










My SciELO
 Custom services
Custom servicesServices on Demand
Journal

Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkRevista Cubana de Ciencias Informáticas
On-line version ISSN 2227-1899
Rev cuba cienc informat vol.9 no.4 La Habana Oct.-Dec. 2015
ARTÍCULO ORIGINAL
Algoritmo para la identificación de variantes de procesos
Algorithm for variants process identification
Damián Pérez Alfonso1*, Raykenler Yzquierdo Herrera1, Eudel Pupo Hernández1, Reynaldo López Jiménez1
1 Facultad 3. Universidad de las Ciencias Informáticas. Carretera a San Antonio de los Baños, Km 21/2, Torrens, Boyeros, La Habana, Cuba. CP.: 19370
*Autor para la correspondencia: dalfonso@uci.cu
RESUMEN
La minería de proceso es una disciplina que impulsa el desarrollo de técnicas y herramientas para analizar los procesos partiendo de los registros de eventos. Las técnicas de minería de proceso son utilizadas en diferentes etapas de la gestión de procesos de negocio, incluyendo el diagnóstico. El diagnóstico del proceso ayuda a tener una visión general del proceso y de los aspectos más significativos del mismo. Las técnicas de minería de proceso para el diagnóstico son afectadas por el ruido y la ausencia de información en los registros de eventos. Esto dificulta la identificación de los patrones de control de flujo del proceso, limitando la consecución de los objetivos del diagnóstico. En este trabajo se propone un algoritmo para la identificación de variantes de modelos de proceso que considera el ruido y la ausencia de información en la identificación de los patrones de control de flujo. Utilizando una implementación de este algoritmo se experimentó con registros de eventos que combinan situaciones de ruido y ausencia de información. Los resultados obtenidos muestran que el algoritmo identifica correctamente los patrones de control de flujo, aún con la presencia de ruido y ausencia de información.
Palabras clave: algoritmo, minería de proceso, patrones de control de flujo, variantes de proceso
ABSTRACT
Process mining is a discipline that impulse tools and techniques development for process analysis, starting from event logs. Process mining techniques are used in differents stages of business process management, including diagnosis. Process diagnosis is useful to obtain a general process view, and it’s more significative elements. Event logs characteristics like noise and lack of information affects process mining techniques in process diagnosis stage. On these scenarios identification of control flow patterns become a rough task, so diagnosis objectives can be complicated to achieve. On this work, an algorithm for identification of process models variants is presented. The proposed solution takes into account the noise and lack of information. An experiment was performed with event logs that combine noise and lack of information, using an implementation of the algorithm proposed. Obtained results show that proposed algorithm identifies properly the control flow patterns even on events logs with noise and lack of information.
Key words: algorithm, control flow patterns, process mining, process variants
INTRODUCCIÓN
La Gestión de Procesos de Negocio (BPM) está orientada a la identificación y gestión sistemática de los procesos de una organización para el logro eficaz y eficiente de los objetivos de la empresa. Como parte de este modelo de gestión se han desarrollado sistemas de información para controlar la ejecución de los procesos, evaluar su funcionamiento y apoyar la toma de decisiones (Weske, 2007). Estos sistemas suelen poseer registros de eventos, donde almacenan información sobre la ejecución de los procesos que soportan. La minería de proceso es una disciplina dirigida al desarrollo de técnicas y herramientas para analizar los registros de eventos, extraer información a partir de ellos y presentar de forma explícita el conocimiento que contienen (van der Aalst, 2011). El estudio de los registros de eventos facilita el análisis del funcionamiento real de una empresa a partir de sus procesos y el orden en que se realizan (Outmazgin y Soffer, 2014).
El ciclo de vida de BPM abarca siete fases: diagnóstico, (re) diseño, análisis, implementación, (re) configuración, ejecución y ajuste (van der Aalst, 2011). El diagnóstico de proceso comprende el análisis de rendimiento, la detección de anomalías, la identificación de patrones comunes y de desviaciones en el proceso (Bose, 2012). Las técnicas de minería de proceso para el diagnóstico identifican los comportamientos registrados con mayor frecuencia, lo que posibilita dirigir la mejora del proceso hacia los elementos más críticos. También detectan ejecuciones anómalas en el registro de eventos lo cual brinda información acerca de posibles fraudes o violaciones en las políticas (Bose, 2012). Adicionalmente, la identificación y tratamiento del ruido y la ausencia de información, así como la identificación de patrones de control de flujo son relevantes para el diagnóstico, por su repercusión en la comprensión del proceso y de las relaciones entre sus actividades (De Weerdt et al., 2012).
En minería de proceso se considera ruido al comportamiento raro e infrecuente contenido en el registro de eventos y que no es representativo del comportamiento común del proceso. Aunque en ocasiones se ve como el resultado de errores ocurridos al registrar los eventos, no existe una forma explícita de identificar en el registro dichos errores, por lo cual se debe considerar el ruido como desviaciones del proceso (van der Aalst, 2011).
La identificación de patrones de control de flujo permite determinar las actividades que se realizan sincrónicamente, los bloques de actividades que se repiten, el orden en que se ejecutan determinadas actividades y otros comportamientos relevantes en el proceso (Bose, 2012). El tratamiento del comportamiento infrecuente es relevante para los algoritmos que identifican patrones de control de flujo. Descartar el ruido equivale a eliminar comportamiento del proceso y considerarlo puede conducir a modelos poco estructurados y complejos. Los algoritmos se basan en el descubrimiento del comportamiento más común, a partir del número de repeticiones de sucesiones directas de las parejas de eventos, denominada envergadura de evento y del número de trazas idénticas, llamado envergadura de traza (Bratosin, 2011).
Para identificar los patrones de control de flujo es necesario que el registro de eventos contenga información suficiente, es decir, posea un nivel de completitud tal que sus trazas sean representativas del comportamiento el proceso (van der Aalst et al., 2004). La completitud puede ser afectada por la ausencia de información, se denomina de esta forma a la ausencia de evidencia en el registro de eventos de la ejecución de algunas tareas del proceso. Estas tareas invisibles pueden no haber sido registradas debido a errores, a que el sistema de información no deja huella de su ejecución o a que no fueron informatizadas (Yzquierdo-Herrera, 2012).
Las técnicas de diagnóstico Análisis de Diagramas de Puntos (Molka et al., 2013) y Visualización de Flujo y Alcance (Gunther, 2009) no son capaces de identificar patrones de control de flujo y solo muestran una vista general del proceso. Por otra parte, la técnica Tandem Arrays (Bose y van der Aalst, 2009) extrae patrones de ejecución del registro de eventos, pero no obtiene las relaciones o dependencias entre ellos. La Minería Difusa (Gunther y van der Aalst, 2007) obtiene del registros de eventos un mapa del proceso que muestra las actividades y sus relaciones, aunque es robusta ante el ruido, no identifica los patrones de control de flujo. La Descomposición en Subprocesos utilizando bloques de construcción (Yzquierdo-Herrera et al., 2013) sí identifica los patrones de control de flujo presentes, considerando además la ausencia de información. Sin embargo, la identificación de los patrones se ve afectada por la presencia de ruido en los registros de eventos.
La detección de patrones de control de flujo, identificación y tratamiento del ruido y ausencia de información en los registros de eventos no son consideradas integralmente por las técnicas de diagnóstico de proceso. Esto se traduce en modelos complejos y desviados de la ejecución real, identificación errónea de los patrones de ejecución y contextualización incorrecta de las anomalías. Por tanto, debido a las limitaciones de las técnicas analizadas se dificulta la comprensión de la estructura del proceso, así como del comportamiento y las anomalías presentes en el registro de eventos, comprometiendo el cumplimiento de los objetivos del diagnóstico.
El algoritmo propuesto en el presente trabajo tiene como objetivo identificar los patrones de control de flujo considerando el ruido y la ausencia de información presente en el registro de eventos. En lugar de construir un único modelo a partir del registro de eventos se construye un árbol de variantes de modelos del proceso.
MATERIALES Y MÉTODOS
El algoritmo desarrollado utiliza como entrada un registro de eventos en formato XES cuyo contenido debe ser coherente con la definición 1 y definición 2 (tomadas de (van der Aalst, 2011)). Los patrones de control de flujo que se presentan en la Definición 3 se identifican a partir del comportamiento registrado (Definición 4).
El algoritmo busca varias descomposiciones alternativas para el mismo subproceso, utilizando diferentes patrones de control de flujo. Las alternativas se construyen, descartando o no, determinados comportamientos presentes en el registro de eventos. También se pueden construir, considerando o no, determinados comportamientos ausentes. Los comportamientos que son descartados como ruido y los que son asumidos como ausentes en una variante, no lo son en otra. Esto permite controlar el impacto estructural del ruido y la ausencia de información en la construcción de las alternativas. Las diferentes alternativas de descomposición que pueden existir en cada subproceso conforman variantes del proceso, concepción expuesta en la Definición 5.
Partiendo de las descomposiciones alternativas por cada subproceso, el algoritmo construye un modelo jerárquico que representa las diferentes variantes de modelos del proceso. Este modelo de proceso denominado Árbol de Variantes se presenta como parte de esta investigación y se describe en la Definición 6. En el Árbol de Variantes se utiliza un operador para representar cada patrón de control de flujo de la Definición 3: el operador → para el patrón Secuencia, ∧ para Paralelismo, × para Selección exclusiva, ∨ para Selección exclusiva ![]() y para el patrón Lazo.
y para el patrón Lazo.
El Árbol de Variantes de la Figura 1 representa el comportamiento contenido en un registro de eventos ![]() generado por un proceso conformado por los subprocesos del conjunto S={s1,s2,s3,s4,s5}. Como puede apreciarse, existen diferentes nodos operador para el mismo subproceso, los cuales pueden tener diferentes subárboles (s2) o no (s3).
generado por un proceso conformado por los subprocesos del conjunto S={s1,s2,s3,s4,s5}. Como puede apreciarse, existen diferentes nodos operador para el mismo subproceso, los cuales pueden tener diferentes subárboles (s2) o no (s3).

Algoritmo para la identificación de variantes de proceso
El algoritmo que se propone para identificar las variantes del proceso, a partir del comportamiento contenido en un registro de eventos, está compuesto por dos procedimientos que se realizan iterativamente, la descomposición en subprocesos (Algoritmo 1) y la búsqueda de variantes de descomposición a partir de la identificación de patrones de control de flujo (Algoritmo 2). Además, el segundo procedimiento incluye un algoritmo para determinar los estados vecinos en la búsqueda (Algoritmo 3).
El algoritmo de descomposición en subprocesos (Algoritmo 1) utiliza un registro de eventos L generado por un proceso P y umbrales de ruido y completitud (T) para construir un Árbol de Variantes VT. Siendo S el conjunto de todos los subprocesos del proceso P, para cada nuevo subproceso si∈ S, se busca una variante de descomposición según cada uno de los patrones de control de flujo.
Los umbrales definen con un número entre cero y uno la cantidad de comportamiento dentro de un subproceso que puede ser descartado o asumido como ausente para descomponer un subproceso considerando determinado patrón de control de flujo. Por ejemplo, un umbral de 0.2 para ruido en el patrón secuencia significa que hasta el 20% del comportamiento expresado en el registro de eventos puede ser descartado para encontrar una descomposición mediante secuencia. De manera similar, un 0.8 de completitud para paralelismo indica que el subproceso puede ser descompuesto mediante ese patrón conteniendo solamente el 80% del comportamiento necesario para ser identificado, ya que el 20% restante se asume como ausente.
La existencia de variantes de descomposición depende del comportamiento registrado por cada subproceso βi. Se denota con ![]() al comportamiento del proceso en si para el patrón que representa w y que no forma parte de βi. De manera similar se denota con
al comportamiento del proceso en si para el patrón que representa w y que no forma parte de βi. De manera similar se denota con ![]() al comportamiento en βi que se ajusta a la descomposición si mediante w. Se puede encontrar una variante de descomposición para si por un operador w siempre que
al comportamiento en βi que se ajusta a la descomposición si mediante w. Se puede encontrar una variante de descomposición para si por un operador w siempre que ![]() pueda ser descartado dentro del umbral de ruido y
pueda ser descartado dentro del umbral de ruido y ![]() pueda ser asumido según el umbral de completitud.
pueda ser asumido según el umbral de completitud.
Para encontrar una variante de descomposición en un subproceso si∈ S es necesario identificar un patrón de control de flujo, lo cual equivale a encontrar varios subprocesos ![]() , que cumplan con lo establecido en la Definición 3. En términos de Teoría de Conjuntos esto es igual a encontrar una partición de Xi (el conjunto de actividades que forman si). En principio pueden existir tantas descomposiciones por un patrón de control de flujo como particiones de Xi. Encontrar los sk es equivalente a encontrar las actividades que pertenecen a cada uno. Como una actividad puede pertenecer únicamente a un subproceso esto significa encontrar n conjuntos disjuntos de las actividades en Xi. De todas las particiones posibles por cada patrón de control de flujo solamente interesa la que mejor se ajusta a βi ,o sea, aquella que requiere descartar menos comportamiento de βi y asumir menos comportamiento ausente de βi para que los subprocesos sk cumplan con lo establecido en la Definición 3.
, que cumplan con lo establecido en la Definición 3. En términos de Teoría de Conjuntos esto es igual a encontrar una partición de Xi (el conjunto de actividades que forman si). En principio pueden existir tantas descomposiciones por un patrón de control de flujo como particiones de Xi. Encontrar los sk es equivalente a encontrar las actividades que pertenecen a cada uno. Como una actividad puede pertenecer únicamente a un subproceso esto significa encontrar n conjuntos disjuntos de las actividades en Xi. De todas las particiones posibles por cada patrón de control de flujo solamente interesa la que mejor se ajusta a βi ,o sea, aquella que requiere descartar menos comportamiento de βi y asumir menos comportamiento ausente de βi para que los subprocesos sk cumplan con lo establecido en la Definición 3.
La búsqueda de la mejor variante de descomposición para si por cada patrón se realiza mediante el procedimiento que se expone en el Algoritmo 2 y está basada en la Búsqueda de costo uniforme, la cual expande el nodo con menor costo de camino. Si el costo de cada paso es mayor o igual que una pequeña constante positiva ε, se garantiza que el método es completo y óptimo. La complejidad temporal y espacial del peor caso de este método de búsqueda pueden ser descritas por la ecuación ![]() , donde r es el factor de ramificación del árbol y C es el costo del camino de la solución óptima (Russell et al., 1995).
, donde r es el factor de ramificación del árbol y C es el costo del camino de la solución óptima (Russell et al., 1995).
En la búsqueda de variantes (Algoritmo 2) cada nodo en el espacio de búsqueda (ψn ) está definido por ![]() , el comportamiento no procesado
, el comportamiento no procesado ![]() , el comportamiento descartado ηw y el comportamiento asumido
, el comportamiento descartado ηw y el comportamiento asumido ![]() . Al adicionar nuevos nodos (ψn ), en caso de existir nodos con la misma descomposición
. Al adicionar nuevos nodos (ψn ), en caso de existir nodos con la misma descomposición ![]() , solamente permanece aquel con menor cantidad de comportamiento por procesar
, solamente permanece aquel con menor cantidad de comportamiento por procesar ![]() independientemente del costo de camino. El objetivo se alcanza cuando
independientemente del costo de camino. El objetivo se alcanza cuando ![]() ha sido procesado y
ha sido procesado y ![]() posee al menos dos conjuntos disjuntos.
posee al menos dos conjuntos disjuntos.
La creación de nuevos nodos de búsqueda, descrita en el Algoritmo 3, se realiza utilizando dos operadores. Si partiendo de ![]() al procesar un comportamiento
al procesar un comportamiento ![]() se genera una descomposición diferente
se genera una descomposición diferente ![]() se comprueba si bx puede descartarse y se genera un nuevo nodo. Si existe un comportamiento
se comprueba si bx puede descartarse y se genera un nuevo nodo. Si existe un comportamiento ![]() (comportamiento de si según el patrón que representa w y que no forma parte de βi) y este puede ser asumido con el objetivo de mantener
(comportamiento de si según el patrón que representa w y que no forma parte de βi) y este puede ser asumido con el objetivo de mantener ![]() también se genera un nuevo nodo.
también se genera un nuevo nodo.
El costo del camino desde un nodo a alguno de sus vecinos es:  es descartado y
es descartado y 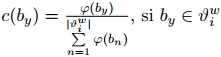 es asumido. En ambos casos solo se crea el nuevo nodo si el costo del camino del nodo origen ($td$td) más el costo del camino al nuevo nodo está dentro de los umbrales de ruido y completitud.
es asumido. En ambos casos solo se crea el nuevo nodo si el costo del camino del nodo origen ($td$td) más el costo del camino al nuevo nodo está dentro de los umbrales de ruido y completitud.
En cada nodo de búsqueda se procesa βi , según el patrón de control de flujo para el cual se busca una descomposición de si (procedimientos processBehaviorTakingOnIncompleteness y processBehaviorByPattern). A continuación se exponen los principios básicos de este procesamiento para cada uno de los patrones.
Secuencia: Existe una descomposición utilizando el operador relativo al patrón secuencia ![]() si ∀1 ≤ j ≤ m se cumple que para cualquier sucesión directa del tipo
si ∀1 ≤ j ≤ m se cumple que para cualquier sucesión directa del tipo ![]() o
o ![]() y además no existe una sucesión indirecta
y además no existe una sucesión indirecta ![]()
La primera descomposición potencial es ![]() b es la sucesión directa más frecuente en li. A partir de esta descomposición se procesan el resto de las sucesiones en
b es la sucesión directa más frecuente en li. A partir de esta descomposición se procesan el resto de las sucesiones en ![]() para adicionar las actividades restantes a los conjuntos que ya existen en
para adicionar las actividades restantes a los conjuntos que ya existen en ![]() o a nuevos conjuntos, considerando las reglas antes descritas. Una vez que todas las actividades de Xi están en
o a nuevos conjuntos, considerando las reglas antes descritas. Una vez que todas las actividades de Xi están en ![]() , se procesan los eventos que inician
, se procesan los eventos que inician ![]() y terminan trazas
y terminan trazas ![]() . Se verifica que si
. Se verifica que si ![]() todas las actividades a que hacen referencia los eventos en
todas las actividades a que hacen referencia los eventos en ![]() se encuentren en v1 y las actividades cuyos eventos pertenecen a
se encuentren en v1 y las actividades cuyos eventos pertenecen a ![]() pertenezcan a vm. Si no se cumple esta condición se considera falta de completitud en li. Si el evento para el cual no se cumple la condición pertenece a
pertenezcan a vm. Si no se cumple esta condición se considera falta de completitud en li. Si el evento para el cual no se cumple la condición pertenece a ![]() se agrega una actividad invisible (∼) a v1 . Si el evento pertenece a
se agrega una actividad invisible (∼) a v1 . Si el evento pertenece a ![]() entonces ∼ se agrega a vm.
entonces ∼ se agrega a vm.
Lazo: Existe una descomposición utilizando el operador relativo al patrón lazo ![]() (υ1 se refiere al subproceso Do y υ2 al subproceso Redo) si se cumplen tres condiciones. Primeramente todas las actividades cuyos eventos pertenecen a
(υ1 se refiere al subproceso Do y υ2 al subproceso Redo) si se cumplen tres condiciones. Primeramente todas las actividades cuyos eventos pertenecen a ![]() forman parte de υ1 y deben poseer eventos en
forman parte de υ1 y deben poseer eventos en ![]() . Además, para toda sucesión directa
. Además, para toda sucesión directa ![]() , a debe iniciar al menos una traza. Y por último, para toda sucesión directa
, a debe iniciar al menos una traza. Y por último, para toda sucesión directa ![]() b debe concluir al menos una traza.
b debe concluir al menos una traza.
En la primera descomposición posible ![]() , υ1 contiene las actividades cuyos eventos pertenecen a
, υ1 contiene las actividades cuyos eventos pertenecen a ![]() y a
y a ![]() y tienen una frecuencia superior al umbral de ruido. Durante el procesamiento de las sucesiones en
y tienen una frecuencia superior al umbral de ruido. Durante el procesamiento de las sucesiones en ![]() el resto de las actividades son adicionadas a v1 y v2 , considerando las reglas descritas. Se pueden descartar sucesiones indirectas y eventos que inician y terminan trazas, siempre dentro del umbral de ruido.
el resto de las actividades son adicionadas a v1 y v2 , considerando las reglas descritas. Se pueden descartar sucesiones indirectas y eventos que inician y terminan trazas, siempre dentro del umbral de ruido.
Paralelismo: Existe una descomposición según el patrón paralelismo ![]()
![]() si cumplen dos condiciones. La primera condición es que
si cumplen dos condiciones. La primera condición es que ![]() exista
exista ![]() Además, en cada una de las trazas debe aparecer al menos un evento de los subprocesos concurrentes, o sea,
Además, en cada una de las trazas debe aparecer al menos un evento de los subprocesos concurrentes, o sea, ![]()
La primera ![]() contiene un conjunto por actividad. Al procesar las sucesiones indirectas
contiene un conjunto por actividad. Al procesar las sucesiones indirectas ![]() que representan violaciones de las condiciones planteadas se unen los conjuntos en los que se encuentran las actividades de la sucesión procesada. La ausencia de los subprocesos en algunas trazas puede ser ignorada dentro del umbral de ruido. Una
que representan violaciones de las condiciones planteadas se unen los conjuntos en los que se encuentran las actividades de la sucesión procesada. La ausencia de los subprocesos en algunas trazas puede ser ignorada dentro del umbral de ruido. Una ![]() puede mantenerse asumiendo una sucesión indirecta
puede mantenerse asumiendo una sucesión indirecta ![]() dentro del umbral de completitud.
dentro del umbral de completitud.
Selección Exclusiva: Es posible identificar una descomposición ![]()
![]() La primera descomposición
La primera descomposición ![]() contiene un conjunto por cada actividad. Al procesar las sucesiones
contiene un conjunto por cada actividad. Al procesar las sucesiones ![]() para las cuales se violan las condiciones planteadas se unen los conjuntos cuyas actividades están asociadas a la sucesión procesada. Una descomposición puede mantenerse si el umbral de ruido permite descartar la sucesión que viola las condiciones planteadas,
para las cuales se violan las condiciones planteadas se unen los conjuntos cuyas actividades están asociadas a la sucesión procesada. Una descomposición puede mantenerse si el umbral de ruido permite descartar la sucesión que viola las condiciones planteadas,
Selección no Exclusiva: Existe una variante de descomposición ![]()
![]() Además debe comprobarse que no existe representación de todos los subprocesos en al menos una traza. La primera
Además debe comprobarse que no existe representación de todos los subprocesos en al menos una traza. La primera ![]() contiene un conjunto por cada actividad. El procesamiento de las sucesiones en
contiene un conjunto por cada actividad. El procesamiento de las sucesiones en ![]() en las cuales se violan las condiciones planteadas provoca la unión de los conjuntos en los que se encuentran las actividades asociadas a la a
en las cuales se violan las condiciones planteadas provoca la unión de los conjuntos en los que se encuentran las actividades asociadas a la a ![]() b procesada. Una descomposición puede mantenerse asumiendo una sucesión b
b procesada. Una descomposición puede mantenerse asumiendo una sucesión b ![]() a dentro del umbral de completitud.
a dentro del umbral de completitud.
RESULTADOS Y DISCUSIÓN
El algoritmo propuesto ha sido implementado en un complemento del marco de trabajo ProM (Verbeek et al., 2011). Los umbrales de ruido y completitud son configurables al iniciar el complemento y en este experimento se utilizaron los valores por defecto: 0.2 para ruido y 0.8 para completitud.
Para comprobar si el algoritmo identifica correctamente los patrones de control de flujo se concibió un experimento con dos grupos de registros de eventos artificiales. Los registros de eventos se generaron a partir de 10 modelos de procesos que combinan diferentes patrones. Los modelos fueron creados con la herramienta Process Log Generator (Burattin y Sperduti, 2011), combinando aleatoriamente características como: cantidad de patrones anidados, probabilidad de Secuencia, Lazo, AND Split/Join y XOR Split/Join. Los modelos de procesos construidos poseen las características descritas en la Tabla 1.
Por cada uno de estos modelos de proceso se generó un registro de eventos, los cuales fueron utilizados para conformar el grupo G1. Luego se extrajo a cada registro de eventos perteneciente a G1 el 5% de sus eventos, con el objetivo de introducir situaciones de ruido y ausencia de información, conformándose así el grupo G2. En la Tabla 2 se muestran las características de los registros de eventos de cada grupo.
El diseño experimental propuesto se resume en la Tabla 3, utilizando la siguiente simbología: G: Grupo de participantes. Cada grupo está formado por 10 registros de eventos generados aleatoriamente. R: Asignación al azar. X: Estímulo. X1 corresponde con la extracción de eventos de G1 y X2 a la aplicación del algoritmo propuesto. O: Observación.
En el primer momento las observaciones O1 y O3 representan la cantidad de patrones de control de flujo presentes en el modelo original. En el segundo momento las observaciones O2 y O4 están asociadas a la cantidad de patrones correctamente identificados por el algoritmo propuesto, con respecto al modelo original. Para cada observación se hacen 10 mediciones, una por cada modelo de proceso. En la Figura 2 se muestra el total de patrones presentes en cada modelo original y los identificados por el algoritmo propuesto, en los registros de eventos de los grupos G1 y G2. Se pueden apreciar diferencias para los modelos 1, 5, 6 y 7.

Los patrones incorrectamente identificados a partir de los registros de eventos de G1 , respecto a los modelos originales 1, 5 y 7 son en todos los casos Selección exclusiva. Las diferencias de los Árboles de Variantes obtenidos con G2 , respecto a los obtenidos con G1 son en el patrón Selección exclusiva para 5 y 6, además de en el patrón Lazo para el caso 6.
A partir del diseño experimental expuesto se realizaron las pruebas estadísticas. Primeramente se realizaron comparaciones por pares en un grupo, utilizando el test no paramétrico de signos con rasgos de Wilcoxon. Al analizar los datos correspondientes al primer y segundo momento se detectó que no existen diferencias significativas (significación 0.083 para G1 y 0.063 para G2) entre los patrones de los modelos originales y los observados en el Árbol de Variantes. Para comprobar el impacto del ruido y la ausencia de información en el método propuesto se compararon los valores de las evaluaciones O2 y O4 utilizando el test de Mann-Whitney. En esta prueba no se encontraron diferencias significativas entre ambos momentos (significación 0.669).
Las diferencias encontradas entre los Árboles de Variantes indican que debe mejorarse el enfoque utilizado para identificar los patrones Selección exclusiva y Lazo. Sin embargo, las pruebas estadísticas aplicadas demuestran que estas diferencias no son significativas. Considerando los resultados obtenidos, se puede afirmar que el algoritmo propuesto identifica correctamente los patrones de control de flujo a partir de registros de eventos con ruido y ausencia de información.
CONCLUSIONES
Para resolver la afectación que provocan el ruido y la ausencia de información en la comprensión del proceso es necesario controlar el impacto estructural de estas características. Sin embargo, considerar ciertos comportamientos infrecuentes como ruido y asumir que faltan determinadas evidencias de la ejecución del proceso, son estimaciones que sólo pueden ser confirmadas a partir del contexto de ejecución particular del proceso analizado. Debido a esto el enfoque adoptado por el algoritmo propuesto es buscar varias descomposiciones alternativas para el mismo subproceso, de tal manera que los comportamientos que son descartados como ruido y los que son asumidos como ausentes en una variante de descomposición, no lo son en otra.
Las variantes de descomposición identificadas en el algoritmo forman variantes de modelos del mismo proceso, que son agrupadas en un modelo de proceso jerárquico, el Árbol de Variantes. A partir de este árbol el analista del proceso puede escoger entre las variantes construidas, lo cual equivale a decidir cuáles comportamientos deben ser considerados como ruido y descartados del modelo resultante, así como seleccionar cuáles comportamientos están ausentes y cómo deben ser insertados en el modelo.
Las pruebas estadísticas realizadas evidencian que la propuesta identifica correctamente los patrones de control de flujo, en registros de eventos con ruido y/o ausencia de información. El presente trabajo puede extenderse construyendo un algoritmo para identificar, de las variantes obtenidas por el algoritmo propuesto, aquellas que optimicen aspectos de interés para el análisis, como rendimiento temporal o consumo de recursos.
AGRADECIMEINTOS
Agradecer al Ing. Osiel Fundora Ramírez por su colaboración en la generación de modelos y registros de eventos artificiales.
REFERENCIAS BIBLIOGRÁFICAS
BOSE, R. (2012). Process Mining in the Large: Preprocessing, Discovery, and Diagnostics. PhD thesis, Eindhoven University of Technology.
BOSE, R. y VAN DER AALST, W. (2009). Abstractions in process mining: A taxonomy of patterns. Business Process Management, (pp. 159–175).
BRATOSIN, C. (2011). Grid architecture for distributed process mining. PhD thesis., Technische Universiteit Eindhoven, Eindhoven, Eindhoven, The Netherlands.
BURATTIN, A. y SPERDUTI, A. (2011). PLG: A framework for the generation of business process models and their execution logs. In Business Process Management Workshops (pp. 214–219).: Springer. 00028.
DE WEERDT, J., DE BACKER, M., VANTHIENEN, J., y BAESENS, B. (2012). A multi- dimensional quality assessment of state-of-the- art process discovery algorithms using real- life event logs. Information Systems, 37, 654–676.
GUNTHER, C. (2009). Process Mining in Flexible Environments. PhD thesis, Eindhoven University of Technology, Eindhoven.
GUNTHER, C. y VAN DER AALST, W. (2007). Fuzzy mining - adaptive process simplification based on multi-perspective metrics. In Business Process Management, volume 4714 LNCS of 5th International Conference on Business Process Management, BPM 2007 (pp. 328–343). Brisbane.
MOLKA, T., GILANI, W., y ZENG, X.-J. (2013). Dotted chart and control-flow analysis for a loan application process. In M. L. Rosa y P. Soffer (Eds.), Business Process Management Workshops, number 132 in Lecture Notes in Business Information Processing (pp. 223–224). Springer Berlin Heidelberg.
OUTMAZGIN, N. y SOFFER, P. (2014). A process mining-based analysis of business process work-arounds. Software & Systems Modeling, (pp. 1–15). 00000.
RUSSELL, S. J., NORVIG, P., CANNY, J. F., MALIK, J. M., y EDWARDS, D. D. (1995). Artificial intelligence: a modern approach, volume 2 of Prentice Hall Series in Artificial Intelligence. Prentice hall Englewood Cliffs, 2 edition.
VAN DER AALST, W. (2011). Process Mining. Discovery, Conformance and Enhancement of Business Processes. Springer, Heidelberg, Dordrecht, London et. al.
VAN DER AALST, W., WEIJTERS, A. J. M. M., y MARUSTER, L. (2004). Workflow mining: Discovering process models from event logs. IEEE Transactions on Knowledge and Data Engineering, 16(9), 1128–1142.
VERBEEK, H., BUIJS, J., VAN DONGEN, B., y VAN DER AALST, W. (2011). XES, XESame, and ProM 6, volume 72 LNBIP of CAiSE Forum 2010 on Information Systems Evolution. Hammamet.
WESKE, M. (2007). Business Process Management. Concepts, Languages, Architectures, volume 368. Leipzig, Alemania: Springer-Verlag Berlin Heidelberg.
YZQUIERDO-HERRERA, R. (2012). Modelo para la estimación de información ausente en las trazas usadas en la minería de proceso. PhD thesis, Universidad de las Ciencias Informáticas.
YZQUIERDO-HERRERA, R., SILVERIO-CASTRO, R., y LAZO-CORTES, M. (2013). Sub-process discovery: Opportunities for process diagnostics. In G. Poels (Ed.), Enterprise Information Systems of the Future, number 139 in Lecture Notes in Business Information Processing (pp. 48–57). Springer Berlin Heidelberg.
Recibido: 29/09/2014
Aceptado: 01/09/2015


{kind=link}