudios indican que para ciertos problemas, la variante de OEP que utiliza los pesos exponenciales para la inercia, ofrece mejores resultados que el uso de pesos lineales [10]. Por otra parte, la estrategia que se use para lograr una mayor diversidad de la población en el algoritmo de OEP, también tiene un papel importante en calidad de las soluciones [11].
En este trabajo se considera la variante del algoritmo de OEP modificado y que utiliza los pesos de la inercia como una función lineal y decreciente [12]. La ecuación que describe la actualización de la velocidad de las partículas es dada por:
Donde, w es el peso de inercia, c1 y c2 son coeficientes positivos de ponderación. El parámetro w sirve de balance entre la capacidad de búsqueda global y local. Mientras mayor sea el valor de w se facilita la búsqueda global, y en caso contrario la búsqueda local. Los coeficientes c1 y c2 se introducen para asegurar la convergencia del algoritmo de OEP. Los términos rand1(0,1) y rand2(0,1) son funciones para generar números aleatorios entre cero y uno. La partícula i y su velocidad en la iteración n, se representan por ![]() y
y ![]() respectivamente. La representación pbesti se corresponde con la anterior mejor ubicación de las partículas, mientras que gbest es la posición de la mejor partícula, es decir, la partícula que ofrece el menor valor de la función objetivo.
respectivamente. La representación pbesti se corresponde con la anterior mejor ubicación de las partículas, mientras que gbest es la posición de la mejor partícula, es decir, la partícula que ofrece el menor valor de la función objetivo.
La relación (4) está compuesta por tres términos: el primero ![]() es referente a la inercia; el segundo
es referente a la inercia; el segundo ![]() es la parte cognitiva, que representa el autoaprendizaje a partir de la propia experiencia del vuelo; el tercero y último
es la parte cognitiva, que representa el autoaprendizaje a partir de la propia experiencia del vuelo; el tercero y último ![]() , es la componente social, que representa la colaboración en el aprendizaje de las partículas en las experiencias de vuelos colectivos. La dinámica de las trayectorias del vuelo de las partículas se presenta por la relación (5):
, es la componente social, que representa la colaboración en el aprendizaje de las partículas en las experiencias de vuelos colectivos. La dinámica de las trayectorias del vuelo de las partículas se presenta por la relación (5):
La función que se corresponde con la mutación del factor peso de inercia es dada por la siguiente relación:
Donde, wmin y wmax son los valores mínimo y máximo del peso de inercia. Los parámetros n y N representan la iteración y el número total de iteraciones prefijadas, respectivamente.
Para la generación de aproximaciones iniciales a través del algoritmo de OEP, en este trabajo se considerarán 600 iteraciones, 30 corridas y los factores de peso se corresponden con los siguientes valores: w1=0,001, w2=0,03 y c1=c2=2
Ahora se presenta el problema de ajuste posinomial y, posteriormente, se formula como una tarea de optimización no convexa.
Ajuste posinomial
Se supone que se conocen los puntos (X(i), f(i)), i=1,2,...,N donde x(i) Є Rn son vectores positivos y ƒ(i) son constantes positivas. El problema de ajuste posinomial consiste en determinar los valores de los coeficientes Ck>0 y de los exponentes a1k, a2k,...,ank tales que,
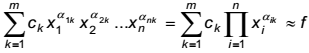 (7)
(7) El problema (7) se puede abordar de varias formas [13]. Una de las más empleadas se basa en transformaciones logarítmicas de las funciones involucradas de modo que se minimice la norma de la diferencia de dos funciones logarítmicas, es decir, se optimiza el siguiente problema:
Ahora bien, a partir de las propiedades de los posinomiales, el logaritmo de la suma de los exponenciales es una función convexa [13]. Sin embargo, en general el problema (8) no es convexo [2] y los métodos determinísticos que frecuentemente se utilizan para solucionarlo son locales y requieren de una buena aproximación inicial para que brinden soluciones aceptables [2]. En el enfoque de determinación de modelos posinomiales a partir de la perturbación de los exponentes del primer monomial generado, no se puede lograría un vector de exponentes nulos, constituyendo una restricción que afecta la estructura física del modelo posinomial y, por lo tanto, se puede perder informaciones en el proceso de ajuste de datos. Para evitar este problema, en este trabajo se propone añadir un parámetro no negativo en el modelo posinomial estándar, de tal forma que se optimice el siguiente problema:
Para solucionar el problema (9) a partir de los métodos clásicos de PNL, se toman como puntos iniciales los vectores que se obtienen a partir de la perturbación de los parámetros del primero monomial generado. Es decir, se construye un posinomial inicial a partir de la combinación lineal de los monomiales previamente generados y, todos ellos, próximos al primero obtenido [1]. El primer monomial se puede lograr fácilmente a través del método de mínimos cuadrados, tras la realización de transformaciones logarítmicas de las funciones involucradas.
Para la discusión y comparación de los resultados de ajuste posinomial a través de métodos de PNL, con y sin la utilización del algoritmo de OEP para generar la aproximación inicial, se consideran los dos ejemplos referidos con anterioridad y que se describen a continuación:
Ejemplo 1. Se considera el problema de la determinación del modelo posinomial que se aproxime al procedimiento de cálculo de la temperatura externa de una pared refractaria de un horno. La temperatura externa (Text) de la pared se considera como una función que depende del espesor de su primera capa (S) y de la temperatura interna (Tint). Para la generación de la base de datos, se considera la información de la tabla 1:
A partir del procedimiento de cálculo de la distribución de la temperatura en la pared, se genera un fichero de datos compuesto por 360 puntos, que se logran al fijar las variaciones ΔTint = 20ºC y ΔS = 6 mm, donde Tint y S varían de 1020 0C a 1300 0C y 108 mm a 246 mm, respectivamente. Una vez que se logra la base de datos, la tarea consiste en buscar un modelo posinomial para estimar Text como una función que depende de S y Tint.
Ahora bien, para la descripción del comportamiento de la temperatura externa a partir de modelos posinomiales, se seleccionó un posinomial con tres términos. A continuación se presenta la tabla de los resultados del ajuste posinomial a través de los métodos de PNL, con y sin la aplicación de la metaheurística:
El mejor modelo posinomial que se obtuvo ofrece un error de 1,3697, explica 99,78 % de la variabilidad de la temperatura externa y se corresponde con la siguiente expresión analítica:
![]()
Ejemplo 2. Ahora se considera el problema de determinación de un modelo matemático que describa los indicadores de desempeño de una instalación experimental de gasificación tipo downdraft. Con este fin, se realiza un experimento 34, con 3 réplicas y, por lo tanto, se realizan 243 experiencias. Así, se buscan modelos posinomiales para ajustarlos comportamientos de las siguientes salidas independientes: Eficiencia energética (Ef), Caudal másico (CM) y Temperatura de la zona de pirólisis (TZ). Las variables independientes del proceso son: Poder calórico de la biomasa (PC), Humedad de la biomasa (HB), Apertura de la válvula de aire (AV) y la Cantidad de biomasa (CB).
Para la descripción del comportamiento de la eficiencia se considera un posinomial con 4 términos, mientras que para CA y TZ, se seleccionan los modelos posinomiales con tres términos. A continuación se presentan los resultados del ajuste posinomial a través de los métodos clásicos, con y sin la aplicación del algoritmo de OEP para generar las aproximaciones iniciales, para las tres variables de salidas:
El mejor modelo que se logró ofrece un error de 0.0457, con el coeficiente de determinación múltiple R2 = 99.32% y se corresponde con la siguiente expresión matemática:
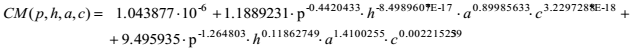
Donde, p, h, a y c representan PC, HB, AV y CB, respectivamente.
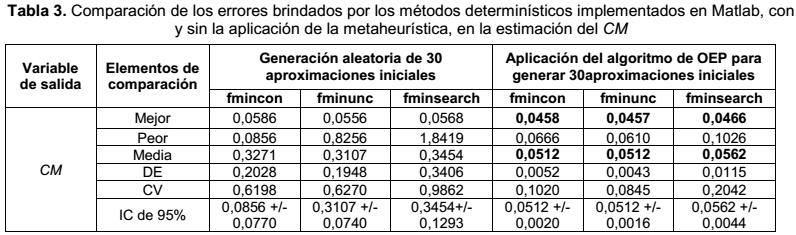
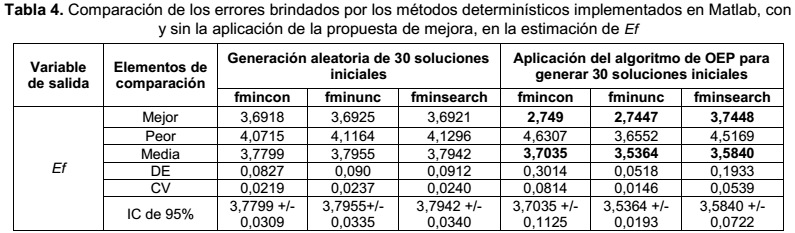
A continuación se presenta la tabla de comparación de los errores brindados por los métodos determinísticos, con y sin la aplicación de la propuesta de mejora, en la estimación de Ef.
El modelo posinomial que se logró brinda un error de 2.7447, explica 83.28% de variabilidad de la eficiencia y tiene la siguiente expresión analítica:

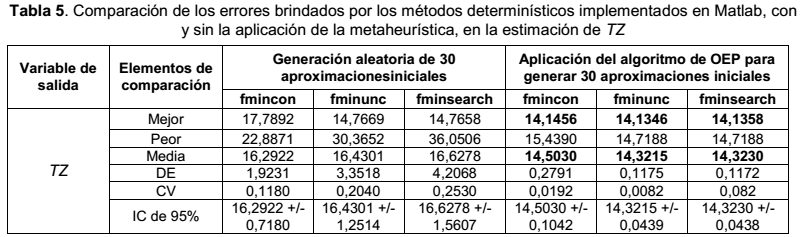
Se presenta la tabla de comparación de los errores brindados por los métodos determinísticos, con y sin la aplicación de la propuesta de mejora, en la estimación de TZ.
El modelo posinomial que se logró ofrece un error de 14.1346, R2 = 70.05 y se corresponde con la siguiente expresión analítica:
![]()
RESULTADOS Y DISCUSIÓN
Al aplicar las pruebas no paramétricas de Mann-Whitney, se observó que las diferencias en las tablas 2, 3, 4 y 5, entre los errores de ajuste posinomial obtenidos, con y sin la aplicación de la metaheurística, son significativas. A este resultado se arriba, empleando el software SPSS Statistics, al observar que el valor de la probabilidad asociada fue menor que el nivel de significación de la prueba α = 0,05 en todos los ejemplos considerados. Lo anterior conlleva a que se debe rechazar la hipótesis nula en todos los problemas aquí tratados, o sea, hay evidencias estadísticas suficientes para rechazar la idea de que no existen diferencias significativas entre los errores de ajuste posinomial, obtenidos con y sin la aplicación de la metaheurística, con un nivel de confianza de 95 %. En las tablas 6 a la 9 se presentan los resultados de las pruebas no paramétricas de Mann – Whitney en el análisis de los errores que se generaron a través de las funciones fminsearch y fmincon, con y sin la aplicación de la metaheurística, en la estimación de CM y de Ef:

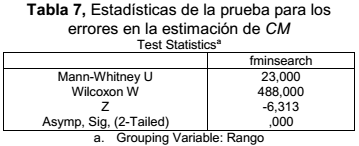


Se observa en las tablas 7 y 9 que el valor de la probabilidad asociada es menor que 0.05, lo que significa que se debe rechazar la hipótesis nula.
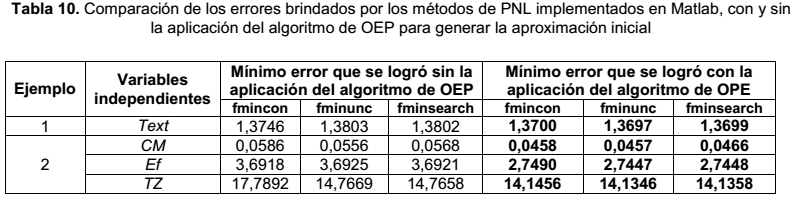
Ahora se ofrece una tabla de resumen de los mejores resultados de ajuste posinomial, que se lograron en cada uno de los problemas considerados:
A partir de la tabla 10, se observa que cuando se utiliza el algoritmo de OEP para determinar la aproximación inicial para los métodos de PNL, se logran menores errores de ajuste, que los que se obtienen mediante la generación aleatoria de aproximaciones iniciales. Este resultado fortalece la idea de que la generación de la aproximación inicial a través del algoritmo de OEP mejora el desempeño de los métodos de PNL en el ajuste posinomial.
En el trabajo de Xue [4] en el ejemplo de la pagina 59 se realizó una aproximación monomial y se logró un error máximo de 0,1180, mucho mayor que 0,0324, que se obtuvo con la aplicación de la metodología desarrollada en este trabajo.
En el trabajo de Hoburg y Abbeel [14], al aproximar la función del ejemplo 6.1 por una función max-monomial con 2 términos, se logró un error de 0,0052 mostrado en la tabla 1. Por otra parte, con el empleo de la metodología propuesta en este trabajo se logró un posinomial con dos términos que ofreció un error de 0.0039.
La metodología desarrollada permite aprovechar:
- La capacidad de exploración del algoritmo de OEP para lograr un acercamiento al optimo global del ajuste posinomial, que se toma como aproximación inicial para los métodos de PNL, es decir, la metaheurística enjambre de partículas asume el papel de método predictor.
- La capacidad de acercamiento de los métodos de PNL para lograr el mejoramiento de la aproximación inicial dada, que redunda en la obtención de modelos de ajuste posinomial de calidad, es decir, los métodos de PNL asumen el papel de métodos correctores.
En caso de no obtenerse una mejoraría al aplicar los métodos de PNL, esto indicaría que la solución obtenida mediante el algoritmo de OEP puede ser de buena calidad. Un mejoramiento adicional se podría lograr variando el parámetro w (peso de inercia) del algoritmo de OEP, lo que conllevaría a emplear este algoritmo a su vez como un método corrector. Al mismo tiempo, todo lo anterior incentiva a investigar otras metaheurísticas en un papel de método corrector y/o predictor.
Los modelos posinomiales, desarrollados por intermedio de la metodología descrita, se pueden aplicar en la aproximación de funciones log-log-convexas y en el ajuste de datos empíricos o de simulaciones tipo caja negra. Además se pueden utilizar para la realización de predicciones y para modelar y solucionar los problemas de optimización no-lineal y no convexa mediante la aplicación de la PG.
CONCLUSIONES
Presentado en el trabajo el algoritmo de OEP y se consideró como complemento de los métodos clásicos de PNL en el ajuste posinomial. El algoritmo de OEP logra identificar aproximaciones iniciales de muy buena calidad para iniciar los métodos de PNL, lográndose mejores resultados de ajuste posinomial, que los obtenidos tomando aproximaciones iniciales aleatorias. Resultó que la generación de la aproximación inicial a través del algoritmo de OEP mejora el desempeño de los métodos de PNL en el ajuste posinomial.
REFERENCIAS
1. Boyd S, Kim S, Vandenberghe L, et al. A tutorial on Geometric Programming. Optimization and Engineering. 2007;8(1):67-127.
2. Hobug W, Abbel P. Geometric programming for aircraft design optimization. AIAA Journal. 2014;52:1-13.
3. Boyd S, Kim S, Patil D, et al. Digital Circuit Optimization via Geometric Programming. Operations Research. 2005;53(6):899-932.
4. Xue X. Electronic Systems Optimization Design via GP-Based Surrogate Modelling. North Carolina, USA: North Carolina State University; 2012. [Citado: julio de 2016] Disponible en: http://repository.lib.ncsu.edu/ir/bitstream/1840.16/7710/1/etd.pdf
5. Aggarwal V, O´Reilly U. Simulation - Based Reusable Posynomial Models for MOS Transistor Parameters In: Design, Automation and Test in Europe Conference and Exhibition; Nice, Francia: Date-Conference.com; 2007. [Citado julio de 2016] Disponible en: https://www.date-conference.com/proceedings-archive/PAPERS/2007/DATE07/PDFFILES/01.5_1.PDF
6. Kim J. Convex piecewise-linear modeling method for circuit optimization via geometric programming. IEEE Transactions Computer-Aided Design of Integrated Circuits and Systems. 2010;29(11):1823-7.
7. Hannah A, Dunson B. Multivariate convex regression with adaptive partitioning. Journal of Machine Learning Research. 2013;14:3261-94.
8. Bonyadi M, Michalewicz Z. Analysis of stability, local convergence and transformation sensitivity of a variant of particle swarm optimization algorithm. IEEE Transactions on Evolutionary Computation. 2015;20(3):370-85.
9. Bonyadi M, Li X. An analysis of the velocity updating rule of the particle swarm optimization algorithm. Journal Heuristics. 2014;20(4):417-52.
10. Ting T, Shi Y, Cheng S, et al. Exponential inertia weight for particle swarm optimization. In: Third International Conference on Swarm Intelligence; China: Researchgate.net; 2012. [Citado diciembre de 2016] Disponible en: https://www.researchgate.net/publication/262389715_Exponential_Inertia_Weight_for_Particle_Swarm_Optimization
11. Shi C, Shi Y, Qin Q. Population diversity of particle swarm optimizer solving single and multi-objective problems. International Journal of Swarm Intelligence Research. 2012;3(4):23-60.
12. Shi Y, Eberhart R. A modified particle swarm optimizer. In: IEEE International Congress on Computational Intelligence; Anchorage, USA: IEEE; 1998. [Citado diciembre de 2016] Disponible en: https://pdfs.semanticscholar.org/5061/72b0e0dd4269bdcfe96dda9ea9d8602bbfb6.pdf
13. Boyd S, Vandenberghe L. Convex Optimization. New York, USA: Cambridge University Press; 2004.
14. Hobug W, Abbel P. Data fitting with geometric-programming-compatible softmax functions. Optimization and Engineering. 2016;14(4):897-918.
Recibido: 3/1/2017
Aceptado: 15/4/2017
Isidro Luis Alemán-Romero, Universidad Tecnológica de La Habana. Centro de Estudios de Matemática. La Habana. Cuba. Correo electrónico: ialeman@cemat.cujae.edu.cu


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}