










My SciELO
 Custom services
Custom servicesServices on Demand
Journal

Article
 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkCuban Journal of Agricultural Science
Print version ISSN 0864-0408On-line version ISSN 2079-3480
Cuban J. Agric. Sci. vol.50 no.2 Mayabeque Apr.-June 2016
Cuban Journal of Agricultural Science, 50(2): 185-191, 2016, ISSN: 2079-3480
ORIGINAL ARTICLE
Integral evaluation of indicators in models of parametric and non-parametric analysis of variance. Use of the categorical principal component
Valoración integral de indicadores en los modelos de análisis de varianza paramétrico y no paramétrico. Uso del componente principal categórico
Magaly Herrera,I Caridad Walkiria Guerra,II Yolaine Medina,I
IInstituto de Ciencia Animal, Apartado Postal 24, San José de las Lajas, Mayabeque, Cuba.
IICentro Universitario Municipal de Güines, Calle 86, No.7312, Güines, Mayabeque, Cuba.
ABSTRACT
In order to establish possible relations among statistical indicators in models of parametric and non-parametric analysis of variance, belonging to completely randomized and random block experimental designs, the categorical principal component analysis was used because they are quantitative and qualitative. The models of analysis of variance of simple classification, with 16 experiments, were selected, as well as those of double classification with five experiments. An amount of 100 discrete and categorical variables were analyzed. A matrix of data was designed using the indicators of completely randomized designs and the test of Kruskal-Wallis, which is its non-parametric homologue, the model of random blocks with its non-parametric homologue, and the test of Friedman. The categorical principal component analysis showed adequate reliability and a variability percentage explained with 0.94. The indicators with more importance in the first dimension are related to probability of type I error and power, showing absolute values close to one and allowing to determine their contribution in this study. The results evidenced the existing relations among the analyzed statistical indicators, from the high degree of positive correlation over 0.90 among the values of probability of type I error in the F test of Fisher (with and without transformation) and its non-parametric homologue test, as well as the high negative correlations, existing between around 0.8 and 0.93 of them with values of power (with or without data transformation). It is necessary to continue the analysis for different data distributions and sample sizes.
Key words: statistical indicators, models of simple and double variance analysis, categorical principal component analysis.
RESUMEN
Para establecer posibles relaciones entre indicadores estadísticos en los modelos de análisis de varianza paramétrico y no paramétrico, correspondientes a los diseños completamente aleatorizados y de bloques al azar, se utilizó el análisis de componentes principales categóricos por ser estos cuantitativos y cualitativos. Se seleccionaron los modelos de análisis de varianza de clasificación simple, con dieciséis experimentos, y doble con cinco. Se analizaron en total 100 variables de tipos discretas y categóricas. Con los indicadores de los diseños completamente aleatorizados y su homólogo no paramétrico, la dócima de Kruskal-Wallis, y el de modelo de bloques al azar con su homólogo no paramétrico, la dócima de Friedman, se conformó una matriz de datos. El análisis de componentes principales categóricos mostró adecuada fiabilidad y porcentaje de variabilidad explicada con 0.94. Los indicadores con mayor peso en la primera dimensión se encuentran relacionados con la probabilidad de error tipo I y la potencia, que presentaron valores absolutos cercanos a uno, que permiten determinar el aporte de los mismos en el estudio. Los resultados evidenciaron las relaciones que existen entre los indicadores estadísticos analizados, a partir del alto grado de correlación positiva por encima de 0.90 entre los valores de probabilidad de error tipo I en la dócima F de Fisher (sin transformación y con ella) y la dócima homóloga no paramétrica, así como de las altas correlaciones negativas que existen entre 0.8 y 0.93 aproximadamente de estos con los valores de potencia (sin y con transformación de los datos). Se considera oportuno continuar el análisis para diferentes distribuciones de datos y tamaños de muestras.
Palabras clave: indicadores estadísticos, modelos de análisis de varianza simple y doble, análisis de componentes principales categóricos.
INTRODUCTION
There are some indicators in the analysis of variance that allow to evaluate quality and rigor of this procedure. Some of them are probability of type I error, test power, sample size and fulfillment of assumptions. In this last, data should distribute normally and have homogeneous variances. However, many times they are not taken into account, even though they provide a valuable information on effectiveness of the used analysis procedures.
De Calzadilla (1999), Vásquez (2011), De Calzadilla et al.(2002) studied and determined relations among indicators related to the analysis of variance. However, there is no information in the literature about an analysis that integrates the results of parametric and non-parametric analysis of variance.
In order to carry out this integrating analysis, a multivariate statistical method is needed, which will allow to establish possible relations among these indicators, and evaluate its contribution to the research. It is suggested the use of categorical principal component analysis (CATPCA), which allows to analyze qualitative and quantitative variables.
The CATPCA is similar to the standard principal component analysis (PCA). It is used with the same objective but, unlike this last, the CATPCA allows to scale the variables at different measuring levels and also allows non-linear relations among them (Molina and de los Monteros 2010).
Like its homologue for continuous variables (principal component analysis), this method may be considered as an exploratory technique for dimension reduction (Navarro et al. 2010, Vázquez 2012). The application of this method allows to integrate statistical indicators from ANAVA due to their characteristics.
Therefore, the objective of this study was to perform an integral analysis of a group of statistical indicators associated to the models of parametric and non-parametric analysis of variance, and to establish possible relations among them through the procedure of categorical principal components.
MATERIALS AND METHODS
The information selected for the database was processed from 2003 and 2011 by the Department of Biomathematics from the Institute of Animal Science, located in San José de las Lajas, Mayabeque province. Data belonged to researches developed by specialists from different departments.
The selected researches were related to 16 experiments that used the completely randomized design (CRD), and some others related to five experiments that applied the random block design (RBD), summing 100 discrete and categorical variables.
In the selected variables, the theoretical assumptions of the analysis of variance and normality of errors were analyzed. For that purpose, the test of Shapiro and Wilk (1965) was used, as well as the test of Levene (1960) for analyzing homogeneity of variance. Both were applied to the original variables, after the use of √X, √X+0.375, arcsine (√p) and Log X transformations for variables of counting and percentage, expressed in a logarithmic scale, respectively.
The parametric analysis of variance was used for CRD and its non-parametric homologue, as well as the Kruskal-Wallis test for RBD and its non-parametric homologue, and the test of Friedman. Both analysis were compared and the statistical results were evaluated. A matrix of data was produced with the obtained information. The lines were the result of the different selected researches, related to the used designs. The columns were the statistical indicators and those of the experimental design that are later mentioned. The matrix had a 100 x12 dimension:
• Type of design (design)
• Type of experiment (code)
• Fulfillment of the assumptions without transformation (Cumpl S/T)
• Fulfillment of the assumptions with transformation (Cumpl T)
• P value of Fisher F test without transformation (Valp S/T)
• P value of Fisher F test with transformation (ValpT)
• P value of non-parametric test (Valp NP)
• Power value for Fisher F test without transformation (Pot S/T)
• Power value for Fisher F test with transformation (Pot T)
• Sample size (SS)
• Amount of treatments (No. Tto)
• Distribution (Distcod)
The CAPTCA was used for performing an integral evaluation of statistical indicators and establish its possible relations, as well as to represent the information through a Biplot graph. The alpha index of Cronbach was used for measuring reliability of the method with a scale of values proposed by Hair et al. (1999).
For the analysis of theoretical assumptions of the model of analysis of variance, Statistica (StatSoft 2007) program was used. For the parametric and non-parametric analysis of variance, the statistical package Infostat (Di Rienzo et al. 2012) was applied, as well as the SPSS statistical package, 19.0 version (IBM Corporation 2010), for categorical principal component analysis.
RESULTS AND DISCUSSION
Table 1 shows a summary of the results of CATPCA for the analyzed indicators. Two dimensions were obtained, which explain 60.8 % of variability of the original information. The Cronbach´s alpha coefficient showed a total reliability level of 0.94, which is considered as excellent, according to the scale proposed by Hair et al. (1999). These authors indicated that the used method is adequate when the values of this coefficient are between 0.60 and 0.70. Dimension one is emphasized because it explains 43.13 % of the total variance, with a coefficient of 0.88. This evidences that the indicators represented in this dimension show a good level of reliability.
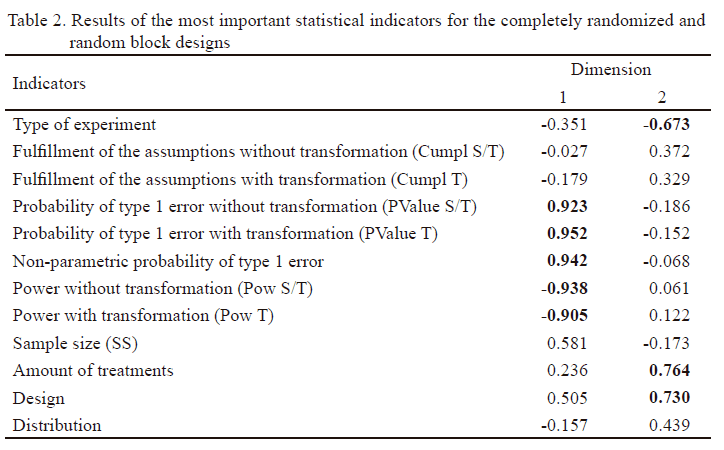
Table 2 shows the most important indicators of each dimension. In the first one, there is a list of those related to probability of type 1 error and power, which present positive and negative values close to one. They allow to determine the contribution of those indicators in the study, which represent one of the aspects to be considered by researchers in the process of experimentation. In dimension two, indicators showing a superior contribution to information are those related to amount of treatments, design (CRD and RBD) and type of experiment, which present values over 0.60.
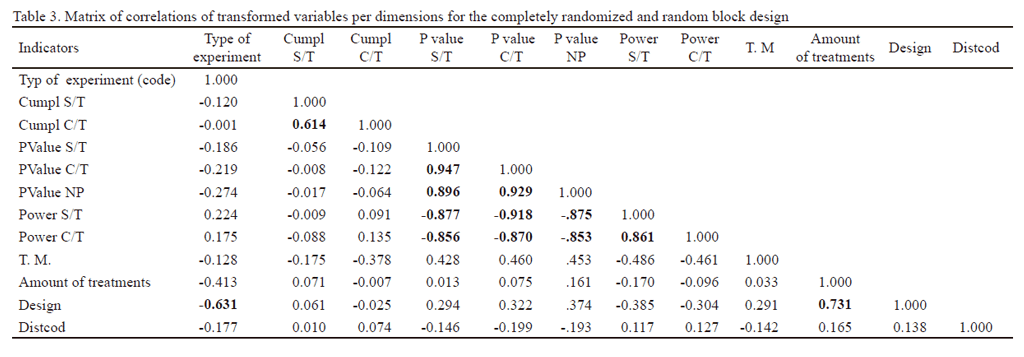
The most notable indicators in dimension one show correlations over 0.80 of absolute value. Those from dimension two show positive correlations over 0.60 (table 3).
It should be highlighted that high negative correlations among probability values of type 1 error and powers, showing an inverse relation, which means a high probability of finding significant differences or rejecting the null hypothesis when it is false, evidenced that with inferior values of α, there were superior values of power and vice versa. This result agrees with that stated by Gómez (2005).
Figure 1 shows a graphic representation of the analyzed statistical indicators that were divided into four groups. The first group includes indicators associated with probability values of type 1 error, Fisher F test, ANAVA test for variables (with and without transformation) and the non-parametric homologues Kruskal- Wallis and Friedman (P NP value). The second group contains criteria related to the fulfillment of theoretical assumptions of ANAVA. The third group includes power values (with and without transformation) and the fourth group, which is different from the rest, contains the indicators related to type of experiment and experimental design.
It is considered that the grouping of probability values of parametric and non-parametric tests is possible because the Fisher F test is characterized by being strong in front of heterogeneity of variance, mainly when it works with the same number of observations per treatments (Steel and Torrie 1992, Peña 1994), as in the case of the analyzed designs. In addition, it presents high power with a low probability of making a type 1 error, manifested in the high negative correlations between powers and probability values of type 1 error (with or without data transformation).
The high negative correlations between power and probability of type 1 error, for the non-parametric test, are due to this last, regarding the parametric one (under the assumption of normal distribution), shows high relative asymptotic efficiency (RAE), which is 95.5%. This corresponds to the criterion of power-efficiency, stated by Siegel (1970), Siegel and Castellan (1995), de Calzadilla (1999), who suggested that, in order to achieve similar results regarding rejection of null hypothesis (H0), the non-parametric test should have a sample size of 100 observations and the parametric one, around 95.
Although sample size is not importantly associated with the analyzed indicators, it is an aspect that should be considered due to its importance for researches. Torres and Cobo (2015) state that nowadays there are no studies on this subject or it is not deeply studied.
The obtained results evidenced the relations among the analyzed statistical indicators, from the high degree of positive correlation among the probability values of type 1 error in the Fisher F test (with or without transformation) and the non-parametric homologue test, as well as the high negative correlations of them with power values (with and without data transformation). This supposes the use of the categorical principal component analysis for an integral evaluation of statistical indicators of models of parametric and non-parametric analysis of variance. It is necessary to continue the study for different data distributions and sample sizes.
REFERENCES
de Calzadilla, J. 1999. Procedimientos de la Estadística no paramétrica. Aplicaciones en las Ciencias Agropecuarias. M.Sc. Thesis, Instituto Nacional de Ciencias Agrícolas, Cuba.
De Calzadilla, J., Guerra, W. & Torres, V. 2002. “Use and misuse of mathematical transformations. Applications in models of analysis of variance”. Cuban Journal of Agricultural Science, 36 (2): 101–104, ISSN: 2079-3480.
Di Rienzo, J. A., Casanoves, F., Balzarini, M. G., González, L., Tablada, M. & Robledo, C. W. 2012. InfoStat. version 2012, [Windows], Universidad Nacional de Córdoba, Argentina: Grupo InfoStat, Available: <http://www.infostat.com.ar/> .
Gómez, V. M. Á. 2005. Inferencia estadística. Díaz de Santos, 544 p., ISBN: 978-84-7978-687-8, Available: <https://books.google.com.cu/books?hl=es&lr=&id=MlgqjIRE_MUC&oi=fnd&pg=PA207&dq=G%C3%B3mez+2005+Inferencia+estad%C3%ADstica&ots=Vz0rDN8OC2&sig=8y_gzxQFQklmbfOtRTxsr6RBuVU&redir_esc=y#v=onepage&q=G%C3%B3mez%202005%20Inferencia%20estad%C3%ADstica&f=false>, [Consulted: April 19, 2016].
Hair, J. 1999. Análisis multivariante de datos. Prentice E. & Cano D. (trans.), Edición: 5 ed., Madrid: PRENTICE HALL, 832 p., ISBN: 978-84-8322-035-1, Available: <https://www.amazon.es/An%C3%A1lisis-multivariante-datos-Joseph-Hair/dp/8483220350>, [Consulted: April 19, 2016].
IBM Corporation 2010. IBM SPSS Statistics. version 19, [Windows], Multiplataforma, U.S: IBM Corporation, Available: <http://www.ibm.com> .
Levene, H. 1960. “Robust tests for the equality of variance”. In: Olkin I., Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling, Stanford University Press, pp. 278–292, ISBN: 978-0-8047-0596-7, Available: <https://books.google.com.cu/books?hl=es&lr=&id=ZUSsAAAAIAAJ&oi=fnd&pg=PA3&dq=Contributions+to+Probability+and+Statistics&ots=GchNfCzOVQ&sig=-W3BeBmuWhTzgRCkktOdQjq0Di4&redir_esc=y#v=onepage&q=Contributions%20to%20Probability%20and%20Statistics&f=false>, [Consulted: April 19, 2016].
Molina, M. Ó. & de los Monteros, P. E. 2010. “Rotación en análisis de componentes principales categórico: un caso práctico”. Metodología de Encuestas, 12 (1): 63–88, ISSN: 15757803.
Navarro, C. J. M., Casas, C. G. M. & González, R. E. 2010. “Análisis de Componentes Principales y Análisis de Regresión para Datos Categóricos. Aplicación en la Hipertensión Arterial”. Revista de Matemática: Teoría y Aplicaciones, 17 (2): 199–230, ISSN: 2215-3373, DOI: 10.15517/rmta.v17i2.2128.
Peña, S. de R. 1994. Estadística: Modelos y Métodos. 2nd ed., Madrid: Alianza Universal Textos, 745 p.
Shapiro, S. S. & Wilk, M. B. 1965. “An Analysis of Variance Test for Normality (Complete Samples)”. Biometrika, 52 (3/4): 591–611, ISSN: 0006-3444, DOI: 10.2307/2333709.
Siegel, S. 1970. Diseño experimental no paramétrico aplicado a las ciencias de la conducta. Revolucionaria ed., Habana, Cuba: Instituto Cubano del Libro, 346 p., Available: <http://www.sidalc.net/cgi-bin/wxis.exe/?IsisScript=bac.xis&method=post&formato=2&cantidad=1&expresion=mfn=032983>, [Consulted: April 19, 2016].
Siegel, S. & Castellan, N. 1995. Estadística no paramétrica aplicada a las ciencias de la conducta. 4th ed., México: Trillas, 432 p., ISBN: 968-24-5101-9, Available: <http://www.sidalc.net/cgi-bin/wxis.exe/?IsisScript=CAMZA.xis&method=post&formato=2&cantidad=1&expresion=mfn=014608>, [Consulted: April 19, 2016].
StatSoft 2007. STATISTICA (data analysis software system). version 8.0, [Windows], US: StatSoft, Inc., Available: <http://www.statsoft.com> .
Steel, R. G. & Torrie, I. H. 1992. Bioestadística: principios y procedimientos. México: McGraw-Hill Interamericana, 228 p.
Torres, V. & Cobo, R. 2015. “Applied Mathematics in researches from the Instituto de Ciencia Animal. Fifty years of experience”. Cuban Journal of Agricultural Science, 49 (2): 117–125, ISSN: 2079-3480.
Vásquez, R. E. 2011. Contribución al tratamiento estadístico de datos con distribución Binomial en el Modelo de Análisis de Varianza. Ph.D. Thesis, Instituto Nacional de Ciencias Agrícolas, Cuba.
Vázquez, Y. 2012. Modelación Estadístico-Matemática con variables mixtas para el estudio de la sostenibilidad social en una empresa ganadera bovina. Ph.D. Thesis, Instituto Nacional de Ciencias Agrícolas, Cuba.
Received: 11/2/2014
Accepted: 1/6/2016
Magaly Herrera, Instituto de Ciencia Animal, Apartado Postal 24, San José de las Lajas, Mayabeque, Cuba. Email: mvillafranca@ica.co.cu


{kind=link}
{kind=link}
{kind=link}
{kind=link}