










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
El constante desarrollo de las tecnologías ha provocado el crecimiento de la información digital. Cada vez aumenta la necesidad de crear alternativas que permitan la recuperación y organización de toda la información para ponerla a disposición de los usuarios de forma eficiente. Una de las alternativas que ayudan a los usuarios a encontrar de manera personalizada lo que es relevante dentro de un mundo sobrecargado de información son los Sistemas de Recomendación.
Un sistema de recomendación es una pieza de software que ayuda a los usuarios a identificar la información de aprendizaje más interesante y relevante de un grupo grande de información. Estos sistemas de recomendación pueden estar basados en filtrado colaborativo, contenido o híbrido (Niemann, et al., 2010), atendiendo las necesidades de los usuarios.
Los sistemas de recomendación recopilan información sobre las preferencias de sus usuarios para un conjunto de elementos (por ejemplo, películas, canciones, libros, bromas, gadgets, aplicaciones, sitios web, destinos de viajes y material de aprendizaje electrónico) (Bobadilla, et al., 2013) y hacen uso de herramientas y técnicas de software para proporcionar sugerencias útiles para un usuario (Ricci, et al., 2011). Dentro de las principales funcionalidades de los sistemas de recomendación, según Cleger (2013), se destaca:
La ayuda a nuevos e infrecuentes visitantes mediante amplias listas de recomendación.
Fomentan la credibilidad a través de una comunidad.
Intentan fidelizar a la clientela a través de servicios de notificación, envío de información con nuevos productos y/o descuentos.
Realizan ventas cruzadas por medio de recomendaciones asociadas por producto.
Construyen relaciones prolongadas garantizando una personalización profunda con ello.
Aunque existen diversos tipos de sistemas de recomendación, todos necesitan información sobre los usuarios y Objetos de Aprendizajes para poder realizar recomendaciones de calidad. Existen diferentes tipos de modelos de recomendación según la bibliografía conocidos también como enfoques tradicionales; estos son: basados en contenidos, filtrado colaborativo, basados en conocimiento e híbridos (Di Noia, 2016; Rezaeinia, et al., 2016).
Los modelos basados en contenidos utilizan algoritmos dependientes del dominio y enfatizan más en el análisis de los atributos de los elementos para generar predicciones. Cuando se recomiendan documentos como páginas web, publicaciones y noticias, la técnica de filtrado basado en contenido es la que tiene más éxito. Las recomendaciones son realizadas basándose solamente en un perfil creado, utilizan algoritmos “ítem a ítem” generados mediante la asociación de reglas de correlación entre ellos (Betancur, Moreno & Ovalle, 2010).
Este tipo de recomendación aprende de los intereses de los usuarios y hace el proceso de recomendación sobre la base de las características presentes en los ítems. Para este tipo de sistema de recomendación se hace coincidir los atributos del perfil del usuario con los atributos de los ítems a recomendar.
Para el caso de los Objetos de Aprendizajes, la recomendación se realiza utilizando los metadatos y una o varias características del perfil del usuario. Este tipo de sistemas tiene como principal limitación, los problemas en las búsquedas cuando se tienen datos poco estructurados y no se puede analizar su contenido, ejemplo en videos y sonidos (Cazella, Nunes & Reategui, 2010). Este problema se minimiza al utilizar solamente los metadatos de los Objetos de Aprendizajes.
En los sistemas de recomendación basada en filtros colaborativos las recomendaciones se hacen basándose en el grado de similitud entre usuarios. Se fundamentan en el hecho de que los Objetos de Aprendizaje que le gustan a un usuario, les pueden interesar a otros usuarios con gustos similares (Vekariya & Kulkarni, 2012). Para la realización de un buen Objeto de Aprendizaje para el usuario actual y los basados en modelos hacen uso del modelo del estudiante para construir un perfil o modelo, a partir del cual se realizan las recomendaciones (Betancur, et al., 2010).
Un usuario de un sistema basado en filtraje colaborativo debe calificar cada uno de los ítems utilizados, indicando cuanto este ítem sirve para su necesidad de información. Estas puntuaciones son recolectadas para grupos de personas, permitiendo que cada usuario se beneficie de las experiencias (calificaciones) de los otros. La ventaja de estos sistemas de recomendación es que un usuario puede recibir recomendaciones de ítems que no estaban siendo buscados de forma activa. La desventaja es el problema del primer evaluador, cuando un nuevo Objeto de Aprendizaje es agregado a la federación no existe manera de recomendarlo por este sistema.
Los sistemas de recomendación basada en conocimiento tratan de sugerir objetos de aprendizaje basados en inferencias acerca de las necesidades del usuario y sus preferencias. Se basa en el historial de navegación de un usuario, elecciones anteriores (Vekariya & Kulkarni, 2012). Un sistema de recomendación basado en conocimiento hace recomendaciones según el historial de navegación de un usuario, este historial está almacenado con el fin de obtener las preferencias e intereses del usuario y con ello obtener la información necesaria para generar recomendaciones.
Estos sistemas también son llamados sistemas de preferencias implícitas ya que deducen las preferencias a partir del comportamiento del usuario y de su historial. Esto permite que en la mayoría de los casos no sea necesario pedir al usuario demasiada información sobre sus preferencias para que pueda ser recomendado. Sugiere ítems basado en las inferencias acerca de las necesidades y preferencias del usuario según su historial de navegación.
Los sistemas de recomendación híbridos buscan la unión entre varios enfoques o técnicas de recomendación con el objetivo de completar sus mejores características y hacer mejores recomendaciones (8). Existen varios métodos de combinación o integración como (Cazella, et al., 2010):
Método ponderado: Donde se combinan las puntuaciones o votos para producir una única recomendación.
Método de Conmutación: El sistema conmuta entre las técnicas de recomendación en función de la situación actual.
Método Mixto: Se presentan las recomendaciones de diferentes sistemas de recomendación al mismo tiempo.
Método de combinación de características de diferentes fuentes de datos: Se entregan como entradas a un único algoritmo de recomendación.
Método de cascada: Cada una de las recomendaciones refina las recomendaciones dadas por los otros.
Métodos basados en memoria y basados en modelos (Vekariya & Kulkarni, 2012).
Debido al uso de las Tecnologías de la Información y las Comunicaciones (TIC), en todas las áreas del conocimiento, se hace indispensable el contar con habilidades de pensamiento computacional y depuración para obtener pensamiento constructivo sobre cualquier número de tareas (Worsley & Blikstein, 2013). Los objetos de aprendizaje son frecuentemente utilizados para el desarrollo del pensamiento y el aprendizaje, ellos pueden ser adquiridos a través de consultas en los distintos repositorios que están en la nube, están diseñados tanto para el material educativo que contienen temas que son de utilidad para los usuarios que lo necesiten.
La forma de aprender conocimientos sobre temas específicos a través de los años ha ido evolucionando partiendo desde el aprendizaje asistido por computadoras, luego los contenidos fueron administrados a través de los sistemas de gestión usuarios y otros no de aprendizaje, en los últimos años aparecen los MOOCS (Massive Online Open Source) y la tendencia son los sistemas Adaptive e-learning que es un nuevo medio de aprendizaje y enseñanza que utiliza un sistema de tutoría inteligente para adaptar el aprendizaje en línea con el nivel de conocimientos del alumno. El aprendizaje en línea es un camino revolucionario para dar educación en la vida moderna que beneficia a muchas personas, en el presente trabajo se propone un modelo de recomendación basado en conocimiento para el desarrollo del pensamiento algorítmico y en particular para el trabajo con objetos de aprendizaje.
Desarrollo
Para el desarrollo de un modelo de recomendación que favorezca la selección del Objeto de Aprendizaje, apropiado para la mejora de habilidades en la resolución de problemas de los programadores, es decir, para el desarrollo del pensamiento algorítmico, se sigue el flujo de trabajo de la Figura 1. El flujo de trabajo propuesto se basa en la propuesta de Pérez Cordón (2008), para sistemas de recomendación basados en conocimiento, que permite flexibilidad en cuanto la agregación de la similitud de los atributos del perfil del usuario, con respecto a la descripción producto mediante el empleo de cuantificadores lingüísticos borrosos.

La descripción detallada del flujo de trabajo del modelo propuesto y cada una de sus actividades se presenta a continuación.
Creación BD con los Objetos de Aprendizaje utilizados para el desarrollo del pensamiento algorítmico.
Cada Objetos de Aprendizaje utilizado para el desarrollo del pensamiento algorítmico se almacena en la Base de Datos que se crea y se denotan por a 𝑖 , estos elementos estarán descritos por un conjunto de características que conformarán el perfil de los Objetos de Aprendizajes, los que matemáticamente se expresan como se muestra en la ecuación 1.

Los perfiles pueden ser obtenidos de forma manual automática o semiautomática y su ecuación matemática es la que se muestra en 2.

Las valoraciones de las características de los Objetos de Aprendizajes,  estarán expresadas utilizando la escala lingüística
estarán expresadas utilizando la escala lingüística  , donde
, donde 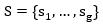 que representa el conjunto de término lingüísticos definidos para evaluar la característica
que representa el conjunto de término lingüísticos definidos para evaluar la característica  ,
,
Descrito el conjunto de Objetos de Aprendizajes, estos se almacenan por el sistema en la Base de Datos, base de datos y se interpretan matemáticamente, como se muestra en la Ecuación 3

Determinación de los vectores de peso
En este caso se sugiere que el vector de pesos(W) asociado al operador OWA sea determinado por un cuantificador regular no decreciente Q (Mezei & Brunelli, 2018). Teniendo en cuenta que si Q es una Cuantificador Incremental Monótono Regular (RIM, por sus siglas en inglés) entonces el valor agregado de la alternativa 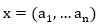 esta dado por
esta dado por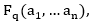 , donde
, donde 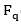 es un operador OWA derivado de Q. El vector con la importancia (V) de los criterios puede ser obtenido mediante el método AHP (Saaty, 1988).
es un operador OWA derivado de Q. El vector con la importancia (V) de los criterios puede ser obtenido mediante el método AHP (Saaty, 1988).
Obtención del perfil del usuario
En esta actividad se obtiene la información del sobre las preferencias de los Objetos de Aprendizajes a utilizar para el desarrollo del pensamiento lingüístico, estas preferencias se almacenan en un perfil, que se describe como se muestra en la ecuación 4.
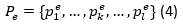
Dicho perfil estará integrado por un conjunto de atributos que se representan como se muestra en la ecuación 5.

Donde 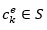
Filtrado
En esta actividad se filtran los Objetos de, que con mayor frecuencia se utilizan para el desarrollo del pensamiento algorítmico, de acuerdo con el perfil del usuario para encontrar cuáles son los Objetos de Aprendizajes más adecuadas. Para tal fin se calcula la similitud entre perfil de usuario,  y cada Objetos de Aprendizaje utilizado para el desarrollo del pensamiento algorítmico almacenado en la Base de Datos. Para el cálculo de la similitud total se emplea el operador OWAWA.
y cada Objetos de Aprendizaje utilizado para el desarrollo del pensamiento algorítmico almacenado en la Base de Datos. Para el cálculo de la similitud total se emplea el operador OWAWA.
Definición 3. Un operador OWAWA (Merigó, 2008b) es una función OWAWA: de dimensión n si tiene un vector de ponderaciones asociado, con  y tal que:
y tal que:

Donde; es el j-ésimo más grande de los , cada argumento 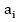 tiene asociada una ponderación
tiene asociada una ponderación 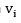 con
con  es la ponderación
es la ponderación 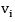 ordenada según
ordenada según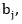 , es decir, según el
, es decir, según el 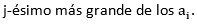
A partir de esta definición se emplea la ecuación 7.
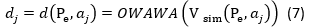
Donde; 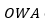 es un operador con el vector de pesos W y V. El vector de pesos W es obtenido a partir de un cuantificador lingüístico borroso seleccionado.
es un operador con el vector de pesos W y V. El vector de pesos W es obtenido a partir de un cuantificador lingüístico borroso seleccionado.
es un vector que contiene la similitud de todos los atributos del perfil del usuario con respecto a la descripción de los productos .
La función calcula la similitud entre los valores de los atributos del perfil de usuario y la y de los productos, , es definida como (Pérez-Teruel, Leyva-Vázquez & Estrada-Sentí, 2015):
Recomendación
Una vez calculada la similitud entre el perfil del usuario y los perfiles almacenado en la BD, de cada uno de los Objetos de Aprendizajes que con frecuencia se utiliza para el desarrollo del pensamiento algorítmico, estos se ordenan de acuerdo con la similitud obtenida, cuya ordenación se representa por el vector de similitud que se muestra en la ecuación 8.
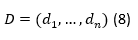
Los mejores serán aquellos que mejor satisfagan las necesidades del perfil del usuario (con mayor similitud).
Ejemplo demostrativo
A continuación se presenta un ejemplo demostrativo basado en (Arroyave, Estrada & González, 2016), supongamos una base de datos:
Descrito por el conjunto de atributos

Mediante el cuantificador lingüístico (Doña Fernández, 2008) se obtiene el vector de pesos W=[0, 0, 0.333, 0.333, 0.333], para indicar importancia de los atributos V=[0.2,0.1, 0.3, 0.2,0.2]. Los atributos se valoran a través de la escala lingüística (Tabla 1).
Tabla 1 - Escala de términos lingüísticos.
| No | Etiquetas | Funciones de pertenencia |
|---|---|---|
| - | Muy bajo (MB) | (0.0,0.0,0.25) |
| - | Bajo (BA) | (0.0,0.25,0.50) |
| - | Mediano (ME) | (0.25,0.50,0.75) |
| - | Alto (AL) | (0.50,0.75,1) |
| - | Muy Alto (MA) | (0.75,1,1) |
Fuente: Şahin & Yiğider (2014).
La vista de la base de datos se muestra cómo se representa en la Tabla 2.

Si un usuario , desea recibir la recomendación del sistema deberá proveer información al mismo mostrando sus preferencias. Las preferencias se muestran a través del vector que se muestra a continuación:
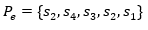
El siguiente paso en nuestro ejemplo, es el cálculo de la distancia entre el perfil de usuario y los productos almacenadas en la base de datos. En la Tabla 3, se muestra la similitud obtenida.
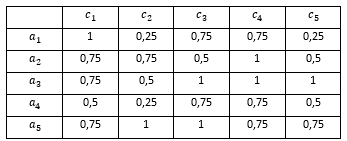
Luego de obtenida la similitud de los atributos almacenado en la Base de Datos para obtener recomendación, se calcula la similitud entre los productos de la base de datos y el perfil en este caso usando el OWAWA y los vectores de peso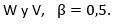 . El resultado que se obtiene se muestra en la Tabla 4.
. El resultado que se obtiene se muestra en la Tabla 4.

En la fase de recomendación se recomendará aquellos productos que más se acerquen al perfil del usuario. El ordenamiento de los productos basado en esta comparación es el que se muestra a continuación.

En caso de que el sistema recomendara los dos productos más similares al deseado por los usuarios, estos serían 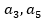 . El ejemplo mostro la aplicabilidad de la propuesta dada por la facilidad de uso y la interpretabilidad de base de datos.
. El ejemplo mostro la aplicabilidad de la propuesta dada por la facilidad de uso y la interpretabilidad de base de datos.
Conclusiones
En este trabajo se presentado la propuesta de un modelo de recomendación siguiendo el enfoque basado en conocimiento para la selección de los objetos de aprendizaje, para la mejora de las habilidades del pensamiento algorítmico útil para la resolución de problemas de los programadores. El modelo de recomendación se basa en el empleo de la computación con palabras para la construcción del perfil de usuario y la base de datos y el empleo del operador OWAWA calculando el vector de pesos mediante cuantificadores lingüísticos borrosos.
Trabajos futuros estarán relacionados con la creación de la base de datos a partir de múltiples expertos, así como la obtención de los pesos de las características utilizando valoraciones en grupo. Adicionalmente se trabajará en la inclusión de modelos de agregación más complejos, así como la hibridación con otros modelos de recomendación. Otras áreas de trabajo futuros estarán relacionadas con el manejo de información heterogénea en los modelos y en el desarrollo de una herramienta informática que implemente la propuesta.

