










Mi SciELO
 Servicios personalizados
Servicios personalizadosServicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkRevista Cubana de Ciencias Informáticas
versión On-line ISSN 2227-1899
Rev cuba cienc informat vol.12 supl.1 La Habana 2018
ARTÍCULO ORIGINAL
Construcción de resúmenes lingüísticos a partir de rasgos de la personalidad y el desempeño en el desarrollo de software.
Building linguistic summaries from personality traits and software development performance.
Iliana Pérez Pupo1*, Pastor López Gómez1, Esmerida Pérez Varona1, Pedro Piñero Pérez1, Roberto García Vacacela2
1Grupo de Investigaciones en Gestión de Proyectos. Universidad de las Ciencias Informáticas. La Habana, Cuba, {iperez, plopezg, eyperez, ppp}@uci.cu
2Universidad Católica de Santiago de Guayaquil, Ecuador. gfercastro@gmail.com
*Autor para la correspondencia: iperez@uci.cu
RESUMEN
Uno de los factores con mayor influencia en el desarrollo de los proyectos de tecnologías de la información son los recursos humanos. En particular es relevante conocer qué relación existe entre los rasgos de la personalidad de un individuo y su rendimiento laboral en diferentes puestos de trabajo. En la presente investigación se aplican algoritmos para la construcción de resúmenes lingüísticos a partir de datos en una base de datos de personas que laboran en proyectos de desarrollo de software y a los que se les aplicaron los siguientes instrumentos de evaluación de la personalidad: BFQ, 16 PF Forma C y el cuestionario sobre estilos de dirección. En el trabajo se presentan los resultados principales obtenidos a partir de la aplicación de un algoritmo para la sumarización lingüística de datos basados en el descubrimiento de reglas de asociación.
Palabras clave: gestión de proyectos, instrumentos de personalidad, resumen lingüístico.
ABSTRACT
One of the most influential factors in the development of information technology projects is human resources. In particular, it is important to know the relationship between people's personality traits and their work performance in different jobs. In this research, algorithms are used to construct language summaries from data in a database of people working on software development projects who have been given the following personality assessment tools: BFQ, 16 PF Form C, and the Leadership Styles Questionnaire. The work presents the main results obtained from the application of an algorithm for the linguistic summation of data based on the discovery of rules of association.
Key words: linguistic data summarization, personality tests, project management.
INTRODUCCIÓN
Los recursos humanos juegan un papel fundamental en las organizaciones orientadas a proyectos. En la selección y contratación de recursos humanos para un proyecto de software es importante tener en cuenta la idoneidad de las personas para el rol que van a desempeñar (The Standish Group International, 2014a) (The Standish Group International, 2014b) (The Standish Group International, 2015). En general, el desempeño de los recursos humanos depende de diversos factores, entre los que se destacan: sus competencias técnicas, la sinergia para el trabajo en equipo y sus habilidades de comunicación (Belbin, 2010). Por otra parte, existe una estrecha relación entre los rasgos de la personalidad y su influencia en los estilos de aprendizaje. Se relaciona a continuación algunos ejemplos de esta estrecha relación (Ahmed y Campbell, 2010):
- La forma en que las personas obtienen la información puede ser clasificada en teórica o práctica. El primer caso se refiere a entender las explicaciones teóricas, la base teórica de las proposiciones, mientras que en el segundo se prefieren las experiencias prácticas y hechos reales.
- El tipo de información que se prefiere, se clasifica en información verbal o información visual. En la verbal se prefiere la información en forma de texto, mientras que en la visual se prefiere la información de imágenes y gráficas.
- En cuanto a la forma en que se procesa la información, un grupo de personas son identificadas como reflexivas a introvertidas y otras como activas o extrovertidas. Los que pertenecen al primer grupo prefieren adquirir la información y disponer de tiempo para procesarla y luego intercambiar. Los del segundo grupo prefieren adquirir información a partir del debate y el intercambio.
- La forma en que las personas organizan la información se puede dividir en personas secuenciales, planeadas o personas globales. Las personas secuenciales prefieren que la información les llegue de forma ordenada y generan información en forma de pasos, mientras que las personas globales prefieren la adquisición de toda la información y luego ellos mismos la organizan.
En el caso particular de los proyectos de software, en este trabajo se plantea la hipótesis de que los rasgos de la personalidad influyen en el desempeño laboral de los recursos humanos en los roles de proyectos. A continuación, se muestran ejemplos de dos ideas que fundamentan esta hipótesis:
- Los programadores están especializados en procesos de transcribir algoritmos expresados originalmente en lenguaje natural al lenguaje de programación. Los algoritmos se presentan en pasos ordenados que siguen un proceso lógico y esto sugiere la existencia de alguna relación con las personas cuyo estilo de aprendizaje es planificado.
- Los analistas por su parte, necesitan desarrollar competencias de comunicación, creatividad y abstracción. Estas características sugieren que exista alguna interrelación entre estilos de aprendizaje y rasgos de personalidad asociados a la extroversión.
Para el estudio de los rasgos de la personalidad, los psicólogos y otros especialistas han desarrollado un número considerable de pruebas, algunas de las cuales se discuten a continuación. La prueba o modelo de Myers-Briggs (Briggs & Myers, 2004) está basado en cuatro escalas para identificar las preferencias del comportamiento humano y extiende en una dimensión, a las tres definidas por Jung en 1920 (Chapman, 2011). La implementación más difundida del modelo Myers-Briggs es el MBTI, pero su aplicación requiere el pago de las licencias necesarias. Otro, es el modelo de roles de equipo de Belbin (Belbin, 2010), que está orientado a evaluar el grado de orientación de las personas hacia el desempeño de tareas (roles de acción), hacia el mundo de las ideas (roles mentales) o hacia las relaciones con las personas (roles sociales). El modelo de los 16 Factores de Personalidad (16PF) desarrollado por Raymond B. Cattell (Cattell, et al., 1970), es uno de los instrumentos de personalidad más aplicados en el ámbito laboral. En su valoración incluye 16 rasgos y tiene las siguientes formas de presentación: A, B, C, D, E y F. El 16PF en sus formas C y D son de uso frecuente en selección de personal y tratan el falseamiento de la información. El modelo de los cinco grandes (FFM), uno de los instrumentos que implementa este modelo, es el Big Five (BFQ) (Caprara, et al., 1995). El BFQ caracteriza al personal en función de las siguientes dimensiones: energía, afabilidad, tesón, estabilidad emocional y apertura mental. Tiene como particularidad que incorpora una escala de distorsión para medir la tendencia a dar una imagen falseada del entrevistado (Caprara, et al., 1995). Este instrumento ha sido empleado en diversas investigaciones asociadas al rendimiento laboral. En general, diferentes autores han desarrollado investigaciones orientadas a aplicar las pruebas antes mencionadas en la asignación de roles en equipo de proyectos de software (Grau, 2012).
Por otra parte, las organizaciones emplean sistemas de información para la gestión de proyectos alineados a estándares como el PMBOK (Snyder & Dionisio, 2017) o la ISO 21500 (ISO, 2012). Estos sistemas recogen con frecuencia datos del cumplimiento de las actividades desarrolladas por los recursos humanos que incluyen indicadores asociados a la eficacia y a la eficiencia, un ejemplo de estos sistemas es la plataforma GESPRO (González, et al., 2016). Además, existen repositorios de datos que recogen datos de estos sistemas de información y lo proveen para el desarrollo de investigaciones (Rivero, et al., 2017). Un ejemplo de estos repositorios es el desarrollado por el Departamento de Investigaciones en Gestión de Proyectos, de la Universidad de las Ciencias Informáticas (Rivero & Pérez, 2018).
A pesar de la disponibilidad de la información y de los instrumentos antes mencionados, aún en los procesos de asignación y desarrollo de los recursos humanos, no se tienen en cuenta suficientemente las características de la personalidad de los mismos. Esta situación se evidencia en los siguientes hechos:
- No se realiza un diagnóstico previo para identificar las características de la personalidad de los miembros de los proyectos.
- En algunos casos no se corresponden las características de la personalidad de los miembros del proyecto con los roles asignados, provocando inconformidad en las tareas que desempeñan.
- A la hora de trabajar en el proyecto, no se reconoce cuáles personalidades pueden entran en conflicto y cómo puede lograrse un trabajo armónico.
Considerando la disponibilidad de datos, la existencia de los instrumentos y las insuficientes investigaciones en este sentido. El presente trabajo tiene como objetivo mostrar los resultados de la aplicación de nuevas técnicas de sumarización lingüística de datos en el descubrimiento de relaciones entre los rasgos de la personalidad y el desempeño laboral.
El trabajo está organizado de la siguiente forma. En la sección Metodología computacional, se describen los algoritmos y técnicas de sumarización lingüística de datos propuestos en la presente investigación. Luego se presenta la sección Análisis de resultados y finalmente se presentan las conclusiones del trabajo.
MATERIALES Y MÉTODOS
En esta sección se presentan brevemente las técnicas de sumarización lingüística de datos y detalles de la forma de aplicación de las mismas en el problema en cuestión.
Las técnicas de sumarización lingüística de datos agrupan un conjunto de técnicas orientadas al descubrimiento de relaciones entre los datos y la representación de estas relaciones en forma de oraciones en lenguaje natural. Su principal aporte es lograr presentar la relación intrínseca en los datos de forma asequible a los decisores humanos, disminuyendo el tiempo requerido para la comprensión del comportamiento de los datos y facilitar la toma de decisiones. Los resúmenes lingüísticos pueden ser sentencias que abarquen diferentes niveles de complejidad, por ejemplo:
- Resúmenes con cuantificador como “la mayoría de los trabajadores tienen salarios altos” que responden a la estructura Qy′s are S, donde y = “los trabajadores”, Q = “la mayoría”, S = “salarios altos”.
- Resúmenes compuestos con cuantificador como “la mayoría de los trabajadores tienen salarios altos y vasta experiencia” que responden a la estructura Qy′s are S, donde y = “los trabajadores”, Q = “la mayoría”, S = “salarios altos y vasta experiencia”, es decir, el sumarizador S involucra más de una variable.
- Resúmenes con cuantificador y calificador como “la mayoría de los trabajadores de edad joven tienen sueldos altos” que responden a la estructura QRy′s are S, donde y = “los trabajadores”, Q = “la mayoría” R = “edad joven”, S = “sueldos altos”. Nótese que la diferencia de este resumen con los dos anteriores es la incorporación de R.
En general los resúmenes lingüísticos están compuestos por los siguientes elementos:
- Los cuantificadores (Q) que se pueden clasificar en: absolutos y relativos. Ejemplos de cuantificadores absolutos son: 10, alrededor de 5, aproximadamente el 15%, más o menos 100. Ejemplos de cuantificadores relativos son: pocos, algunos, alrededor de la mitad, la mayoría, casi todos.
- Calificador o filtro (R): que representan condiciones para que se cumpla un predicado, estos filtros también representan variables del conjunto de datos que son convertidas a borrosas a partir de asignar a los datos un término lingüístico que expresa su valor.
- Sumarizador (S): representa una o varias variables que responden características del objeto de estudio que se quieren analizar, sobre este conjunto de variables se realiza la consulta.
- Grado de verdad (T) del resumen que toma valores en el intervalo [0, 1] y es un indicador de calidad del resumen. Varios autores han propuesto diferentes formas de calcular indicadores de calidad de los resúmenes. En particular en esta investigación se trabaja con el conjunto de valores de T propuestos por Zadeh en (Zadeh, 1983) y que comprende los siguientes criterios: grado de verdad, grado de imprecisión del resumen, grado de cubrimiento de objetos de la base de datos por el resumen, el grado de adecuación del resumen, la longitud del resumen y un valor que integra al resto de los indicadores.
Tabla 1: Protoformas propuestas por Kacprzyk & Zadrozny (Kacprzyk and Zadrożny, 2005) (Boran et al., 2016) (Donis-Diaz et al., 2014).
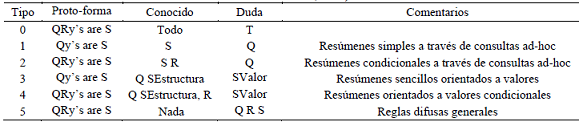
Las protoformas no solo representan la estructura de los resúmenes, sino también la forma que éstos son buscados o accedidos. Por ejemplo, la protoforma tipo 0 representa que se tiene el resumen y lo que se quiere buscar es su valor de verdad T, mientras que las protoformas de la 1 a la 4 representan procesos donde se tiene alguna duda o se quiere conocer sobre el comportamiento de alguna variable y para ello se cuenta con algunos datos conocidos. En estos casos se debe responder a la pregunta del comportamiento de las variables que son consideradas como dudas. Finalmente, la protoforma 5 responde al caso más general donde se quiere descubrir completamente el resumen.
Existen diferentes algoritmos para la construcción de resúmenes que basan su funcionamiento en el trabajo con estas protoformas. Los resúmenes más sencillos pueden ser construidos combinando principios de la lógica borrosa con lenguajes de consulta de bases de datos (Kacprzyk and Zadrożny, 1995). Las protoformas más complejas como la 5 son construidas con otras técnicas que pueden combinar técnicas de aprendizaje automático o técnicas de minería de datos. Ejemplos de algoritmos que han sido empleados para la construcción de resúmenes son los algoritmos genéticos (Donis-Diaz, et al., 2014).
En general, no existe un algoritmo único para generar resúmenes ni que tenga absoluta efectividad en todos los escenarios. Cada escenario es particular respecto a factores como: la naturaleza de los datos, las interrelaciones relaciones entre los datos y la semántica de lo que representan. Por este motivo es preciso para cada escenario en particular, el diseño de algoritmos propios, ajustados y considerando las especificidades. A continuación, se presenta un algoritmo para la generación de resúmenes lingüísticos en el escenario de la toma de decisiones asociadas a los recursos humanos y la ubicación de los mismos en roles de proyectos, atendiendo a los rasgos de su personalidad.
Notación necesaria para el algoritmo:
- DataSI: Conjunto de datos proveniente del sistema de información asociado al desempeño de los recursos humanos y los procesos de evaluación del desempeño laboral.
- D: conjunto de datos para el análisis que se obtienen inicialmente de los instrumentos para el análisis de la personalidad empleados.
- Tflv: conjunto de variables lingüísticas que representan a cada atributo.
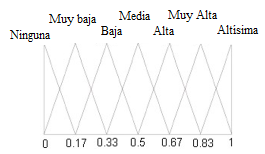

Figura 1: Ejemplo de variables lingüísticas que representan a los datos.
- RulesParameters: parámetros para generar las reglas de asociación (soporte y confianza).
- Q: variable lingüística de los cuantificadores de los resúmenes, un ejemplo de la variable lingüística es la gráfica derecha de la figura 1.
- Object: objeto ´y´ de la base de datos.
- ParT-S_nomra: par T-norma y S-norma empleadas en la evaluación y agregación de los datos.
Como precondición para la aplicación de este algoritmo, se debe contar con los datos asociados al desempeño laboral de los recursos humanos (DataSI) a los que se les aplicarán los instrumentos para la evaluación de los rasgos de personalidad. Estos datos de desempeño generalmente son provistos por sistemas de información asociados a la gestión de los proyectos.
Algoritmo para generar resúmenes a partir de rasgos de personalidad:
Entradas:
DataSI: Conjunto de datos asociados al desempeño provenientes del sistema de información
Tflv: variables lingüísticas de cada atributo del conjunto de datos.
RulesParameters: parámetros para generar las reglas de asociación (soporte y confianza).
Q: variable lingüística de los cuantificadores de los resúmenes.
Object: objeto de estudio ´y´ de la base de datos.
ParT-S_nomra: par T-norma y S-norma
- Inicio
- Selección del instrumento de análisis de la personalidad a aplicar.
A partir del análisis de los instrumentos realizada por Pastor en aa (López, 2018), en esta investigación se recomienda el trabajo con los instrumentos: BFQ, 16 PF Forma C y Encuesta de estilos de dirección.
- D = Aplicar el instrumento recopilando los datos de los encuestados.
- D = D x DataSI // combinación de los datos provistos por los instrumentos y los provenientes del sistema de información de gestión de recursos humanos.
- Df = Fuzzify(D, Tflv) // Transformación de los datos D en borrosos
- Rules = Extract_rules(Df, RulesParameters) // Genera reglas de asociación usando apriori
- Summaries = Execute_linguistic_summarization(UnifiedRules, Object, Q) // Genera los resúmenes lingüísticos
- TLS = TCalculator(Summaries, ParT-S_nomra) // mientras ´Summaries´ no esté vacío, calcular el grado total de validez de cada resumen.
- LSList = Reorder(TLS) // Reordenar los resúmenes lingüísticos en función de los valores de TLS.
- LSList = AprendizajeActivo (LSList)
// Refinar y unificación de resúmenes aplicando Aprendizaje Activo.
- Devolver LSList // lista ordenada de los resúmenes lingüísticos y mejorada por los expertos.
- Fin
En el algoritmo propuesto, a partir de aplicar el instrumento seleccionado en el paso 2, se recopila un conjunto de datos combinados con los datos provistos por el sistema de información asociados a la evaluación del desempeño de los recursos humanos. Esta combinación de los datos, responde al producto cartesiano de la base de datos asociada a la evaluación del desempeño de los recursos humanos y la base de datos obtenida por la aplicación del instrumento.
Los datos previamente combinados y contenidos en D, son sometidos a un proceso de conversión a valores lingüísticos por medio de aplicar el principio de máxima membresía a cada uno de los datos. A partir de este momento, se generan reglas de asociación empleando el algoritmo apriori (Wasilewska, 2007)y ajustado a los parámetros requeridos que fueron entradas al algoritmo. Las reglas de asociación son transformadas en resúmenes lingüísticos a partir de calcular para las mismas los cuantificadores. Luego los resúmenes son ajustados a partir de incluir artículos y verbos que transforman los resúmenes finalmente en oraciones en lenguaje natural, fáciles de interpretar por los decisores humanos. Finalmente, los resúmenes son evaluados a partir de combinar los valores T propuestos por Zadeh (Zadeh, 1983) con técnicas de aprendizaje activo donde participan especialistas en gestión de proyectos. Los resultados de la evaluación son empleados para reordenar los resúmenes que finalmente son entregados a los decisores.
RESULTADOS Y DISCUSIÓN
Para esta investigación se tomaron datos de 60 personas en activo en el desarrollo de proyectos de software y se recuperaron los datos de desempeño de estas personas a partir de datos del sistema de información de gestión de proyectos y del repositorio para investigaciones (Rivero & Pérez, 2018), en particular, la base de datos empleada fue la de Asignación de recursos a tareas.
Para identificar en el escenario real de aplicación qué instrumento reporta los mejores resultados, se aplican los siguientes instrumentos: BFQ, 16 PF Forma C, Encuesta de estilos de dirección tradicional y Encuesta de estilos de dirección basado en computación con palabras. Este último instrumento es una modificación al cuestionario para evaluar estilos de dirección, donde los encuestados expresan sus preferencias en forma de palabras en lugar de valores numéricos como lo hace el cuestionario en su forma tradicional.
Los datos provenientes de estos instrumentos son combinados con los datos recuperados, asociados a la evaluación de desempeño y se obtuvieron los siguientes resultados. En total se trabajó una base de datos de 25 variables.
Resúmenes más relevantes obtenidos a partir de los datos provenientes del instrumento: “Cuestionario sobre estilos de dirección forma tradicional”.
- La mayoría de los especialistas con alto rendimiento en el rol de programador se caracterizan por ser pasivos y orientados hacia las tareas en condiciones normales y en condiciones de tensión.
- La mayoría de los miembros del proyecto con alto rendimiento en un tercer rol como implantadores, se caracterizan por ser personas pasivas en condiciones normales y pueden realizar tareas en el rol de programador.
- Casi todos los especialistas con un rendimiento medio en un segundo rol como analista, se orientan hacia las personas en condiciones normales y pueden realizar tareas en el rol de programador.
Resúmenes más relevantes obtenidos a partir de los datos provenientes del instrumento: “Cuestionario sobre estilos de dirección en la variante que emplea computación con palabras”.
- La mayoría de los programadores con rendimiento alto, se caracterizan por ser pasivos y orientados se hacia las personas tanto en condiciones normales como de tensión. En condiciones normales presentan mezcla técnica, por lo que se consideran personas exactas, precisas, calmadas, lógicas, completan trabajos importantes siguiendo siempre métodos probados y no les gusta asumir riesgos.
- La mayoría de los especialistas que se desempeñan en un segundo rol como arquitectos, con un rendimiento alto, se caracterizan por ser pasivos en condiciones de tensión.
- Muchos de los especialistas que se desempeñan en su segundo rol asignado como analistas, con rendimiento medio, en condiciones normales son pasivos y orientados hacia las personas. En condiciones de tensión también son pasivos.
- Alrededor del 50% de los especialistas que se desempeñan en un tercer rol como implantador, con un rendimiento medio, se orientan hacia las personas en condiciones normales y se orientan hacia las tareas en condiciones de tensión.
- La mayoría de los especialistas que se desempeñan en tareas de calidad, con un rendimiento alto, se orientan hacia las personas en condiciones normales y se orientan hacia las tareas en condiciones de tensión.
Se debe notar que la combinación del instrumento de “Evaluación de estilos de dirección” en su variante de computación con palabras con el algoritmo de generación de resúmenes, obtuvo más resúmenes que el instrumento en su variante tradicional.
Resúmenes más relevantes obtenidos a partir de los datos provenientes del instrumento: “Inventario de personalidad 16 PF en Forma C”.
- La mayoría de los especialistas con rendimiento alto en el rol de programador coincidieron como grupo en valores normales en la protensión, la fuerza en el ego, por ser emocionalmente estables, tranquilas, maduras, realistas, calmadas, equilibradas y capaces de mantener solida la moral del grupo.
- Muchos de los especialistas que se desempeñan en tareas de calidad con un rendimiento alto, coincidieron como grupo en valores normales en la animación, la sensibilidad, la abstracción y la socialización.
- 8 especialistas implantadores altos se desempeñan como personas astutas, calculadoras, perspicaces, sutiles y lucidas. Su enfoque es intelectual y poco sentimental.
- La mayoría de los especialistas con un rendimiento medio en un segundo rol como analistas, coincidieron como grupo en valores normales en la animación, aprensión o seguridad y la socialización.
- La mayoría de los especialistas con rendimiento alto en un segundo rol como arquitecto, coincidieron como grupo en valores normales en el perfeccionismo y la atención a las normas.
Resúmenes más relevantes obtenidos a partir de los datos provenientes del instrumento: “BFQ”.
- La mayoría de los especialistas con rendimiento alto en el rol de programador, se caracteriza por ser moderadamente meticulosos, precisos, responsables, planificados, ordenados y capaces de dominar sus emociones. Además, son poco comprensivos y tolerantes.
- La mayoría de los especialistas con rendimiento alto en tareas de calidad, se caracterizan por ser moderadamente creativos, activos, informados y abierto a intereses de tipo cultural. Además, son bastante responsables, ordenados, cooperativos y afectivos.
- 8 implantado alto: Se consideran personas responsables, planificados y ordenadas. Se pueden desempeñar como programador.
- Los especialistas con rendimiento alto en un segundo rol como arquitecto, se caracterizan por ser moderadamente responsables, planificados, ordenados y diligentes. Con poca tranquilidad y paciencia. Además, son muy poco activos y pueden realizar tareas en el rol de programador.
- Los especialistas con rendimiento alto en un segundo rol como analista, se caracterizan por ser moderadamente creativos, informados, activos, comprensivos y tolerantes. Además, presentan cierto sesgo positivo en sus respuestas por lo que tienden a negar sus defectos personales o son particularmente ingenuos.
- Los especialistas con rendimiento medio en un segundo rol como analista, se caracterizan por ser moderadamente creativos, activos, informados, meticulosos, precisos, abierto a lo nuevo, a ideas y valores diferentes a los propios. Además, son poco comprensivos, tolerantes y afectivos.
Además, se realizó una corrida del algoritmo de generación de resúmenes lingüísticos con los datos combinados del desempeño y de los cuatro instrumentos seleccionados. En este sentido se obtuvieron los siguientes resúmenes:
- La mayoría de los especialistas con rendimiento alto en el rol de programador, coincidieron como grupo en valores normales en la animación, planificados, seguridad, autosuficiencia y extraversión. Además, son personas pasivas en condiciones normales.
- La mayoría de los especialistas con rendimiento medio en un segundo rol como analista, coincidieron como grupo en valores normales en la animación, activos, seguridad, extraversión y atención a las normas.
En el experimento se obtuvo que los especialistas con rendimiento alto en el rol de programador y arquitectos se caracterizan por meticulosos, precisos, responsables, planificados, ordenados; pero que son poco tolerantes y que tiene una elevada fuerza de ego. Estas características deben canalizarse para evitar conflictos interpersonales durante el desarrollo de los proyectos. Una de las formas de mitigar estas situaciones es precisamente el desarrollo de los recursos humanos en forma de actividades que estrechen los lazos entre los miembros de los equipos y que acerquen a los programadores a otros miembros.
Se identifica además que rasgos de la personalidad adecuados para los analistas, es que estos sean creativos, informados, meticulosos, precisos, activos, abiertos a lo nuevo, a ideas y a valores diferentes a los propios. Estas características ayudan a su desempeño laboral y al intercambio con los clientes. En caso de que los analistas no cumplan con estos rasgos de la personalidad, se debe considerar la reubicación de los recursos humanos.
Durante la aplicación de los instrumentos, adicionalmente se indicó a cada entrevistado que evaluara el nivel en que los resultados de cada instrumento se adecuaban a su naturaleza. Para ello, se les pidió que expresaran sus preferencias usando los siguientes términos lingüísticos CBTL = {ninguno, muy bajo, bajo, medio, alto, muy alto, perfecto} representados por la variable lingüísticade la figura 2. Para computar las preferencias de los encuestados se empleó el modelo de computación con palabras 2-tuplas (Herrera & Martínez, 2000).
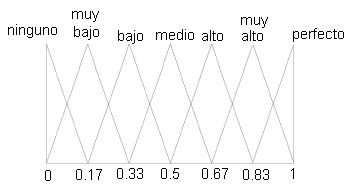
Figura 2: Variable lingüística empleada en la evaluación de los instrumentos.
En ese sentido, según criterio de los encuestados, los instrumentos se ordenan en cuanto a mejor resultado, de la siguiente forma:
- Instrumento BFQ.
- Instrumento 16PF.
- Encuesta de estilos de dirección basado en computación con palabras.
- Encuesta de estilos de dirección tradicional.
CONCLUSIONES
- El procedimiento propuesto permite la identificación de relaciones entre los rasgos de la personalidad y el índice de evaluación del rendimiento en los roles asignados en proyectos de software. Este método ha sido probado en proyectos de software, pero su concepción permite su aplicación en diversos escenarios.
- En la aplicación de los instrumentos, se pudo identificar que el BFQ fue el que los participantes refirieron que era el que más se ajustaba a sus características. Se recomienda este instrumento para aplicarlo en otras investigaciones en organizaciones orientadas al desarrollo de proyectos de software.
- En el experimento se obtuvo que los especialistas con rendimiento alto en el rol de programador, se caracterizan por ser moderadamente meticulosos, precisos, responsables, ordenados y capaces de dominar sus emociones; pero que son poco tolerantes y es preciso que los gestores de proyectos conozcan estas características para facilitar la comunicación en el proyecto y evitar conflictos interpersonales.
- Generalmente, los especialistas con un buen desempeño en el rol de analista, se caracterizan por ser: creativos, informados, meticulosos, precisos, abiertos a lo nuevo, a ideas y a valores diferentes a los propios. Estos elementos facilitan la comunicación y la correcta gestión de los interesados, lo cual ayuda a su desempeño laboral y al intercambio con los clientes.
REFERENCIAS BIBLIOGRÁFICAS
Ahmed, F. y Campbell, P. (2010). Learning & Personality Types: A Case Study of a Software Design Course. Journal of Information Technology Education: Volume 9.
Belbin, M. (2010). Team Roles at Work (Butterworth Heinemann, 2nd ed., 2010.) ISBN 978-1- 85617-800-6 R. Meredith Belbin, Team Roles at Work (Butterworth Heinemann, 2nd ed., 2010.). http://www.belbin.com/rte.asp?id=29.
Boran, F. E., Akay, D., & Yager, R. R. (2016). An overview of methods for linguistic summarization with fuzzy sets. Expert Systems with Applications, 61, p. 356–377.
Briggs, K. y k. Myers. (2004). Introducción al Type (MBTI): Una guía para entender los resultados de su evaluación Myers-Briggs Type Indicador. Sexta ed. Consulting Psychologists Press. California, USA.
Caprara, G.V., Barbaranelli, C. y Borgogni, L. (1995). Manual del BFQ. Tea Ediciones, Madrid.
Cattell, R., Eber, H. y Tatsuoka, M. (1970). Handbook for the 16PF Questionnaire. Champaign: IPAT.
Chapman, A. (2011). Personality theories, types and tests. http://www.businessballs.com/personalitystylesmodels.htm
Donis-Diaz, C. A., Bello, R., Kacprzyk, J., & others. (2014). Linguistic data summarization using an enhanced genetic algorithm. Czasopismo Techniczne, p. 3–12.
González, R. S., Pupo, I. P., et al. (2016). Ecosistema de Software GESPRO-16.05 para la Gestión de Proyectos. Revista Cubana de Ciencias Informáticas, 10, p. 239-251, ISSN: 2227-1899 | RNPS: 2301.
Grau, R. (2012). La eficiencia en la graduación universitaria analizada con descubrimiento de conocimientos en la base de estudiantes de la Universidad Central de Las Villas.
Herrera, F. & Martínez, L. (2000). A 2-tuple Fuzzy Linguistic Representation Model for Computing with Words. IEEE Transactions on Fuzzy Systems, vol. 8, nº 6, p. 746-752.
ISO. ISO 21500:2012 (2012) Guidance on Project Management. International Organization for Standardization. Disponible en: http://www.iso.org/iso/catalogue_detail?csnumber=50003.
Kacprzyk, J., & Zadrożny, S. (2005). Linguistic database summaries and their protoforms: towards natural language based knowledge discovery tools. Information Sciences, 173(4), p. 281–304. doi:10.1016/j.ins.2005.03.002.
Kacprzyk, J., & Zadrożny, S. (1995). FQUERY for Access: fuzzy querying for a Windows-based DBMS, in: Fuzziness in Database Management Systems, eds. P. Bosc and J. Kacprzyk, (Physica-Verlag, Heidelberg, 1995), p. 415–433.
López, P. (2018). Procedimiento para la aplicación de test de personalidad como apoyo a la gestión de recursos humanos en proyectos informáticos. Tesis para optar al grado de: Máster en Gestión de Proyectos. Dpto. de Investigaciones en Gestión de Proyectos, Universidad de las Ciencias Informáticas, La Habana, Cuba.
Piñero, P.; Torres, S. (2013). Paquete para la Dirección Integrada de Proyectos y la ayuda a la toma de decisiones. II Taller internacional las TIC en las Organizaciones, XV Convención y Feria Internacional, Informática 2013, ISBN 978-959-7213-02-4.
Piñero, P. Y., Pérez, I., et al. (2014). Sistema de Información para la Gestión de Organizaciones Orientadas a Proyectos. DOI: 10.13140/2.1.3491.1522, V Congreso Iberoamericano de Ingeniería de Proyectos, Loja Ecuador. Disponible en: http://congreso.riipro.org/index.php/CIIP/V-CIIP/paper/viewFile/105/31.
Project Management Institute. 2017. Newtown Square, Pennsylvania 19073-3299 USA. ISBN 978-1-62825-184-5. 2013. Disponible en: http://www.pmi.org/.
Rivero, C. C., & Pérez, I. (2018). Repositorio de Investigaciones en Gestión de Proyectos, Bases de Datos de Evaluación de Proyectos. Maestría en Gestión de Proyectos / Seminario de Investigaciones, Departamento de Investigaciones en Gestión de Proyecto, Universidad de las Ciencias Informáticas, La Habana, Cuba. Retrieved from http://aulacened.uci.cu.
Rivero, C. C., Pérez, I., Piñero, P. Y., & Huergo, R. H. B. (2017). Proceso de limpieza de datos en la construcción del repositorio para investigaciones en gestión de proyectos. http://www.informaticahabana.cu/sites/default/files/ponencias2018/CCI44.pdf.
Santos, A. C. (2010). Tecnología de gestión de recursos humanos (Tercera edición corregida y ampliada ed.pp 327- 374). La Habana: Ed. “Félix Varela” y Academia.
Snyder, C., & Dionisio, C. S. (2017). A project manager’s book of forms: A companion to the PMBOK guide. John Wiley & Sons.
The Standish Group International. (2014a). Chaos Report. New York: The Standish Group International, Inc.
The Standish Group International. (2014b). Big Bang Boom, Chaos Report. New York: The Standish Group International, Inc. 2014. https://www.standishgroup.com/sample_research_files/BigBangBoom.pdf.
The Standish Group International. (2015). Standish Group 2015 Chaos Report. Disponible en: https://www.infoq.com/articles/standish-chaos-2015.
Torres, S. (2015). Modelo de evaluación de competencias a partir de evidencias durante la gestión de proyectos. Tesis de Doctorado en Ciencias Técnicas por la Universidad de las Ciencias Informáticas, La Habana, Cuba.
Zadeh, L. A. (1983). A computational approach to fuzzy quantifiers in natural languages. Computers & Mathematics with Applications, 9(1), p. 149–184.
Wasilewska, A. (2007). Apriori algorithm. Lecture Notes, Accessed, 10. Retrieved from https://www3.cs.stonybrook.edu/ cse634/lecture_notes/07apriori.pdf.
Recibido: 18/05/2018
Aceptado: 12/09/2018

