










 Serviços customizados
Serviços customizados Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
Los problemas de secuenciación están presentes en todas aquellas situaciones donde es necesario ejecutar un conjunto de tareas y para esto se requiere la asignación de las mismas a los recursos disponibles en intervalos de tiempo. En (Zhang, 1996) se define la secuenciación de tareas como el proceso de seleccionar planes alternativos y asignar recursos y tiempos a un conjunto de actividades en un plan. Debido a esto, las asignaciones deben obedecer ciertas restricciones que reflejan las relaciones temporales entre las actividades y las limitaciones de los recursos compartidos. La mayoría de las investigaciones en el área de la secuenciación de tareas se han enfocado en el desarrollo de procedimientos exactos para la generación de una solución base asumiendo que se tiene toda la información necesaria y un ambiente determinístico (Herroelen, y otros, 2005). Este enfoque es conocido en la literatura como problemas de secuenciación de tareas en ambientes de tipo offline.
En ambientes online, por otra parte, una secuencia de trabajos σ = {J1, J2,…, Jn} tiene que procesarse en un número determinado de máquinas. Los trabajos arriban al sistema uno a uno, y cuando un nuevo trabajo llega tiene que ser inmediatamente despachado hacia una de las máquinas, sin tener conocimiento sobre trabajos futuros. El objetivo es optimizar una función objetivo determinada. Los problemas de secuenciación pueden clasificarse teniendo en cuenta el ambiente de las máquinas, las características de los trabajos y la función objetivo. Esta clasificación se conoce comúnmente como (|(|( (Graham, y otros, 1979), donde ( representa el ambiente de las máquinas, ( las características de los trabajos y ( el criterio a optimizar.
Según el ambiente de las máquinas el escenario más simple es en el que se cuenta con un solo recurso, pues los trabajos tienen una sola operación a ser procesada y solo existe una máquina que pueda ejecutarla. Cuando existen múltiples máquinas el entorno se torna más complicado, ya que pueden ser idénticas o pueden diferir en velocidad. Los posibles ambientes con máquinas paralelas se resumen de la siguiente forma (Martínez-Jiménez, 2012):
Máquinas Paralelas Idénticas: Procesan los trabajos a la misma velocidad.
Máquinas Paralelas Diferentes: El tiempo de procesamiento depende de la máquina.
Máquinas Paralelas no relacionadas: El tiempo de procesamiento depende de la máquina y del trabajo.
El presente trabajo se centra en modelar un problema de clasificación que se corresponde con un ambiente de máquinas paralelas no relacionadas, donde se cuenta con diferentes máquinas para procesar los reportes, cada una tiene características diferentes, y cada reporte puede ser procesado solo por una máquina en específico. Hay dos formas posibles de solucionar este tipo de problemas, utilizando enfoques jerárquicos o integrados. El primero divide el problema en enrutamiento (asignando una máquina a cada reporte) y secuenciación, mientras que el segundo considera ambos pasos al mismo tiempo. En nuestro caso se siguen las ideas de los enfoques jerárquicos y la propuesta de solución se basa en la utilización de varios enfoques de sistemas neuroborrosos existentes en la literatura para asignar una máquina a cada reporte y dar esa asignación como entrada a un algoritmo de secuenciación.
El resto del artículo está estructurado de la siguiente manera: La próxima sección presenta una descripción general de los problemas de secuenciación en ambientes con máquinas paralelas no relacionadas y posibles métodos de solución, y hace una descripción general del problema a resolver. Posteriormente se describen los algoritmos neuroborrosos aplicados a la problemática existente, y por último se muestra la configuración de los experimentos, así como los resultados obtenidos. El trabajo termina con conclusiones sobre los resultados obtenidos por los algoritmos neuroborrosos al aplicarse a los conjuntos de datos de clasificación de reportes.
CLASIFICACIÓN DE REPORTES EN PROBLEMAS DE SECUENCIACIÓN
En los problemas de secuenciación de tareas de la vida cotidiana se procesan trabajos siguiendo un determinado orden, de forma tal que se logre optimizar los tiempos en los que transitan por el sistema. La ejecución de los reportes generados por los clientes de los supermercados a través de compras por diferentes vías, es un problema de secuenciación de tareas. Muchos de los reportes deben cumplir una serie de condiciones y el sistema debe ser capaz de priorizar su ejecución en caso de ser necesario.
Existe una cantidad de m tipos de máquinas, donde cada tipo de máquina cuenta con un número determinado de recursos. También se tienen n reportes en lotes, agrupados por el tipo de reporte, los cuales deben ser procesados por un tipo de máquina. Estos reportes cuentan además con un idioma, un tiempo medio de procesamiento, una cantidad determinada de pedidos y un tiempo total de procesamiento que está dado por la cantidad de pedidos y la máquina especializada en este. Los reportes son independientes, por tanto, pueden ser procesados simultáneamente siempre que haya capacidad disponible. Si las máquinas están ocupadas, los reportes deben esperar que exista disponibilidad. Entre los recursos no existe ningún tipo de relación.
La Tabla 1 muestra un pequeño ejemplo donde se puede apreciar el formato de los datos que necesitan ser procesados. En el sistema existen 9 tipos de máquinas que procesan reportes con características específicas, pero además se cuenta con una décima que es capaz de asumir cualquier tipo de reportes, es decir, a la máquina número 10 se le puede asignar reportes que no necesiten tratamiento especial alguno y reportes de las otras 9 en caso de que estas sufran algún tipo de avería.
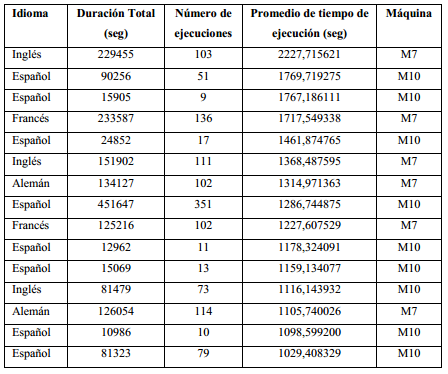
En este trabajo se cuenta con tres bases de casos con 150 lotes de reportes cada una, y cada base cuenta con la información en el formato mostrado en la tabla anterior. En el primer juego de datos las 10 máquinas están trabajando, por lo que cada reporte es asignado a su correspondiente recurso, y en los otros dos existen máquinas sin funcionar, uno con nueve recursos funcionando y el otro con solo seis. Como se mencionó anteriormente, al resolver un problema de este tipo se pueden usar dos alternativas, dividir el problema en ruteo y secuenciación, o resolver ambas cosas a la vez. En este caso para construir una solución al problema de secuenciación se ha optado por realizar inicialmente el paso de ruteo, por tanto, para cada reporte se debe decidir qué recurso lo procesará, y para eso se aplican los algoritmos neuroborrosos que se detallan en la próxima sección.
Sistemas Neuroborrosos
La creciente necesidad de desarrollar sistemas inteligentes adaptativos para solucionar problemas del mundo real ha hecho que la fusión entre las redes neuronales artificiales y los sistemas de inferencia borrosos haya atraído un creciente interés por parte de investigadores de diversas áreas científicas (Gajate-Martín, 2011). Los sistemas neuroborrosos surgen a principios de los noventa combinando las ventajas de las redes neuronales artificiales y de los sistemas de inferencia borrosos (Jang, 1993).
Es necesario aclarar que no basta que una red neuronal y un sistema de inferencia borroso sean usados juntos para estar en presencia de un modelo neuroborroso. Un sistema neuroborroso es una forma de crear un sistema de inferencia borroso utilizando algún tipo de heurística o método de aprendizaje inspirado en los mecanismos de aprendizaje usados en las redes neuronales (Nauck, 2000). Una de las ventajas fundamentales es que las redes neuronales aprenden “desde cero” a través del ajuste de las interconexiones entre sus distintas capas. Sin embargo, uno de los mayores problemas de estas técnicas es que el conocimiento aparece de forma implícita en forma de “caja negra” y suelen fallar cuando se producen comportamientos fuera de la región de entrenamiento (Gajate-Martín, 2011).
Por otra parte, los sistemas de inferencia borrosos pueden utilizar el conocimiento humano mediante el almacenamiento de información en forma de bases de reglas y conjuntos de datos, realizando posteriormente razonamientos borrosos para inferir el valor de salida. Estas técnicas permiten expresar incertidumbre en los sistemas basados en reglas y poseen además robustez intrínseca. Sin embargo, la obtención de las reglas borrosas y de las funciones de pertenencia correspondientes depende en gran medida del conocimiento que se tenga a priori del sistema objeto de estudio. Esto se plasma, entre otros factores, en la dificultad que existe para ajustar los parámetros de las funciones de pertenencia de manera óptima (Grau-García, y otros, 2012). La fortaleza principal de los métodos neuroborrosos es que son aproximadores universales que ofrecen reglas interpretables (Jin, 2000).
Además de las ventajas anteriormente detalladas, debemos mencionar que en el lugar donde se aplicarán los resultados de este trabajo existían investigaciones precedentes donde se utilizaban los sistemas de inferencia borrosos, y se solicitó que las primeras pruebas se realizaran utilizando este tipo de sistemas, de ahí que en esta investigación se decida utilizar los cuatro algoritmos que se describen a continuación:
FURIA (Fuzzy Unordered Rule Induction Algorithm): Este algoritmo constituye una ampliación o extensión de RIPPER (Cohen, 1995), un algoritmo de aprendizaje de reglas del estado del arte, preservando sus conocidas ventajas, como por ejemplo, los conjuntos de reglas simples y comprensibles. En particular, FURIA aprende reglas borrosas en lugar de reglas convencionales, y conjuntos de reglas no ordenadas en lugar de listas de reglas. Además, para tratar con ejemplos no cubiertos hace uso de una regla eficiente de estiramiento. Los resultados experimentales presentados en (Hühn, y otros, 2009) muestran que FURIA supera significativamente al algoritmo RIPPER original, así como a otros clasificadores como por ejemplo el C4.5, en términos de precisión de clasificación.
IVTURS (Sanz, y otros, 2013): Un sistema de clasificación lingüística basado en reglas difusas, el cual se basa en un nuevo método de razonamiento difuso evaluado por intervalos con ajuste y selección de reglas. Este proceso de inferencia utiliza funciones de equivalencia restringidas por intervalo para aumentar la relevancia de las reglas en las cuales la equivalencia de los grados de membresía por intervalos de los patrones y los grados ideales de membresía son mayores, lo cual es un comportamiento deseable. Adicionalmente, su construcción parametrizada permite calcular la función óptima para cada variable, lo que podría implicar una mejora potencial en el comportamiento del sistema. Además, este ajuste de la equivalencia se combina con la selección de reglas para disminuir la complejidad del sistema. IVTURS se compone de tres etapas: 1) La generación de un sistema de clasificación inicial basada en reglas difusas (IV-FRBCS). Para hacer esto, primero se aprende la base de reglas utilizando el algoritmo de aprendizaje de reglas difusas conocido como FARC-HD (modelo de clasificación basado en reglas de asociación difusa para problemas de alta dimensión) y luego se modelan las etiquetas lingüísticas con IVFS; 2) La aplicación de un IV-FRM y 3) Un paso de optimización que utiliza la sinergia entre el ajuste de la equivalencia y la selección de reglas.
SLAVE (Structural Learning Algorithm in Vague Environment): es un algoritmo de aprendizaje inductivo que utiliza conceptos basados en la teoría de la lógica difusa y utiliza un enfoque iterativo para aprender con algoritmos genéticos. Este método es un enfoque alternativo de los enfoques clásicos de Pittsburgh y Michigan. El algoritmo de aprendizaje extrae un conjunto de reglas difusas de una serie de ejemplos. Este proceso se desarrolla a través un método iterativo en el que se selecciona una regla cada vez. SLAVE utiliza un algoritmo genético para seleccionar la regla que mejor representa el sistema, esta se incorpora en el conjunto final de reglas. Con el fin de obtener nuevas representaciones, la regla anteriormente obtenida se penaliza (mediante la eliminación de los ejemplos incluidos en esta regla) y se repite el proceso. Este esquema iterativo se repite hasta que el conjunto de reglas obtenidas representa adecuadamente los ejemplos en el conjunto de entrenamiento, retornando el conjunto de reglas como la solución al problema (Gonzalez, y otros, 2001). Se han propuesto modificaciones a este algoritmo, que incluyen nuevos operadores genéticos para reducir el tiempo necesario para aprender y mejorar la comprensión de las reglas obtenidas. Además, se han propuesto nuevas formas de penalizar las reglas en el enfoque iterativo que permite mejorar el comportamiento del sistema (Gonzalez, y otros, 1999).
NSLV(González, y otros, 2009): Es un algoritmo de aprendizaje de reglas difusas basado en el uso de una estrategia de cobertura secuencial. Extrae iterativamente una regla única que se agrega al conjunto de reglas. La selección de la mejor regla en cada iteración se lleva a cabo por medio de una Algoritmo Genético. El algoritmo devuelve la base de reglas final obtenida al terminar el proceso de aprendizaje. NSLV es una versión mejorada de SLAVE2 que evita el sesgo generado por la selección de la clase en el proceso iterativo. Definitivamente, NSLV es la evolución natural de los algoritmos SLAVE y SLAVE2 descritos en (Garcia, y otros, 2014).
Como se mencionó anteriormente, el objetivo general de estos métodos es encontrar el conjunto de reglas difusas que mejor se ajuste a los datos de entrenamiento. En este trabajo se evalúa el desempeño de los cuatro métodos neuroborrosos descritos ante el problema de clasificación de reportes en problemas de secuenciación. Una vez aplicados estos algoritmos se obtiene una asignación de reportes a recursos, y es posible entonces pasar a realizar la secuenciación que no es más que encontrar el orden adecuado en que deben ejecutarse los reportes dentro de cada recurso, con el objetivo de minimizar el tiempo de completamiento. En la próxima sección se muestra un ejemplo de reglas obtenidas a partir de uno de los conjuntos de datos con los que se realizan los experimentos.
RESULTADOS Y DISCUSIÓN
Para la ejecución de los algoritmos neuroborrosos descritos en el epígrafe anterior se utiliza la herramienta Keel (Alcalá-Fdez, y otros, 2011), herramienta implementada en Java, de código abierto que permite resolver problemas de regresión, clasificación, agrupamiento, entre otros. Para esto cuenta con una gran colección de algoritmos de extracción del conocimiento, técnicas de pre-procesamiento, algoritmos de aprendizaje basados en inteligencia computacional, algoritmos evolutivos de aprendizaje de reglas basados en diferentes enfoques, etc.
Como paso inicial se importaron los datos en el Keel en formato xls y se aplicaron las respectivas divisiones o particiones que requiere el programa. Se utilizó validación cruzada en diez particiones (10 fold cross-validation). Los resultados de los experimentos en cuanto a la clasificación se muestran en la siguiente Tabla 2.
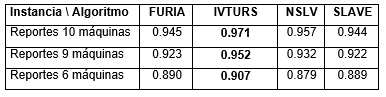
Según los resultados obtenidos y como se muestra en la tabla anterior, en todos los casos el algoritmo IVTURS obtiene los mejores resultados al tener una mayor calidad en las reglas difusas encontradas. Dichas reglas pueden ser interpretadas de manera tal que se obtenga una clasificación lo más certera posible en cuanto a que tipos de reportes están destinados a que máquina, teniendo en cuenta las características de los reportes. De la ejecución de los algoritmos analizados en este artículo se obtienen dos tipos de ficheros como resultados, uno que define las particiones difusas consideradas por el algoritmo para cada variable, y otro archivo que describe el conjunto final de reglas difusas obtenidas. En la Figura 1 se muestra un ejemplo de las particiones de las variables “número de ejecuciones” y “duración total”, para el caso en que todas las máquinas están funcionando.

Estas particiones, teniendo en cuenta los valores de dichas variables, pueden clasificarse en “muy bajo”, “bajo”, “medio”, “alto” y “muy alto”, en orden de L_0 (5) a L_4(5) respectivamente. En el caso de los idiomas las particiones serían: L_0(6)=inglés, L_1(6)=español, L_2(6)=francés, L_3(6)=alemán, L_4(6)=portugués, L_5(6)=dutch.
Utilizando las particiones mostradas anteriormente el algoritmo obtiene un conjunto de 12 reglas difusas de las cuales se ejemplifican cuatro en la Figura 2.

Utilizando el conjunto de 12 reglas difusas creadas por el algoritmo IVTURS se pueden establecer algunas asociaciones, por ejemplo, si analizamos la regla número 2, de acuerdo a las particiones creadas por el algoritmo, la misma establece que si el idioma es L_1(6), definido como español, entonces la máquina a la que se asigna el reporte es M10 con un factor de certidumbre entre 0.95 y 1. Un análisis similar puede realizarse con la regla 3, la cual establece que si el número de ejecuciones del reporte es bajo, entonces la máquina a la cual se envía es igualmente la número 10 con un factor de certidumbre entre 0.90 y 0.915. El conocimiento que se puede extraer de las reglas permite realizar una asignación apropiada de reportes a máquinas o recursos, con vistas a desarrollar posteriormente un proceso de secuenciación favorable en términos de tiempo de ejecución de las tareas a desarrollar.
CONCLUSIONES
En este trabajo se ha presentado el uso de sistemas neuroborrosos para la clasificación de reportes en ambientes de secuenciación, lo cual constituye un paso importante para el desarrollo del proceso de secuenciación de las tareas a ejecutar por los recursos disponibles. El uso de algoritmos neuroborrosos permite obtener un conjunto de reglas difusas para la interpretación de los resultados del modelo.
Los resultados experimentales mostraron que los cuatro métodos utilizados presentan buen rendimiento en cuanto a exactitud de la clasificación. Específicamente el algoritmo IVTURS obtuvo los mejores resultados para los tres juegos de datos utilizados en la experimentación.
Al analizar las reglas difusas obtenidas por este algoritmo se puede arribar a conclusiones importantes sobre la clasificación de los reportes teniendo en cuenta el idioma o el número de ejecuciones del mismo que se solicitan, este conocimiento puede ayudar en la toma de decisiones y en la utilización de los recursos de las empresas de forma eficiente.

