










 Custom services
Custom services
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
as instituciones de educación superior además del personal relacionado con la enseñanza, la investigación, la administración y los servicios son considerados como una parte importante del ciclo de formación profesional de los estudiantes universitarios. Además, la administración de la gestión de la calidad y la toma de decisiones tiene lugar como resultado del procesamiento de datos y pruebas, en lugar de opiniones o suposiciones de expertos. Esto implica la implementación de diversos procedimientos que garanticen la calidad educativa (González López, 2006). Esta situación se halla enmarcada en que predecir el éxito académico del estudiantado es un desafío para las instituciones de educación superior, esto, debido a la heterogeneidad del alumnado, programas de estudio, docentes, infraestructura, acceso a recursos, etc. Así, la brecha entre la tasa de matrícula y graduación de las universidades se expande en la medida en que la universidad aumenta su oferta académica. En consecuencia, es necesario promover estudios académicos sobre el modelamiento y aplicación del aprendizaje semi-supervisado de minería de datos en la Educación Superior.
En el ámbito educativo, es posible encontrar trabajos previos con diversos métodos para predecir o encontrar patrones de comportamiento asociados con el desempeño del estudiantado. Más específicamente, en este trabajo usamos reglas de asociación. Así mismo Sawant & Shah (2016), estudió y comparó varios tipos de algoritmos de clasificación supervisada y no supervisada en minería de datos para seleccionar la mejor técnica. Posteriormente, la técnica no supervisada fue aplicada para identificar los factores del éxito académico. Por otro lado, Yang (2008), estudió el efecto de la influencia social en la predicción del rendimiento académico. Ya que, el mayor desafío viene de la dificultad de recoger una lista de amigos idónea para los estudiantes. Después los autores construyen la relación social de los estudiantes de acuerdo a su comportamiento en el plantel y predicen el rendimiento académico.
Además, construyen la red social mediante el aprendizaje semi-supervisado y evalúan el algoritmo propuesto. Por otro lado, Romero & Romero (2010), exploró la extracción de reglas de asociación raras recogiendo datos de estudiantes en una plataforma LMS específicamente Moodle. Por lo general, estas reglas se generan cuando los conjuntos de datos están desequilibrados. Este tipo de reglas es más difícil de encontrar cuando se aplican algoritmos tradicionales de minería de datos. Otro trabajo, también relacionado con las reglas de la asociación tiene que ver con He (2011), donde los autores tomaron como fuente de información a 300 estudiantes, ellos dividen la información en cinco categorías para el primer nivel y 14 categorías para el segundo nivel; así que en el primer nivel se consideró como fondo y aplicaron el algoritmo apriori para obtener las reglas que forman parte del conocimiento oculto de los datos.
Así mismo, Liu (2012), realizó el análisis de minería de datos con un conjunto de datos vinculados a las puntuaciones finales del estudiante. Como parte del trabajo, los autores procesan previamente los datos dividiéndolos en tres clases: Pobre, Media y Mejor. Una vez preparada esta información utilizan los algoritmos de clasificación como una herramienta de minería de datos para obtener conocimiento. De todos los trabajos revisados Sawant (2016), está en consonancia con nuestra investigación, ya que usamos técnicas de preprocesamiento de datos y técnicas no supervisadas para la obtención de patrones útiles. Sin embargo, a pesar de su potencial importancia a nivel académico es un área poco investigada, por lo tanto, se requiere nuevas investigaciones que profundicen su aplicabilidad.
En este contexto planteamos como objetivo determinar a través de la minería de datos, cuáles son los factores que se asocian con la escala del tiempo promedio de graduación del alumnado. Para este propósito, adquirimos información relevante usando reglas de asociación estimulando el consecuente con una salida deseada.
En esta sección abordamos el estudio del aprendizaje semi-supervisado utilizando técnicas de aprendizaje no supervisado. Concretamente usamos reglas de asociación estimulando su consecuente por medio de una variable categórica. Los datos obtenidos para este estudio se recuperaron de la base de datos institucional de un centro de estudio universitario en Ecuador, el conjunto de datos dispone de variables numéricas y categóricas, en concreto, 53 variables y 849 observaciones de estudiantes de las diferentes carreras universitarias.
Desarrollo
En la publicación de García, Luengo, & Herrera (2016), se ha manifestado que una parte esencial para cualquier algoritmo en minería de datos es disponer de un conjunto de datos íntegro y limpio. Basándonos en este trabajo hemos efectuado el pre-procesado de los datos. En primer lugar, realizamos el filtrado de los datos atípicos, después etiquetamos estos datos como un dato perdido, esto, con el fin de que sean usados en la siguiente fase del preprocesado de datos. En segundo lugar, las observaciones con datos perdidos fueron remplazadas por un valor que es asignado por la función rfimpute del algoritmo Random Forest (Breiman, 2001), que resultó más eficiente y precisa al tratar anomalías en los datos. En tercer lugar, aplicamos un filtrado de características, para seleccionar las variables más relevantes. En cuarto lugar, obtenidas las características relevantes del conjunto de datos, hemos efectuado la filtración de observaciones usando la función NoiseFiltersR (Morales, et al., 2017). Por último, hemos balanceado los datos con el algoritmo SMOTE (Chawla, Bowyer, Hall & Kegelmeyer, 2002). Es decir, se ha equiparado las observaciones para evitar el sesgo en los datos. Todo esto para filtrar los de mayor relevancia, así el conjunto de datos original se ha reducido en 16 variables descrito en la Tabla 1.
Tabla 1 Descripción de variables del conjunto de datos estudiado.
| Variable | Tipo | Valores | Descripción |
|---|---|---|---|
| carrera | numérico | [1-14] | Carrera universitaria. |
| sostenimiento | categórico | {Público, Privado} | Colegio donde obtuvo el bachillerato. |
| taprobacion_1 | numérico | [0,3] | Cantidad de cursos repetidos en el primer año de la carrera. |
| pedad2 | numérico | [0,15] | Cantidad de docentes con edades menores a 40 años, que dieron clases en primer curso. |
| taprobacion_2 | numérico | [0,3] | Cantidad de cursos repetidos en el segundo año de la carrera. |
| sedad2 | numérico | [0,15] | Cantidad de docentes con edades entre 46 y 60 años, que dieron clases en segundo curso. |
| taprobacion_3 | numérico | [0,3] | Cantidad de cursos repetidos en el tercer año de la carrera. |
| tedad3 | numérico | [0,15] | Cantidad de docentes con edad superior a 60 años, que dieron clases en tercer curso. |
| habito estudios | categórico | {si, no} | Hábito de estudios. |
| tamaño familia | numérico | [1-3] | Número de personas constituida por la familia. |
| jornada trabajo | categórico | {Tiempo completo, medio tiempo, tiempo parcial, eventual} | Jornada laboral del estudiante. |
| Núm. Matriculas | numérico | [1-15] | Total de matrículas acumuladas. |
| financiamiento | categórico | {Fondos propios, crédito, beca} | Tipo de financiamiento de estudios. |
| Estrato Aprob | categórico | {Muy alta, alta, baja} | Cantidad total de cursos aprobados |
| Est Exp Doc | entero | [1-3] | Promedio de años de experiencia del profesorado. |
| estrato graduación | categórico | {Muy alta, alta, baja} | Medida de tiempo en años para graduarse. |
Diseño experimental
El objetivo del trabajo lo hemos centrado en analizar la escala de tiempo promedio de graduación del estudiante. Durante los últimos años ha existido un gran interés en mejorar las tasas de graduación de parte de las instituciones de educación superior. En trabajos similares, se han calculado diversas medidas para evaluar la importancia de los patrones encontrados en el aprendizaje automático y determinar las reglas de asociación de mayor importancia (Berzal & Cubero, 2010; Kumar & Chadha, 2012; Prajapati, Garg & Chauhan, 2017; Varshali & Jitendra, 2012). Por ello, el proceso de extracción de reglas lo hemos realizado de la siguiente manera. En primer lugar, hemos transformado las variables numéricas a categóricas. En segundo lugar, hicimos un estudio exploratorio de las variables para detectar la magnitud de correspondencia entre variables. En tercer lugar, el conjunto de datos lo hemos convertido en transacciones para facilitar la detección de reglas. En cuarto lugar, se filtró las reglas más relevantes de acuerdo con las métricas planteadas en este trabajo. Por último, las reglas de mayor interés son seleccionadas y mostradas en gráficos para facilitar la comprensión de las reglas descubiertas.
Métricas usadas
En este trabajo se incluyó métricas de importancia para evaluar las reglas de asociación, hemos usado Confidence, Support, Lift y Conviction. Esto, con el fin de reducir el volumen de reglas, y conseguir las reglas con mejor representación (Han, et al., 2017).

La confianza es el porcentaje de transacciones en el conjunto de datos D con el conjunto de elementos X que también contiene el conjunto de elementos Y.
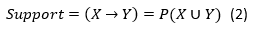
El soporte es el porcentaje de transacciones en el conjunto de datos D que contienen ambos conjuntos de elementos X e Y.

El valor de lift 1 indica que X e Y aparecen tan frecuentemente juntos bajo la suposición de independencia condicional.

Conviction mide la fuerza de implicación de la regla de independencia estadística, donde P (Y) es la probabilidad de que Y no aparezca en una transacción.
Obtención de reglas de asociación
Hemos obtenido el patrón de reglas transformando el conjunto de datos en transacciones, con el fin de que el algoritmo trabaje con ellas y devuelva reglas de asociación. Para este fin, hemos creado una rutina en algoritmo 1 que permitió extraer las reglas usando todas las posibles combinaciones entre las métricas de soporte y confianza. También, a esta rutina hemos establecido el número de términos que componen el antecedente de la regla y el consecuente (Tabla 2).

En esta sección analizamos los resultados encontrados, en respuesta a la pregunta de investigación sobre cuáles son las variables que se relacionan con el tiempo de graduación de los estudiantes.
Es importante conocer la actividad o comportamiento de los datos, ya que esto ha permitido en primer plano tener una idea más clara de los datos. Para ello, hemos usado la matriz de correlación y el método de correlación de Pearson que presentamos en la Figura 1. Aquí se calculó la magnitud o el grado de asociación entre las variables.

En la figura 1 la correspondencia gradual de variables tanto positivas (azulado) como negativas (rojizo). Las formas de las elipses determinan el grado de correspondencia, cuanto más fina la elipse mayor correspondencia existió entre las variables.
Transacciones del conjunto de datos
En esta etapa, se consiguió transformar las observaciones en transacciones. Las transacciones simplifican en 364 de las primeras 849 iniciales. Esta reducción es notoria debido a la eliminación de transacciones redundantes y menos significativas. En tal sentido mostramos la Figura 2 que muestra las etiquetas (ítems) de las transacciones a través de un mapa de calor.
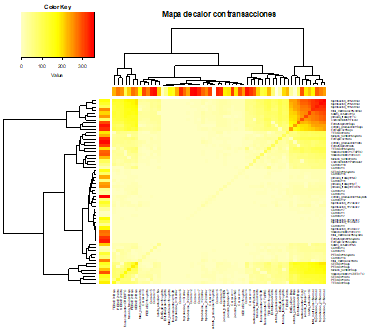
Fig. 2 Mapa de calor de transacciones del conjunto de datos, con concentraciones de transacciones más relevantes en la parte superior derecha.
El color rojizo indicó mayor concentración de transacciones. Las transacciones tienen un orden de agrupamiento jerárquico. La cantidad de transacciones se definió por el color, el cuadro superior izquierdo valora el número de transacciones y la proximidad del color.
En la Fig. 2, las etiquetas del eje X e Y con mayor concentración de datos se han agrupado de manera jerárquica y aparecen con mayor frecuencia en las transacciones. De modo que las etiquetas frecuentes de acuerdo con la figura son: taprobacion_1, taprobacion_2, taprobacion_3, total-matriculas, habito-estudios, jornada-trabajo, sostenimiento, Estrato Aprob, estrato_graduacion y Estrato Exp Doc.
Como parte de la exploración de reglas de asociación, hemos explorado el conjunto de reglas de forma general, en primera instancia obtuvimos 41 019 reglas, luego discriminamos las reglas que tuvieron un valor de lift inferior a 1 quedando reducido a 34 593 reglas. En segundo lugar, debido a que el alto número de reglas representa una vaguedad para ofrecer un conocimiento válido, hemos eliminado las reglas redundantes quedando un total de 35 064 reglas. La idea principal es reducir las reglas a un punto que sean manejables e interpretables, es por esto, que también filtramos las reglas de acuerdo con la métrica conviction y hemos conseguido finalmente 18 298 reglas. Aunque, todavía sigue siendo un número de reglas alto, se logró reducir un 45% de reglas que carecían de importancia. De esta manera, nos hemos quedado con reglas relevantes y de mayor utilidad para el análisis.
En esta etapa, usamos el aprendizaje semi-supervisado, que consistió en establecer una salida personalizada de las reglas de asociación. En este sentido, hemos establecido una variable con etiquetas de interés que permitió obtener un patrón útil respecto al tiempo de graduación del estudiantado. Por ello, hemos considerado un nuevo conjunto de reglas con el consecuente inducido, es decir, hemos forzado que el consecuente tuviera solo la etiqueta vinculada con la escala de tiempo de graduación. Esto, para obtener un patrón de regla útil. Las etiquetas se asocian al tiempo que tarda el estudiantado en graduarse: “Muy Alta” (superior a 10 años), “Alta” (entre 7 y 10 años) y “Baja” (menor a 7 años) (Figura 3).

Fig. 3 Matriz de puntos de las reglas de asociación filtrada de acuerdo con la métrica lift. Los puntos más rojizos representan a reglas de asociación de alto interés.
Los parámetros usados para obtener un conjunto de reglas adecuado fueron confianza=0.86, Soporte =0.01 y el número de etiquetas del antecedente = 5. En la Tabla 3 mostramos el conjunto de reglas obtenido y la valoración de las métricas. Las reglas encontradas se encuentran ordenadas de forma descendente según la columna conviction (Conv). De acuerdo con estos resultados, llama la atención las primeras cuatro reglas de asociación, donde el consecuente con la variable inducida ha demostrado que el tiempo de espera promedio para la graduación del estudiantado es “muy alta” y “alta”.

Las reglas mostradas en la Tabla 3 con el consecuente “Muy alta”, tienen una confianza del 87.5% de aparición en las transacciones, los términos del antecedente SEDAD2 y TEAD3 se han relacionado con edades de profesores que dictaron clases en el segundo y tercer año respectivamente, SEDAD2=Alta, que fue el número de profesores entre 46 y 60 años; y TEDAD3=Baja, que fue el número de profesores con edades superiores a 60 años. Adicionalmente, la etiqueta carrera=12 se refirió a la carrera de ingeniería agropecuaria.
Visualización de los patrones.
De acuerdo con los hallazgos encontrados, en la Tabla 4 hemos resumido las etiquetas comunes del antecedente respecto al consecuente.

En la Tabla 4, la incidencia de graduación “Baja” tuvo etiquetas de taprobacion-1 y taprobacion-2 como “Normal”, TEDAD3=Muy Alta y, EstratoAprob = “Bajo”. El estrato de aprobación indicó tres niveles bajo, alto y muy alto. Es decir, que el curso es superado sin la presentación a exámenes de suspensión.
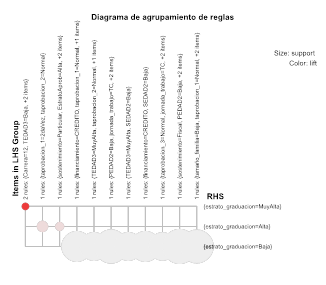
Fig. 4 Agrupamiento de reglas de asociación, en esta figura se muestra el consecuente RHS con las tres categorías de la variable que sirve de pivote para filtrar las reglas.
Por otro lado, en las Figuras 4, 5 y 6 hemos presentado las reglas de asociación obtenidas de forma visual. Basados en el trabajo de Yang (2008), donde se describió la importancia del enfoque de la exploración visual y las reglas de asociación mediante el uso del grafico de coordenadas paralelas, ya que es aquí donde se puede visualizar la correspondencia entre los conjunto de ítems. Por ello, hemos presentado la Figura 5 con el recorrido de cada etiqueta desde su inicio hasta el consecuente.

Fig. 5 Diagramas de coordenadas paralelas que ha permitido visualizar el recorrido de las etiquetas hasta el consecuente. El color rojizo de las líneas representa.
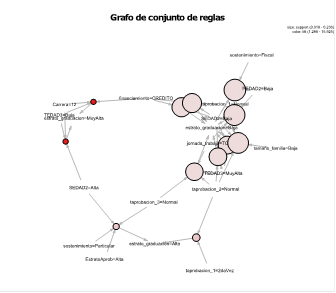
Fig. 6 Grafo dirigido con la concurrecia entre etiquetas del conjunto de reglas asociación obtenidas. El color rojizo lo hemos asociado con la métrica lift y el tamaño de los nodos con la métrica support.
De acuerdo con los hallazgos encontrados, las etiquetas del consecuente indican una incidencia de graduación “Baja” que corresponden a factores donde el profesorado del tercer curso con edad superior a los 60 años tuvo una participación “Muy Alta”. Además, los tiempos de aprobación en primer y segundo curso fueron “Normal”, es decir, que el estudiantado con bajo tiempo de graduación no suspendió asignaturas. Otras etiquetas menos frecuentes fueron jornada_trabajo=TC (TC=tiempo completo), financiamiento=CREDITO y tamaño_familia=Baja. Por otra parte, la incidencia de graduación “Alta” se debe a que tanto en primer y segundo curso las tasas de aprobación fueron “2daVez” o “3raVez”, es decir, se evidenció que el estudiantado ha suspendido asignaturas y tuvo matriculas adicionales para aprobar un año; también, que el profesorado del tercer curso con edad superior a 60 años tuvo una baja participación en la impartición de clases.
Por último, la incidencia de graduación “Muy Alta” se relacionó con las categorías de edades del profesorado en segundo y tercer curso. Para el segundo curso el profesorado con edades entre 46 y 60 años tuvo una “Alta” participación en las clases; mientras que, para el tercer curso el profesorado con edad superior a 60 años tuvo una “Baja” participación en las clases. Por otro lado, se encontró otra etiqueta conexa con el tiempo de graduación “Muy Alta” y fue la etiqueta carrera= 12 que correspondió al estudiantado de la carrera de Agropecuaria.
Conclusiones
El presente trabajo, centra su atención en el aprendizaje semi-supervisado usado para descubrir la escala de tiempo promedio de graduación del estudiantado. De manera más concreta, se ha investigado y descubierto las variables relevantes para la obtención del patrón de reglas de asociación. Por un lado, hemos encontrado variables relacionadas con edades del profesorado y el aprovechamiento del estudiante en los tres primeros años. Por otro lado, variables socioeconómicas tales como el financiamiento de estudios, tamaño de la familia y jornada de trabajo del estudiante. El aprendizaje semi-supervisado permitió conseguir reglas de asociación con alto nivel de confianza y además permitió desechar reglas espurias del análisis. También fue clave para lograr una mejor interpretación de las reglas usando gráficos.
Proponemos estudiar mediante otras técnicas de machine learning como: K-vecinos cercanos (KNN), Maquina de soporte vectorial (SVM) o Agrupamiento difuso (Clustering fuzzy), esto con el fin de detectar otros patrones que ayuden a los administradores académicos tener un nuevo conocimiento.

