










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Cubana de Ciencias Informáticas
versión On-line ISSN 2227-1899
Rev cuba cienc informat vol.7 no.1 La Habana ene.-mar. 2013
ARTÍCULO DE REVISIÓN
La web semántica: una breve revisión
The semantic web: a brief overview
Yusniel Hidalgo Delgado1*, Rafael Rodríguez Puente 2
1 Departamento de Programación. Facultad 3. Universidad de las Ciencias Informáticas, Carretera a San Antonio de los Baños, km 2 ½, Torrens, Boyeros, La Habana, Cuba. CP.: 19370. *Correo electrónico: yhdelgado@uci.cu
2 Facultad 3. Universidad de las Ciencias Informáticas, Carretera a San Antonio de los Baños, km 2 ½, Torrens, Boyeros, La Habana, Cuba. CP.: 19370
RESUMEN
La web actual posee algunas limitaciones a las cuales se hace necesario encontrarle soluciones prácticas. En este sentido Tim Berners-Lee ha definido el concepto de web semántica como una extensión de la web actual en la que no están presentes dichas limitaciones. En la última década han surgido un sinnúmero de trabajos teóricos y prácticos relacionados con la web semántica, evidenciando un importante impulso en su evolución. En este artículo se enuncian tres de las principales limitaciones presentes en la web actual: formato, integración y recuperación. Se describen además las principales tecnologías que han surgido en los últimos años para dar solución a las tres limitaciones anteriormente mencionadas. Finalmente, se presentan algunas de las principales áreas de aplicación de estas tecnologías en diferentes ámbitos, tanto en la academia como en la industria.
Palabras clave: Anotación semántica, datos enlazados, web semántica.
ABSTRACT
The current web has some limitations that are necessary to find a practical solution. In this sense Tim Berners-Lee, creator of the web, has defined the semantic web concept as the extension of the current web without these limitations. In the last decade, a great amount of theoretical and practical work related with the semantic web has emerged showing a significant boost in its evolution. In this paper three of the main limitations of the current web are shown. The main technologies that have emerged in the last few years for giving solution to the three mentioned limitations are presented. Finally, some of the main areas of application of these technologies are shown.
Key words: Linked data, semantic annotations, semantic web.
INTRODUCCIÓN
En 1989, un informático de la Organización Europea para la Investigación Nuclear (CERN, por sus siglas en Inglés) llamado Tim Berners-Lee crea la World Wide Web (WWW, por sus siglas en inglés). Tim, preocupado por la gestión de la información acerca de los aceleradores y experimentos que se hacían en el CERN, propuso una solución basada en un sistema distribuido de hipertextos que pretendía resolver el problema de la pérdida de la información y permitir el intercambio de información entre los científicos de dicho centro de investigación (Berners-Lee, 1989).
Fue por aquellos años que surgió el Identificador Uniforme de Recursos (URI, por sus siglas en inglés) para identificar inequívocamente un recurso, ya sea un servicio, una página o una dirección de correo en una red o sistema. También surgió el Protocolo para la Transferencia de Hipertextos (HTTP, por sus siglas en inglés) como protocolo para el intercambio de hipertextos y el Lenguaje de Marcado de Hipertextos (HTML, por sus siglas en inglés) para la presentación de la información.
En enero de 1993 eran conocidos 50 servidores HTTP en todo el mundo, cifra que se elevó a 200 en tan solo diez meses. Este fue el inicio de la explosión de la web, al punto de que a finales de 1994 existían más de 10.000 servidores y 10 millones de usuarios en el mundo (Berners-Lee, 1996; Cailliau, 1995).
En 1997, la cifra se elevó a más de 650.000 servidores web y en octubre del 2011, según las estadísticas publicadas por la Compañía de Servicios de Internet Netcraft, existían en el mundo 448.164.344 de estos servidores con aproximadamente 2.095.006.005 usuarios de Internet (Netcraft, 2011).
En octubre del 2011, el volumen de información existente en la web era enorme y siguió creciendo de manera exponencial. Según Netcraft (ver Figura 1) existen aproximadamente 506 millones de sitios web.
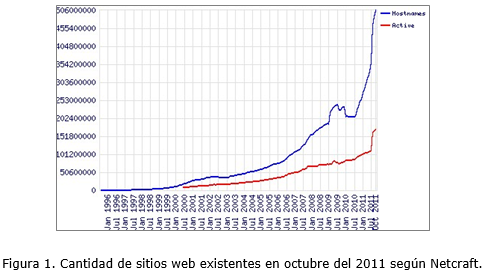
La primera versión de la web consistía en páginas HTML editadas manualmente las cuales enlazaban a otras páginas que a menudo eran escritas por personas con intereses comunes. Esta primera versión de la web se conoce en la literatura como web 1.0 y se extendió desde los años 1990 al 2000. En una etapa posterior la web se basa en la generación de sitios web dinámicos a partir de datos almacenados en bases de datos. En esta etapa no solo el administrador del sitio es capaz de gestionar los contenidos web, sino que el usuario final mediante interacción con formularios, también puede añadir nuevos contenidos a los ya existentes. En este sentido ha cobrado especial importancia el uso de wikis, blogs y foros de discusión (Fernández, 2009). Ver Figura 2.

En los últimos años ha cobrado especial interés el concepto de web semántica o web de los datos, lo que constituye una evolución natural de la web tradicional. La web semántica no constituye una web totalmente nueva, sino que constituye una extensión de la web tradicional en la que los datos poseen un significado comprensible por sistemas informáticos. La web semántica se soporta sobre la plataforma tecnológica de la web actual manteniéndose el uso del protocolo HTTP para el intercambio de datos.
En este artículo se describen los principales problemas existentes en la web actual así como algunas de las tecnologías de la web semántica que intenten resolver estos problemas. Finalmente se enuncian las principales áreas de aplicación en las cuales han sido utilizadas tecnologías de la web semántica en la solución de problemas concretos.
DESARROLLO
La web se ha convertido en un enorme repositorio de información textual semi-estructurada que abarca casi todas las áreas del conocimiento humano. La literatura universal, el conocimiento científico y la prensa digital son solo algunos de los contenidos web que consumen a diario millones de personas alrededor del mundo.
La web es ahora mucho más social. Solo en 2010 fueron creados aproximadamente 152 millones de blogs en Internet, registradas 175 millones de personas en Twetter y 600 millones en Facebook (Pingdom, 2011). A pesar de sus ventajas, la web posee algunos problemas que aún no han podido ser resueltos completamente, a continuación se describen los más relevantes:
Formato: la mayoría de los contenidos web actuales poseen algún grado de estructuración. Estos contenidos están creados en lenguaje HTML, el cual está orientado a la estructuración de documentos textuales en lugar de datos, es decir, los contenidos están diseñados para ser leídos por humanos, lo que significa que los sistemas computacionales no son capaces de procesar a gran escala y de forma automática la información de manera que les permita extraer su semántica.
Integración: el problema de la integración de los datos en la web, está estrechamente vinculado con el problema del formato. Los datos estructurados no son publicados de forma clara y precisa, lo que dificulta su extracción antes de ser usados. Los datos se encuentran dispersos, sin relación explícita entre ellos, imposibilitando su descubrimiento y utilización por sistemas informáticos. Sin este tipo de relación entre los datos, es prácticamente imposible razonar sobre los mismos, en aras de obtener su valor semántico útil para los sistemas de información.
Recuperación: el problema de la búsqueda y recuperación de los contenidos web, está estrechamente relacionado con los problemas del formato y la integración. Los resultados ofrecidos por motores de búsqueda como Google y Yahoo resultan imprecisos y, en muchos casos, no satisfacen las necesidades de búsqueda de los usuarios. Esto se debe a que están orientados a responder consultas basadas en palabras claves, no siendo capaces de recuperar la información a partir de consultas expresadas en lenguaje natural. Existen al menos tres tipos de situaciones que pueden producir estos errores: la sinonimia, la polisemia y el multilingüismo.
En el año 2001, Tim Berners-Lee publicó un artículo en donde alerta sobre la necesidad de extender la web actual para solventar los problemas descritos con anterioridad (Berners-Lee, et al., 2001). En dicho artículo, Tim propuso el concepto de web semántica y reveló sus implicaciones para el desarrollo futuro de la web. A continuación se sintetizan algunos elementos sobre la web semántica.
La web semántica
La web semántica no pretende sustituir la web actual, sino que es una extensión en la que la información tiene un significado bien definido posibilitando a los humanos y las computadoras trabajar en cooperación (Berners-Lee, et al., 2001).
La web semántica puede ser considerada como una evolución natural de la web actual en la que los datos son presentados en un formato único procesable por las computadoras. En este sentido, la World Wide Web Consortium (W3C) de conjunto con investigadores de todo el mundo, han venido trabajando en la última década en la definición de varios estándares, muchos de los cuales han sido utilizados en el desarrollo de múltiples aplicaciones.
Datos enlazados
Un aspecto clave que ha posibilitado el acelerado crecimiento de la web ha sido la posibilidad de que cualquiera, sin poseer profundos conocimientos de computación, pueda adicionar nuevos documentos enlazados a la web actual de manera que estos sean descubiertos por los motores de búsqueda y otras personas mediante navegadores web. Este mismo principio de enlazado puede ser aplicado a los datos en la web. En este sentido los datos enlazados proporcionan una solución técnica para realizar dicho enlazado.
Los datos enlazados se refieren a un conjunto de buenas prácticas para la publicación y enlazado de datos estructurados en la web. Estos datos enlazados provienen de diferentes fuentes de datos que pueden ser mantenidas por organizaciones con diferentes localizaciones geográficas. La idea básica de los datos enlazados es aplicar la arquitectura general de la web a la tarea de compartir datos estructurados a escala global (Berners-Lee, 2006).
En (Berners-Lee, 2006) se describen los cuatro principios básicos de los datos enlazados:
- Use URIs como nombres para las cosas.
- Use URIs HTTP, de modo que las personas puedan ver esos nombres.
- Cuando alguien ve una URI, proporciona información útil, usando los estándares (RDF, SQPRQL).
- Incluye enlaces a otras URIs, de modo que ellos puedan descubrir más cosas.
El primer principio propone el uso de URIs para identificar no solo documentos web y contenido digital, sino que también sirva para referenciar a objetos del mundo real y conceptos abstractos. El segundo principio propone el uso de URIs HTTP para identificar objetos y conceptos abstractos, posibilitando que estas URIs estén desreferenciadas sobre el protocolo HTTP y en cambio den una descripción del objeto o concepto identificado. El tercer principio propone el uso de un único modelo de datos para publicar datos estructurados en la web. El cuarto principio propone el uso de hiperenlaces para conectar no solo documentos web, sino cualquier tipo de cosa. Por ejemplo, un hipervínculo puede estar entre un lugar y una persona, o entre un lugar y una empresa.
Arquitectura de la web semántica
La Figura 3 muestra la arquitectura de referencia de la web semántica que fuera propuesta por Tim Berners-Lee en 2001. Desde su concepción inicial, esta arquitectura ha tenido cambios significativos, de forma que el propio Berners-Lee ha propuesto otras tres versiones de la misma (Gerber, et al., 2008).
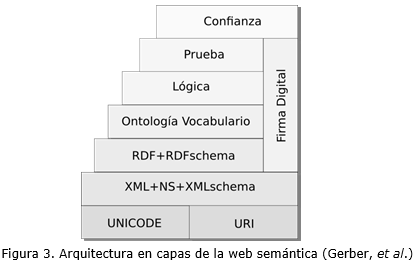
En (Al-Feel, et al., 2009) se propone una nueva arquitectura compuesta por 11 capas horizontales y una capa vertical. Algunas características de esta nueva aproximación son:
- Se sigue el mismo principio de la arquitectura de 7 capas del modelo Open Systems Interconnected (OSI, por sus siglas en inglés) en la que las capas están unas encima de las otras a diferencia de otras aproximaciones en las que las capas pueden coexistir en un mismo nivel.
- Las capas describen funcionalidades y no tecnologías, teniendo en cuenta que las tecnologías pueden cambiar en el tiempo, permitiendo a la arquitectura mantener su consistencia independientemente de las tecnologías que se utilicen en su implementación.
Los criterios que se tuvieron en cuenta para su evaluación fueron los formulados en el método propuesto por Gerber, et al., (2007). Estos criterios son:
- Contexto claramente definido.
- Nivel de abstracción adecuado.
- Ocultar los detalles de implementación innecesarios.
- Funciones de las capas claramente definidas.
- Apropiada especificación de las capas (interfaces y las dependencias existentes entre las capas).
- Modularidad.
A continuación se describen algunas de las tecnologías y estándares más utilizados en el desarrollo de soluciones basadas en la web semántica:
XML (del inglés, eXtensible Markup Language): es un Lenguaje de Etiquetado Extensible ampliamente utilizado en la estructuración, almacenamiento e intercambio de una gran variedad de datos entre sistemas de información. Su función es describir los datos en vez de mostrarlos (Quin, 2011).
XMLNS: los espacios de nombre XML proporcionan un método simple para cualificar elementos y nombre de atributos usados en documentos XML asociando estos con un espacio de nombre identificado por referencias URI. Proporciona un método para evitar conflictos de nombres de los elementos (Bray, et al., 2009).
XML Schema: los esquemas XML expresan vocabularios compartidos y permitir que las máquinas puedan realizar las reglas hechas por personas. Proporcionan un medio para la definición de la estructura, el contenido y la semántica de los documentos XML con más detalle. XML Schema fue aprobado como Recomendación del W3C, el 2 de mayo de 2001 y una segunda edición que incorpora muchas erratas se publicó el 28 de octubre 2004.
RDF (del inglés, Resource Description Framework): dado que los datos en la web semántica están altamente distribuidos, la descripción de los recursos debería estar codificada en una forma que facilite su integración desde múltiples fuentes de dato. RDF es un modelo de datos en forma de grafo dirigido y etiquetado que permite describir recursos. Un grafo RDF puede estar serializado en múltiples formas, siendo la serialización XML una de las más utilizadas.
SPARQL: SPARQL Protocol and RDF Query Language, es un lenguaje declarativo de consultas similar a SQL que permite realizar consultas sobre los datos en un grafo RDF. El resultado de las consultas pueden ser un conjunto de resultados o grafos RDF.
OWL (del inglés, Web Ontology Language): es un lenguaje de la web semántica diseñado para representar conocimiento complejo acerca de cosas, grupos de cosas y relaciones entre las cosas. Es un lenguaje basado en lógica computacional de modo que el conocimiento expresado en OWL puede ser razonado por programas de computadoras que verifican la consistencia del conocimiento permitiendo que conocimiento implícito se convierta en conocimiento explícito. Los documentos OWL, conocidos como ontologías, pueden ser publicados en la web los cuales pueden incluso hacer referencia hacia o desde otras ontologías OWL.
RDFa (RDF, por sus siglas en inglés, annotations): es una especificación que permite expresar datos estructurados como atributos en algún lenguaje de marcado. Un recurso representado en este formato mostrará información legible tanto para un navegador web como para aplicaciones que analicen código RDF, ya que toda la información semántica está incrustada como metadatos de la página web (Adida y Birbeck, 2008).
SKOS (del inglés, Simple Knowledge Organization System): es un modelo de datos común para compartir y enlazar datos en sistemas de organización de conocimiento en la web. Muchos sistemas de organización de conocimiento tales como tesauros, taxonomías, esquemas de clasificación y sistemas de encabezado de temas, comparten una estructura similar y son utilizados en aplicaciones similares. SKOS es capaz de capturar muchas de estas similitudes y hacerlas explícitas, permitiendo compartir datos y tecnologías entre diversas aplicaciones.
RIF (del inglés, Rule Interchange Format): el objetivo de RIF es definir un estándar para el intercambio de reglas entre sistemas de reglas y en particular, entre motores de reglas para la web. Junto con este estándar se definió una familia de lenguajes llamados dialectos.
Todas las tecnologías y estándares descritos anteriormente permiten la incorporación de la información semántica necesaria en los sistemas de información, siendo las anotaciones semánticas una vía para acometer dicho propósito.
Anotación semántica
La anotación semántica se refiere al proceso mediante el cual se adicionan metadatos semánticos a los recursos web (Sánchez y Fernández, 2005). Una anotación semántica combina conceptos de metadatos y ontologías, es decir, los campos de los metadatos son asociados con términos en una ontología, los cuales son usados para describir estos campos (Macário, et al., 2010).
Las anotaciones semánticas se pueden clasificar en: manuales, semi-automáticas y automáticas. Las anotaciones manuales son realizadas generalmente por un anotador humano con la ayuda de un sistema de anotación de textos que vincula los términos de una ontología con los recursos web. Sus principales debilidades radican en que las anotaciones se ven afectadas por factores como: la experticia del anotador sobre el dominio de la información, la motivación personal y su entrenamiento en el proceso de anotación. La anotación semi-automática es realizada por herramientas que explotan técnicas de Procesamiento del Lenguaje Natural (PLN) para encontrar las referencias en el texto a los conceptos existentes en ontologías. Este tipo de herramientas necesitan como entrada un corpus de documentos previamente anotados para que sirvan para entrenar el sistema de anotación (Sánchez y Fernández, 2005). En el caso de la anotación automática, aún queda mucho por hacer, aunque se han obtenido algunos resultados interesantes como el propuesto en (Macário, et al., 2010) en el cual se obtiene un sistema de anotación automática para fuentes de datos espaciales utilizando flujos de trabajo científicos.
Aplicaciones de la web semántica
La web semántica, a pesar de que aún no está generalizada debido en gran medida a la madurez de las tecnologías existentes, tiene un sinnúmero de aplicaciones, a continuación se mencionan algunas de ellas:
- Gestión de documentos digitales: uno de los aspectos novedosos relacionados con la web semántica es la introducción de las anotaciones semánticas como se describió anteriormente. El sistema SABIOS permite mejorar los procesos de inserción, catalogación y recuperación de documentos digitales a través de uso de las anotaciones semánticas combinado con sistemas Multiagentes (Guzmán, et al., 2007).
- Tesauros documentales: en (Pérez, 2004) se presenta una propuesta básica de automatización y utilización de tesauros documentales en entornos distribuidos de recuperación de información mediante servicios web basados en RDF.
- Visualización de información: la web semántica y sus características han permitido adaptar la visualización de la información para que tome ventaja de las propiedades que ofrecen las ontologías (Chen, 2002; Georgieva, 2005). Es aquí donde se habla de visualización de información basada en ontologías (Fluit, et al., 2004).
- Gestión de información financiera y económica: en (Bravos, et al., 2004) se muestra una ontología para el dominio financiero y económico lo cual implicó una mejora en el diseño e integración de las aplicaciones desarrolladas por el grupo Analistas Financieros Internacionales (AFI), una empresa española que genera información financiera y económica diariamente. Los autores destacan que, luego de aplicar los resultados de su investigación, se obtienen resultados más precisos en las búsquedas así como relaciones que antes no aparecían.
- Entornos universitarios: en (Uribe, 2010) se propone una clasificación de las aplicaciones semánticas según la utilidad que pueden tener para los integrantes de una comunidad universitaria: estudiantes, profesores, investigadores y administradores. En este trabajo se muestran varias herramientas consideradas como parte de la web semántica así como la utilidad que tienen. El autor concluye que estas herramientas tienen potencialidad para la gestión de información y del conocimiento, entre lo que se puede mencionar la localización, selección, recuperación, organización, evaluación, producción y divulgación en forma adecuada y eficiente de la información, ello muestra una necesidad de alfabetización informacional.
- Gestión de referencias bibliográficas: el proyecto de curso (Galey, 2010) obtuvo como resultado el desarrollo de un gestor bibliográfico que facilita el tratamiento de referencias y ofrece la posibilidad de traducir entre varios formatos de publicaciones, centrándose en tecnologías de la web semántica.
- Buscadores semánticos: los buscadores semánticos han dejado los laboratorios de investigación para convertirse en aplicaciones funcionales. Uno de los primeros buscadores semánticos es SWOOGLE (Ding, et al., 2004) el cual extrae metadatos a partir documentos RDF y OWL. También es capaz de encontrar las relaciones existentes entre dichos documentos. En el 2006 surge SemSearch (Lei, et al., 2006), un buscador semántico orientado a usuarios comunes que no están familiarizados con las tecnologías de la web semántica o con el dominio específico de los datos semánticos. En (D’Aquin y Motta, 2011) se presenta Watson, un buscador semántico que proporciona un conjunto de APIs que contienen funciones de alto nivel para encontrar, explorar y consultar datos semánticos y ontologías que han sido publicadas en línea.
Por otra parte, existe una lista de casos de estudio publicados en (Baker, et al., 2009) que incluyen la descripción de sistemas que han sido desplegados en organizaciones utilizando técnicas y tecnologías de la web semántica, entre ellos se pueden mencionar:
- Un archivo digital de música para la emisora nacional de Noruega.
- Un repositorio semántico de contenidos web para la investigación clínica.
- Un motor de búsqueda para servicios en línea de las administraciones públicas.
- Una ontología del patrimonio cultural de Cantabria.
- Un marco de trabajo para referencias geográficas.
CONCLUSIONES
- La web actual presenta un conjunto de limitaciones a las cuales es deseable encontrarle una solución práctica. Estas limitaciones son: formato, integración y recuperación.
- La web semántica ha dejado de ser un concepto abstracto para materializarse en diversos proyectos, tanto en la academia como en la industria, con un alto valor para el progreso social.
- En la última década, la comunidad científica se ha concentrado en el desarrollo de tecnologías y estándares que dinamicen el crecimiento de la web semántica, permitiendo así la construcción de una web dotada de mucho más significado, el cual puede ser procesado tanto por los humanos como por las máquinas.
- Los motores de búsqueda semánticos han comenzado a emerger como una de las aplicaciones más prometedoras de las tecnologías de la web semántica, proporcionando una solución eficiente a las limitaciones presentes en los motores de búsquedas tradicionales en los que las consultas son basadas en palabras claves, por lo que no tienen en cuenta la semántica de la necesidad de información expresada.
- Teniendo en cuenta las aplicaciones de la web semántica, mencionadas, se puede apreciar que los problemas de la web actual han sido parcialmente resueltos en algunos ámbitos de aplicación.
REFERENCIAS BIBLIOGRÁFICAS
ADIDA, B. y BIRBECK, M. RDFa primer [Consultado el: 9 de diciembre de 2011]. Disponible en: [http://www.w3.org/TR/xhtml-rdfaprimer/]
AL-FEEL, H.; M.A.KOUTB, et al. Toward an Agreement on Semantic Web Architecture. En Proceedings of the International Conference on Information and Communication Technologies. France. 2009. p. 806-810.
BAKER, T.; HEATH, T., et al. Semantic Web Case Studies and Use Cases Disponible en: [http://www.w3.org/2001/sw/sweo/public/UseCases/]
BERNERS-LEE, T. Information Management: A Proposal [Consultado el: 19 de octubre de 2011]. Disponible en: [http://www.w3.org/History/1989/proposal-msw.html]
BERNERS-LEE, T. Linked Data [Consultado el: 19 de noviembre de 2011]. Disponible en: [http://www.w3.org/DesignIssues/LinkedData.html]
BERNERS-LEE, T. The World Wide Web: Past, Present and Future [Consultado el: 19 de octubre de 2011]. Disponible en: [http://www.w3.org/People/Berners-Lee/1996/ppf.html]
BERNERS-LEE, T.; HENDLER, J., et al. The Semantic Web. Scientific American Magazine, 2001, 29-37 p.
BRAVOS, J.; CARRAZANA, C., et al. Aplicación de tecnologías de la Web Semántica a la gestion de la información financiera y económica. En V Congreso Interacción Persona Ordenador. Universitat de Lleida. 2004.
BRAY, T.; HOLLANDER, D., et al. Namespaces in XML 1.0 Third Edition. ed. W3C, [Consultado el: 7 de diciembre de 2011]. (W3C Recommendations). Disponible en: [http://www.w3.org/TR/REC-xml-names/].
CAILLIAU, R. A Little History of the World Wide Web W3C, [Consultado el: 17 de noviembre de 2011]. Disponible en: [http://www.w3.org/History.html].
CHEN, C. Information Visualization Versus the Semantic Web. En Visualizing the Semantic Web. 2002.
D’AQUIN, M. y MOTTA, E. Watson, More Than a Semantic Web Search Engine. Semantic Web, 2011, Vol. 2, Nº p. 55-63. ISSN 1570-0844.
DING, L.; FININ, T., et al. Swoogle: A Semantic Web Search and Metadata Engine. En Thirteenth ACM Conference on Information and Knowledge Management. 2004. p. 652–659.
FERNÁNDEZ, L. C. Procedimiento semi-automático para transformar la web en web semántica. Phd, Departamento de Inteligencia Artificial. Universidad Nacional de Educación a Distancia, 2009.
FLUIT, C.; SABOU, M., et al. Supporting User Tasks through Visualization of Light-weight Ontologies. En Staab, S. y Studer, R. (editor). Handbook on Ontologies. Berlin: Springer-Verlag, 2004, p. 415-434.
GALEY SÁNCHEZ, J. M. Aplicación web semántica para la gestión de referencias bibliográficas. Tutor: Fernández Gil, A. y Ortiz Martín, R. Proyecto de Fin de Carrera, Rey Juan Carlos, 2010.
GEORGIEVA, R. Ontology-Based Information Representation. Joint Advanced Student School (JASS). Course 6: Next-Generation User-Centered Information Management. St. Petersburg: 2005, Disponible en: http://www14.in.tum.de/konferenzen/Jass05/courses/6/index.html.
GERBER, A.; MERWE, A. V. D., et al. A Functional Semantic Web Architecture. En Proceedings of the 5th European Semantic Web Conference on The Semantic Web: Research and Applications. Tenerife, Canary Islands, Spain. 2008. p. 273--287.
GERBER, A. J.; BARNARD, A., et al. Towards A Semantic Web Layered Architecture. En Proceedings of the 25th conference on IASTED International Multi-Conference: Software Engineering. Innsbruck, Austria. 2007. p. 353-362.
GUZMÁN LUNA, J. A.; TORRES PARDO, D., et al. SABIOS: una aplicación de la Web semántica para la gestión de documentos digitales. Revista Interamericana de Bibliotecología, 2007, vol. 30, Nº 1, p. 51-72.
LEI, Y.; UREN, V., et al. SemSearch: A Search Engine for the Semantic Web. En Knowlegde Engineering and Knowledge Managment Conference. 2006.
MACÁRIO, C. G. N.; SOUSA, S. R. D., et al. Play It again, SAM — Using Scientific Workflows to Drive the Generation of Semantic Annotations. En Sixth IEEE International Conference on e–Science. 2010.
NETCRAFT. October 2011 Web Server Survey Netcraft.com, [Consultado el: 17 de noviembre de 2011]. Disponible en: [http://news.netcraft.com/archives/2011/10/06/october-2011-web-server-survey.html#more-5024]
PÉREZ AGÜERA, J. R. Automatización de tesauros y su utilización en la web semántica. BiD: textos universitaris de biblioteconomia i documentació, 2004, Nº 13. Disponible en: [http://www.ub.edu/bid/13perez2.htm]
PINGDOM. Internet 2010 in numbers. [Consultado el: 17 de noviembre de 2011]. Disponible en: [ http://royal.pingdom.com/2011/01/12/internet-2010-in-numbers/]
QUIN, L. Extensible Markup Language (XML) W3C. [Consultado el: 7 de diciembre de 2011]. Disponible en: [http://www.w3.org/XML/]
SÁNCHEZ, L. y FERNÁNDEZ, N. La web semántica: fundamentos y breve "estado del arte". Novatica, 2005, vol. XXXI, Nº 178, ISSN 0211-2124.
URIBE TIRADO, A. La web semántica y sus posibles aplicaciones en las universidades. Acimed: Revista Cubana de información en Ciencias de la Salud, 2010, vol. 21, Nº 2. Disponible en: [http://www.acimed.sld.cu/index.php/acimed/article/view/41]
Recibido: 15 de enero de 2013.
Aprobado: 1 de marzo de 2013.

