










 Servicios personalizados
Servicios personalizados
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Desde el comienzo del siglo XXI el análisis de sentimiento o minería de opiniones ha sido un área de investigación muy activa dentro del campo del procesamiento de lenguaje natural (Natural Language Processing; NLP) (Hu and Liu, 2004)-(Das and Chen, 2001). El estudio de las opiniones está asociado a áreas de la sociedad como la salud, el gobierno, la economía, entre otras. En los últimos años, han aumentado las propuestas comerciales para el uso del análisis de sentimientos. Compañías incipientes y grandes empresas como: Microsoft, Google, Hewlett-Packard y Adobe tienen sus propuestas para el análisis de opiniones sobre sus productos y servicios o los de terceros (Liu, 2015).
La minería de opiniones o el análisis de sentimientos es el estudio computacional de las opiniones, evaluaciones, actitudes y emociones que expresan las personas acerca de productos, servicios, organizaciones, individuos y eventos (Liu, 2015)-(Liu, 2012). Las investigaciones y propuestas existentes tienen un alcance a nivel de documento, oraciones o aspectos (características). Aunque el análisis a nivel de documento y de oración es muy ventajoso en muchos casos, no garantiza obtener mucha información sobre el objeto de la opinión. Para realizar un análisis a mayor profundidad de las opiniones es necesario trabajar a nivel de aspectos.
El análisis de sentimientos a nivel de aspectos permite tener un mayor detalle de los sentimientos expresados por el autor o autores del texto analizado. Para lograr efectividad en este tipo de análisis se requiere primeramente de la identificación de las entidades presentes en la parte de la oración analizada (frase, oración o párrafo). A estas entidades se le deben asociar los aspectos que las describen y posteriormente clasificar los sentimientos asociados a este conjunto de información (entidades, aspectos). Ejemplos de posibles entidades son productos, servicios, personas, organizaciones y eventos (Jiménez Zafra, 2015). Las opiniones expresadas sobre los aspectos o características de una entidad pueden ofrecer mayor información. Por ejemplo, en una opinión sobre un producto, la persona que escribe una opinión expresa datos positivos o negativos sobre las características que lo conforman.
El análisis de sentimientos a nivel de aspectos es una tarea compleja porque además de reconocer los aspectos es necesario extraer la entidad a la cual están asociados. La extracción de entidades en el análisis de sentimiento es similar al problema clásico de reconocimiento de entidades nombradas (Named Entity Recognition; NER) (Sarawagi, 2008), (Indurkhya and Damerau, 2008).
Las entidades se refieren a los nombres de productos, servicios, individuos, eventos y organizaciones y los aspectos se refieren a los atributos y componentes de estas entidades. Esta tarea presenta complejidades porque se debe identificar la categoría a la que pertenece la entidad (lugar, organización, evento, etc.) y también relacionar las posibles referencias a una misma entidad en un texto. Este última subtarea del análisis de entidades tiene el reto de resolver la posible sinonimia (varios nombres para identificar una misma entidad) y la polisemia (el nombre de una entidad tiene distintos significados), estando estrechamente relacionada a otras tareas del NLP como el análisis de correferencias (Gottipati and Jiang, 2011), (Dredze et al., 2010).
Los aspectos pueden estar representados por diferentes palabras o sinónimos. El uso de modificadores de opinión en uno o varios aspectos puede variar el sentimiento expresado en ellos (Hu and Liu, 2004). Algunos autores (Ding et al., 2008)-(Li et al., 2010) han tratado de enfrentar esta tarea a través de reglas lingüísticas o diccionarios de palabras, pero la construcción de estos recursos es muy costosa por el tiempo, personal y otros recursos que demanda. Una alternativa para lograr la extracción y clasificación de aspectos ha sido el empleo de diferentes modelos de máquinas de aprendizaje sobre grandes conjuntos de entrenamiento de dominios específicos (opiniones sobre: restaurantes, efectos electrodomésticos, etc.). La construcción de estos conjuntos puede ser cara y se incrementa cuando se desea extender a otros dominios o idiomas como el Español (Liu, 2015). Una de las posibles soluciones es encontrar modelos que permitan aprender de varios conjuntos de datos y reconocer de forma automática reglas o patrones lingüísticos que puedan ser extensibles a otros dominios del conocimiento o idiomas (Chen y Liu, 2016). Este trabajo está orientado a analizar las principales propuestas que usan aprendizaje profundo para la extracción de aspectos y la clasificación del sentimiento presente en ellos.
El análisis de sentimientos a nivel de aspecto es conocido en la literatura como Análisis de Sentimiento Basado en Aspectos (Aspect Based Sentiment Analysis; ABSA). Esta tarea fue llamada inicialmente análisis de sentimiento basado en características (Hu and Liu, 2004), (Liu, 2010) y está formada por dos subtareas principales:
Extracción de aspectos: Se encarga de extraer aspectos y entidades de los documentos teniendo en cuenta que los aspectos pueden ser explícitos o implícitos. Por ejemplo, en la oración “La comida de ese restaurante es deliciosa y barata” se debe extraer como aspecto “la comida” de la entidad “restaurante”. En este ejemplo, el aspecto aparece como una palabra simple, pero este puede contener frases compuestas que hacen esta tarea aún más compleja. Es importante tener en cuenta que la extracción de aspectos siempre está relacionada con una entidad (Zhang and Liu, 2014). En esta oración el adjetivo “barata” expresa la existencia de otro tipo de aspecto implícito que es el “precio”. Algunos autores han trabajado el reto de identificar aspectos implícitos (Su et al, 2008)-(Fei et al, 2012), aunque no abunda la literatura sobre este tema.
Clasificación de los sentimientos del aspecto: Determina si la opinión que se emite sobre el aspecto es positiva, negativa o neutral. En la oración del ejemplo anterior la opinión acerca de la comida del restaurante es positiva.
En la propuesta de (Pontiki et al, 2016) se establecen tres importantes subtareas para el ABSA:
Extracción del objeto de la opinión (Opinion Target Expression; OTE): Esta subtarea tiene como objetivo la extracción de los términos del aspecto (e.g., entidad o atributo).
Detección de la categoría del Aspecto (Aspect Category; AC): Esta subtarea se relaciona con la identificación y agrupamiento de los aspectos en conceptos más generales como comida, confort, limpieza, etc.
Polaridad del sentimiento (Sentiment Polarity; SP): Esta subtarea es encargada de asignar un sentimiento a los aspectos extraídos.
Por ejemplo, en la oración “El teléfono tiene una cámara potente pero una batería muy mala.” los aspectos cámara y batería serían obtenidos por la subtarea OTE. En el caso de la subtarea AC estos aspectos pudieran ser clasificados como accesorios u otro concepto que pudiera agruparlos y la subtarea SP daría al aspecto cámara una polaridad positiva y a la batería negativa. La clasificación propuesta por (Pontiki et al, 2016) propone una mayor granularidad para el ABSA y varios de los trabajos analizados en esta revisión sistemática se relacionan con una o varias de estas subtareas.
Uno de los objetivos de la tarea ABSA es poder dar a un flujo de información no estructurado una estructura o forma de representación (La Vie, 2015). El Lenguaje de Marcación de Votación Universal (Universal Voting Markup Language; UVML) (Phillips, 2013), es una propuesta para anotar con etiquetas las opiniones, pero no permite explotar la riqueza semántica que aparece relacionada a la opinión como son los aspectos. Los emoticons es una popular forma de asociar opiniones a una posible estructura a través de iconos o ideogramas (Aoki and Uchida, 2011), pero la simpleza de esta forma de etiquetar no permite incluir los aspectos o características. En las propuestas (Nguyen and Shirai, 2015), (Ye, 2017) se emplean el árbol sintáctico y las etiquetas morfológicas relacionadas a los aspectos y palabras de opinión que permiten obtener una estructura pero es difícil relacionar en ella la entidad a la que pertenecen los aspectos y otros datos de interés como el tiempo en que se emite la opinión.
Una forma de estructurar el texto de opiniones que explícitamente hace referencia a sus aspectos o características es la propuesta que se presenta en (Liu, 2015). Ésta tiene en cuenta la relación entre entidades y aspectos, y considera la opinión como un quíntuplo: O=(e,A,S,h,t), donde e es la entidad objetivo, A es el conjunto de aspectos de la entidad e, S es el conjunto de sentimientos de la opinión asociado a los aspectos en A, h es quién emite la opinión y t indica cuándo se emitió la opinión. En el caso de los sentimientos que aparecen en S, éstos pueden ser positivos, negativos o neutrales, o establecer una escala de valores (1-5, cantidad de estrellas) u otra granularidad (positivos, muy positivos, neutros, negativos, muy negativos) que indique el grado de positividad o negatividad expresado (Liu, 2015), (Liu, 2012), (Tang, 2015).
Existen varias estrategias para la extracción de aspectos:
Empleando la frecuencia con que aparecen los términos (Popescu, 2005)-(Long et al., 2010) .
Analizando las relaciones sintácticas (Hai et al, 2011), (Moghaddam and Ester, 2010)-(Zhai et al., 2011).
Usando técnicas de aprendizaje supervisado como Campos Aleatorios Condicionales (Conditional Random Field; CRF) (Choi et al., 2006), (Yang and Cardie, 2012) y Máquinas de Vectores de Soporte (Support Vector Machine; SVM) (Hofmann, 1999) .
Empleando métodos no supervisados basados en la detección de tópicos presentes en un documento según la Asignación Latente de Dirichlet (Latent Dirichlet Allocation; LDA) (Blei et al., 2003) y otras propuestas derivadas de esta (Li et al., 2010)-(Branavan et al., 2009).
Uno de los conceptos que ha tenido mucho éxito, al aplicarlo a varios dominios del conocimiento humano (procesamiento de imágenes, procesamiento de lenguaje natural, entre otros), es el aprendizaje profundo (Deng and Yu, 2014). Las estrategias que siguen este concepto permiten el aprendizaje automático de las características de los datos de entrada en varias capas de abstracción y logran que el sistema aprenda las más complejas funciones. Las habilidades de aprender automáticamente cuáles características son importantes es fundamental cuando los datos tienen una alta dimensionalidad (Deng and Yu, 2014). Algunas propuestas han sido aplicadas con éxito en la tarea de ABSA con buenos resultados. La existencia de muy pocos artículos de revisión que agrupen los principales resultados de ABSA empleando aprendizaje profundo motivó esta investigación. En este trabajo se hace un análisis de los principales resultados encontrados en la literatura que demuestran los casos exitosos empleando aprendizaje profundo para la extracción de aspectos. De ahí que el objetivo de este artículo de revisión consiste en ofrecer un análisis crítico y comparativo de las principales propuestas y trabajos de revisión que emplean estrategias de aprendizaje profundo para la extracción de aspectos, profundizando en las formas de representación, modelos, resultados y conjuntos de datos empleados en esta tarea.
Este artículo está organizado de la siguiente forma: en la sección “materiales y métodos” se explica cómo se realizó esta revisión sistemática de la literatura y se ofrecen respuestas a las diferentes preguntas de investigación relacionadas a los principales métodos, medidas de evaluación, principales conjuntos de datos de entrenamiento, etc. En la sección “resultados y discusión” se analizan los diferentes resultados de esta investigación. Finalmente, en las conclusiones se resumen las tendencias actuales del ABSA empleando métodos de Aprendizaje Profundo.
MATERIALES Y MÉTODOS
Sobre el uso del aprendizaje profundo en el análisis de sentimientos se ha escrito una gran cantidad de trabajos, inicialmente enfocados en su mayoría a la detección de la polaridad de opiniones considerando todo el documento u oración donde son expresadas. Debido a los excelentes resultados reportados del uso de esta técnica, se han desarrollado y publicado varios artículos que proponen soluciones para la tarea ABSA empleando técnicas del aprendizaje profundo en el período de 2011 hasta 2019.
Para contribuir al avance en la tarea ABSA, en especial la extracción de aspectos empleando estrategias de aprendizaje profundo, es útil realizar una evaluación, identificación e interpretación de las investigaciones más relevantes hasta la fecha. Una búsqueda sobre revisiones de la literatura o estados del arte reveló la existencia de 27 estados del arte o revisiones sistemáticas de la literatura. Estas investigaciones tienen una escasa referencia a propuestas dirigidas a la tarea ABSA o es incompleta la referencia a soluciones que empleen técnicas de aprendizaje profundo.
En esta sección se muestran los criterios seguidos para realizar una revisión sistemática de la literatura (Systematic Literature Review; SLR) tomando como base las pautas propuestas en (Budgen and Brereton, 2006). Se desarrolló una SLR sobre la extracción de aspectos empleando técnicas de aprendizaje profundo en el período de enero 2011 hasta febrero 2019. Si los estudios han sido publicados en más de una fuente o memorias de conferencias, se eligió el trabajo más completo. Se tuvieron en cuenta las publicaciones de varias fuentes de búsqueda de investigación científica: ACM Digital Library, IEEE Explorer, ScienceDirect, Scopus, Springer Link y Google Scholar. No se tomaron en cuenta en la investigación los trabajos que no tienen referencia de la revista, conferencia o memoria de evento, ni aquellos que son un resumen o publicación parcial de otro artículo. El área principal de investigación dentro de la cual pueden encontrarse artículos relevantes determina los términos principales de búsqueda. Los términos de búsqueda empleados fueron:
“aspect extraction” + “opinion mining” + “deep learning”
“aspect extraction” + “sentiment analysis” + “deep learning”
“aspect-based sentiment analysis” + “deep learning”
“aspect-level opinion mining” + “deep learning”
Las búsquedas realizadas permitieron obtener 53 artículos donde se aborda la extracción de aspectos utilizando aprendizaje profundo. Como muestra la Figura 1, a partir de 2015, aumentaron los trabajos sobre los métodos de aprendizaje profundo para la extracción de aspectos, esto se debe al surgimiento de herramientas y modelos que permiten entrenar eficientemente las propuestas basadas en aprendizaje profundo para resolver problemas del NLP, entre ellos el ABSA.
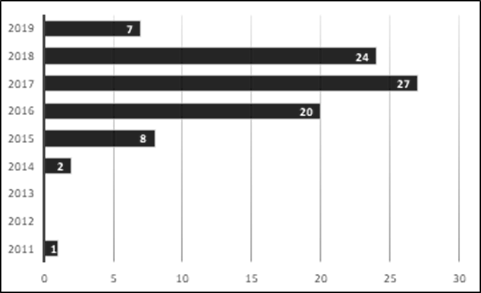
Fig. 1 Cantidad de publicaciones sobre el uso del aprendizaje profundo en la extracción de aspectos en el período 2011- 2019.
En la Figura 1 se muestra como desde 2012 hasta 2013 no se encontraron publicaciones que relacionen el ABSA y las técnicas de aprendizaje profundo. Suponemos que la aparición de formas de representación del conocimiento más eficiente para el entrenamiento de redes neuronales en tareas del PLN como Word Embeddings propuesta por (Mikolov et al., 2013) y herramientas como word2vec y Glove propuesta por (Pennington et al., 2014) han permitido el aumento de trabajos que usen técnicas de aprendizaje profundo a partir de 2014.
Preguntas de investigación
En esta sección se presentan las preguntas de investigación que guían la SLR y se ofrece un resumen de los datos recogidos de los 89 artículos y 27 estados del arte para responderlas.
RQ1: ¿Los métodos de aprendizaje profundo para la tarea ABSA son tratados en los artículos de revisión?
Durante la investigación se encontraron más estados del arte y SLR sobre el análisis de sentimientos en general que específicamente sobre la tarea ABSA. En (Tang, 2015) se hace un análisis de varias estrategias que usan el aprendizaje profundo para el análisis de sentimientos mencionando con poca profundidad su empleo en la extracción de aspectos o características. Los autores sólo hacen alusión a tres artículos que abordan la tarea ABSA; aunque mencionan varias propuestas para la representación de las palabras y su uso con técnicas de aprendizaje profundo al enfrentar el análisis de sentimientos. El trabajo publicado en (Sun et al., 2017) tuvo como objetivo estudiar los métodos que realizan la extracción de aspectos pero sólo menciona uno que usa técnicas de aprendizaje profundo a pesar de mostrar algunas propuestas que las emplearon en otras tareas del análisis de sentimientos. En (More and Ghotkar, 2016) se presenta un estudio del estado de arte de métodos que han dado una propuesta para la tarea ABSA pero no se menciona ninguno que empleara el aprendizaje profundo con tales propósitos. En (Cambria, 2019) se abordan trabajos dirigidos al análisis de las palabras para determinar la emoción presente en las opiniones, pero no se relacionan propuestas para la extracción de aspectos y el uso del aprendizaje profundo. Los avances en el campo del análisis de opiniones para datos de diversos medios (fotos, texto, audio) y el empleo de algunas propuestas de aprendizaje profundo empleadas a tales efectos, aunque no especialmente dirigidas a la extracción de aspectos, son presentados en (Soleymani et al., 2017). En el trabajo publicado en (Yousif et al., 2017) se realiza un estudio de las propuesta para el análisis de sentimientos en citaciones científicas, mencionando la extracción de aspectos o características, y estableciendo como resultado que sólo existen dos propuestas que emplean el aprendizaje profundo. Una revisión sistemática de la literatura orientada a las propuestas existentes para el análisis de sentimientos usando dominios cruzados o adaptación al dominio es presentado en (Al-Moslmi et al., 2017). Esta investigación menciona la existencia de tres propuestas que emplean la extracción de aspectos empleando técnicas de aprendizaje profundo, pero esto resulta insuficiente para el conjunto de investigaciones sobre el tema. En (Kirilenko et al., 2017) se ofrece un estudio de las propuestas existentes para el análisis de sentimientos en el dominio del Turismo. En artículo no se mencionan trabajos que emplean el aprendizaje profundo para la extracción o clasificación de aspectos. En (Yadollahi et al., 2017) se presenta un interesante estado del arte sobre las propuestas asociadas a la determinación de las emociones del autor de textos de opinión. En esta investigación no se abordan soluciones o investigaciones asociadas a la extracción de aspectos, pero sí se hace referencia a algunas propuestas que emplean técnicas de aprendizaje profundo en el análisis de sentimientos. En (Ramya et al., 2017) se analizan varias propuestas que realizan la extracción de aspectos, pero solamente se hace referencia a una investigación que realiza la tarea ABSA empleando técnicas de aprendizaje profundo. En (Ain et al., 2017) se presenta un estudio de las técnicas de aprendizaje profundo para el análisis de sentimientos, pero solo se menciona una propuesta específica sobre la extracción de aspectos. El estado del arte más abarcador es el propuesto en (Zhang et al., 2018); no obstante, no se tuvieron en cuenta 23 artículos significativos sobre el tema. En (Zhang et al., 2018) aparece un análisis de varias propuestas que usan el ABSA y estrategias de aprendizaje profundo. Se describen las principales características de estas propuestas; sin embargo, no se analiza cuál de ellas presenta el mejor resultado o las formas de representación del conocimiento y los conjuntos de datos más empleados, datos muy importantes para los investigadores.
Los 27 estados del arte o revisiones sistemáticas de la literatura que se consultaron en esta investigación hacen poca referencia a investigaciones que enfrentan la tarea de la extracción de aspectos usando algoritmos del aprendizaje profundo. Esto fundamenta la necesidad de realizar una investigación más profunda.
RQ2: ¿Cuáles son los métodos de aprendizaje profundo más empleados en la literatura?
Los modelos de aprendizaje profundo tienen varias mejoras sobre las máquinas de aprendizaje tradicionales. Dos de sus más destacados aportes son que reducen la necesidad de construir los datos (mediante un pre-procesamiento inicial) y realizar ingeniería de características en los conjuntos de entrenamiento (LeCun et al., 2015). Durante este proceso también pueden aparecer características no detectadas por los humanos.
Estos modelos consisten en técnicas de aprendizaje supervisado o no supervisado teniendo como estructura principal varias capas de Redes de Neuronas Artificiales (Neural Networks; NN) (LeCun et al., 2015) que son capaces de aprender una representación jerárquica en arquitecturas profundas. Las arquitecturas de Aprendizaje Profundo están compuestas de varias capas de procesamiento, donde cada capa produce respuestas no-lineales basadas en la capa anterior y la entrada inicial.
Aunque las NN fueron introducidas en el siglo pasado, el crecimiento de las propuestas con Aprendizaje Profundo se enmarca en 2006 cuando Geoffrey Hinton presentó el concepto de Redes de Creencia Profunda (Hinton and Salakhutdinov, 2006). El desarrollo de este tipo de modelo de aprendizaje ha sido posible por los avances del hardware en general y el desarrollo de Unidades de Procesamiento Gráfico (Graphics Processing Unit; GPU) y aceleradores de hardware. Además de la estructura de las redes neuronales, la profundidad de estos modelos y los avances del hardware, las técnicas de aprendizaje profundo han mejorado su desempeño a partir de:
Uso de Unidades de Rectificación Lineal (Rectified Linear Units; ReLUs) como funciones de activación (Glorot et al., 2011).
Introducción de métodos dropout (He et al., 2016).
Inicialización aleatoria de los pesos de las redes (Sutskever et al., 2013).
Solución del problema de la desaparición del gradiente, así como su explosión con el uso de las redes de memoria de corto plazo (Long Short-Term Memory; LSTM) (Hochreiter et al., 1997).
Arquitecturas de modelos de Aprendizaje Profundo
En esta sección se muestra una breve descripción de los modelos de aprendizaje profundo más comunes encontrados en este análisis sistemático de la literatura. Descripciones más detalladas sobre los modelos y arquitecturas de aprendizaje profundo se presentan en (LeCun et al., 2015), (Deng, 2014). La Tabla 1 resume estos modelos, atributos y características.

En las redes neuronales el elemento más simple e importante es la neurona que puede recibir una o varias entradas y a través de su función de activación produce una salida. Cada neurona tiene un vector de pesos asociado al tamaño de la entrada y el sesgo que deben ser optimizados durante el proceso de entrenamiento. La salida es la entrada de la siguiente capa en la red neuronal. La capa final de la red representa la predicción del modelo. La función de pérdida determina la exactitud de esta predicción calculando el error entre los valores obtenidos en la última capa y los valores de comprobación. Un algoritmo de optimización como el Gradiente Descendente Estocástico (Stochastic Gradient Descent; SGD) (Bottou, 2010) es empleado para ajustar los pesos de las neuronas calculando el gradiente de la función de pérdida. El índice de error es propagado hacia atrás en todos los pesos de las neuronas de la red (Backpropagation (Williams and Hinton, 1986)). La red repite el ciclo de entrenamiento después de balancear los pesos de cada neurona en cada ciclo, hasta que el error alcanza una cota deseada. En el entrenamiento de las redes neuronales de los modelos de Aprendizaje Profundo hay dos importantes parámetros: el epoch y el batch. El epoch hace referencia a la cantidad de veces que es necesario pasar por los datos de entrenamiento para encontrar los pesos de la red que se ajustan mejor a los resultados esperados. El batch hace referencia a los subconjuntos de datos del entrenamiento que son tomados en cada iteración y evaluados. La función de pérdida se obtiene mediante el promedio de los valores de pérdida de los ejemplos pertenecientes al batch. Esta es una optimización que permite encontrar una solución rápidamente (LeCun et al., 2015).
Los trabajos revisados emplean el aprendizaje profundo a través de enfoques supervisados, no supervisados o pueden usar propuestas híbridas combinando la salida de un método no supervisado con otro supervisado (Deng and Yu, 2014). Algunos ejemplos de algoritmos de aprendizaje profundo expuestos en (Deng and Yu, 2014) y (LeCun et al., 2015) y encontrados en el análisis realizado en esta investigación son: las Redes Neuronales Convolucionales (Convolutional Neural Networks; CNN) (LeCun, 1989), las Redes Neuronales Recurrentes (Recurrent Neural Network; RNN) (Williams and Hinton, 1986), la propuesta nombrada Memoria a Corto Plazo (Long Short Term Memory; LSTM) (Hochreiter et al., 1997), las Unidades Recurrentes Cerradas (Gated Recurrent Units; GRU) (Chung et al., 2015) y sus variantes Bidireccionales, Autoencoders (Bourlard and Kamp, 1988), (Hinton and Zemel, 1994), y las Máquinas de Boltzman Restringidas (Restricted Boltzmann Machines; RBM) (Smolensky, 1986). A continuación, describiremos brevemente estas redes.
Redes Neuronales Convolucionales: Una CNN recibe una entrada en 2-Dimensiones (e.g., una imagen, una señal de audio, una oración). La capa de convolución es la parte principal de una CNN y consiste en un conjunto de parámetros a aprender, llamados filtros y que poseen la misma forma que la entrada, pero de menor dimensión. En el proceso de entrenamiento, el filtro de cada capa convolucional se mueve a través de todos los datos de entrada y calcula un producto interno entre la entrada y el filtro. Este cálculo permite mapear las características del filtro. Otra parte importante de la arquitectura de un CNN es la capa de asociación (pooling), la que opera sobre el mapa de características que se obtiene como salida de la capa de convolución. El objetivo del pooling es reducir el tamaño espacial de la representación, con el objetivo de disminuir la cantidad de parámetros y el tiempo de cálculo y reducir la posibilidad de sobre entrenamiento. El max pooling es una estrategia que toma el valor máximo de cada región. Al resultado de la capa de convolución o pooling en una CNN se le aplica una función de activación. Es frecuente seleccionar ReLU, la cual consiste en neuronas con la función de activación de la forma 𝑓 𝑥 =𝑚𝑎𝑥 0,𝑥 aunque pueden se seleccionadas otras como la tangente hiperbólica (Wu et al., 2016). La principal diferencia de CNN y las redes neuronales completamente conectadas es que cada neurona en CNN está conectada solamente con un pequeño subconjunto de la entrada. Esto disminuye la cantidad de parámetros en la red y disminuye el tiempo y la complejidad del entrenamiento (LeCun et al., 2015). La Figura 2 muestra una propuesta de arquitectura de una CNN.

Redes Neuronales Recurrentes: Estas redes están orientadas a resolver problemas de secuencias o de series de tiempo (e.g., audio, texto) (Deng, 2014) que pueden tener tamaño variable. La entrada de una RNN consiste en el dato actual y el anterior. Esto significa que la salida en el instante 𝑡−1 afecta la salida del instante 𝑡. Cada neurona está equipada con un ciclo de retroalimentación que retorna la salida actual como entrada del próximo paso, como se muestra en la Figura 3. Así, cada neurona en una RNN tiene una memoria interna que mantiene la información de los cálculos de la entrada anterior (Deng and Yu, 2014). Una de las mayores debilidades de las RNN es el problema de la desaparición del gradiente (vanishing gradient), asociado a que éste sea cercano o igual a cero y el problema de la explosión del gradiente, que provoca que el gradiente aumente considerablemente (Deng, 2014).

Memoria a Corto Plazo: LSTM es una extensión de las RNN y resuelve el problema de la desaparición y explosión del gradiente de las RNN. Estas usan el concepto de compuertas para sus neuronas. Cada una de estas compuertas calcula un valor entre 0 y 1 basado en su entrada. Incluyendo el mecanismo del ciclo de retroalimentación de una RNN para almacenar información, cada neurona en un LSTM (llamada una célula de memoria) tiene una compuerta multiplicativa de olvido (forget gate), lectura (read gate) y escritura (write gate). Estas compuertas son las que controlan el acceso de información en la neurona y evitan cualquier perturbación por datos de entrada irrelevantes. Cuando la compuerta de olvido está activa, la neurona escribe su dato dentro de ella. Cuando la compuerta de olvido está inactiva, la neurona olvida el contenido anterior. Cuando la compuerta de escritura es puesta a 1, otras neuronas pueden escribir en la neurona. Si la compuerta de lectura está activa, el contenido de la neurona pueda ser leído (Dohaiha et al., 2018).
Unidades Recurrentes Cerradas: Las GRU son una extensión de las RNN que evitan como las LSTM el problema de la desaparición y explosión del gradiente. La diferencia principal con respecto a las redes LSTM es que solamente definen dos compuertas: la de restauración (reset gate) y la de actualización (update gate) y manipula el flujo de información de manera similar a las redes LSTM sin la unidad de memoria. El uso de menos compuertas hace a la GRU menos costosa computacionalmente.
Redes Recurrentes Bidireccionales: Los tres modelos anteriores se enfocan en obtener el próximo estado a partir del anterior. Un propuesta que ha obtenido buenos resultados en modelos RNN es incorporar una capa hacia adelante y hacia atrás con el objetivo de aprender información de los tokens próximos y anteriores (Joty et al., 2015). Como se muestra en la Figura 4, en cada instante 𝑡, una capa oculta hacia adelante ℎ 𝑡 se calcula basándose en el estado previo ℎ 𝑡−1 y la entrada actual 𝑥 𝑡 . De igual forma la capa oculta hacia atrás ℎ 𝑡 se calcula basándose en el estado oculto futuro ℎ 𝑡+1 y la entrada actual 𝑥 𝑡 . La representación del contexto hacia adelante ( ℎ 𝑡 ) y hacia atrás ( ℎ 𝑡 ) son concatenados en un gran vector del instante 𝑡 de la forma: ℎ =[ ℎ 𝑡 , ℎ 𝑡 ].

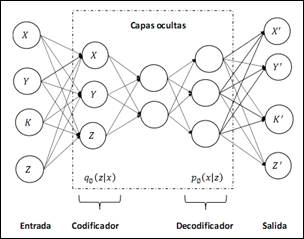
Autoencoders: Las redes AE consisten de una capa de entrada y una de salida que son conectadas a través de una o más capas ocultas, como se muestra en la Figura 5. Tienen la misma cantidad de neuronas de entrada que de salida. Estas redes tienen dos componentes principales: un codificador y un decodificador. El codificador recibe la entrada y trasforma ésta en una nueva representación, la cual es usualmente llamada un código o variable latente. El decodificador recibe el código generado por el codificador y lo trasforma en una reconstrucción de la entrada original. El procedimiento de entrenamiento de estas redes tiene como objetivo la minimización del error de reconstrucción. Existen varias variaciones y extensiones de los AE, entre ellos los ruidosos, contractivos, apilados o variacionales (Deng, 2014).
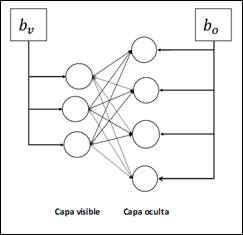
Máquinas de Boltzman Restringidas: Una RBM es una red neuronal estocástica que consiste en dos capas: una capa visible que contiene la entrada conocida y una capa oculta que contiene las variables latentes. La reconstrucción de una RBM es aplicada a la conectividad de las neuronas comparadas con máquinas de Boltzman. Las RBM construyen un grafo bipartito, como se muestra en la Figura 6, de manera que las neuronas de la capa visible deben estar conectadas a todas las neuronas de la capa oculta, pero no existe conexión entre dos unidades de la misma capa. En estas redes el sesgo de la capa de entrada está conectado a todas las neuronas de esa capa (de igual forma ocurre con el sesgo en la capa oculta). Este tipo de red puede ser apilada para formar redes neuronales profundas y también puede crear bloques de redes de Creencia Profunda (LeCun et al., 2015).
En el análisis realizado en esta investigación se encontraron más trabajos con modelos supervisados que no supervisados o híbridos. De las propuestas que siguen un enfoque supervisado, el 42% corresponden a variantes que usan LSTM, como se muestra en la Figura 7. La selección de este método está dado por la naturaleza secuencial de la información en las tareas de NLP para la información textual (LeCun et al., 2015). En los trabajos analizados se identificó que una de las características de las redes LSTM es su uso en forma bidireccional. Esta configuración de la red propone el entrenamiento de dos redes LSTM, donde la segunda recibe como entrada la salida de la primera, y ambas concatenan los estados ocultos (Huang et al., 2018)-(Chaudhuri and Ghosh, 2016).
En (Gu et al., 2017), (Poria et al., 2016) se emplea una variante de CNN mediante el uso de una secuencia de redes convolucionales donde la salida de una red es la entrada de la otra. Este algoritmo es conocido como Redes Convolucionales Apiladas o en Cascada (Convolucional Stacked Network; CSN). La selección de este tipo de algoritmos por parte de los investigadores se justifica por la variedad de problemas de NLP que se pueden resolver aplicando las CNN y los buenos resultados que se han obtenido. Esta técnica permite, a partir de la representación de las palabras, aplicar en cada capa de la red una operación de convolución o de selección de características importantes.

Fig. 7 Clasificación de los métodos de aprendizaje profundo empleados en la extracción de aspectos, donde se muestra la cantidad de artículos y el porciento que representa del total.
Otros enfoques del aprendizaje profundo muy empleados de forma supervisada son GRU y RNN. El empleo de estos algoritmos por parte de los autores se justifica porque estas técnicas están especializadas para procesar secuencias de valores. Estos métodos procesan una oración desde el inicio hasta el final, analizando una palabra a la vez. Además, se auxilian de las relaciones de dependencias y los árboles sintácticos para extraer a nivel de palabras las relaciones semánticas y sintácticas. De esta forma, logran capturar las representaciones del conocimiento más abstractas y de más alto nivel en diferentes capas. Por otro lado, las RNN son capaces de modelar secuencias de tamaño arbitrario por la aplicación de unidades recurrentes a lo largo de las secuencias de tokens. Las RNN tienen como desventajas el desvanecimiento o explosión del gradiente. Esto provoca que las RNN no sean suficientes para modelar dependencias de gran tamaño. Este problema ha motivado que varias propuestas usen las LSTM y GRU para la extracción de aspectos (Sun et al., 2015), (Yuan et al., 2017).
El resto de los trabajos revisados emplean los algoritmos del aprendizaje profundo de forma no supervisada, como el uso de Autoencoders en la investigación publicada en (Glorot et al., 2011). Esta técnica implementa una red neuronal que copia los datos de la capa de entrada en la capa de salida. Internamente, tiene una capa oculta que se encarga de codificar y decodificar los datos de entrada a través de dos funciones. Por lo general, estas funciones se definen de forma que la copia sea aproximada y de esta manera el modelo es forzado a priorizar aquellos aspectos que sean propiedades útiles de los datos.
En (Wang et al., 2015) se prueba un RBM para la extracción de aspectos. Esta red neuronal es un modelo basado en energía con una distribución de probabilidad conjunta especificada por una función de energía. En (Wang et al., 2015) las unidades de la capa oculta representan aspectos, sentimientos previamente seleccionados y palabras de rechazo, mientras que la capa de entrada está asociada a las palabras de las oraciones de entrenamiento.
En (He et al., 2017), (Xiong et al., 2016) se usa una Red de Memoria Profunda (Deep Memory Network; DMN) que es entrenada a partir de un conjunto de aspectos predefinidos. En varios trabajos (He et al., 2017)-(Huang et al., 2016) se reporta el empleo del Mecanismo de Atención (Attention Mecanism) que promedia los pesos que pueden ser relevantes en otros puntos de una red neuronal. Este mecanismo permite incluir características lingüísticas o sintácticas al proceso de aprendizaje de la red neuronal que implementa el algoritmo del aprendizaje profundo. Varias propuestas (Joty et al., 2015), (Poria et al., 2016), (Ying et al., 2017) agregan reglas lingüísticas al empleo de algoritmos del aprendizaje profundo.
Debido a que la extracción de aspectos es una tarea de gran importancia en el análisis de sentimientos, aparecen muchas propuestas que realizan la extracción de aspectos y la clasificación de la polaridad de los aspectos (positiva, negativa y neutra) de forma paralela (Tang, 2015), (Nguyen-Hoang et al., 2016), (Xu et al., 2017).
En algunos trabajos analizados, la forma de realizar la hibridación es mezclando la salida de un método de aprendizaje profundo con el entrenamiento de una máquina de aprendizaje como CRF. En (Wang et al., 2016) primeramente se entrena una RNN, y la salida resultante se utiliza como entrada de un CRF. Esta propuesta no supera los resultados del método ganador en la competencia SemEval 2016 para la tarea ABSA. En (Xianghua et al., 2013) se relaciona la salida de un CNN con un CRF pero no mejora los resultados de SVM contra los que se prueba este método. Los resultados obtenidos en los artículos analizados indican que se debe revisar si realmente es beneficioso relacionar métodos de aprendizaje profundo con otros modelos, tales como CRF. En (Wang and Lu, 2018) se propone el uso de LSTM y en la salida de la red neuronal un CRF para el aprendizaje. Empleando esta variante combinada de LSTM-CRF se obtuvieron resultados de más de un 83% de Micro-F1. En el caso de (Kirilenko et al., 2017) es probado con los mejores métodos de la competición SemEval 2014 para la tarea ABSA y otros métodos que usan CRF. Para todos los casos los resultados de este método lo superan.
Algunas propuestas no tienen como objetivo extraer todos los aspectos asociados a una entidad, sino que tienen el propósito de extraer los aspectos que estén asociados a categorías prefijadas (Wu et al., 2016), (Wang et al., 2015), (Nguyen-Hoang et al., 2016). Por ejemplo, en (Nguyen-Hoang et al., 2016) un conjunto de datos sobre restaurantes se evalúa para determinar cuán buena es la extracción de aspectos o palabras asociadas a comida, personal y ambiente. En la Figura 8 se muestra una taxonomía que clasifica los principales métodos de Aprendizaje Profundo analizados en esta investigación.
La clasificación correspondiente a los “Modelos de Aprendizaje Profundo” hace referencia a aquellos artículos que utilizan CNN, LSTM o GRU para la tarea ABSA (Cheng et al., 2017), (Ying et al., 2017), (Xu et al., 2017). La clasificación nombrada “Mecanismo de Atención + Modelos de Aprendizaje Profundo” engloba aquellos trabajos que combinan el Mecanismo de Atención con modelos como CNN, LSTM, BLSTM o BGRU (Huang et al., 2018), (Chen et al., 2017). En esta investigación se encontraron 10 trabajos que realizan esta combinación y recientemente se ha convertido en una práctica muy extendida entre los investigadores en ABSA. La clasificación “Máquinas de Aprendizaje + Modelos de Aprendizaje Profundo” se refiere a los trabajos donde se usan modelos de Aprendizaje Profundo como CNN, LSTM o BLSTM y luego una máquina de aprendizaje de tipo CRF (Wang et al., 2016), (Mai and Le, 2018).

Como se muestra en esta investigación los modelos más empleados para la extracción de aspectos son los supervisados. Estos modelos sufren la desventaja de necesitar para su entrenamiento muchos datos o ejemplos etiquetados (Wang, 2019). La necesidad de usar grandes conjuntos de datos está asociada al uso de la regularización y el dropout para la reducción del error, así como el empleo del Gradiente Descendiente para encontrar los pesos de la red neuronal (LeCun et al., 2015). Por lo que, se debe seguir trabajando en la construcción e identificación de conjuntos de datos para ABSA teniendo en cuenta diversos dominios e idiomas (Wang et al., 2018). Una posible solución para la existencia de pocos datos etiquetados para algunas clases o la aparición durante el entrenamiento de nuevas clases es el uso de estrategias como el aprendizaje Few-shot (Wang and Lu, 2018). Este esquema de aprendizaje está en su fase de desarrollo pero las propuestas actuales permitirán a los investigadores en ABSA obtener mejores resultados con conjuntos de datos poco o no etiquetados (Wang, 2019), (Young et al., 2018).
RQ3: ¿Cuáles son los conjuntos de datos empleados para el entrenamiento y evaluación de los métodos?
Los trabajos analizados han empleado diferentes conjuntos de datos para evaluar los métodos que realizan la extracción de aspectos, como se muestra en la Figura 9. Los conjuntos de datos más empleados son los de SemEval 2014, 2015 y 2016, Yelp, Amazon y SentiHood. “Ganu 2009” representa un conjunto de datos propuesto en (Ganu et al., 2009) formado por opiniones sobre restaurantes y no se encuentra público. “MPQA” es un conjunto de datos propuesto en (Wiebe etal., 2005) compuesto por noticias etiquetadas según las opiniones presente en ellas y “SSAC 2017” es el conjunto de datos del taller sobre detección de emociones, opiniones y análisis de sentimientos celebrado en 2017. “Hu 2004” es el conjunto de datos propuesto en (Hu and Liu, 2004) compuesto por opiniones de efectos electrodomésticos y que se encuentra público para el uso de los investigadores.
En varios trabajos como en (Nguyen and Shirai, 2015), (Poria et al., 2016), (Tang et al., 2016) se emplea el conjunto de datos propuesto en la competición SemEval 2014 (Pontiki et al., 2014) para evaluar la tarea ABSA. Este conjunto de datos está compuesto por oraciones que contienen opiniones sobre los dominios de restaurantes y laptops, como se muestra en la Tabla 2. Este conjunto posee para cada oración los aspectos presentes en ella y la opinión que se expresa sobre ellos. Para expresar la polaridad de la opinión asociada a los aspectos se establecieron las categorías: positiva, negativa, conflicto y neutral, como se muestra en la Tabla 3.
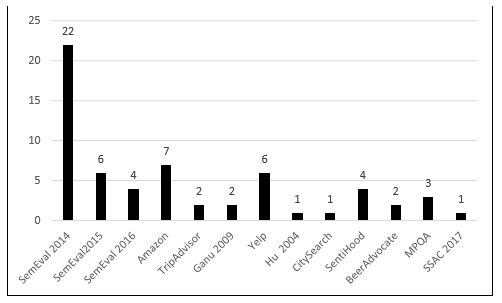
Fig. 9 Uso en los trabajos analizados de las colecciones de opiniones disponibles para la validación.

Tabla 3 Cantidad de oraciones según la polaridad de los aspectos en el conjunto de datos de SemEval 2014.

Los aspectos anotados en el conjunto de datos o corpus están agrupados por las categorías: comida, servicio, precio, ambiente (la atmósfera y ambiente en un restaurante), y anécdotas/misceláneas (no pertenecientes a ninguna de las anteriores). Para asignar la polaridad de cada término se tomó una ventana de seis palabras donde se buscaron los términos con polaridades más cercanas y se sumaron los valores asignados a cada término (-1: negativo, 1: positivo, 0: neutral). El tipo de polaridad “conflicto” se asigna cuando la suma es igual a 0 pero no todos los términos en la ventana son neutrales. La mayoría de los aspectos son palabras simples (2148 para el dominio de Laptops, 4827 para restaurantes). Este conjunto está disponible en formato XML y se puede descargar a través de META-SHARE , repositorio dedicado a compartir recursos para el NLP.
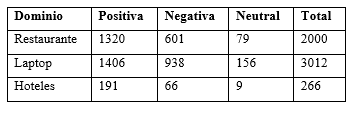
Otro conjunto de datos usado en varias publicaciones (Cheng et al., 2017), (Ma et al., 2018), es el propuesto en la competición SemEval 2015 (Pontiki et al., 2015), para evaluar propuestas en la tarea ABSA. Este conjunto de datos se caracteriza por tener oraciones en tres dominios (laptops, restaurantes y hoteles), aunque para el dominio hoteles no se proporcionó un conjunto de entrenamiento, como se muestra en la Tabla 4.

Al dominio laptops, de este conjunto de datos de SemEval 2015, se asignaron nueve categorías (general, precio, calidad, funcionamiento y rendimiento, usabilidad, diseño y características, portabilidad, conectividad, misceláneas). Fueron definidas cinco categorías para el dominio restaurantes (general, precio, calidad, estilo y opciones, misceláneas) y ocho para el dominio hoteles (general, precio, confort, precio, limpieza, calidad, diseño y características, misceláneas). La polaridad se define a nivel de oración teniendo en cuenta el documento donde aparece. El valor neutral de la polaridad se aplica cuando se tiene igual cantidad de términos positivos y negativos. En la Tabla 5 se muestra la cantidad de oraciones según la polaridad de los aspectos en el conjunto de datos de SemEval 2015. Este conjunto de datos, al igual que el conjunto de SemEval 2014, está disponible en formato XML a través de la plataforma META-SHARE.
Tabla 5 Cantidad de oraciones según la polaridad de los aspectos en el conjunto de datos de SemEval 2015.
En (Cheng et al., 2017), (Ruder et al., 2016), (Toh and Su, 2016) se usa el conjunto de datos propuesto en SemEval 2016 (Pontiki et al., 2015) para entrenar y evaluar los métodos propuestos. Este conjunto de datos consta de 39 subconjuntos, de éstos, 19 para entrenamiento y 20 para prueba. Los textos contienen información de siete dominios (laptop, teléfonos móviles, cámaras digitales, hoteles, restaurantes, museos y telecomunicaciones) y ocho idiomas (inglés, árabe, chino, alemán, francés, ruso, español y turco). En la competencia SemEval 2016 se propuso la evaluación de métodos para la extracción de aspectos a nivel de oración y a nivel de documento. Los conjuntos de datos de hoteles, restaurantes y laptops fueron anotados con el mismo esquema de anotación de SemEval 2015. Este conjunto de datos, al igual que los ofrecidos en SemEval 2014 y 2015, está disponible en formato XML a través de la plataforma META-SHARE. Los trabajos analizados en este SLR han empleado el conjunto de datos para el idioma inglés. La Tabla 6 muestra la cantidad de opiniones por dominios para el subconjunto de los datos en idioma inglés, donde SB1 corresponde a los textos disponibles para extraer aspectos a nivel de oración y SB2 corresponde a los textos disponibles para determinar los aspectos a nivel de documento.
Tabla 6 Cantidad de opiniones por dominios en el conjunto de datos de SemEval 2015 para el idioma inglés.

El conjunto de datos obtenido a partir de TripAdvisor (Xianghua et al., 2013) es usado por (Pham and Le, 2016), (Pham and Le, 2017) e incluye 174615 opiniones de 1768 hoteles, donde se abordan cinco aspectos: precio, habitación, ubicación, limpieza y servicio. A cada opinión se le asigna una puntuación en el rango de 1 a 5 estrellas.
Varios autores han usado los datos obtenidos del sitio web de Amazon para evaluar sus propuestas. En (Gu et al., 2017) se utilizaron 12700 opiniones de teléfonos inteligentes publicadas en el sitio web de Amazon. En cada oración los términos fueron etiquetados con cinco aspectos predefinidos (batería, pantalla, cámara, altavoz, velocidad de ejecución). Las oraciones que tienen al menos un aspecto fueron etiquetadas con la polaridad (positiva o negativa). En el trabajo publicado en (Glorot et al., 2011) se usa otro conjunto de datos proveniente del sitio web de Amazon. Este conjunto contiene más de 340000 opiniones de 22 tipos de productos diferentes los que están etiquetados con la polaridad positiva o negativa. En (Glorot et al., 2011) se empleó un subconjunto de esta colección que solo aborda cuatro dominios: libros, dvd, productos electrodomésticos y de cocina. Para cada dominio se tomaron 1000 opiniones positivas y 1000 negativas. En (Ding et al., 2017) se usa otro conjunto de datos procedente del sitio web de Amazon y que fue construido y evaluado en (Wang et al., 2011). Este conjunto de datos está asociado al dominio de opiniones sobre dispositivos para mp3 donde cada opinión tiene una escala de 1 a 5 estrellas (puntuación). En general, en los trabajos que han empleado datos de Amazon los datos han sido construidos durante el proceso de investigación o se han empleado conjuntos de datos públicos.
Otro conjunto de datos usado por varios investigadores (Xu et al., 2017), (Xianghua et al., 2013), (Ding et al., 2017) es el propuesto en la competición Yelp . Este conjunto de datos consta de 5200000 opiniones sobre diferentes negocios y se encuentra disponible de forma pública. Las opiniones tienen una escala de 1 a 5 estrellas (puntuación) que indican la polaridad y otros criterios como útil, gracioso o interesante, con un valor numérico según los puntos o votos recibidos. Los datos se encuentran en formato JSON y SQL. Los métodos que han empleado este conjunto han trabajado solo con una pequeña parte de él. Por ejemplo, en (Xu et al., 2017) se toman 1598 opiniones sobre restaurants y 1335 sobre laptops. En (Ding et al., 2017) se usan 20000 opiniones sobre restaurantes. La selección de un conjunto pequeño (opiniones sobre restaurantes o laptops) (Ye, 2017), (Ding et al., 2017), (Pham et al., 2017) se debe a que se entrena con este conjunto de datos y se compara con otros conjuntos como los de SemEval 2014, SemEval 2016 o de Amazon.
Una característica presente en varios trabajos es que no realizan el entrenamiento y la evaluación con un único conjunto de datos (Ye, 2017), (Poria et al., 2016), (Cheng et al., 2017), (Wang et al., 2016), (Li and Lam, 2017), sino que entrenan con un conjunto (por ejemplo: Yelp, Amazon, SemEval 2014, 2015 y 2016) y evalúan con otro conjunto que en la mayoría de los casos es del mismo dominio del entrenamiento. El conjunto de datos más empleado por los investigadores es el de SemEval 2014. La selección se debe a que los datos están etiquetados con bastante granularidad (polaridad a nivel de aspecto y oración, categorías de aspectos). Características similares tiene los conjuntos de datos de SemEval 2015 y 2016, ya que se tomaron a partir del propuesto en SemEval 2014. La mayoría de los trabajos realizan el entrenamiento y evaluación sobre opiniones en los dominios de restaurantes y laptops. Los trabajos revisados no usan el mismo conjunto de datos para evaluar sus propuestas, lo que dificulta establecer comparaciones. El empleo de un mismo conjunto de datos permitiría tener un criterio más certero de la efectividad de cada propuesta.
RQ4: ¿Cuáles son las formas de representación textual más empleadas al extraer aspectos utilizando métodos de aprendizaje profundo?
La forma de representación textual está asociada a la posible organización de la información del texto no estructurado. Los textos generalmente se conforman por párrafos, oraciones y palabras. Una correcta organización de la información no estructurada es necesaria para lograr un efectivo entrenamiento de los métodos de aprendizaje profundo y consecuentemente realizar una eficaz extracción de aspectos. El aprendizaje profundo se basa esencialmente en el trabajo con redes neuronales. Uno de los retos más importantes al utilizar redes neuronales es lograr una forma de representación correcta para los datos de entrada a la red. Los conjuntos de entrenamiento de estas redes están formados por documentos u oraciones que contienen palabras.
Word Embeddings (Mikolov et al., 2013) se definió para lograr un mejor entrenamiento de las redes neuronales que se utilizan en NLP. Éste es el nombre de un conjunto de lenguajes de modelado y técnicas de aprendizaje dónde las palabras o frases del vocabulario se vinculan a vectores de números reales. Word Embeddings conceptualmente transforma un espacio con una dimensión por cada palabra a un espacio vectorial continuo con menos dimensiones (Mikolov et al., 2013). Estos vectores se pueden crear a partir de un conjunto de palabras con la herramienta word2vec .
De las propuestas analizadas, el 93% emplea como forma de representación el Word Embeddings, como se muestra en la Figura 10. Éste necesita de grandes volúmenes de información para la creación de los vectores asociados a las palabras. Siguiendo la forma de representación Word Embeddings se han creado varios modelos, como se muestra en la Figura 11. Uno de los primeros modelos propuestos en la literatura fue Senna (Collobert et al., 2011). Para este modelo se define un vector de 50 dimensiones y los conjuntos de datos pueden ser entrenados a partir de las herramientas creadas por los autores . En (Pennington et al., 2014) se propone el modelo Glove , que se diferencia del anterior porque trata de capturar las estadísticas globales y al mismo tiempo las relaciones en el contexto donde aparecen las palabras. Con este modelo se pueden obtener vectores pre-entrenados con grandes conjuntos de información, como el existente en Wikipedia en inglés. Los modelos Skip-gram y bolsa de palabras contextual (Contextual Bag-of-Words; CBOW) fueron propuestos por (Mikolov et al., 2013). El primero predice, dada una palabra, las palabras del contexto o ventana. El objetivo de CBOW es predecir una palabra si se conoce el contexto o ventana de palabras.

Fig. 10 Formas de representación textual empleadas en las publicaciones acerca de la extracción de aspectos utilizando aprendizaje profundo.
En (Mikolov et al., 2013) se propuso e hizo público un conjunto de vectores pre-entrenados, a partir de un conjunto de datos de noticias procedentes del sitio Google News (100 mil millones de palabras). El modelo contiene un vector de dimensión 300 para 3 millones de palabras o frases. Este conjunto de vectores fue empleado por siete de los trabajos analizados en este artículo de revisión que emplean el Word Embeddings en la extracción de aspectos utilizando métodos del aprendizaje profundo.
En varios trabajos (Ye, 2017), (Cheng et al., 2017), (Toh and Jian, 2015) se usan conjuntos de datos (como el propuesto en Yelp o Amazon ) para el entrenamiento del vector asociado a las palabras usando la herramienta word2vec. En la Figura 11 se muestran los resultados de la cantidad de veces en que son usados estos vectores. Auto CBOW y Auto Skip-Gram representan la cantidad de veces en que las propuestas realizan el entrenamiento de un Word Embeddings a partir de un conjunto de datos de entrenamiento y la herramienta word2vec. Fasttext , empleado en (Xu et al., 2018), (Schmitt et al., 2018) con muy buenos resultados, es un modelo de Word Embedding propuesto por (Grave et al., 2018) y que posee un modelo pre-entrenado. Este conjunto de vectores pre-entrenados y la herramienta para el entrenamiento del corpus muestra mejores resultados que word2vec y Glove en términos de velocidad, escalabilidad y efectividad (Young et al., 2018). Se deben hacer evaluaciones en la tarea ABSA de estos datos con respecto a otras propuestas como word2vec, Senna, Sentiment WE, Glove.

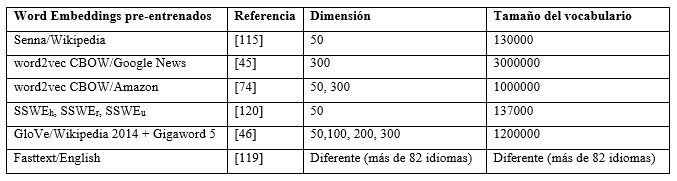
Sentiment WE, conocido como el Word Embeddings específico de sentimientos (Sentiment-Specific Word Embedding ; SSWE) (Tang et al., 2014), representa un conjunto de Word Embeddings entrenados con tweets de sentimientos. Este conjunto de vectores de Word Embeddings tiene dimensión 50 y está dividido en SSWEh, SSWEr y SSWEu. Cada uno de estos conjuntos ha sido entrenado con diferentes algoritmos y solo usa oraciones de sentimientos. SSWEu tiene en cuenta simultáneamente la oración de sentimiento y el contexto donde ocurren las palabras. En las propuestas presentadas en (Tang and Qin, 2016), (Vo et al., 2015) se comparan los resultados obtenidos con estos conjuntos y los vectores pre-entrenados de Glove, pero no se obtienen mejores resultados. La Tabla 7 ofrece detalles de los Word Embeddings pre-entrenados.
Para la extracción de aspectos con métodos de aprendizaje profundo, en (Pham et al., 2017) se realiza una comparación entre los resultados con diferentes modelos: Skip-gram, CBOW y Glove. Durante la evaluación de esta propuesta los mejores resultados se alcanzaron al usar el modelo Glove. En la propuesta publicada en (Li and Lam, 2017), se realiza el entrenamiento usando Word Embeddings de 200 dimensiones con word2vec y el conjunto de datos de Yelp en el dominio de opiniones de restaurantes. Además, emplearon para el dominio de laptop un Word Embeddings de vectores pre-entrenados con el modelo Glove.
El concepto de vector de valores reales asociados a palabras puede ser extendido a oraciones o párrafos, a partir del conjunto de datos de entrenamiento. En (He et al., 2017) se realiza el entrenamiento del vector de valores reales en función de las oraciones presentes en el conjunto de datos y en el trabajo publicado en (Pham and Le, 2017) se usan los párrafos. Estas formas de representación de la información repercutieron negativamente en la calidad de la extracción de aspectos.
En (Glorot et al., 2011) se emplea una bolsa de palabras (bag-of-words) y se obtiene un vector binario que codifica la presencia/ausencia de unigramas y bigramas. En (Wang et al., 2015) se tiene un vector de palabras y se calcula la frecuencia de los términos (Term Frecuency; TF) para los sustantivos en el conjunto de datos de entrenamiento y se calcula la frecuencia inversa del documento (Inverse Document Frecuency; IDF) en un conjunto de datos de n-gramas de Google . Las propuestas que utilizan estas formas de representación del conocimiento no necesitan grandes conjuntos de datos para su entrenamiento y no utilizan una representación vectorial de grandes dimensiones; sin embargo, pierden la riqueza semántica que posee el Word Embeddings. Por esta razón, no superan los resultados alcanzados por aquellas propuestas que utilizan Word Embeddings.
Algunos autores evalúan la posibilidad de agregar al vector del modelo Word Embeddings más entradas asociadas a las características del contexto donde aparecen las palabras (Poria et al., 2016), (Ma et al., 2017). En (Yadollahi et al., 2017) se emplea un vector de Word Embeddings de 300 dimensiones. A este vector se le añaden seis entradas asociadas a seis tipos de etiquetas morfológicas que puede tener la palabra (sustantivo, verbo, adjetivo, adverbio, preposición, conjunción) y se codifican estas entradas de forma binaria según las características morfológicas de la palabra. En esta propuesta, el Word Embeddings con las entradas de las etiquetas morfológicas mejoran los resultados de evaluación del método. En (Xu et al., 2017) se utiliza el vector pre-entrenado Glove, donde se le añade a cada palabra una entrada con la distancia relativa al aspecto presente en la oración y otra entrada para la etiqueta morfológica de la palabra con el objetivo que ayuden en el proceso de aprendizaje. Los resultados obtenidos por el método propuesto en este trabajo superan al resto de los métodos con los que es comparado.
Lo antes expuesto reafirma que Word Embeddings es la forma de representación del conocimiento más empleada en los artículos analizados que realizan la extracción de aspectos con métodos de aprendizaje profundo. En estos artículos son usados varios modelos como: Senna, Glove, Skip-gram y CBOW. La forma en que son entrenados estos modelos y el uso de los vectores pre-entrenados, como el que usa información de Google News y los de Glove, influyen en los resultados finales. Para poder seleccionar el mejor modelo, se debe investigar más sobre la influencia de estos modelos en los resultados.
RQ5: ¿Cuáles son las medidas y los dominios del conocimiento que más se utilizan para evaluar el desempeño de los métodos de aprendizaje profundo en la extracción de aspectos?
Los métodos analizados han sido validados mediante la aplicación de diversas medidas de calidad. Las medidas para la evaluación de los resultados de las diferentes propuestas se concentran en el uso de la Exactitud (Accuracy), Exhaustividad (Recall) y Micro F1; no obstante, otras medidas también han sido empleadas, ellas son: la media del Error Cuadrático Medio (Root Mean Square Error), la Correlación local del aspecto en la opinión (Aspect correlation inside reviews) y la correlación global de aspectos en todas las opiniones (Aspect correlation across all reviews), como se muestra en la Figura 12.
Las medidas Accuracy, Precision, Recall y Micro F1 son muy usadas para evaluar la clasificación en problemas de NLP. Éstas cuantifican la calidad de la extracción de aspectos teniendo en cuenta la cantidad de aspectos extraídos de forma correcta con respecto a los aspectos de referencia. La Perplejidad (Perplexity) es otra medida de validación empleada para analizar la calidad en la identificación de aspectos (Wang et al., 2015), (Ding et al., 2017). Esta medida cuantifica, para cada documento, la cantidad de aspectos encontrados respecto a la cantidad total de palabras del documento. En (He et al., 2017), (Ding et al., 2017) se emplea la medida Coherencia de Tópicos (Topic Coherence), propuesta en (Mimno et al., 2011). Ésta es una medida de la calidad de los aspectos basada en la coocurrencia de palabras. Según esta medida, el método de aprendizaje profundo propuesto en (He et al., 2017) tiene mejores resultados que LDA al extraer aspectos. En (Pham and Le, 2016), (Pham and Le, 2017) se emplean las medidas Aspect correlation inside reviews y Aspect correlation across all reviews para evaluar la calidad de la extracción de aspectos. La primera medida intenta medir cuán bien el método puede mantener el orden relativo de los aspectos dentro de la opinión (a nivel de oración). La segunda indica si los valores obtenidos y los valores del conjunto de prueba para un aspecto dado daría una clasificación similar en todas las opiniones donde aparece este aspecto.

Fig. 12 Medidas de evaluación usadas para calcular la calidad de las propuestas que aplican aprendizaje profundo para la extracción de aspectos.
Muchas veces se dificulta la comparación entre las propuestas existentes, ya sea porque utilizan diferentes medidas de validación o diferentes colecciones (que en algunos casos no están disponibles o se utiliza un subconjunto de aquellas disponibles); por ejemplo, en las publicaciones (Nguyen and Shirai, 2015), (Wu et al., 2016), (Wang et al., 2015), (Nguyen-Hoang et al., 2016), (Tang et al., 2016), (Lakkaraju et al., 2014) no se realiza una comparación con otras investigaciones que han reportado buenos resultados empleando CRF o LDA (Qiu et al, 2011), (Li et al., 2010), (Lazaridou et al., 2013) .
Algunas propuestas solo miden sus resultados a través del Accuracy (Huang et al., 2016), (Xu et al., 2017), (Tang et al., 2016), (Xu et al., 2017), (Gu et al., 2018). Estos resultados no permiten determinar correctamente la calidad del método. Esto se debe a que solamente se tienen en cuenta la relación entre los datos correctos y el total de aspectos extraídos por el método y se excluye la información del conjunto de pruebas. El uso de las medidas Accuracy, Recall y Micro F1 por varios autores no es aislado (se muestran los tres resultados para poder demostrar la validez de los métodos). Micro F1 es una medida que combina los resultados del Accuracy y el Recall (Wu et al., 2018). Por esta razón es seleccionada para identificar cuáles de los trabajos analizados arrojan los mejores resultados.
Para el caso de los métodos que extraen aspectos asociados a categorías (Aspect-Category Sentiment Analysis; ACSA), el mejor resultado de Micro-F1 es el obtenido en (Gu et al., 2017), alcanzándose un 93.63% al emplear CNN a un conjunto de datos de opiniones de Amazon sobre teléfonos inteligentes. En esta propuesta se probó contra un SVM usando validación cruzada. Una valoración más completa de este método debería incluir su comparación respecto a métodos que utilicen CRF o LDA. El segundo mejor resultado en la subtarea ACSA es el obtenido en (Xue et al., 2017) donde se obtiene un 88.91% de Micro-F1 al entrenarse con el conjunto de datos propuesto en la competición SemEval 2014.

Para la extracción de aspectos el mejor resultado teniendo en cuenta la medida de evaluación Micro-F1 es el reportado en (Poria et al., 2016), obteniéndose un 82% para el dominio Laptop y un 87.7% para restaurantes. El método propuesto en este trabajo es CNN, aunque se auxilia de reglas lingüísticas propuestas por los autores y que tienen influencia en los resultados finales. La otra propuesta que tiene buenos resultados es (Wang and Pan, 2017), donde se obtiene un 85.29% de Micro-F1 al ser evaluado en el conjunto de datos SemEval 2014 con opiniones sobre restaurantes. En este mismo conjunto de datos para opiniones de laptops se alcanza un 77.80%. En este trabajo presentado en (Wang and Pan, 2017) se emplea un GRU con mecanismo de atención y se extraen a la misma vez aspectos y términos de opinión. El método es evaluado con otras propuestas que usan técnicas de aprendizaje profundo y CRF. En este trabajo se muestra como otros métodos que combinan aprendizaje profundo y características lingüísticas obtienen resultados similares. Este método en dominios diferentes (laptops, restaurantes) obtiene resultados diferentes, y en algunos casos, con una marcada diferencia. Esto es un inconveniente de los métodos propuestos porque en algunas ocasiones son dependientes del dominio de aplicación y, por tanto, se requiere el desarrollo de sistemas específicos para cada dominio. Una gran parte de los métodos propuestos realiza la evaluación solamente con opiniones sobre dominios de restaurantes y laptops. El uso de estos dominios está dado por la existencia de los conjuntos de datos de las competiciones SemEval 2014, 2015 y 2016 y las referencias de los mejores resultados en estas competiciones para poder comparar. Esto pudiera ocultar errores para el ABSA en otros dominios del conocimiento, incluso existiendo la disponibilidad de conjuntos de datos. La propuesta presentada en (Wang et al., 2018) asume el reto de aprender en múltiples dominios empleando técnicas de Aprendizaje Profundo y enfrentando el problema del olvido catastrófico. El olvido catastrófico ocurre cuando se deben aprender secuencialmente varias tareas empleando redes neuronales (Kirkpatrick et al., 2017). En la propuesta referenciada en (Wang et al., 2018) se obtiene un accuracy de 72.73% y un Micro F1 de 67.92%. Aunque estos resultados son bajos, este trabajo indica la posibilidad de lograr resultados en el reto de obtener buenos resultados en ABSA para varios dominios empleando modelos del Aprendizaje Profundo.
En la Figura 13 el dominio restaurantes es el más utilizado al evaluar las propuestas existentes para la extracción de aspectos. Es interesante destacar que en este dominio es frecuente encontrar términos de opinión o aspectos sobre distintos servicios y productos que se pueden ofrecer en un restaurante. Este es un dominio diverso por los diferentes temas que pueden ser abordados por los usuarios.
RESULTADOS Y DISCUSIÓN
El análisis de los 89 artículos sobre el uso del aprendizaje profundo para la extracción de aspectos publicados desde enero de 2011 hasta febrero de 2019 arrojó los siguientes resultados:
LSTM es la técnica del aprendizaje profundo más empleada en la extracción de aspectos. La selección de esta técnica por parte de los investigadores se justifica por la variedad de problemas del NLP resueltos aplicando LSTM y la naturaleza secuencial de los datos en la tarea ABSA.
Word Embeddings con vectores asociados a palabras es la forma de representación más empleada para la extracción de aspectos aplicando aprendizaje profundo. Dentro de éste, el modelo más usado es skip-gram con un conjunto de vectores pre-entrenados con la información de Google News. No obstante, algunos investigadores emplean exitosamente otros conjuntos de datos para el entrenamiento inicial del Word Embeddings. Esta forma de representación es muy útil para datos de entradas de las redes neuronales de los algoritmos del aprendizaje profundo debido a que representan un vector de números reales. Los grandes conjuntos de datos con los que se crean los vectores permiten cubrir gran cantidad de ejemplos y representar la relación semántica entre palabras, información útil en el proceso de extracción de aspectos.
El conjunto de datos más empleado por los investigadores es el de SemEval 2014. La selección de éste se debe a que los datos están etiquetados con bastante granularidad (polaridad a nivel de aspecto y oración, categorías de aspectos) y la cantidad de información disponible para el proceso de entrenamiento y prueba. En el aprendizaje y la evaluación también se pueden usar otros conjuntos de datos como los de Yelp y Amazon. La mayoría de los trabajos realizan el entrenamiento y la evaluación sobre opiniones en los dominios de restaurantes y laptops. Esto sucede porque son los dominios más frecuentes y con más ejemplos en los conjuntos de datos.
Varias propuestas no logran mejores resultados que otras máquinas de aprendizaje como SVM, LDA o CRF. Otros trabajos analizados no evalúan los métodos propuestos con estas máquinas de aprendizaje.
Algunas propuestas evalúan su calidad solamente con el Accuracy. Se debe evitar usar solamente una medida de calidad porque no se tiene un criterio acertado acerca de la calidad de los métodos propuestos.
El uso de reglas lingüísticas combinadas con técnicas de aprendizaje profundo logra mejorar los resultados de los métodos al ser evaluados con otras propuestas como CRF o LDA.
En el futuro los autores deben evaluar el impacto del uso de recursos externos como lexicones, redes de conceptos y técnicas de aprendizaje profundo no supervisadas.
Es necesario continuar las investigaciones en el uso de métodos de aprendizaje profundo para la tarea ABSA. Los principales resultados de esta investigación sugieren que se debe profundizar en la identificación del mejor modelo de Word Embeddings, evaluar dominios diferentes al de restaurantes y laptops, y realizar comparaciones con propuestas entrenadas con CRF o LDA.
CONCLUSIONES
En esta investigación se logró agrupar y evaluar varios de trabajos que no se analizaron en 27 artículos de revisión sobre el análisis de sentimiento o la tarea ABSA. De estos trabajos se han logrado determinar las formas de representación, modelos, resultados y conjuntos de datos empleados. Sin embargo, la cantidad de trabajos es insuficiente. Los resultados sobre dominios del conocimiento (restaurante, hoteles, laptop, entre otros) evidencia la necesidad de definir propuestas que pueda tener buenos resultados en múltiples dominios del conocimiento. La mayoría de los métodos que usan técnicas de aprendizaje profundo siguen un enfoque supervisado, por lo que requieren partir de colecciones previamente clasificadas. Una línea de investigación pudiera estar dirigida a seguir profundizando en el desarrollo de propuestas no supervisadas o híbridas para la extracción de aspectos. Las nuevas propuestas de métodos de aprendizaje profundo deben ser evaluadas contra otras máquinas de aprendizaje, para poder estimar correctamente su aporte. Se debe continuar investigando en la identificación y selección de los mejores modelos para la representación textual. Futuros análisis de la literatura se deben orientar al estudio, consolidación, clasificación y crítica en general de los métodos de aprendizaje profundo en la tarea ABSA para múltiples dominios. Es necesaria la investigación y creación de propuestas que usen recursos externos como lexicones y redes de conceptos combinado con técnicas de aprendizaje profundo (principalmente no supervisadas) para la tarea ABSA. Las competiciones SemEval 2017 y SemEval 2018 no dedicaron tareas a la evaluación del ABSA pero otras como ESWC 2017 y 2018 (Reforgiato Recuper et al., 2017) mantienen activa las propuestas de nuevos métodos de extracción de aspectos y análisis de sentimientos. De conjunto a nuevas propuestas para ABSA, uno de los campos de investigación que ha tomado auge para el análisis de opiniones en todos sus niveles es la detección de opiniones falsas (fake opinions).

