










My SciELO
 Custom services
Custom servicesServices on Demand
Journal

Article
 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkCuban Journal of Agricultural Science
Print version ISSN 0864-0408On-line version ISSN 2079-3480
Cuban J. Agric. Sci. vol.53 no.1 Mayabeque Jan.-Mar. 2019 Epub Jan 18, 2019
Biomatemática
Modelo de regresión categórica para el análisis e interpretación de la potencia estadística
1Universidad Agraria de La Habana, Autopista Nacional y Carretera de Tapaste, San José de las Lajas, Mayabeque, Cuba
2Instituto de Ciencia Animal, Apartado Postal 24, San José de las Lajas, Mayabeque, Cuba
Se establecen criterios de valor teórico-práctico en modelos de análisis de varianza de efectos fijos (paramétricos y no paramétricos), a partir de un análisis integral de variables relacionadas con indicadores estadísticos y del diseño experimental, que incluye la potencia estadística como variable dependiente. La información analizada se seleccionó de investigaciones independientes, procesadas por el departamento de Biomatemática del Instituto de Ciencia Animal, desarrolladas en áreas de aves, cerdos, pastos y rumiantes. Los experimentos analizados se corresponden con diseños completamente aleatorizados (DCA), balanceados y de bloques al azar (DBA). Los resultados se procesaron por la dócima paramétrica F de Fisher y se compararon con las dócimas homólogas no paramétricas, Kruskal-Wallis y Friedman. Se seleccionaron 21 experimentos en total, 16 relacionados con el DCA y cinco con el DBA. Para el análisis de los datos, se conformó una matriz de datos con las nueve variables seleccionadas. Se considera, como el resultado más sobresaliente, la fuerte relación negativa que se manifiesta entre la potencia y la probabilidad de error tipo I en los modelos de análisis de varianza (paramétrico y no paramétrico). Esto es, a bajos valores de la probabilidad de error tipo I, altos valores de la potencia. Resulta conveniente, en próximos estudios, profundizar en los aspectos de tamaño de muestra, la distribución de la variable en estudio y el criterio de potencia-eficiencia (Asymptotic Relative Efficiency, ARE en inglés), en relación con la probabilidad de error tipo I y la potencia.
Palabras clave: Indicadores estadísticos y del diseño experimental; análisis de varianza paramérico y no paramétrico
Introducción
Bono y Arnau (1995), al revisar el desarrollo del concepto de potencia de una dócima, señalan que en la teoría desarrollada por Neyman y Pearson, de 1928 al 1933, la potencia de una dócima estadística es la probabilidad de resultados significativos. Su estimación, según indican estos autores, queda determinada por tres componentes básicos: tamaño de muestra, nivel de significación (α) y tamaño del efecto a detectar.
Existen dos formas de estimar la potencia: la prefijada (a priori) y a posteriori. La primera le indica al investigador sobre el tamaño de muestra necesario para una potencia adecuada y, con este fin, se han construido tablas de potencia. La potencia a posteriori, es importante en la interpretación de los resultados de estudios terminados, como es el caso de este trabajo, cuyo propósito es alertar sobre la conducta a seguir en investigaciones futuras.
Scheffé (1959) aborda la potencia de la dócima F de Fisher en modelos de análisis de varianza (ANAVA), con efectos fijos. Hace referencia a las tablas de potencia, calculadas para los valores de α = 0.01 y 0.05, y reproduce gráficos de potencia para la dócima F de Fisher.
Siegel y Castellan (1995), en el área de la estadística no paramétrica, introducen el concepto de potencia - eficiencia o eficiencia asintótica relativa, usualmente conocida como ARE (del inglés, Asymptotic Relative Efficiency) o eficiencia de Pitman. Diversos autores (De Calzadilla 1999, Guerra et al. 2000, Cristo 2001, De Calzadilla et al. 2002, Vásquez 2011 y Cabrera et al. 2012) realizaron evaluaciones empíricas para valorar la conveniencia de la aplicación de los modelos de análisis de varianza, paramétrico y no paramétrico, con enfoques univariados y bivariados.
Menchaca (1974, 1975), Venereo (1976), Caballero (1979) y Menchaca y Torres (1985) aportaron tablas de tamaños de muestra y número de réplicas en modelos de análisis de varianza, asociados a los diseños completamente aleatorizados, bloques al azar, cuadrado latino y de cambio. En ellos incluyen la máxima diferencia estandarizada entre dos medias (Δ), la cantidad de tratamientos (t), el nivel de significación (α) y la potencia de la dócima (1-β). Estas tablas representan valiosas herramientas de trabajo para investigadores de diferentes ramas. En la actualidad, con el avance de la informática, existen paquetes estadísticos que incluyen el cálculo de la potencia, como el InfoStat, G Power y el SPSS, entre otros.
Con los antecedentes establecidos, se decidió utilizar otra vía de análisis e interpretación de la potencia estadística mediante un análisis integral de variables (numéricas y categóricas) que pueden incidir en ella, asociadas con indicadores estadísticos y del diseño experimental. Para ello, se consideró conveniente aplicar un análisis de regresión categórica (CATREG, siglas en inglés de categorical regression).
Se propone establecer criterios de valor teórico - práctico, a partir de un análisis integral de variables asociadas con la potencia estadística, en modelos de análisis de varianza de efectos fijos (paramétricos y no paramétricos).
Materiales y Métodos
La información analizada se seleccionó de las bases de datos con variables numéricas (conteos y proporciones), procesadas por el departamento de Biomatemática del Instituto de Ciencia Animal, de 2003 - 2011, ubicado en San José de las Lajas, provincia Mayabeque. Los datos procesados corresponden a investigaciones independientes, desarrolladas en áreas de aves, cerdos, pastos y rumiantes, asociados a los diseños completamente aleatorizados (DCA) balanceados y de bloques al azar (DBA).
Los resultados experimentales se analizaron según los correspondientes modelos de análisis de varianza paramétricos (simple y doble) y las docimas homólogas no paramétricas Kruskal-Wallis y Friedman, respectivamente. En cada caso, se recogió como variables asociadas con indicadores estadísticos, la probabilidad de error tipo I de las dócimas paramétricas y no paramétricas, distribución de la variable respuesta (en general fue Normal, Binomial y Poisson), potencia de la dócima F de Fisher, tamaño de muestra en el diseño experimental y cumplimiento de los supuestos básicos del ANAVA. El resto de las variables se corresponde con el diseño experimental.
La cantidad de experimentos y variables por diseño experimental son:
Se conformó una matriz de datos con las siguientes variables:
Tipo de experimento
Tipo de diseño experimental
Número de tratamientos
Cumplimiento de los supuestos teóricos
Probabilidad de error tipo I de la dócima F de Fisher
Probabilidad de error tipo I de las dócimas homólogas no paramétrica
Potencia de la dócima F de Fisher
Tamaño de muestra en el diseño experimental
Distribución de la variable
Para establecer la relación de la potencia de la dócima F de Fisher con el resto de las variables, se aplicó el análisis de regresión categórica, por la presencia de variables numéricas (3 y 5 al 8) y categóricas (1; 2; 4 y 9).
De acuerdo con los criterios de Meulman y Heiser (2010) y las aplicaciones realizadas por Navarro et al. (2010), Vázquez (2012) y Guerra et al. (2014), en las Ciencias Agropecuarias y otras, las características generales del CATREG se resumen en los siguientes aspectos:
Se basan en la Metodología de Escalamiento Óptimo, propuesta por la escuela holandesa de escalamiento de datos, con numerosos aportes del Grupo de Teoría de Sistema de Escalamiento de Datos en la Universidad de Leiden, en Holanda, implementados con los créditos de dicho grupo por IBM SPSS Statistics, en diferentes versiones.
Resulta adecuado para datos que son difíciles o imposibles de analizar mediante los métodos de la estadística clásica.
Las cuantificaciones óptimas de cada variable, se obtienen por el método de los mínimos cuadrados alternantes (minimiza la función de pérdida de información).
Las cuantificaciones de cada variable se mejoran por procedimientos iterativos.
Las variables cuantificadas tienen propiedades métricas.
Amplía el método clásico de análisis de regresión, mediante el escalamiento óptimo de variables nominales, ordinales y numéricas, simultáneamente.
Se obtiene una ecuación de regresión lineal, óptima para las variables transformadas.
Los coeficientes de regresión estimados reflejan los cambios que producen las variables predictoras en la variable respuesta.
Las cuantificaciones óptimas reflejan las características de las variables originales.
Los indicadores de las variables categóricas deben ser enteros positivos.
Solo permite una variable respuesta y un máximo de 200 variables predictoras.
En el análisis de CATREG se incluyen aspectos característicos del análisis de regresión clásico: coeficiente de determinación (R2), análisis de varianza en la regresión y significación de los parámetros del modelo. Como elementos complementarios de este análisis, se incluyen para el análisis otros indicadores:
Importancia: medida de la importancia relativa de las variables predictoras, dada por Pratt (1987).
Tolerancia: representa la proporción de la variación de cada variable predictora, que no es explicada por las otras. Representa una protección ante la multicolinealidad (Hair et al. 1999).
Para el procesamiento de la información, se seleccionó del análisis de regresión la opción escalamiento óptimo (CATREG), del software estadístico SPSS versión 22.0 (2013).
Resultados y Discusión
En la aplicación del análisis de regresión categórica, se consideró la potencia como variable dependiente, para analizar su relación con el resto de las variables. En la tabla 1, se refleja el alto valor del coeficiente de determinación (R2), acompañado por la significación del modelo, que indica que la potencia presenta una buena explicación por parte de las variables analizadas.
La tabla 1 incluye los coeficientes de regresión parcial, estandarizados con su significación estadística, al considerar los resultados del ANAVA paramétrico, excepto la probabilidad de error tipo I (valor p). El resto de los indicadores no muestra aportes estadísticos significativos para la explicación de la potencia (valor p > 0,05). Se considera que es necesario tener en cuenta en próximas investigaciones, el tamaño de muestra, por su conocida incidencia en la potencia y por la significación mostrada (valor p = 0.065).
Table 1 Fit of the CATREG model and significance of the regression coefficients with the parametric ANAVA

La incidencia significativa y negativa de la probabilidad de error tipo I en la potencia, al considerar el resto de las variables constantes, se corrobora con las altas correlaciones negativas de orden cero y parcial, que se observan en la tabla 2, entre la probabilidad de error tipo I y la potencia.

Se considera que existe correspondencia de los resultados antes mencionados con lo informado en la literatura especializada, específicamente por Mood y Graybill (1972) y Rodríguez (2008), quienes denotan la función de potencia como:

De este análisis se concluye que una dócima potente debe mostrar una baja probabilidad de error tipo I (rechazar la hipótesis nula siendo cierta) y alta potencia (rechazar la hipótesis nula siendo falsa), situación que debe estar en correspondencia con las características de la dócima en cuestión, en este caso la dócima F de Fisher.
Estas altas correlaciones negativas son corroboradas con los resultados de un estudio de simulación realizado por Vázquez (2011), donde se incluye el análisis de la potencia y la probabilidad de error tipo I, bajo el supuesto de distribución binomial. A ello se adiciona el trabajo de Herrera (2014), en investigaciones de ciencia animal.
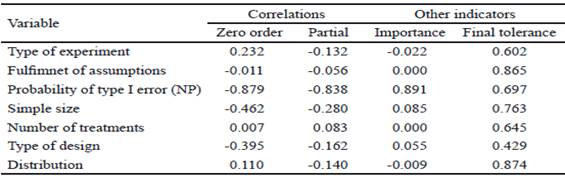
En la tabla 2 se destaca, por su importancia, la probabilidad de error tipo I, que es capaz de explicar 76.6 % de su variabilidad (dada por la tolerancia), siendo baja en el caso del número de tratamientos y tipo de diseño, y muy alta para el cumplimiento de los supuestos y la distribución de la variable.
La distribución de las variables analizadas que, en gran medida, corresponden a la distribución normal, binomial y Poisson, aunque no presenta una incidencia apreciable en la potencia, debe ser motivo de análisis en próximas investigaciones, al igual que el tamaño de muestra.
Por el alto nivel de coincidencias que presenta la toma de decisiones basadas en la probabilidad de error tipo I, de la docima F de Fisher del ANAVA, con sus homólogas no paramétricas (docimas Kruskal- Wallis y Friedman), se realizó un análisis comparativo de las probabilidades de error tipo I, mediante la dócima t de Student para muestras pareadas (tabla 3).

Como se puede observar en la tabla, no existen diferencias estadísticas significativas (P < 0.05) entre las probabilidades de error tipo I en cada diseño.
En este resultado se decide valorar el comportamiento del modelo CATREG, al sustituir los valores de la probabilidad de error tipo I de la dócima F de Fisher, por los correspondientes a las dócimas Kruskal- Wallis y Friedman (según el diseño). Se identifica esta variable en este análisis por probabilidad de error tipo I (NP). Los resultados obtenidos se reflejan en las tablas 4 y 5. Se observa que se mantiene incidencia muy significativa y negativa de la probabilidad de error tipo I (NP) en la potencia, al considerar el resto de las variables o indicadores constantes, muy similar a lo informado en la tabla 1.
Los resultados de la tabla 4 se corroboran con los indicadores de correlación de orden cero y parcial, que aparecen en la tabla 5. En cuanto a la importancia y la tolerancia (tabla 5), se reitera que la probabilidad de error tipo I (NP), se destaca por su importancia con respecto al resto de los indicadores, algo más baja para explicar su variabilidad (69.7 %).De igual forma, se considera la alta tolerancia de las variables cumplimiento de supuestos y distribución de la variable.
De los análisis realizados, se puede constatar que el indicador que presenta una fuerte relación negativa con la potencia, es la probabilidad de error tipo I en los modelos de ANAVA (paramétrico y no paramétrico). Esto es, a bajos valores de la probabilidad de error tipo I, altos valores de la potencia.
Table 4 Fit of the CATREG model and significance of the regression coefficients with the non-parametric ANAVA.

Se concluye que el uso del modelo de regresión categórica resulta una herramienta alternativa de análisis para valorar la incidencia de cada una de las variables seleccionadas de indicadores estadísticos y del diseño experimental, en la potencia estadística y en modelos de análisis de varianza de efectos fijos mediante la dócima F de Fisher con sus homólogas no paramétricas (dócimas de Kruskal-Wallis y Friedman). Se identifica la probabilidad de error tipo I como el indicador más importante que contribuye a explicar la potencia, y se evidencia la fuerte relación negativa entre la potencia y la probabilidad de error tipo I en los modelos de análisis de varianza (paramétrico y no paramétrico).
Se recomienda profundizar en los aspectos de tamaño de muestra, distribución de la variable analizada y el criterio de potencia- eficiencia, en relación con la probabilidad de error tipo I y la potencia, así como incorporar a los análisis resultados del modelo lineal generalizado, como otra alternativa a valorar.
References
Bono, R. y Arnau, J. 1995. Consideraciones generales en torno a los estudios de potencia. Revista Anales de Psicología. 11(1): 193-202. [ Links ]
Caballero, A. 1979. Tamaños de muestras en diseños completamente aleatorizados y bloques al azar donde la unidad experimental esté formada por grupos de animales. Revista Cubana de Ciencia Agrícola. 13 (3): 225-235. [ Links ]
Cabrera, A., Guerra, C. W., Herrera, M. & Suris, M. 2012. Non-parametric statistical methods and data transformations in agricultural pest population studies. Chilean Journal of Agricultural Research. 72(3): 440-443. [ Links ]
Cristo, M. 2001. Comportamiento de las dócimas no paramétricas respecto a las paramétricas en distribuciones no normales. Tesis presentada en opción al título de Master en Matemática. Universidad Central de Las Villa. Cuba. [ Links ]
De Calzadilla, J. 1999. Procedimientos de la Estadística no paramétrica. Aplicaciones en las Ciencias Agropecuarias. Master Thesis. Cuba. [ Links ]
De Calzadilla J., Guerra, W. & Torres, V. 2002. El uso y abuso de transformaciones matemáticas. Aplicaciones en modelos de análisis de varianza. Rev. Cubana Ciencia Agrícola. 36(1): 103-106. [ Links ]
Guerra, C. W., De Calzadilla, J. & Torres, V. 2000. Índice de eficiencia en relación con procedimientos de la estadística no paramétrica. Revista Cubana de Ciencia Agrícola 34 (1): 1-4. [ Links ]
Guerra, C. W., Herrera, M., Vázquez, Y. & Quintero, A. B. 2014. Contribución de la Estadística al análisis de variables categóricas: Aplicación del Análisis de Regresión Categórica en las Ciencias Agropecuarias. Revista Ciencias Técnicas Agropecuaria. 23(1): 68 - 73. [ Links ]
Hair, J. F., Anderson, R. E., Tatham, R. L. & Lack, W. C. 1999. Analisis Multivariate. Practice. Hall Iberia. Madrid. España. 799 p. [ Links ]
Herrera, M. 2014. Métodos Estadísticos alternativos de análisis con variables discretas y categóricas en investigaciones agropecuarias. PhD Thesis. ICA. Mayabeque. Cuba. 100p. [ Links ]
Menchaca, M. A. 1974. Tablas útiles para determinar tamaños de muestras en diseño de Clasificación Simple y de Bloques al Azar. Revista Cubana de Ciencia Agrícola. 8 (1) 111-116. [ Links ]
Menchaca, M. A. 1975. Determinación de tamaños de muestra en diseños Cuadrados Latinos. Revista Cubana de Ciencia Agrícola. 9 (1): 1-3. [ Links ]
Menchaca, M. A. & Torres, V. 1985. Tablas de uso frecuente en la Bioestadística. Instituto de Ciencia Animal. Cuba. [ Links ]
Meulman, J.J. & Heiser, W.J. 2010. SPSS versión 19.0 for Windows. Categories. Statistical Package for the Social Sciences. [ Links ]
Mood, A. M. & Graybill, F. A. 1972. Introducción a la teoría de la Estadística. Ediciones Aguilar S. A. Madrid. España. 536 p. [ Links ]
Navarro, J.M., Casa, G. & González, E. 2010. Análisis de Componentes Principales y Análisis de Regresión para datos categóricos. Aplicación en la Hipertensión Arterial. Revista de Matemática. Teorías y Aplicaciones. 17(2):199-230. [ Links ]
Pratt, J. W. 1987. Dividing the indivisible: Using simple symmetry to partition variance explained. In: Proceedings of the Second International Conference in Statistics, T. Pukkila, and S. Puntanen, eds. Tampere, Finland: University of Tampere. [ Links ]
Rodríguez, F. 2008. Estudio de métodos no paramétricos. Informe de pasantías presentado como requisito para optar al título de Licenciado en Matemática Mención Probabilidad y Estadística. Universidad Nacional Abierta, Centro Local Metropolitano. Caracas Venezuela.. [ Links ]
Scheffé, H. 1959. The Analysis of Varianza. John Wiley & Sons, Inc, New York. 477p. [ Links ]
Siegel, S. y Castellan, N. J. 1995. Estadística no paramétrica aplicada a las Ciencias de la Conducta. Cuarta edición. Editorial Trillas, México. p 57. [ Links ]
SPSS 2013. Version 22.0 for Windows. Statistical Package for the Social Sciences. IBM. [ Links ]
Vásquez, R. E. 2011. Contribución al tratamiento estadístico de datos con distribución Binomial en el Modelo de Análisis de Varianza. PhD Thesis. Instituto Nacional de Ciencias Agrícolas. Cuba. [ Links ]
Vázquez, Y. 2012. Modelación Estadístico - Matemática con variables mixtas para el estudio de la sostenibilidad social en una Empresa ganadera bovina. PhD Thesis. ICA. Mayabeque. Cuba. 100p. [ Links ]
Venereo, A. 1976. Número de réplicas en diseños cuadrados latinos balanceados para la estimación de efectos residuales. Revista Cubana de Ciencia Agrícola. 10(3): 237-246. [ Links ]
Recibido: 14 de Junio de 2018; Aprobado: 18 de Enero de 2019
 This is an open-access article distributed under the terms of the Creative Commons Attribution License
This is an open-access article distributed under the terms of the Creative Commons Attribution License
